小米放了个大招。1.02万亿参数的MoE模型,MIT协议直接开源,API平台狂送100T Token。我第一反应是,小米?做手机那个小米?
在AI大模型这件事上,小米一直存在感不高。DeepSeek、Kimi、通义千问轮番上热搜的时候,小米的MiMo系列就像个安静做题的学霸,考得不差,但就是没人注意。但这次V2.5,真的不太一样。
 图片来源:mimo.xiaomi.com/mimo-v2-5/a...
图片来源:mimo.xiaomi.com/mimo-v2-5/a...
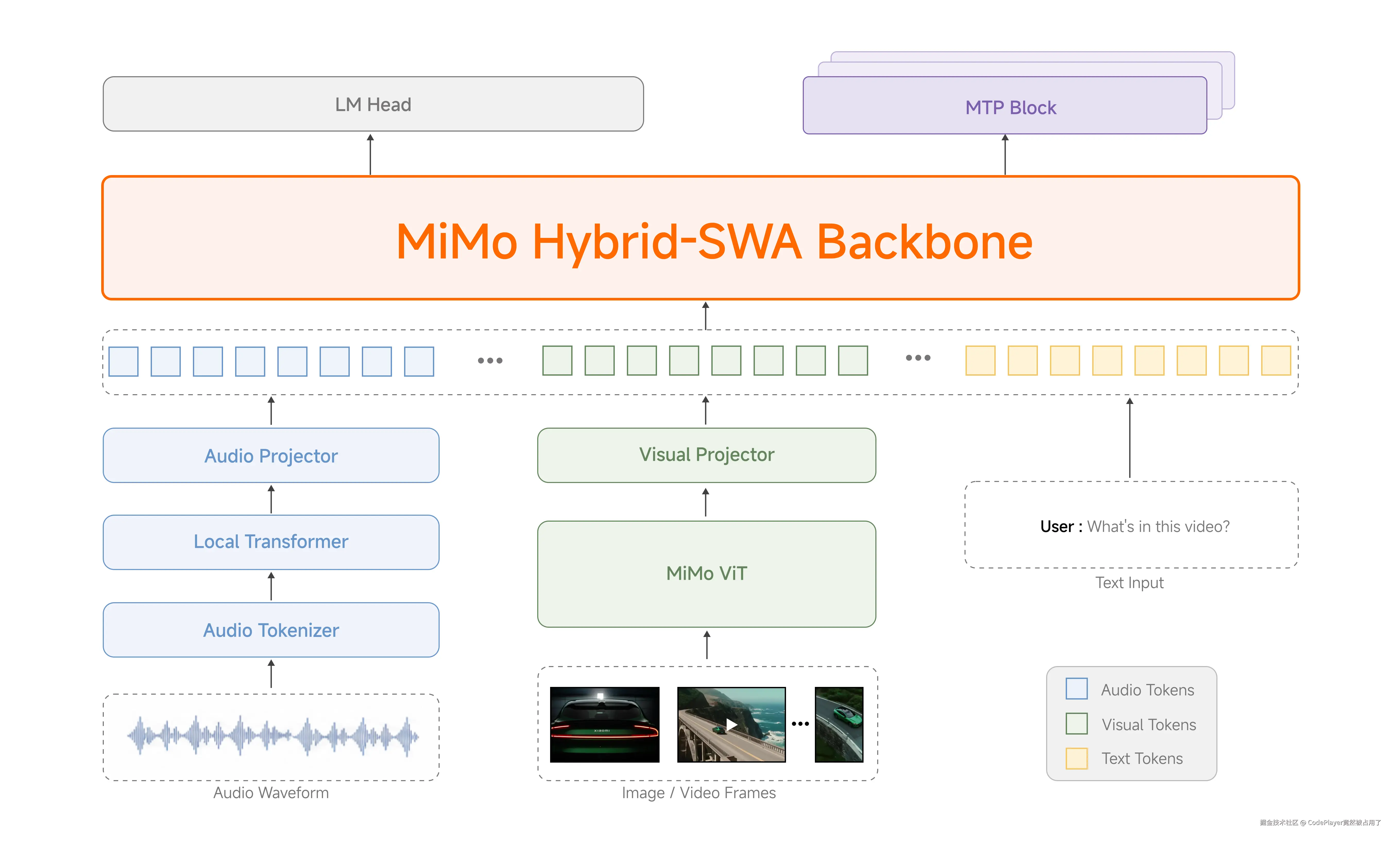
先说最炸裂的。MiMo-V2.5-Pro,1.02万亿总参数,420亿激活参数,MIT协议。你没看错,MIT。不是什么Apache 2.0加一堆限制条款,不是「仅限研究用途」的假开源,是MIT------拿去商用、改代码、继续训练,想怎么用怎么用,连版权声明都不需要。当然标一下还是好的。1.02T总参,比DeepSeek-V4-Pro还大。
而且不是一个模型开源,是整个家族全端上来了。310B的多模态版,1T的Pro版,8B的语音识别版,还有语音合成版,全部MIT。连基础模型Base版都一起开了。我之前见过太多「开源」大模型了,开源权重但限制商用,开源小模型但大模型闭源。像小米这样一口气把1T参数的Pro版和310B的多模态版全开了,还用最宽松的MIT协议,确实少见。
