上一篇写了"服务崩溃但监控全正常"的问题。写完之后我自己又想了一下,那篇的结论是"监控停在了基础设施层,根因藏在更上面"。那实际排障的时候,监控指标看不出来,下一步几乎所有人都会做同一件事------去翻日志。
道理没错。监控指标覆盖不到的东西,日志里通常都有------报错堆栈、慢查询明细、调用链超时、配置加载失败。对大部分排障场景来说,日志确实是最后一道防线。
但我想接着说一个问题:你翻日志的时候,确定日志还在吗?
我们有一次半夜排障,业务系统在凌晨2点出了问题,值班的人2:15开始排查,打开日志平台搜那个时段的日志------空的。不是这个时间段没有日志输出,应用的stdout确实在正常打日志,但日志平台上就是查不到。
后来查下来,是那台服务器上的Filebeat在凌晨1:40因为OOM被系统kill了。从那时候开始,这台机器上的日志就没有被采集。日志一直在写磁盘,但没有人把它搬到日志平台上去。
排障的人在日志平台上看到的是"这个时段没有日志",他第一反应是"应用是不是没打日志"。验证了一下发现应用在正常打日志,那就是采集链路断了。但这个验证本身就花了十几分钟------先SSH上去看本地日志文件确认有日志,再回来查Filebeat的进程状态,发现不在了。
整个排障从2:15开始,到2:50才真正开始看到有用的日志。前面35分钟全浪费在"找日志在哪"上面。
这种事在多门店环境里不是偶发的。120家门店,每家至少跑一个采集Agent,任何一个挂了,那家门店的日志就断了。而且跟告警链路一样------采集Agent挂了不会自动告警,因为它自己就是负责采集数据的,自己挂了,谁来报?
一、先搞清楚日志从产生到你看到它,走了几步
跟上一篇写告警链路一样,在讲断裂点之前,先把日志的完整路径理一遍。
一条日志从"应用输出"到"你在日志平台上搜到它",要经过这几步:
应用输出日志(stdout / 写文件)
→ 日志写入本地磁盘(日志文件)
→ 采集Agent读取日志文件(Filebeat / Fluentd / Logstash等)
→ 日志通过网络传输到日志平台(Kafka / 直连ES等)
→ 日志平台接收、解析、索引(Elasticsearch等)
→ 运维人员在平台上搜索/查看六步。大部分人的注意力在最后一步------"搜不到就是没有"。但实际上前面五步任何一步出问题,你都搜不到。
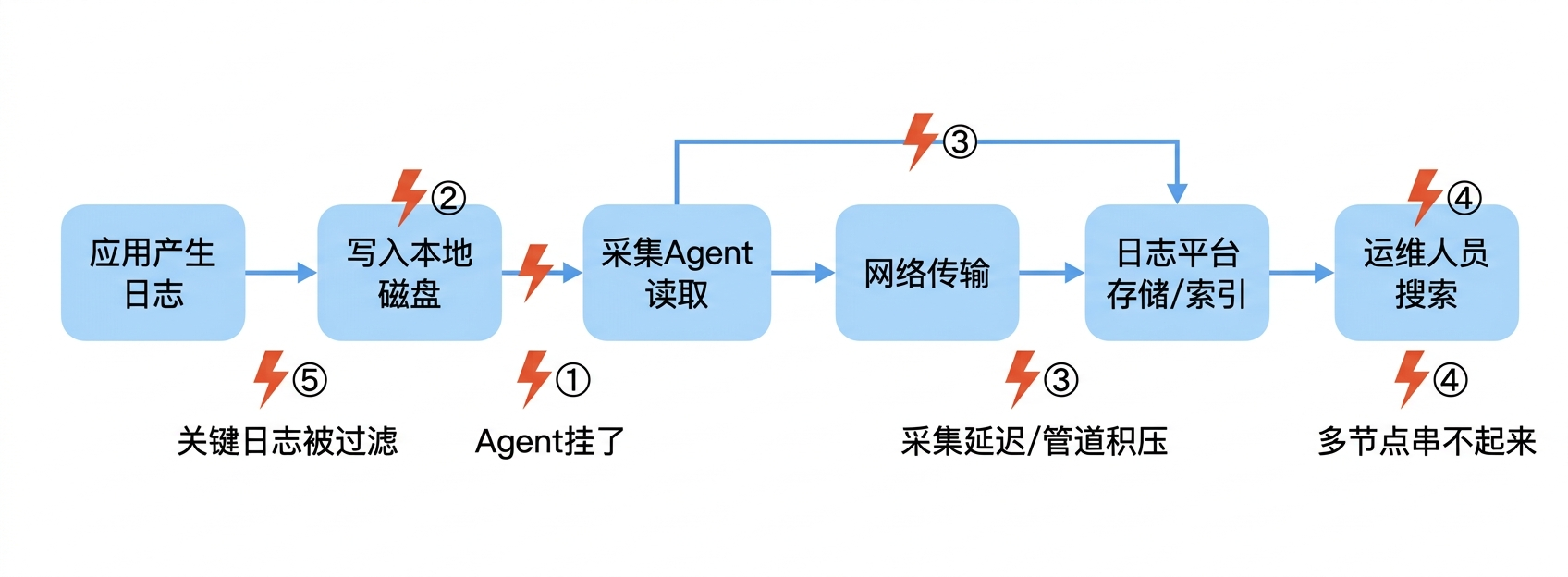
差别在于:告警链路断了,你可能到故障扩散了才发现。日志链路断了,你在排障的时候才发现------而这个时候已经是最需要日志的时候了。
下面讲5个最常断的地方。
二、断裂点1:采集Agent挂了,日志一直在写但没人搬
这是最常见的,也是开头那个案例的情况。
日志采集的逻辑是:应用把日志写到磁盘文件里,采集Agent(Filebeat、Fluentd、Logstash、或者平台自带的Agent)持续读取这些文件,把新增的内容发送到日志平台。Agent挂了,日志文件还在涨,但没有人把新增的部分搬出去。
从日志平台的视角看,这台机器的日志"停止更新了"。但平台不会主动告诉你"这台机器的日志断了"------它只知道没收到新数据,不知道是因为没有新日志还是因为采集链路断了。
常见原因
-
Agent进程被OOM kill。门店端的设备经常内存紧张,系统优先kill非核心进程。Filebeat这种后台进程优先级低,容易被干掉。尤其是日志量大的时候,Filebeat自身的内存占用也会涨上去。
-
Agent配置文件被覆盖或丢失。升级操作系统、安装补丁、或者同事手动操作的时候,把Agent的配置目录搞坏了。Agent启动了但读不到配置,等于没启动。
-
