Redis中的常见数据结构由哪些
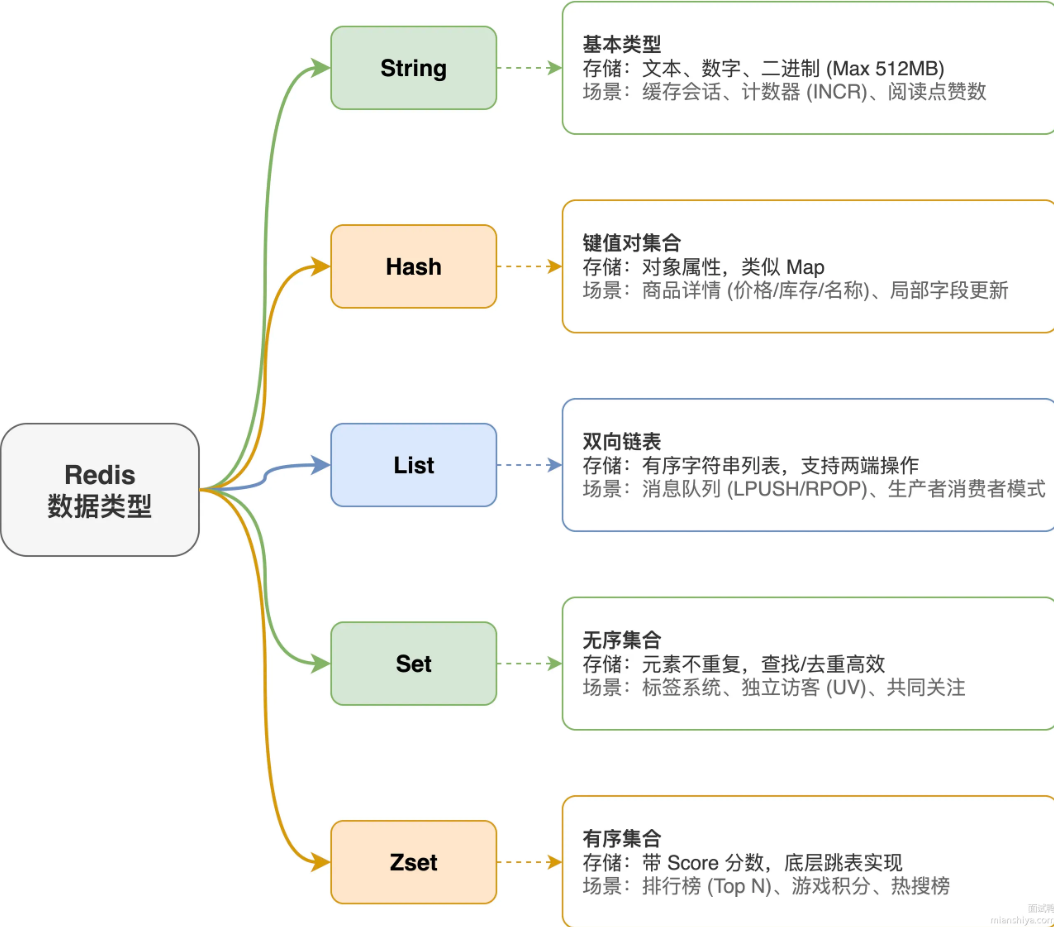
Redis中数据结构由五个部分组成:
- String
- List
- Hash
- Set
- Zset
接下来我们进行详细了解:
String 是最基础的类型,能存储文本数字,二进制,最大位512MB。典型场景:缓存用户会话,页面数据,计数器。像文章阅读量,点赞数,直接用INCR原子递增就行。
Hash 本质是键值对集合,适合存储对象属性 。像一个商品数据,ID作为key,价格,库存,名称都可以存储在一个hash中,改个字段不用整体覆盖。
List 是有序的字符串列表,底层是双向链表,支持两端操作。常见的场景是消息队列。LPUSH生产消息,RPOP消费消息。
Set 是无序不重复的集合,查找和去重效率很高 。适合做标签系统,记录某个页面的独立访客,共同关注等需要去重或集合运算的场景。
Zset 和Set类似,但每个元素自带 一个score分数来排序,底层用跳表来实现。适合用力啊创建一个排行榜,按score排序后直接取TopN。
拓展
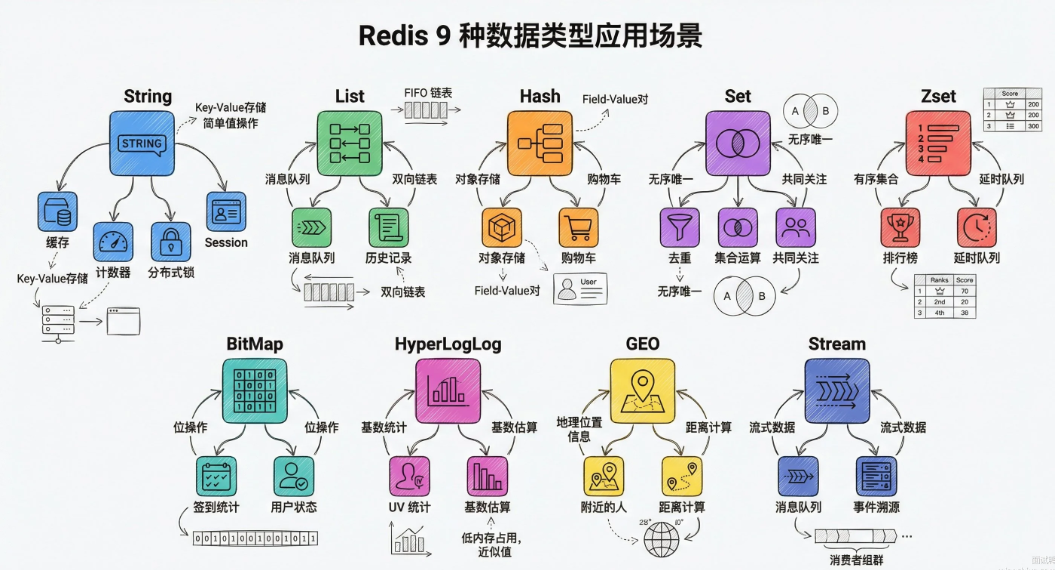
随着Redis版本更新,又出现了四种高级的数据结构;
- bitmap
- hyperloglog
- geo
- stream