说开源慷慨容易,关键还是得看本事。
先看MiMo-V2.5-Pro的表现。基础模型层面,MMLU 89.4,GSM8K 99.6,MATH 86.2。MATH 86.2是什么概念?DeepSeek-V4-Pro Base是64.5,Kimi-K2 Base是70.2,直接甩了一大截。GPQA-Diamond 66.7,Kimi-K2 Base只有48.1。当然Base模型的对比要谨慎,训练数据量不同、训练策略不同,差距不一定代表能力差距,但至少说明小米在预训练阶段下了大功夫。
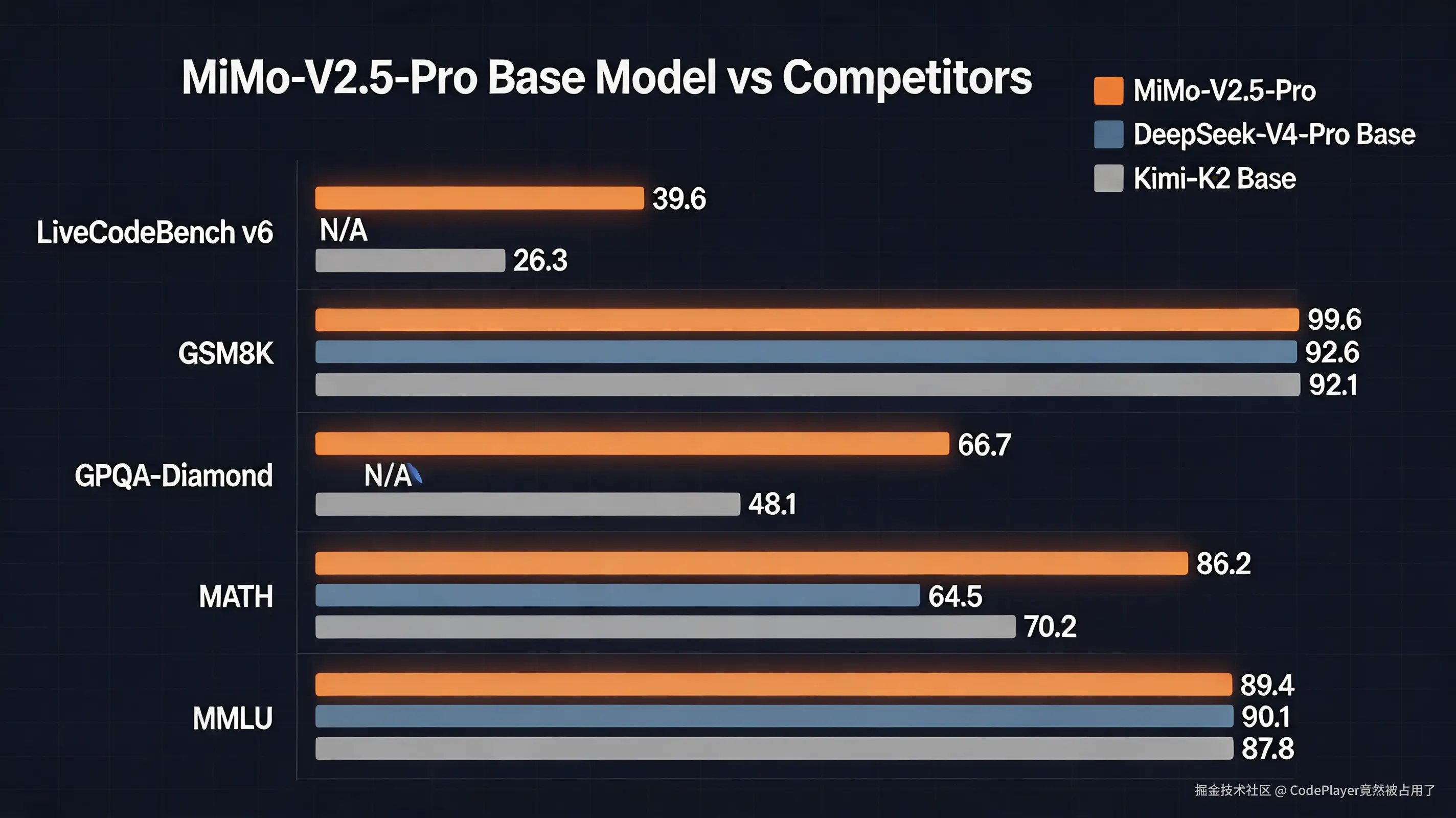 MiMo-V2.5-Pro Base vs DeepSeek-V4-Pro Base vs Kimi-K2 Base
MiMo-V2.5-Pro Base vs DeepSeek-V4-Pro Base vs Kimi-K2 Base
对话模型层面,Agent能力是这次的主打方向。SWE-Bench Pro 57.2,和Claude Opus 4.6的57.3几乎打平;Terminal-Bench 2.0 68.4,超过了Opus 4.6的65.4。Claw-Eval(Agent综合评测)63.8,还没追上Opus 4.6的70.4,但比GPT-5.4的60.3和DeepSeek V4 Pro的59.8都高。
