LLM为核,上下文为限:拆解AI Agent生态的底层逻辑
在当前AI Agent热潮中,我们常常被Function Calling、MCP、Skill、ReAct、Agent等概念包围,仿佛这些技术是独立于LLM之外的"黑科技"。但拨开层层包装会发现一个核心真相:LLM(大语言模型)是所有AI能力的基础,而上下文窗口的局限性,是所有后续技术需要解决的共同命题。这就像一台电脑,LLM是它的CPU,而上下文窗口就是它的内存------CPU再强,内存不够,也跑不动复杂程序。
本文将跳出概念堆砌,从LLM的本质出发,拆解其核心约束(上下文有限),再串联起围绕这个约束诞生的各类技术(System Prompt、工具调用、MCP、Skill、Agent等),用接地气的类比帮你明白:所有看似复杂的AI技术,本质都是在"有限的上下文窗口里,高效组织信息,让LLM这个概率模型发挥最大能力"。
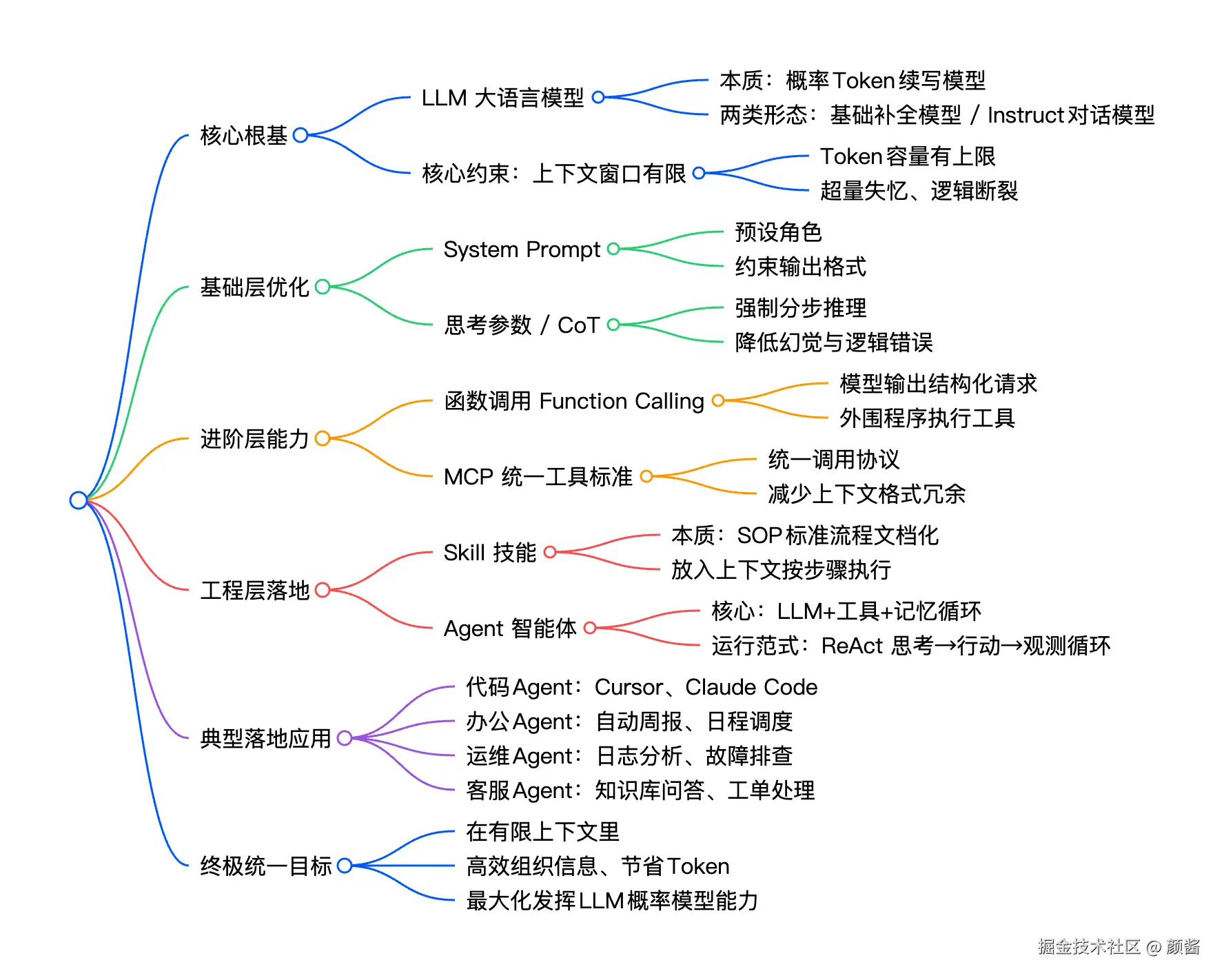
一、先锚定核心:LLM的本质的是"概率模型+上下文约束"
要理解整个AI生态的逻辑,首先要打破一个误区:LLM不是"万能大脑",而是一个"基于概率的文本接龙模型",类比下来,就像一个背熟了所有拼音和词语的小学生------他不会真正"理解"句子的深意,但能根据前面的字,大概率拼出下一个字,凑出通顺的句子。
LLM的核心工作原理很简单:给定一段输入(上下文),它会基于训练过程中学习到的语言规律,以概率最大化为原则,逐字预测下一个Token。无论是聊天、写文案、推理,本质上都是这种"概率接龙"的延伸------它不会"思考",只会基于上下文信息,给出最可能的输出,就像小学生接龙造句,只看前面的词,不深究背后的逻辑。
而LLM最大的天花板,也是所有后续技术的起点,就是:上下文窗口有限。
所谓上下文窗口,就是LLM一次能"记住"的最大Token数量(比如常见的4k、8k、32k Token),相当于人类的"短期记忆容量",更形象地说,就像我们手机的运行内存------后台开的APP太多(上下文Token太多),手机就会卡顿、闪退;LLM的上下文超过容量,就会"遗忘"前面的信息,导致输出逻辑断裂、错误。
这就引出了一个核心命题:既然LLM是基础(没有它,所有AI能力都无从谈起),且上下文窗口有限,那我们该如何在这个约束下,让LLM的概率预测能力发挥到极致?
后续所有的技术演进,从System Prompt到Agent,本质上都是在回答这个问题------就像我们给手机清理后台、关闭无用APP,只为让有限的内存,能流畅运行核心程序。
二、基础优化:给LLM定规则、强思考,用好有限上下文
在不改变LLM本身的前提下,我们首先能做的,是通过"规则引导",让有限的上下文发挥更大价值------核心是让LLM"想清楚再说""按规矩做事",避免无效Token浪费,提升输出质量,这就像给小学生定学习规则,让他上课不跑偏、不偷懒,把精力用在重点上。
1. System Prompt:上下文的"前置规则"
