一、期望(Expectation)
期望是对随机变量在分布下的"加权平均"。
离散情形:
连续情形(积分):
在连续随机变量里:概率不是"点的值",而是"密度函数",所以期望会变成积分形式:
求平均 = 所有可能值 × 它出现的概率密度
积分和期望的关系:连续情形下,期望本质上就是一个积分。p(x)是权重(概率密度),f(x)是被加权的函数。
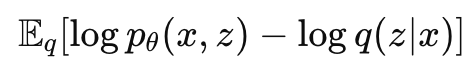
等价于
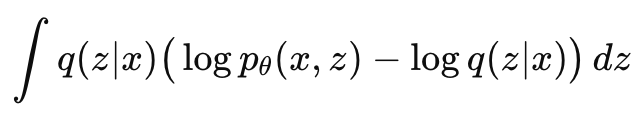
因为想要的p(z∣x)很难算,所以用q(z∣x)来近似它
二、VAE/Diffusion 中反复出现的核心公式
1. 边际化(Marginalization)
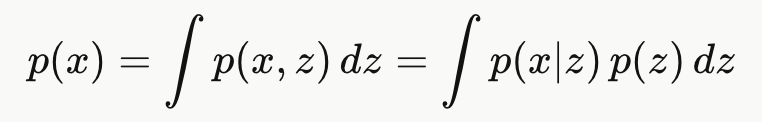
这是 VAE 最核心的困难之处------这个积分对所有 z 都是 intractable 的。
2. 贝叶斯公式
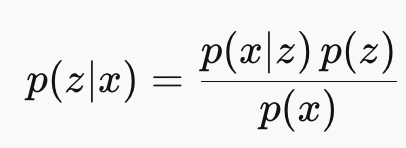
VAE 用一个神经网络来这个难以计算的后验 p(z∣x):
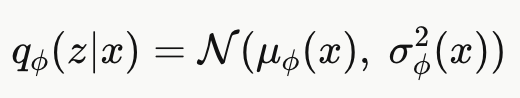
这里编码器网络接收输入 x,输出两个值:
:隐变量的均值
ϕ就是这个网络的所有可学习参数,通过最大化 ELBO 来训练。
3. KL 散度
衡量两个分布"距离"的函数:
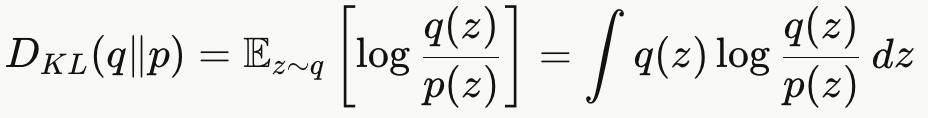 (z∼q:z服从q分布)
(z∼q:z服从q分布)
KL(q||p) = "用 q 作为权重,衡量 q 和 p 的差异"意思就是"如果数据是按照 q 分布出现的,
那 p 有多不匹配?"所以必须用q来采样(用 q 加权),不能用Ep,否则变成在模型生成的数据下评估误差。
展开就是:,ELBO 其实就是这个结构的变形!
,当且仅当 q=p时等于 0。
4. 蒙特卡洛估计(MC Estimation)
当积分无法解析计算时,用采样近似:
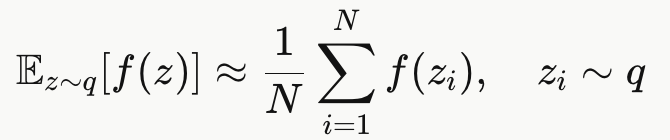
VAE 的重建项就是这样估计的(通常 N=1,因为batch 和多次迭代已经在平均了)。
原来的期望是
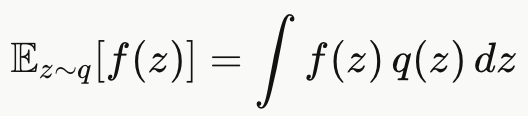
这是一个连续积分( 这个期望本质上是一个高维积分,而积分里的函数形式又非常复杂**)**,要对所有可能的 z 值加权求和------有无穷多个点。而蒙特卡洛估计只用了 N 离散的采样点:
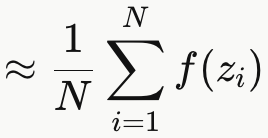 用有限个离散样本替代了无穷连续的积分。
用有限个离散样本替代了无穷连续的积分。