目录
[2.1 二项分布](#2.1 二项分布)
[2.2 泊松分布](#2.2 泊松分布)
[2.3 几何分布](#2.3 几何分布)
[2.4 超几何分布](#2.4 超几何分布)
[3.4 正态分布的泊松积分、标准化分析思路](#3.4 正态分布的泊松积分、标准化分析思路)
一、随机变量、分布函数的定义
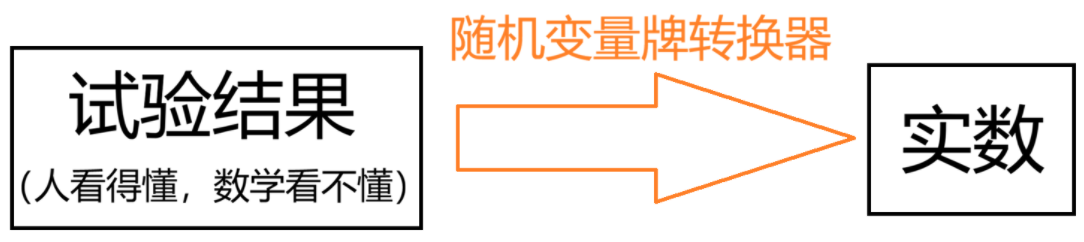
(1)随机变量是什么?把试验结果映射成实数的转换器
前面我们已经知道了任何试验都会有不同的结果,但这个结果是人可以辨别的事件,而非数学概率论中的定义。比如抛硬币,我们只知道他有正、反两面性,但如何在数学中定义呢?
这就是随机变量函数,它是一个讲试验结果转换成实数的"转换器",不过我们通常的叫法省略了函数,直接说随机变量。有了这个实数后,我们就可以通过数学工具(函数、微积分等)来研究概率问题了。

(2)随机变量的分类
根据取值的特点,分为三类:
- 离散型随机变量:取值是有限个或可列无限个孤立的点,比如骰子点数 {1,2,3,4,5,6}。
- 连续型随机变量:取值充满一个或多个区间,比如身高、时间、温度。
- 非离散非连续型:理论上存在,工程中极少用到。
在概率论中我们只讨论离散型随机变量和连续型随机变量。
(3)分布函数:试验结果的概率累加
每一种试验都会有对应的概率。比如抛硬币,正反两面的概率就都为0.5。如果将正面映射为1,反面映射为0。则在数学中可以称为该事件为0、1的概率均为0.5。

在抛硬币的例子中就是,F(0)=0.5;F(1)=1。这里并不是说正面的概率就是1,而是由于分布函数的定义是累计的,所以它天然把反面0的概率包含在内了,才呈现出1的状态。
(4)分布函数的4大性质
分布函数(概率累加函数)F(x)的常见性质如下。

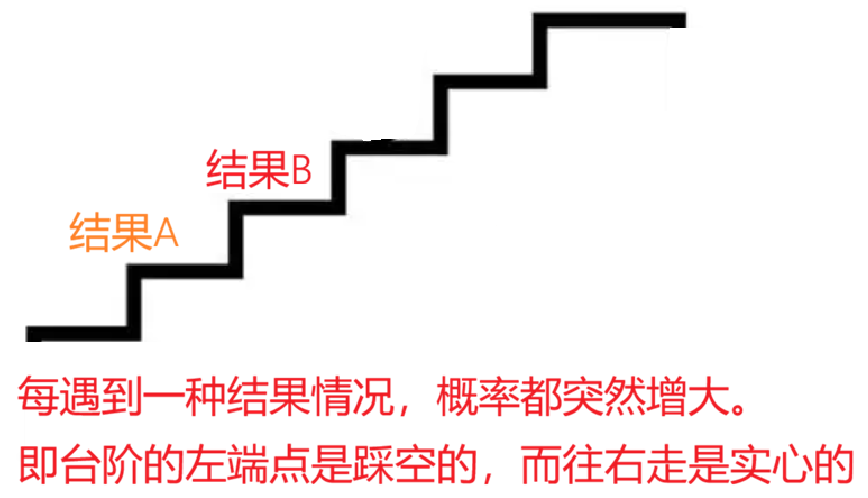
这里提到离散型分布函数只遵守右连续性,其实是因为离散型的分布图是阶梯状的,每遇到一个事件才会概率陡然增加。但不管怎么说,在任意台阶中间部分都是连续的。所以实际上"右连续性"的作用并没有想象中那么大。
(5)用分布函数计算区间概率
我们可以用分布函数直接计算各种区间的概率:

二、离散型随机变量
(1)离散型随机变量的定义、分布列
如果随机变量 X 的取值是有限个 或可列无限个 (比如自然数集),则称 X 为离散型随机变量。
简单来说就是结果为有限的试验,且概率只分布在每个试验结果单点上。比如抛硬币只有两种结果,可为离散型。比如掷骰子有6个点数,也为离散型。
对于离散型,我们通常可以用分布列来清晰表示每个点的概率,从而更好分析分布函数。分布列即为一个表格,列清楚了每一个x点处的概率。

对于离散型随机变量,分布律比分布函数更直观、更常用。它的分布函数 F(x) 是一个阶梯函数,在每个x_k 处发生跳跃,跳跃高度就是 p_k。
(2)几种常见的离散型分布
2.1 二项分布

2.2 泊松分布
由于单纯的二项分布可能比较难计算,比如试验次数K很大时,p^K难以计算,且容易引起精度丢失。于是泊松这个人对二项分布进行了近似化化简(化简手法主要是1^∞这个高数中的极限,感兴趣的可以自行尝试)。

后来人们逐渐发现,泊松分布似乎可以不依赖于二项分布,而可以将λ单独作为一个稀有时间的发生概率。比方说我们以前是二项分布,而λ=np,表示重复n次伯努利试验,每一次发生的概率为p,则这n次中发生的次数一共为n*p=λ次。

2.3 几何分布

2.4 超几何分布

三、连续型随机变量
(1)连续型随机变量的定义
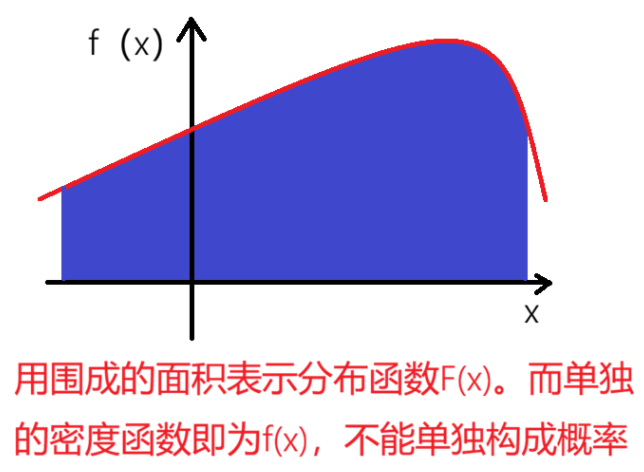
一个人的身高正好为170.00000cm是不可能的,所以在这个单点处概率无限逼近于0。而如果取一段区间,比如身高在160,170之间则概率必定存在,且不为0。即连续型随机变量的单点概率都为0,只有放在区间上讨论才有概率的意义。

(2)性质
由于我们用变上限积分函数来定义了连续型随机变量的分布函数。于是F(x)所满足的性质基本就是变上限积分函数的性质。

(3)几种常见的连续型分布
3.1均匀分布
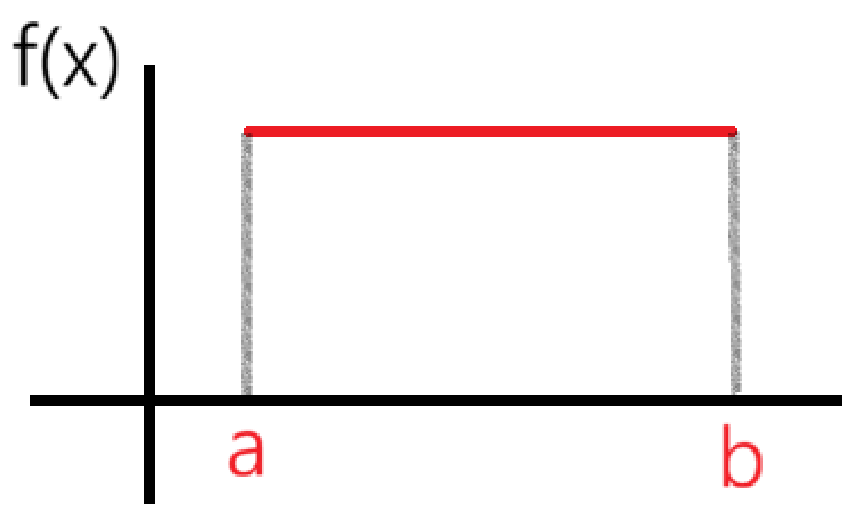
均匀分布及概率密度为一条水平线。每个相同长度的区间对总概率的影响都是相同的。

