目录
[1.1 磁盘、服务器、机柜、机房](#1.1 磁盘、服务器、机柜、机房)
[1.2 磁盘的物理结构](#1.2 磁盘的物理结构)
[1.3 磁盘的存储结构](#1.3 磁盘的存储结构)
[1.4 磁盘的逻辑结构](#1.4 磁盘的逻辑结构)
[1.4.1 理解过程](#1.4.1 理解过程)
[1.4.2 真实过程](#1.4.2 真实过程)
[1.5 CHS && LBA地址](#1.5 CHS && LBA地址)
[2. 引入文件系统](#2. 引入文件系统)
[2.1 引入 "块" 概念](#2.1 引入 "块" 概念)
[2.2 引入 "分区" 概念](#2.2 引入 "分区" 概念)
[2.3 引入 "inode" 概念](#2.3 引入 "inode" 概念)
[3. ext2 文件系统](#3. ext2 文件系统)
[3.1 宏观认识](#3.1 宏观认识)
[3.2 Block Group](#3.2 Block Group)
[3.3 块组内部结构](#3.3 块组内部结构)
[3.3.1 超级块 (Super Block)](#3.3.1 超级块 (Super Block))
[3.3.2 GDT (Group Descriptor Table)](#3.3.2 GDT (Group Descriptor Table))
[3.3.3 块位图(Block Bitmap)](#3.3.3 块位图(Block Bitmap))
[3.3.4 inode位图(Inode Bitmap)](#3.3.4 inode位图(Inode Bitmap))
[3.3.5 i节点表(Inode Table)](#3.3.5 i节点表(Inode Table))
[3.3.6 Data block](#3.3.6 Data block)
[3.4 inode 和 Datablock的映射](#3.4 inode 和 Datablock的映射)
[3.5 目录与文件名](#3.5 目录与文件名)
[3.6 路径缓存](#3.6 路径缓存)
[3.7 挂载分区](#3.7 挂载分区)
[3.7.1 一个实验](#3.7.1 一个实验)
[3.7.2 一个结论:](#3.7.2 一个结论:)
[3.8 文件系统总结](#3.8 文件系统总结)
[4. 软硬连接](#4. 软硬连接)
[4.1 软链接](#4.1 软链接)
[4.2 硬链接](#4.2 硬链接)
[4.3 软硬链接的区别](#4.3 软硬链接的区别)
[4.3 软硬链接的应用场景(重点)](#4.3 软硬链接的应用场景(重点))
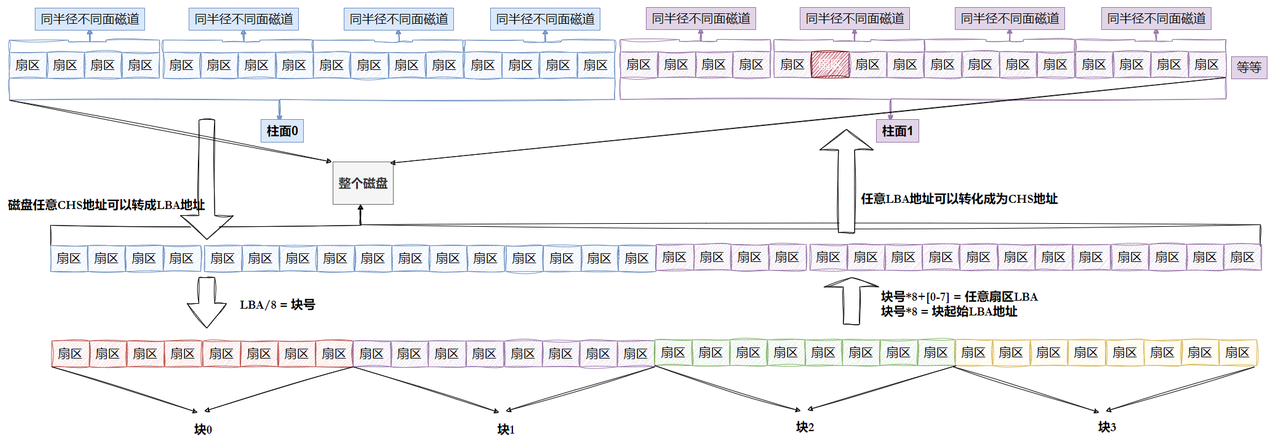
1.理解硬件
1.1 磁盘、服务器、机柜、机房







小公司也要用网呀!也要有自己的网站,所以有了大公司提供的云服务!!
磁盘如何存储数据??
计算机只认识二进制,有可能用电信号的有无来表示0、1,在传输数据时,有可能用电信号的高低电频来表示0、1,在磁盘中,为什么叫磁盘?简单的理解:计算机只认识二进制,往磁盘中存储的数据都是二进制的,但是二进制也是我们加工处理之后的说法。什么又叫做二进制??磁盘的光滑的盘面是由上百亿个磁铁拼在一起,打磨光滑,叫做磁盘。规定磁铁南极为0,北极为1。在磁盘中写入1,在特定的小磁铁由南极变为北极,清0就由北极变为南极。用磁头修改磁盘上的数据就是更改磁盘中的某块南北极朝向的问题。
扔磁盘的时候必须将数据销毁了,才可以被淘汰。要保证数据安全。只是将磁盘的数据清空是不够的,厂家可以恢复出来,深度清理磁盘是通过火烧!!还有就是进行对磁盘整盘格式化,全写0或全写1。
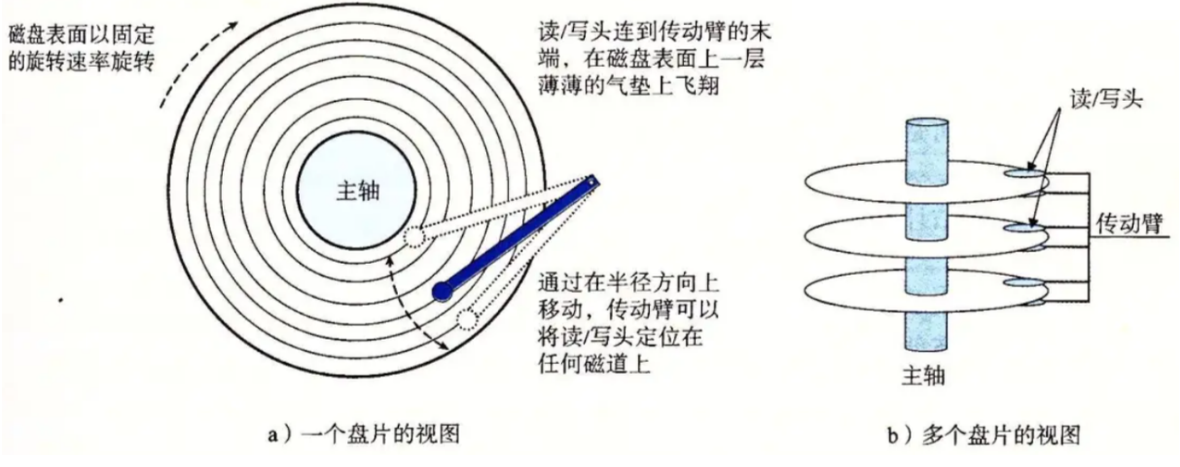
1.2 磁盘的物理结构

磁盘在高速旋转的同时,磁头也是在左右来回摆动的,但是磁盘和磁头是没有进行任何的接触的!!!
1.3 磁盘的存储结构
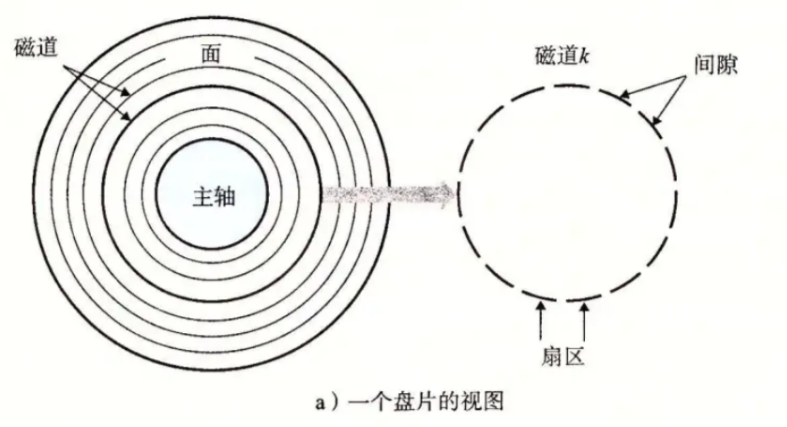

扇区是OS访问磁盘设备的基本单位:一般为512字节!!磁盘被称为是块设备!!
