目录
[如何理解 TCP 通信是全双工?](#如何理解 TCP 通信是全双工?)
[1. 第一层:](#1. 第一层:)
[2. 第二层:](#2. 第二层:)
[3. 第三层:](#3. 第三层:)
[4. 第四层:](#4. 第四层:)
[5. 第五层:](#5. 第五层:)
[6. 第六层:](#6. 第六层:)
[JsonCpp 库](#JsonCpp 库)
[JsonCpp 库的使用](#JsonCpp 库的使用)
[运行结果 :](#运行结果 :)
[运行结果 :](#运行结果 :)
一、TCP的通信是全双工的
很多同学在学习 Linux 网络时,总会被几个问题绕晕:传输层到底在哪实现?TCP 是协议还是代码?网络层和传输层的关系是什么?缓冲区到底属于哪一层?
今天我们就来解答这几个问题:
相关问题
问题 1:传输层是在内核中实现的吗?
是的,传输层(TCP/UDP)是 Linux 内核网络栈的核心组成部分,由操作系统内核实现,应用层代码不参与协议本身的处理,应用层的程序(C/C++/Python/Java 等),只能通过socket()、send()、recv() 等系统调用,向内核的传输层模块发起请求。
网络层也一样,和传输层同属内核网络栈。网络层的核心协议是 IP 协议,完整实现也是在 Linux 内核中。
TCP/UDP 都是只在传输层中起作用,因为 TCP/UDP 是传输控制协议,它们的核心工作都在传输层内,不会跨层越界。
问题 2:TCP 具体是个协议吗?这个协议实现在内核里吗?
TCP 是国际标准协议规范,是由 IETF 定义的标准化网络通信协议,任何操作系统(Linux、Windows、macOS)要实现 TCP,都必须遵守这个规范,才能保证不同系统的 TCP 可以互通。
TCP 协议的代码实现,是在 Linux 内核中实现的,Linux 内核用 C 语言完整实现了 TCP 协议的所有规范。
当我们在应用层调用connect()、send()时,本质流程是:应用层发请求 → 内核的 TCP 传输层代码执行协议逻辑 → 把数据交给 IP 网络层 → 网卡发往网络。
如何理解 TCP 通信是全双工?
- 全双工即允许同一时间对一个 TCP 连接同时进行读和写操作:同一时间,一个线程 / 进程可以通过 sockfd 从内核的接收缓冲区读取数据,同时另一个线程 / 进程也可以通过同一个 sockfd 向内核的发送缓冲区写入数据,两种操作互不阻塞、互不影响。
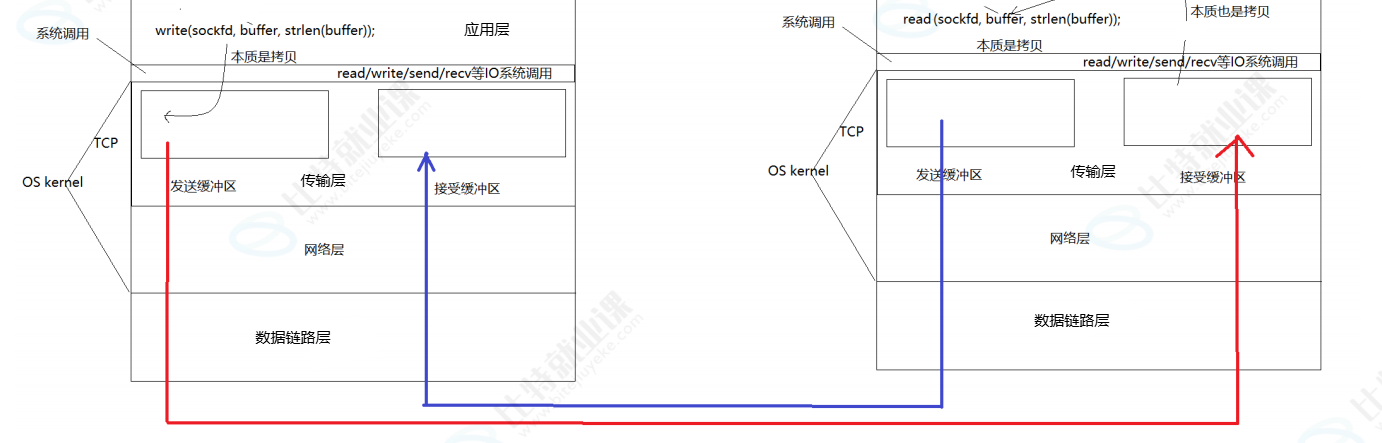
-
TCP 内核对象中会同时维护两个完全独立的缓冲区:一个发送缓冲区、一个接收缓冲区。写操作 (write) 只会操作发送缓冲区,读操作 (read) 只会操作接收缓冲区,二者的内存空间、内核处理逻辑完全隔离,因此同一时间对发送缓冲区的写入和对接收缓冲区的读取互不干扰,这就是 TCP 通信全双工的底层支撑。
-
写操作(write)时,用户通过 write 系统调用,借助 sockfd 将用户态缓冲区的数据拷贝到内核的发送缓冲区中,后续由 TCP 协议栈异步完成发送。
-
读操作(read)时,用户通过 read 系统调用,借助 sockfd 将内核接收缓冲区中已收到的数据拷贝到用户态缓冲区中,完成数据的读取。
在内核中查找缓冲区
