目录
[机器学习 VS 深度学习](#机器学习 VS 深度学习)
[特征值分解(Eigen Value Decomposition,EVD)](#特征值分解(Eigen Value Decomposition,EVD))
[Two-Stage之Fast RCNN算法](#Two-Stage之Fast RCNN算法)
[Fast RCNN介绍](#Fast RCNN介绍)
[Fast RCNN的不足](#Fast RCNN的不足)
[One-Stage之YOLO v1](#One-Stage之YOLO v1)
[YOLO v1的核心思想](#YOLO v1的核心思想)
[YOLO v1的具体步骤(以本节导图为例)](#YOLO v1的具体步骤(以本节导图为例))
[YOLO v1的不足:](#YOLO v1的不足:)
[One-Stage之YOLO v2](#One-Stage之YOLO v2)
[YOLO v2的改进](#YOLO v2的改进)
本阶段课程目标
- 课程难度高
- 仅作为扩展内容
- 是数据分析后期的一个发展方向
- 了解原理即可
认识深度学习
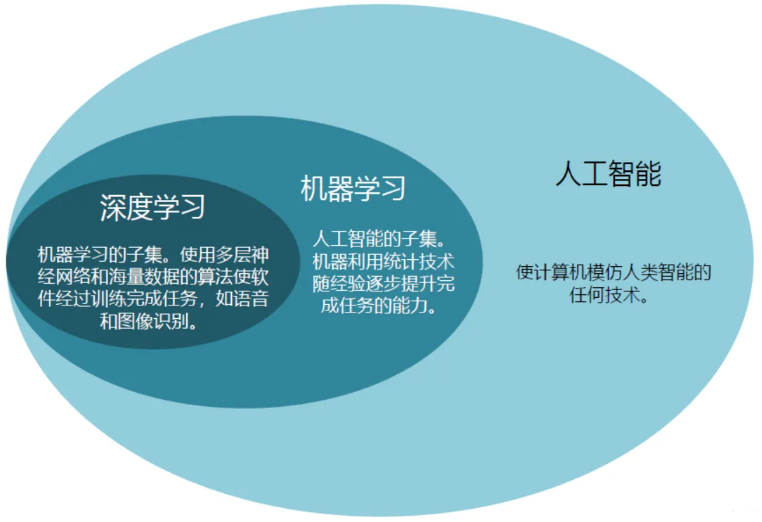
什么是深度学习
深度学习(DeepLearning,DL)属于机器学习的子类。它的灵感来源于人类大脑的工作
方式,是利用深度神经网络来解决特征表达的一种学习过程。深度神经网络本身并非是一个
全新的概念,可理解为包含多个隐含层的神经网络结构。
机器学习 VS 深度学习
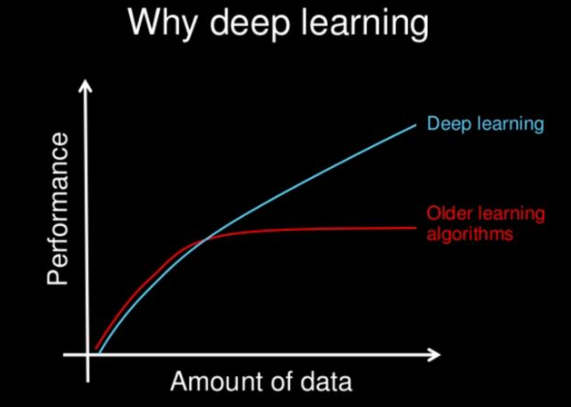
- 数据依赖性
深度学习与传统的机器学习最主要的区别在于随着数据规模的增加其性能也不断增长;
当数据很少时,选择机器学习算法的性能更好。
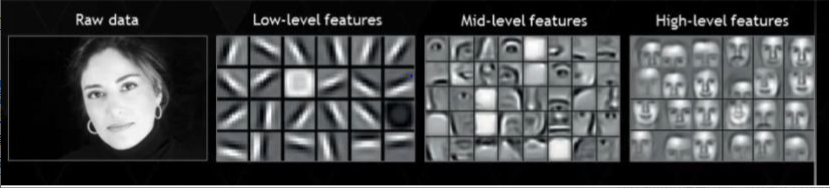
- 特征处理
在机器学习中,大多数应用的特征都需要专家确定然后编码为一种数据类型;
深度学习尝试从数据中直接获取高等级的特征,这是深度学习与传统机器学习算法的主
要的不同
例如,卷积神经网络尝试在前边的层学习低等级的特征(边界,线条),然后学习部分人
脸,然后是高级的人脸的描述。
- 执行时间
深度学习算法中参数很多,数据量大,所以训练需要消耗更长的时间
- 可解释性
机器学习算法给出了明确的规则,可解释性很强,解释决策背后的推理很容易;
深度学习对于给出的预测结果不能给出确切的解释,可解释性弱
PyTorch介绍与安装

PyTorch介绍
PyTorch是一个基于Torch的Python开源机器学习库和深度学习库,用于图像处理、自
然语言处理等应用程序。
PyTorch的"前世今生":
- PyTorch的前身是Torch,但因Torch采用了小众的编程语言是Lua,所以流行度不高,这也就有了PyTorch的出现
- PyTorch主要由Facebook的人工智能小组开发
PyTorch的安装
PyTorch的安装分为CPU版本与GPU版本两种方式
- CPU版本安装
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple torch torchvision
import torch
print(torch.__version__) # 1.11.0+cpu
import torchvision
print(torchvision.__version__) # 0.12.0+cpu注意:
本课程安装的torch版本是'1.11.0+cpu',torchvision版本是'0.12.0+cpu',经测试环境稳定。
- GPU版本安装
GPU版本的安装比较复杂,需要安装安装CUDA和cuDNN等加速库,而且需要电脑的配
置比较高,想要挑战的同学可以访问PyTorch官网(https://pytorch.org/)进行下载安装。
Tensor介绍与创建方法

什么是Tensor
Tensor,中文叫作张量,是PyTorch中基本的数据类型。实际上,PyTorch将NumPy的
Array包装成Tensor,为其定义了各种方法和函数。Tensor之于PyTorch,相当于Array之于
Numpy
比较:
- 标量是只有大小没有方向的量,如1、2、3等;
- 向量是既有大小又有方向的量,如u=(2,5,8);
- 矩阵是由多个向量组成的数表;
- 而标量、向量、矩阵都是张量的特例: 标量是零维张量、向量是一维张量、矩阵是二维张量。 张量还可以向更高维推广。
Tensor的常用创建方法
import torch
a = torch.Tensor(2,4) # 创建一个2x4的矩阵Tensor
b = torch.DoubleTensor(2,3,4) # 创建2x3x4的64位浮点数Tensor
c = torch.zeros(2,4) # 创建全0的Tensor
d = torch.ones(2,4) # 创建2x4的全1的Tensor
e = torch.eye(3) # 创建3x3的单位矩阵Tensor
x = torch.rand(2,4) # 创建2x4的数据为区间[0,1)的随机数的Tensor
y = torch.arange(1,4) # 创建在指定区间(不包括结尾数)的一维Tensor
z = torch.arange(1,4,0.5) # 第三个参数指定步长Tensor的数学运算

Tensor基本数学运算
python
import torch
a = torch.Tensor([[1,2,3],[4,5,6]])
b = torch.ones(2,3)
b.add(a) # 直接使用Tensor实例调用数学操作方法
torch.add(a,b) # 使用torch库的方法
b.add_(a) #注意:该方法带有下划线,此时返回值将覆盖对象(张量b被结果覆盖)
a + b # 使用加法运算符直接相加
# 还可以让Tensor中的每个元素都加上同一个标量
a = torch.rand(3)
a + 2 # 第一种方式
torch.add(a,2) # 第二种方式
a.add(2) # 第三种方式
# 返回Tensor中每个元素的绝对值
torch.abs(torch.Tensor([[-5,-4,-3],[-3,-2,-1]]))
# 对Tensor中的每个元素向上取整
a = torch.Tensor([0.2,1.5,3.4])
torch.ceil(a)
# 返回Tensor中每个元素的以e为底的指数
torch.exp(torch.Tensor([1,2,3]))
# 返回Tensor中所有元素的最大值
torch.max(torch.Tensor([1,2,3]))Tensor线性代数运算
python
import torch
# 向量与向量的点积(内积)
a = torch.Tensor([1,2,3])
b = torch.Tensor([2,3,4])
torch.dot(a,b) # 第一种方式
a.dot(b) # 第二种方式
# 矩阵与向量的乘法
a = torch.Tensor([[1,2,3],[2,3,4],[3,4,5]])
b = torch.Tensor([1,2,3])
torch.mv(a,b) # 第一种方式
a.mv(b) # 第二种方式
# 两个矩阵相乘
a = torch.Tensor([[1,2,3],[2,3,4],[3,4,5]])
b = torch.Tensor([[2,3,4],[3,4,5],[4,5,6]])
torch.mm(a,b) # 第一种方式
a.mm(b) # 第二种方式
# 转置矩阵
a = torch.rand(2,2)
torch.t(a) # 返回a的转置矩阵
a.T # 调用T属性Tensor的连接、切片、变形

python
import torch
# 连接
a = torch.rand(2,2)
b = torch.rand(2,2)
torch.cat((a,b),0) # 在0维度(垂直方向)上连接
torch.cat((a,b),1) # 在1维度(水平方向)上连接
# 切片
c = torch.rand(2,4)
torch.chunk(c,2,1) # 将张量c按第二个维度切分为两块
# 使用view( )变形
x = torch.rand(2,3,4)
x.size()
y = x.view(2,12)
y.size()
z = x.view(-1,1) # -1参数代表该维度数目自动计算
z.size() PyTorch自动微分

自动微分(Autograd)是什么
Autograd中文叫作自动微分,是PyTorch进行神经网络优化的核心。自动微分,顾名
思义就是PyTorch自动为我们计算微分(更多情况计算的是导数)。
例如:有一个向量x=(1,1),将它作为输入,接着,将输入乘以4得到向量z=(4,4),最后求
出长度并输出一个标量y,值为5.6569。从数学角度推导y关于x向量的微分
y=z12+z22=(4x1)2+(4x2)2=4x12+x22
根据这个关系不难分别计算y关于x1和x2的导数
∂y∂x1=∂(4x12+x22)∂x1≈2.8284
如果一个输入需要经过比上面例子更多的计算步骤,那么靠人工去计算微分就变得力不
从心。幸运的是,PyTorch的Autograd技术可以帮助我们自动求出这些微分值。
PyTorch自动微分
复杂的计算可以被抽象成一张图(graph)。一张复杂的计算图可以分为叶子节点(输入
值和神经网络的参数)、中间节点、输出节点、信息流(运行过程)四个部分。
-
叶子结点、中间节点、输出节点都是Tensor
-
Tensor在自动微分方面有3个重要属性:requires_grad、grad、grad_fn
-
requires_grad属性设置为True时,表示该Tensor需要自动计算微分
-
grad属性用于存储Tensor的微分值
-
grad_fn属性用于存储Tensor的微分函数
注意:
- 当叶子节点的requires_grad为True时,信息流经过该节点时,所有中间节点的
requires_grad属性都会变成True
-
只要在输出节点调用反向传播函数backward( ),PyTorch就会自动求出叶子节点
的微分值并更新存储在叶子节点的grad属性中。需要注意的是,只有叶子节点的grad属性能被更新
PyTorch与特征值分解------EVD


特征值分解(Eigen Value Decomposition,EVD)
特征值分解,就是将矩阵A分解为如下式:
A=Q∑QT
其中,Q为特征矩阵,Q中的列向量q~i~称为特征向量,Σ则是一个对角阵,主对角线上
的元素就是特征值。
PyTorch实现EVD
python
import torch
A = torch.tensor([[-1,1,0],[-4,3,0],[1,0,2]],dtype=torch.float64)
result = torch.linalg.eig(A)
print(result) # result中包含了特征值和特征向量特征值分解(EVD)的应用场景------PCA
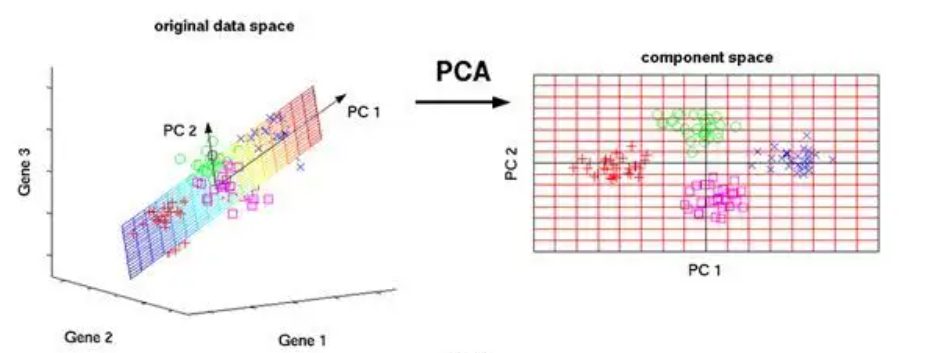
EVD的应用场景------PCA
PCA(Principal Component Analysis),主成分分析,是线性的数据降维技术,PCA通
过找出几个综合变量作为主成分,来代替原来众多的变量,其中每个主成分都是原始变量的
线性组合,而且各个主成分之间不相关(即线性无关)。
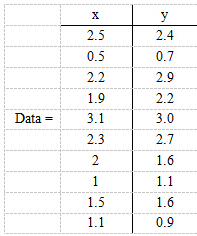
举例说明:
-
原始数据
-
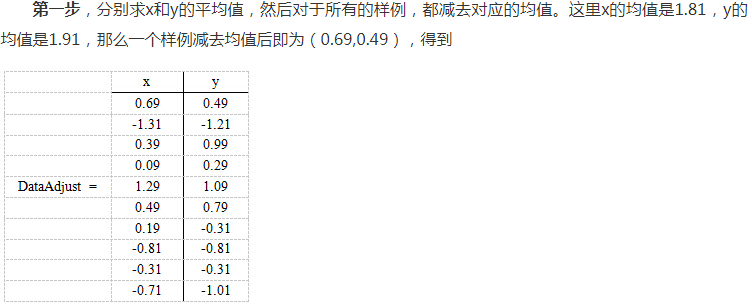
-