60%的磁盘最内道的和最外道的磁道上的扇区个数是一样的。还有40%是新技术。本篇文章认为扇区个数是一样的,方便计算!!可以理解为最内道和最外道的疏密程度不一样,所以导致扇区个数一样。所以可以将高频访问的数据放在磁盘的内侧,数据更密集。访问的数据不怎么高频可以放在外侧。
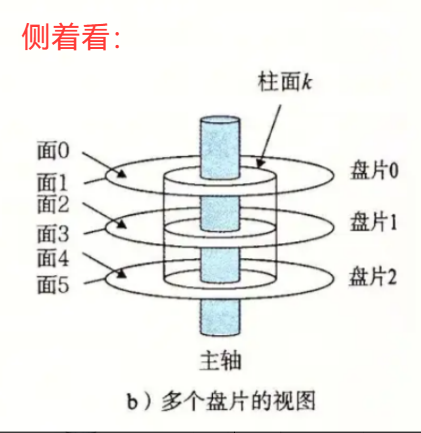
一个盘片两面,所以上面的图是三盘六面。正反都有数据。
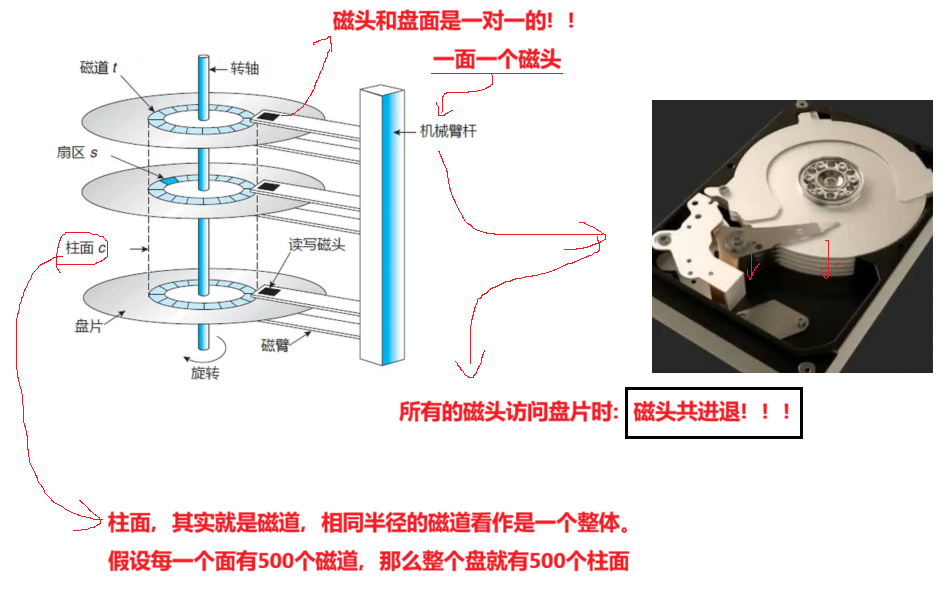

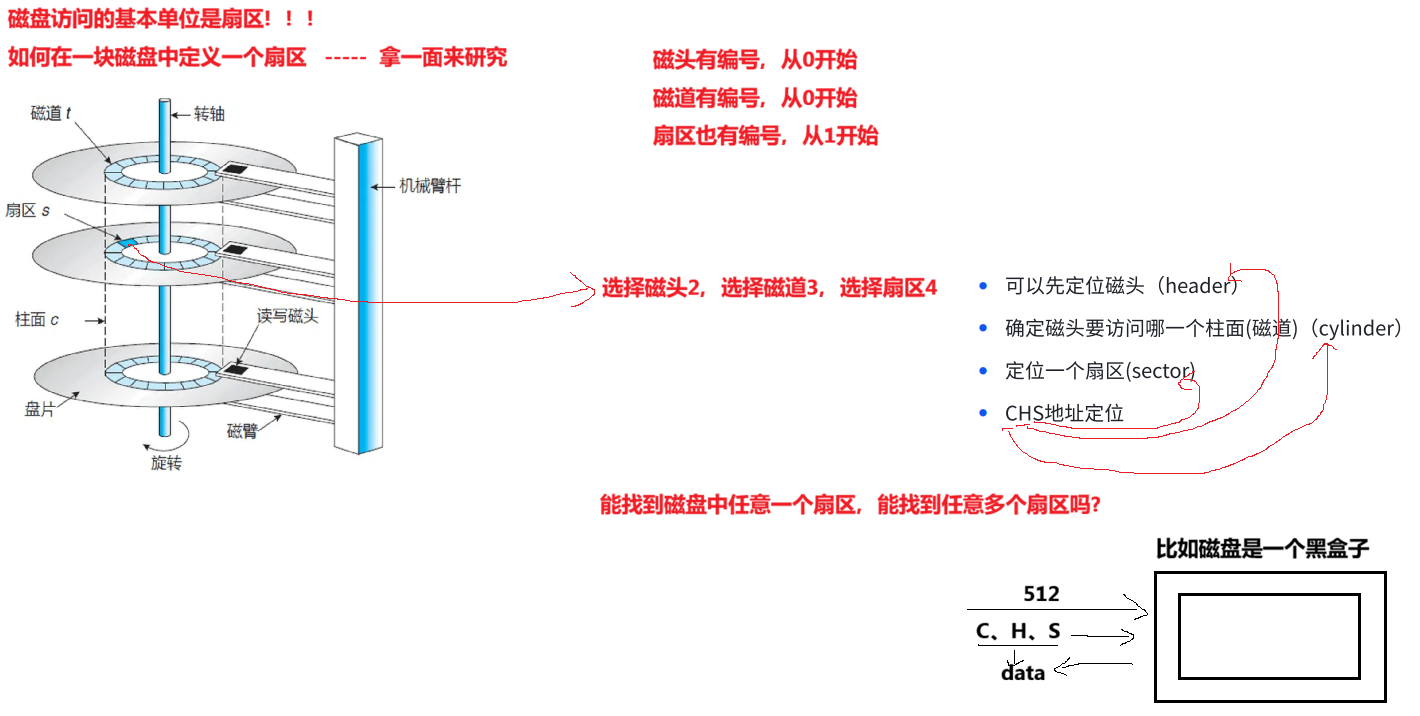
等下会谈到将存储结构进行一个抽象,不再采用CHS这样的寻址方式,这样的寻址方式太老了,要求OS做的工作太多了。
文件 = 内容 + 属性,都是数据,无非就是占据哪几个扇区的问题!所以能定位多个扇区!!!
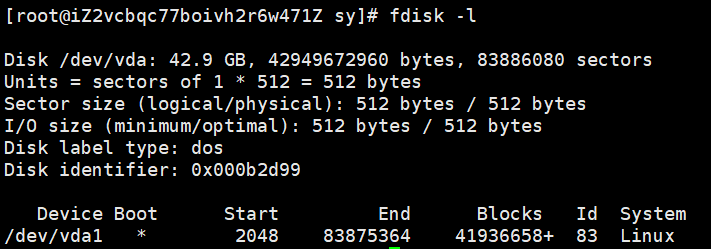
- 扇区是从磁盘读出和写入信息的最小单位,通常大小为 512 字节。
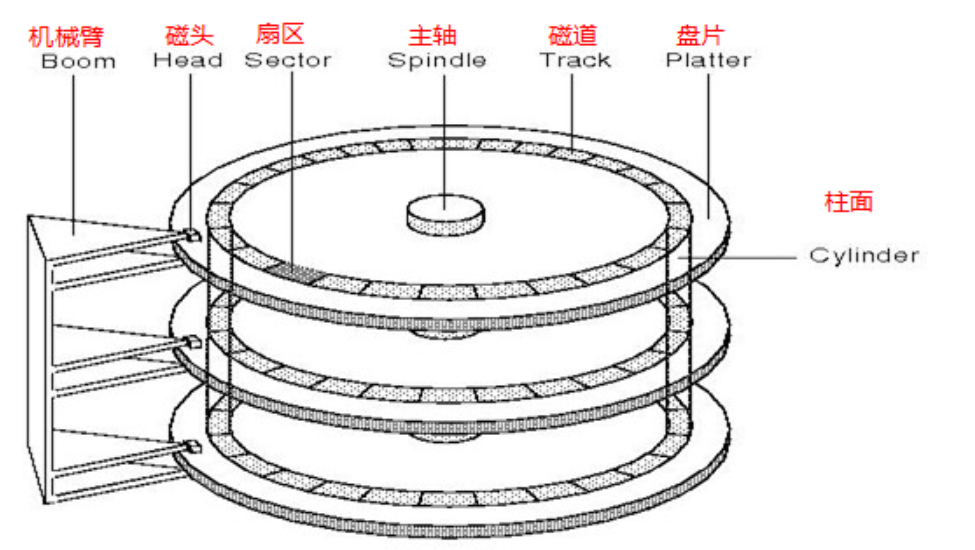
- 磁头(head)数:每个盘片⼀般有上下两⾯,分别对应1个磁头,共2个磁头
- 磁道(track)数:磁道是从盘片外圈往内圈编号0磁道,1磁道...,靠近主轴的同⼼圆⽤于停靠磁头,不存储数据
- 柱⾯(cylinder)数:磁道构成柱⾯,数量上等同于磁道个数
- 扇区(sector)数:每个磁道都被切分成很多扇形区域,每道的扇区数量相同
- 圆盘(platter)数:就是盘片的数量
- 磁盘容量=磁头数 × 磁道(柱⾯)数 × 每道扇区数 × 每扇区字节数
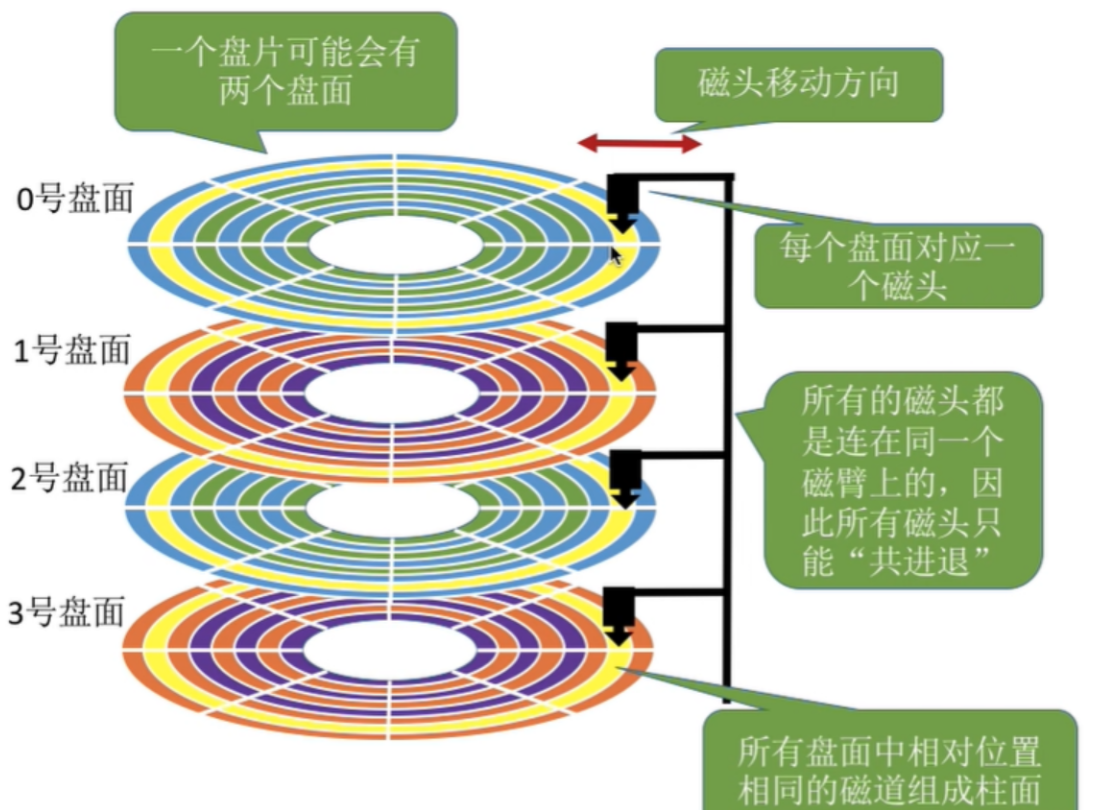
- 细节:传动臂上的磁头是共进退的(这点比较重要,后面会说明)
柱面(cylinder),磁头(head),扇区(sector),显然可以定位数据了,这就是数据定位(寻址)方式之⼀,CHS寻址方式。
CHS寻址:
