腾讯 Ima 知识库架构解读
腾讯AI智能工作台Ima 是腾讯推出的智能办公产品,依托 混元大模型 与 RAG架构 打造知识管理体系,支持Windows/Mac双平台,提供AI问答 、多模态文本创作、图像生成等核心功能。其核心能力覆盖多格式文档智能整合管理、大模型驱动的精准问答交互、动态知识图谱构建与更新,以及跨部门知识协同共享等场景。
最近刚好有机会深入了解下 ima 的实现过程,由于 腾讯Ima 未开源,我们可通过研究其旗下另一款开源同构产品 WeKnora 间接推测其架构。二者同属腾讯知识管理类产品,定位虽有差异,但共享核心技术理念。
WeKnora 的主力开发语言为Go,项目启动前需在本地完成 Ollama 与 Docker 的安装配置:其中Ollama用于部署所需大模型,Docker则负责部署数据库等相关镜像组件。
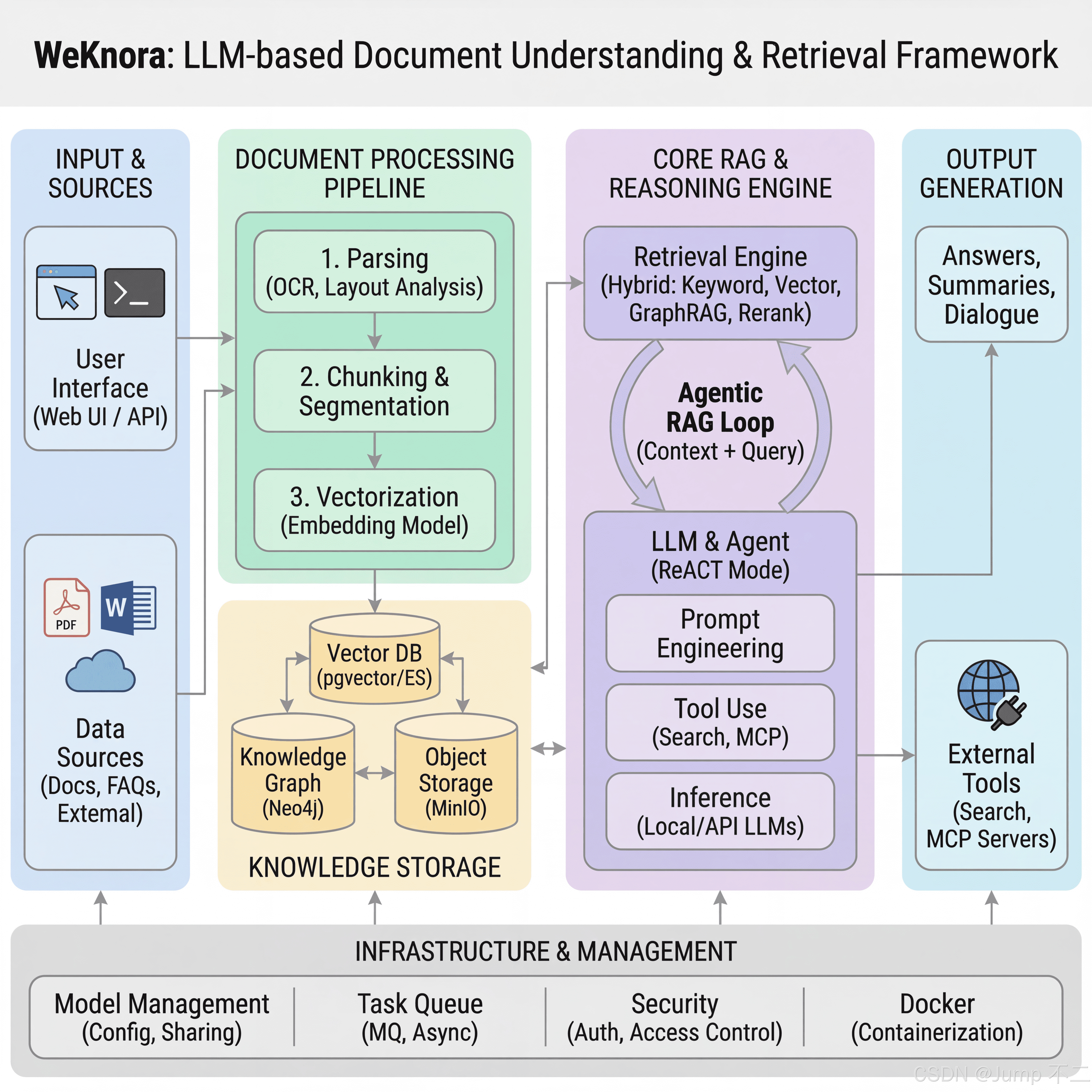
从架构图可见,WeKnora 核心分为两大模块:左侧绿色模块聚焦用户文档的上传与解析,同步完成知识库 与向量库 的构建。右侧紫色模块聚焦 问答交互------即基于用户问题检索知识库,整合信息后生成精准回答。
一、文件上传:多格式解析与知识库构建
首先我们来看看文件上传后的处理逻辑。从代码层面可知,WeKnora 支持多种格式文件上传,涵盖PDF、TXT、MD、DOCX、DOC、JPG、PNG、CSV、XLSX及XLS等11类格式。

