作者:昇腾实战派 * 3号小金鱼
背景概述
随着人工智能向更复杂、更贴近真实世界的应用演进,单一模态的模型已难以满足对多源信息融合与理解的需求。多模态大模型(Multimodal Large Language Models, MLLMs)应运而生,通过整合图像、文本、语音、视频等多种信息形式,实现跨模态的语义理解与生成能力。这类模型以Transformer架构为基础,将不同模态的数据统一转化为可处理的token序列,在统一的嵌入空间中完成特征对齐与信息融合,从而支持视觉问答、图像描述、多模态对话等丰富任务。近年来,从双编码器到LLM-based架构的演进,再到轻量化、可扩展、端到端统一建模的探索,多模态理解正逐步迈向更高效、更智能的新阶段。
当前昇腾平台已适配多种多模态大模型
基本概念
多模态大模型普遍基于Transformer based架构,NLP对文本进行embedding,CV对图像patch进行Embedding,从图像、视频、文本、语音数据中提取特征,转换为tokens,进行不同模态特征的对齐,送入(类)Transformer进行运算。
这类模型将LLM的生成与推理能力扩展到超越文本的数据,能够在多种信息模态下实现丰富的语义理解。现有方法大多集中于视觉-语言理解(VLU),通过融合视觉(如图像与视频)与文本输入,实现对空间关系、物体、场景及抽象概念的综合理解。这些模型运行在混合输入空间中,其中文本数据以离散表示方式编码,视觉信号则被编码为连续表示。与传统LLM类似,这类模型的输出以离散token形式生成,通常采用基于分类的语言建模和特定任务的解码策略。 下图展示了多模态理解模型的典型架构。
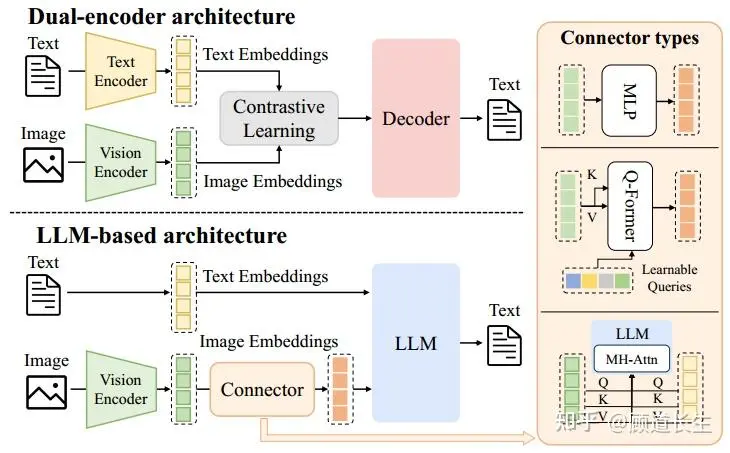
多模态理解模型的架构,包括多模态编码器 、连接器 与大语言模型(LLM):
- 多模态编码器将图像、音频或视频转换为特征,这些特征通过连接器处理后输入LLM。
- 连接器的架构大致可分为三类:基于投影的连接器、基于查询的连接器和基于融合的连接器。
视觉语言模型(VLM)两个大类别:
| 说明 | 架构图 | |
|---|---|---|
| 类别1:Dual-Encoder | 早期VLM模型主要采用双编码器架构,通过分别编码图像与文本,并在对齐的潜在空间中联合推理,代表性方法包括CLIP、ViLBERT、VisualBERT与UNITER。这些开创性模型奠定了多模态推理的核心原则,但过度依赖基于区域的视觉预处理和独立编码器,限制了模型的可扩展性与泛化能力。该类模型构建方法又称为"跨模态注意力架构方法"(cross-attention-based),该方法特点是引入交叉注意力机制, | * 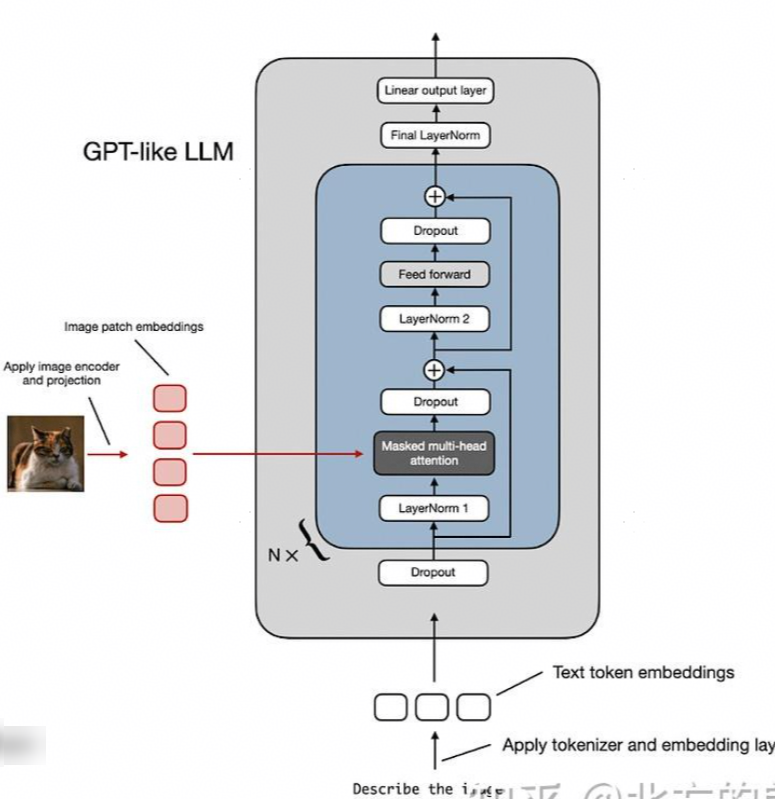 |
| 类别2:LLM-Based | 随着强大LLM的兴起,VLU模型逐渐转向仅解码器架构,通常以冻结或微调的LLM为基础。该类模型构建方法又称为"统一嵌入解码器架构方法"(decoder-only) 这些方法主要通过结构各异的连接器转换图像嵌入。连接器也分为3个主要类别:例如,* * MiniGPT-4采用单层可学习投影层,将CLIP提取的图像嵌入映射到Vicuna的token空间。* BLIP-2提出查询Transformer,将冻结的视觉编码器与冻结的LLM(如Flan-T5或Vicuna)连接,以极少的可训练参数实现高效视觉-语言对齐。* Flamingo则通过门控跨注意力层,将预训练视觉编码器与冻结的Chinchilla解码器连接。 | * 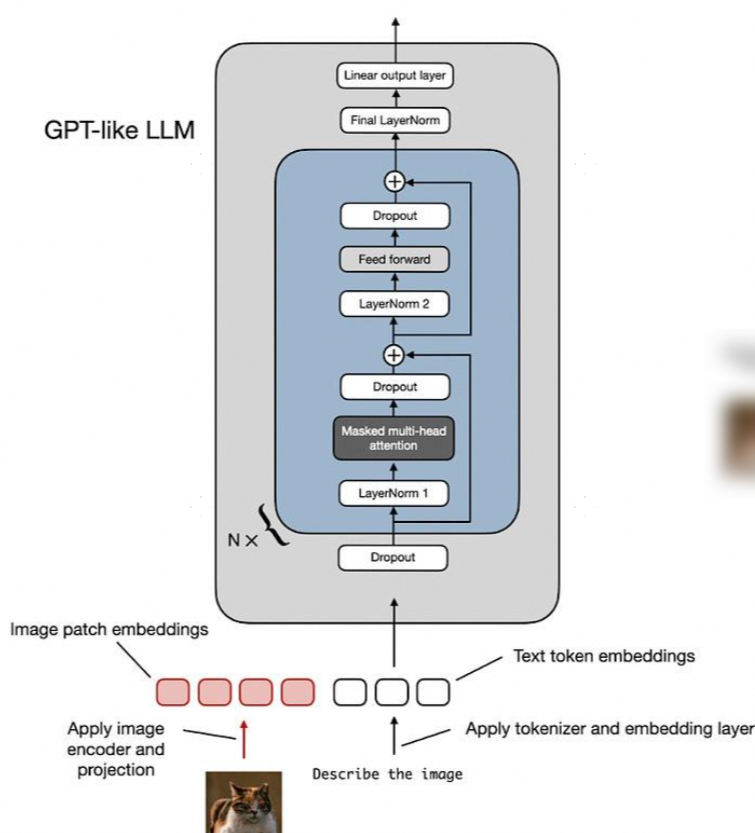 |
VLM前沿动态
- GPT-4V在GPT-4框架基础上扩展图像输入能力,虽为闭源模型,但展现出强大的视觉推理、图像描述与多模态对话能力。
- Gemini基于解码器架构,支持图像、视频与音频模态,其Ultra版本在多模态推理任务中树立了新基准。
- Qwen系列展示了可扩展的多模态设计:Qwen-VL集成视觉接收器 与定位模块,Qwen2-VL引入动态分辨率处理 与M-RoPE机制,增强对多样输入的稳健性。
- LLaVA-1.5与LLaVA-Next结合CLIP视觉编码器与Vicuna风格LLM,在VQA(视觉语言问答)与指令跟随任务中表现出色。
- InternVL系列探索统一多模态预训练策略 ,联合学习文本与视觉数据,提升各类视觉-语言任务表现。
- Ovis通过可学习的视觉嵌入查找表引入结构嵌入对齐机制,使视觉嵌入结构上对齐文本token。
近期部分模型进一步探索可扩展、统一的 多模态处理架构。DeepSeek-VL2采用专家混合(MoE)架构 ,提升跨模态推理能力。总体而言,这些模型展现出向指令微调、token中心化框架演进的趋势,能够以统一、可扩展的方式处理多样化多模态任务。
图像Patch
为什么需要将图像处理成 Patch?