对早期的磁盘非常有效,知道用哪个磁头,读取哪个柱⾯上的第几扇区就可以读到数据了。但是CHS模式⽀持的硬盘容量有限,因为系统⽤8bit来存储磁头地址,用10bit来存储柱面地址址,用6bit来存储扇区地址,而⼀个扇区共有512Byte,这样使用CHS寻址⼀块硬盘最大容量为256 * 1024 * 63 * 512B = 8064 MB(1MB = 1048576B)(若按1MB=1000000B来算就是8.4GB)
1.4 磁盘的逻辑结构
1.4.1 理解过程
磁带:

磁带上面的磁带条就是存储数据的介质,我们可以把磁带 "拉直",形成线性结构

那么磁盘本质上虽然是硬质的,但是逻辑上我们可以把磁盘想象成为卷在一起的磁带,那么磁盘的逻辑存储结构我们也可以类似于:
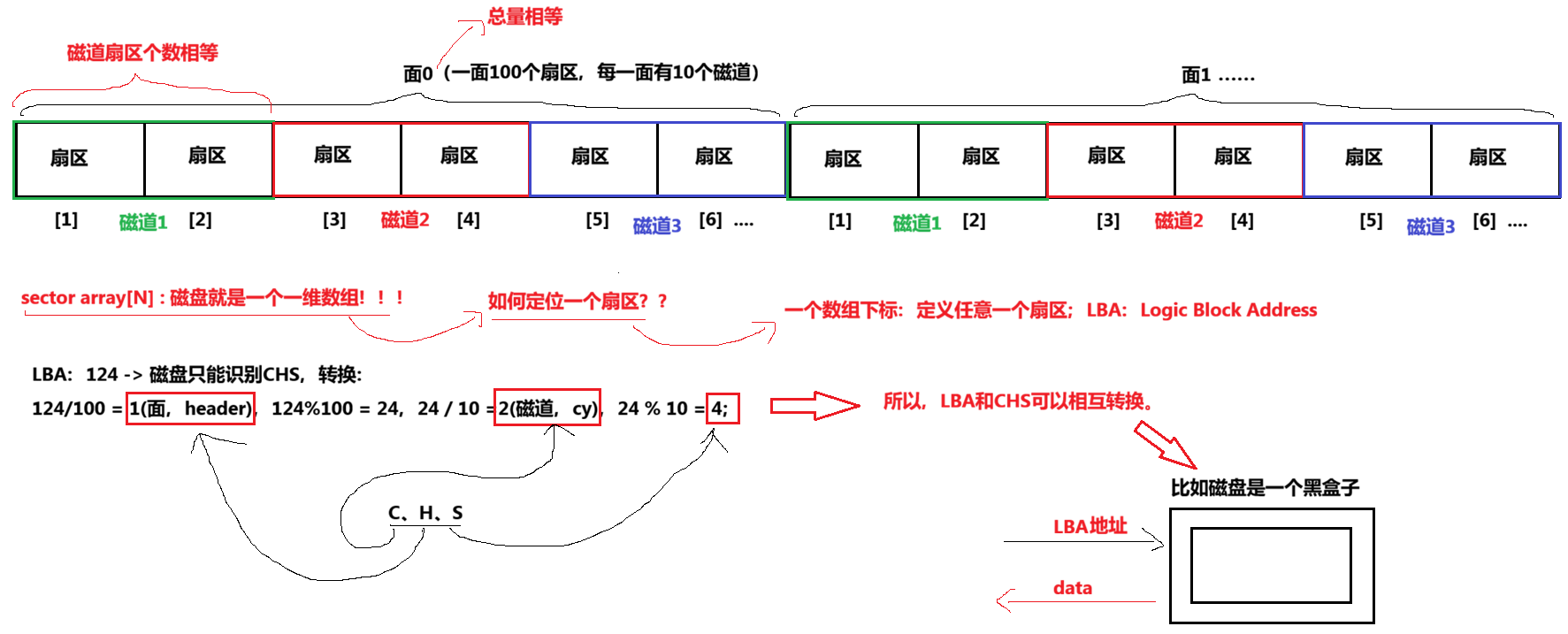
当代磁盘用的都是LBA地址,给磁盘LBA地址,磁盘内部会将LBA地址转为CHS,将数据写到一个扇区上,只要能写到一个扇区上就能够写到100个扇区里。磁盘的每个扇区大小如果为512的话,OS开机的时候只需要识别到磁盘的总容量是多少,瞬间就能够计算出一共有多少个LBA,每一个扇区的LBA地址是多少?

1.4.2 真实过程
一个细节:传动臂上的磁头是共进退的
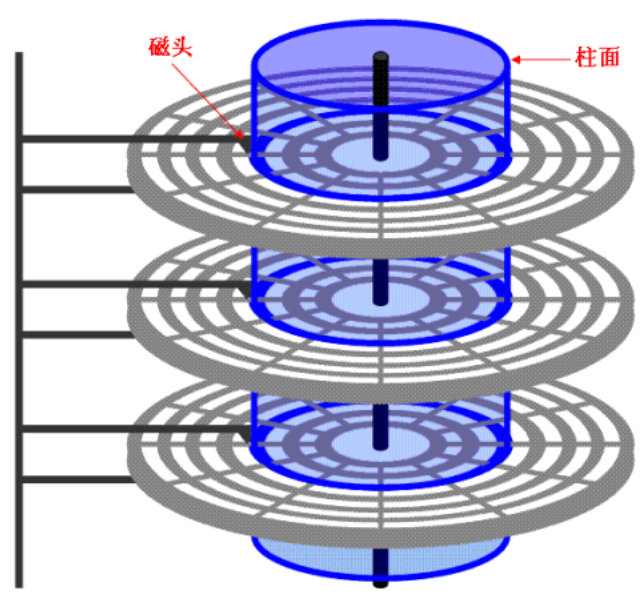
柱面是一个逻辑上的概念,其实就是每一面上,相同半径的磁道逻辑上构成柱面。
所以,磁盘物理上分了分多面(纵向的柱面),但是在我们看来,逻辑上,磁盘整体是由 "柱面"卷起来的。有点向山楂卷:

所以,磁盘的真实情况是:
磁道:
某一盘面的某一个磁道展开:

即:一维数组
柱面:
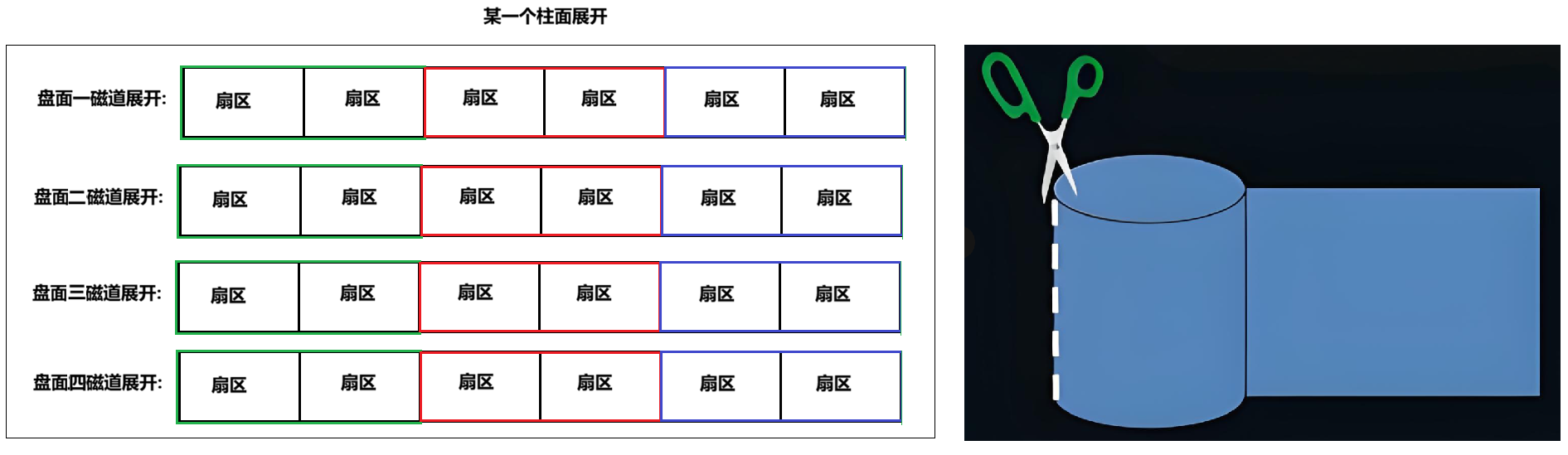
柱面上的每个磁道,扇区个数是一样的
这就是二维数组
磁盘:
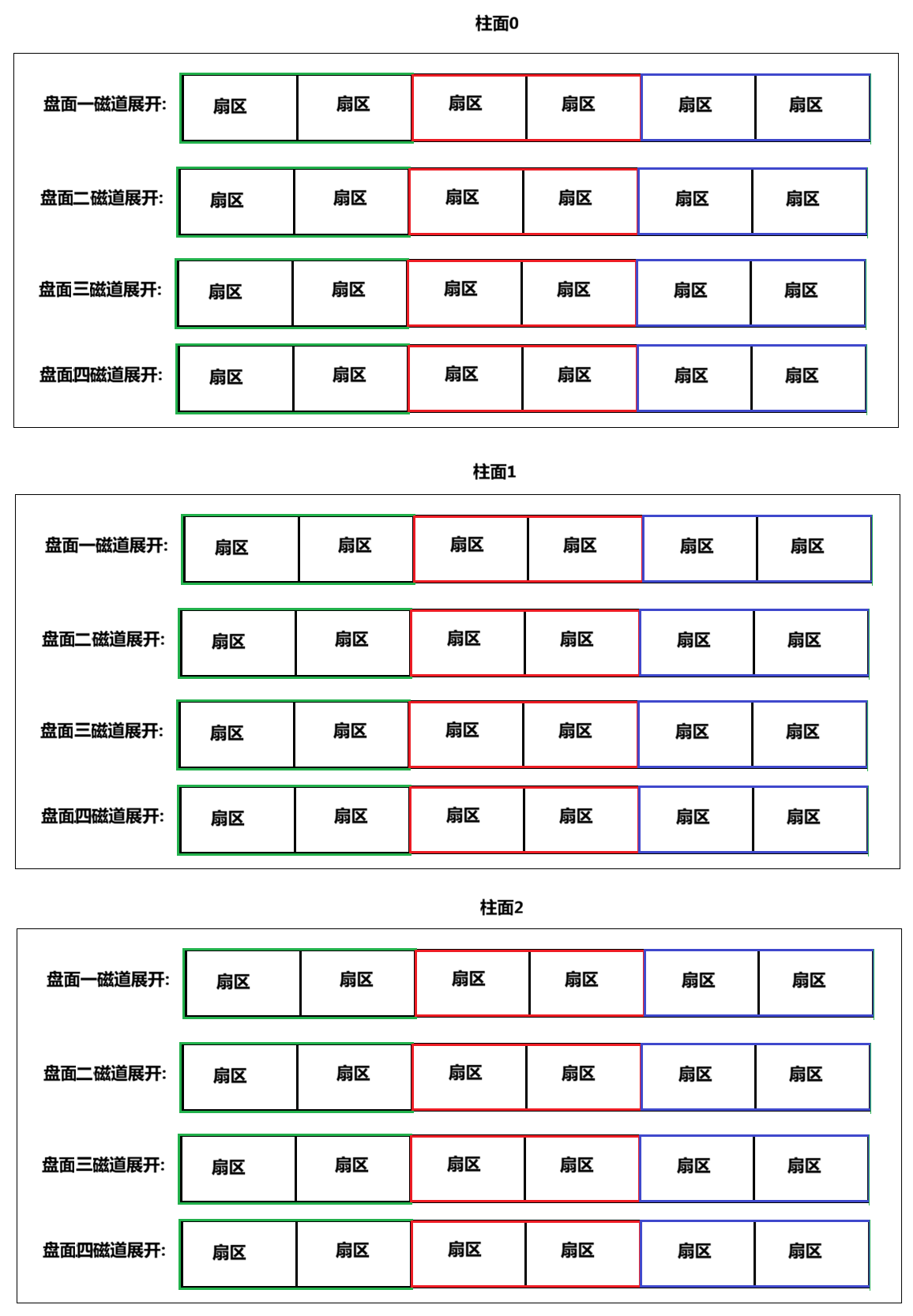
磁盘,就是一个三维数组(sector array )!!!所以定位磁盘上的任意一个扇区是通过3个下标,C,H,S -> 三维数组的下标(顺序也是如此)!!!即:sector array 柱面 磁头 扇区
即:
sector array C H S !!!
