项目介绍:这是一个开箱即用的合同风险检测工具。支持上传 PDF/Word 格式的购销、租赁、服务等合同文件,自动识别主体信息缺失、标的物不明、违约责任不完整等法律风险,并输出结构化审查意见与修改建议,结果可溯源至原文页码。适用于企业法务合规审查、业务合同自查及交易对手风险筛查。
GitHub 项目地址: https://github.com/intsig-textin/xparse-sample-projects
接下来我们将讨论实现方法。
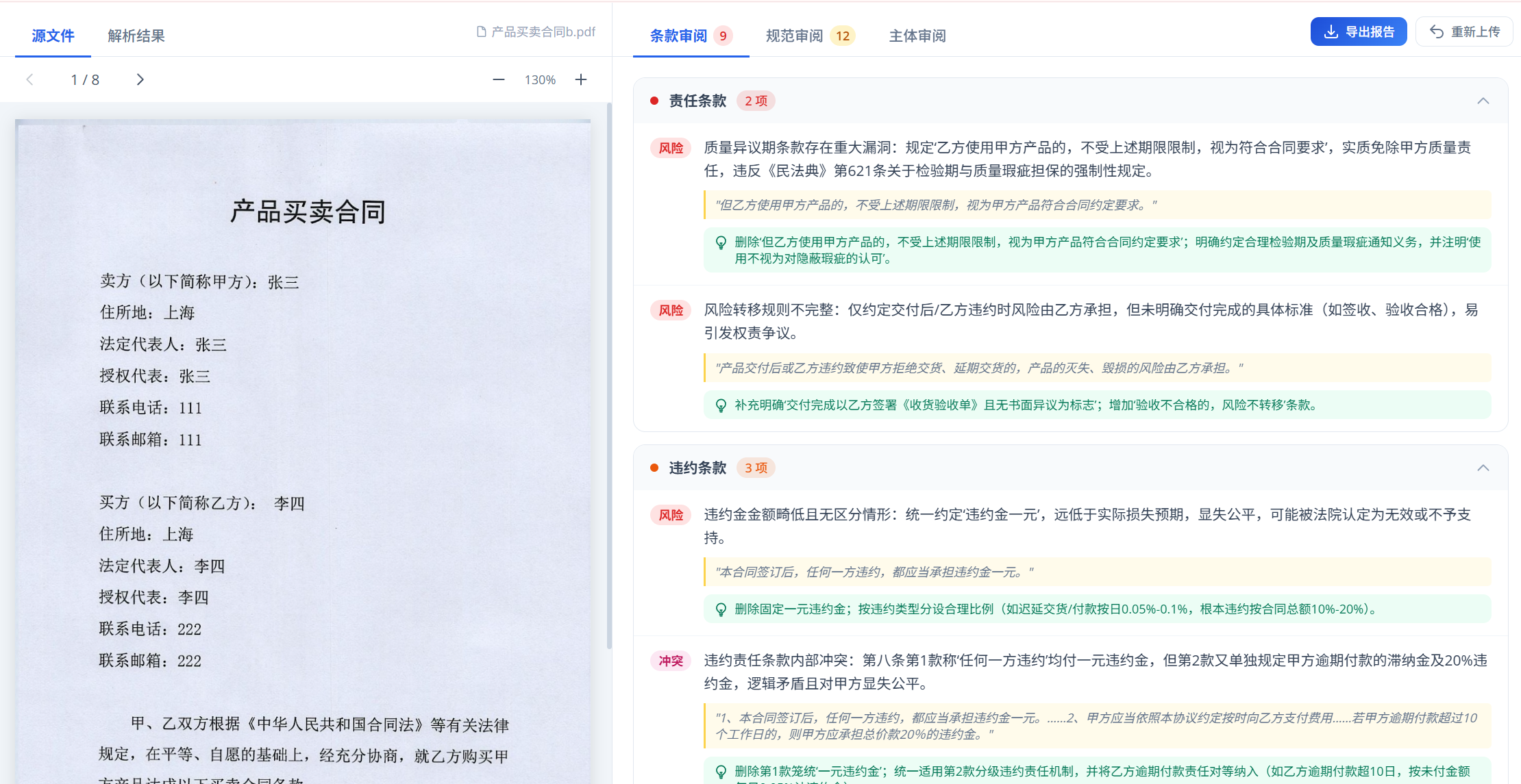
当我们的目标是把扫描件、图片件、带水印合同做成可交付的审查工具,重点不是"让模型看合同",而是先把输入清洗干净,再把不同审查目标拆成不同输出结构。
一、先把目标定义清楚
这类工具真正要解决的是下面几个问题:
- 输入质量不稳定,很多合同是扫描件、拍照件、带水印 PDF
- 同一份合同里既有法律风险问题,也有格式规范问题
- 输出不能只是摘要,还要能生成审查报告
因此更合理的目标不是"总结合同",而是把流程拆成下面这条链路:
- 上传合同文件
- 调用 TextIn 做解析和预处理
- 得到统一中间层
markdown + pages - 并行执行条款风险审阅和规范审阅
- 汇总审阅结果并导出 Word 报告
二、架构应该怎么拆
建议把这类合同审查工具拆成四层:
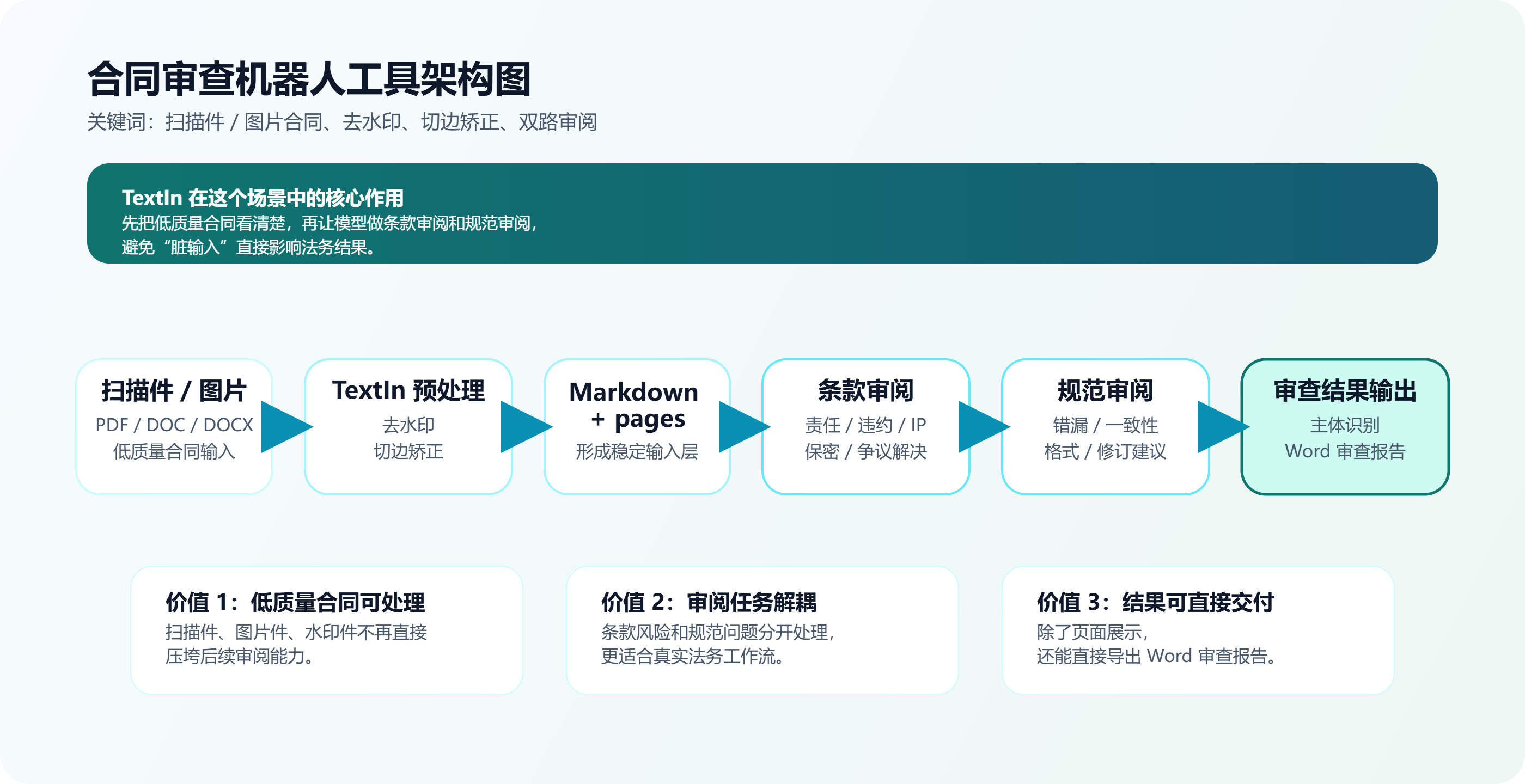
这四层分别解决:
- 解析层:把低质量文档先转成统一文本结构
- 审阅层:把法律语义问题和文本规范问题分开处理
- 汇总层:把两类 JSON 合并成页面可消费结构
- 交付层:导出审查报告,而不是停留在聊天结果
三、先把解析层输入输出定义对
真正调用的仍然是 TextIn 的二进制解析接口,而不是 form-data:
HTTP
POST https://api.textin.com/ai/service/v1/pdf_to_markdown对应代码里的请求方式如下:
Python
headers = {
"x-ti-app-id": TEXTIN_APP_ID,
"x-ti-secret-code": TEXTIN_SECRET_CODE,