传统的图像处理主要依赖于卷积神经网络(CNN),CNN 通过局部感受野和层层抽象来提取图像特征。然而,当前许多强大的 MLLMs 的基础架构是 Transformer 模型,这种模型最初为处理文本等序列数据而设计,其核心优势在于通过自注意力机制捕捉序列中元素之间的长距离依赖关系。 参考:链接
将原始图像直接输入 Transformer 面临两大挑战:
- 巨大的维度: 高分辨率图像包含海量像素点,直接将像素矩阵作为输入,维度过高,计算和内存消耗巨大,难以处理。
- 结构不匹配: Transformer 处理的是一维序列,而图像是二维网格结构。需要一种方式将二维图像转化为一维序列,同时尽可能保留原有的空间信息。
将图像分割成固定大小的"补丁"(patches)并排成序列,提供了一种优雅的解决方案。这种方法将图像类比于文本中的"词语"或"tokens",使得 Transformer 模型能够以处理文本序列的方式来处理图像。
图像 Patch 处理的详细过程
将原始图像转化为模型可接受的 Patch 序列通常包括以下几个步骤:
- 图像分割 (Image Segmentation into Patches):
- 过程: 将原始图像按照固定大小(例如 16×16 或 32×32 像素)分割成一系列互不重叠的小块。
- 示例: 对于一张 H×W 的图像,使用 P×P 的 patch 大小,会得到 (H/P)×(W/P) 个图像块。例如,256x256 图像用 16x16 的 patch 分割,会得到 16×16=256 个 patch。
- 目的: 将大型二维图像分解成可管理的、标准大小的基本处理单元。
- 展平 (Flattening):
- 过程: 将每个 P×P×C(高 × 宽 × 通道数)的图像块的像素数据按顺序展平为一个长度为 P×P×C 的一维向量。
- 示例: 一个 16x16x3 的 RGB patch 展平后得到一个 768 维的向量。
- 目的: 将每个图像块转换为一个标准的向量格式,适配后续的线性变换。
- 初始 Patch 嵌入 / 线性投影 (Initial Patch Embedding / Linear Projection):
- 过程: 对每个展平后的 patch 向量应用一个线性变换(一个全连接层)。这个线性层将高维的展平向量(维度 P2C)投影到模型内部统一的嵌入维度 D。
- 目的: 这不仅仅是维度变换,更是一个可学习的过程。它学习将原始像素数据映射到模型所在的嵌入空间中具有语义意义的向量表示,类似于文本处理中的词嵌入层。这一步将原始像素信息转化为模型能够理解的、低维稠密的特征嵌入。
- 位置编码 (Positional Encoding):
- 原因: Transformer 的自注意力机制是位置无关的,它处理序列时不考虑元素的顺序。然而,图像中 patch 的空间位置信息(哪个 patch 在左上角,哪个在右下角)至关重要。
- 过程: 在 Patch 嵌入向量中加入一个表示该 patch 在原始图像中空间位置的向量(位置编码)。位置编码可以是预设的(如正弦/余弦函数)或可学习的。
- 目的: 为每个 patch 嵌入注入空间上下文信息,使模型能够理解 patch 之间的相对和绝对空间关系,从而捕捉图像的整体结构。
Patch 之间的排序方式
将二维图像块排列成一维序列时,最常用和标准的方式是采用从左到右、从上到下 的顺序,即 raster scan 顺序。
这意味着,序列的第一个元素是图像左上角的 patch,然后依次是同行的右侧 patch,直到行末。接着是下一行的第一个 patch,再是同行的右侧 patch,以此类推,直到图像右下角的 patch 成为序列的最后一个元素(除了可能的 CLS Token)。
这种排序方式简单直观,并且与位置编码的生成方式紧密配合,使得每个序列索引都能唯一对应到原始图像中的一个空间位置。
将原本在二维空间中相邻的 patches(如上下相邻的 patch)在序列中隔开,这确实与 CNN 通过局部卷积核处理邻近区域 的方式不同。这会破坏某些依赖于严格二维邻近性的局部特征 吗?Transformer 模型依靠其独特的机制来克服这个问题,并不会因此"破坏"特征。
- 自注意力机制的全局连接能力: 与 CNN 的局部感受野不同,Transformer 的自注意力机制允许序列中的每一个 patch 嵌入 与所有其他 patch 嵌入直接计算注意力权重并进行信息交换,无论它们在序列中是相邻还是相隔很远。这意味着,即使上下相邻的 patch 在序列中距离较远,模型也可以在单个注意力层中捕捉到它们之间的关系。
- 位置编码提供的空间语境: 位置编码确保了模型知道每个 patch 在原始二维图像中的真实空间位置。模型学习到序列中相隔较远的两个 patch(例如,序列索引为 i 和 j 的 patch)在原始图像中是上下相邻的(例如,基于它们的位置编码),从而可以在处理过程中有效地整合它们的信息。