重要结论1:
磁盘的本质是一个三维数组!!!


将整个磁盘想象成一个线性结构,每一个扇区都有一个下标,对应的地址是LBA地址,其实就是线性地址!!!将LBA地址转化为CHS地址,本质就是将一维数组的下标,转换成为3个数字!!!
OS只需要使用LBA就可以了!!!LBA地址转换成CHS地址,CHS如何转换成为LBA地址,这个工作是磁盘自己来做的!
重要结论2:
磁盘,就是一个以sector为单位的一维数组!!!
1.5 CHS && LBA地址
LBA转成CHS:
- 柱⾯号C = LBA // (磁头数*每磁道扇区数)【就是单个柱⾯的扇区总数】
- 磁头号H = (LBA % (磁头数*每磁道扇区数)) // 每磁道扇区数扇区号S = (LBA % 每磁道扇区数) + 1
- "//": 表示除取整
CHS转成LBA:
- 磁头数*每磁道扇区数 = 单个柱⾯的扇区总数
- LBA = 柱⾯号C*单个柱⾯的扇区总数 + 磁头号H*每磁道扇区数 + 扇区号S - 1
- 即:LBA = 柱面号C*(磁头数*每磁道扇区数) + 磁头号H*每磁道扇区数 + 扇区号S - 1
- 扇区号通常是从1开始的,而在LBA中,地址是从0开始的柱面和磁道都是从0开始编号的
- 总柱面,磁道个数,扇区总数等信息,在磁盘内部会⾃动维护,上层开机的时候,会获取到这些参数。
2. 引入文件系统
2.1 引入 "块" 概念
访问磁盘时的基本单位是512个字节,磁盘是典型的块设备,OS读取磁盘时,OS不会按照硬件的扇区个数为单位来读。
理由一:扇区512字节为单位太小了,磁盘和内存之间IO时效率较低
理由二:OS不想硬编码,不想每次读磁盘都读512字节,OS规定访问磁盘的时候,读取磁盘的时候,必须把磁盘划分为一个一个的块,一个个"块"是由格式化的时候决定的,并且不可以更改,最常见的大小是4KB,即连续8个扇区组成一个 "块","块"是文件存取的最小单位。
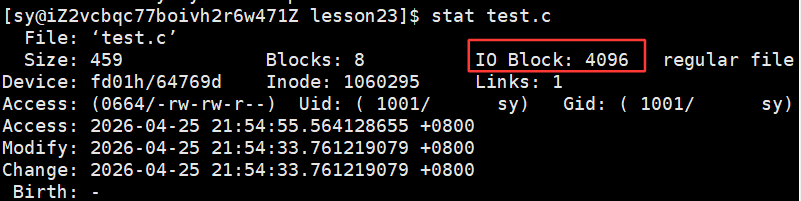
一般的文件系统和文件交互时都是以4KB为单位的。4KB就是8个扇区组成的一个 "块"。
注意:
- 磁盘就是⼀个三维数组,我们把它看待成为⼀个"⼀维数组",数组下标就是LBA,每个元素都是扇区
- 每个扇区都有LBA,那么8个扇区⼀个块,每⼀个块的地址我们也能算出来。
- 知道LBA:块号 = LBA/8
- 知道块号:LAB=块号*8 + n. (n是块内第几个扇区)
所以:
OS看待磁盘,就认为磁盘是一个块设备,每一个块都有下标!!!
文件系统的角度(以4KB为单位):磁盘当作 block arrayN ---> 磁盘是块设备 !!!
块号是由8个LBA地址构成的。磁盘被当作是一个块设备,由n个块构成的。磁盘总容量 / 4KB,就知道整个磁盘有多少数据块,然后拿着块号,想上找,找到LBA地址,再次向上找CHS,就可以访问到一个或多个扇区。


物理内存/外设,看起来是外设,但是OS和外设之间进行沟通的时候,也有他的寄存器,可以通过它所对应的寄存器,写入它的控制命令,地址,数据硬件电路自动会进行对设备的访问。外设比较慢尤其是磁盘,是因为数据寄存器、地址寄存器数量有点少,内部又是机械设备,进行IO的时候,很多时候都要等磁盘就绪,这就是进程发起IO后,进程会处于短暂的D状态。
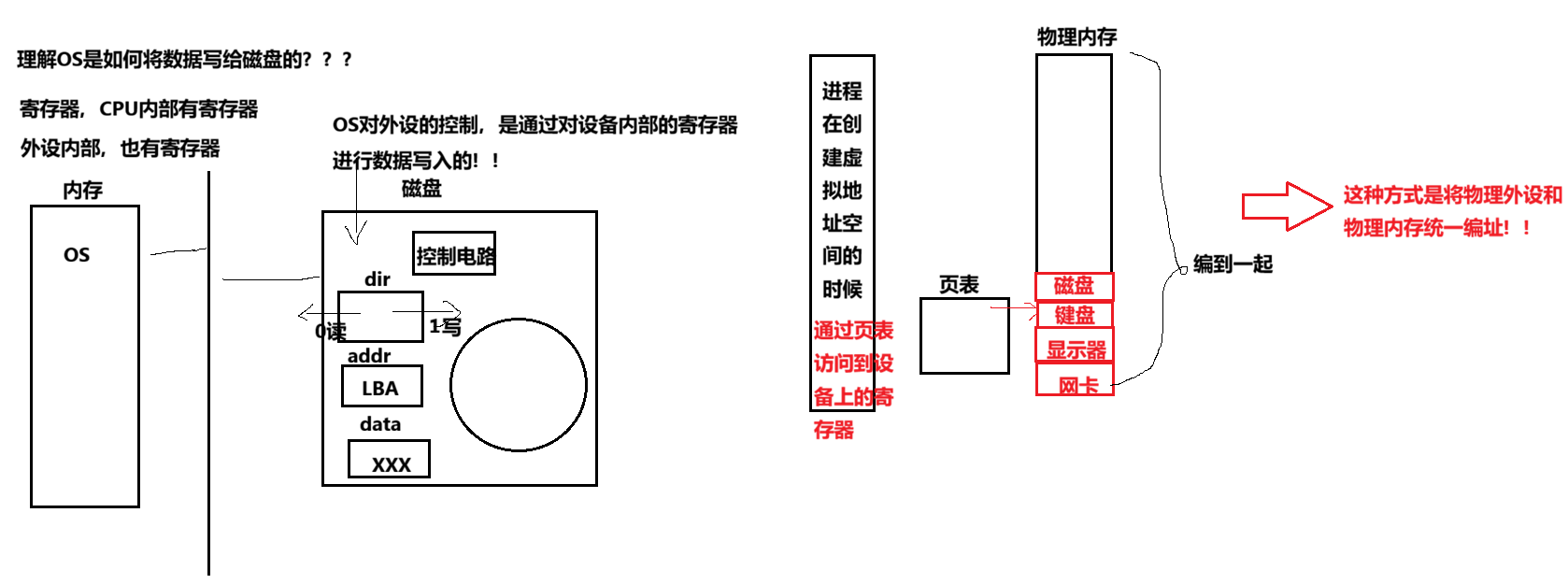
2.2 引入 "分区" 概念
其实磁盘是可以被分成多个分区(partition)的,windows上C盘,D盘,其实是一块物理盘对应的分区!!!
柱面是分区的最小单位,柱面大小一致,扇区个位⼀致,那么其实只要知道每个分区的起始和结束柱面号,知道每⼀个柱面多少个扇区,那么该分区多大,其实和解释LBA是多少也就清楚了。
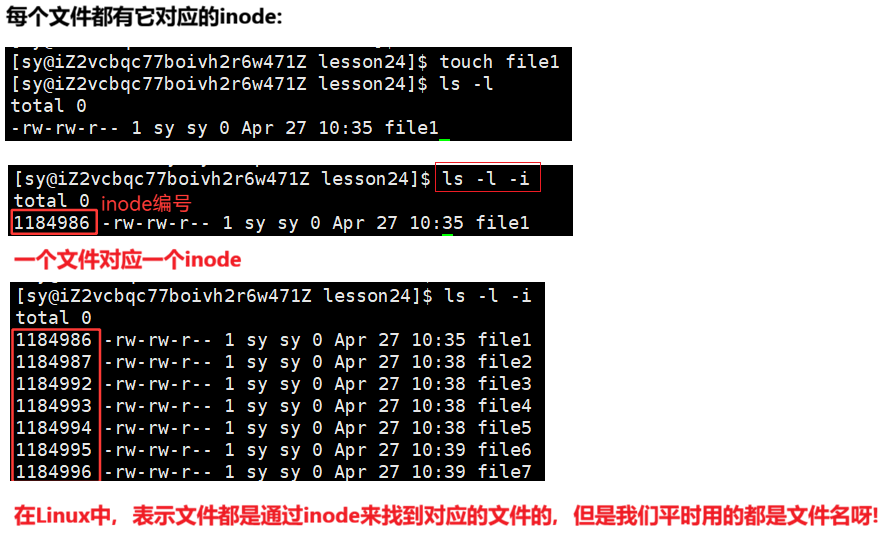
2.3 引入 "inode" 概念
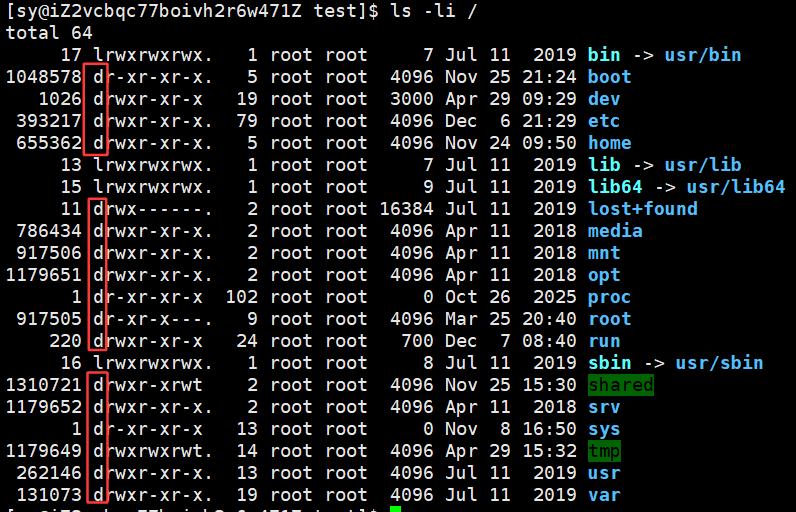
之前我们说过 文件=数据+属性 ,我们使⽤ ls -l 的时候看到的除了看到文件名,还能看到文件元数据(属性)。
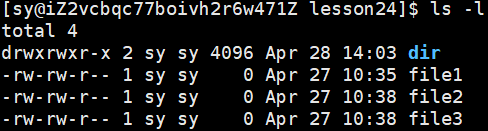
每行包含7列:
- 模式
- 硬链接数
- 文件所有者
- 组
- 大小
- 最后修改时间
- 文件名
其实这个信息除了通过这种⽅式来读取,还有⼀个stat命令能够看到更多信息
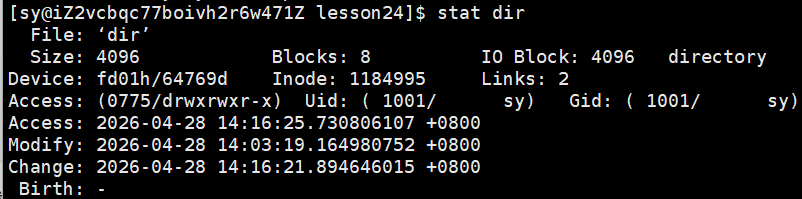
到这我们要思考⼀个问题,文件数据都储存在"块"中,那么很显然,我们还必须找到⼀个地方储存文件的元信息(属性信息),比如文件的创建者、⽂件的创建日期、文件的大小等等。这种储存文件元信息的区域就叫做inode,中文译名为"索引节点"。
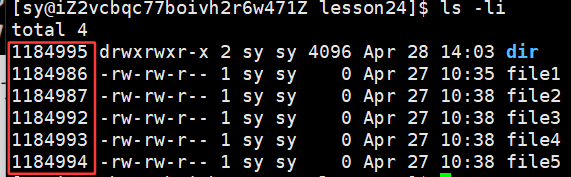
所以⼀个文件的属性inode长什么样子呢?