bitmap用位来存储数据,每个bit之占0或1,空间利用率极高。当统计1000万用户的签到状态,一个用户只占1bit。用setbit设置状态,用getbit读取状态:
java
SETBIT user:sign:202409 12345 1 # 用户 12345 在 9 月签到
GETBIT user:sign:202409 12345 # 查询签到状态HyperLogLog 是一种用来做"基数统计"(去重计数)的概率型数据结构,用极小的空间估算大量数据的去重数量。适合统计网站UV(独立访客数量)这种对精度要求不高但数据量大的场景
java
PFADD page:uv user1 user2 user3 # 记录访问用户
PFCOUNT page:uv # 估算独立用户数geo用来存地理位置信息,支持经纬度存储和 空间查询。底层是用Zset实现的,经纬度被编码成score。场景:附近的人,外卖配送距离。
java
GEOADD riders 116.403 39.915 "rider001" # 存骑手位置
GEORADIUS riders 116.4 39.9 5 km # 查 5 公里内的骑手stream是专门为消息队列设计的数据结构。相比list做队列;Stream多了两个关键性:自动生成全局唯一消息ID,支持消费组模式。
跳表的实现原理
在之前的学习中我们了解了Zset的底层是跳表并非红黑树。
我们现在来了解一下跳表的原理:
跳表本质上是一个多层链表 。底层链表保存所有元素,上层链表是下层的子集,通过这种分层索引结构把链表的O(n)查找优化到O(logn)
查询的过程:
查找的时候从最高层开始,先往右走,遇到比目标值大的节点就往下一层走,重复直到找到目标或者确定不存在。比如查找50,从顶层的10开始,跳到40发现比50小继续往右,发现下个目标是70比目标大就往下一层走,在第二层从40往右一步就找到50了。
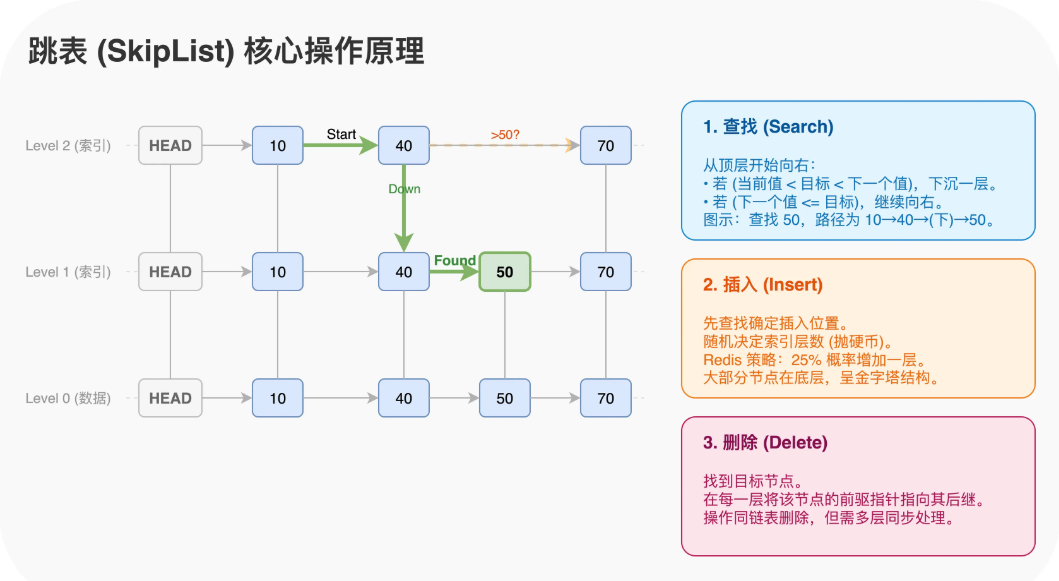
插入过程:
先用查找的方式定位到插入位置,然后随机决定新节点要建几层索引。Redis用25%概率往上加一层。导致了大部分节点只在底层,少部分节点会出现在高层索引中。
删除过程
先找到节点,然后把这个节点在各层的前后指针都接上,跟普通链表删除一样,只是要在多层都操作一遍。
知道了跳表原理,我们来区分一下为什么Redis用跳表而不用红黑树:
- 实现简单,红黑树的左旋右旋太复杂,跳表就是多层链表,好写好调试。
- 范围查询效率高,Zset通常要取排名10-20的数据,跳表在底层链表上顺着走就行,红黑树得中序遍历。
- 内存占用可靠,跳表每个节点平均1.33个指针,红黑树每个节点固定3个指针。
Redis的性能瓶颈时如何处理
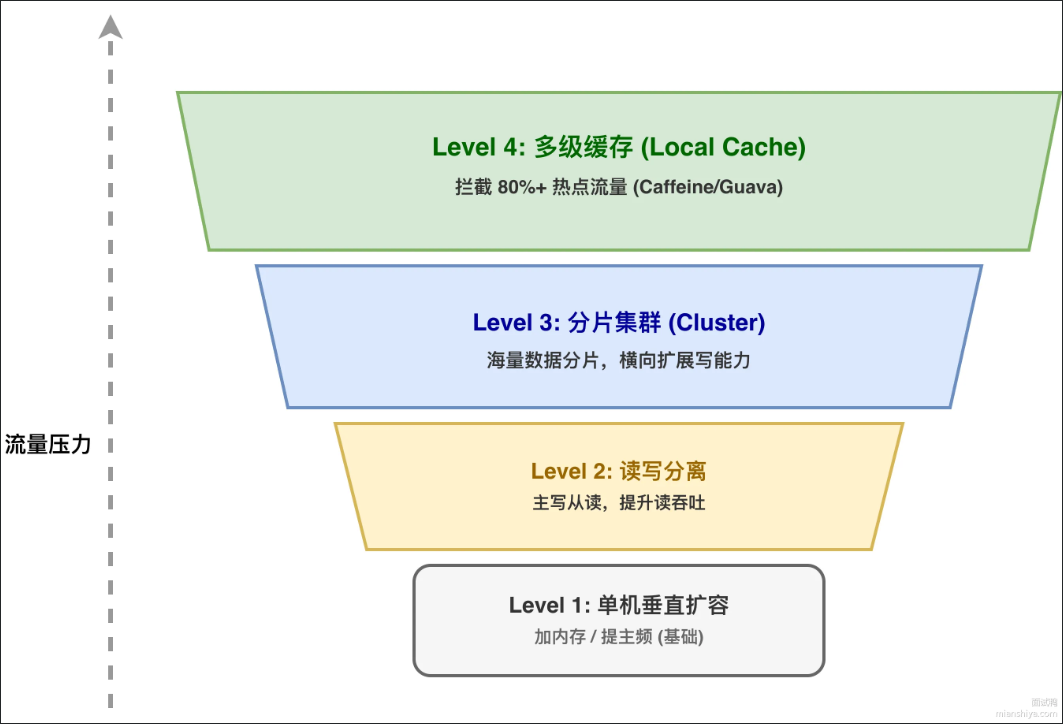
当Redis出现性能瓶颈时,核心处理方法是:分摊压力,从单机到集群逐渐递进。
- 垂直扩容:先看单机资源有没有用满,内存不够就加内存,CPU频率能提就提。