按文件属性可将其归为三大类:第一类是 文本类文件 (含可直接解析为文本的格式),包括TXT、MD(Markdown)、DOC/DOCX(Word)、CSV/XLSX/XLS(表格)及纯文本PDF;第二类是无法直接解析为文本的 流式文件 ,如JPG/JPEG/PNG图片及扫描件PDF;第三类是 图文混合文件(如含图文的PDF)。由于混合文件的处理逻辑本质是"文本+图片"的融合处理,因此后续将聚焦文本类与图片类数据展开讨论。
WeKnora 为每种文件类型单独设计了处理类,所有处理逻辑均封装在 /docreader/parser 目录中。
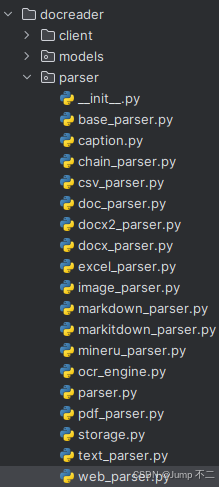
其中PDF解析逻辑最为复杂(需兼顾文本与图片内容),因此框架采用 责任链模式 实现解析。优先使用 MinerU 工具解析,若解析失败则使用 微软开源的 Markitdown 文件解析工具。
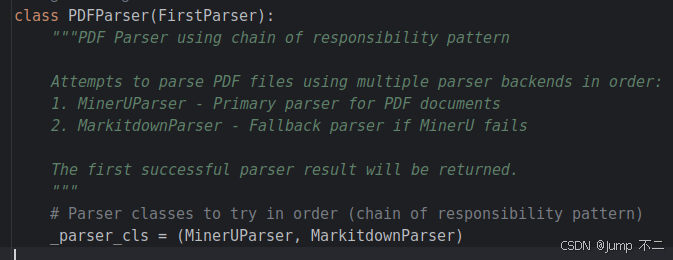
从 mineru_parser.py 文件的实现逻辑来看,WeKnora 会先将PDF拆分为文本与图片两部分,完成图片保存后再对两部分分别解析。(下图)
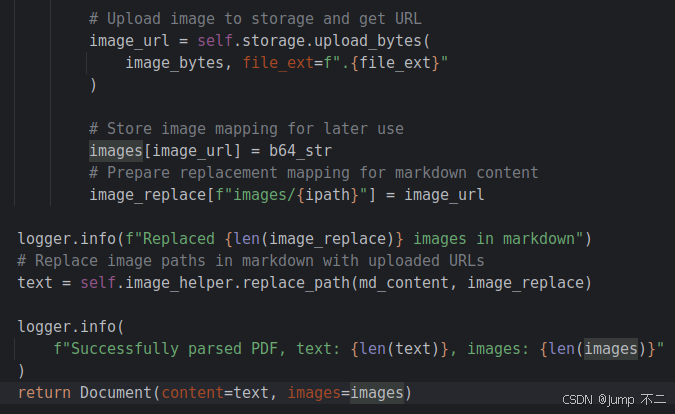
先开看看文本部分的处理逻辑,不同文本类型(如TXT、DOC、Excel)的处理细节虽有差异,但核心流程保持一致。对于文本类文件,框架会先通过正则匹配识别"不可切分的整体内容"(如MD表格、图片占位符等)。即使此类内容体积过大,仍然会直接作为单个chunk 保留(不进行切分)。(这种情况理论上会影响系统实际运行性能)