System Prompt(系统提示词)是每段对话的"先决条件",它会被优先放入上下文窗口,为LLM定义角色、输出规则、约束边界------相当于给LLM立好"规矩",就像老师给学生定课堂纪律:"上课只能发言,不能打闹",让LLM在有限的上下文里,优先遵循规则输出,避免偏离需求。
比如,我们可以在System Prompt中定义:"你是一个严谨的技术助手,所有输出必须结构化,工具调用请求需用指定JSON格式,不冗余、不发散"。这样一来,LLM在后续对话中,会自动遵循这个规则,将有限的上下文Token用在"核心输出"上,而非无效的冗余表达,就像学生按老师要求,只专注于答题,不写无关的话。
核心价值:通过前置规则,减少上下文浪费,让LLM的输出更贴合需求,本质是"在有限上下文里,优先明确约束"。
2. 思考参数:让LLM"慢下来,想清楚"
LLM默认的输出逻辑是"快速给出概率最高的结果",这就容易导致逻辑跳跃、错误(尤其是复杂问题)------就像人类没多想就脱口而出,容易说错话,也像小学生做题图快,跳过步骤直接写答案,很容易算错。
思考参数(如OpenAI的temperature、top_p,或部分模型的"思考步数"参数)的作用,就是让LLM"放慢节奏",增加思考过程的权重。设置后,LLM会在输出前,先在上下文窗口内完成"分步推理",再给出最终答案------这本质上是内置的CoT(思维链),让有限的上下文,优先用于"逻辑推理",而非"快速输出",就像老师要求学生"必须写出解题步骤",放慢速度,减少错误。
举个例子:没有思考参数时,LLM会直接给出"3+4-2=5";设置思考参数后,它会在上下文里先拆解"3+4=7,7-2=5",再输出结果------虽然占用了少量Token,但大幅降低了错误率,让概率模型的推理能力更稳定,就像小学生写清步骤,就算算错,也能快速找到问题所在。
3. LLM的两类形态:补全与对话,都是上下文适配的产物
LLM本质都是"补全模型"------给定上文,补全下文,就像我们玩的"成语接龙"游戏,给定前一个成语,接上最可能的下一个。但基于上下文的使用场景,衍生出了两类常用形态:
- 基础补全模型:仅负责"续写文本",上下文就是简单的输入文本,没有明确的指令引导,适合文本生成、续写等场景,就像成语接龙只给前一个词,不管你接得是否贴合场景;
- Instruct对话模型:经过指令微调,能理解人类的自然语言指令,上下文窗口中会优先解析"指令意图",再进行补全------本质是优化了上下文的"信息优先级",让LLM更快捕捉需求,减少无效输出,就像有人告诉你"成语接龙要接描写春天的词",你会优先选择贴合要求的成语,而不是随便接一个。
两者的核心区别,不是LLM本身的能力差异,而是"上下文信息的组织方式"差异------对话模型更擅长将上下文里的"指令"作为核心,优先响应,更贴合人类交互场景。
三、进阶突破:工具调用与标准化,突破上下文的"信息边界"