- 读写分离:写请求还是走主节点,但把读请求分流到从节点。一主三从的架构,读QPS直接翻3倍。适合读多写少的场景,像商品详细页,用户信息查询。
- Redis集群分片数据量超过单机内存上限,或者写请求压力太大,尝试分片集群。16384个槽位分散到多个主节点,写压力也能横向扩展。
- 多级缓存 :在应用层加一层本地缓存,Caffeine,把热点数据兜在本地,压根不走网络。像秒杀场景,库存这种热key必须本地缓存顶着。
拓展
如何定位性能瓶颈在哪
用Redis自带的监控命令:
java
# 查看实时性能指标
redis-cli info stats
# 慢查询日志,超过 10ms 的命令都记下来
config set slowlog-log-slower-than 10000
slowlog get 10
# 内存分析
memory doctor
memory stats我们来看看常见的性能瓶颈右哪些:
- 内存不足:used_memory超过maxmemory,开始频繁淘汰数据,响应时间飙升。
- CPU打满:大key操作或者复杂命令把CPU吃满,其他请求只能排队等着。比如对一个百万元素的Set执行SMEMBERS,单次操作就能卡住几秒。
- 网路带宽:单机网卡吞吐量优先,一旦数据量大,网络就成了瓶颈
- 持久化阻塞:AOF重写或者RDB快照时,fork子进程拷贝页表,内存越大fork越慢。