cpp
/*
* Structure of an inode on the disk
*/
struct ext2_inode {
__le16 i_mode; /* File mode */
__le16 i_uid; /* Low 16 bits of Owner Uid */
__le32 i_size; /* Size in bytes */
__le32 i_atime; /* Access time */
__le32 i_ctime; /* Creation time */
__le32 i_mtime; /* Modification time */
__le32 i_dtime; /* Deletion Time */
__le16 i_gid; /* Low 16 bits of Group Id */
__le16 i_links_count; /* Links count */
__le32 i_blocks; /* Blocks count */
__le32 i_flags; /* File flags */
union {
struct {
__le32 l_i_reserved1;
} linux1;
struct {
__le32 h_i_translator;
} hurd1;
struct {
__le32 m_i_reserved1;
} masix1;
} osd1; /* OS dependent 1 */
__le32 i_block[EXT2_N_BLOCKS];/* Pointers to blocks */
__le32 i_generation; /* File version (for NFS) */
__le32 i_file_acl; /* File ACL */
__le32 i_dir_acl; /* Directory ACL */
__le32 i_faddr; /* Fragment address */
union {
struct {
__u8 l_i_frag; /* Fragment number */
__u8 l_i_fsize; /* Fragment size */
__u16 i_pad1;
__le16 l_i_uid_high; /* these 2 fields */
__le16 l_i_gid_high; /* were reserved2[0] */
__u32 l_i_reserved2;
} linux2;
struct {
__u8 h_i_frag; /* Fragment number */
__u8 h_i_fsize; /* Fragment size */
__le16 h_i_mode_high;
__le16 h_i_uid_high;
__le16 h_i_gid_high;
__le32 h_i_author;
} hurd2;
struct {
__u8 m_i_frag; /* Fragment number */
__u8 m_i_fsize; /* Fragment size */
__u16 m_pad1;
__u32 m_i_reserved2[2];
} masix2;
} osd2; /* OS dependent 2 */
};
/*
* Constants relative to the data blocks
*/
#define EXT2_NDIR_BLOCKS 12
#define EXT2_IND_BLOCK EXT2_NDIR_BLOCKS
#define EXT2_DIND_BLOCK (EXT2_IND_BLOCK + 1)
#define EXT2_TIND_BLOCK (EXT2_DIND_BLOCK + 1)
#define EXT2_N_BLOCKS (EXT2_TIND_BLOCK + 1)
备注:EXT2_N_BLOCKS = 15再次注意:
- 文件名属性并未纳入到inode数据结构内部
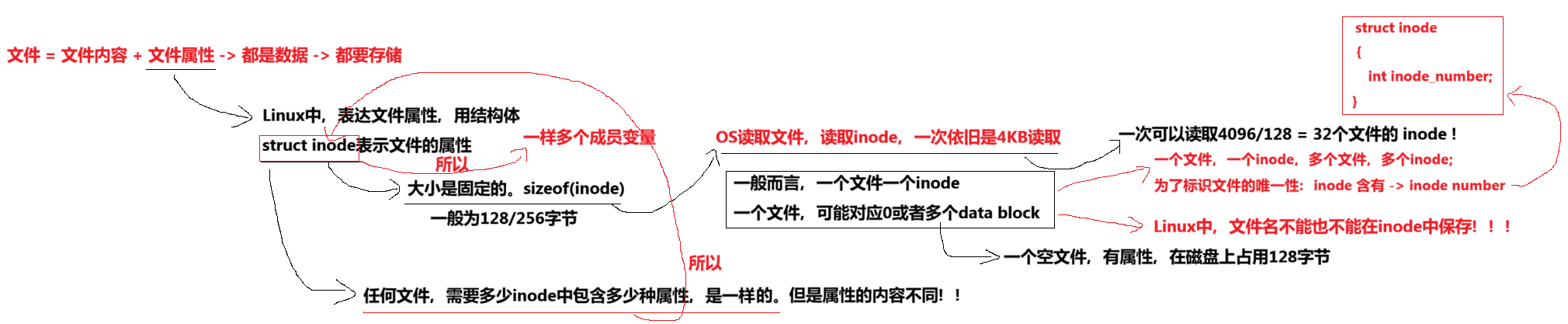
- inode的大小一般是128字节或者256,我们后面统⼀128字节
- 任何文件的内容大小可以不同,但是属性大小⼀定是相同的
问题:
- 我们已经知道硬盘是典型的"块"设备,操作系统读取硬盘数据的时候,读取的基本单位是"块"。"块"又是硬盘的每个分区下的结构,难道"块"是随意的在分区上排布的吗?那要怎么找到"块"呢?还有就是上⾯提到的存储⽂件属性的inode,又是如何放置的呢?
- 文件系统就是为了组织管理这些的!!
3. ext2 文件系统
3.1 宏观认识
所有的准备⼯作都已经做完,是时候认识下文件系统了。我们想要在硬盘上储⽂件,必须先把硬盘格式化为某种格式的⽂件系统,才能存储⽂件。文件系统的目的就是组织和管理硬盘中的⽂件。在Linux 系统中,最常见的是 ext2 系列的⽂件系统。其早期版本为 ext2,后来又发展出 ext3 和 ext4。ext3 和 ext4 虽然对 ext2进行了增强,但是其核心设计并没有发生变化,我们仍是以较老的 ext2 作为演示对象。