-

-

-
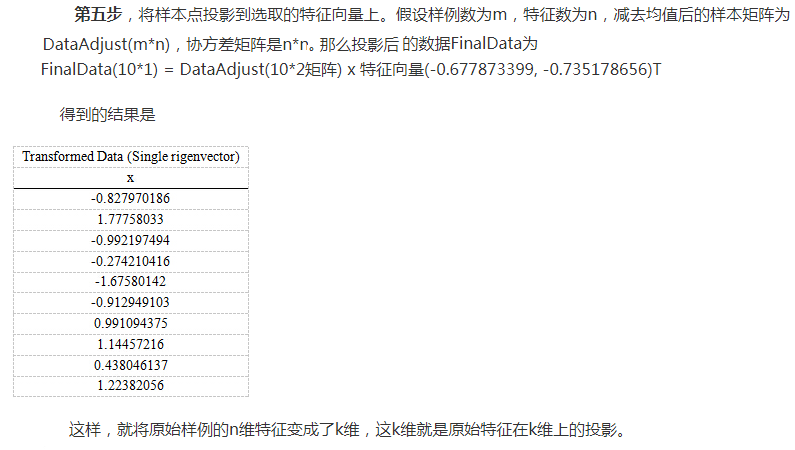
人工神经网络与全连接神经网络
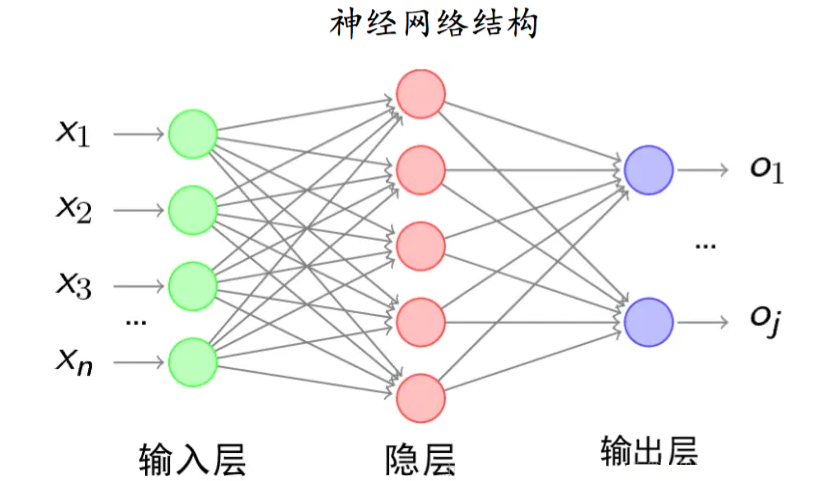
人工神经网络、全连接神经网络
人工神经网络(Artificial Neural Network,ANN)可以对一组输入信号和一组输出信号之
间的关系进行建模,其灵感源于动物的神经中枢,由大量的人工神经元连接而成;
全连接神经网络是一种连接方式较为简单的人工神经网络结构,某一层的任意一个节
点,都和上一层所有节点相连接。
感知器工作机制
感知器即单层神经网络,也即"人工神经元",是组成神经网络的最小单元
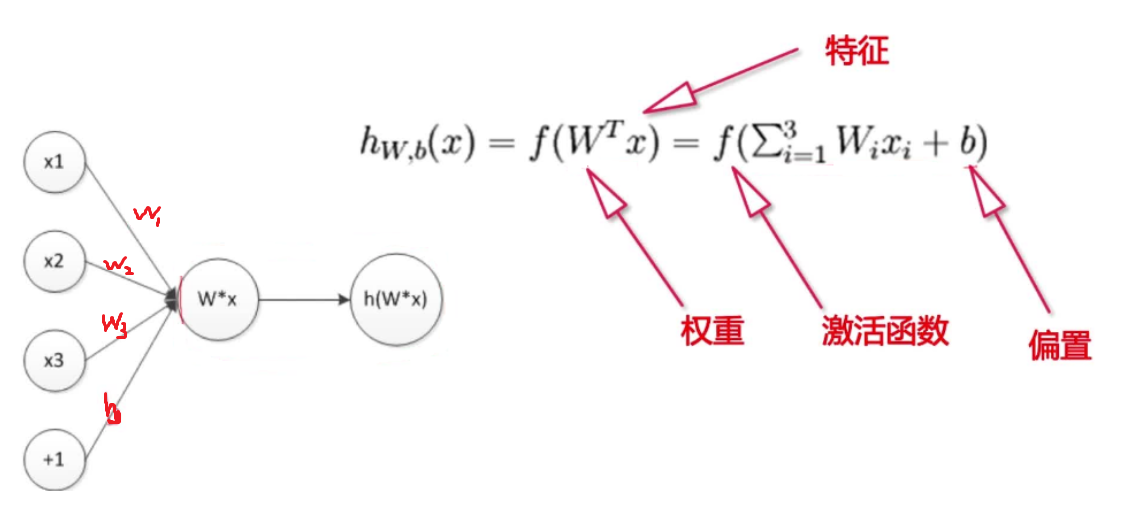
神经网络的激活函数
在神经网络中可以引入非线性激活函数,这样就可以使得神经网络可以对数据进行非线
性变换,解决线性模型的表达能力不足的问题
常见的激活函数
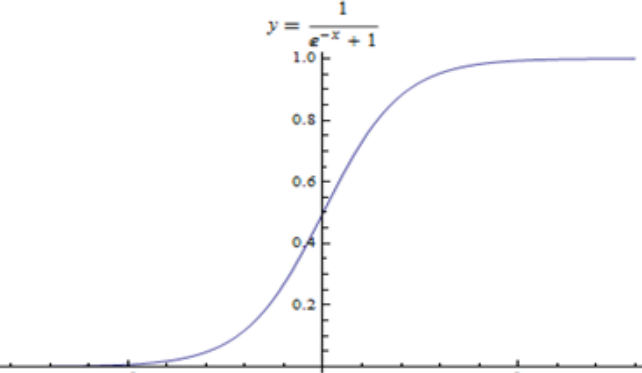
- Sigmoid激活函数
y=11+e−x
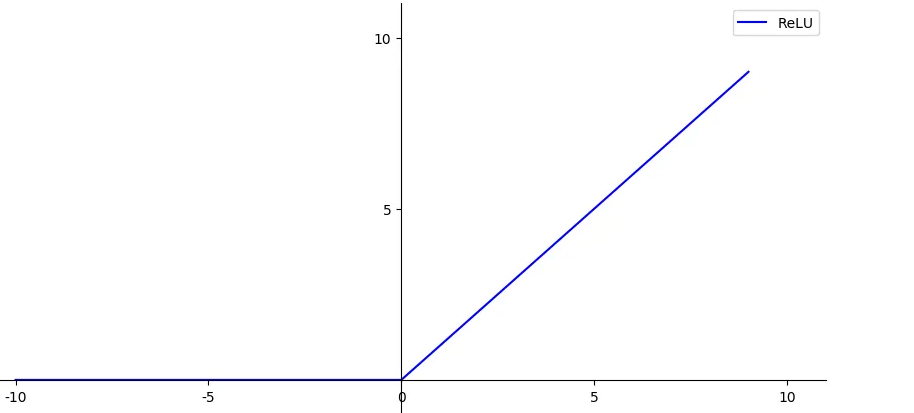
- Relu激活函数
y=max(0,x)
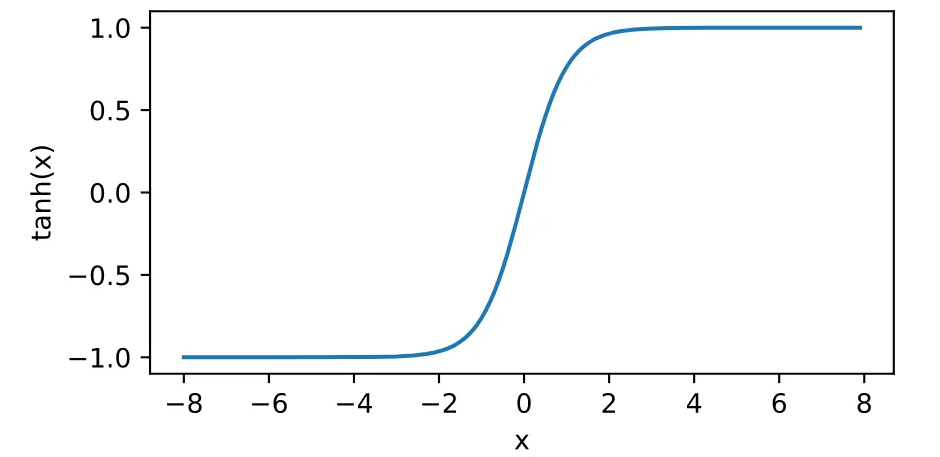
- tanh激活函数
y=ex−e−xex+e−x=1−e−2x1+e−2x
神经网络的过拟合问题
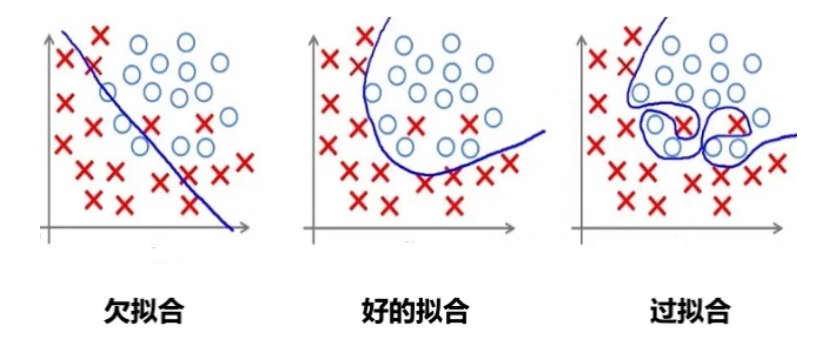
神经网络因为隐藏层的存在可以实现复杂的非线性拟合功能。但随着神经网络层数加
深,神经网络很容易发生过拟合现象(在训练集上表现很好,在未知的测试集上表现很
差,即"泛化能力差")。
解决神经网络过拟合问题的方法:
- 正则化
与很多机器学习算法一样,可以在待优化的目标函数上添加正则化项(例如L1、L2正
则),可以在一定程度减少过拟合的程度
- Dropout(随机失活)
可以将Dropout理解为对神经网络中的每一个神经元加上一道概率流程,使得在神经
网络训练时能够随机使某个神经元失效。
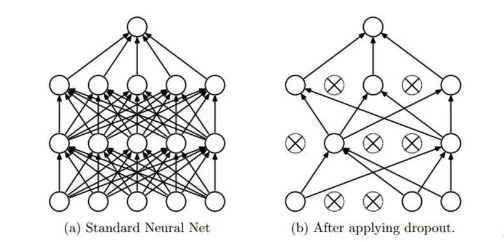
注意:
- 对于不同神经元个数的神经网络层,可以设置不同的失活或保留概率
- 如果担心某些层所含神经元较多或比其他层更容易发生过拟合,则可以将该层的失活概率设置得更高一些
前向传播与反向传播

前向传播
计算输出值的过程称为"前向传播"
python
import torch
x = torch.ones(2)
# 在前向传播时就应该修改该属性值,目的是在反向传播时可以自动计算微分
x.requires_grad = True
# 可以查看此时x的grad、grad_fn属性,均没有值
z = 4 * x # 向量与实数相乘
y = z.norm() # 求z向量的长度
print(y)反向传播(Backpropagation,BP)
-
反向传播(BP)是用来求解神经网络参数的重要方法
-
BP算法通过计算输出层结果与真实值之间的偏差(损失函数)来进行逐层调节参数
以线性模型为例:
y^=wx+bmin J(w)=||y−y^||2w=w−η∂J(w)∂w
-
调用输出节点的backward()方法PyTorch就会自动求出叶子节点的微分值
python
y.backward() # 调用输出节点的backward()方法对整个图进行反向传播
print(x.grad) # 此时x向量的grad属性已更新为x向量的微分值此时查看一下z与y的grad值,发现并没有改变,因为它们都不是叶子节点
神经网络实现线性回归