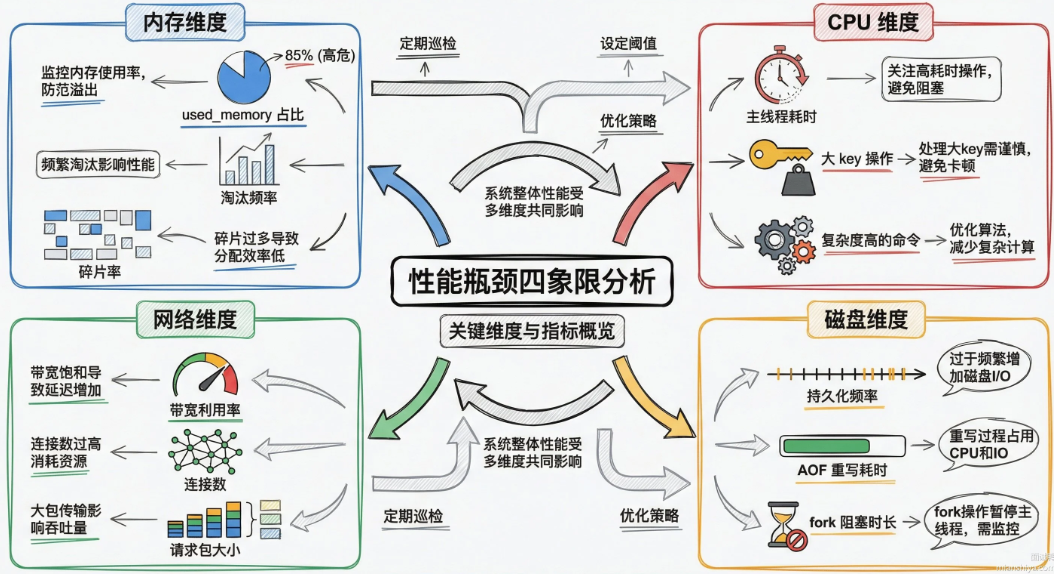
Redis中的Hash是什么
Redis 的 Hash 是一种键值对集合,能把多个字段和值存在同一个 key下面,特别适合存对象的属性。比如存用户信息,用user:1001作为key,里面放name、age、city这些字段,改单个字段不用整体覆盖,比用String存JSON灵活多了。
Hash底层有两种编码方式。数据量小的适合用listpack存储,紧凑省内存;数据量大了自动切换成hashtable,查询效率O(1).切换阈值默认为512个字段或者单个值超过64字节
拓展
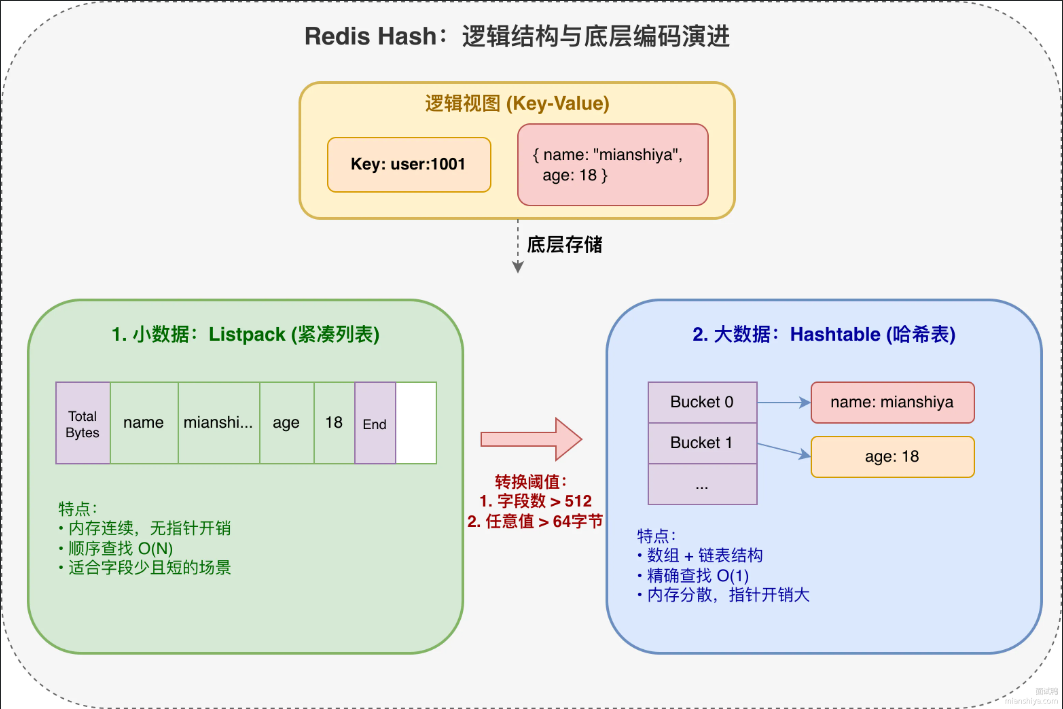
渐进式rehash
Redisd哈希表扩容不是一次搬完的,而是分多次慢慢搬,这就是渐进式rehash。
因为Redis是单线程,如果一次性搬几十万个key,这段事件其他请求都得等待,服务直接等待。
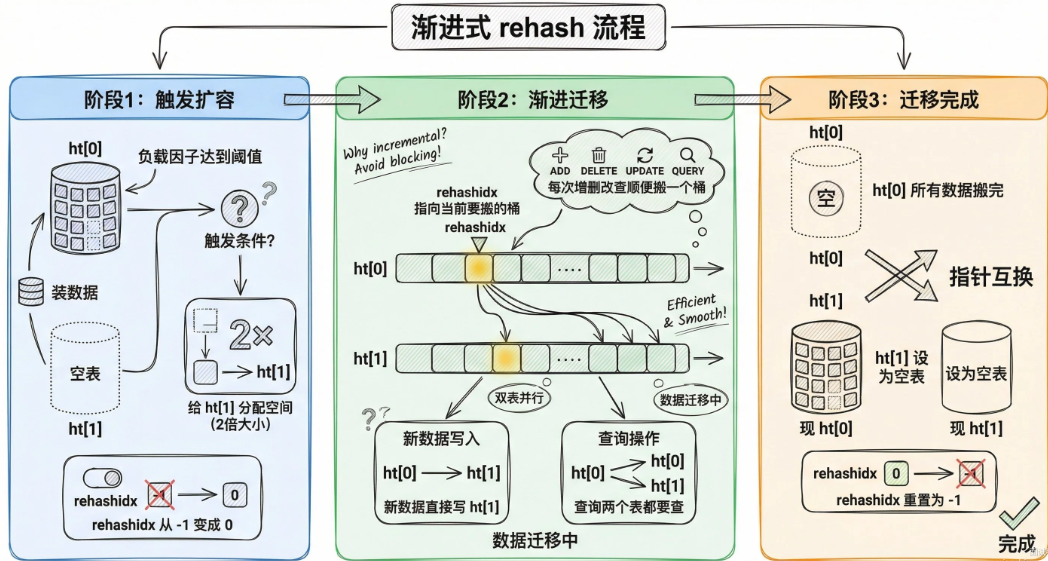
流程如下:
1)触发扩容后,给ht1分配空间,大小是第一个大于等于htO.used*2 的2次方幂。比如原表的值是1024,那个其扩容之后的新表大小就是 2048。
2)把 rehashidx的值从-1设成0,标记开始rehash
3)每次对 Hash 做增删改查,顺便把 rehashidx 对应的桶从 htO 搬到ht1,然后rehashidx++4)新插入的数据直接写 ht[11,查询的时候两个表都要查
