我见过最优雅的 AI Agent 架构,就五层
改一个功能,另外三个地方莫名其妙出了 bug。
做过复杂项目的人,对这句话一定不陌生。
模块之间的依赖像一碗搅乱的意大利面,你拽起一根,整碗都跟着动。改记忆系统,消息路由崩了。改工具调用,上下文管理出了问题。每次动代码都像在拆炸弹------不知道哪根线是致命的那根。
AI Agent 系统把这个问题放大了好几倍。
你同时要面对:多平台接入、长期记忆存储、工具调用执行、LLM 流式响应、多 Agent 协作调度...这些模块如果没有清晰的边界,系统三个月后就是一场噩梦。
最近正在研究 OpenClaw 的 AI Agent 框架,它的架构设计给了我很大的启发。
不是那种"哦原来还可以这么做"的惊喜,而是"这个问题我也踩过,但我没想到可以这样解"的共鸣。
它的答案,是一个五层蛋糕。
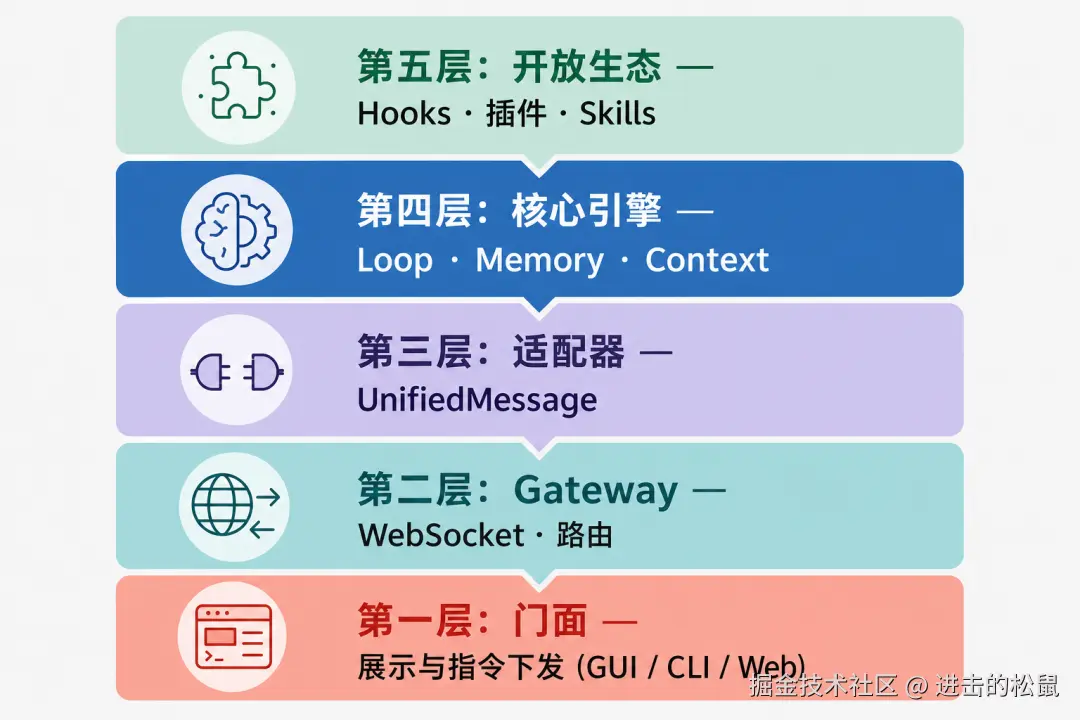
第一层:门面,但有严格的边界

用户看到的是三种入口------macOS 原生应用、命令行工具、Web UI。