3.2指数分布
指数分布通常出现在电子元器件的寿命曲线中。比如一块电池的使用寿命概率密度曲线。

指数分布有一个核心性质:
无记忆性。即一个电子元件已经使用了 t 小时,它再使用 T 小时才坏的概率,和一个新元件直接使用 T 小时就坏的概率相同,与已使用时间无关。
证明如下:
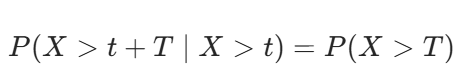
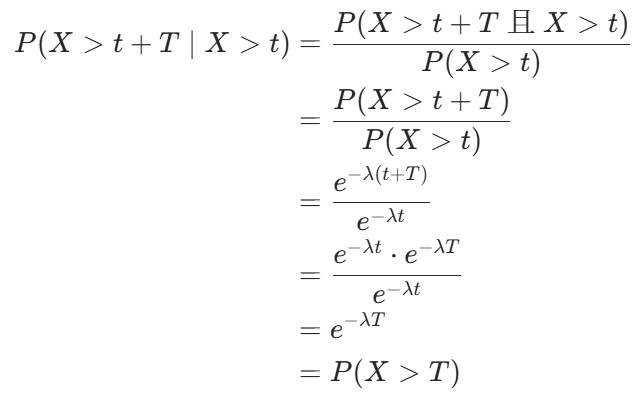
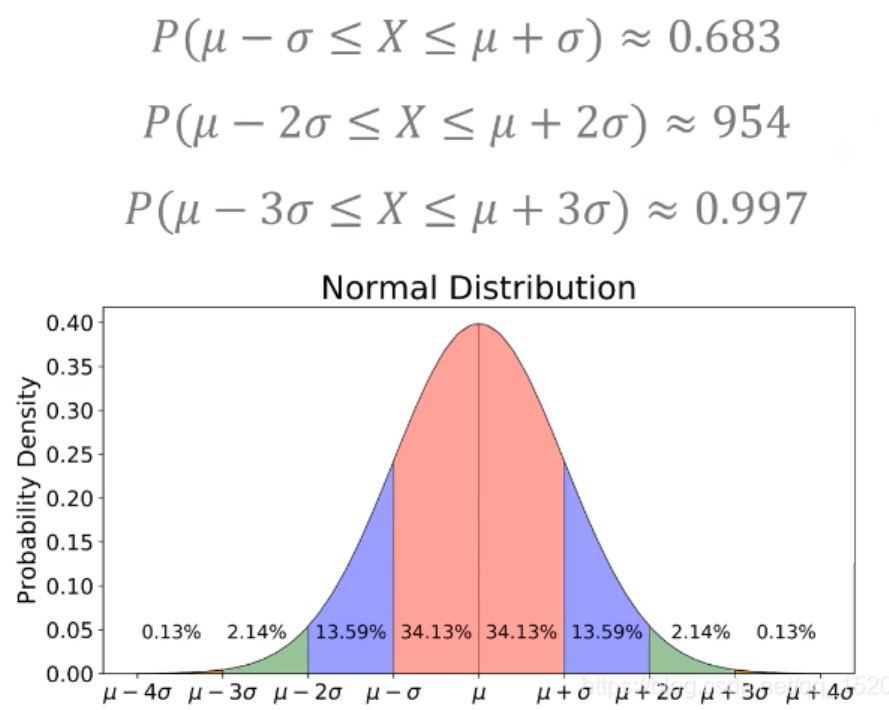
3.3正态分布

3.4 正态分布的泊松积分、标准化分析思路
正态分布就是满足上图的情况。在实际题目中往往只会给出标准形式的正态分布概率图。即X~N(0,1)。所以我们首先得将非标准的转化成标准的正态分布。

简单来说,想要把非标准形式化为标准形式,只需要两步:
(1)让x加上μ,将对称轴平移到y轴上。
(2)让x乘以σ,用以抵消指数部分里面的分母
而这上述其实就是x*σ+μ(这个x仅仅代表变量,可以自由换名字,我们后面就换成了z),现在我们定义另一个变量z=x-μ/σ即可,经过两边平移后可得x=σ*z+μ
泊松积分:

而泊松积分就是令X~N(μ,A/2)得到的一个特殊结论,利用他我们可以求出e^(-x²/A)形式的积分结果。