定义网络模型
python
from torch import nn,optim
class LR(nn.Module): # 神经网络模型需要继承nn.Module类
def __init__(self):
super(LR,self).__init__() # 先调用父类的构造方法
self.linear = nn.Linear(in_features=1,out_features=1)
def forward(self,x): # 前向传播方法,x参数接收输入特征
out = self.linear(x) # 线性加权操作
return out定义损失函数、优化器
python
criterion = nn.MSELoss() # 训练数据集均方误差作为损失函数
# 随机梯度下降优化器
optimizer = optim.SGD(LR_module.parameters(),lr=1e-4) 神经网络实现多分类

softmax函数
pl=ezl∑j=1kezj
由上式可以看出:softmax函数可以巧妙地将多个分类的分数(z~l~)转化为(0,1)的值并且
和为1
softmax函数计算的结果是各个分类的预测概率值
定义多分类网络模型
python
import torch.nn.functional as F
from torch import nn,optim
# 构建神经网络类
class Net(nn.Module):
def __init__(self,input_feature,num_hidden,outputs):
super(Net,self).__init__()
# 从输入层到隐层的线性加权
self.hidden = nn.Linear(in_features=input_feature,out_features=num_hidden)
# 从隐层到输出层的线性加权
self.out = nn.Linear(in_features=num_hidden,out_features=outputs)
def forward(self,x): # 前向传播
temp1 = F.relu(self.hidden(x))# 从输入层到隐层,添加relu函数
temp2 = self.out(temp1) # 从隐层到输出层的线性加权
results = F.softmax(temp2) # 对线性加权结果使用Softmax函数
return results定义损失函数和优化器
python
criterion = nn.CrossEntropyLoss() # 交叉熵损失函数
# 随机梯度下降法优化器
optimizer = optim.SGD(net.parameters(),lr=0.02) 卷积神经网络(CNN)

什么是卷积神经网络(CNN)
卷积神经网络(Convolutional Neural Network,CNN)是传统神经网络的一个改进。
卷积神经网络主要应用在图像识别领域,它模仿了人脑的视觉处理机制,采用分级提取
特征的原理,每一级的特征均由网络学习提取。
例如,在人脸识别过程中,最底层特征基本上是各方向上的边缘,越往上的神经层越
能提取出人脸的局部特征(眼睛、嘴巴、鼻子等),最上层由不同的高级特征组合成人脸的
图像。
为什么使用CNN
在处理图像识别任务时,如果采用全连接神经网络,会存在参数数量太多、无法利用
像素之间的位置信息的问题。
CNN通过"局部连接"和"参数共享"可以更高效地完成图像识别任务
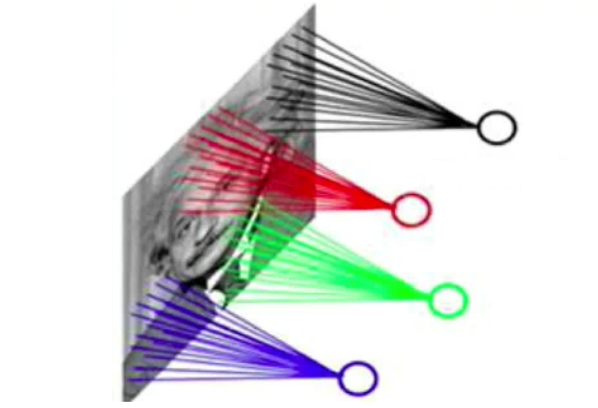
- 局部连接:每个神经元不再和上一层的所有神经元连接,而只和上一层相邻的局部区域
内的神经元连接。
- 参数共享:在卷积的过程中,一个卷积核内的参数是共享的。
卷积的理解
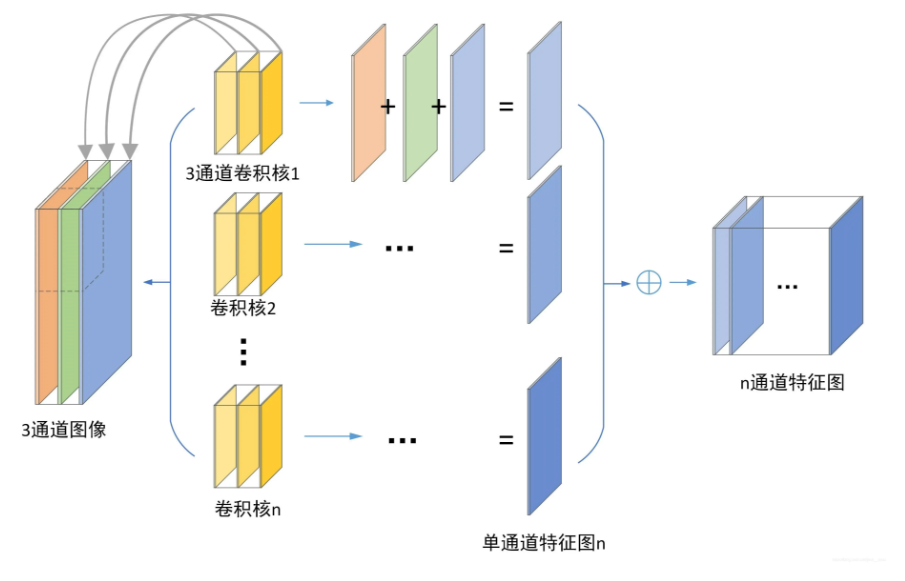
什么是卷积
从数学的角度来看,卷积可以理解为一种类似于加权运算的操作。
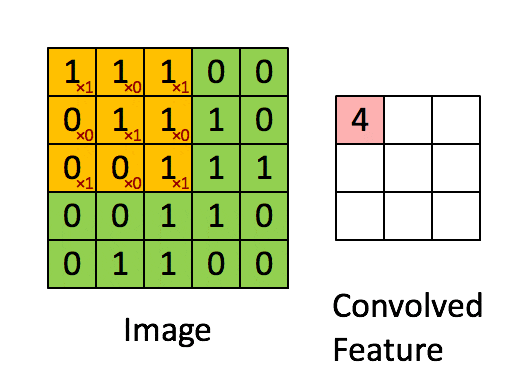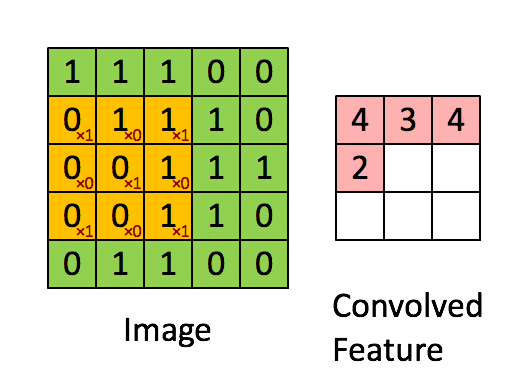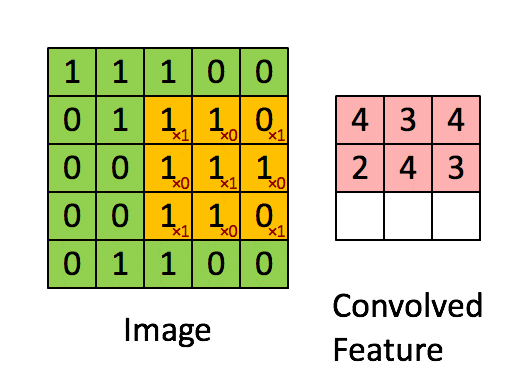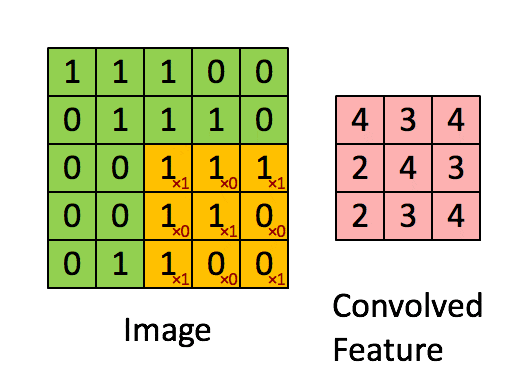
在进行卷积操作之前,需要定义一个过滤器(卷积核),其中的每一格都有一个权重值。
卷积的过程是将每个格子中的权重值与图片对应的像素值相乘并累加,所得到的值就是特征
图FeatureMap(经过卷积运算后的神经元集合)中的一个值。
注意:
- 卷积核的通道数与输入数据的通道数相同
- 卷积核的个数与输出的通道数相同
Padding的作用
由于过滤器(卷积核)在移动到边缘的时候就结束了,中间的像素点比边缘的像素点参与
计算的次数要多。因此越是边缘的点,对输出的影响就越小,我们就有可能丢失边缘信息。
为了解决这个问题,可以进行填充(padding),即在图片外围补充一些像素点,并将这些像素
点的值初始化为0。
卷积输出尺寸大小
n+2p−fs+1
其中,n为输入尺寸,p为填充尺寸,f为卷积核(过滤器)尺寸,s为移动步长
池化的理解
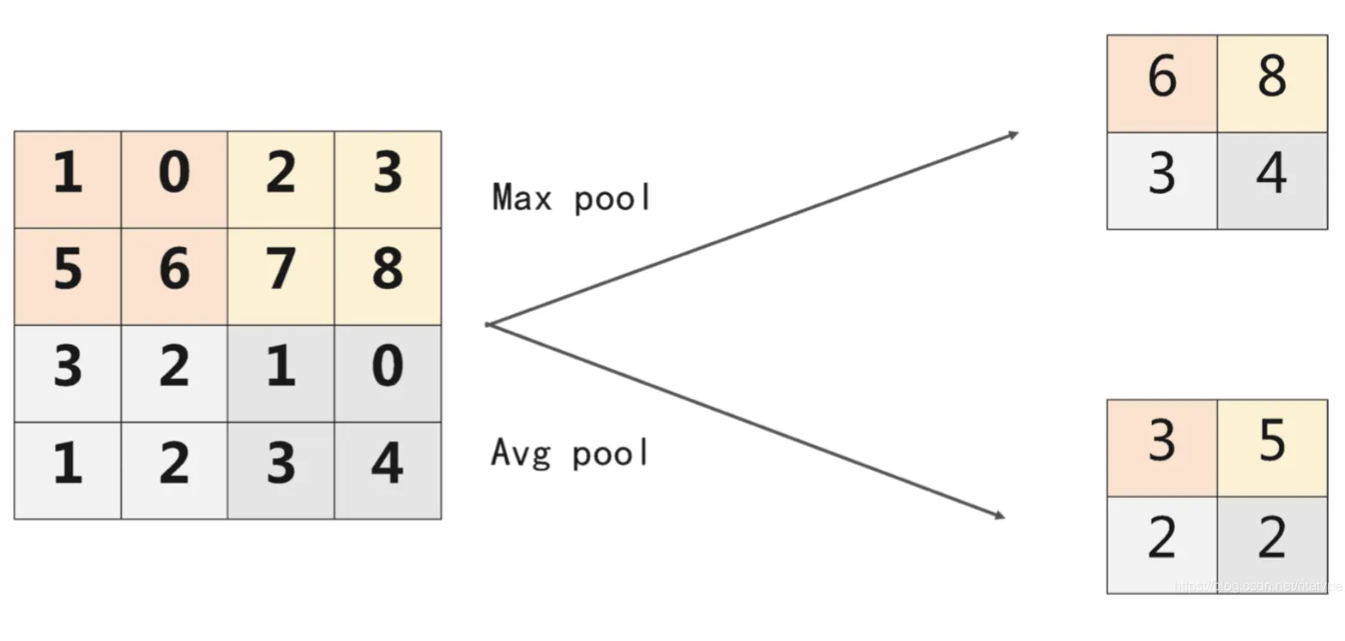
什么是池化
池化相当于对输入数据的高度和宽度进行缩小,通过对数据进行分区采样,把一个大
的矩阵降采样成一个小的矩阵,减少计算量,同时可以防止过拟合。
池化的方式
常用的池化方法有最大值池化(max pooling)和平均值池化(average pooling)两种
- 最大值池化(max pooling):在样本中取各区域数据的最大值作为采样后的样本值
- 平均值池化(average pooling): 在样本中取各区域数据的平均值作为采样后的样本值
反卷积的理解
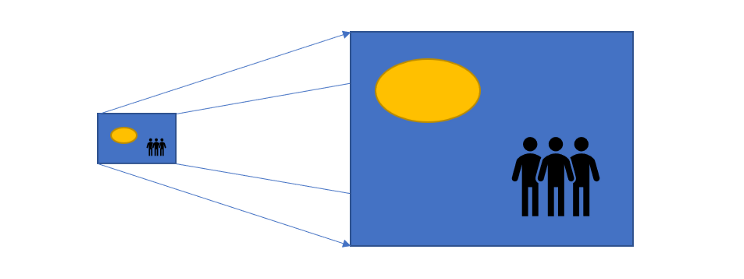
什么是反卷积
反卷积也叫作"转置卷积",通过输入图片的特征,输出图片,起到通过特征还原原图的
作用,但是反卷积并不是卷积的完全逆过程。
反卷积的过程
在反卷积中,过滤器(卷积核)是作用于输出数据上的
例子:
有一个2x2的输入,并希望最终得到一个4x4的输出,为此,选择使用3x3的过滤器(卷
积核),填充padding(这个padding用于输出数据)设置为1,移动步长设置为2。
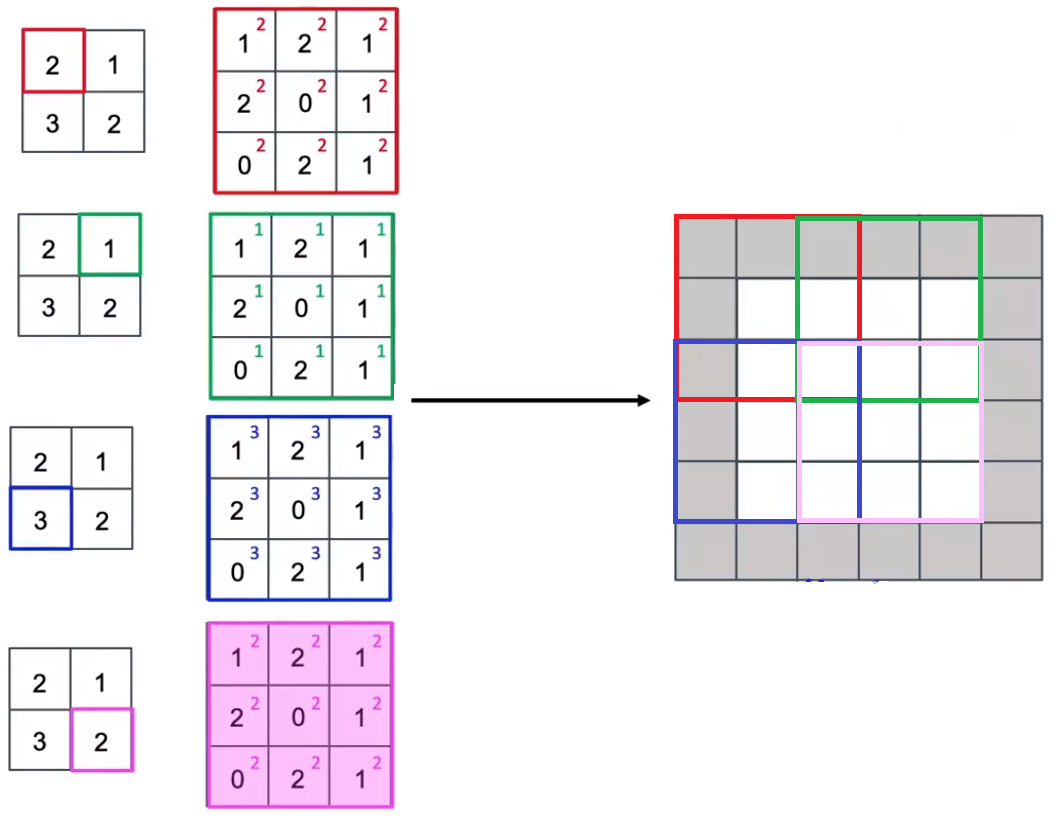
-
从输入的左上数据(也就是2)开始,使用该数据(也就是2)乘以过滤器中的每一个元素
-
使用运算后的过滤器粘贴在输出数据的对应位置(即左上角3x3的红框位置),但要注 意:填充区域不会包括任何数值!
-
再从输入的右上数据(也就是1)开始,做同样的操作(注意要移动过滤器)
-
在粘贴过滤器数据的时候,遇到重叠部分,需要进行数值相加的操作
-
剩下的操作类似
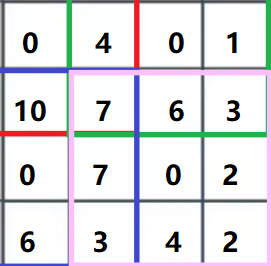
经过反卷积操作后的最终效果:
AlexNet网络结构
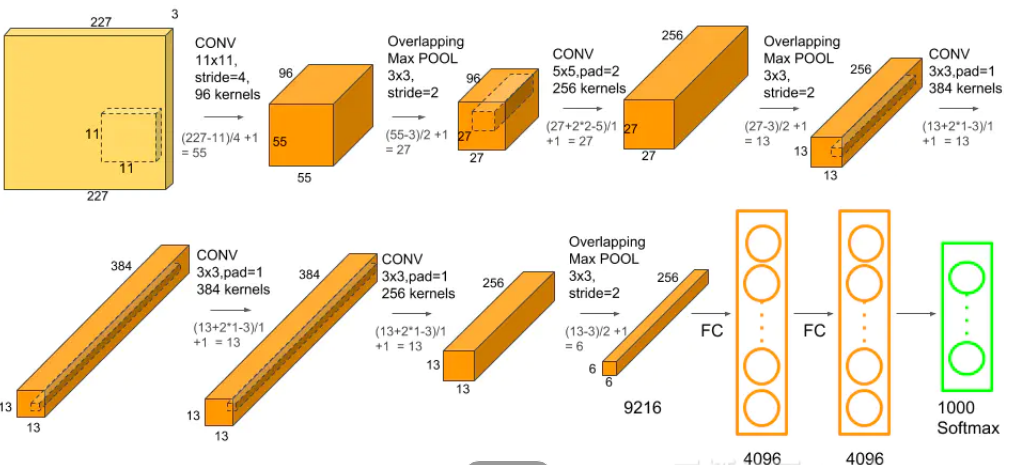
AlexNet介绍
AlexNet是2012年ImageNet竞赛中获得冠军的卷积神经网络模型,其准确率领先第二
名模型10%。由于当时GPU计算速度有限,所以采用了两台GPU服务器进行计算。
AlexNet不算池化层总共有八层,前五层为卷积层,后三层为全连接层。AlexNet的简
略结构如下:输入-卷积-池化-卷积-池化-卷积-卷积-卷积-池化-全连接-全连接-全连接-输出。
VGGNet网络结构
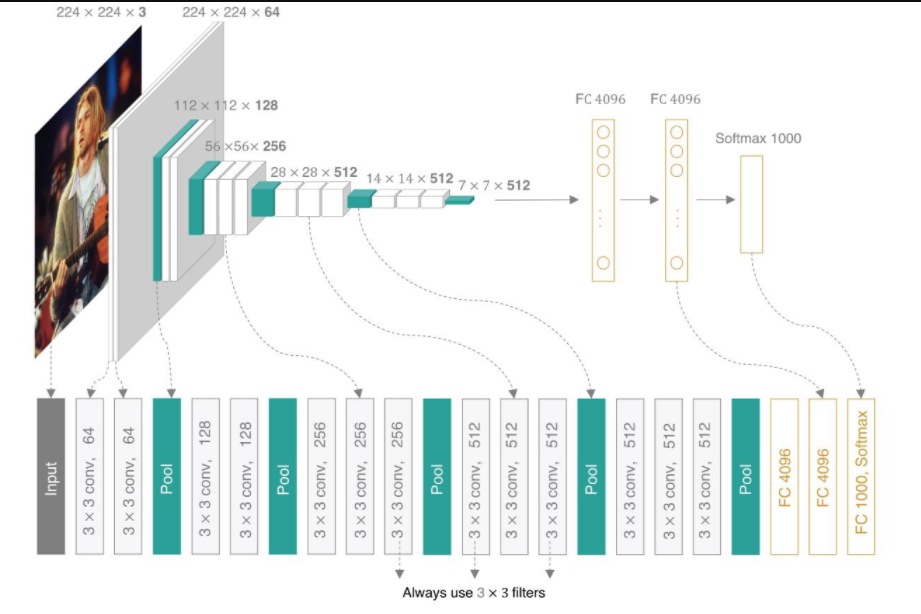
VGGNet介绍
VGGNet探索了卷积神经网络的深度和性能之间的关系,通过多次堆叠3x3的卷积核,使
得网络层数总体变多,达到了16~19层。
VGG的启示
VGGNet采用了多次堆叠3x3的卷积核,这样做的目的是减少参数的数量。
例如,2个3x3的卷积核效果相当于1个5x5的卷积核效果,因为它们的感受野(输入图
像上映射区域的大小)相同。但2个3x3卷积核的参数个数(18个)却比1个5x5(25个)
的卷积核参数个数少。
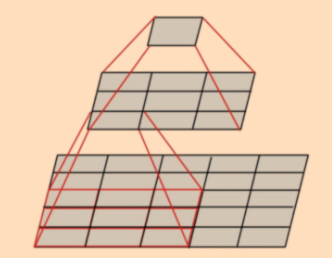
类似地,3个3x3的卷积核相当于1个7x7的卷积核,而1个7x7的卷积核的参数个数为
49,而3个3x3的卷积核的参数个数仅为27。
ResNet网络结构
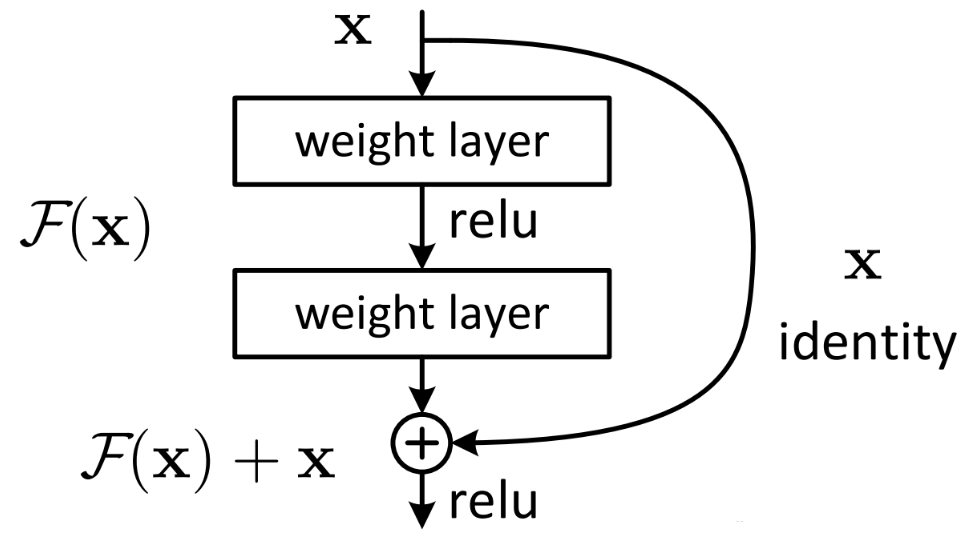
ResNet介绍
- ResNet 即深度残差网络,由何恺明及其团队提出
- ResNet使用了一种连接方式叫做"shortcut connection",顾名思义,shortcut就是"抄
近道"的意思
- ResNet模型引入残差网络结构,在两层或两层以上的节点两端添加了一条"捷径",这
样一来,原来的输出F(x)就变成了F(x)+x
- ResNet通过引入残差结构,我们就可以直接使用传统的反向传播对很深的神经网络进行
训练,并且收敛速度快,误差小
退化
- 网络越深,梯度消失的现象就越来越明显,网络的训练效果也不好,这样的问题就称
为"退化"
- ResNet通过引入残差结构,很好地解决了"退化"问题
- 退化与过拟合都会使网络预测准确率降低,但两者并不是一回事
Cifar10图像分类