LLM的上下文有限,不仅意味着"记不住太多信息",还意味着"自身知识有限"(比如实时数据、专业数据库),就像一个博学但不外出的学者------他懂很多理论,但不知道当天的天气、最新的新闻。为了突破这个边界,我们需要让LLM"调用外部工具"------但工具调用的核心,依然是"在有限上下文里,高效组织工具请求和反馈信息"。
1. 工具调用的底层逻辑:上下文的"闭环流转"
工具调用的核心流程,完全围绕上下文窗口展开,我们可以拆解为5步,结合类比清晰看到上下文的作用,就像一个人出门办事:
- System Prompt定义规则:在上下文窗口中,提前约定"工具调用的结构化格式"(如JSON),让LLM知道"如何输出工具请求",就像家人提前告诉你"去超市买东西,要列好清单,写清物品和数量";
- LLM判断需求:基于用户输入和上下文信息,判断"是否需要调用工具"(比如用户问"今天天气",LLM知道自身没有实时数据,需要调用天气工具),就像你出门前,判断自己不知道天气,需要查手机;
- 输出结构化请求:LLM按约定格式,在上下文窗口中输出工具调用参数(如"{"tool":"weather","params":{"city":"北京","date":"2026-04-29"}}"),就像你按家人要求,列好"买牛奶2盒、面包1袋"的清单;
- 外围程序执行:外部程序解析上下文里的结构化请求,调用工具并获取结果,就像超市收银员按你的清单,帮你找到对应物品;
- 结果回喂上下文:将工具返回的结果(如"北京今日晴,22℃")重新塞进上下文窗口,LLM基于新的上下文,继续推理并给出最终答案,就像你把买好的东西带回家,家人根据你买的物品,安排后续的早餐。
关键点:LLM只负责"思考是否调用工具"和"输出请求",真正的工具执行由外部程序完成;而所有交互(请求、结果)都在上下文窗口中流转------本质是"用工具补充上下文的信息缺口,让LLM的概率预测有更完整的信息支撑",就像你靠手机查天气、靠超市买东西,弥补自己的信息和能力缺口。
2. MCP:工具调用的"标准化语言",减少上下文冗余
在工具调用的初期,不同工具、不同LLM的调用格式杂乱无章:查天气用一种格式,查快递用另一种格式,不同LLM对同一种工具的理解也不同------这会导致上下文窗口中充斥大量"格式说明",浪费宝贵的Token,就像不同国家的人交流,没有统一语言,需要反复翻译,浪费时间和精力。
MCP(统一工具调用标准)的核心作用,就是"固定工具调用的结构":为所有工具(天气、快递、数据库等)定义一套统一的请求格式和参数规范,让任何LLM都能看懂,任何工具都能接入,就像全世界统一用英语交流,不用反复翻译,提升效率。
比如,统一规定"查天气"的请求格式为"{"type":"weather","city":"xxx","date":"xxx"}",无论哪个LLM,只要遵循这个格式输出,外部程序就能解析------这样一来,上下文窗口中就不用重复携带"格式说明",节省Token,让信息组织更高效,就像统一语言后,不用再反复解释"我说的是什么意思"。