多模态编码器
又称为视觉骨干网络 ,在将图像 Patch 转换为初始嵌入序列后,这些序列会被输入到一个视觉骨干网络中,进行更深层次的特征提取和抽象。这个视觉骨干网络是 MLLM 中专门负责处理图像信息的部分。以下是一些常见的视觉部分选择及其分析。参考:链接
传统的卷积神经网络 (CNN)
- 代表模型: ResNet、ResNeXt、EfficientNet 等。
- 核心思想: 利用卷积和池化进行层次化特征提取。
- 优点: 技术成熟,计算效率相对较高(对于局部特征),对局部结构敏感。
- 缺点: 缺乏原生处理长距离依赖的能力,输出格式需转换,缺乏原生的跨模态对齐。
- 应用场景: 早期或特定需求(如边缘设备)的 MLLMs,或作为混合模型的一部分。
原生视觉 Transformer (ViT)
- 代表模型: Vision Transformer (ViT) 原始版本及其变体。
- 核心思想: 在 Patch 序列上直接应用标准的 Transformer Encoder。
- 优点: 强大的全局建模能力,与 Transformer 架构天然兼容,可扩展性强。
- 缺点: 对局部细节捕捉相对弱,计算量大(高分辨率),缺乏原生的跨模态对齐。
- 应用场景: 许多现代 MLLMs 的首选,特别是需要强大全局视觉理解能力的模型。
层次化视觉 Transformer (Hierarchical ViT)
- 代表模型: Swin Transformer、PVT 等。
- 核心思想: 结合层次化思想和 Transformer,逐步扩大感受野。
- 优点: 兼顾局部和全局信息,计算效率更高(特别是高分辨率),输出多尺度特征。
- 缺点: 结构相对复杂,缺乏原生的跨模态对齐。
- 应用场景: 处理高分辨率图像、对计算效率有要求或需要多尺度视觉特征的 MLLMs。
图文对齐模型 (Image-Text Alignment Models) 的图像编码器
- 代表模型: CLIP(其 Vision Transformer 或 ResNet 图像编码器)、ALIGN、Florence、CoCa 等。
- 核心思想: 在大规模图文对数据上进行对比学习等联合训练,使图像和文本在共享空间中对齐。
- 优点:强大的预训练跨模态对齐能力,泛化能力强,简化后续融合。
- 缺点: 可能牺牲部分纯视觉任务性能,依赖预训练数据质量。
- 应用场景: 当前绝大多数领先的 MLLMs 首选,特别是需要理解图文关联和开放世界概念的模型。
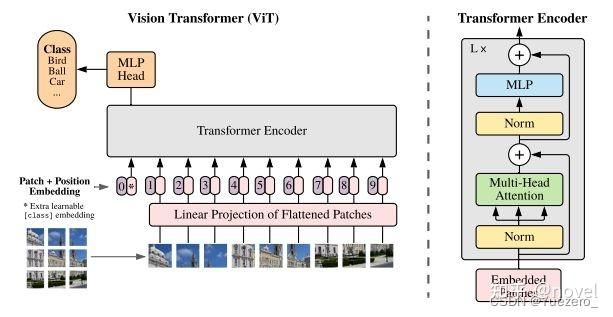
ViT
vit开山论文《 An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale (2020)》
ViT(Vision Transformer)是一种将 Transformer 模型应用于图像分类任务的方法。它将图像分割为一系列的小块patch,并将每个小块作为序列输入 Transformer 模型。通过自注意力机制,ViT 能够在图像中捕捉全局和局部的视觉信息,实现图像分类,示意图如下:
上图所示的 "线性投影" 由单个线性层(即全连接层)(全连接为比较原始的实现,后续通常使用conv算子来替换linear全连接,【通常conv2d可以等价看做稀疏的linear连接】)组成。此层的目的是将图像块(展平为矢量)投影为与 transformer 编码器兼容的嵌入大小。展平为 256 维向量的图像块将向上投影到 768 维向量,如下图:
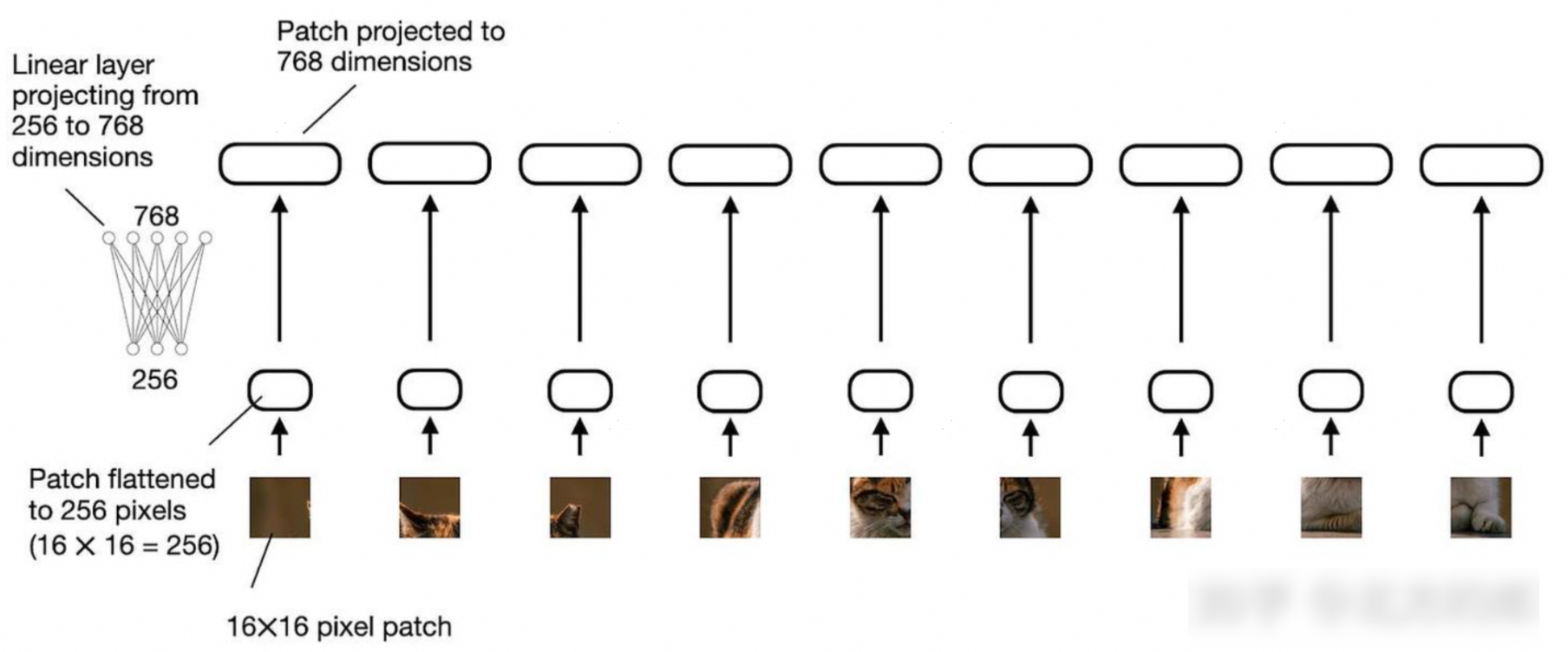
ViT通常作为图像编码器,与文本的分词和嵌入类似,生成图像嵌入(经过Projector之后和文本信息融合)
参考:深入浅出多模态大模型
Hierarchical ViT
Hierarchical ViT(Hierarchical Vision Transformer,分层视觉 Transformer)是对原始 ViT(Vision Transformer)的改进,核心是通过多阶段下采样模拟卷积神经网络(CNN)的层级特征提取能力,在保持 Transformer 全局建模优势的同时,提升对多尺度视觉信息的捕捉效率。以下从来源、原理和应用模型三方面展开说明。
背景
原始 ViT(2020 年由 Google 提出)将图像分割为固定大小的非重叠 patch(如 16×16),直接输入 Transformer 编码器,输出单一层级的特征。但这种设计存在明显局限:
- 多尺度信息缺失:原始 ViT 仅输出单一分辨率的特征(如输入 224×224 图像,输出 14×14 的 patch 特征),无法像 CNN(如 ResNet)那样通过池化层生成不同分辨率的层级特征(如高分辨率的边缘信息、低分辨率的语义信息)。