5)搬完之后 ht0 和 ht1指针互换,rehashidx 重置为-1
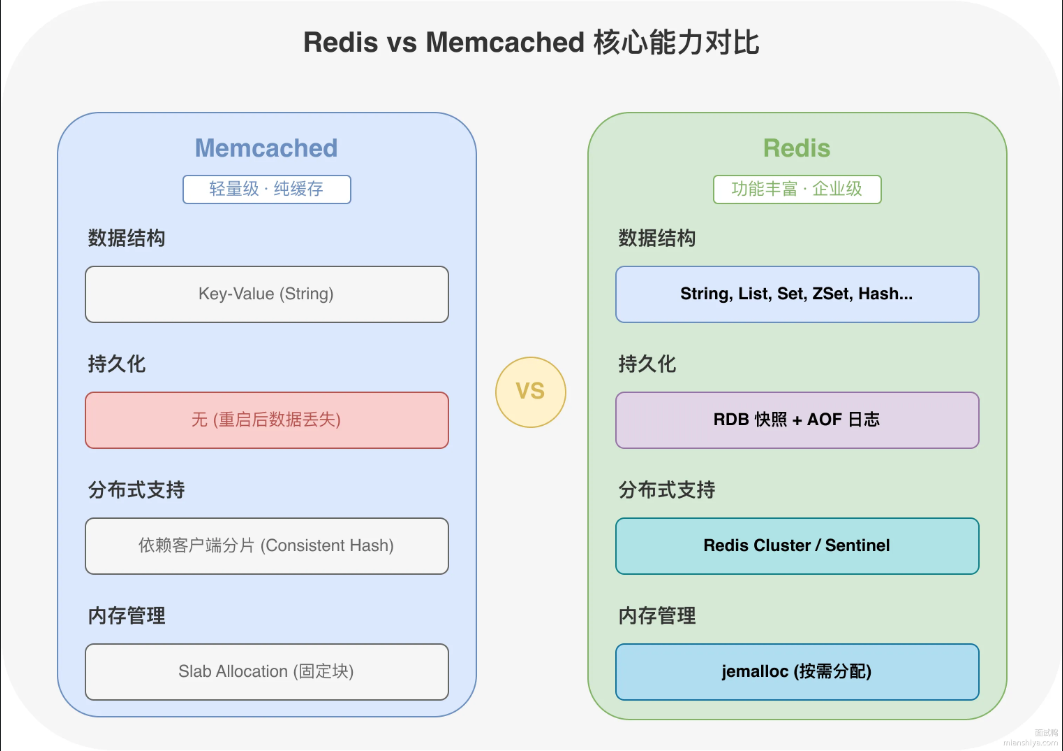
Redis和Memcached有哪些区别
Redis 和 Memcached 都是内存级别的缓存系统,但 Redis 功能更丰富,Memcached 更轻量纯粹。数据结构方面,Redis 支持 String、List、Set、Sorted Set、Hash 五种基础结构,还有 HyperLogLog、Bitmap、Geo 等扩展类型;Memcached 只支持简单的 key-value 字符串存储。
持久化方面,Redis 提供 RDB 快照和 AOF日志两种方式,服务重启数据还在;Memcached 压根没有持久化,一重启数据全没了。
分布式方面,Redis 原生支持主从复制、哨兵和 Redis Cluster 集群模式;Memcached 服务端没有分布式逻辑,分片全靠客户端自己算hash 来分发。
功能方面,Redis 支持发布订阅、Lua脚本、事务、Stream消息队列等;Memcached 就是纯粹的缓存,啥扩展功能都没有。
Redis支持事务吗
我们都知道MySQL的事务机制,那Redis和MySQL的事务由什么区别呢?
Redis事务:只保证命令打包执行不被其他客户端插队,不支持回滚