Cifar10介绍
- Cifar10介绍网址:https://www.cs.toronto.edu/~kriz/cifar.html
处理思路
- 保存图片
python
import pickle
def unpickle(file):
with open(file, 'rb') as fo:
dict = pickle.load(fo, encoding='bytes')
return dict
# 图片的标签名称(顺序已排好)
label_name = ["airplane",
"automobile",
"bird",
"cat",
"deer",
"dog",
"frog",
"horse",
"ship",
"truck"]
import glob
import numpy as np
# pip install opencv-python -i https://pypi.tuna.tsinghua.edu.cn/simple/
import cv2
import os
def save_image(filenames,save_path):
for l in filenames:
l_dict = unpickle(l) # 每个l_dict包含了10000张图片
for im_idx,im_data in enumerate(l_dict[b'data']):
im_label = l_dict[b'labels'][im_idx] # 标签(0-9)
im_name = l_dict[b'filenames'][im_idx] # 图片名称
im_label_name = label_name[im_label] # 标签名称
im_data = np.reshape(im_data,[3,32,32]) # 整理图片形状
im_data = np.transpose(im_data,(1,2,0)) # opencv中对图片的处理是HWC
if not os.path.exists("{}\\{}".format(save_path,im_label_name)):
os.mkdir("{}\\{}".format(save_path,im_label_name))
# 使用cv2存储图片
cv2.imwrite("{}\\{}\\{}".format(save_path,im_label_name,
im_name.decode("utf-8")),im_data)
if __name__ == '__main__':
# 获取训练集文件名
train_filenames = glob.glob("CIFAR10\\data_batch_*")
train_save_path = "data\\TRAIN"
save_image(train_filenames,train_save_path)
print("训练数据集保存完毕!")
test_filenames = glob.glob("CIFAR10\\test_batch*")
test_save_path = "data\\TEST"
save_image(test_filenames,test_save_path)
print("测试数据集保存完毕!")编写数据集类(继承torch.utils.data.Dataset),加载数据
python
import enum
from torchvision import transforms
from torch.utils.data import DataLoader, Dataset
from PIL import Image
import numpy as np
import glob
# 标签名称
label_name = ["airplane", "automobile", "bird",
"cat", "deer", "dog",
"frog", "horse", "ship", "truck"]
# 训练集数据预处理
train_transform = transforms.Compose([
transforms.RandomHorizontalFlip(), # 随机水平翻转
transforms.RandomVerticalFlip(), # 随机垂直翻转
transforms.ToTensor(), # 将数据转换成张量Tensor对象
# 分别指定三个通道的均值和标准差,进行归一化数据
transforms.Normalize((0.49,0.48,0.44),
(0.21,0.18,0.22))
])
# 测试集数据预处理
test_transform = transforms.Compose([
transforms.CenterCrop((32,32)), # 从中心位置裁剪指定大小的图像
transforms.ToTensor(), # 将数据转换成张量Tensor对象
# 分别指定三个通道的均值和标准差,进行归一化数据
transforms.Normalize((0.49,0.48,0.44),
(0.21,0.18,0.22))
])
label_dict = {}
for idx,name in enumerate(label_name):
label_dict[name] = idx
def default_loader(path):
return Image.open(path).convert("RGB")
# 自定义的Dataset是一个包装类,用来将数据包装为Dataset类,
# 然后传入DataLoader中从而使DataLoader类更加快捷的对数据进行操作
class MyDataset(Dataset):
def __init__(self,im_list,transform=None,loader=default_loader):
super(MyDataset,self).__init__()
imgs = []
for im_item in im_list:
# im_item形如:'data\\TRAIN\\airplane\\xxx.png'
im_label_name = im_item.split("\\")[-2]
# imgs存储的是图片路径和其对应的label
imgs.append([im_item,label_dict[im_label_name]])
self.imgs = imgs
self.transform = transform # 预处理
self.loader = loader # 加载函数
# index参数是一个索引,这个索引的取值范围要根据__len__这个方法的返回值确定
def __getitem__(self, index):
im_path,im_label = self.imgs[index]
im_data = self.loader(im_path)
if self.transform is not None:
im_data = self.transform(im_data) # 图像预处理
return im_data, im_label
def __len__(self):
return len(self.imgs)
# 读取数据集的所有文件名列表
im_train_list = glob.glob("data\\TRAIN\\*\\*.png")
im_test_list = glob.glob("data\\TEST\\*\\*.png")
train_dataset = MyDataset(im_train_list,
transform=train_transform)
test_dataset = MyDataset(im_test_list,
transform=test_transform)
# 训练数据加载器
train_loader = DataLoader(dataset=train_dataset,
batch_size=128,
shuffle=True)
# 测试数据加载器
test_loader = DataLoader(dataset=test_dataset,
batch_size=128,
shuffle=False)
print("训练集数据量:",len(train_dataset))
print("测试集数据量:",len(test_dataset))编写神经网络类
python
import torch.nn as nn
import torch.nn.functional as F
class VGGbase(nn.Module):
def __init__(self):
super(VGGbase, self).__init__()
# 32x32
self.conv1 = nn.Sequential(
# 输入通道数in_channels=3,输出通道数out_channels=64
# conv1卷积的效果保持了输入与输出的尺寸相同(都是32)
nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1),
# 对输入batch的每一个特征通道进行normalize,64表示输出的channel数量
nn.BatchNorm2d(64),
nn.ReLU()
)
# 16 x 16
self.max_pooling1 = nn.MaxPool2d(kernel_size=2, stride=2)
# 16 x 16
self.conv2_1 = nn.Sequential(
nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(128),
nn.ReLU()
)
# 16 x 16
self.conv2_2 = nn.Sequential(
nn.Conv2d(128, 128, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(128),
nn.ReLU()
)
# 8 x 8
self.max_pooling2 = nn.MaxPool2d(kernel_size=2, stride=2)
# 8 x 8
self.conv3_1 = nn.Sequential(
nn.Conv2d(128, 256, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(256),
nn.ReLU()
)
# 8 x 8
self.conv3_2 = nn.Sequential(
nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(256),
nn.ReLU()
)
# 4 x 4
self.max_pooling3 = nn.MaxPool2d(kernel_size=2,
stride=2)
# 4 x 4
self.conv4_1 = nn.Sequential(
nn.Conv2d(256, 512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(512),
nn.ReLU()
)
# 4 x 4
self.conv4_2 = nn.Sequential(
nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(512),
nn.ReLU()
)
# 2 x 2
self.max_pooling4 = nn.MaxPool2d(kernel_size=2,
stride=2)
# batchsize * 512 * 2 *2 --> batchsize * (512 * 4)
self.fc = nn.Linear(512 * 4, 10)
def forward(self, x):
batchsize = x.size(0)
out = self.conv1(x)
out = self.max_pooling1(out)
out = self.conv2_1(out)
out = self.conv2_2(out)
out = self.max_pooling2(out)
#
out = self.conv3_1(out)
out = self.conv3_2(out)
out = self.max_pooling3(out)
out = self.conv4_1(out)
out = self.conv4_2(out)
out = self.max_pooling4(out)
# batchsize * c * h * w --> batchsize * n
out = out.view(batchsize, -1)
out = self.fc(out)
# dim=1是对行做归一化
out = F.log_softmax(out, dim=1)
return out
def VGGNet():
return VGGbase()训练
python
import torch
import torch.nn as nn
from vggnet import VGGNet
from load_cifar10 import train_loader
import os
# 防止核崩溃的设置
os.environ['KMP_DUPLICATE_LIB_OK'] = 'True'
epoch_num = 200 # 训练轮数
lr = 0.01 # 学习率
batch_size = 128 # 每批的训练样本数
net = VGGNet()
#loss
loss_func = nn.CrossEntropyLoss()
#optimizer
optimizer = torch.optim.Adam(net.parameters(), lr= lr)
# optimizer = torch.optim.SGD(net.parameters(), lr = lr,
# momentum=0.9, weight_decay=5e-4)
# step_size:每多少轮循环后更新一次学习率(lr)
# gamma:每次更新lr的gamma倍
scheduler = torch.optim.lr_scheduler.StepLR(optimizer,
step_size=5,
gamma=0.9)
step_n = 0
for epoch in range(epoch_num): # 外层循环"轮"
print(" epoch is ", epoch)
net.train() # 设置模型为训练模型
for i, data in enumerate(train_loader): # 内层循环加载每一批数据
inputs, labels = data
outputs = net(inputs) # 前向传播
loss = loss_func(outputs, labels)
optimizer.zero_grad() # 清空梯度
loss.backward() # 反向传播,计算梯度
optimizer.step() # 更新参数
_,pred = torch.max(outputs.data,dim=1)
correct = pred.eq(labels.data).cpu().sum()
print("step",i,"loss is:",loss.item(),
"mini-batch correct is:",100.0 * correct / batch_size)
if not os.path.exists("models"):
os.mkdir("models")
torch.save(net.state_dict(),"models/{}.pth".format(epoch+1))
scheduler.step() # 更新学习率
print("lr is ",optimizer.state_dict()["param_groups"][0]["lr"]) 迁移学习
引入迁移学习的背景
人类在生活中会不断利用事先拥有的知识去学习新知识。比如,在学习骑摩托车时,
在不知不觉中就利用了之前骑自行车的背景知识。
例如,在构建图像识别应用的过程中,很少有人重新训练一个卷积神经网络。我们
完全可以使用一个已经成熟的卷积网络结构,使用该网络进行初始化或作为其他图片识别任
务的固定特征抽取器。
认识迁移学习
迁移学习是指将在某个任务中训练得到的模型进行微调后迁移到另一个相似的任务
中。
例如,想做一个小猫识别系统,但是只拥有少量的"小猫数据"和大量的"小狗数据",通
常,可以先利用大量的小狗图片训练出卷积神经网络,由于猫和狗非常相似,所以只要拿少
量的小猫图片对该卷积神经网络进行微调,就可以得到一个很好的小猫识别系统。
提示:
两个识别任务越相似,两者的高级特征(在晚期的卷积层提取)就越相似。
实战_AlexNet迁移学习的图片识别