"Content-Type": "application/octet-stream",
}
params = {
"parse_mode": "auto",
"page_count": 200,
"dpi": 144,
"table_flavor": "html",
"apply_document_tree": 1,
"markdown_details": 1,
"page_details": 1,
"apply_merge": 1,
"crop_dewarp": 1,
"remove_watermark": 1,
"get_image": "both",
}
resp = await client.post(
"https://api.textin.com/ai/service/v1/pdf_to_markdown",
headers=headers,
params=params,
content=file_bytes,
)这里值得单独解释三个参数:
crop_dewarp=1:用于切边和矫正,适合扫描件、拍照件remove_watermark=1:对带水印合同尤其重要get_image=both:保留页面图像信息,后续做证据页展示更方便
这一层最重要的输出仍然是:
JSON
{
"code": 200,
"result": {
"markdown": "合同正文 markdown",
"pages": []
}
}如果前端要上传文件,通常会在本地后端包一层 /api/parse;但需要记住,真正的解析接口协议仍然是"二进制文件流 + 解析参数"。
四、为什么这里一定要先做统一中间层
合同审查里最常见的误区,是把 OCR 之后的原始文本直接丢给模型,然后希望一次生成所有意见。这样做表面上简单,工程上却不稳。
先统一成 markdown + pages 有三个直接好处:
markdown负责承载正文、标题、条款结构pages负责承载分页信息,后续可以挂页面预览或证据定位- 整个系统后续都面向统一中间层,不再面向原始文件类型
也就是说,PDF、DOC、DOCX、扫描件在进入审阅层之前,都会收敛成同一种输入对象。
五、为什么要拆成两条审阅链路
合同审查至少有两类完全不同的目标:
- 法律语义风险
- 文本规范与一致性问题
如果把这两类问题塞进同一个 Prompt,模型输出很容易混杂,后续展示和报告导出也很难稳定。更合理的做法是:同一份 markdown,两份不同 Prompt,两棵不同 JSON 树。
前端编排层的核心就是并行调用:
JavaScript
callLLM(CLAUSE_PROMPT, markdown)
callLLM(NORM_PROMPT, markdown)这一步的重点不是"并发"本身,而是把两个不同目标明确拆开。
六、Prompt 应该怎么写,为什么这么写
1. 条款风险审阅 Prompt
条款风险审阅的 Prompt 先把审查范围写死:
Plain
重点审查以下5类风险点:
1. 责任条款
2. 违约条款
3. 知识产权
4. 保密条款
5. 争议解决接着把每条问题的输出字段写死:
Plain
- issue_type: 必须是 "风险"、"缺失"、"冲突"、"建议" 之一
- description: 问题的详细描述,不超过100字
- value: 从合同中精确引用的相关原文片段
- suggestion: 具体的修改或补充建议最终输出结构固定为:
JSON
{
"clause_review": {
"责任条款": [{"issue_type":"","description":"","value":"","suggestion":""}],
"违约条款": [],
"知识产权": [],
"保密条款": [],
"争议解决": []
},
"parties": {
"party_a": {"name":"","role":"甲方"},
"party_b": {"name":"","role":"乙方"}
}
}为什么要把 parties 也放在这一条链路里?因为条款风险判断天然依赖主体关系,很多责任边界和义务归属都离不开甲乙方身份。
2. 规范审阅 Prompt
规范审阅的目标完全不同,所以 Prompt 也必须单独定义:
Plain
检查以下4类规范性问题:
1. 错漏
2. 一致性
3. 格式
4. 修订对应输出结构也固定为:
JSON
{
"norm_review": {