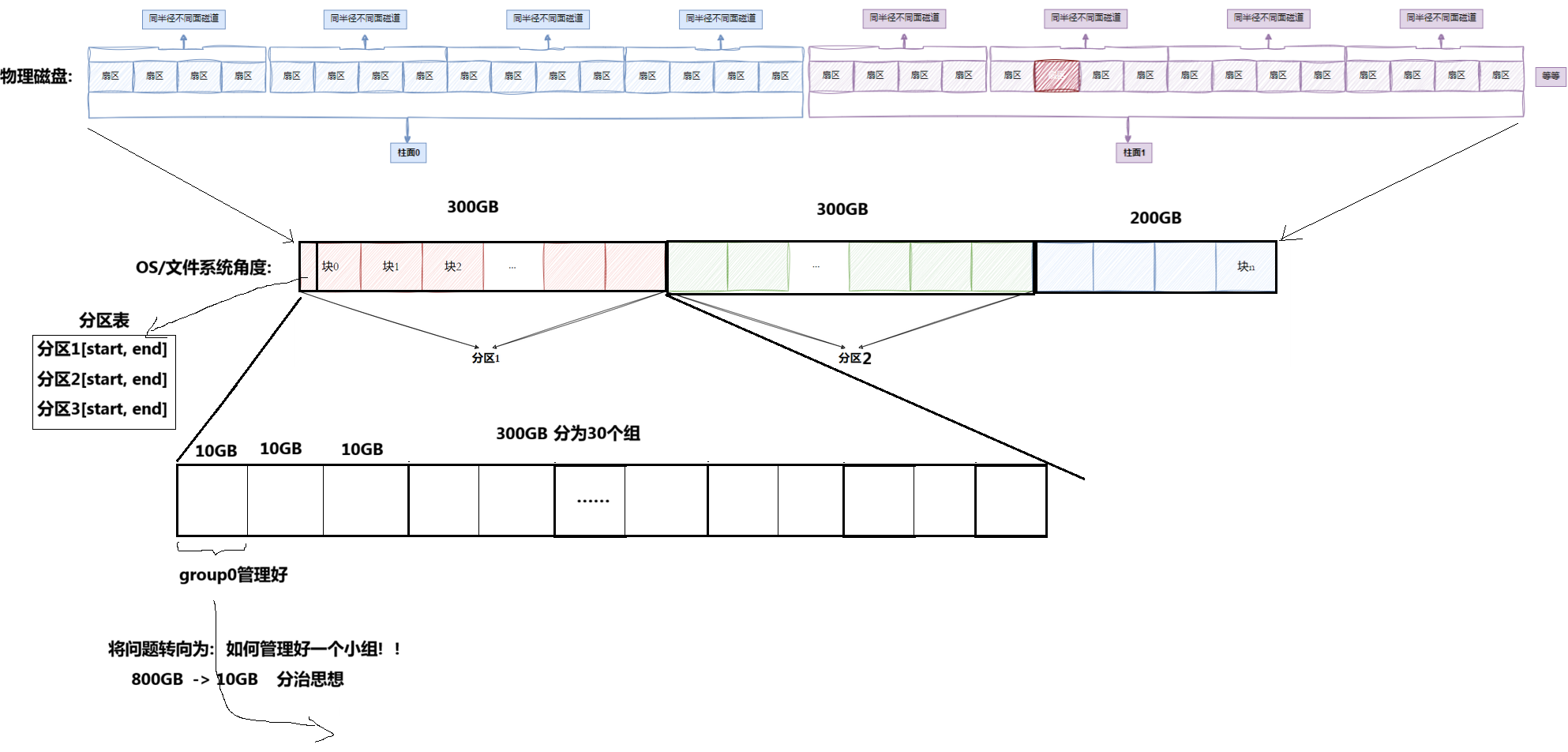
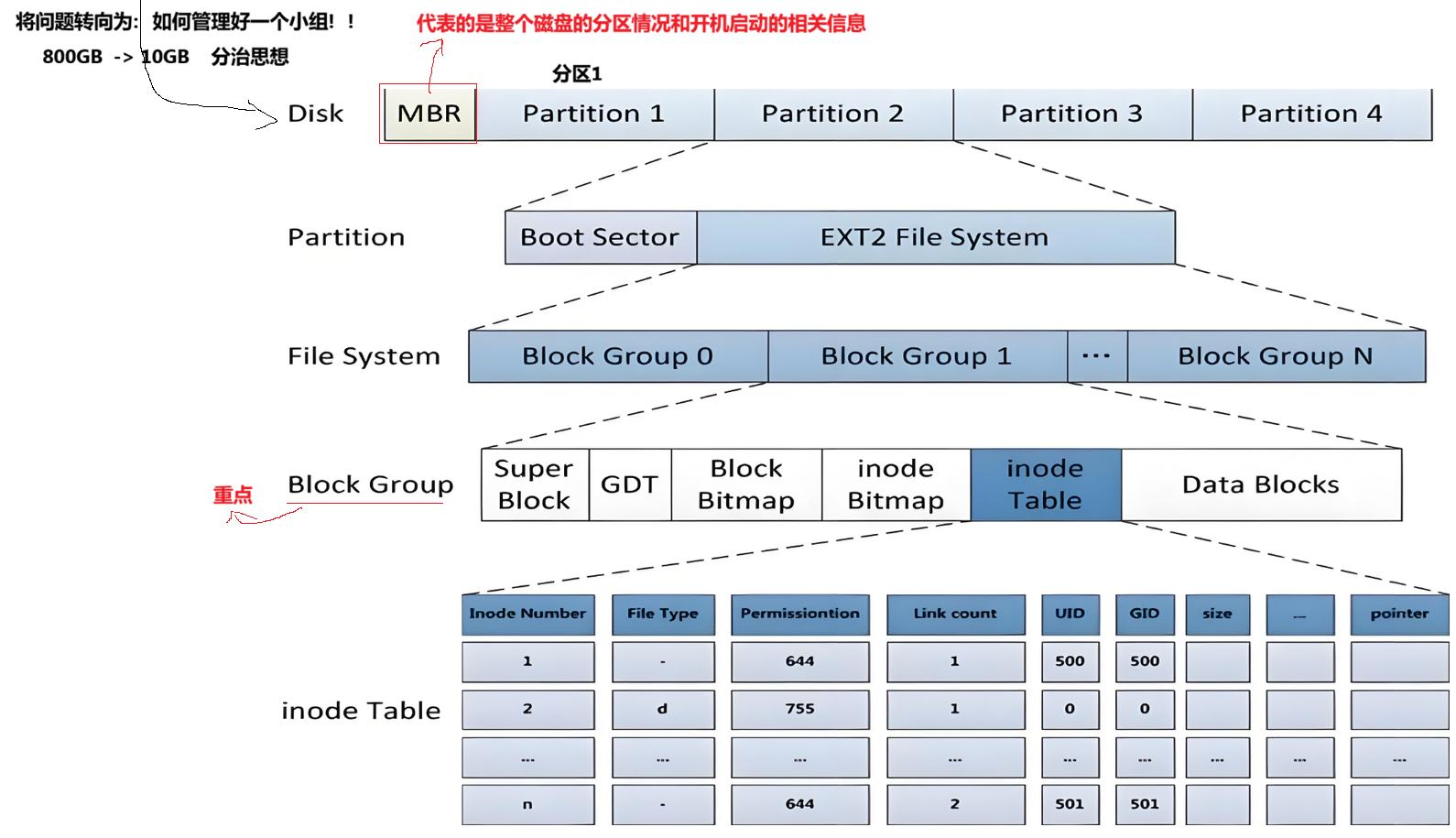
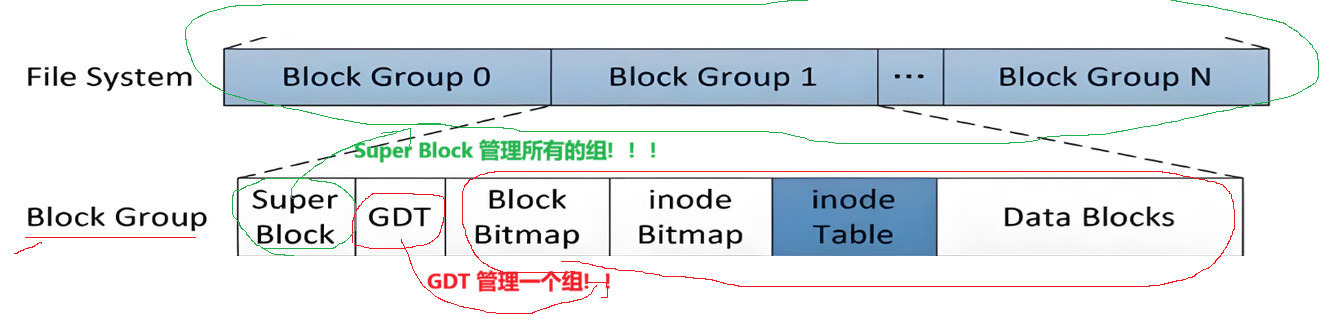
ext2⽂件系统将整个分区划分成若干个同样大小的块组 (Block Group),如下图所示。只要能管理⼀个分区就能管理所有分区,也就能管理所有磁盘文件。
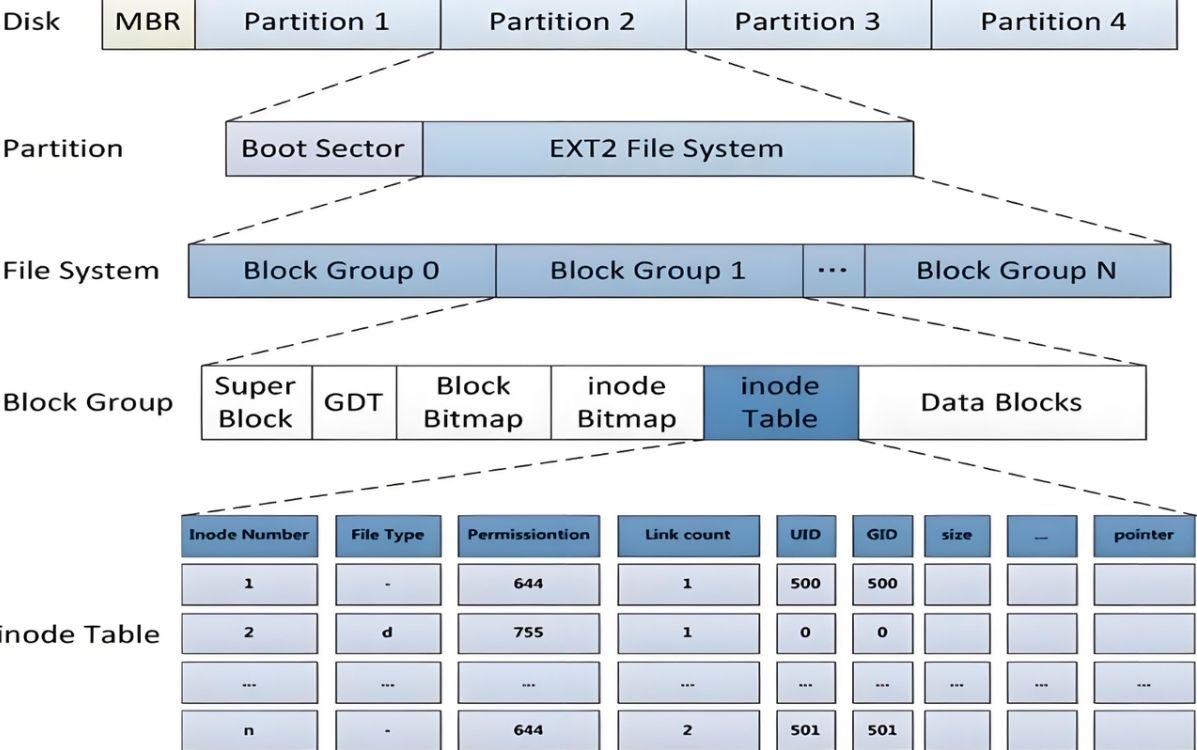
上图中启动块(Boot Block/Sector)的大小是确定的,为1KB,由PC标准规定,⽤来存储磁盘分区信息和启动信息,任何文件系统都不能修改启动块。启动块之后才是ext2文件系统的开始。
3.2 Block Group
ext2文件系统会根据分区的大小划分为数个Block Group。而每个Block Group都有着相同的结构组成。
3.3 块组内部结构
3.3.1 超级块 (Super Block)
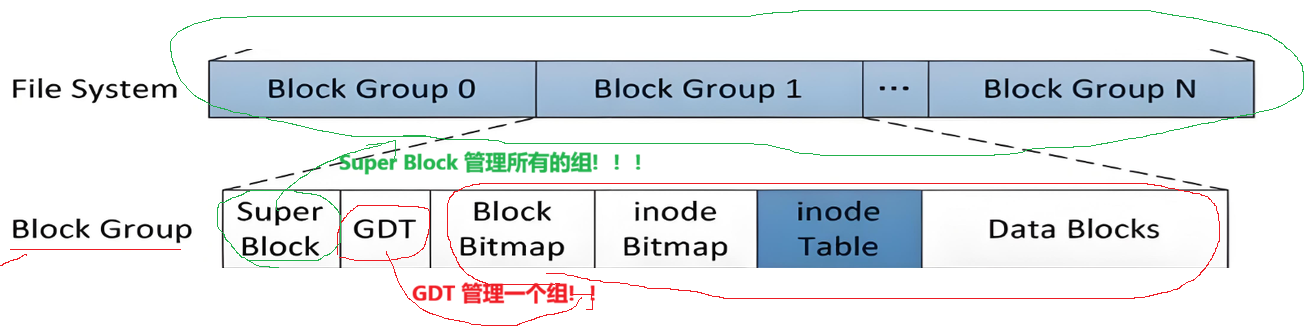
存放文件系统本身的结构信息,描述整个分区的文件系统信息。记录的信息主要有:block 和 inode 的总量,未使用的 block 和 inode 的数量,一个block 和 inode 的大小,最近一次挂载的时间,最近一次写入数据的时间,最近一次检验磁盘的时间等其它文件系统的相关信息。Super Block 的信息被破坏,可以说整个文件系统结构就被破坏了。
Super Block 描述的是整个文件系统所对应的宏观管理信息;GDT 管理一个组:
cpp
/*
* Structure of the super block
*/
struct ext2_super_block {
__le32 s_inodes_count; /* Inodes count */
__le32 s_blocks_count; /* Blocks count */
__le32 s_r_blocks_count; /* Reserved blocks count */
__le32 s_free_blocks_count; /* Free blocks count */
__le32 s_free_inodes_count; /* Free inodes count */
__le32 s_first_data_block; /* First Data Block */
__le32 s_log_block_size; /* Block size */
__le32 s_log_frag_size; /* Fragment size */
__le32 s_blocks_per_group; /* # Blocks per group */
__le32 s_frags_per_group; /* # Fragments per group */
__le32 s_inodes_per_group; /* # Inodes per group */
__le32 s_mtime; /* Mount time */
__le32 s_wtime; /* Write time */
__le16 s_mnt_count; /* Mount count */
__le16 s_max_mnt_count; /* Maximal mount count */
__le16 s_magic; /* Magic signature */
__le16 s_state; /* File system state */
__le16 s_errors; /* Behaviour when detecting errors */
__le16 s_minor_rev_level; /* minor revision level */
__le32 s_lastcheck; /* time of last check */
__le32 s_checkinterval; /* max. time between checks */
__le32 s_creator_os; /* OS */
__le32 s_rev_level; /* Revision level */
__le16 s_def_resuid; /* Default uid for reserved blocks */
__le16 s_def_resgid; /* Default gid for reserved blocks */
/*
* These fields are for EXT2_DYNAMIC_REV superblocks only.