项目实战
- 数据预处理设置
python
import torch
import torchvision
from torchvision import datasets,transforms
import matplotlib.pyplot as plt
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'True'
# 预处理设置
data_transforms = {
"train":transforms.Compose([
transforms.Resize(230), # 自适应缩小到最大边长为230的大小
transforms.CenterCrop(224), # 居中裁切,此处的224是为了适应后面的alexnet网络
transforms.RandomHorizontalFlip(), # 随机水平翻转
transforms.ToTensor(),
transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5]) # 归一化
]),
"test":transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5]) # 归一化
])
}数据加载
python
data_directory = "data"
trainset = datasets.ImageFolder(os.path.join(data_directory,"train"),
data_transforms["train"])
testset = datasets.ImageFolder(os.path.join(data_directory,"test"),
data_transforms["test"])
trainloader = torch.utils.data.DataLoader(trainset,batch_size=5,
shuffle=True)
testloader = torch.utils.data.DataLoader(testset,batch_size=5,
shuffle=True)- 随机展示样本
python
# 随机展示训练样本
def imshow(inputs):
inputs = inputs / 2 + 0.5
inputs = inputs.numpy().transpose((1,2,0))
plt.imshow(inputs)
plt.show()
inputs,classes = next(iter(trainloader))
print("classes=",classes)
imshow(torchvision.utils.make_grid(inputs))- 模型迁移
python
from torchvision import models
alexnet = models.alexnet(pretrained=True)
print(alexnet)
import torch.nn as nn
for param in alexnet.parameters():
param.requires_grad = False # 限制参数更新
alexnet.classifier = nn.Sequential(
nn.Dropout(p=0.5, inplace=False),
nn.Linear(in_features=9216, out_features=4096, bias=True),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5, inplace=False),
nn.Linear(in_features=4096, out_features=4096, bias=True),
nn.ReLU(inplace=True),
# 此处将out_features参数改为了2
nn.Linear(in_features=4096, out_features=2, bias=True)
)
CUDA = torch.cuda.is_available()
if CUDA:
alexnet = alexnet.cuda()
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(alexnet.classifier.parameters(),lr=0.001)- 训练函数
python
def train(model,criterion,optimizer,epochs=1):
for epoch in range(epochs):
running_loss = 0.0
for i,data in enumerate(trainloader):
inputs,labels = data
if CUDA:
inputs,labels = inputs.cuda(),labels.cuda()
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs,labels)
loss.backward()
optimizer.step() # 更新参数
running_loss += loss.item()
if i % 10 == 9:
print("[Epoch:%d,Batch:%5d] loss: %.3f"%(epoch+1,i+1,running_loss / 100))
running_loss = 0.0
print("Finished Training")- 测试函数
python
def test(testloader,model):
correct = 0
total = 0
for data in testloader:
images,labels = data
if CUDA:
images = images.cuda()
labels = labels.cuda()
outputs = model(images)
_,predicted = torch.max(outputs.data,1)
total += labels.size(0)
correct += (predicted == labels).sum()
print("Accuracy on the test set:%d %%"%(100*correct / total))- 模型的加载与保存、调用执行
python
def load_param(model,path):
if os.path.exists(path):
model.load_state_dict(torch.load(path))
def save_param(model,path):
torch.save(model.state_dict(),path)
if __name__ == "__main__":
load_param(alexnet,"tl_model.pkl")
train(alexnet,criterion,optimizer,epochs=2)
save_param(alexnet,"tl_model.pkl")
test(testloader,alexnet)GAN的基本概念
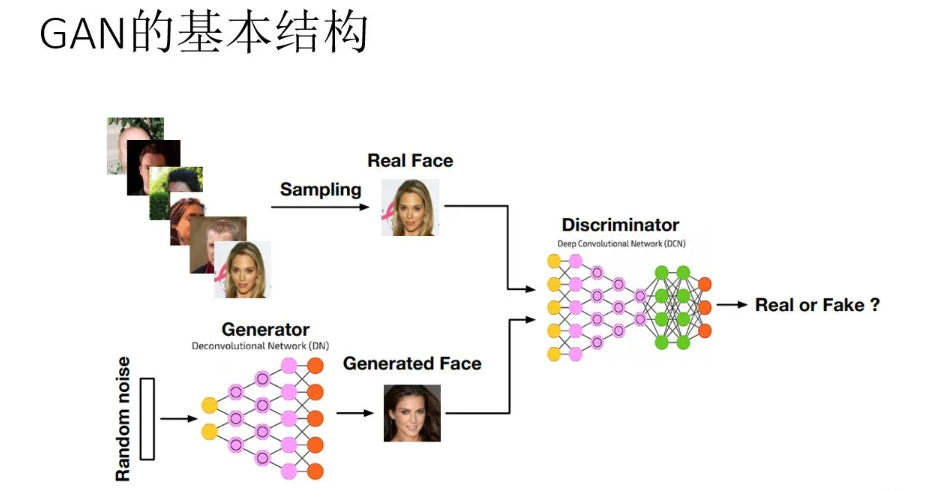
生成对抗网络(Generative Adversarial Network,简称GAN)是近年来比较热门的技
术,几乎每周都会有相关的新论文发表。LeCun将GAN称为"有史以来最酷的事物"。
GAN的基本概念
- 生成:GAN的目的就是生成一些有趣的、接近真实的东西,比如让机器自己产生一幅画
一段文字,或者让机器根据输入条件生成一些东西。
- 生成器(generator):它是一个神经网络或者可以看成是一个函数。只要向生成器中
输入一个向量,就可以输出一些东西。
- 对抗:对生成器生成的内容进行鉴别,通过不断提高鉴别的准确率,促使生成器生成更
逼真的内容。
- 鉴别器(discriminator):也是一个神经网络或者可以看成是一个函数。例如,将图片
输入鉴别器后,鉴别器会输出一个0到1的标量,数值越接近1表示图片越真实,越
接近0表示图片越虚假。
GAN的训练过程
GAN训练过程
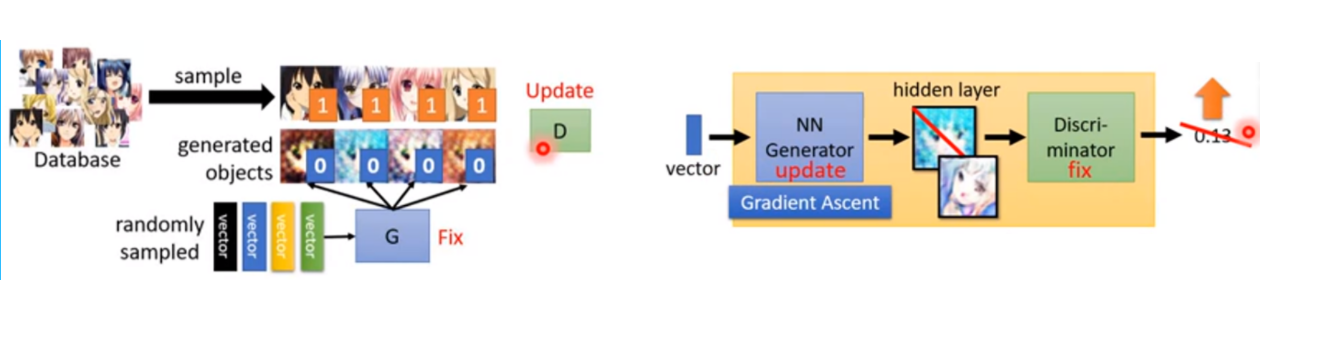
- 初始化生成器和鉴别器的参数
- 在每一个训练迭代中进行下面两个步骤
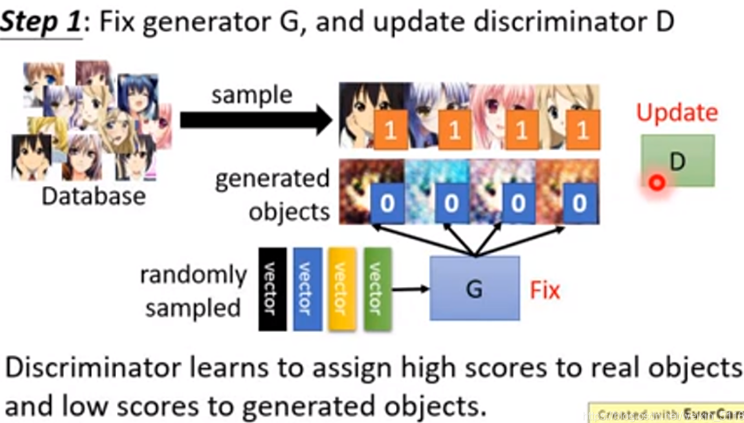
第一步:固定生成器,升级鉴别器
向生成器中输入一些随机向量,会生成一些随机的图片,将生成器生成的图片标注为
0,表示假图片。从真实数据样本集中抽取一些图片标注为1,表示真实的图。此时的鉴别
器就相当于一个二元分类模型,通过训练,鉴别器可以成功分辨出哪些图片是生成器生成的
假图,哪些是真实的图。
第二步:固定鉴别器,升级生成器
将生成器和鉴别器连成一个网络,由生成器产生图片并传入鉴别器中,鉴别器判断
图片是否真实进行打分,越真实得到的分数越接近1。此过程中,固定了鉴别器中的参数,
只更新生成器的参数,使得生成器产生的图片得到的分数越来越高。
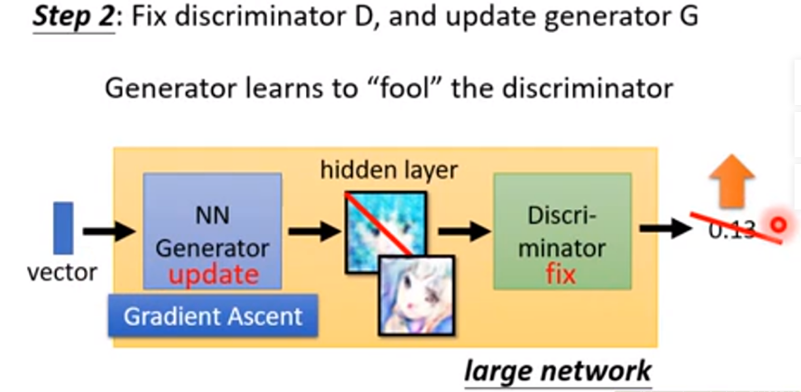
实战_使用GAN生成二次元头像