- 计算效率不足:若需处理高分辨率图像(如 512×512),原始 ViT 的 patch 数量会急剧增加(如 512/16=32,32×32=1024 个 patch),导致 Transformer 的自注意力计算量平方级增长。
为此一系列"分层ViT结构"被提出,典型包括**PVT(Pyramid Vision Transformer,2021)、Swin Transformer(2021)**,核心原理是引入 CNN 式的多阶段下采样,构建层级化特征金字塔。
基本原理
核心思想是分阶段对特征进行下采样 ,逐步减少序列长度(patch 数量),同时增加特征维度,最终生成多分辨率的层级特征图,与 CNN 的 "高分辨率→低分辨率" 特征金字塔一致。
1. 多阶段结构(对应 CNN 的 "卷积块 + 池化")
将网络分为多个阶段(通常 4 个阶段,对应 CNN 的 conv1 到 conv4),每个阶段包含:
- Patch 合并 / 重排列(Patch Merging/Reorganization):对当前阶段的特征进行下采样(如 2×2 合并),减少 patch 数量(序列长度)。例如:
- 阶段 1:输入图像分割为 4×4 小 patch(如 8×8 像素),生成高分辨率特征(如 56×56 序列长度);
- 阶段 2:将 2×2 相邻 patch 合并为 1 个新 patch,序列长度降至 28×28,特征维度翻倍;
- 后续阶段重复此操作,最终输出 4 个分辨率的特征(如 56×56、28×28、14×14、7×7)。
- Transformer 编码器:每个阶段用 Transformer 处理当前分辨率的 patch 特征,捕捉该尺度下的局部与全局依赖。
2. 适配多尺度任务的特征输出
最终输出的多层级特征可直接用于需要多分辨率信息的任务:
- 高分辨率特征(如 56×56)保留细节信息(边缘、纹理),适合目标检测中的定位;
- 低分辨率特征(如 7×7)包含高层语义(类别、场景),适合图像分类或语义分割。
3. 计算效率优化
通过分阶段下采样,序列长度随阶段指数级减少(如从 56×56→28×28→14×14→7×7),避免了原始 ViT 中长序列导致的高计算量(自注意力复杂度为 O (N²),N 为序列长度)。
典型模型应用
分层结构已成为视觉 Transformer 的主流设计,以下是代表性模型:
1. Swin Transformer(2021,微软)
- 创新点:引入 "移位窗口注意力(Shifted Window Attention)",在分层下采样的同时,通过窗口内注意力减少计算量,并通过窗口移位实现跨窗口信息交互。
- 应用:在 ImageNet 分类、COCO 目标检测、ADE20K 语义分割等任务上均达到 SOTA,是首个在检测 / 分割任务上超越 CNN 的 Transformer 模型,后续被用于多模态模型(如 Swin-LLaVA)。
2. PVT(Pyramid Vision Transformer,2021,清华大学)
- 创新点:极简分层设计,通过 "Patch Embedding" 分阶段调整 patch 大小(如阶段 1 用 4×4,阶段 2 用 2×2)实现下采样,无额外窗口约束,保留全局注意力优势。
- 衍生模型:PVTv2 进一步优化了自注意力计算,引入相对位置编码,在小数据集上表现更优。
3. ConvNeXt VIT(2022,Meta)
- 创新点:融合 CNN 与分层 ViT 的优势,用卷积进行下采样,用 Transformer 处理特征,既保留 CNN 的局部归纳偏置,又具备 Transformer 的全局建模能力。
- 特点:在 ImageNet 上精度与 Swin 相当,但训练速度更快。
4. ViTAE(2021,北大 & 华为)
- 创新点:提出 "自适应分层注意力(Adaptive Hierarchical Attention)",根据任务动态调整不同阶段的注意力范围(局部 / 全局),平衡效率与精度。
- 应用:在低分辨率图像分类和高分辨率遥感图像分割任务中表现突出。
5. 多模态模型中的应用
- FLAVA(2021,Meta):用分层 ViT 提取图像多尺度特征,与文本特征在不同层级对齐,提升跨模态检索精度。
- LLaVA-HiT(2023):基于 Swin Transformer 构建分层视觉编码器,为大语言模型提供多分辨率视觉特征,增强细粒度图像理解能力。
Clip
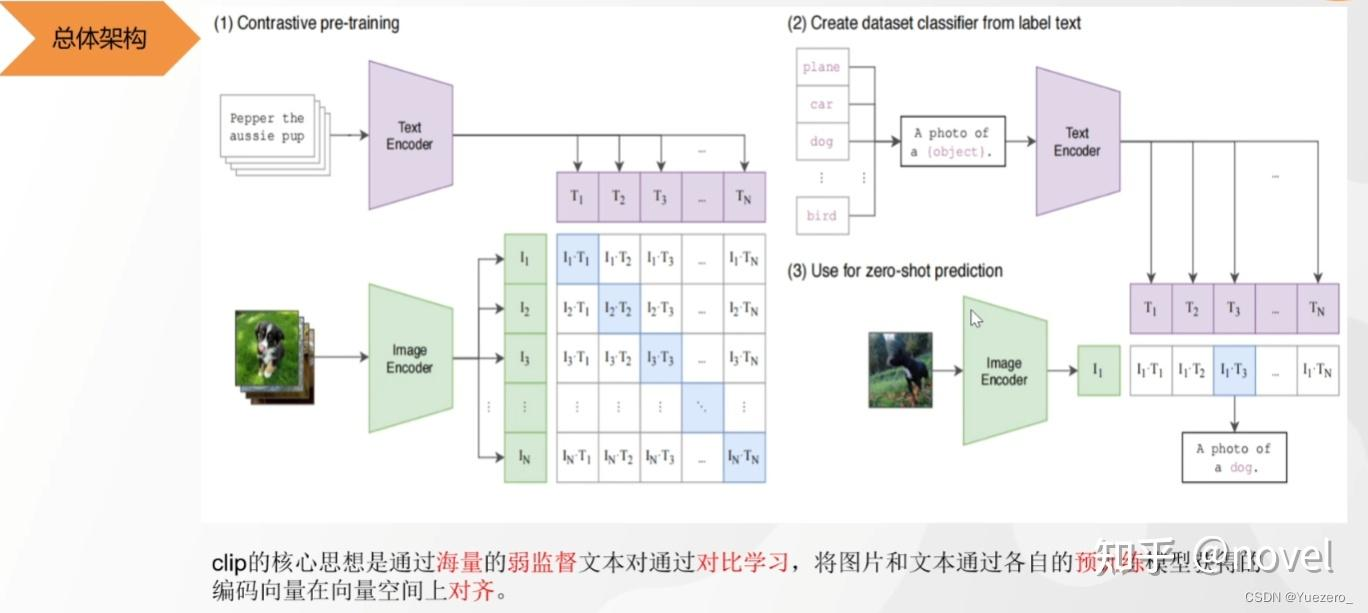
CLIP (Contrastive Language-Image Pretraining)是一种跨模态的预训练模型,它能够同时处理图像和文本。通过将图像和文本进行对比学习 ,CLIP 提供了一个共享的视觉和语义空间,使得图像和文本可以进行直接的匹配和检索。 (参考:链接)