但我觉得最值得说的,是Token效率。在Claw-Eval上,MiMo-V2.5-Pro平均每个轨迹消耗约70K Token,实现了64%的Pass³。作为对比,Claude Opus 4.6用114K Token达到70.8%,GPT-5.4用183K Token才到60.3%,Gemini 3.1 Pro更是烧了227K Token只拿到55.9%。MiMo-V2.5-Pro用不到GPT-5.4四成的Token量,跑出了比GPT-5.4更好的成绩。你在实际业务中跑Agent的话,这个Token效率差异就是真金白银。
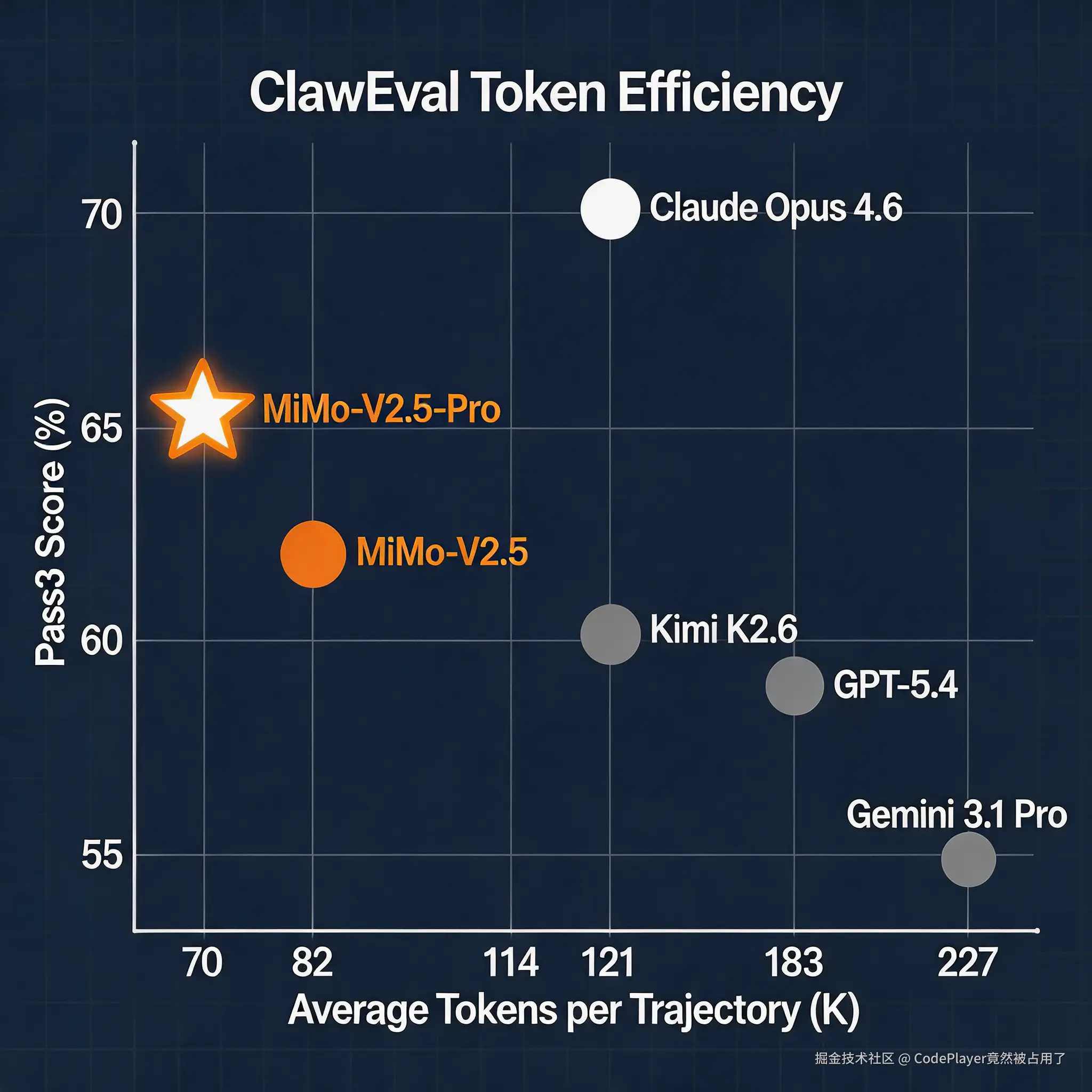 ClawEval评测,MiMo-V2.5-Pro用最少Token跑出最好成绩
ClawEval评测,MiMo-V2.5-Pro用最少Token跑出最好成绩
多模态方面,MiMo-V2.5(310B/15B那个)是原生全模态,文本、图像、视频、音频统一架构,不是拼接的。Video-MME 87.7,CharXiv RQ 81.0,HR-Bench 4k 88.5,跟Gemini 3 Pro和Kimi K2.6基本在一个水平线上。多模态这块我自己还没亲自测过,不好下太强的判断,至少从Benchmark来看,没有明显短板。