项目实战
- 数据预处理与加载数据集
python
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import matplotlib.pyplot as plt
import os
from torchvision import datasets,transforms,models
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
# 设置预处理方式
data_transform = transforms.Compose([
transforms.RandomHorizontalFlip(), # 对训练样本进行随机水平翻转
transforms.ToTensor(), # 转化成Tensor
transforms.Normalize((0.5,),(0.5,)) # 对每个通道按照指定均值和标准差进行归一化
])
# 加载数据集("井")
trainset = datasets.ImageFolder(root="faces",transform=data_transform)
# 数据加载器("桶")
trainloader = torch.utils.data.DataLoader(trainset,batch_size=5,
shuffle=True)- 图片的保存、显示
python
# 图片保存、显示
def imshow(inputs,picname):
inputs = inputs / 2 + 0.5
inputs = inputs.numpy().transpose((1, 2, 0))
plt.imshow(inputs)
plt.savefig(os.path.join('faces', '0',picname+".jpg")) # 保存图片
plt.show()
plt.pause(0.01)
inputs,__ = next(iter(trainloader))
imshow(torchvision.utils.make_grid(inputs),"RealDataSample")- 鉴别器定义
python
# 定义鉴别器
class D(nn.Module):
def __init__(self,nc,ndf):
super(D,self).__init__()
self.layer1 = nn.Sequential(nn.Conv2d(in_channels=nc,out_channels=ndf,
kernel_size=4,stride=2,padding=1),
nn.BatchNorm2d(num_features=ndf), # 按每一个channle来做归一化
nn.LeakyReLU(0.2,inplace=True))
self.layer2 = nn.Sequential(nn.Conv2d(in_channels=ndf,out_channels=ndf*2,
kernel_size=4,stride=2,padding=1),
nn.BatchNorm2d(num_features=ndf*2), # 按每一个channle来做归一化
nn.LeakyReLU(0.2,inplace=True))
self.layer3 = nn.Sequential(nn.Conv2d(in_channels=ndf*2,out_channels=ndf*4,
kernel_size=4,stride=2,padding=1),
nn.BatchNorm2d(num_features=ndf*4), # 按每一个channle来做归一化
nn.LeakyReLU(0.2,inplace=True))
self.layer4 = nn.Sequential(nn.Conv2d(in_channels=ndf*4,out_channels=ndf*8,
kernel_size=4,stride=2,padding=1),
nn.BatchNorm2d(num_features=ndf*8), # 按每一个channle来做归一化
nn.LeakyReLU(0.2,inplace=True))
self.fc = nn.Sequential(nn.Linear(256*6*6,1),nn.Sigmoid())
def forward(self,x):
temp1 = self.layer1(x)
temp2 = self.layer2(temp1)
temp3 = self.layer3(temp2)
temp4 = self.layer4(temp3)
temp5 = temp4.view(-1,256*6*6)
out = self.fc(temp5).reshape(-1)
return out - 生成器定义
python
# 定义生成器
class G(nn.Module):
def __init__(self,nc,ngf,nz,feature_size):
super(G,self).__init__()
self.prj = nn.Linear(in_features=feature_size,out_features=nz*6*6)
self.layer1 = nn.Sequential(nn.ConvTranspose2d(in_channels=nz,
out_channels=ngf*4,
kernel_size=4,stride=2,
padding=1),
nn.BatchNorm2d(num_features=ngf*4),
nn.ReLU())
self.layer2 = nn.Sequential(nn.ConvTranspose2d(in_channels=ngf*4,
out_channels=ngf*2,
kernel_size=4,stride=2,
padding=1),
nn.BatchNorm2d(num_features=ngf*2),
nn.ReLU())
self.layer3 = nn.Sequential(nn.ConvTranspose2d(in_channels=ngf*2,
out_channels=ngf,
kernel_size=4,stride=2,
padding=1),
nn.BatchNorm2d(num_features=ngf),
nn.ReLU())
self.layer4 = nn.Sequential(nn.ConvTranspose2d(in_channels=ngf,
out_channels=nc,
kernel_size=4,stride=2,
padding=1),
nn.BatchNorm2d(num_features=nc),
nn.Tanh())
def forward(self,x):
temp1 = self.prj(x) # x.size() = (5,100)
#print("temp1.size()=",temp1.size()) # (5,1024*6*6)
temp2 = temp1.view(-1,1024,6,6)
#print("temp2.size()=",temp2.size()) # (5,1024,6,6)
temp3 = self.layer1(temp2)
#print("temp3.size()=",temp3.size()) # (5,512,12,12)
temp4 = self.layer2(temp3)
temp5 = self.layer3(temp4)
out = self.layer4(temp5)
return out- 训练函数
python
d = D(3,32) # 创建鉴别器对象
g = G(3,128,1024,100) # 创建生成器对象
criterion = nn.BCELoss() # 二分类交叉熵损失函数
d_optimizer = torch.optim.Adam(d.parameters(),lr=0.0003) # 鉴别器的优化器对象
g_optimizer = torch.optim.Adam(g.parameters(),lr=0.0003) # 生成器的优化器对象
# 训练函数
def train(d,g,criterion,d_optimizer,g_optimizer,
epochs=1,show_every=100,print_every=10):
iter_count = 0
for epoch in range(epochs): # 外层循环"轮"
for inputs,_ in trainloader: # 每批抽5张图
real_inputs = inputs # 真图样本的特征
fake_inputs = g(torch.randn(5,100)) # 生成器生成假图
real_labels = torch.ones(real_inputs.size(0)) # 真图标签记为1
fake_labels = torch.zeros(fake_inputs.size(0)) # 假图标记为0
real_outputs = d(real_inputs) # 使用鉴别器对真图进行鉴别,每张图鉴别结果为0-1之间的数
d_loss_real = criterion(real_outputs,real_labels) # 鉴别器对真图的损失值
real_scores = real_outputs
fake_outputs = d(fake_inputs) # 使用鉴别器对假图进行鉴别,每张图鉴别结果为0-1之间的数
d_loss_fake = criterion(fake_outputs,fake_labels) # 鉴别器对假图的损失值
fake_scores = fake_outputs
d_loss = d_loss_real + d_loss_fake # 鉴别器的总的损失值
d_optimizer.zero_grad() # 清空上一次的梯度
d_loss.backward() # 反向传播,计算梯度
d_optimizer.step() # 更新鉴别器参数
fake_inputs = g(torch.randn(5,100)) # 生成器生成假图
fake_outputs = d(fake_inputs)
g_loss = criterion(fake_outputs,real_labels)
g_optimizer.zero_grad() # 清空上一次的梯度
g_loss.backward() # 反向传播,计算梯度
g_optimizer.step() # 更新生成器参数
if (iter_count % show_every == 0):
print('Epoch:{},Iter: {}, D: {:.4}, G:{:.4}'.format(epoch,iter_count, d_loss.item(), g_loss.item()))
picname = "Epoch_"+str(epoch)+"Iter_"+str(iter_count)
imshow(torchvision.utils.make_grid(fake_inputs.data),picname)
if (iter_count%print_every == 0):
print('Epoch:{},Iter: {}, D: {:.4}, G:{:.4}'.format(epoch,iter_count, d_loss.item(), g_loss.item()))
iter_count += 1
print("Finish Training,OK!")
train(d,g,criterion,d_optimizer,g_optimizer,epochs=1)TorchGAN框架生成二次元头像

TorchGAN介绍
TorchGAN是基于PyTorch开发的GAN设计框架,它可以快速开发和定制GAN
安装方式:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple torchgan==0.1.0
TorchGAN生成图片
python
import os
import matplotlib.pyplot as plt
import numpy as np
# Pytorch and Torchvision Imports
import torch
import torch.nn as nn
import torchvision
from torch.optim import Adam
import torch.nn as nn
import torch.utils.data as data
import torchvision.datasets as dsets
import torchvision.transforms as transforms
import torchvision.utils as vutils
# Torchgan Imports
import torchgan
from torchgan.models import *
from torchgan.losses import *
from torchgan.trainer import Trainer
# 防止核崩溃
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
# 数据预处理
data_transform = transforms.Compose([
transforms.Resize((32, 32)),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
])
# 加载数据
trainset = dsets.ImageFolder('faces', data_transform)
dataloader = torch.utils.data.DataLoader(trainset, batch_size=64,shuffle=True)
# Plot some of the training images
real_batch = next(iter(dataloader))
plt.figure(figsize=(8,8))
plt.axis("off")
plt.title("Training Images")
plt.imshow(np.transpose(vutils.make_grid(real_batch[0][:64], padding=2, normalize=True).cpu(),(1,2,0)))
plt.show()
# 定义GAN网络
dcgan_network = {
# 定义生成器
"generator": {
"name": DCGANGenerator, # 深度卷积生成器
# DCGANGenerator的参数设置
"args": {
"encoding_dims": 100,
"out_channels": 3,
"step_channels": 32,
"nonlinearity": nn.LeakyReLU(0.2),
"last_nonlinearity": nn.Tanh()
},
"optimizer": {
"name": Adam,
"args": {
"lr": 0.0001,
"betas": (0.5, 0.999)
}
}
},
# 鉴别器
"discriminator": {
"name": DCGANDiscriminator, # 深度卷积鉴别器
"args": {
"in_channels": 3,
"step_channels": 32,
"nonlinearity": nn.LeakyReLU(0.2),
"last_nonlinearity": nn.LeakyReLU(0.2)
},
"optimizer": {
"name": Adam,
"args": {
"lr": 0.0003,
"betas": (0.5, 0.999)
}
}
}
}
# TorchGAN支持的损失函数
wgangp_losses = [WassersteinGeneratorLoss(), WassersteinDiscriminatorLoss(), WassersteinGradientPenalty()]
# 检查设备是否支持CUDA,并设置训练的轮数
if torch.cuda.is_available():
device = torch.device("cuda:0")
# Use deterministic cudnn algorithms
torch.backends.cudnn.deterministic = True
epochs = 400
else:
device = torch.device("cpu")
epochs = 100
print("Device: {}".format(device))
print("Epochs: {}".format(epochs))
# 创建训练器对象
trainer = Trainer(dcgan_network, wgangp_losses, sample_size=64, epochs=epochs, device=device)
# 开始训练,训练后,会在代码根目录下生成一个images文件夹
trainer(dataloader)目标检测概述