本质上,MCP是"为上下文减负",让有限的Token优先用于"核心请求和结果",而非"格式适配"。
四、工程落地:Skill与Agent,让上下文高效循环起来
有了规则引导、工具调用和标准化,下一步就是将这些能力落地为"能自动干活的Agent"------而Agent和Skill的核心,依然是"围绕上下文,组织信息、循环执行",就像一个能自主完成任务的实习生,不用你一步步指挥,就能按流程把事情做好。
1. Skill:上下文的"流程化文档",本质是文档化的SOP
Skill(技能)不是新能力,而是"将一套完整的操作流程,文档化后放入上下文",让Agent能按流程一步步执行------本质上,Skill就是SOP(标准操作流程)的文档化,就像公司给实习生的"操作手册" ,写清每一步该做什么、怎么做,实习生照着手册,就能完成任务。
比如,"旅行规划Skill"会将流程写成文档,放入上下文窗口:"1. 调用天气工具查询目的地天气;2. 调用地图工具筛选景点;3. 调用日历工具规划路线;4. 整合信息生成方案"。Agent看到这份文档,就会按流程调用工具,每一步的结果都回喂上下文,逐步推进任务,就像实习生照着操作手册,一步步完成旅行规划,不用自己瞎琢磨。
核心价值:将复杂任务拆解为标准化步骤,让上下文窗口中的信息"按流程有序组织",避免LLM在有限的上下文里"混乱推理",提升任务执行的可靠性,就像操作手册能避免实习生出错,让工作更高效。
2. Agent:LLM+工具调用的"上下文循环框架"
很多人觉得Agent是"比LLM更高级的模型",其实不然------Agent的本质,是将LLM、工具调用、Skill/SOP,放进一个"上下文循环"里 ,这个循环就是我们之前提到的ReAct范式,就像一个能自主解决问题的员工,会自己思考、自己动手、自己看结果,直到完成任务。
Thought(思考)→ Action(调用工具/执行步骤)→ Observation(工具结果/步骤反馈)→ 再思考 → 再行动......直到信息足够,输出最终答案。
整个循环的核心,依然是上下文窗口,就像员工的"工作笔记",记录着需求、步骤、结果,随时查看、随时更新:
- Thought:LLM基于上下文里的用户需求、Skill流程、历史反馈,判断下一步该做什么,就像员工看工作笔记,思考"下一步该做什么";
- Action:LLM按规则输出工具请求,写入上下文,就像员工按思考结果,动手完成任务;
- Observation:工具结果回喂上下文,更新上下文信息,就像员工完成一步任务后,记录结果,看看是否符合要求;
- 循环:LLM基于更新后的上下文,继续思考,直到完成任务,就像员工根据结果,调整下一步计划,直到把事情做好。
简单说,Agent就是"让LLM在有限的上下文里,自动完成'思考-行动-反馈'的循环",不用人类干预,就能高效利用上下文信息,完成复杂任务,就像一个得力的员工,不用你事事操心。需要特别补充的是,我们常见的cursor claudeCode也属于Agent的典型应用------它以LLM为核心,将代码生成、语法校验、逻辑优化等流程封装为内置Skill,通过上下文循环调用代码相关工具,自动完成代码编写、调试等任务,本质是"代码领域的专属Agent",其核心依然是在有限上下文内,高效组织代码相关信息,让LLM的概率预测能力精准匹配代码生成需求。