产品经理用 GUI,工程师用 CLI,远程访问用 Web。这不是功能堆砌,是对不同用户心理模型的尊重。
但真正有意思的,是这层做了什么限制。
控制面只负责两件事:展示 和 指令下发。不承担任何业务逻辑。
无论你用哪个入口,发出去的消息都会被标准化成同一种格式,再往下传。
听起来很普通对吧?但它的价值在于:未来你想新增一个 iPad 客户端、一个 Raycast 插件,你只需要实现一个新的"展示层",核心逻辑一行不用动。
变化被锁在了边界里。
这层还管着系统的生命周期。10 步初始化序列,按依赖关系严格排序------先加载配置,再建数据库连接,再加载安全策略,再启动网关监听...任何一步失败,系统优雅回滚,不带病运行。
很多系统在启动错误处理上是事后诸葛亮,OpenClaw 把它放进了架构里。
第二层:交通枢纽,但不只是转发
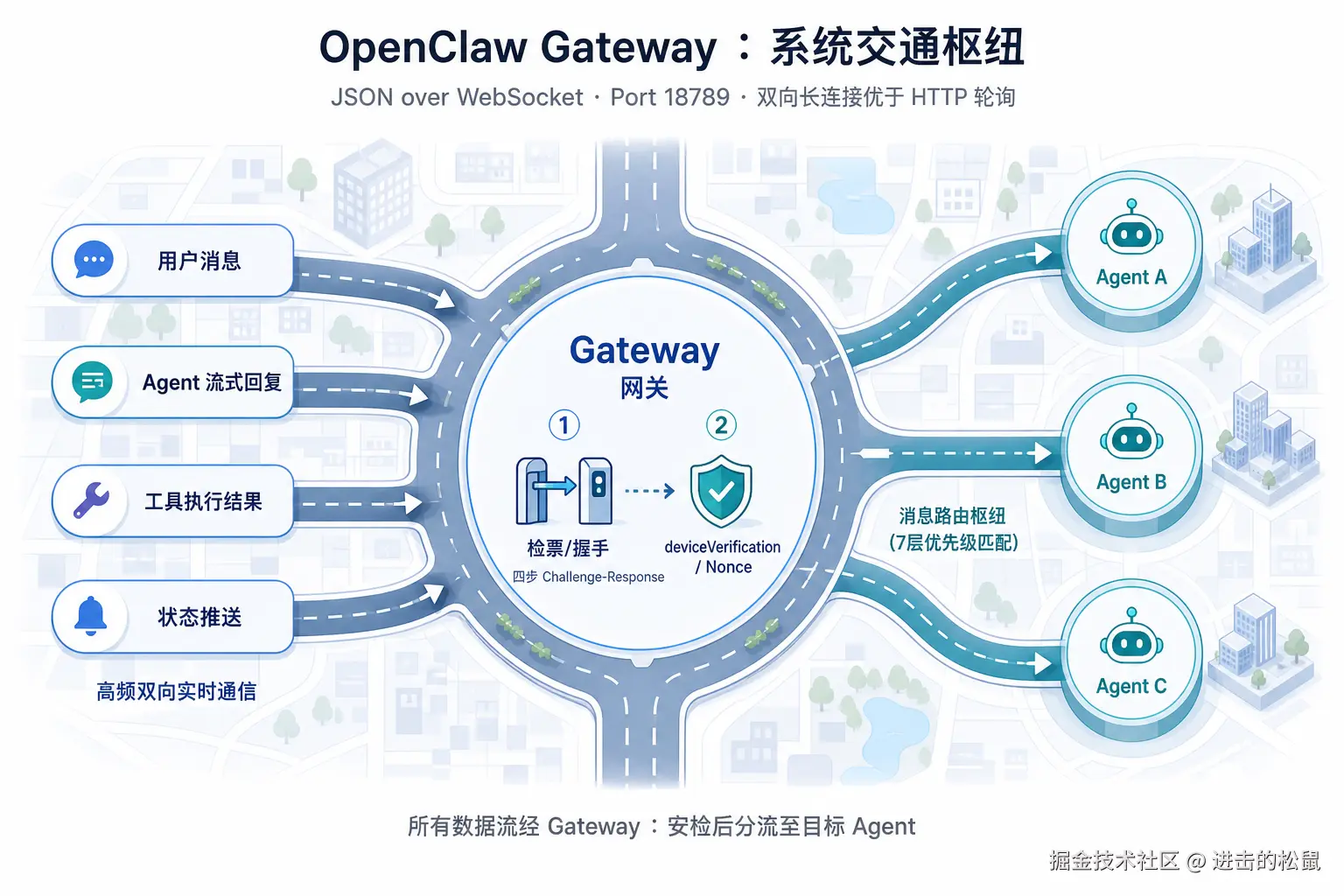
Gateway 网关,系统所有数据流的必经之地。
用 WebSocket 而不是 HTTP,原因很实际:Agent 系统充满双向实时通信------用户发消息、Agent 流式回复、工具结果返回、状态推送。长连接的效率远优于轮询,这不是技术偏好,是场景驱动的选择。