*
* Note: the difference between the compatible feature set and
* the incompatible feature set is that if there is a bit set
* in the incompatible feature set that the kernel doesn't
* know about, it should refuse to mount the filesystem.
*
* e2fsck's requirements are more strict; if it doesn't know
* about a feature in either the compatible or incompatible
* feature set, it must abort and not try to meddle with
* things it doesn't understand...
*/
__le32 s_first_ino; /* First non-reserved inode */
__le16 s_inode_size; /* size of inode structure */
__le16 s_block_group_nr; /* block group # of this superblock */
__le32 s_feature_compat; /* compatible feature set */
__le32 s_feature_incompat; /* incompatible feature set */
__le32 s_feature_ro_compat; /* readonly-compatible feature set */
__u8 s_uuid[16]; /* 128-bit uuid for volume */
char s_volume_name[16]; /* volume name */
char s_last_mounted[64]; /* directory where last mounted */
__le32 s_algorithm_usage_bitmap; /* For compression */
/*
* Performance hints. Directory preallocation should only
* happen if the EXT2_COMPAT_PREALLOC flag is on.
*/
__u8 s_prealloc_blocks; /* Nr of blocks to try to preallocate*/
__u8 s_prealloc_dir_blocks; /* Nr to preallocate for dirs */
__u16 s_padding1;
/*
* Journaling support valid if EXT3_FEATURE_COMPAT_HAS_JOURNAL set.
*/
__u8 s_journal_uuid[16]; /* uuid of journal superblock */
__u32 s_journal_inum; /* inode number of journal file */
__u32 s_journal_dev; /* device number of journal file */
__u32 s_last_orphan; /* start of list of inodes to delete */
__u32 s_hash_seed[4]; /* HTREE hash seed */
__u8 s_def_hash_version; /* Default hash version to use */
__u8 s_reserved_char_pad;
__u16 s_reserved_word_pad;
__le32 s_default_mount_opts;
__le32 s_first_meta_bg; /* First metablock block group */
__u32 s_reserved[190]; /* Padding to the end of the block */
};3.3.2 GDT (Group Descriptor Table)
块组描述符表,描述块组属性信息,**整个分区分成多个块组就对应有多少个块组描述符。**每个块组描述符存储一个块组的描述信息,如在这个块组中从哪里开始是inode Table,从哪里开始时Data Blocks,空闲的 inode 和数据块还有多少个等等。块组描述符在每个块组的开头都有一份拷贝。
cpp
// 磁盘级blockgroup的数据结构
/*
* Structure of a blocks group descriptor
*/
struct ext2_group_desc
{
__le32 bg_block_bitmap; /* Blocks bitmap block */
__le32 bg_inode_bitmap; /* Inodes bitmap */
__le32 bg_inode_table; /* Inodes table block*/
__le16 bg_free_blocks_count; /* Free blocks count */
__le16 bg_free_inodes_count; /* Free inodes count */
__le16 bg_used_dirs_count; /* Directories count */
__le16 bg_pad;
__le32 bg_reserved[3];
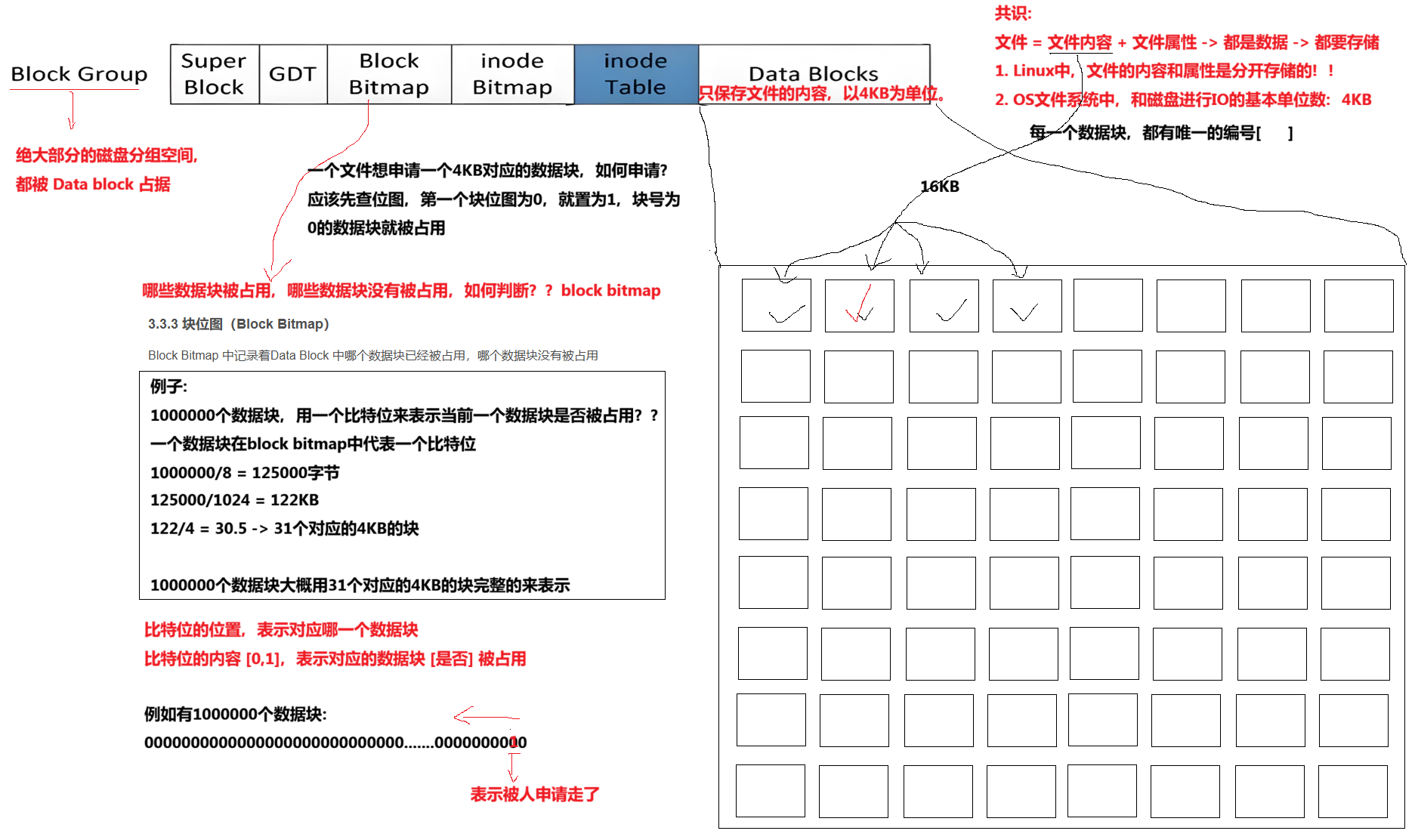
};3.3.3 块位图(Block Bitmap)
Block Bitmap 中记录着Data Block 中哪个数据块已经被占用,哪个数据块没有被占用
3.3.4 inode位图(Inode Bitmap)
每个 bit 表示一个 inode 是否空闲可用。
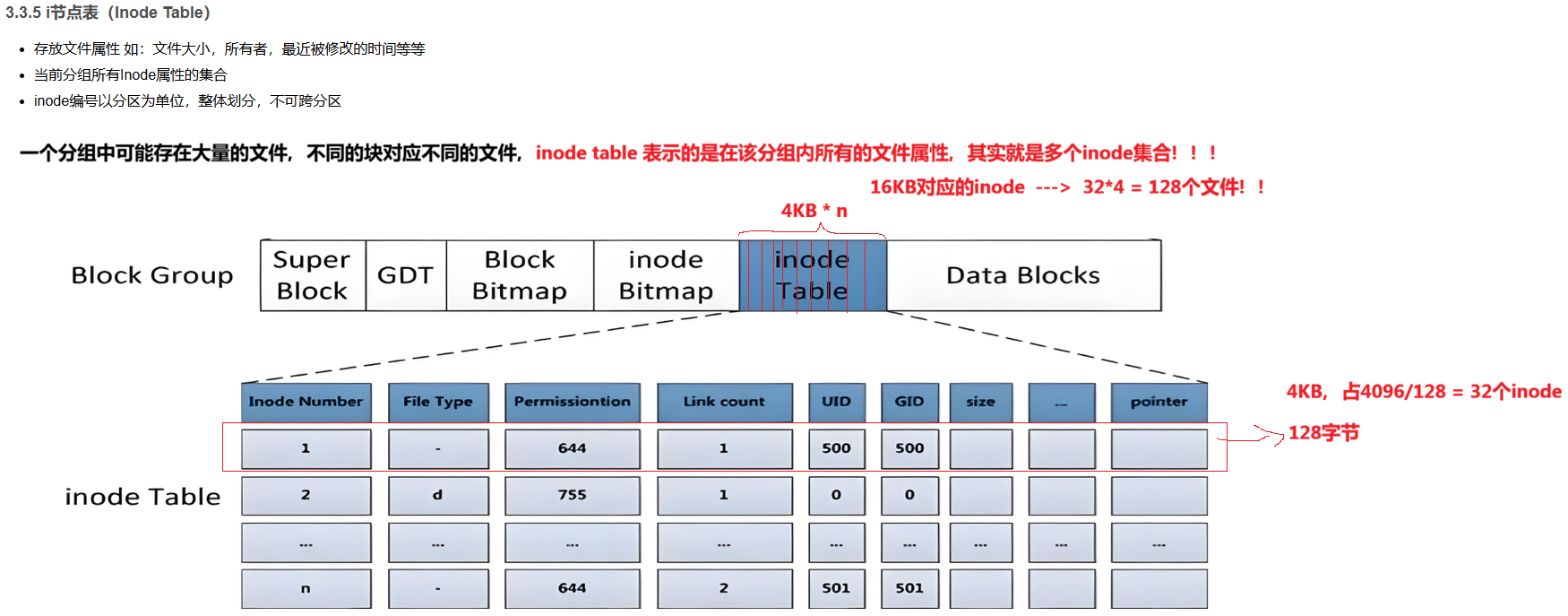
3.3.5 i节点表(Inode Table)
- 存放文件属性 如:文件大小,所有者,最近被修改的时间等等
- 当前分组所有Inode属性的集合
- inode编号以分区为单位,整体划分,不可跨分区
3.3.6 Data block
数据区:存放文件内容,也就是⼀个⼀个的Block。根据不同的⽂件类型有以下几种情况:
- 对于普通文件,文件的数据存储在数据块中。
- 对于目录,该目录下的所有⽂件名和⽬录名存储在所在⽬录的数据块中,除了文件名外,ls -l命令看到的其它信息保存在该⽂件的inode中。
- Block 号按照分区划分,不可跨分区
文件的内容如何在一个分组中进行保存?