那这两个缓冲区具体在哪,我们在 Linux 内核源码中一探究竟:
1. 第一层:
我们都知道,在每个进程PCB的 task_struct 中都有一个指向 struct files_struct* 的指针 files, 是一个指向当前进程的文件资源管理器的指针。
2. 第二层:
每个 files 指针指向的 struct task_struct 结构体里,有一个 struct file *类型的数组,上图红色方框圈出来了,这个数组就是我们常说的文件描述符表,数组下标就是文件描述符 fd,每个数组元素类型是 struct file 类型,struct file 是专门用来表示一个已打开文件实例的结构体类型。每调用一次 open()、socket()、pipe() 这类打开资源的函数时,内核就会在内核内存中创建一个全新的、独立的 struct file 结构体对象,然后在当前进程的文件描述符表 fd_array 中,找到一个空闲的数组下标fd,让这个下标对应的指针,指向刚创建的 struct file。
3. 第三层:
在 struct file 结构体内部,有一个 void *private_data 私有数据指针。我们在使用 socket() 创建网络套接字时,本质就是内核创建 Socket 网络文件,对于 Socket 文件来说,这个指针会进一步指向底层的 struct socket 套接字对象。
4. 第四层:
我们调用 socket() 创建网络套接字时,内核也会创建一个 struct socket 结构体,在 struct socket结构体中,有两个最核心的指针,一个是 struct file *file 回指指针,指向上面的 struct file 结构体。
另一个指针就是 struct sock *sk,这个 sk 指向 TCP/UDP 传输层内核对象 struct sock(TCP 场景下实际为 struct tcp_sock)。
5. 第五层:
struct sock 结构体是 Linux 内核中 TCP/UDP 传输层协议的真正本体,是整个 Socket 通信链路的核心数据载体。整个 struct sock 结构体的成员非常多,这里我们只截了最核心的两个成员,就是 TCP 收发缓冲区:
- sk_receive_queue:TCP 接收缓冲区
- sk_write_queue:TCP 发送缓冲区
sk_receive_queue 和 sk_write_queue 的类型是结构体 struct sk_buff_head。这个结构体是 Linux 内核中专门用于管理网络数据包的双向链表头结构体,它本身不存储任何业务数据,仅作为链表的入口;而我们说的 TCP 接收缓冲区、发送缓冲区,底层本质是一个双向链表,只是逻辑上按照先进先出的队列规则来操作。
6. 第六层:
在 struct sk_buff_head 结构体中,最核心的就是红框标注的两个指针:
- struct sk_buff *next:正向指针,用于指向链表中的下一个数据包节点;
- struct sk_buff *prev:反向指针,用于指向链表中的上一个数据包节点;