什么是目标检测
目标检测(Object Detection)就是要让计算机不仅能够识别出输入图像中的目标物
体,还能够给出目标物体在图像中的位置。
目标检测算法的两大流派
- 两步走(Two-Stage)算法:先产生候选区域,然后再进行CNN分类(RCNN系列)。
- 一步走(One-Stage)算法:直接对输入图像应用算法,并输出类别和相应的定位 (YOLO系列)。
Two-Stage之RCNN算法
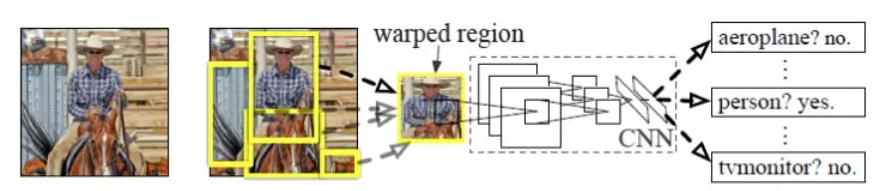
认识RCNN
- RCNN算法以Region(候选区域)开头首字母R加CNN进行命名
- RCNN算法是Two-Stage算法的代表,即先生成候选区域,再利用CNN进行识别分类
- RCNN采用选择性搜索(Selective Search)的方法来预先提取一些可能的候选区域
RCNN的步骤
- 生成较可能是目标物体的候选区域
- 对候选区域利用CNN进行特征提取
- 将提取的特征送入SVM分类器
- 使用回归对目标位置进行修正
RCNN的缺陷
- 采用选择性搜索方法提取候选区域的速度慢
- CNN需要分别对每一个候选区域进行一次特征提取,存在着大量重复运算
Two-Stage之SPPNet算法
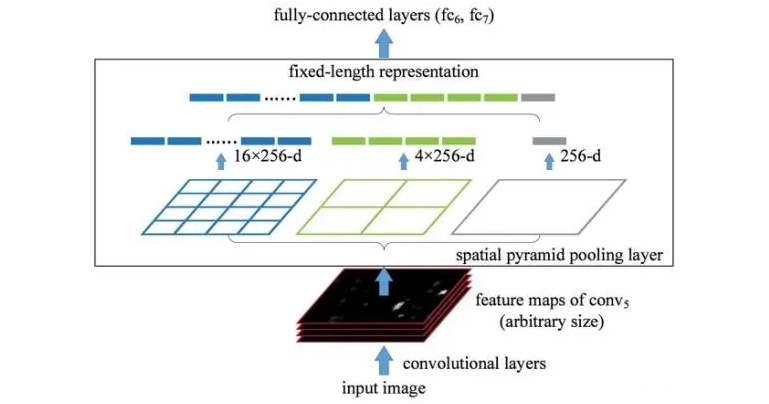
SPPNet出现的原因
在RCNN算法中输入图片的尺寸必须是固定的,这是因为在设计的时候FC层中神经元的
个数都是固定的,导致输入图片尺寸必须是固定的。
在裁剪、缩放成固定尺寸的时候,会对原图造成不同程度的扭曲和拉伸,进而会对提取
到的卷积层的feature map产生精度上的影响,降低图像识别准确率。
SPPNet算法
SPPNet全程是Spatial Pyramid Pooling Convolutional Networks(空间金字塔池化卷
积网络),在CNN后面加入SPP(空间金字塔池化)就可以让FC层也适应不同尺寸的输入
图片。
具体做法是,在卷积层得到的特征图是256层,每层都做一次SPP。先把每个特征图分
割成多个不同尺寸的网格,比如网格分别为4x4、2x2、1x1,然后每个网格做max
pooling,这样256层特征图就形成了16x256,4x256,1x256维特征,它们连起来就形成了一
个固定长度的特征向量,将这个向量输入到后面的全连接层。
SPPNet对RCNN最大的改进就是对特征提取步骤做了修改,特征提取不再需要每个候选
区域都经过CNN,只需要将整张图片输入到CNN就可以,直接从特征图获取有效特征,和
RCNN相比,速度有显著提高。
Two-Stage之Fast RCNN算法
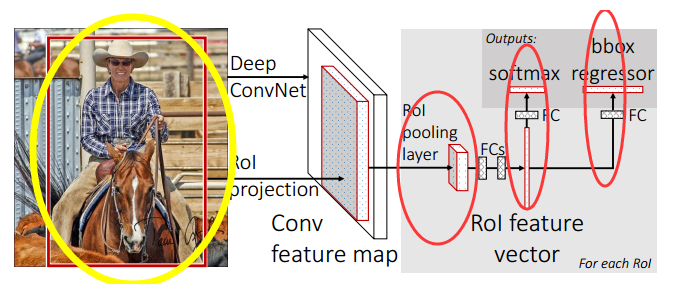
Fast RCNN介绍
Fast RCNN设置了一种兴趣区域(Region of Interest,RoI)池化的池化层结构,有效地
解决了RCNN必须将图像区域剪裁、缩放到相同尺寸大小的操作。
Fast RCNN还提出了多任务损失函数,每一个RoI都有两个输出向量:softmax概率输出
向量和每一类的边界框回归位置向量。
Fast RCNN的不足
对于RCNN的选择性搜索的候选框生成方法依然没做改进
One-Stage之YOLO v1
提示:
YOLO:you only look once,指的是只需要浏览一次就可以识别出图中物体的类别和位置
YOLO v1的核心思想
YOLO v1将输入图像划分为S * S的网格(Grid),每个网格预测两个边界框,如果目标
物体的中心落入相应的网格中,那么该网格就负责检测出该目标物体。
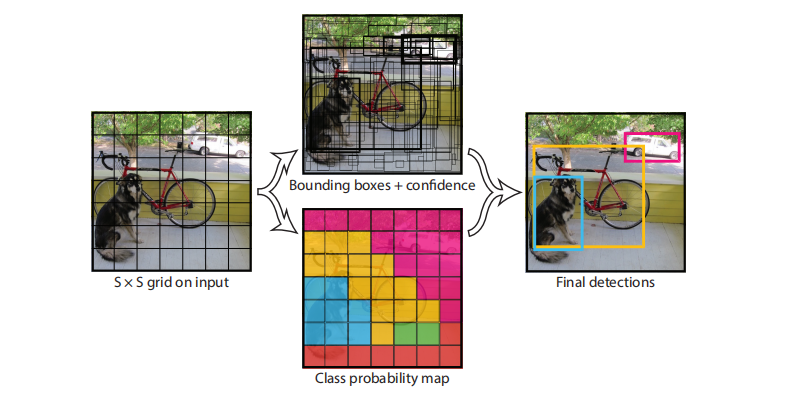
YOLO v1的具体步骤(以本节导图为例)
-
图像划分
1号图中显示图片被分为 7 × 7 = 49个grid cell
2号图中显示每个grid cell生成2个边界框,一共98个边界框
3号图中用不同颜色表示每个grid cell所预测的物体最可能的分类,如蓝色的grid cell
生成的边界框最可能框住的是狗、黄色的grid cell最可能预测自行车...
4号图为最终输出的显示效果
-
边界框预测
每一个网格预测2个边界框,每个边界框有四个坐标和一个置信度(confidence),所以最
终的预测结果是 7 × 7 × (2 ∗ 5 + 类别数量)个向量
第二个class probablity map,这一路的工作其实是和上一步是同时进行的,负责的是
网格(gird cell)类别的分数,预测的结果放在最后的张量中
YOLO v1的不足:
由于一个网格只能预测两个边界框,这使得YOLO v1对密集的小物体的检测效果并不好
One-Stage之YOLO v2
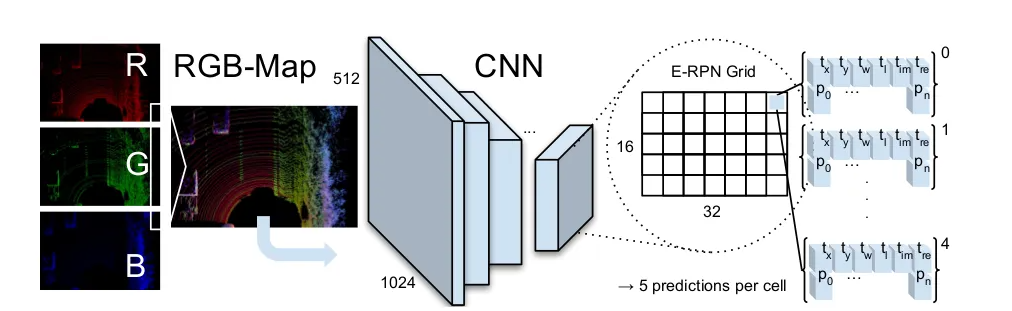
YOLO v2的改进
YOLO v2重点对YOLO v1的定位问题给出了解决方案:使用Darknet-19作为预训练网
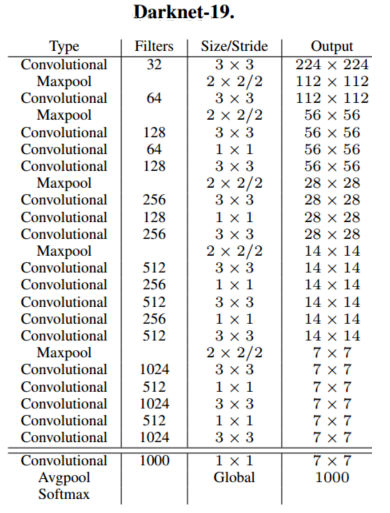
络,增加了BN(Batch Normalization)层,把分类数据集和检测数据集混合到一起。
Darknet-19基础模型:
RNN介绍
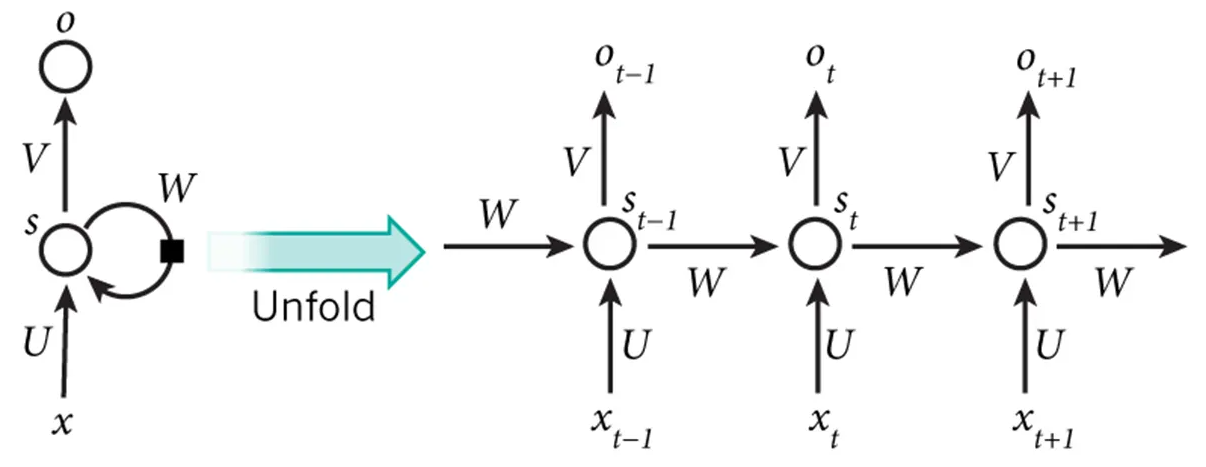
认识RNN
RNN(Recurrent Neural Network),即"循环神经网络",是在基础神经网络模型中增加
了循环机制。具体的表现形式为网络会对前面的信息进行记忆并应用于当前的计算中,即当
前时刻利用了上一时刻的信息,这便是"循环"的含义。
RNN的应用领域
- 语音识别
- OCR识别(optical character recognition)
- 机器翻译
- 文本分类
- 视频动作识别
- 序列标注
常见的RNN模型
LSTM
认识LSTM
LSTM是Long-Short Term Memory的缩写,中文名叫长短期记忆网络,它是RNN的改进
版本。为了更好地解决"梯度爆炸"和"梯度消失"的问题,让RNN具备更强、更好的记忆,于
是就出现了LSTM。
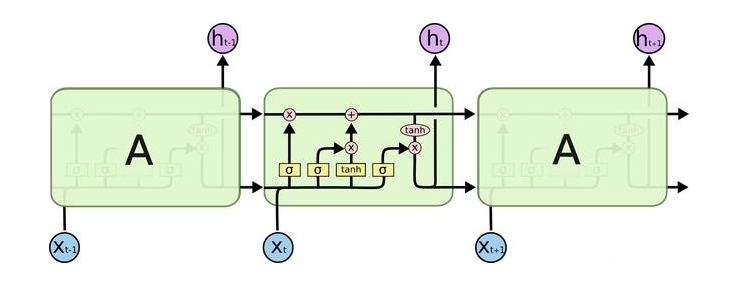
LSTM的"门结构"
LSTM的关键就是记忆细胞(在最上面的贯穿水平线上)。记忆细胞提供了记忆的功
能,使得记忆信息在网络各层之间很容易保持下去。
- 遗忘门(Forget Gate)
遗忘门的作用是控制t-1时刻到t时刻时允许多少信息进入t时刻的门控设备
遗忘门的计算公式如下:
Γtf=σ(wfat−1,xt+bf)
其中,x~t~是当前时刻的输入,a~t-1~是上一时刻隐状态的值
- 输入门(Input Gate)
输入门的作用是确定需要将多少信息存入记忆细胞中。除了计算输入门外,还需要
使用tanh计算记忆细胞的候选值c^'^~t~
Γti=σ(wiat−1,xt+bi)ct′=tanh(wcat−1,xt+bc)
然后,就可以对当前时刻的记忆细胞进行更新了
ct=Γtfct−1+Γtict′
- 输出门(Output Gate)
输出门是用来控制t时刻状态值对外多少是可见的门控设备
输出门与t时刻隐层节点输出值得公式为:
Γto=σ(woat−1,xt+bo)at=Γtotanh(ct)
Seq2Seq模型
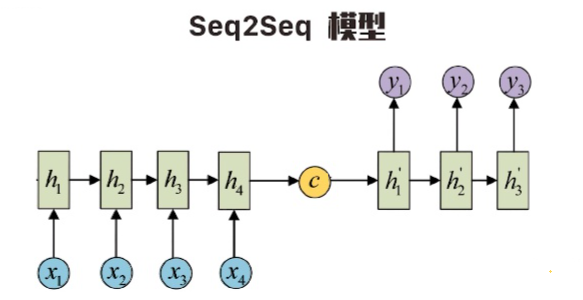
Seq2Seq表现形式
在RNN的结构中,最常见的就是不等长的多对多结构,即输入、输出虽然都是多个,但
是并不相等。这种不等长的多对多结构就是Seq2Seq(序列对序列)模型。
例如,汉译英的机器翻译时,输入的汉语句子和输出的英文句子很多时候并不是等长
的,这时就可以用Seq2Seq模型了。
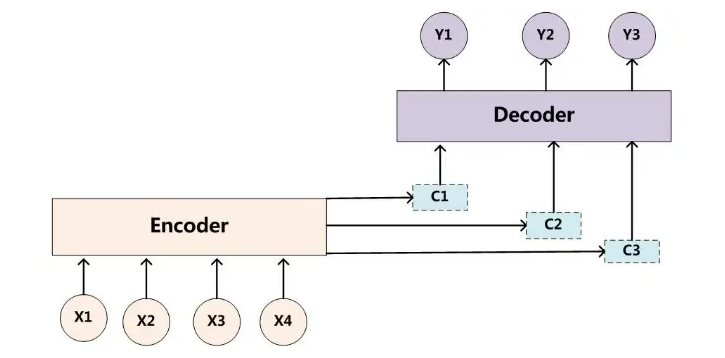
Encoder+Decoder
Seq2Seq由一个编码器(Encoder)和一个解码器(Decoder)构成,编码器先将输入
序列转化为一个上下文向量C(理解序列),然后再用一个解码器将C转化为最终输出(生
成序列)。
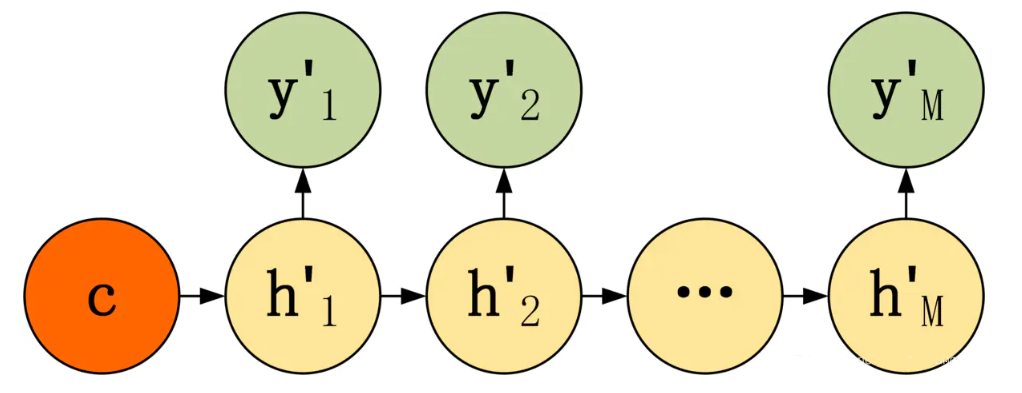
- 编码器(Encoder)
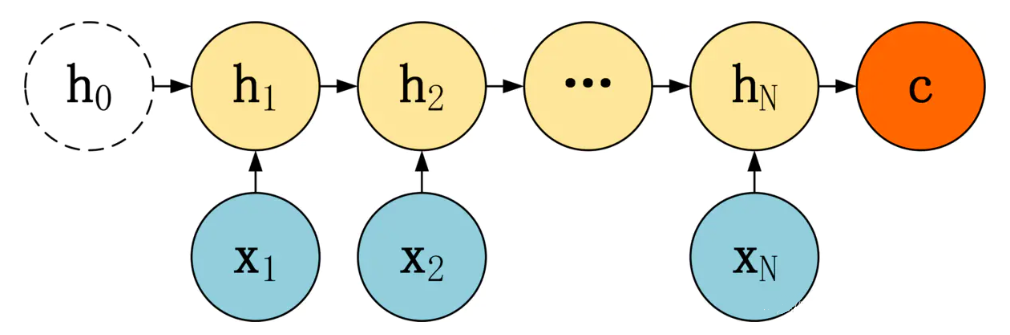
-
解码器(Decoder)
Attention模型
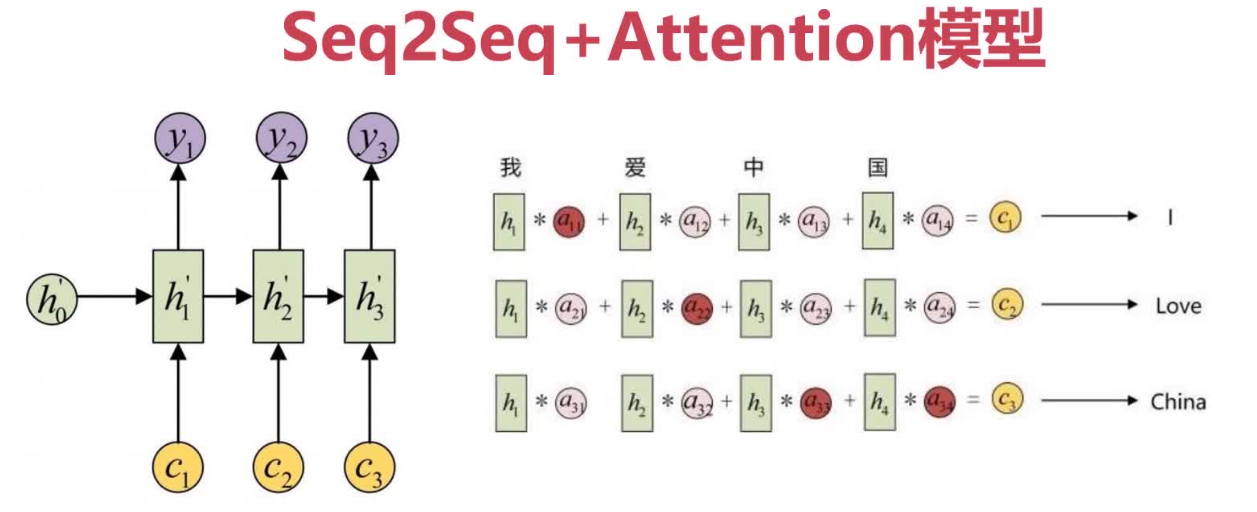
引入Attention模型的必要性
Seq2Seq作为一种通用的编码-解码结构,在编码器将输入编码成上下文向量C后,在
解码时每一个输出Y都会不加区分地使用这个C进行解码,这样并不能有效地聚焦到输入目
标上。
Seq2Seq+Attention模型
Seq2Seq引入Attention模型后,Attention模型(注意力模型)通过描述解码中某一时
间步的状态值和所有编码中状态值的关联程度(即权重),计算出对当前输出更友好的上下
文向量,从而对输入信息进行有选择性的学习。
y1=f(C1)y2=f(C2,y1)y3=f(C3,y1,y2)...
认识NLP