打分矩阵的对角线为正样本,从i2t和t2i的方向分别计算infoNCE损失
CLIP------图文匹配 预训练图像和文本编码器 :训练<图片,文本>对,进行对比学习。N个图像和N个文本,用Bert和ViT提取文本和图片的特征(768维),向量两两相乘,得到<图片,文本>对儿之间的余弦相似度(向量乘法)。标签对比学习 :对角线上相匹配的图文是正样本(正确的pair=1),其他不匹配的全是负样本(错误的pair=0),这两个标签计算loss反向传播,最大化正样本对的余弦相似度,最小化负样本对的优余弦相似度,约束前面的Bert和ViT梯度下降修改参数。最终预训练得到文本和图像编码器Bert和ViT。 根据刚刚的预训练,任意给出文本(dog、car、cat...)与图片计算余弦相似度(相乘),相似度分数最大的就是正确的<图片,文本>对。
CLIP是一个双塔结构,分别有图片塔f(.)和文本塔g(.),那么损失可以表达为如下公式:(B为batch_size,t为可学习参数,常用来表示温度系数)
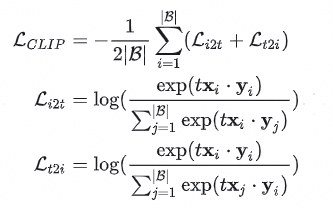
其基本思想就是从打分矩阵中,从i->t和t->i的方向去判断出正样本的位置(也就是对角线的位置),注意到由于采用的是softmax形式去归一化正负样本,将其视为了概率分布,因此正负样本之间的概率关系是耦合在一起的,在提高正样本概率的同时,势必会压低负样本的概率。
clip采用的是跨模态注意力机制 ,通常使用在双编码器架构类型的VLM模型中,通过CrossAttention来实现,是Transformer 模型(SelfAttention)中的一种注意力机制。与自注意力机制不同,CrossAttention 允许模型在处理输入序列时,同时关注另一个相关的序列。CrossAttention 在多模态任务中经常使用,例如将图像和文本进行对齐或生成多模态表示。(Q和K不同源,K和V同源)
Siglip
采用sigmoid损失的图文预训练方式。 【2024 微信搜索团队】 (参考:链接)
CLIP中的infoNCE损失是一种对比性损失,在SigLIP这个工作中,作者提出采用非对比性的sigmoid损失,能够更高效地进行图文预训练。在SigLIP中,损失函数如下公式所示,其中的Zij为给定图片文本对的标签,当为成对的正样本时候Zij=1,当不是成对的负样本时候Zij=-1。此时对于正负样本来说是解耦的,增加正样本的概率并不意味着压低负样本的概率。负样本数量的绝对占优,会导致在训练初期负样本的损失主导了整个损失,因此引入了一个可学习的偏置项b去缓解初始阶段的训练困难问题。
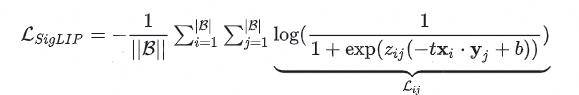
- 在CLIP中,正负样本是pairwise 建模的:由于采用的softmax函数去建模正负样本之间的关系,而CLIP训练的global batch size一般都很大(如32k),这意味着某GPU上的正样本需要见到其他所有GPU上的样本 ,并以此作为负样本。因此通常都需要汇聚多节点多卡的特征向量,这个时候需要频繁地调用**
all_gather**,带来了沉重的通信代价,也会拖慢整个训练过程的速度。 - 在SigLIP中,正负样本是pointwise 建模的:采用的sigmoid loss是独立对每个正负样本进行计算的,最后再进行loss的累加,这意味着可以在本地完成大部分的计算,在涉及到本地的正样本和其他设备的负样本进行交互计算的时候,仅需要很少的
gather操作就能完成设备间向量的交换就可以(对于图文预训练来说,交换文本特征向量即可 ,通信代价很低),而不需要all_gather操作。
多模态连接器(VL-Adapter)
多模态模型中有效地融合和处理图像信息,是构建强大 MLLMs 的关键挑战之一。无论选择哪种视觉骨干网络,其输出的视觉特征(例如 ViT 的 CLS Token 输出,CLIP 的图像嵌入,或 CNN 的最终特征图)通常需要一个额外的转换步骤,以便与模型中的其他模态(尤其是文本)信息进行有效的融合和交互。这个转换通常由一个或多个线性层(有时是更简单的 MLP)完成,我们称之为 Projector(投影层)。
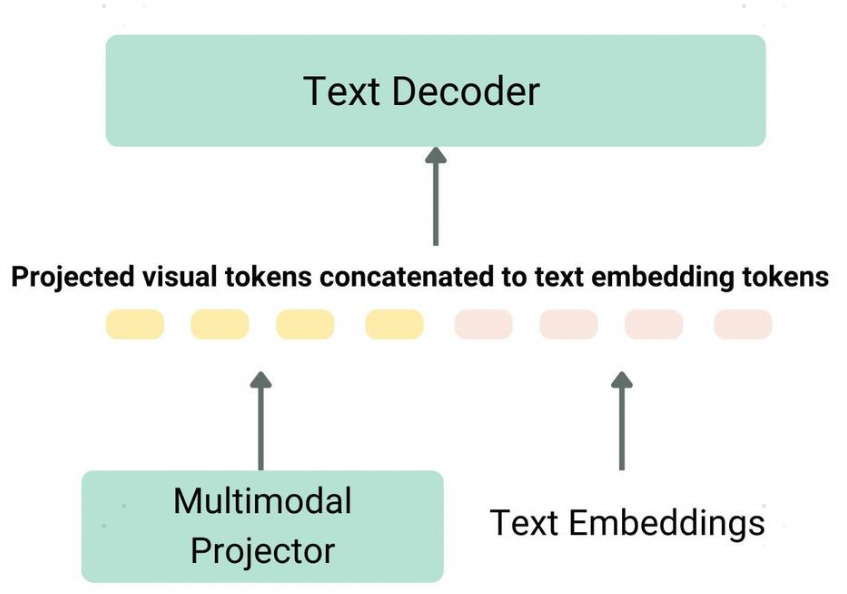
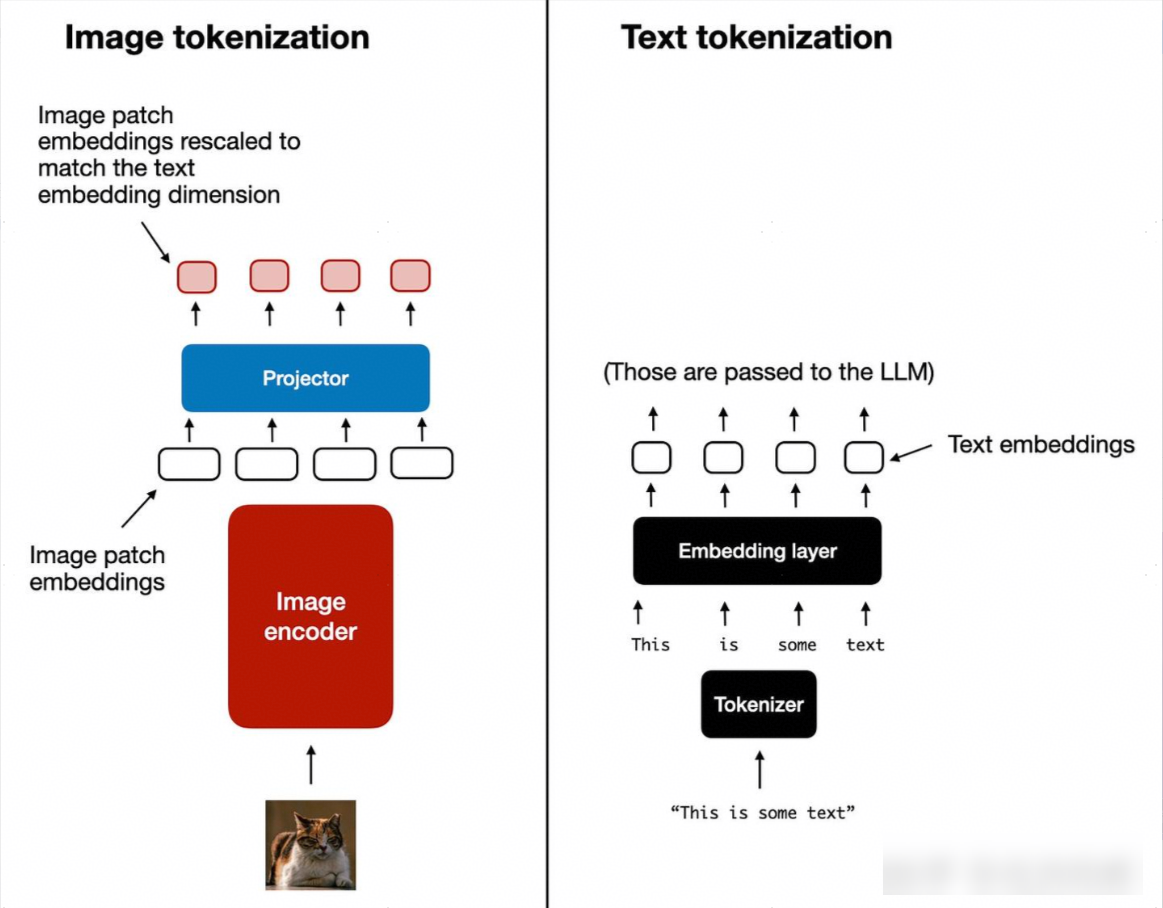
如上图所示,图像Embedding和文本Embedding需要进行融合,就需要一个叫做多模态连接器的模块,该模块作用:
-
- 统一的多模态嵌入空间:可以将多种模块的潜在语义空间进行对齐,
- 维度对齐:另外也可以将两类Embedding的hidden_state维度进行对齐。