Redis事务用MULTI,EXEC,WATCH,DISCARD四个命令实现:
- multi开启事务,之后发的命令不会立刻执行,而是进入一个队列排队
- 队列里可以塞任意多条命令,Redis会回复queued标识入队成功
- EXEC一次性把队列里的命令全部执行,期间不会被其他客户端的命令打断
- 如果中途不想执行了,用DISCARD丢弃整个队列
- WATCH可以在MULTI之前监视某些key,如果这些key在EXEC之前被别人改了,整个事务作废。
一句话总结:
Redis 事务通过 MULTI 开启,将命令入队,最后用 EXEC 一次性顺序执行,期间不会被其他命令打断。
注意的是:MySQL事务执行到一半出错可以回滚,Redis不行。Redis事务里某条命令执行失败剩下的命令照样继续跑,已经执行的也不会撤销
在实际工程中,一般不会使用Redis事务,选择lua脚本更好用。
拓展
Redis事务与MySQL事务的区分
| 特性 | Redis 事务 | MySQL 事务 |
|---|---|---|
| 原子性 | 打包执行不被打断,但不支持回滚 | 完整的原子性,支持回滚 |
| 隔离性 | 单线程串行执行,天然隔离 | 支持 4 种隔离级别 |
| 持久性 | 取决于 AOF 配置 | 通过 redo log 保证 |
| 一致性 | 不保证,部分失败不回滚 | 通过回滚保证 |
| 性能 | 极高,无额外开销 | 需要记录日志,有开销 |