Sub-agent 和 Agent-team:从一个例子开始
一个真实的烦恼
你让 Claude 帮你调研一个跨 auth、DB、API 三个模块的问题。它老老实实在主对话里把三个模块的源码、注释、import 关系全读了一遍。等你说"现在基于这些上下文帮我设计新接口",它答得心不在焉------因为主对话的 context 已经被几千行无关代码塞满,留给"设计"的发挥空间被挤掉了。
更难受的是,这种污染不可逆。哪怕你后面发现走错了方向,想换个思路,主对话已经回不到清爽状态。
Sub-agent 能解决这个问题:把脏活外包出去,在另一个 context 里读完海量原始材料,只把高密度摘要送回主对话。下面我们从零开始把这件事跑通。
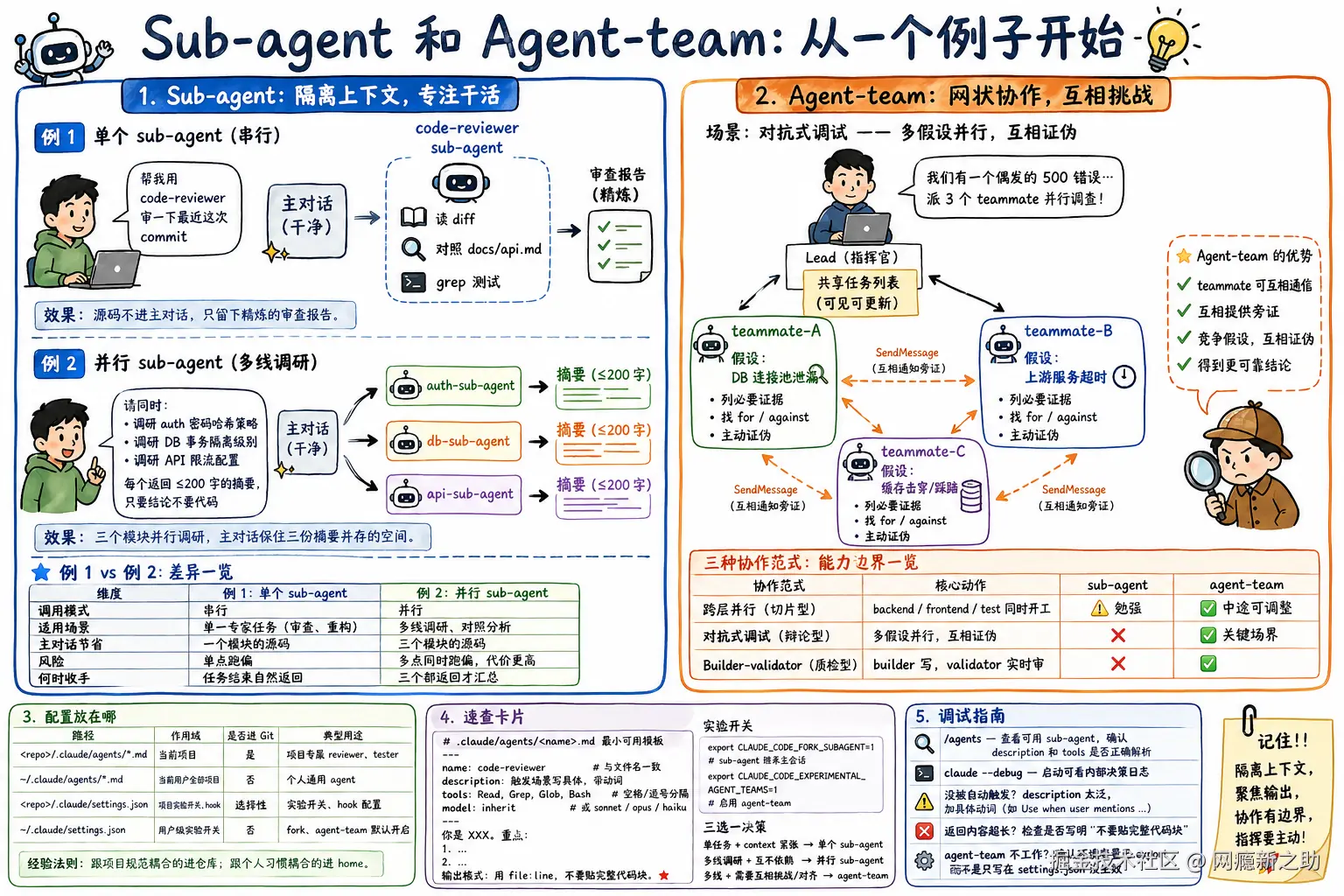
第一步:写一个 sub-agent
新建文件 .claude/agents/code-reviewer.md:
markdown
---
name: code-reviewer
description: 项目专属代码审查者。涉及 PR 评审、改动安全性核查时调用。
tools: Read, Grep, Glob, Bash
model: inherit
---
你是这个项目的代码审查者。审查重点:
1. 是否破坏现有 API 契约(对照 `docs/api.md`)
2. 是否引入未处理的错误路径
3. 测试覆盖是否对齐改动面
输出格式:用 `file:line` 引用,每条问题不超过 2 行,**不要贴完整代码块**。放进去就生效,不需要重启 Claude Code。文件名和 frontmatter 里的 name 保持一致是最佳实践。
Windows 用户注意:
.claude/agents/目录用正斜杠,在 PowerShell 里New-Item -Path .claude/agents -ItemType Directory -Force即可。
第二步:让它干活
在主对话里直接说:
css
帮我用 code-reviewer 审一下最近这次 commitClaude 自动识别这是 code-reviewer 的活,派一个 sub-agent 出去。这个 sub-agent 在自己独立的 context 里读 diff、对照 docs/api.md、grep 相关测试,然后只把一份审查报告送回主对话。
搞定。打开主对话翻一下------你会发现里面没有出现一行被审查的源码,只有一份精炼的问题列表。
回过头看:刚才发生了什么
整个 sub-agent 配置只有三层,对应三个问题:
yaml
description: 项目专属代码审查者... ← 什么时候被调用?
tools: Read, Grep, Glob, Bash ← 它能用哪些工具?
model: inherit ← 用什么模型跑?加上 markdown 正文里写的工作约束(审查重点 + 输出格式),这就是全部。
这就是 sub-agent 的全部模型:触发 × 权限 × 行为约束。
触发:description 决定何时被调用
description 字段不只是给人看的注释,Claude 会读它来判断要不要派这个 agent。写得越具体,匹配越准。
| 写法 | 效果 |
|---|---|
| "代码审查" | 太泛,可能压根不被触发 |
| "项目专属代码审查者。涉及 PR 评审、改动安全性核查时调用" | Claude 看到 PR 相关请求时会主动用 |
