大家好 👋,我是 Moment,目前正在使用 Next.js、NestJS、LangChain 开发 DocFlow。这是一个面向 AI 场景的协同文档平台,集成了基于
Tiptap的富文本编辑、NestJS后端服务、实时协作与智能化工作流等核心模块。在这个项目的持续打磨过程中,我积累了不少实战经验,不只是
Tiptap的深度定制、编辑器性能优化和协同方案设计,也包括前端工程化建设、React 源码理解以及复杂项目架构实践。如果你对 AI 全栈开发、文档编辑器、前端工程化或者 React 源码相关内容感兴趣,欢迎添加我的微信
yunmz777一起交流。觉得项目还不错的话,也欢迎给 DocFlow 点个 star ⭐
很多项目在早期都能跑通,到了中后期却开始不稳。最常见的原因不是模型变差,而是上下文结构越来越乱。你把规则、问题、历史、检索结果、工具输出全部堆在一起,短期看起来省事,长期一定会出问题。常见表现有这些:
- 明明要求输出
JSON,模型还是自由发挥 - 明明给了检索结果,模型却忽略证据
- 明明上一轮说清楚了,这一轮又答偏
- 一加新条件,前面的格式约束就失效
- 出问题时很难定位是规则错、检索错还是历史污染
问题的核心不在提示词文案,而在上下文分层。role 的价值正是在这里。
role 的本质
role 不是标签装饰,它在告诉模型三件事:
- 这段内容来自谁
- 这段内容属于哪一层
- 这段内容应按什么优先级理解
同一句话放在不同 role,效果会明显不同。比如 请只输出 JSON 放在高优先级规则层通常更稳,塞进用户问题里更容易在复杂场景被冲掉。所以 role 解决的是上下文治理问题,不是接口语法问题。
常见 role 和信息来源
在多数对话接口里,核心角色通常是四类:
developersystemuserassistant
还有一个容易混淆的点,工具返回结果通常不应当当作普通对话角色,而应作为独立证据输入。从工程视角看,一次请求里的上下文来源通常是五层:
- 规则层,通常来自
system或developer - 任务层,来自当前
user - 历史层,来自对话历史中的
user与assistant - 事实层,来自
tool、检索或数据库 - 生成目标层,定义这一轮最终输出要求
四个核心角色怎么用
developer
developer 是应用开发者写给模型的长期行为约束。它描述这个助手长期应如何工作,而不是本轮要回答什么问题。适合放在这里的内容:
- 助手定位
- 默认语言
- 回答结构
- 输出格式
- 工具使用策略
- 不确定时的处理方式
- 禁止编造规则
ts
const input = [
{
role: "developer",
content:
"你是技术讲解助手。默认中文。先给结论再展开。不确定时明确说明,不要编造。",
},
{
role: "user",
content: "请解释 JWT 和 Session 的区别",
},
];system
system 也是高优先级层,但更偏平台级或全局边界。它常用于跨场景都成立的底线规则。适合放在这里的内容:
- 全局身份边界
- 合规与安全要求
- 平台级能力限制
- 不可突破的红线
很多项目里 developer 与 system 会有重叠。只要职责清晰,是否拆开都可以。
user
user 承载本轮任务目标,不承载长期规则。它回答的是现在要做什么,而不是系统长期怎么做。常见内容:
- 当前问题
- 补充条件
- 输出偏好
- 输入材料
ts
const input = [
{
role: "developer",
content: "你是中文技术助手,回答准确并保持简洁。",
},
{
role: "user",