Projector 在不同视觉骨干和训练场景下的必要性,使用基于图像任务预训练的视觉骨干(CNN, 原生 ViT, 层次化 ViT):
-
- 这些骨干网络在图像分类等任务上预训练,其特征空间主要反映视觉本身的特征,与语言嵌入空间是独立的。
- 在这种情况下,Projector 层是至关重要且必不可少的。它需要学习一个复杂的映射,将纯视觉空间中的特征有效地转换到语言模型的嵌入空间,以实现模态间的对齐。Projector 承担着主要的跨模态对齐学习任务。
多模态Projector的通常结构简单,可以使用线性投影:例如SmolVLM-256M-Instruct模型的Projector结构就是一个线性投影:
如上所述,除了线性投影层(MLP),Projector还有Q-Former和LLM其它这两种典型架构,如下图:参考链接
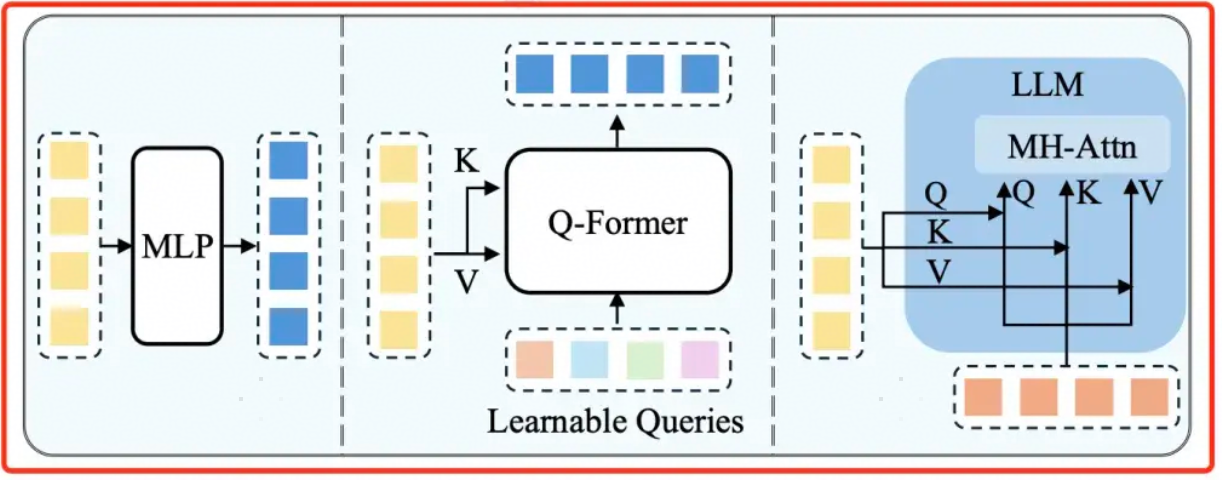
Q-Former
Q-Former 首次是在微软 2021 年的论文《BLIP: Bootstrapping Language-Image Pre-training》,并在后续多模态模型(如 BLIP-2、LLaVA 等)中广泛应用,提出一种轻量化的Querying Transformer(Q-Former)来弥补模态之间的差异,大大降低了可训练参数量,并采用两阶段来训练它:
- 第一阶段采用通过冻结的图像编码器来学习图像-文本表征能力,
- 第二阶段采用冻结的LLM学习图像到文本的生成能力。
最新的论文很少见到Q-Former 的方案了,逐渐被淘汰了,原因主要是Q-Former参数量(100+M)相对于Linear/MLP等更大,收敛更慢,相同setting下无法取得LLaVA-1.5这样优秀的性能。并且,在数据量和计算量都充足的前提下,Q-Former也没有展现出明显的性能收益。 代表模型包括:BLIP-2、InstructBLIP、VisCPM、VisualGLM。
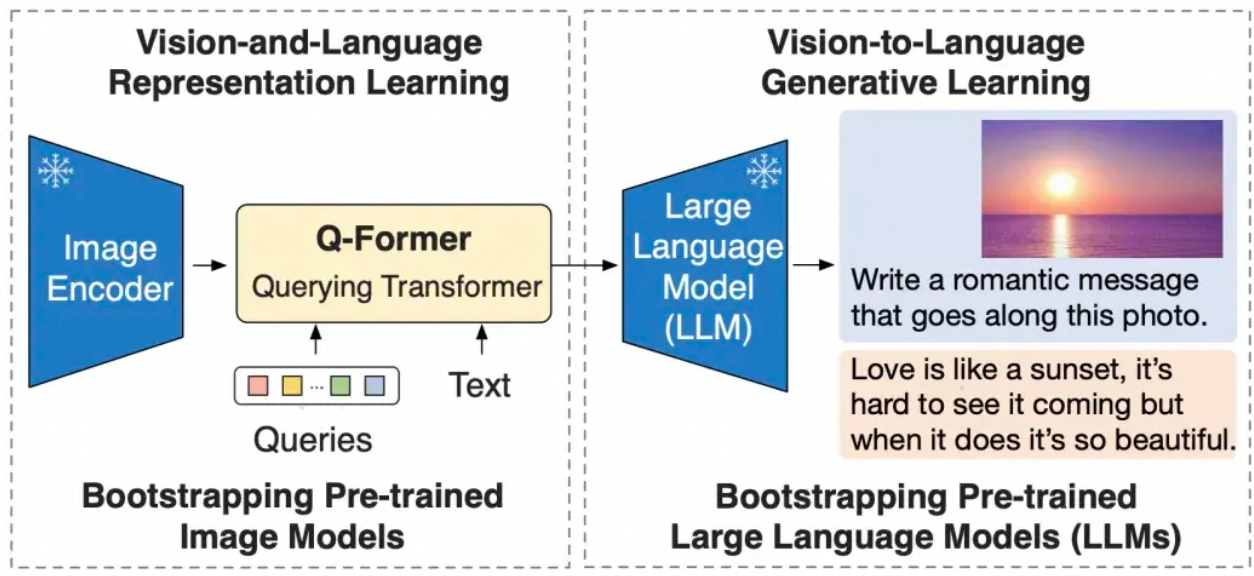
Q-Former(Query Transformer)是一种连接视觉编码器与语言模型的桥梁机制,核心思想是通过可学习的查询向量(Query) 对视觉信息进行高效提取和语义对齐,解决视觉 - 语言任务中 "视觉特征冗余" 和 "跨模态语义鸿沟" 的问题。
核心原理:用 "查询向量" 作为视觉 - 语言的中间媒介
Q-Former 的核心是一个轻量级 Transformer 编码器,包含两组输入:
-
- 可学习的查询向量(Queries):数量固定(如 32 或 64 个),作为 "视觉信息的语义探测器",不依赖具体图像内容,通过训练学习如何从视觉特征中提取有价值的信息。
- 视觉特征序列:由视觉编码器(如 ViT)输出的图像 patch 特征(通常数量较多,如 14×14=196 个),包含图像的细粒度空间信息。
通过 Q-Former 的自注意力机制,查询向量会与视觉特征进行交互,最终输出查询向量的语义特征------ 这些特征既保留了图像的关键信息,又被压缩到固定长度(与查询向量数量一致),便于后续与语言模型对接。
关键设计:实现视觉信息的 "语义压缩" 与 "语言对齐"
- 视觉特征的高效筛选
原始视觉编码器输出的 patch 特征数量多(如 196 个)且包含大量冗余信息(如背景像素)。Q-Former 通过查询向量与视觉特征的注意力交互,自动聚焦于图像中与语义相关的区域(如物体、场景),最终用少量查询向量(如 32 个)的特征 "浓缩" 图像的核心信息,避免将冗余视觉特征直接输入语言模型导致的效率低下。 - 跨模态语义对齐
Q-Former 在预训练阶段(如用图文对数据)同时接收视觉特征和文本序列(通过文本编码器转换为特征),让查询向量在与视觉特征交互的同时,也通过交叉注意力与文本特征对齐。这种设计使查询向量的输出特征天然具备 "视觉语义→语言语义" 的映射能力,缓解了视觉与语言的模态差异。 - 灵活性与通用性
Q-Former 的输出是固定长度的查询特征(如 32×d),可无缝对接各种语言模型(如 GPT、Llama 等),无需修改语言模型结构。同时,通过调整查询向量的数量,可灵活平衡信息保留与计算效率(如少查询向量适合轻量任务,多查询向量适合细粒度理解)。
优势总结
- 降维增效:将高维视觉特征压缩为固定长度的查询特征,减少后续语言模型的输入负担。
- 语义聚焦:通过注意力机制自动筛选关键视觉信息,避免冗余干扰。
- 模态对齐:预训练中同时学习视觉与语言语义,使查询特征成为跨模态桥梁。
- 兼容性强:可适配任意视觉编码器和语言模型,便于灵活构建多模态系统。
Q-Former 的设计为多模态模型提供了一种高效的 "视觉 - 语言接口",是近年来 BLIP 系列、LLaVA 等主流多模态模型的核心组件。
线性投影器及MLP