聊完数据聊架构,这次MiMo-V2.5的几个设计我觉得挺有意思。
混合注意力机制,不全用全局注意力,5:1交替使用滑动窗口注意力和全局注意力,窗口大小128。这招直接把KV缓存存储降了约7倍,但通过可学习的注意力汇聚偏置,长上下文性能没怎么掉。在GraphWalks长上下文评测里,MiMo-V2.5-Pro在1M上下文时BFS还能保持37%,Parents保持62%。上一代MiMo-V2-Pro在长上下文上基本就是断崖式下跌。
多Token预测,3个轻量级MTP模块,推理时用推测解码把输出速度提了3倍。DeepSeek也在用类似的思路,但小米在MTP模块里用了稠密FFN,329M参数3层,比较轻量。MoE路由方面,Pro版384个路由专家,每次激活8个,1.02T总参只激活42B,稀疏比很高,推理成本可以控制得比较低。训练数据量,V2.5用了约48T Token预训练,Pro版用了27T Token,不算特别大,但结合MOPD(多教师策略蒸馏)的后训练方法,最终效果不错。
 两个版本的关键架构参数对比
两个版本的关键架构参数对比
这次最让我意外的,是MiMo开放平台的100T Token赠送活动。新用户注册就送,之前买过Token Plan的用户还重置了Credit余额。这手笔,比很多大厂都大方。
 图片来源:mimo.xiaomi.com/mimo-v2-5-p...