"错漏": [{"description":"","value":"","suggestion":"","severity":""}],
"一致性": [],
"格式": [],
"修订": []
}
}这里多出来的 severity 很重要,因为规范问题后续往往需要分优先级展示和导出。
七、输入、Prompt、输出是怎么一一对应的
把这类工具做稳,至少要先对齐下面三件事:
1. 输入层
两条审阅链路共用同一份合同 markdown。这意味着解析层只做一次,后续所有审阅都面向同一个中间层。
2. Prompt 层
- 条款风险审阅 Prompt 定义
clause_review + parties - 规范审阅 Prompt 定义
norm_review
也就是说,Prompt 不是为了"多说几句提示",而是为了把返回 JSON 的形状提前定下来。
3. 输出层
页面展示和 Word 报告导出都依赖这两棵固定 JSON 树:
clause_review适合按风险类别分组展示norm_review适合按严重程度和问题类型展示parties则可以直接进入报告首页或摘要部分
只有输入和输出先对齐,导出层才不会再做一轮混乱的二次解析。
八、和传统做法相比,差别在哪里
1. 不是 OCR 后直接全文摘要
全文摘要很容易把法律风险、格式问题、修订建议全部混在一起,后续既不方便统计,也不方便导出。
2. 不是只靠规则审查
规则很适合检查编号、日期、金额一致性,但对责任边界、违约责任、知识产权、争议解决这些语义问题不够。
更合理的边界是:
- 低质量输入问题交给解析层处理
- 语义风险交给条款风险 Prompt
- 规范性问题交给规范审阅 Prompt
以上是一种"先解析清洗、再双链路审阅"的合同审查实践方案。核心思路是把低质量合同(扫描件、拍照件、水印 PDF)先通过 TextIn 统一成干净的 markdown + pages 中间层,再将法律语义风险与文本规范问题拆成两条独立的审阅链路,分别输出固定 JSON,最终合并生成结构化审查报告。方案已发布在 GitHub,欢迎大家在项目中与我们交流。如果你在实际处理合同时遇到更复杂的场景(如手写体干扰、印章遮挡、多版本修订痕迹等),或者有不同的架构思路,欢迎留言或私信探讨。