除了cursor 、claudeCode这类垂直领域Agent,当前Agent的应用场景已覆盖多行业,且均遵循"LLM为核、上下文为限"的底层逻辑:比如办公领域的自动化Agent,可调用邮件、日历、文档工具,按预设SOP自动完成周报生成、会议安排等任务;运维领域的Agent,能调用服务器监控工具、日志分析工具,循环排查系统异常、生成运维报告;客服领域的Agent,可整合知识库工具、对话记录工具,自主响应客户咨询、处理简单投诉。这些Agent虽应用场景不同,但核心逻辑完全一致------依托LLM的推理能力,在有限上下文窗口内,通过工具调用、流程执行的循环,高效完成特定领域的复杂任务。
五、终极总结:所有技术,都在解决同一个上下文问题
看到这里,我们可以串联起所有知识点,形成一个完整的逻辑闭环,用一个类比总结所有:
LLM就像一个聪明但记性不好的厨师(概率模型,会做饭但记不住太多步骤),上下文窗口就是他的"备忘录"(有限容量,记不下太多菜谱和步骤);System Prompt是"厨师的工作准则"(定规矩,不跑偏),思考参数是"让厨师慢慢做菜,不图快"(减少错误);工具调用是"厨师用的厨具和食材"(弥补自身不足),MCP是"统一的厨具使用规范"(减少麻烦);Skill是"菜谱"(标准化步骤,照着做),Agent是"能自主做饭的厨师"(循环执行,不用指挥)。
-
核心基础:LLM是概率模型,所有AI能力都基于它的"概率预测"能力,就像厨师是做饭的核心,没有厨师,再好用的厨具也没用;
-
核心约束:LLM的上下文窗口有限,Token数量决定了它能"记住"和"处理"的信息上限,就像厨师的备忘录容量有限,记不下太多菜谱;
-
所有技术的目标:在有限的上下文窗口里,高效组织信息,让LLM的概率预测能力发挥最大价值,就像让厨师合理利用备忘录,记好关键步骤,做好菜;
-
技术演进逻辑:从System Prompt(定规则)、思考参数(强推理),到工具调用(补信息)、MCP(标准化),再到Skill(流程化)、Agent(循环化),都是在不断优化"上下文的信息组织方式"------减少冗余、补充缺口、规范流程、自动循环,就像给厨师完善准则、放慢速度、配齐厨具、定好菜谱,让他能自主、高效地做好菜。
而这背后,都是实实在在的工程问题:如何设计工具让Agent调用更顺畅?如何写Skill文档让流程更可靠?如何管理上下文让Token花在刀刃上?理解了这个核心,我们就不会被繁杂的概念迷惑,能更清晰地看透AI Agent的底层逻辑。
毕竟,LLM为核,上下文为限------所有AI技术的演进,都是在"根"的基础上,不断突破"界"的限制,让AI能更高效、更可靠地完成任务,就像厨师不断提升自己,合理利用有限的备忘录,做出更美味的菜。