依靠这一对指针,内核就能将一个个存储真实网络数据的 struct sk_buff 数据包结构体,串联成一条完整的双向链表。struct sk_buff_head 是链表头,而每一个 struct sk_buff 是链表节点,节点内部也包含相同的 next 和 prev 指针,用于完成双向串联。
至此我们就找到了两个缓冲区的位置。
所以在调用 socket() 时,内核会同时创建一个 struct file 类型的 Socket 网络文件;创建 struct socket 套接字结构体;创建 struct sock 传输层内核对象,同时创建收发缓冲区;然后通过指针把它们层层绑定起来(file → socket → sock);全部创建、绑定完毕后,最后才分配 fd,把 fd 作为 socket() 的返回值返回给用户进程。需要注意的是 struct socket、struct sock 不是 "在文件里面创建的",它们是独立创建,只是用指针链挂到了 struct file 上。
read、write阻塞的本质
TCP 通信中,应用层的 write、read 阻塞本质上就是典型的生产者 - 消费者模型:对于 write 发送数据来说,应用进程是生产者,TCP 内核协议栈是消费者,应用进程通过 write 将用户态数据拷贝到内核发送缓冲区(生产行为),TCP 内核协议栈则负责将缓冲区中的数据封装协议头并发送到网络(消费行为),当应用进程生产速度过快、TCP 消费速度过慢,导致内核发送缓冲区被填满时,生产者(应用进程)就无法继续往缓冲区写入数据,此时 write 就会阻塞;而对于 read 接收数据来说,TCP 内核协议栈是生产者,应用进程是消费者,TCP 协议栈将网络中收到的数据存入内核接收缓冲区(生产行为),应用进程通过 read 从接收缓冲区拷贝数据到用户态(消费行为),当 TCP 生产速度慢、应用进程消费速度快,导致内核接收缓冲区为空时,消费者(应用进程)就无法读取到数据,此时 read 就会阻塞,这就是write、read 因内核缓冲区满或空而发生阻塞的底层本质。
最终本质
在 TCP 通信过程中,应用层调用 write、read 函数时会触发系统调用,函数参数中的文件描述符 fd 作为索引,会先在当前进程 PCB 的文件描述符表中找到对应的 struct file 网络文件对象,再通过 struct file 的私有数据指针找到 struct socket 套接字中间层结构体,接着通过 struct socket 的 sk 指针定位到 struct sock 传输层内核对象,最终将应用层缓冲区的数据拷贝至 struct sock 内部的 TCP 发送缓冲区,或是将 struct sock 接收缓冲区中的数据拷贝回应用层;数据进入内核缓冲区后,内核传输层会为其封装 TCP 协议头部,再交由网络层封装 IP 头部完成路由寻址,随后下传到数据链路层封装以太网帧头部,最后由网卡将数据发送至网络中;接收数据时则是反向流程,网络数据经网卡逐层解包后存入 TCP 接收缓冲区,等待应用层通过 read 系统调用读取。
二、应用层自定义协议
为什么要在应用层自定义协议?
-
我们知道,TCP 是面向字节流的通信方式,没有天然的消息边界。应用层调用 write 发送数据时, 是把数据拷贝到内核的发送缓冲区里,但是数据什么时候发、一次发多少、网络好不好、会不会延迟、等问题都是由底层 TCP 协议栈和网络状态决定,我们应用层控制不了。正因为这样,实际通信中很容易出现数据粘在一起、拆分不完整、一次多读、一次少读等问题,接收端根本分不清哪一段是一条完整业务消息。