Agent到日志平台的网络中断。门店到总部的VPN或专线抖动,Agent在本地一直在跑,但数据发不出去。有些Agent会把没发出去的数据暂存在本地队列里,但队列也有上限,超了就开始丢。
-
Agent升级后没重启或者没配置开机自启。升了个版本,服务没拉起来,或者重启了机器,Agent没有自启动。
排查命令
bash
# 检查Filebeat是否在运行
ps aux | grep filebeat
systemctl status filebeat
# 查看Filebeat最近的日志,看有没有报错
tail -100 /var/log/filebeat/filebeat.log
# 检查Filebeat的registry文件,看它跟踪到哪个位置了
cat /var/lib/filebeat/registry/filebeat/log.json | python3 -m json.tool | head -50
# 检查网络连通性(假设日志平台在 log-server:5044)
telnet log-server 5044
curl -v http://log-server:9200/_cluster/health怎么防
跟告警链路的采集器心跳一样的思路:给日志采集Agent也配一层心跳监控。
Agent每隔60秒上报一个心跳指标到监控平台。连续3个周期没收到心跳,出一条"日志采集Agent离线"的告警。
这条告警不走日志链路(否则Agent挂了,这条告警也发不出去),走监控链路。也就是说,日志Agent的存活状态由监控系统来看护,不依赖日志系统自身。
不过这里有个前提,你的监控平台得能统一管理所有门店的Agent状态。如果监控和日志是两套独立系统,Agent的心跳数据在监控侧,日志采集状态在日志侧,两边对不上。我们用的运维平台是ITOM和日志采集管理在同一个系统里的,120家门店的Agent存活状态在一个界面上能看全,哪家离线了、离线多久了、最后一次上报什么时候,不用在两个系统之间跳。如果你的工具链是分散的,这步就得自己写脚本把两边的数据拉到一起,能做但比较折腾。
另外建议把Agent配成systemd托管并启用自动重启:
bash
# /etc/systemd/system/filebeat.service 中加上
[Service]
Restart=always
RestartSec=10这样Agent被kill了至少能自动拉起来,不至于断了一整夜没人知道。
三、断裂点2:日志被轮转覆盖,关键时段的日志已经不在了
这个比Agent挂了更让人抓狂,因为你连SSH上去看本地文件都看不到了。
日志文件不可能无限增长,所以几乎所有环境都配了日志轮转(logrotate)。但轮转策略配不好,排障的时候发现你需要的那段日志已经被覆盖了。
常见原因
-
logrotate配置保留的文件数太少。默认配置可能只保留3个轮转文件,每个100MB。日志量大的时候一天就能轮转好几次,凌晨出的故障,早上去查的时候那段日志可能已经被挤掉了。
-
磁盘空间不足,运维脚本把旧日志清了。门店设备磁盘本来就不大,有些团队写了定时脚本,磁盘超过80%就自动删最老的日志。故障复盘的时候需要7天前的日志,发现已经被自动清理了。
-
容器重启,日志跟着没了。如果日志写在容器内部而不是挂载到宿主机的volume,容器一重启,之前的日志全没了。Pod漂移到另一个节点也是一样------新节点上没有旧日志。
-
应用框架的日志轮转和系统的logrotate打架。Java应用用Logback自己管轮转,系统层面又配了logrotate去管同一个文件。两边都在轮转,互相干扰,偶尔会出现日志文件被截断或者部分内容丢失的情况。
排查方法
bash
# 查看logrotate配置
cat /etc/logrotate.d/myapp