安全上,它用了"挑战-响应"握手机制。
每次连接都生成一个动态随机数,客户端用私钥签名返回,网关验证通过才建立信任。就算攻击者截获了历史通信数据,也无法伪造------因为上一次的随机数已经作废了。
更有意思的是它的消息路由。
7 层优先级匹配规则,从"精确用户绑定"到"默认兜底",依次降级。你可以把特定用户的消息路由给专属 Agent,把某个群组交给群组专属处理器,让功能型 Agent 按名称接单。
路由逻辑集中在一处,不会散落在各个 Agent 里,不会"各自为战"。
第三层:适配器,把异构世界统一成一种语言
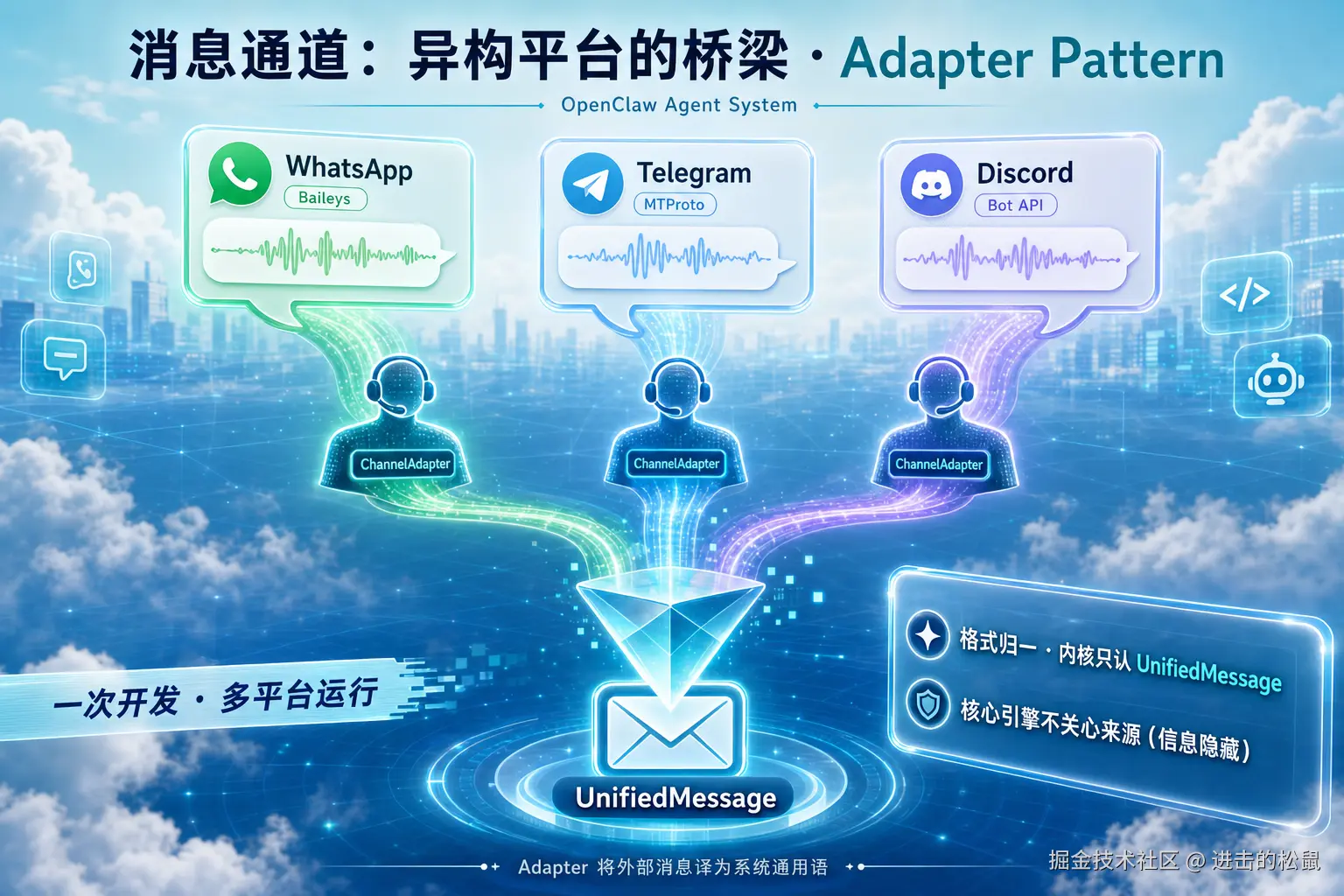
WhatsApp 用 Baileys 库,Telegram 走 MTProto 协议,Discord 是 Bot API,Signal 有端对端加密...
如果为每个平台写一套处理逻辑,核心代码会被平台细节污染得面目全非。