-
我们可以用一个最简单的场景直观理解:假设发送方需要向接收方传输一条完整的业务指令 " ls -a -l ",在没有自定义协议约束的 TCP 通信中,由于 TCP 面向字节流的特性,数据会以连续字节的形式在内核缓冲区中传输,底层 TCP 协议栈可能会因为网络波动、缓冲区大小限制等原因,将这条完整指令拆分发送。极端情况下,接收方第一次调用 read 时,可能只会读到不完整的片段 "ls",后续才能读到剩下的 -a -l;接收端无法判断一条完整指令的边界,会直接将读到的 ls 当作完整指令解析,最终导致业务逻辑执行错乱。
-
所以,光靠 TCP 底层保证可靠传输还不够,我们自己必须在应用层提前说好统一的格式、规则,规定每条消息发多大、怎么开头、怎么收尾、怎么拆分、怎么解析,这套双方提前约定好的发送规则和数据格式,就是我们自己设计的用户自定义应用层协议,用来从根本上解决 TCP 字节流无边界带来的解析混乱问题。
应用层自定义协议的本质
-
用户自定义协议的核心本质,是由通信双方开发者自主设计、自主约定、自主实现的。从消息的整体结构、字段划分、边界标记,到每条数据的发送格式、解析逻辑,全部由我们自己定义与把控,操作系统内核只负责帮我们传输字节流,不会干预、也不会知晓我们业务数据的具体含义与格式。
-
我们之前编写 TCP、UDP 基础通信代码时是没有在应用层自定义协议的。因为对于 UDP 而言,其本身是面向报文的协议,具备天然的消息边界,一次发送对应一次接收,无需额外约定格式即可精准拆分消息;而在 TCP 的代码编写中,收发数据量小、传输频率低、网络状态稳定,write 写入的数据能被内核一次性完整发送,read 读取的数据也恰好是单次完整消息,只是偶然规避了 TCP 字节流无边界带来的粘包、拆包问题,并非底层 TCP 能帮我们完成消息解析。一旦脱离简单测试场景,进入复杂业务通信,TCP 字节流的特性就会暴露,此时自定义协议就成为了保障数据正确解析的必要条件。
-
后面在实际的网络项目开发中,只要是基于 TCP 做业务通信,都需要我们自己设计并实现自定义应用层协议。我们前面写的简单 TCP 通信代码,只是为了演示通信原理,收发的数据短、逻辑简单;但在真实项目中,传输的数据量大、收发频率高、网络环境复杂,TCP 字节流的无边界特性必然会导致数据拆分、粘包、解析错乱的问题,就像我们刚才举的指令拆分例子一样。操作系统和 TCP 协议栈只会帮我们保证数据可靠到达,不会帮我们区分哪一段是一条完整的业务消息,所以我们必须自己定义消息格式、约定解析规则,也就是自定义协议,才能保证项目中两端数据解析的准确性与稳定性。
粘包和拆包问题
- TCP 是面向字节流的协议,内核的发送缓冲区和接收缓冲区是连续的字节队列,所以在 TCP 协议栈眼里是没有 "一条一条消息" 的概念。
所谓粘包,就是发送方连续发两条消息,TCP 可能会把它们合并成一块发给接收方;
所谓拆包,就是一条完整消息太长,TCP 会把它拆成好几段分开发送。
-
就拿我们刚才举的例子,发送方连续发送两条指令:ls -a -l 和 pwd。
-
粘包场景就是 TCP 合并发送,接收方一次读到 ls -a -lpwd,两条指令粘在一起,接收端根本不知道哪里是第一条的结尾、哪里是第二条的开头,解析直接报错;