# 查看当前日志文件和轮转文件
ls -lht /var/log/myapp/
# 检查磁盘使用情况
df -h
# 查看最近的logrotate执行记录
cat /var/lib/logrotate/status | grep myapp
# Docker环境下查看容器日志存储位置和大小
docker inspect --format='{{.LogPath}}' <container_id>
ls -lh $(docker inspect --format='{{.LogPath}}' <container_id>)怎么防
核心原则:本地日志是临时存储,日志平台才是持久存储。排障依赖的日志不应该只在本地磁盘上。
具体动作:
-
轮转策略按故障排查周期来定,不按磁盘空间来定。如果你的故障复盘通常需要回看7天的日志,那本地日志至少保留7天。磁盘不够就加磁盘或者压缩存储,别为了省空间把排障的底牌丢了。
-
容器日志必须挂载volume 。
docker run -v /host/log/path:/app/logs,日志写到宿主机上。容器挂了日志还在。K8s环境用hostPath或者PVC。 -
日志采集链路正常的情况下,本地日志丢了不要紧。但前提是采集链路是通的(断裂点1没出问题)。这也是为什么Agent心跳监控很重要------它是日志持久存储的前提。
-
logrotate和应用框架的轮转,只选一个管。别两个都开着。建议让应用框架管轮转(Logback/Log4j),logrotate不管这些应用日志文件。
四、断裂点3:日志在路上------采集延迟导致排障时看不到最新日志
这个断裂点不是"日志丢了",是"日志还没到"。
你在日志平台上搜最近5分钟的日志,什么都没有。但实际上应用在5分钟前确实输出了大量日志。问题是这些日志正在传输管道里排队,还没到Elasticsearch(或者其他存储后端)里。你搜的时候它还没被索引。
在日志量正常的时候可能看不出来。一旦某个时段日志量暴增------比如故障期间大量报错日志集中输出------管道就堵了。偏偏你最需要看日志的时候,恰恰就是日志量最大的时候。
常见原因
-
Kafka队列积压。如果日志链路是 Agent → Kafka → Logstash → Elasticsearch 这种架构,Kafka的消费速度跟不上生产速度的时候就会积压。正常情况下延迟几秒,积压的时候可能延迟几分钟甚至十几分钟。
-
Elasticsearch索引速度跟不上。ES的写入性能和集群规模、分片数、字段映射复杂度都有关系。日志量突增的时候,ES开始频繁GC或者merge,索引速度下降,新日志写不进去或者写进去了但还没刷新,搜不到。
-
网络带宽瓶颈。门店到总部的链路带宽有限,正常业务流量和日志传输共享带宽。故障期间业务流量可能也在涨(比如用户反复刷新),挤压了日志传输的带宽。
-
Agent本地缓冲区满了开始丢弃。Filebeat的spool_size和bulk_max_size配置限制了本地缓冲区大小。缓冲区满了之后的行为取决于配置------有的会阻塞(等缓冲区腾出空间),有的会丢弃最老的数据。
排查方法
bash
# 检查Filebeat的发送积压情况
curl -s http://localhost:5066/stats | python3 -m json.tool | grep -A5 "output"
# 如果有Kafka,检查消费者lag
kafka-consumer-groups.sh --bootstrap-server kafka:9092 --describe --group logstash-group
