Encoder-Decoder PLM
Datawhale-happy_llm
Encoder-Decoder 预训练语言模型(PLM)是自然语言处理领域中一种极其重要且经典的架构,尤其擅长处理 Seq2Seq(Sequence-to-Sequence)任务。它巧妙地结合了双向上下文理解和单向自回归生成的优势。
T5 (Text-to-Text Transfer Transformer) 是 Google 在 2019 年底提出的一项里程碑式工作(论文标题为 Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer)。在这项工作中,证明了在处理复杂的序列到序列(Seq2Seq)任务时,标准的编码器-解码器架构依然是最稳定、性能上限最高的选择。以下将主要介绍 T5 的模型架构和预训练任务。
1、 核心架构解构
顾名思义,这种架构由两个主要部分组成,它们通过**交叉注意力机制(Cross-Attention)**紧密耦合:
Encoder(编码器 - 负责"理解"):
- 机制: 采用双向自注意力机制(Bidirectional Self-Attention)。
- 作用: 它能够一次性"看"到完整的输入序列,充分捕捉前后文的依赖关系,将离散的 Token 映射为富含全局上下文信息的隐状态向量(Hidden States)。
Decoder(解码器 - 负责"生成"):
- 机制: 采用带掩码的单向自注意力(Masked Self-Attention)加上交叉注意力(Cross-Attention)。
- 作用: 采用自回归(Auto-regressive)方式,基于已生成的历史 Token 和 Encoder 提供的隐状态,逐个预测下一个 Token。其核心数学表达为最大化条件概率:P(yt∣y<t,X)P(y_t | y_{<t}, X)P(yt∣y<t,X),其中 XXX 是输入,yyy 是输出。
信息桥梁(Cross-Attention):
- 在 Decoder 生成每一个新 Token 时,交叉注意力层会动态地去"查阅" Encoder 输出的完整信息。Decoder 的隐状态作为 Query,Encoder 的输出作为 Key 和 Value,确保生成的每个词都高度贴合输入语义。
T5架构的关键改进:
1. 相对位置偏置 (Relative Position Bias)
这是 T5 架构中最核心的改动之一。传统的 Transformer 使用绝对位置编码(将正弦波或可学习的位置向量直接加在输入的 Token Embedding 上),而 T5 彻底抛弃了输入层的位置编码,改在 注意力机制的计算过程 中引入相对位置信息。
在计算 Attention 分数时,T5 会根据 Query (查询) 和 Key (键) 之间的"相对距离",在 Logits 上加上一个可学习的偏置项 BBB:
Attention(Q,K,V)=softmax(QKTdk+B)VAttention(Q, K, V) = softmax\left(\frac{QK^T}{\sqrt{d_k}} + B\right)VAttention(Q,K,V)=softmax(dk QKT+B)V
- 对数分桶 (Log-Binning): 为了控制参数量并提升泛化能力,T5 并没有为每一个物理距离分配一个独立的偏置。对于距离较近的 Token,给予精确的相对位置偏置;对于距离较远的 Token,则按照对数比例划分到同一个"桶(Bucket)"中,共享同一个偏置权重。
- 工程价值: 这种设计赋予了 T5 极强的长度外推能力(Extrapolation)。例如在构建复杂的垂直领域检索增强生成(RAG)系统时,输入往往需要拼接多个检索到的文献切片,导致上下文长度波动极大。相对位置编码能让模型更鲁棒地处理推理时遇到的大于预训练长度的序列。
2. 简化的层归一化 (Simplified LayerNorm / RMSNorm)
标准的 LayerNorm 需要计算输入的均值和方差,并进行减均值和除方差的操作,同时包含可学习的缩放(Scale)和偏移(Bias)参数。