-
拆包场景就是 TCP 拆分发送,接收方第一次只读到 ls,第二次读到 -a -lpwd,接收端把半截指令当成完整指令处理,直接业务崩溃。
-
而我们自定义协议的核心目的,就是给每一条业务消息打上明确的边界标记(比如约定 "前 4 字节是整条消息的长度")。接收端拿到数据后,先读长度,再严格按长度截取完整消息,不管 TCP 底层是粘包还是拆包,应用层都能精准拆分出独立、完整的业务消息。
解决方法:
那怎么解决粘包和拆包问题呢? 有三种方法:
第一种是固定长度法,即约定每条消息占用固定字节数,接收端每次严格读取固定长度字节作为一条完整消息,优点是实现简单,缺点是存在空间浪费;
第二种是特殊结束符法,约定一个唯一不与业务数据冲突的字符作为消息结尾,接收端循环读取直到识别到结束符为止,优点是灵活无浪费,缺点是需要保证业务数据中不会出现结束符;
第三种也是工业级项目必用的长度头协议法(自定义协议核心),约定消息前固定 N 个字节存储整条消息的总长度,接收端先读取长度头,再根据长度精准读取后续完整消息体,该方法兼顾灵活、精准、无浪费三大优点,是解决粘包最通用、最稳定的方案。
三、序列化和反序列化
什么是序列化和反序列化
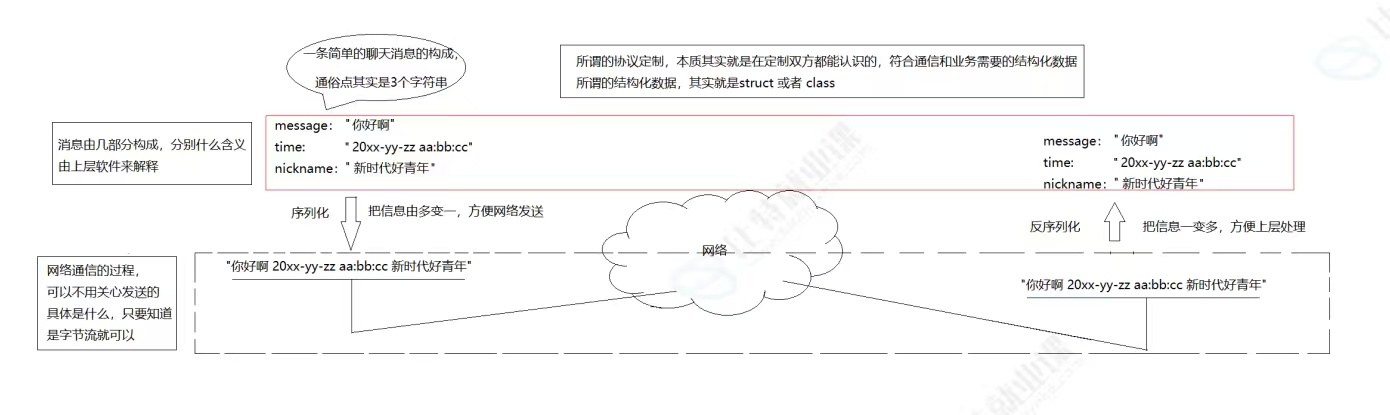 当我们通过自定义协议,成功解决了 TCP 粘包问题、保证了单条消息的边界完整性后,又会遇到下一个实际开发中的核心痛点:我们在业务中要传输的数据内容,从来都不是单纯的字符串,而是像用户名、年龄、操作指令、状态码这类不同类型、结构复杂的结构化数据。比如要传输一条包含用户身份和操作的指令,里面既有整数类型的 ID、字符串类型的用户名,还有操作指令字符串,这些零散、多类型的数据,它们在代码里通常以结构体、类的形式存在。
当我们通过自定义协议,成功解决了 TCP 粘包问题、保证了单条消息的边界完整性后,又会遇到下一个实际开发中的核心痛点:我们在业务中要传输的数据内容,从来都不是单纯的字符串,而是像用户名、年龄、操作指令、状态码这类不同类型、结构复杂的结构化数据。比如要传输一条包含用户身份和操作的指令,里面既有整数类型的 ID、字符串类型的用户名,还有操作指令字符串,这些零散、多类型的数据,它们在代码里通常以结构体、类的形式存在。
这种分散且多类型的结构化数据,本身是无法直接放进我们约定好的应用层自定义协议的格式中、也无法适配网络传输 ------ 网络只认连续的二进制字节流,不识别结构体、成员变量这些上层业务概念。
想要让这些结构化数据适配网络传输,就必须把它们统一转换成一段连续、规整的二进制字节流;而接收端拿到二进制流后,又需要把它精准还原回原来的结构化数据,方便上层业务处理。这个结构化数据与二进制流之间的相互转换的过程,就是我们接下来要重点讲解的序列化与反序列化。
序列化,本质就是把这种由多个零散成员组成的结构化数据,统一整合、转换为一段连续、规整的二进制字节流,也就是图里说的 "由多变一",让原本复杂的结构体,变成一段可以直接塞进协议、通过网络发送的数据流;接收端收到这段二进制流后,再通过反序列化,将单一的字节流精准还原为原本的结构体,也就是图里的 "由一变多",恢复成上层业务可以直接读取、处理的结构化数据。
如何实现序列化和反序列化?