图片来源:mimo.xiaomi.com/mimo-v2-5-p...
小米图什么呢?坦率的讲,逻辑不难理解。小米跟OpenAI、Anthropic不一样,它不需要靠卖API赚钱,它需要的是让更多人用MiMo,把AI能力嵌入小米生态------手机、汽车、智能家居。模型开源、API便宜,都是为了降低开发者进入小米生态的门槛。1T参数MIT开源,这种事一出来,技术圈自然会讨论,比花钱投广告有效多了。100T Token看着多,但对小米来说就是算力成本,用100T Token换来一波开发者入驻,这获客成本比买量便宜多了。
小米在AI这件事上的策略跟做手机一样,性价比卷死你,用规模换利润。
说个有意思的事。Hacker News上有人评价MiMo-V2-Pro是「最被低估的模型发布」。这个评价放在V2.5上依然成立。小米做AI的方式,跟大多数公司不一样,它不搞「模型即服务」那一套,不靠API收费赚钱,不设各种使用限制,它就是把模型扔出来,MIT协议,你爱怎么用怎么用。
这让我想起小米做手机的早期。2011年,小米1发布,1999元,同等配置的其他手机至少要3000+。雷军说,小米的硬件综合净利润率永远不超过5%。当时很多人觉得这是噱头,后来发现,他是认真的。手机微利,靠MIUI生态和互联网服务赚钱;现在AI也一样,模型开源免费,靠生态和硬件赚钱。同样的配方,同样的味道。
你想想看,当小米把1T参数的模型用MIT协议开源出来的时候,其他还在用限制性许可证、还在靠API收费的厂商,压力有多大。这不是简单的技术竞争,这是商业模式的降维打击。
MiMo不是最强的模型,但它可能是目前对开发者最友好的模型。
我自己的判断是,MiMo-V2.5-Pro的能力介于DeepSeek V4 Pro和Claude Opus 4.6之间,某些场景比如数学和长上下文甚至更强,但Agent综合能力跟Opus 4.6还有差距,特别是复杂推理和多步骤规划。Token效率是它最大的亮点,实际部署成本低很多。对行业来说,小米这一波对DeepSeek和Kimi的压力不小------同样是国产MoE模型,MiMo-V2.5-Pro参数更大、协议更宽松、Token效率更高,开源社区的注意力是有限的,1T参数加MIT的组合,会分流很多原本关注DeepSeek的开发者。
如果你是做Agent开发,值得试。尤其是对Token成本敏感的场景,API调100T免费Token够跑不少实验了。本地部署的话1T参数的Pro版门槛不低,但310B/15B激活的V2.5版还是可以搞搞的,SGLang和vLLM都支持,部署难度不算大。说了这么多,我自己还没在生产环境跑过MiMo-V2.5,以上判断主要基于官方数据和社区反馈。Benchmark和实际体验的差距,懂的都懂。等我跑完自己的测试集,会再分享实际体验。
1T参数开源,100T Token白送,MIT协议随便用。
这操作,确实很小米。