Linear Projector(线性投影器 )首次被引入 MLLM 是2023年4月 LLaVA1.0 的发布,论文中提出了一种更简单的投影方法,通过线性变换将Modality Encoder编码的特征映射到LLM的表示空间中。代表模型主要有:LLaVA、MiniGPT-4、NEXT-GPT。 主要优点是结构简单,效果不弱于Q-Former。
多层感知机(Multi-Layer Perception, MLP) 首次被引入 MLLM 是在2023 年 10 月 LLaVA1.5 中提出的,LLaVA1.5 在对比LLaVA1.0结构上,将视觉特征从线性映射(单个神经元),改进为多层感知机(MLP)。代表模型包括:LLaVA1.5/NeXT、CogVLM、DeepSeek-VL、Yi-VL。MLP结构成为了的MLLM中模态对齐的主流结构,LLAVA 系列的技术路线被大家更认可,主要原因是:MLP用最简洁的结构在效果上碾压其他一众复杂结构,并且具有更快的收敛速度,对数据量的依赖也少。
其它
2022年DeepMind提出感知重采样技术(Perceiver Resampler)主要采用了感知重采样 和门控交叉注意力技术,代表模型有Flamingo、Qwen-VL、MiniCPM-V、LLaVA-UHD。
- 感知重采样:其输入是视觉编码器(如 ViT)输出的视觉 patch 特征 (通常数量众多,例如一张图像会被拆分为 1000 + 个 patch,序列长度很长),输出是固定长度的重采样特征(例如 64 或 128 个向量),可直接作为语言模型的输入。通过少量可学习的 "重采样向量(Resampler Vectors)",从大量视觉特征中提取关键语义信息,将变长、高冗余的视觉输入压缩为固定长度的特征序列,同时保留与语言任务相关的核心信息。
- 门控交叉注意力机制:在每一层LLM上都会增加corss- attention以入到LLM中与视觉向量进行交互,融合多模态信息。
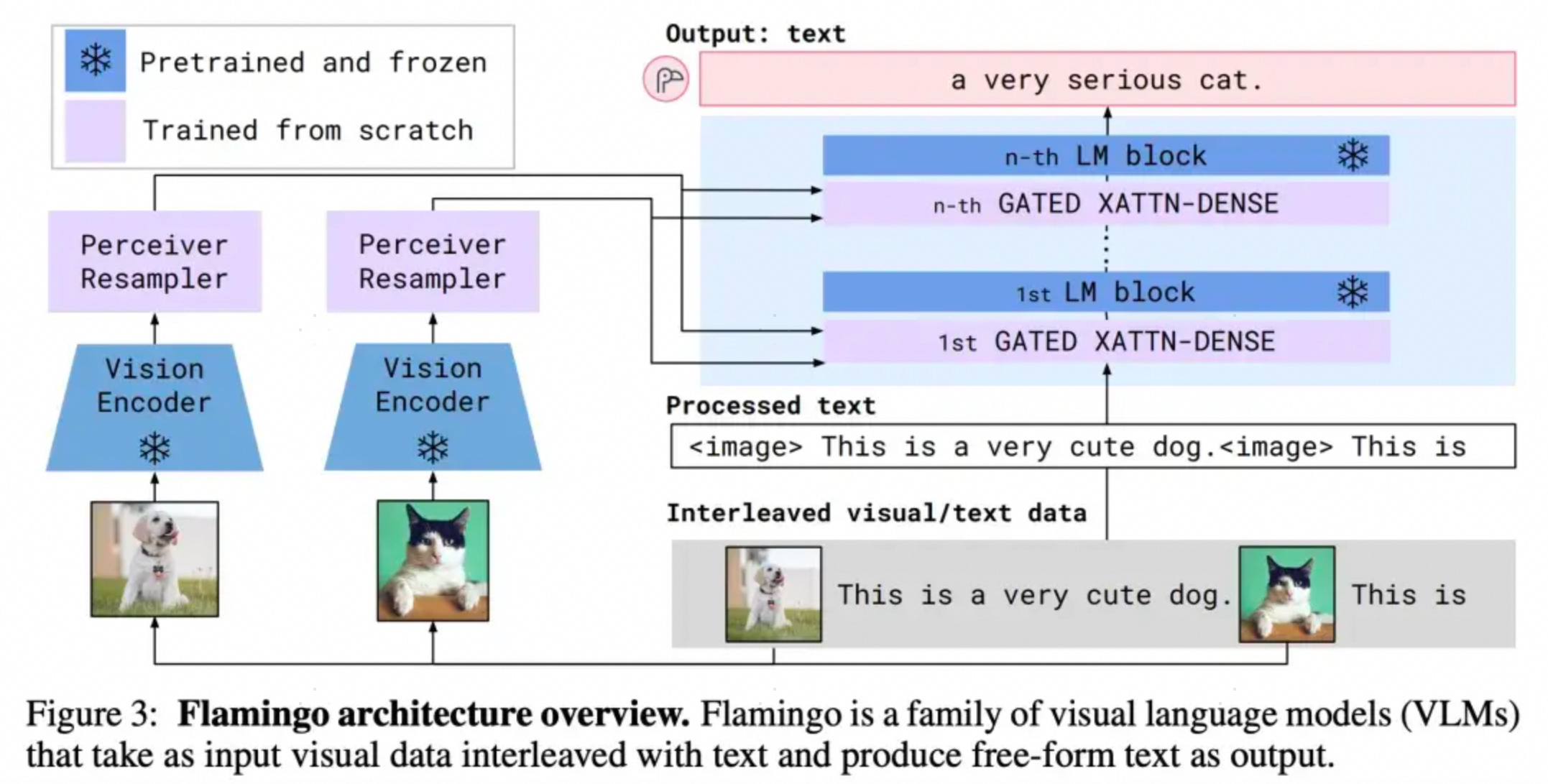
常见的多模态Projector以及对应的模型如下图所示:

几种方法优缺点对比概述:
- Q-Former:参数量大,训练的成本较高,需要更多的数据,且目前看来尽管使用更多数据,性能上与MLP相比也没有优势。
- Linear Projector:简单高效,适用于计算资源有限的场景,但是效果上不如MLP;
- MLP: 具有强大的表示能力,适用于需要捕捉复杂关系的任务。
- Perceiver Resampler :在多模态信息融合中表现出色,尤其适用于需要跨模态交互的任务,resampler降低tokens后,在高分辨率、多图、视频的训练上都会降低很多成本。一层cross-attention block的resampler,和MLP在参数量上接近。
经典模型---Dual-Encoder架构
Kimi-VL-A3B-Thinking-2506
Kimi-VL-A3B-Thinking-2506是当前表现顶尖的 Dual-Encoder 多模态理解模型。它凭借在数学推理、视频理解、高分辨率视觉感知等多个核心任务上的突破性性能,远超同类型双编码器模型,同时兼顾轻量化与高效性,成为该架构下多模态理解的标杆模型。
架构适配性强,延续双编码器核心设计: 视觉端采用MoonViT 编码器,具备 14×14 图像分块、27 层网络结构等配置,能原生处理高分辨率图像;文本端则基于DeepSeek-V3 优化版编码器,支持 128K 长上下文处理,适配多语言文本的深层语义提取。两者通过 MLP 投影器实现跨模态特征融合,既保留了双编码器模型分开编码、支持离线计算的高效特性,又强化了模态间的语义对齐能力。
轻量化设计兼顾效率,落地性极强:该模型采用 MoE(混合专家)架构,语言解码器仅激活 2.8B 参数,配合 Muon 优化器提升训练稳定性,在降低计算成本的同时,还优化了推理效率 ------ 多模态推理任务的平均思考长度减少 20%。这种 "高效能 + 轻量化" 的特点,让它既适合学术场景的复杂推理任务,也能适配工业界大规模检索、实时视觉交互等对速度和成本敏感的场景。
经典模型---LLM-based架构
Qwen VL系列
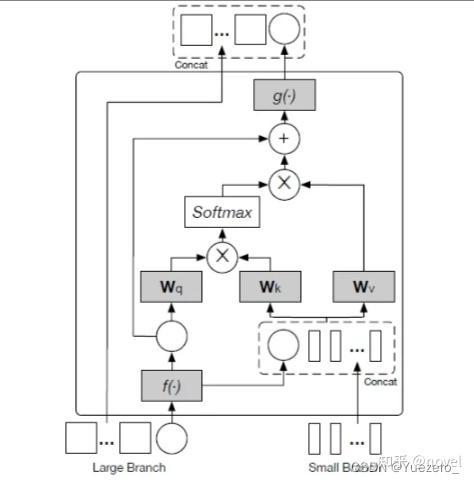
Qwen VL模型于2023年8月发布,基于Qwen-7B 为基座研发,模型采用 ViT - bigG(基于openclip训练而来) 作为视觉编码器,搭配位置感知的 VL 适配器压缩视觉特征并保留位置信息,实现在图文识别、描述、问答等基础功能上新增视觉定位和图像文字理解能力。模型输出案例:(已目标识别为例)

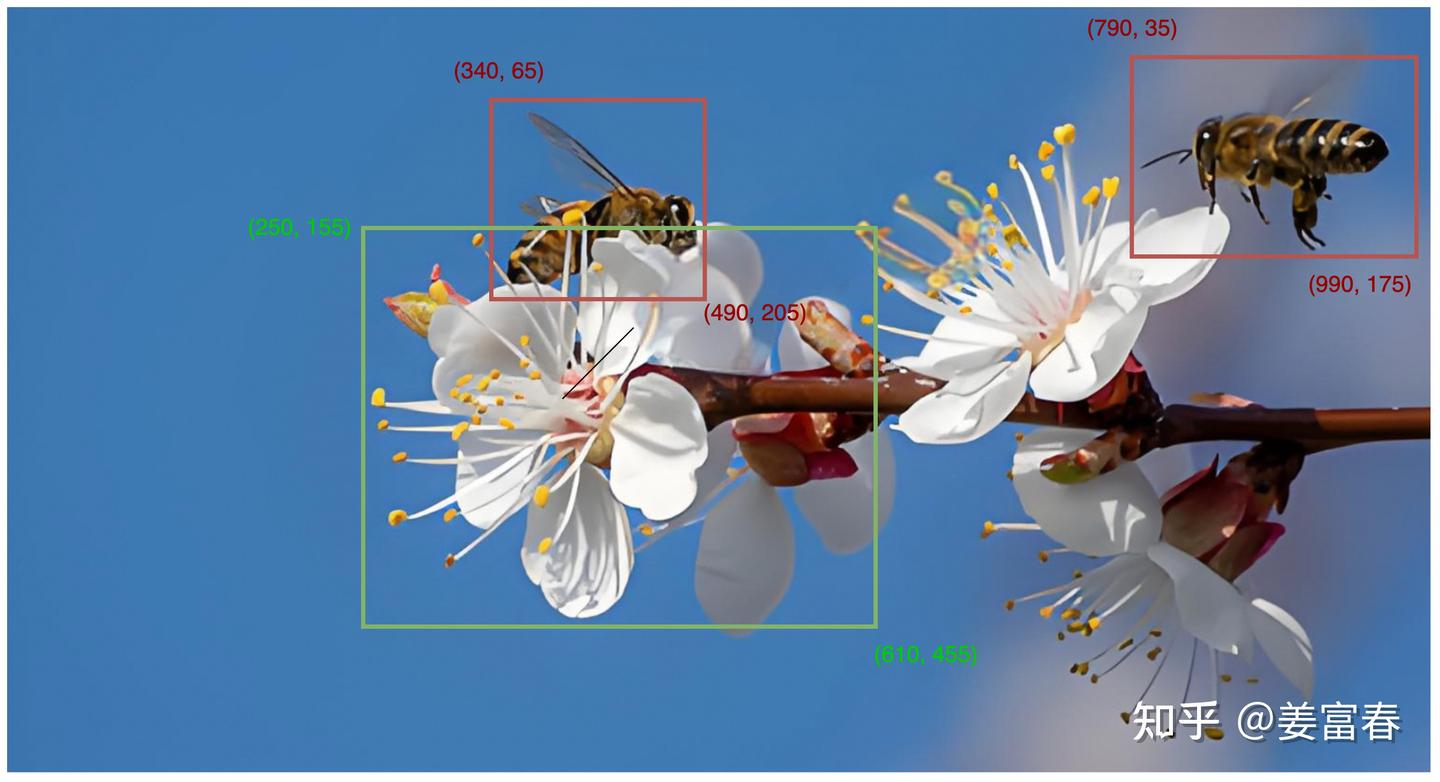
模型特色功能原理介绍如下:
位置感知的适配器