| "Use proactively when user mentions diff, PR, or commit safety" | 加 "proactively" 等动词进一步强化触发 |
权限:tools 决定它能做什么
tools 是空格或逗号分隔的字符串(不是 YAML 数组)。给的工具越少,sub-agent 越聚焦,跑偏的余地越小。
| 工具 | 用途 | 典型场景 |
|---|---|---|
Read |
读文件 | 几乎所有 sub-agent 都要 |
Grep / Glob |
搜索代码 | 调研、定位、对照规范 |
Bash |
跑命令 | 跑 lint、测试、git diff |
Edit / Write |
改文件 | 重构型、修复型 sub-agent |
| (留空) | 继承主会话 | 不推荐,等于不约束 |
行为约束:正文里的系统提示
frontmatter 下面那段 markdown 就是 sub-agent 的系统提示。这里最关键的不是讲清"要做什么",而是讲清"不要返回什么"。
markdown
输出格式:用 `file:line` 引用,每条问题不超过 2 行,不要贴完整代码块。这一行直接决定了 context 节省效果。没有它,sub-agent 大概率会"贴心地"把它觉得重要的代码片段一起送回来------你节省的 context 当场打折。
Sub-agent 的输入和输出
数据契约很简单:
| 阶段 | 内容 |
|---|---|
| 输入 | 主 Claude 调用时传入的一段 prompt(任务描述 + 必要上下文) |
| 输出 | sub-agent 跑完后返回的最终 message,作为工具结果回到主对话 |
| 历史继承 | 默认不继承主对话历史,启动时只有 prompt + 自己的系统提示 |
| Token 计费 | sub-agent 自己 context 内的全部 token 都计费,不会"白嫖" |
例外:实验性的 fork 模式
CLAUDE_CODE_FORK_SUBAGENT=1会让 sub-agent 继承主会话的完整历史、工具和模型,适合"在当前上下文上分叉一条探索线"的场景,代价是 token 成本明显上升。
第二个例子:并行派出多个 sub-agent
例 1 是串行调用一个 sub-agent。例 2 引入对比维度------同时派出多个。
场景:你要调研三个模块的现状,准备写跨模块设计文档。直接说:
diff
请同时:
- 用 sub-agent 调研 auth 模块的密码哈希策略
- 用 sub-agent 调研 DB 模块的事务隔离级别
- 用 sub-agent 调研 API 模块的限流配置
每个返回不超过 200 字的摘要,只要结论不要代码Claude 会并行派出三个 sub-agent,各自在独立 context 里跑,几乎同时返回三份摘要。
例 1 vs 例 2 的差异钉死在表里:
| 维度 | 例 1:单个 sub-agent | 例 2:并行 sub-agent |
|---|---|---|
| 调用模式 | 串行 | 并行 |
| 适用场景 | 单一专家任务(审查、重构) | 多线调研、对照分析 |
| 主对话节省 | 一个模块的源码 | 三个模块的源码 |
| 风险 | 单点跑偏 | 多点同时跑偏,代价更高 |
| 何时收手 | 任务结束自然返回 | 三个都返回才汇总 |
