写在前面
本文看下文件系统相关内容。
1:为什么需要文件系统?
我们知道,磁盘是用来存储需要持久化数据的。但是有些问题需要来解决,比如文件应该如何存储到磁盘中,存储到磁盘中之后又该如何查看,如何删除磁盘中的文件等。所以就需要一个专门来做这块内容的东西,也就是本文要分析的文件系统,这也是文件系统存在的意义。
2:文件系统基础介绍
2.1:基础介绍
文件系统既然是用来管理文件的,为了方便管理,文件系统为每个文件都定义了两个基本元素,如下:
- 索引节点
存储文件的元信息,如文件的修改时间,大小,访问权限,数据的位置(可理解为指向磁盘某位置的指针),如下红框中的信息就是文件的元信息:
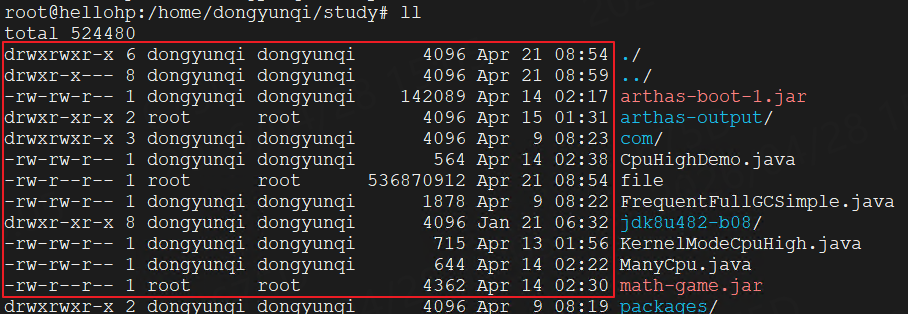
这里需要注意的是索引节点也是在磁盘中存储的,负责存储索引节点的磁盘区域还有一个专门的名称,叫索引节点区。
为什么没有文件名称呢?
这是因为这里的元信息是文件唯一存在的信息,在Linux中文件名称是可以有多个的,比如软连接的存在,这里可以这样来理解,在Java中指向某个对象的变量是可以有多个的,这里的变量就可以理解为文件名称。
- 目录项
存储文件的名称,索引节点指针(指向对应的索引节点,从而可以获取文件元信息和文件信息),和其他目录项的关系(这样就构成了一组文件的树状结构),这里目录项不同于索引节点,其是存储在内存中。
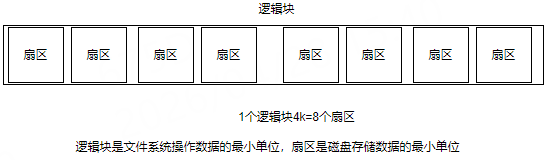
通过目录项和索引节点,就可以一层一层的找到我们需要的文件,那么我们看到的文件内容又是如何存储的呢?首先,对于磁盘来说,数据存储的最小单位是扇区,一个扇区的大小为513B,如果文件系统每次都以扇区为单位来读写数据,那速度可就真的苍了个天了!所以,文件系统定义了逻辑块的概念,一个逻辑块4k,也就是包含8个扇区:
此时我们就可以来看下基于索引节点和目录项来操作文件的结构图了:
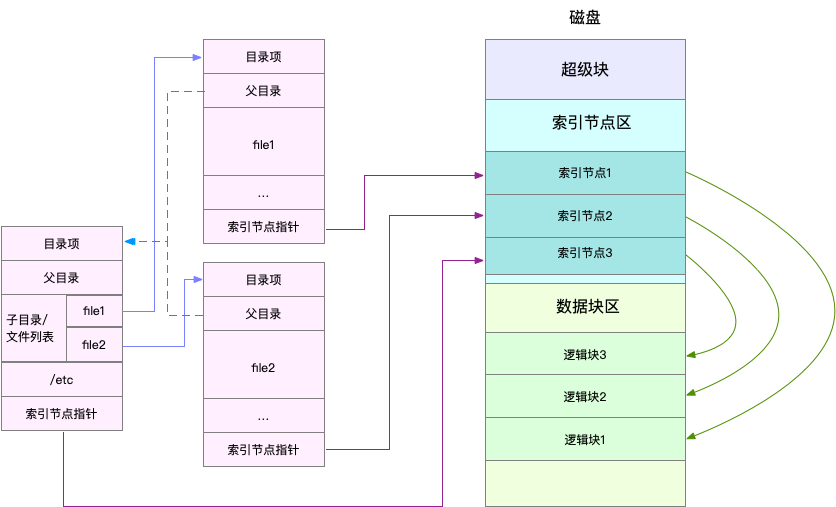
这里通过目录项构成了一种树状的结构,也就是文件的层次关系:
通过目录项中的索引节点指针可以找到索引节点,进一步的通过索引节点可以找到逻辑块,从而就可以操作数据了。
超级块是用来存储文件系统本身相关信息的,知道即可。
2.2:VFS
VFS全称,virtual file system,即虚拟文件系统,那么为什么需要虚拟文件系统呢?原因是文件系统多种多样,有基于磁盘的文件系统,有基于内存的文件系统,甚至有基于网络的文件系统,就算是相同底层存储结构文件系统的操作方法也不尽相同,那么这么多的差异化对于上层应用来说可能就是噩梦了。所以就需要一层抽象来屏蔽这种差异。所以就有了VFS。看到这里不知道你想没有想到设计模式中的门面模式 。
VFS定义了统一的接口来规范对于文件系统的调用,具体通过系统调用的方式来完成,比如当我们执行cat命令时就会执行如下的函数:
int open(const char *pathname, int flags, mode_t mode);
ssize_t read(int fd, void *buf, size_t count);
ssize_t write(int fd, const void *buf, size_t count); open函数执行一个系统调用打开文件,read函数执行一个系统调用读取文件的内容,write函数执行一个系统调用将获取的文件内容输出到控制台,如:
基于VFS的架构可以参考下图:
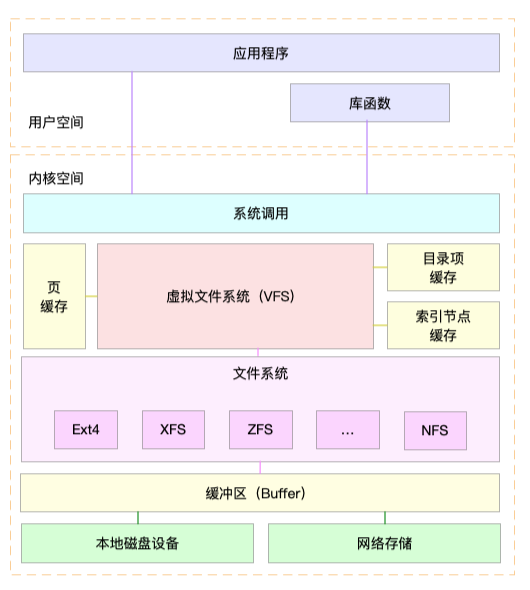
从图中可以看出用户空间通过系统调用的方式来和VFS进行交互。
3:文件系统性能观测
root@hellohp:/home/dongyunqi/study# df -h
Filesystem Size Used Avail Use% Mounted on
tmpfs 387M 36M 352M 10% /run
/dev/mapper/ubuntu--vg-ubuntu--lv 9.8G 9.8G 0 100% /
tmpfs 1.9G 0 1.9G 0% /dev/shm
tmpfs 5.0M 0 5.0M 0% /run/lock
/dev/sda2 1.8G 200M 1.5G 13% /boot
tmpfs 387M 12K 387M 1% /run/user/1000
tmpfs 3.7G 12K 3.7G 1% /var/snap/microk8s/common/var/lib/kubelet/pods/6f9032d4-8a02-4efa-9429-8ee0888ec228/volumes/k写在后面
参考文章列表
多知道一点
磁盘在经过了文件系统格式化之后分为哪些区域?
超级块:存储文件系统状态信息,如索引节点,逻辑块的使用情况等
索引节点区:存储索引节点
数据块区:存储文件数据
文件系统都有哪些类型?
第一种是基于磁盘的文件系统,如Ext4,overlayFS等。
第二种是基于内存的文件系统,如/proc文件系统。
第三种是基于网络的文件系统,如NFS,SMB,iSCSI。
不管是哪种文件系统,都必须要经过挂载才能使用。这里挂载的目标是VFS的某个子目录,挂载的位置称为挂载点。
当完成了挂载之后,就可以来访问文件系统了,这个访问的过程就是IO,而根据IO读写方式的不同可以将IO分为不同的种类。
- 缓冲IO,非缓冲IO
缓冲IO是通过标准库函数来加速访问,非缓冲IO是直接通过系统调用访问文件。 - 直接IO,非直接IO
直接IO:直接和文件系统交互,非直接IO:和页缓存交互,内核再和文件系统交互。
裸IO,跳过文件系统直接和磁盘交互。
- 阻塞IO和非阻塞IO
阻塞IO,阻塞等待结果。非阻塞IO,不阻塞等待结果,可定时查询,或者被动接收通知。 - 同步IO和异步IO