该adapter是一个随机初始化的单层Cross-Attention模块,使用一组可学习的query向量,将来自ViT的图像特征作为Key向量。通过Cross-Attention操作后将视觉特征序列压缩到固定的256长度。【Q-Former类别的Adapter】
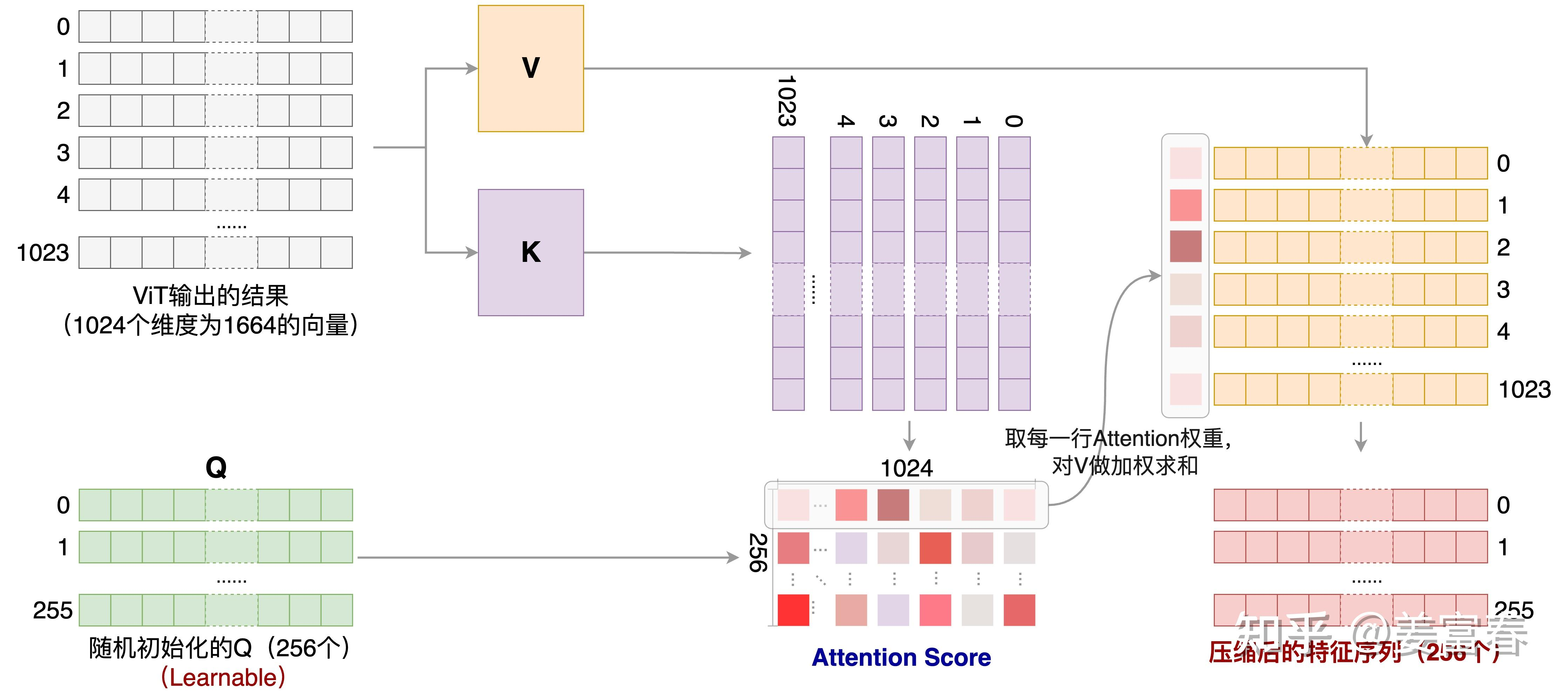
上图描述了基于可学习Query和ViT输出的序列作为 的Attention计算过程,经过Cross-Attention后,将ViT阶段的1024长度的序列,压缩到了长度为256的序列。此外,考虑到位置信息对于精细图像理解的重要性,Qwen-VL将二维绝对位置编码(三角位置编码)**【位置感知】**整合到Cross-Attention的 中,以减少压缩过程中可能丢失的位置细节。随后将长度为256的压缩图像特征序列输入到大型语言模型中。
Qwen2 VL基于 Qwen2 LLM 完成升级,提供 2B、8B、72B 三种参数规模,有如下特点:
- 引入Naive Dynamic Resolution(NDR) 机制,能根据图像分辨率自适应生成视觉 token,解决固定分辨率的处理瓶颈;
- 序列长度压缩的Adapter;
- 提出M - RoPE 多模态旋转位置编码,统一文本、图像、视频的位置信息建模。
此外,它还实现了图像与视频的统一处理范式,可将图像视为特殊视频,借助 3D 卷积支持 20 分钟以上长视频的理解,为后续长视频相关能力拓展打下基础。特色功能原理介绍如下:
NDR
Qwen-VL采用标准的ViT要求输入的图片要统一处理成单一的、固定的分辨率,才能feed到模型进行处理,通常会导致图片失真、扭曲,导致信息损失或者对模型产生误导,如下图所示对比标准ViT和动态分辨率ViT的区别:
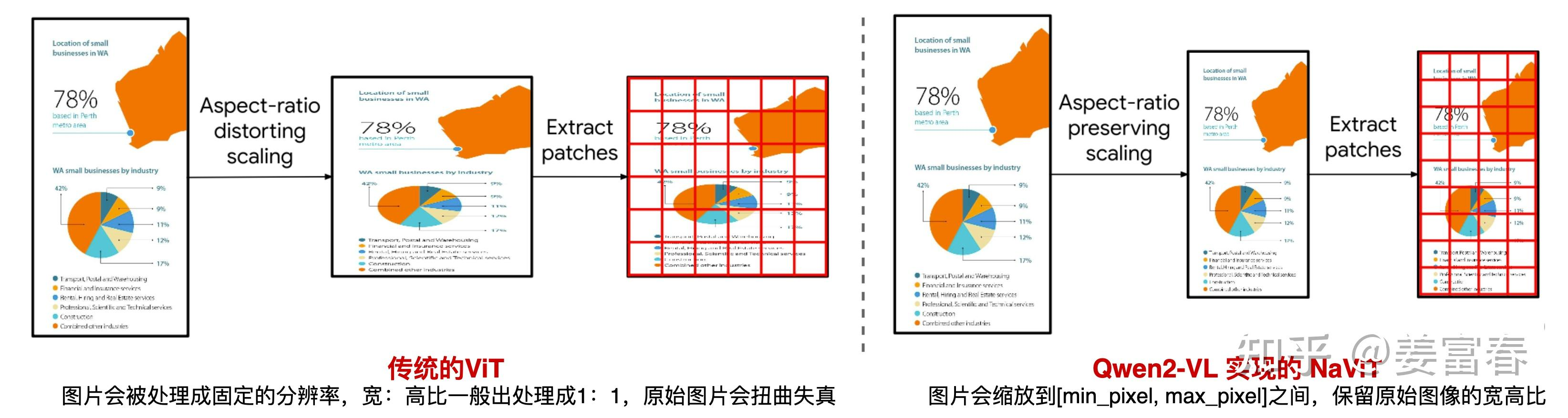
Qwen2 VL所采用的原生动态分辨率方法 则会保留原始图片的宽高比,将图片resize到适当的大小,图片像素满足min_pixel,max_pixel区间,再对图片做Patch处理,将每个图片处理成变长的Vision token序列,再输入给LLM模型。
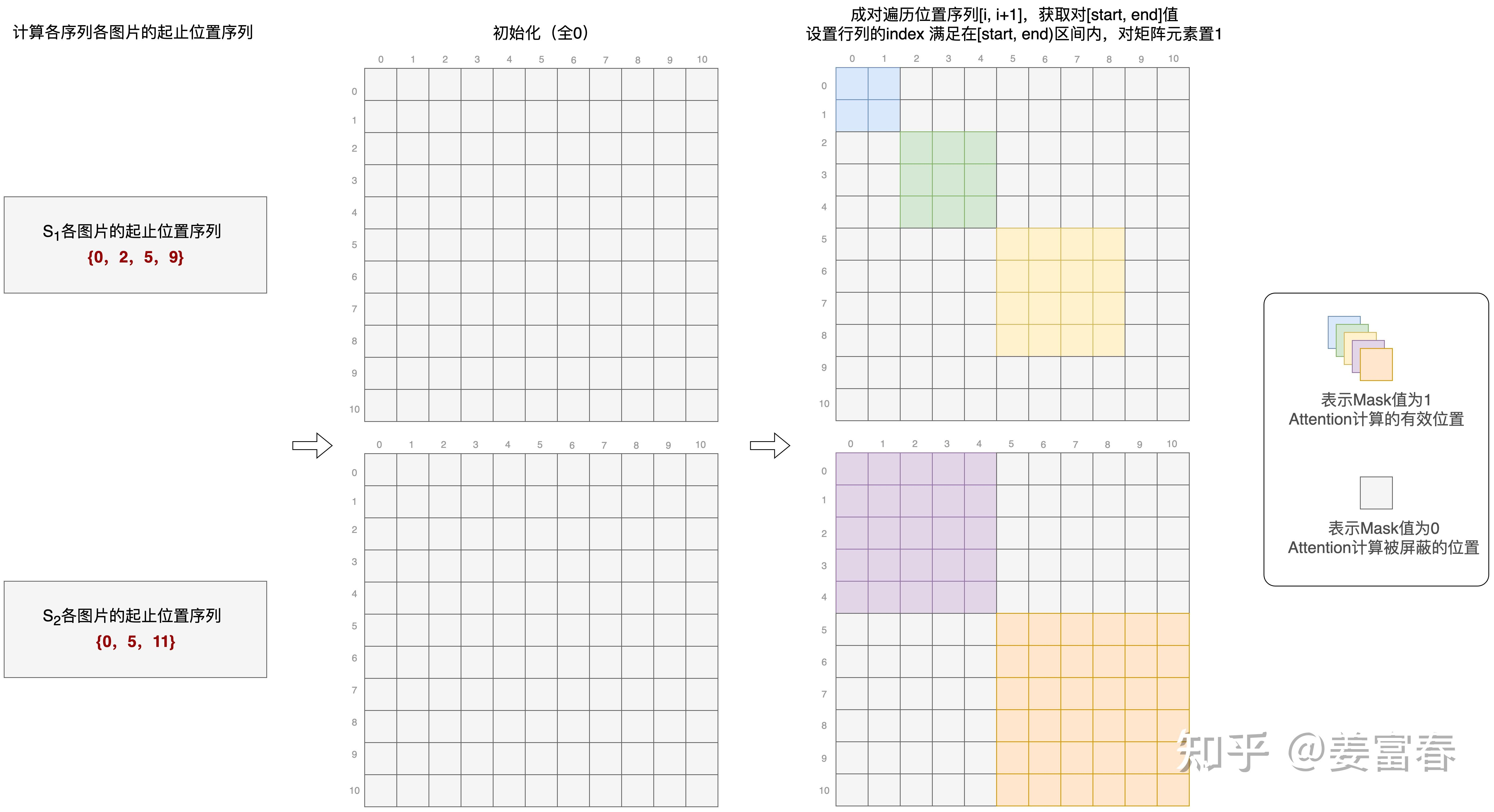
为了解决不同样本序列长度不同产生Padding导致计算浪费的问题,引入了NaViT的Patch+n'+Pack技术(Patch n' Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution),将不同图像的多个Patch打包到一个序列中,在ViT中通过变长FA的形式实现不同图片atten计算隔离:
实现序列长度压缩的Adapter
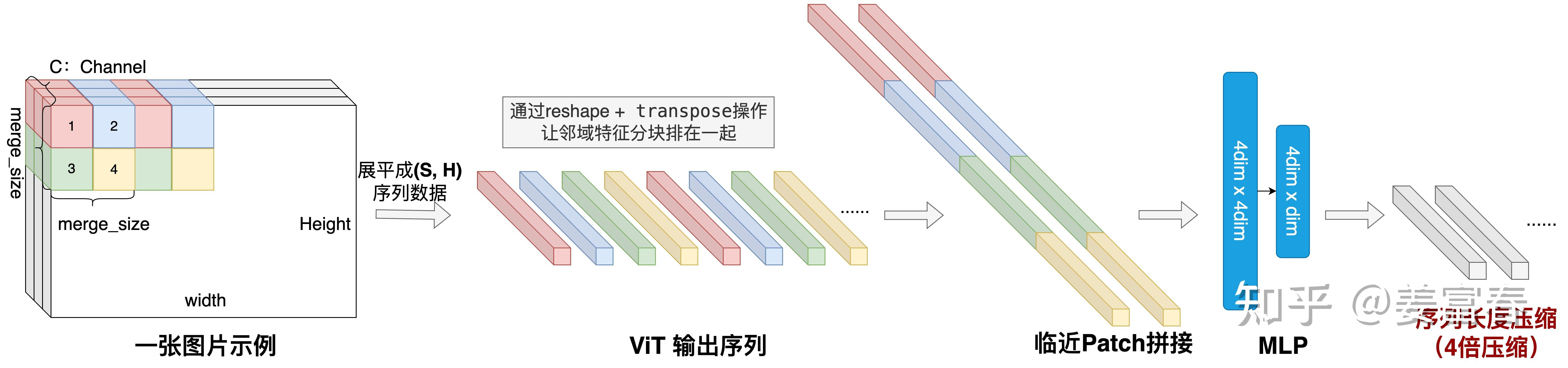
相对Qwen VL的Adapter使用Cross-Attention,Qwen2 VL采用计算更加高效的MLP,并且对空间位置临近的patch 特征做拼接,将序列长度压缩到原始的1/4,实现计算更加高效,如下图:
M - RoPE
M-ROPE(多模态旋转位置编码,由Qwen2-VL首次引入)将原始旋转嵌入分解为代表时间、高度和宽度的三个部分,使得大规模语言模型能够同时捕捉和整合一维文本序列、二维视觉图像以及三维视频的位置信息。这一创新赋予了语言模型强大的多模态处理和推理能力,能够更好地理解和建模复杂的多模态数据。

Qwen2.5 VL 提供3B、7B、32B、72B,并提供 AWQ 量化版本方便落地,首次推出QwenVL HTML 格式,能输出带边界框的 HTML 结构,适配票据、论文、网页截图等多种文档的结构化解析;支持点、框、属性的稳定 JSON 输出,可精准检测人体关键点、物体状态等信息。在视频处理方面,其能力升级到支持 1 小时以上长视频的事件捕获与片段定位;视觉 Agent 能力也实现突破,可直接完成电脑、手机的 GUI 界面操作,适配工具调用类场景。
Qwen3 VL退出Dense和MOE双架构,推出Qwen3 - VL - 235B - A22B、Qwen3 - VL - 30B - A3B 等型号,具有如下创新:
- Interleaved - MRoPE 编码,在时间、宽、高多维度优化位置编码,提升长视频时序推理能力;
- 通过DeepStack 融合多层 ViT 视觉特征,强化细粒度识别;
- 新增文本 - 时间戳对齐机制,大幅提升事件级视频定位精度。
- 上下文长度原生达 256K,最高可拓展至 1M,能轻松处理书本级长文档和小时级长视频;
如果你对多模态大模型、强化学习、昇腾 NPU 部署、模型性能优化感兴趣,欢迎持续关注【AI模力圈】。
我们会持续更新:
- 多模态模型结构拆解
- 强化学习算法原理与实践
- 昇腾 NPU 迁移部署与踩坑复盘
- 模型训练与推理性能优化