OpenClaw 的做法是适配器模式:每个平台对应一个 ChannelAdapter,把平台特有的格式转换成统一的 UnifiedMessage 对象。
核心引擎拿到的永远是这个标准格式。
它根本不知道------也不需要知道------这条消息是从 Telegram 还是 WhatsApp 来的。
所以,如果你想新增 Slack 支持,只需要写一个 SlackChannelAdapter。其他层,一行代码不用改。
这就是低耦合。不是说说的那种,是架构上强制保证的那种。
第四层:真正的大脑,但它被切成了三片
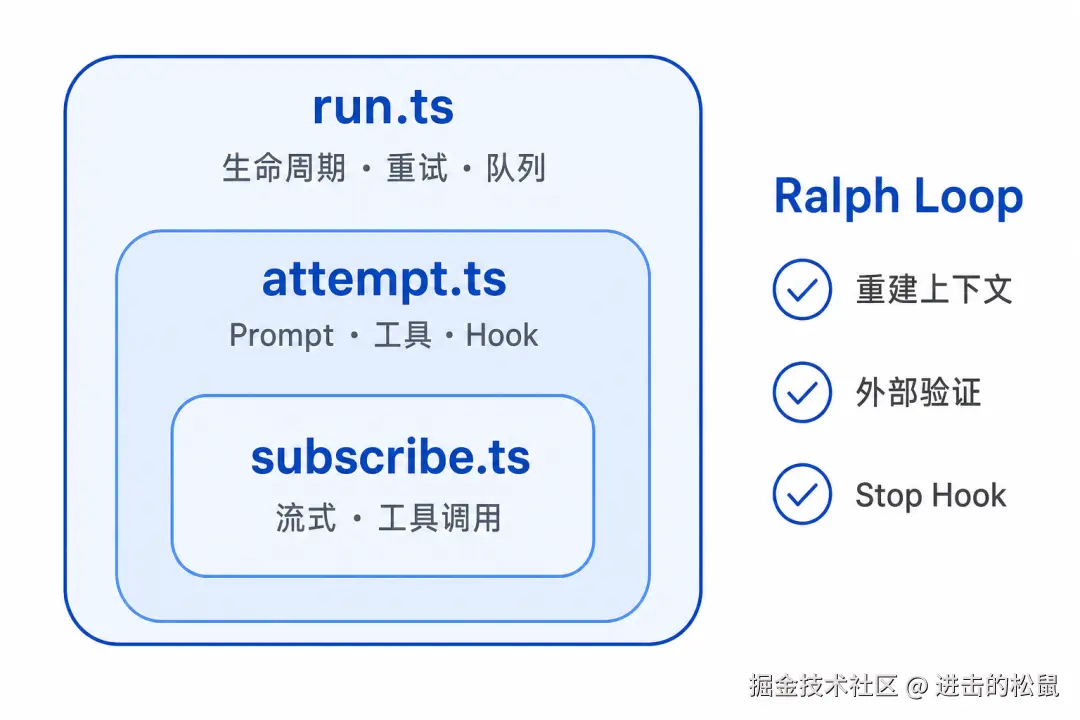
核心引擎层是整个系统最复杂的地方,也是最值得细看的地方。
Agent Loop 的执行被切成三层嵌套:
外层 run.ts:管全局生命周期,处理重试、队列、会话串行化。出了错,它决定是重试还是放弃。
中层 attempt.ts:管单次 LLM 交互,构建 Prompt,注册工具,提供 6 个插件 Hook 点。
内层 subscribe.ts:消费流式 token,执行工具调用,同步实时状态。
分这三层的意义在哪?