一种方法是我们可以手动实现序列化与反序列化,另一种方法是直接使用成熟开源的序列化库。而在实际项目开发中,我们强烈推荐并且几乎都使用现成的成熟序列化库,绝不建议自己手写实现。
当然手动实现序列化能让我们学习和理解整个过程,比如说如何把结构体里的 int、字符串按字节拼接成二进制流,再手动解析拆分,这个过程能帮我们吃透 "多变一、一变多" 的核心逻辑;但在真实的线上项目中,自己手写序列化有三大致命缺陷:第一,兼容性极差,不同语言、不同平台之间无法互通;第二,容错率极低,稍微处理不好大小端、字节对齐、数据边界,就会出现解析崩溃、数据错乱;第三,开发效率极低,复杂结构体的序列化要写大量重复、冗余的代码,且很难保证稳定性。因此我们不建议自己手写实现。
而市面上已经有大量经过工业级验证、跨语言、高性能的成熟序列化库,比如我们 C++ 开发中最常用的 Protobuf(谷歌出品)、JSON、FlatBuffers,这些库帮我们封装好了所有底层细节:大小端转换、字节对齐、边界校验、跨语言兼容,我们只需要定义好结构体,一行代码就能完成序列化和反序列化,既稳定、安全,又能极大提升开发效率,是企业级项目开发的标准选择。
JsonCpp 库
而我们今天就介绍一个市面上成熟的序列化库,这个库叫 JsonCpp 库,这个库是 C++ 生态里最经典、最常用的 JSON 序列化 / 反序列化开源库,专门用来处理 JSON 格式数据。这个库是一个 C++ 库,基于 C++ 语法和标准库开发,适配所有 C++ 的编译器,是 C++ 后端、网络开发的标配。
它专门解决两件事:
- 序列化:把 C++ 里的结构体、对象、零散数据,转换成 JSON 格式字符串(本质就是连续字节流,适配网络发送);
- 反序列化:把网络收到的 JSON 字符串,解析还原成 C++ 可直接操作的变量、对象。