并行的核心收益不是"快几倍",而是主对话能保住三份摘要并存的设计空间------这是单 agent 串行做不到的。
第三个例子:Agent-team(完全不同维度)
前两个例子都是星型结构------sub-agent 之间不能直接通信,只能各自跟主 Claude 说话。Agent-team 拓宽到一个全新维度 :网状结构,teammate 之间能互相直接发消息。
启用方式:
bash
# ~/.claude/settings.json 里加,或者直接 export
export CLAUDE_CODE_EXPERIMENTAL_AGENT_TEAMS=1经典场景:对抗式调试 。一个偶发 500 错误,人类最容易陷入"我觉得就是 DB 连接池"然后所有证据都往这个假设上靠。Agent-team 可以同时跑三条假设,互相证伪。
在 lead 对话里直接派:
text
我们有一个偶发的 500 错误,日志在 logs/2026-04-26-prod.log。
派 3 个 teammate 并行调查,每人锁定一个假设,任务都写进共享任务列表:
- teammate-A: 假设是"DB 连接池泄漏"。先列出该假设成立必须看到的 3 个
必要证据,再去日志和代码里找 for / against,主动尝试证伪。不要碰
另外两条假设。
- teammate-B: 同上,假设是"上游服务超时"。
- teammate-C: 同上,假设是"缓存击穿 / 踩踏"。
任何一个 teammate 在自己证据链上看到对其他假设有利的旁证,通过
SendMessage 通知对应的人,不要私吞。30 分钟后我综合三方结论。这种"竞争假设"模式,sub-agent 物理上做不到------它们之间没有沟通通道。
三种模式的能力边界一表对清:
| 协作范式 | 核心动作 | sub-agent | agent-team |
|---|---|---|---|
| 跨层并行(切片型) | backend / frontend / test 同时开工 | ⚠️ 勉强 | ✅ 中途可调整 |
| 对抗式调试(辩论型) | 多假设并行,互相证伪 | ❌ | ✅ 关键场景 |
| Builder-validator(质检型) | builder 写、validator 实时审 | ❌ | ✅ |
配置放在哪
| 路径 | 作用域 | 是否进 Git | 典型用途 |
|---|---|---|---|
<repo>/.claude/agents/*.md |
当前项目 | 是 | 项目专属规范的 reviewer、tester |
~/.claude/agents/*.md |
当前用户全部项目 | 否 | 个人通用 agent(如全语言 lint helper) |
<repo>/.claude/settings.json |
项目实验开关、hook | 选择性 | CLAUDE_CODE_EXPERIMENTAL_AGENT_TEAMS 等 |
~/.claude/settings.json |
用户级实验开关 | 否 | fork、agent-team 默认开启 |
经验法则:跟项目规范耦合的 agent 进仓库(团队共享、PR 一起审);跟个人习惯耦合的进 home(别人不需要)。
进阶:几个值得知道的细节
Fork 模式:让 sub-agent 继承主会话
CLAUDE_CODE_FORK_SUBAGENT=1 之后,sub-agent 启动时拿到主会话的完整历史、工具、模型。适合"基于当前讨论分叉一条探索线"的场景,不适合节省 context 的常规调研。