content: "请解释什么是 RAG,并给一个 TypeScript 场景示例",
},
];assistant
assistant 是模型历史回复层,作用是保持多轮连续性。它不是规则层,也不是事实仓库。
ts
const input = [
{
role: "developer",
content: "你是前端导师,解释时要循序渐进。",
},
{
role: "user",
content: "什么是向量数据库",
},
{
role: "assistant",
content: "向量数据库是为高维向量检索设计的存储与查询系统。",
},
{
role: "user",
content: "它和传统数据库的区别是什么",
},
];assistant 历史不是越多越好。历史过长、重复或噪声过多,会直接拉低后续轮次稳定性。
工具返回到底放哪层
工具结果、检索片段、数据库查询、网页抓取,本质上都是外部证据,不是模型自己说过的话。如果把这些内容伪装成 assistant 历史,会出现三个问题:
- 语义边界混乱,模型分不清自述和证据
- 历史层污染,后续轮次越来越难控
- 调试成本上升,问题定位困难
更稳的策略是:
- 规则放
system或developer - 任务放
user - 历史放
assistant - 证据放独立事实层
在 RAG、Agent、工作流编排里,这一点几乎是稳定性的分水岭。
一句话说清楚:把规则、任务、历史、外部事实和生成目标分层放置,LLM 的稳定性、可信度和可调试性都会明显提升。
四种高频场景的组织方式
单轮问答
developer + user 即可,结构最轻。
ts
const input = [
{
role: "developer",
content: "你是中文技术助手,回答清晰且准确。",
},
{
role: "user",
content: "请解释什么是 SSE",
},
];多轮对话
在 developer + user 基础上加入必要 assistant 历史,保证上下文连续。
RAG 问答
规则、问题、证据分层,不要把检索内容伪装成 assistant。
ts
const input = [
{
role: "developer",
content: "仅依据提供资料回答,不确定时明确说明。",
},
{
role: "user",
content: "文档里如何定义 RLS",
},
// 检索结果作为独立证据输入
];工具调用型 Agent
流程通常是规则定义、任务输入、模型决策、工具返回、最终回复。关键点始终是证据层和历史层分离。
这一段也可以直接用一张图讲透,重点表达每个角色的禁放内容、统一分层原则和高频错误。
如下图所示:
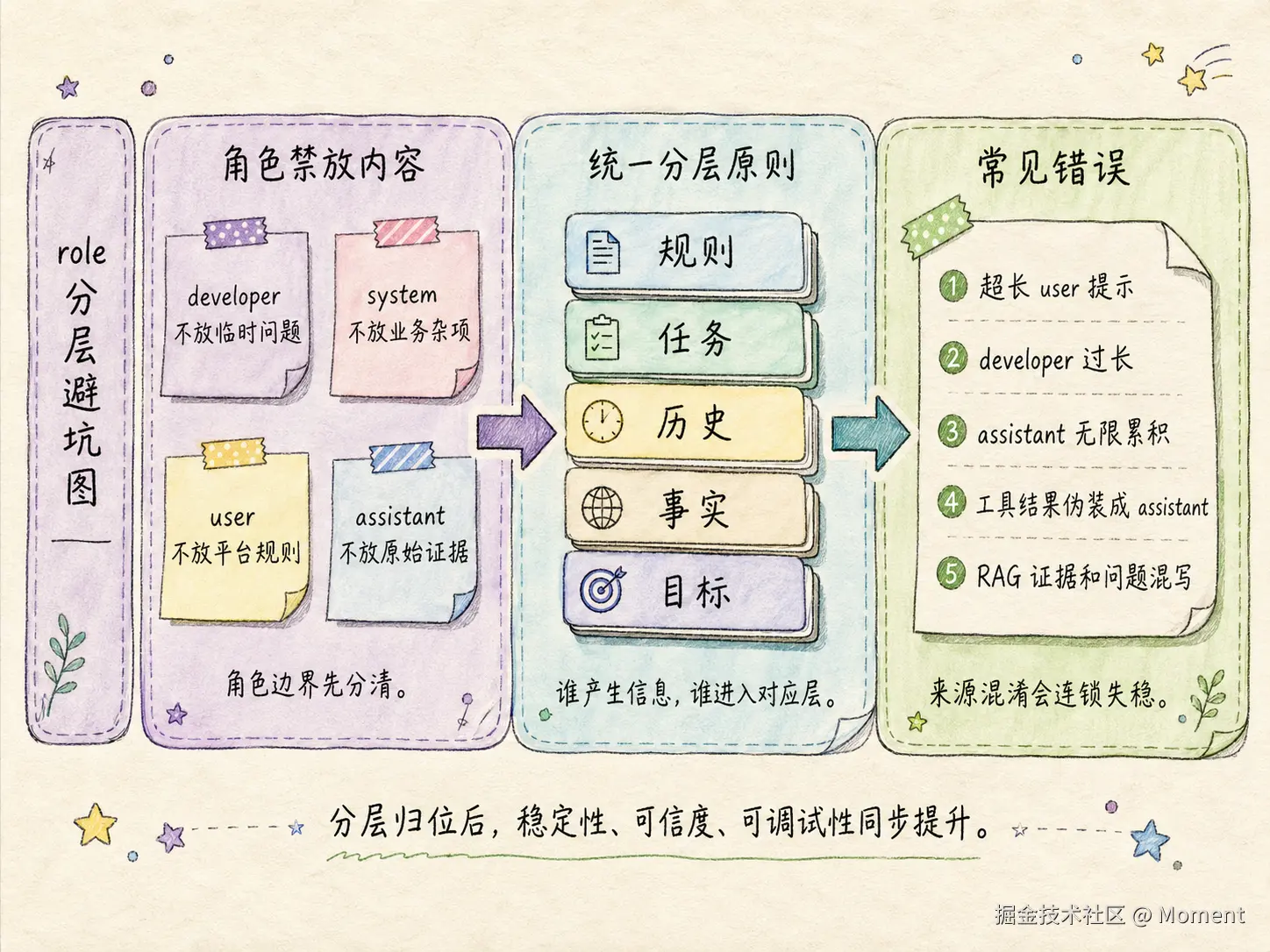
图里按左中右依次呈现禁放项、分层原则、错误清单,读者扫一眼就能建立正确的上下文组织习惯。
总结
给 LLM 传递上下文时,role 不是身份扮演,它是上下文架构的第一层。核心角色可以记成四个:
developer负责应用规则system负责全局边界user负责当前任务assistant负责历史承接
工具返回、检索结果、数据库结果这类外部事实,应单独进入证据层。一句话总结这套方法就是,规则、任务、历史、外部事实、生成目标必须分层,各归各位。只要这件事做对,很多看起来像模型能力问题的现象,最终都能回到可治理的上下文工程问题。 如果把这套原则再压缩成一条执行口令,就是谁定义规则、谁提出任务、谁给出证据、谁负责输出,都必须放在各自那一层,不能混写。结构一旦干净,后续 prompt 设计、RAG 召回和 Agent 调试都会明显轻松。