值得注意的是,Excel的处理逻辑较为特殊。WeKnora 按 "每行一个chunk" 的规则进行切分,以表头为Key、对应列值为Value,每行生成一组KV键值对。这种方式在常规场景下表现应该不错,但实际业务中存在大量格式复杂的Excel文件(如合并单元格、特殊格式等),此时该拆分方式的适配性会显著下降。
所有文本数据拆分为chunk后,将进入后续处理环节。WeKnora 默认采用 nomic-embed-text 作为 嵌入模型。选择该模型的核心考量可能在于适配多数使用者的硬件配置------ nomic-embed-text 在CPU或低配GPU环境下可实现更优的推理速度,降低部署门槛。
向量化后的数据将存储于PostgreSQL 、Elasticsearch 及 Qdrant 三种数据库中,这三类数据库的镜像会在项目启动时自动拉取并完成安装。

同时,每个chunk除了进行向量嵌入,还会同步开展 关键信息提取 ,用于知识图谱 构建。WeKnora 直接借助大模型完成信息提取与图谱构建,并将最终生成的知识图谱存入图数据库。

从实现细节可见,WeKnora 默认仅支持11种实体类别,若这些类别无法覆盖实际业务场景,需用户自行调整 prompt 以适配新的实体类型。
而在文档整体处理流程中,图片部分的处理逻辑同样关键。如前文所述,PDF会被拆分为文本与图片两部分,文本部分按上述逻辑处理,图片部分则先通过 OCR识别 转换为文本,再沿用文本的处理流程完成后续操作。WeKnora OCR识别采用的是行业广泛应用的 PaddleOCR 工具。
二、知识获取:精准检索与智能交互实现
知识获取是用户与系统交互的核心环节,WeKnora通过"问题优化-双渠道检索-信息融合-智能生成"的全流程设计,确保用户能快速获取精准、全面的知识答案。其核心逻辑是依托前文构建的向量库与知识图谱,通过大模型驱动的检索与整合,实现从问题到答案的高效转化。
当用户提出问题时,WeKnora 会先利用大模型对问题进行改写优化,将原始问题调整为更契合检索需求的自然语言问句(如补充上下文信息、优化表述逻辑、明确核心诉求等)。

随后进入核心的信息检索与召回环节,具体流程可分为两步并行推进。
-
第一步是向量检索,基于改写后的问题生成对应的向量表示,然后在已构建的向量库(存储于PostgreSQL、Elasticsearch及Qdrant中的向量化chunk数据)中进行相似性匹配,召回与问题语义相关的知识片段;
-
第二步是图数据库检索,同步提取问题中的核心实体、关键词及语义关系,依据这些信息在图数据库的知识图谱中检索关联的实体节点、属性及关系链路,获取结构化的知识关联信息。

检索完成后,框架会对两类渠道召回的信息进行融合处理。
- 先分别对向量检索结果按语义相似度得分排序、对图数据库检索结果按关联紧密程度排序。
- 再结合信息的可信度、时效性等维度进行二次筛选与权重分配,最终整合形成一份精准、全面的候选信息集合,提交给大模型生成符合用户需求的最终回答。
三、结语
WeKnora 以 "多格式文档解析 - 双库构建" 为基础,以 "智能问题优化 - 双渠道检索 - 信息融合生成" 为交互核心,借助 Go 语言生态、Ollama 大模型部署、PaddleOCR 等技术工具,实现了知识的高效管理与精准输出。
尽管 WeKnora 在复杂格式文档适配、实体类别扩展性等方面仍有优化空间,但其展现的 "大模型 + RAG + 知识图谱" 的融合思路,精准契合了企业级知识管理对高效整合、智能交互、协同共享的核心需求。未来,随着大模型技术的迭代与行业需求的深化,这类知识管理产品在处理复杂度、检索精准度、场景适配性等方面的能力有望进一步提升,为企业数字化转型中的知识沉淀与价值释放提供更坚实的支撑。
🔥 若你对 AI 技术🤖(如模型开发、NLP 应用、行业落地等)感兴趣,欢迎✉️私信我~
拉你进专属交流群👥,和技术大牛们面对面深度探讨、互换经验!💡