T5 为了提升计算效率,去掉了均值中心化(Mean Centering)的步骤,也不再使用偏移参数(Bias),仅保留了方差缩放,这实际上就是后来大语言模型标配的 RMSNorm(Root Mean Square Normalization):
y=xEx2+ϵ⋅γy = \frac{x}{\sqrt{Ex\^2 + \epsilon}} \cdot \gammay=Ex2+ϵ x⋅γ
其中 γ\gammaγ 是可学习的缩放参数,不再有 +β+\beta+β。
同时,T5 采用了 Pre-Norm 结构,即在每次进入 Self-Attention 层和前馈神经网络(FFN)层之前进行归一化,而不是之后。这极大地稳定了深层网络的梯度。
3. 去除全局偏置项 (No Bias Terms)
除了在 LayerNorm 中去除了 Bias,T5 在整个网络的 所有线性映射层(Dense Layers / Linear Layers) 中都去除了偏置项。即只做矩阵乘法 y=Wxy = Wxy=Wx,而不做 y=Wx+by = Wx + by=Wx+b。实验表明,去除这些偏置项几乎不会影响模型性能,同时还能精简参数量并略微提升计算速度。
2、 经典的预训练目标 (Pre-training Objectives)
纯 Encoder(如 BERT)通常做完形填空,纯 Decoder(如 GPT)通常做下一个词预测。而 Encoder-Decoder 模型为了同时锻炼两者的配合,通常采用**去噪自编码(Denoising Autoencoding)**的策略。
系统会故意破坏一段完整的文本,将其作为输入喂给 Encoder,然后要求 Decoder 还原出原始的、无损的文本。常见的"破坏"手段包括:
- Span Corruption(跨度破坏): 随机将输入文本中连续的几个词替换为一个特殊的掩码 Token。
- Text Infilling(文本填充): 类似于跨度破坏,但掩码长度可以为 0(即强制模型插入词)或更长。
- Sentence Permutation(句子重排): 将文档中的句子顺序打乱,让模型恢复正确的逻辑顺序。
- Document Rotation(文档旋转): 随机选择一个 Token 作为起始点,将文档循环移位。
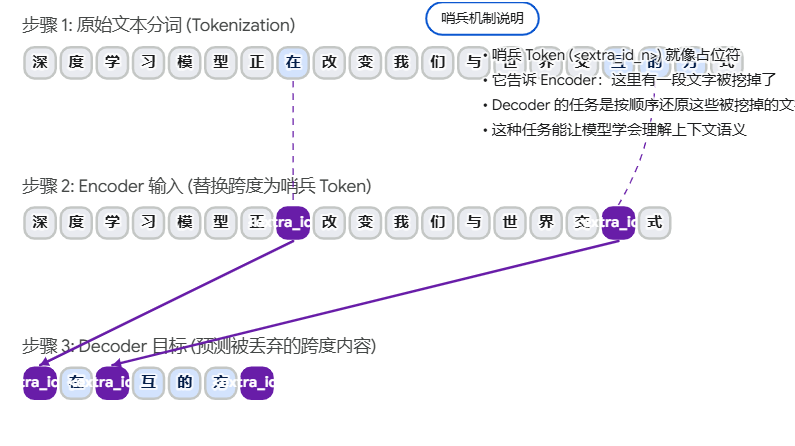
T5 的预训练并不是像 GPT 那样预测下一个词,也不是像 BERT 那样简单的完形填空,而是采用了 Span Corruption(跨度破坏) 任务。
1. 任务逻辑
- 输入端 (Encoder): 将原始句子中随机选取的连续片段(Spans)替换为特殊的哨兵 Token(Sentinel Tokens,如
<extra_id_0>)。 - 目标端 (Decoder): 要求模型生成被屏蔽的内容,每个片段前也带上对应的哨兵 Token。
2. 为什么 T5 的预训练更高效?
这种设计强制 Decoder 不仅要预测丢失的词,还要学会"定位"和"重构"。相比于 BERT 的 MLM,T5 需要生成更长的连续序列,这为其后来在摘要、翻译等生成任务上的强大表现打下了基础。
T5 的另一个伟大创新是 Task Prefix(任务前缀)。
它不需要针对特定任务修改输出层(比如分类层或回归层),而是通过在输入前加上 translate english to german: 或 stsb sentence1: 这种描述性的字符串,将不同的下游任务映射到同一个生成空间。
| 任务类型 | 输入前缀示例 | 输出目标示例 |
|---|---|---|
| 翻译 | translate English to German: Hello |
Hallo |
| 分类 | cola sentence: The cat sat on the mat. |
acceptable |
| 摘要 | summarize: [长文章内容] |
[简短摘要] |
| 相似度 | stsb sentence1: [A] sentence2: [B] |
3.8 (以字符串形式生成) |