因为这个库属于成熟第三方开源库,需要我们自己编译源码或安装依赖才能使用,并不是 C++ 标准库自带的。
在我当前 Ubuntu 版本下是没有安装这个库的,现在我们安装。
这是安装命令。
安装好之后查头文件已经存在。

JsonCpp 库的使用
序列化
序列化(结构体对象 → 字符串):推荐用 Json::FastWriter(网络传输必用)
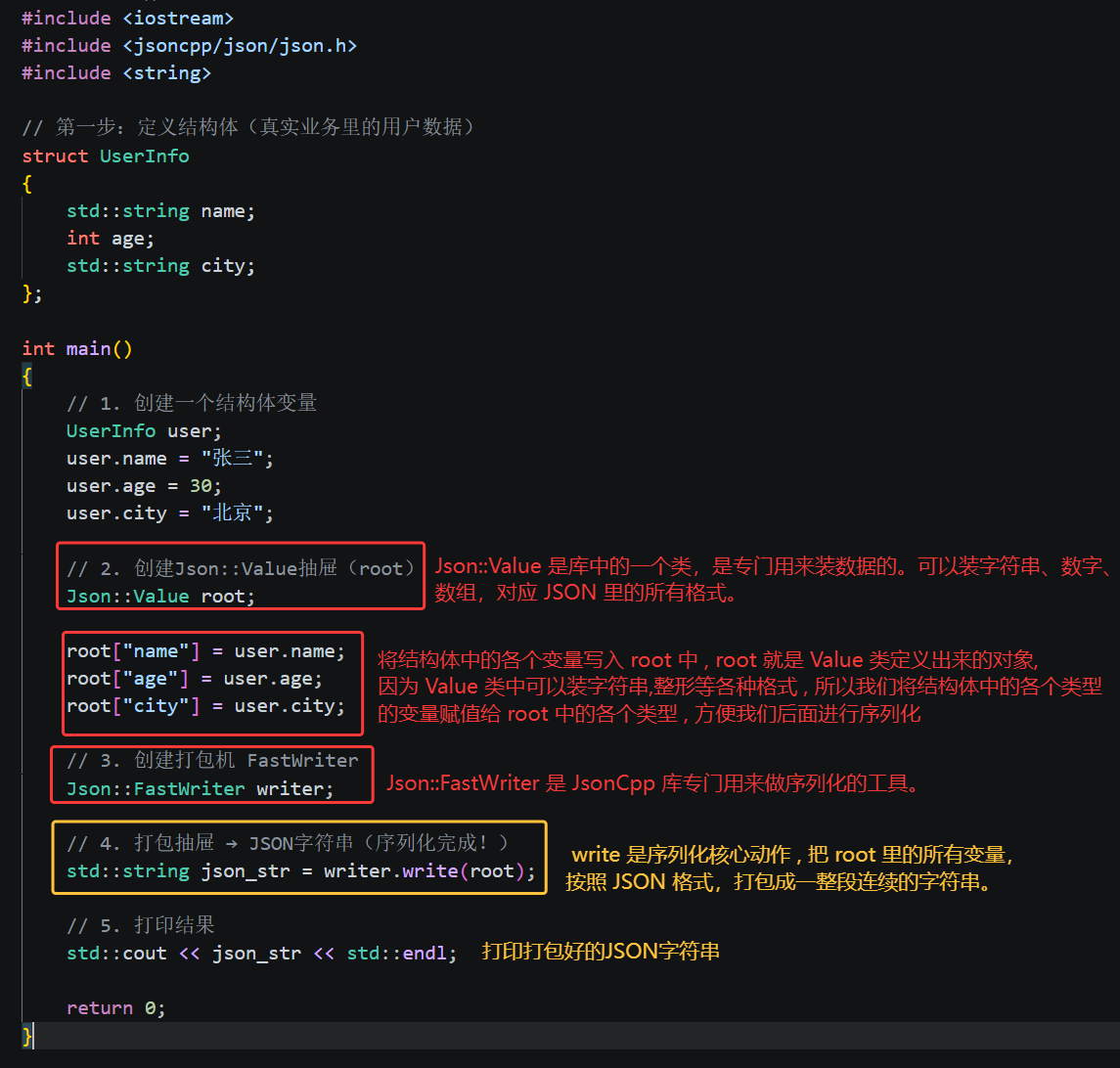
Json::Value 是库专门用来装数据的类。它是 JsonCpp 库自带的一个 "万能容器",它能接收 C++ 里所有常用类型(int、string、bool、数组、嵌套结构体);但是 JsonCpp 库只认 Json::Value 这一种格式,不认我们自己定义的 struct、class;所以在进行序列化之前必须先把我们的结构体转换到 Json::Value 定义的对象中,再转换为 JSON 字符串。相当于一个"中转站"。
Json::FastWriter 也是库中的一个类,是专门用来做序列化的工具类。为什么叫 Fast?是因为它打包出来的字符串没有多余空格、换行,体积最小、速度最快,网络传输首选。而 write(root) 函数就是这个类中专门进行序列换转换的函数,将结构体类型转换为 JSON 字符串类型。
运行结果 :
根据运行结果,已经说明序列化成功完成了!将我们原本的 UserInfo 结构体序列化为字符串格式了,但是可能由于中文 Unicode 转义编码的问题,这里没有将汉字打印出来,我们先不管。

反序列化
下面我们将上面已经序列化后的JSON字符串再反序列化回来:
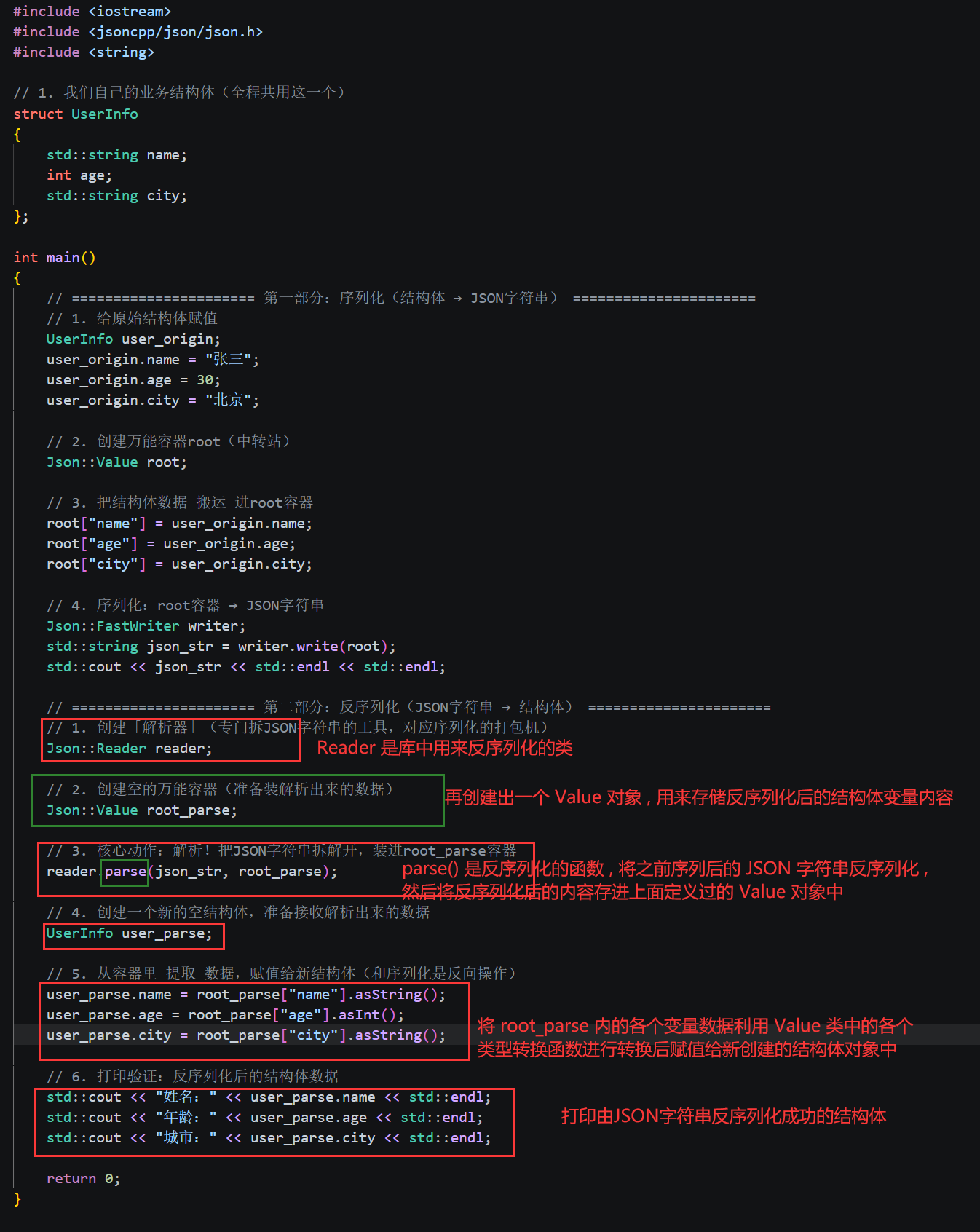 Json::Reader 是 JsonCpp 库专门用来做反序列化的工具类,类中有一个函数 parse() 专门用来反序列化解析 JSON 字符串。