什么是NLP
NLP(Natural Language Processing),即"自然语言处理",主要研究使用计算机来
处理、理解及运用人类语言的各种理论和方法,属于人工智能的一个重要研究方向。
简单来说,NLP就是如何让计算机理解人类语言。
NLP的主要研究方向
NLP是一个庞大的技术体系,研究方向主要包括机器翻译、信息检索、文档分类、问答
系统、自动摘要、文本挖掘、知识图谱、语音识别、语音合成等。
相较于CNN重点应用于计算机视觉领域,RNN则更多地应用于NLP方向。
词汇表征
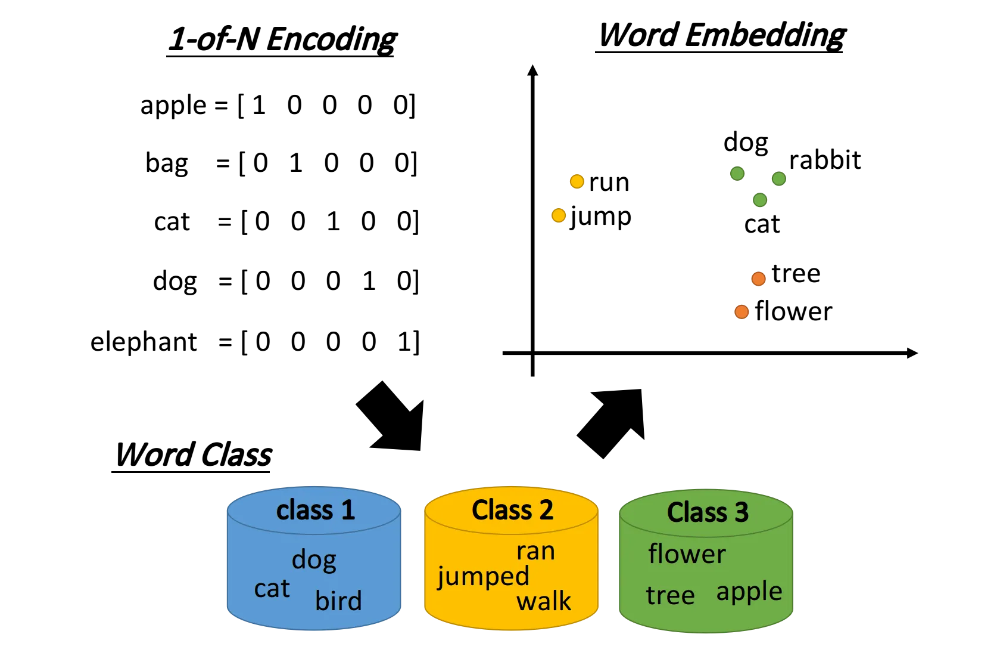
什么是词汇表征
在NLP中,最细粒度的表示就是词语,但是计算机并不能直接识别词语,需要将词语转
化为计算机可识别的数值形式,这种对词语的转化和表征就是"词汇表征"。
词汇表征的种类
- one-hot编码
缺点:维数灾难、不能很好地获取词汇间的相似性
- 词嵌入(Word Embedding)
将词汇表中的每个单词表示为一个合理的普通向量,word2vec是典型的词嵌入技术
word2vec

word2vec介绍
word2vec是一种基于神经网络的词嵌入技术,通过训练神经网络得到一个关于输入X和
输出Y之间的语言模型,获取训练好的神经网络权重,这个权重是用来对输入词汇X进行向
量化表示的。
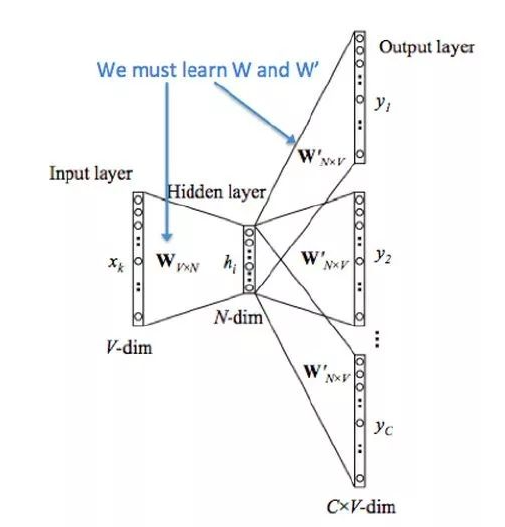
word2vec的两种模型
- CBOW模型
CBOW(Continuous Bag-of-Words Model),即"连续词袋模型",其应用场景是根据
上下文预测中间词,输入X是每个词汇的one-hot向量,输出Y为给定词汇表中每个词作为目
标词的概率。
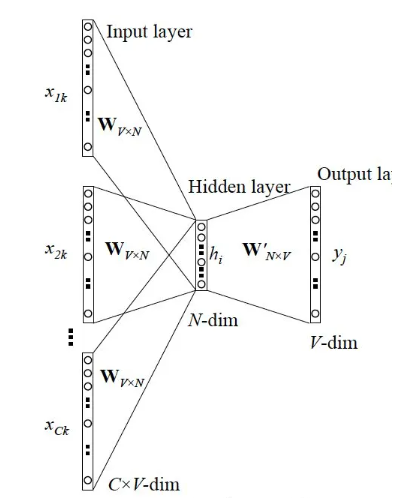
- Skip-gram模型
也称为"跳字模型",应用场景是根据中间词预测上下文词,所以输入X为任意单词,输出
Y为给定词汇表中每个词作为上下文词的概率。