想修改重试策略,只动 run.ts。想优化 Prompt 构建,只动 attempt.ts。想改流式处理,只动 subscribe.ts。
修改不跨层扩散,这是架构设计里最难得的品质之一。
除此之外,核心引擎层还有三个子系统协同工作:Memory System 负责向量记忆,Routing Engine 处理多 Agent 协作,Context Manager 用自适应算法压缩上下文,避免 token 爆炸。
这里还有一个值得单独说的设计------Ralph Loop 范式。
它包含三个原则:
- 每轮迭代重新构建上下文,避免历史信息污染
- 引入外部工具客观验证 LLM 输出,而非盲目信任
- 通过 Stop Hook 强制在必要时停止,避免无限循环
这三个原则组合起来,解决的是早期 Agent 系统最常见的死亡模式。
一个名字:幻觉循环。
Agent 不停地自我强化一个错误的判断,越跑越偏,停不下来。Ralph Loop 的三原则,从源头截断了这条路。
第五层:开放,但核心不膨胀
24 个生命周期 Hook 点,38+ 官方插件,52+ 内置技能。
这层的哲学只有一句话:核心不膨胀,能力靠生长。
第三方开发者可以在任意 Hook 点注入逻辑,不需要 fork 项目修改核心代码。Skills 甚至支持声明式的 SKILL.md 文件------零代码扩展能力。
你开放的不是代码,而是接入点。这是生态设计的智慧。
两个技术选型,藏着一套价值观
为什么用 Node.js 不用 Python?
Agent 系统的核心是大量并发 I/O------等 LLM 响应、等工具执行、等平台回复。这是 Node.js 事件循环的主场,不是 CPU 密集型计算的战场。不是技术偏好,是场景驱动。
为什么用 SQLite 不用云端数据库?
这背后是一个明确的立场:Local-First。
数据存在用户本地,数据主权归用户所有。复制一个文件,记忆随身带走。没有云账号,没有订阅费,没有数据泄露的担忧。
这个选择当然有代价------多设备实时同步很麻烦,高并发写入会遇到瓶颈。
但这是有意为之的权衡,不是技术局限。设计者清楚自己在为谁服务,并为此付出了相应的代价。
这种清醒,在很多系统里是缺席的。
最后说一句
OpenClaw 的五层架构给我最大的启发,不是某个具体技术点,而是一种优先级排序:
先想清楚每一层的职责边界,再想层与层之间的接口,最后才是具体实现。
边界划清了,耦合自然就低了。职责集中了,内聚自然就高了。
很多项目走的是相反的路------先写功能,再发现模块纠缠,再痛苦地重构。
下次设计一个新系统时,我会先问自己三个问题:
这个改动,会影响几层?
这个新功能,应该放在哪一层?
如果要替换这个模块,需要改多少其他地方?
如果答案都是"一层"、"明确"、"几乎不用改"------ 那架构大概是对的。
如果你也在做 AI Agent 相关的开发,欢迎留言交流。