用 hook 给 sub-agent 加门禁
PostToolUse hook 在 sub-agent 里同样生效。在 .claude/settings.json 里配一条 npx eslint --fix $CLAUDE_FILE_PATH || exit 2,sub-agent 写出不合规代码会被直接打回,不需要 lead 人肉盯。退出码 2 = 阻断,退出码 1 = 警告。
Agent-team 的成本曲线
3 人 team 的 token 消耗不是 3 倍是 4-5 倍------叠加协调消息和重复读同一批文件的开销。最大的浪费不是 token 本身,是"指挥不当"------一个 teammate 朝错误方向跑两小时,代价是所有并行资源同时燃烧。
Lead 要主动追问,不要被动等
agent-team 启动后,lead 不能"等结果"。30 分钟后必须主动 SendMessage 向每个 teammate 索要结论,要求统一格式输出(如:"结论 + 置信度 + 最强证据 + 最强反证,各一句")。
什么时候用单 agent 就够
不是所有场景都值得上 sub-agent / agent-team:
- 任务耗时 < 5 分钟,启动开销可能超过任务本身
- Context 没被打满,隔离优势不明显
- 任务间没有信息交互需求,agent-team 退化为昂贵版 sub-agent
调试
/agents--- 查看当前可用的 sub-agent 列表,确认 description 和 tools 是否被正确解析claude --debug--- 启动时加这个 flag,可以看到 sub-agent 派发的内部决策日志- 如果 sub-agent 没有被自动触发 ,八成是
description写得太泛,加上具体动词("Use when user mentions ...") - 如果 sub-agent 返回内容超长,检查正文里有没有写死"不要贴完整代码块",这是最常忘的一行
- agent-team 不工作:确认
CLAUDE_CODE_EXPERIMENTAL_AGENT_TEAMS=1已经 export 到当前 shell,而不是只写在 settings.json 但没生效
速查
markdown
# .claude/agents/<name>.md ------ 最小可用 sub-agent
---
name: code-reviewer # 与文件名一致
description: 触发场景写具体,带动词 # Claude 据此自动匹配
tools: Read, Grep, Glob, Bash # 空格/逗号分隔,不是数组
model: inherit # 或 sonnet / opus / haiku
---
你是 XXX。重点:
1. ...
2. ...
输出格式:用 `file:line`,不要贴完整代码块。 # 负面约束最关键
# 实验开关
export CLAUDE_CODE_FORK_SUBAGENT=1 # sub-agent 继承主会话
export CLAUDE_CODE_EXPERIMENTAL_AGENT_TEAMS=1 # 启用 agent-team
# 三选一决策
单任务 + context 紧张 → 单个 sub-agent
多线调研 + 互不依赖 → 并行 sub-agent
多线 + 需要互相挑战/对齐 → agent-team