# 检查Elasticsearch的索引写入延迟
curl -s 'http://es-server:9200/_cat/thread_pool/write?v&h=node_name,active,queue,rejected'
# 对比日志时间戳和入库时间
# 在ES里搜最近一条日志,看 @timestamp(日志产生时间)和 _index 时间(入库时间)的差值怎么防
-
在日志平台上配一个"采集延迟"监控面板。方法:对比每条日志的产生时间(应用打的时间戳)和入库时间(ES的写入时间),算差值。差值超过5分钟就报警。
-
日志链路的容量要按峰值来估,不按均值。故障期间的日志量可能是平时的10倍以上。Kafka的partition数、ES的写入节点数、网络带宽,都要按峰值来配,至少留2倍余量。
-
排障的时候先确认延迟。如果在日志平台上搜不到最近几分钟的日志,别急着判断"没有日志"。先SSH到那台机器上看本地日志文件,确认应用有没有在打日志。如果本地有日志但平台上没有,大概率是管道延迟或者Agent问题,不是"应用没产生日志"。
这个判断顺序很重要。很多时候排障方向一开始就偏了,就是因为在日志平台上没搜到日志,就以为"应用没产生日志",然后去查应用配置、重启应用、查代码逻辑......白白浪费半小时。
五、断裂点4:日志都在,但多个节点的日志串不起来
这个问题在单体应用时代几乎不存在。一台服务器,一个日志文件,所有日志都在一个地方。
但现在的环境是这样的:一个用户请求进来,经过了网关、认证服务、业务服务A、业务服务B、数据库代理,可能分布在3台甚至5台不同的机器上。每台机器上都有日志,但你打开5个日志文件,怎么知道哪一行和哪一行是同一个请求的?
如果没有统一的TraceID把同一个请求的所有日志串起来,跨节点排障基本靠猜。或者靠时间戳大致对齐------但如果各节点的时钟不同步(NTP配置有问题),连时间对齐都做不到。
常见原因
-
没有TraceID机制。很多系统在设计的时候没有考虑分布式追踪。没有统一的请求ID贯穿所有服务,日志里找不到一个字段可以把多个节点的日志关联起来。
-
TraceID没有透传。入口服务生成了TraceID,但调用下游服务的时候没有把TraceID放到HTTP Header或者消息队列的metadata里传下去。到了下游服务,日志里的TraceID是新生成的另一个,跟上游对不上。
-
各节点时钟不同步。分布式环境里如果NTP没配好,不同节点的系统时间可能差几秒甚至几十秒。你按时间排序看日志,顺序是乱的,根本看不出因果关系。
-
日志格式不统一。A服务用JSON格式,B服务用纯文本。时间戳一个用UTC一个用本地时间。字段名一个叫trace_id一个叫requestId。就算都采集到日志平台了,也很难做关联查询。
排查方法
bash
# 检查NTP同步状态
timedatectl status
chronyc tracking
# 检查应用日志里是否包含TraceID字段
head -20 /var/log/myapp/app.log | grep -i "trace"
# 在日志平台上按TraceID搜索,看能搜出几个服务的日志
# 如果只搜出1个服务的,说明TraceID没有透传到下游怎么防
-
TraceID是分布式日志的基础设施,不是可选项 。如果你的系统是微服务或者多服务架构,TraceID必须作为基础能力来做。技术上不复杂------入口服务生成一个UUID,放到HTTP Header里(通常用
X-Request-ID或X-Trace-ID),每个下游服务从Header里取出来写到自己的日志里,再透传给自己的下游。 -
统一日志格式 。所有服务用统一的JSON结构输出日志,至少包含这几个字段:
timestamp(ISO8601格式,统一时区)、trace_id、service_name、level、message。格式统一了,日志平台上才能做跨服务关联查询。 -
NTP必须配且必须验证。每台机器都要配NTP,而且要定期验证同步状态。时钟偏差超过1秒就应该告警。这个看起来是小事,但一旦出问题,所有基于时间顺序的排障都会被搞乱。
-
如果一步到位做不了,至少先做到核心链路。不需要所有服务一次性全改。先把最核心的业务链路(比如订单流程、收银流程)的几个服务加上TraceID透传。这几个服务出问题的概率最高,排障频率也最高,投入产出比最好。
六、断裂点5:日志级别配太高,关键信息被过滤掉了
这个断裂点跟前面4个不一样------不是链路断了,是日志本身就没被写出来。
应用日志通常分级:TRACE → DEBUG → INFO → WARN → ERROR。生产环境的日志级别一般配成INFO或者WARN,低于这个级别的日志不输出。
问题是有些对排障很关键的信息,被开发写在了DEBUG甚至TRACE级别里。比如数据库连接池的状态变化、HTTP请求的详细参数、第三方接口调用的完整请求和响应。这些信息在正常运行时确实没必要输出,但出了故障需要定位根因的时候,这些才是最有价值的。
日志级别配成了WARN,你在日志平台上只能看到WARN和ERROR------知道"出错了",但不知道"出错之前发生了什么"。
常见原因
-
生产环境一刀切配成WARN。为了减少日志量和磁盘开销,统一把日志级别调到WARN。结果INFO级别里很多有用的上下文信息全没了。
-
日志采集的过滤规则太激进。有些团队在采集侧配了过滤规则,只采集WARN和ERROR级别的日志。本地磁盘上INFO日志是有的,但没采集到日志平台上。
-
关键信息被开发写在了不合适的级别。数据库连接池借出/归还这种信息,有的框架默认是DEBUG级别。正常运行时看不到,需要的时候也看不到。
-
动态调级能力缺失。出了故障想临时把日志级别调到DEBUG,但应用不支持运行时动态调整,得改配置文件然后重启。重启之后故障现场就变了。
排查方法
bash
# 检查应用当前的日志级别配置
# Spring Boot应用
curl http://localhost:8080/actuator/loggers | python3 -m json.tool | head -30
# 检查logback/log4j配置文件
cat /app/config/logback-spring.xml | grep -i "level"
# 检查采集Agent的过滤规则
cat /etc/filebeat/filebeat.yml | grep -A10 "processors"怎么防
-
生产环境默认INFO,不要默认WARN。INFO级别的日志量确实比WARN大,但这些日志是排障的上下文。如果担心日志量太大,用采集侧的过滤来控制------平台上只索引WARN和ERROR,但本地磁盘保留INFO,需要的时候可以SSH上去看。
-
支持运行时动态调级。Spring Boot的Actuator、Log4j2的JMX、或者自己写一个配置中心的监听。出了故障可以不重启应用就把某个包的日志级别临时调到DEBUG。排完之后再调回去。
-
对排障关键的信息,至少写在INFO级别。跟开发团队约定:连接池状态变化、外部接口调用结果(成功/失败/耗时)、关键业务事件(订单创建/支付完成),这些必须是INFO级别。DEBUG留给真正只有开发调试时才需要的内容。
-
采集规则和应用日志级别要协调。别出现"应用输出了INFO日志,但采集Agent把INFO过滤掉了"这种情况。采集侧的过滤策略要跟运维和开发团队对齐。
七、一份日志采集健康检查清单