Json::Reader 是 JsonCpp 库专门用来做反序列化的工具类,类中有一个函数 parse() 专门用来反序列化解析 JSON 字符串。
解析完之后我们还必须先将转换后的内容存入 Vlaue 类定义出来的一个变量 root_parse 中,因为 Value 类还是库唯一认识的中转站,必须先装这里。
parse(json_str, root_parse) 把 JSON 字符串 json_str 拆开,把里面的 name、age、city,挨个装进 root_parse 容器里。parse() 是反序列化的核心动作,和序列化的writer.write(root)完全反向。
Json::Value 里存的数据,本质上是 "JSON 类型"(比如 JSON 字符串、JSON 数字),不是直接的 C++ std::string、int 类型。因此我们还得使用 Value 类中提供的 asString() 和 asInt() 函数将它们转换为 C++ 中的各个类型。最后存入我们业务层的结构体中打印出来。
运行结果 :
反序列化后将之前序列化的JSON字符串成功的转换了回来,运行结果正确。
四、总结
本文深入解析了TCP通信的核心机制与应用层协议设计。首先阐述了TCP全双工通信原理,指出内核通过独立的发送/接收缓冲区实现读写并行。接着揭示了TCP字节流特性导致的粘包/拆包问题,提出三种解决方案:固定长度法、特殊结束符法和长度头协议法(最优)。然后重点讲解了序列化/反序列化技术,将结构化数据转换为二进制流以适应网络传输,推荐使用JsonCpp等成熟库而非手动实现。最后通过实例演示了JsonCpp的序列化与反序列化流程,验证了其在处理复杂数据结构时的有效性。全文系统性地构建了从传输层到应用层的完整网络通信知识体系。
谢谢大家的观看!