把5个断裂点整理成一份检查清单。我们现在每周跑一次,配合告警链路的月度巡检一起做。
| 检查项 | 检查方法 | 预期结果 | 检查频率 |
|---|---|---|---|
| Agent存活状态 | 心跳监控 + 进程检查 | 所有Agent在线,无超过2个采集周期未上报的 | 实时监控 |
| 日志文件轮转策略 | 检查logrotate配置和磁盘空间 | 关键日志本地保留≥7天 | 每月 |
| 采集延迟 | 对比日志产生时间和入库时间 | 正常延迟<5分钟,峰值<15分钟 | 每日 |
| TraceID覆盖率 | 抽样检查核心链路日志的TraceID字段 | 核心服务日志100%包含TraceID | 每周 |
| 日志级别配置 | 核查生产环境各服务的日志级别设置 | 生产环境默认≥INFO级别 | 每次发版后 |
| 采集Agent版本一致性 | 统计所有门店的Agent版本 | 版本偏差不超过1个小版本 | 每月 |
| 日志格式统一性 | 抽样检查不同服务的日志格式 | 时间戳格式、字段名、时区统一 | 每季度 |
最后一项"日志格式统一性"看起来不紧急,但长期来看它决定了你在日志平台上能不能做跨服务的关联查询。格式不统一,数据都在但用不起来。
八、我的排查顺序:日志搜不到的时候先查什么
最后说一下实际排障时的判断顺序。当你在日志平台上搜不到预期的日志时,不要急着下结论"应用没打日志"。
我的排查顺序是:
第一步:SSH到机器上看本地日志文件。
确认应用有没有在正常输出日志。如果本地文件有日志但平台没有,问题在采集链路,不在应用。
第二步:查采集Agent是否存活。
ps aux | grep filebeat,看进程在不在。不在就是断裂点1。
第三步:确认不是延迟问题。
看本地日志文件的最新写入时间和日志平台上最新一条日志的时间差。如果差几分钟,可能是管道延迟(断裂点3),等一会儿可能就有了。
第四步:确认日志有没有被轮转覆盖。
如果你要找的是几小时前甚至几天前的日志,先看本地有没有轮转文件。ls一下日志目录,看文件的时间范围。
第五步:检查日志级别。
如果你搜的是ERROR日志能搜到,但搜INFO搜不到------那大概率是日志级别或者采集过滤的问题。
这个顺序不是唯一正确的,但它能帮你在5分钟之内判断出"日志断在哪个环节",而不是花半小时在各种可能性之间来回猜。
九、日志链路和告警链路,本质是同一类问题
写完这篇回头看,日志链路和告警链路(上一篇的内容)其实是同一类问题:你以为这条链路是通的,因为它大部分时候看起来在正常工作。但它"局部断裂"的时候不会告诉你,只是安静地丢掉了一部分数据。
告警链路断了,你不知道某个故障发生了。日志链路断了,你知道故障发生了,但找不到排查它需要的信息。两条链路的维护思路也一样:不能"配好了就不管了",需要持续监控、定期检查。
如果你也在做多门店运维,建议把日志采集的健康检查跟告警链路的巡检放在一起做。这两条链路一条断了,另一条的价值就打了折扣------告警告诉你出了事,日志告诉你为什么出了事。两条都通,排障才能真正闭环。
不过"放在一起做"说起来简单,我们一开始也是分开巡检的,两边各出各的报告。后来发现经常对不上,告警那边说"这家门店采集器在线",日志这边说"这家门店日志Agent离线"。查了一圈才发现,两套系统里的设备标识不一致,同一台设备在监控系统里叫一个名字,在日志系统里叫另一个名字。后来切到一体化的运维平台之后这个问题就没了,监控Agent和日志采集Agent的状态在同一个资产视图下管理,设备ID是统一的,巡检报告出来就是一张表,这台设备的监控在不在、日志在不在、工单有没有未关闭的,一眼能看全。用过之后才体会到,很多时候卡你的不是功能够不够,是数据对不对得上。