文件的属性如何在一个分组中进行保存?


有了上面的知识,下面进行知识的串联:







3.4 inode 和 Datablock的映射
每一个文件都有自己对应的inode,有了对应的inode,将来拿着inode数字,就可以得到相关文件的属性,文件也有对应的内容,所以inode里还存在了一张表,inode和数据块之间的映射表:i_block
cpp
/*
* Structure of an inode on the disk
*/
struct ext2_inode {
__le16 i_mode; /* File mode */
__le16 i_uid; /* Low 16 bits of Owner Uid */
__le32 i_size; /* Size in bytes */
__le32 i_atime; /* Access time */
__le32 i_ctime; /* Creation time */
__le32 i_mtime; /* Modification time */
__le32 i_dtime; /* Deletion Time */
__le16 i_gid; /* Low 16 bits of Group Id */
__le16 i_links_count; /* Links count */
__le32 i_blocks; /* Blocks count */
__le32 i_flags; /* File flags */
union {
struct {
__le32 l_i_reserved1;
} linux1;
struct {
__le32 h_i_translator;
} hurd1;
struct {
__le32 m_i_reserved1;
} masix1;
} osd1; /* OS dependent 1 */
__le32 i_block[EXT2_N_BLOCKS];/* Pointers to blocks */
__le32 i_generation; /* File version (for NFS) */
__le32 i_file_acl; /* File ACL */
__le32 i_dir_acl; /* Directory ACL */
__le32 i_faddr; /* Fragment address */
union {
struct {
__u8 l_i_frag; /* Fragment number */
__u8 l_i_fsize; /* Fragment size */
__u16 i_pad1;
__le16 l_i_uid_high; /* these 2 fields */
__le16 l_i_gid_high; /* were reserved2[0] */
__u32 l_i_reserved2;
} linux2;
struct {
__u8 h_i_frag; /* Fragment number */
__u8 h_i_fsize; /* Fragment size */
__le16 h_i_mode_high;
__le16 h_i_uid_high;
__le16 h_i_gid_high;
__le32 h_i_author;
} hurd2;
struct {
__u8 m_i_frag; /* Fragment number */
__u8 m_i_fsize; /* Fragment size */
__u16 m_pad1;
__u32 m_i_reserved2[2];
} masix2;
} osd2; /* OS dependent 2 */
};
#define EXT2_NDIR_BLOCKS 12
#define EXT2_IND_BLOCK EXT2_NDIR_BLOCKS
#define EXT2_DIND_BLOCK (EXT2_IND_BLOCK + 1)
#define EXT2_TIND_BLOCK (EXT2_DIND_BLOCK + 1)
#define EXT2_N_BLOCKS (EXT2_TIND_BLOCK + 1)
//inode 的⼤⼩通常是 128 字节 或 256 字节
cpp
__le32 i_block[EXT2_N_BLOCKS];/* Pointers to blocks */数组可以理解为是一个无符号整数,里面存放的该文件所对应的数据块的块号。所以一个文件要被访问,直接拿着inode table中的映射关系直接在当前的data block中去找,对应的块号是多少,直接找对应的块就好了。
其实,EXT2_N_BLOCKS =15,一个块大小是4KB,只能建立15组的映射关系的话,总共大小是60KB,而在linux中一个文件最大不止60KB,所以,该怎么办?
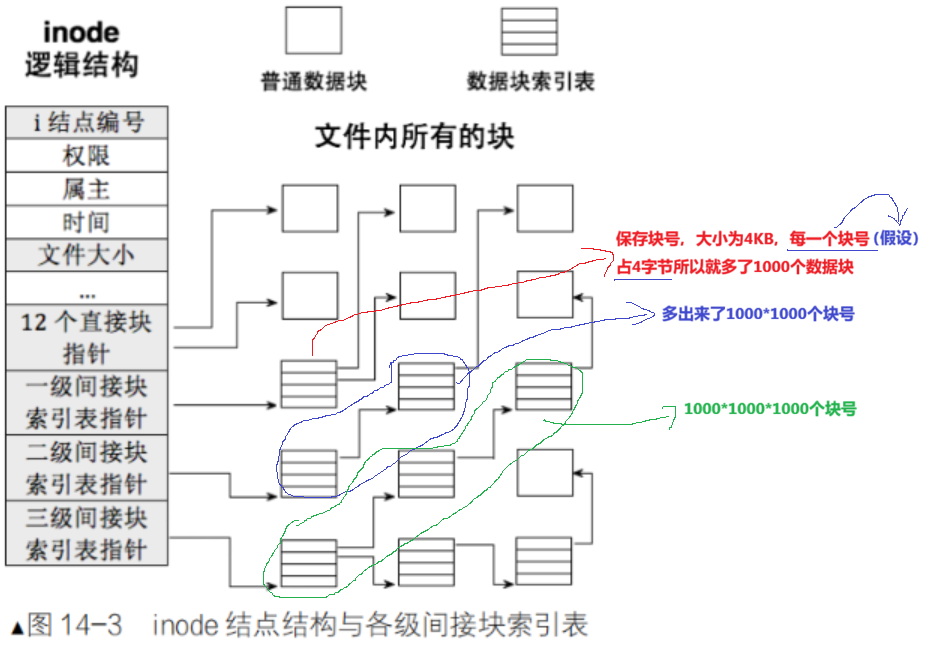
但是一个块组内所对应的数据块个数不够的话,inode的编号在整个分区中是有效的,数据块也是在整个分区内全局有效的,实际上inode table中建立和数据块对应的映射时,不仅仅仅限于自己坐在组的块,本组内的块不够了,再在文件系统层面上的其它的组内去要,块也是可以在文件系统内跨组的。去抢别人的块号如何抢?因为每一个块组大小都是一样的,inode个数固定的,block个数固定,所以去其他组,起始编号能够算出来的,inode table和data block是可以进行跨组的,在分区内有效。
所以,打开一个文件Linux系统从根目录开始做路径解析,把所有的目录打开在内存里创建dentry缓存/dentry树,打开对应的每一个目录的文件名和inode的映射关系,路径的每一个节点都有文件名。找到当前目录,找到要访问的文件inode,根据inode/每一个组inode个数,就可以得到在哪个组,inode的属性就找到了,找到对应的块,要的内容就拿到了,文件的属性和内容就全部拿到了。
但是还是会有一个问题:

3.5 目录与文件名
- 目录也是⽂件,但是磁盘上没有目录的概念,只有文件属性+文件内容的概念。
- 目录的属性不用多说,内容保存的是:文件名和Inode号的映射关系
- 所以,访问文件,必须打开当前目录,根据文件名,获得对应的inode号,然后进行文件访问
- 所以,访问⽂件必须要知道当前⼯作⽬录,本质是必须能打开当前⼯作⽬录⽂件,查看⽬录⽂件的内容!
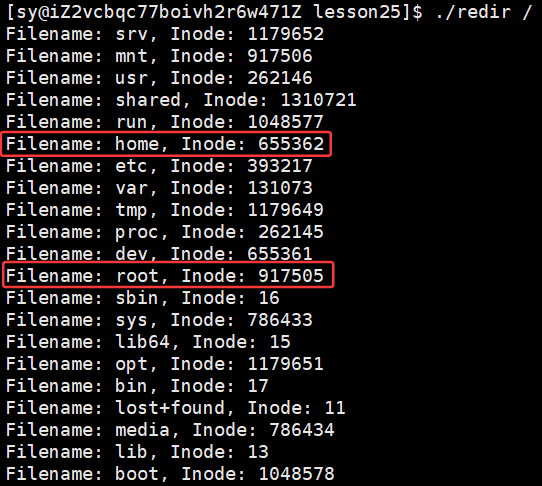
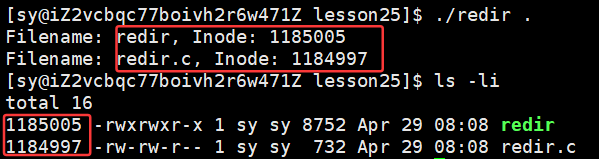
代码证明:文件名和inode在指定目录中确实是存在映射关系的!!!
cpp
//redir.c
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <dirent.h>
#include <sys/types.h>
#include <unistd.h>
int main(int argc, char* argv[]) {
if (argc != 2) {
fprintf(stderr, "Usage: %s <directory>\n", argv[0]);
exit(EXIT_FAILURE);
}
DIR* dir = opendir(argv[1]); // 系统调⽤,⾃⾏查阅
if (!dir) {
perror("opendir");
exit(EXIT_FAILURE);
}
struct dirent* entry;
while ((entry = readdir(dir)) != NULL) { // 读取目录,系统调⽤,⾃⾏查阅
// Skip the "." and ".." directory entries
if (strcmp(entry->d_name, ".") == 0 || strcmp(entry->d_name, "..")
== 0) {
continue;
}
printf("Filename: %s, Inode: %lu\n", entry->d_name, (unsigned
long)entry->d_ino);
}
closedir(dir);
return 0;
}
dirent 与 dentry 类似
d_name:当前对应的文件名
cpp
//打开一个目录,访问这个目录下的所有的文件名和inode
struct dirent* entry;
while ((entry = readdir(dir)) != NULL) { // 读取目录,系统调⽤,⾃⾏查阅
// Skip the "." and ".." directory entries
if (strcmp(entry->d_name, ".") == 0 || strcmp(entry->d_name, "..")
== 0) {
continue;
}运行结果:
3.6 路径缓存
问题1:Linux磁盘中,存在真正的目录吗?
答案:不存在,只有文件。只保存文件属性+文件内容
问题2:访问任何文件,都要从 / 根目录开始进行路径解析?
答案:原则上是,但是这样太慢,所以Linux回缓存历史路径结构
问题3:Linux目录的概念,怎么产生的?
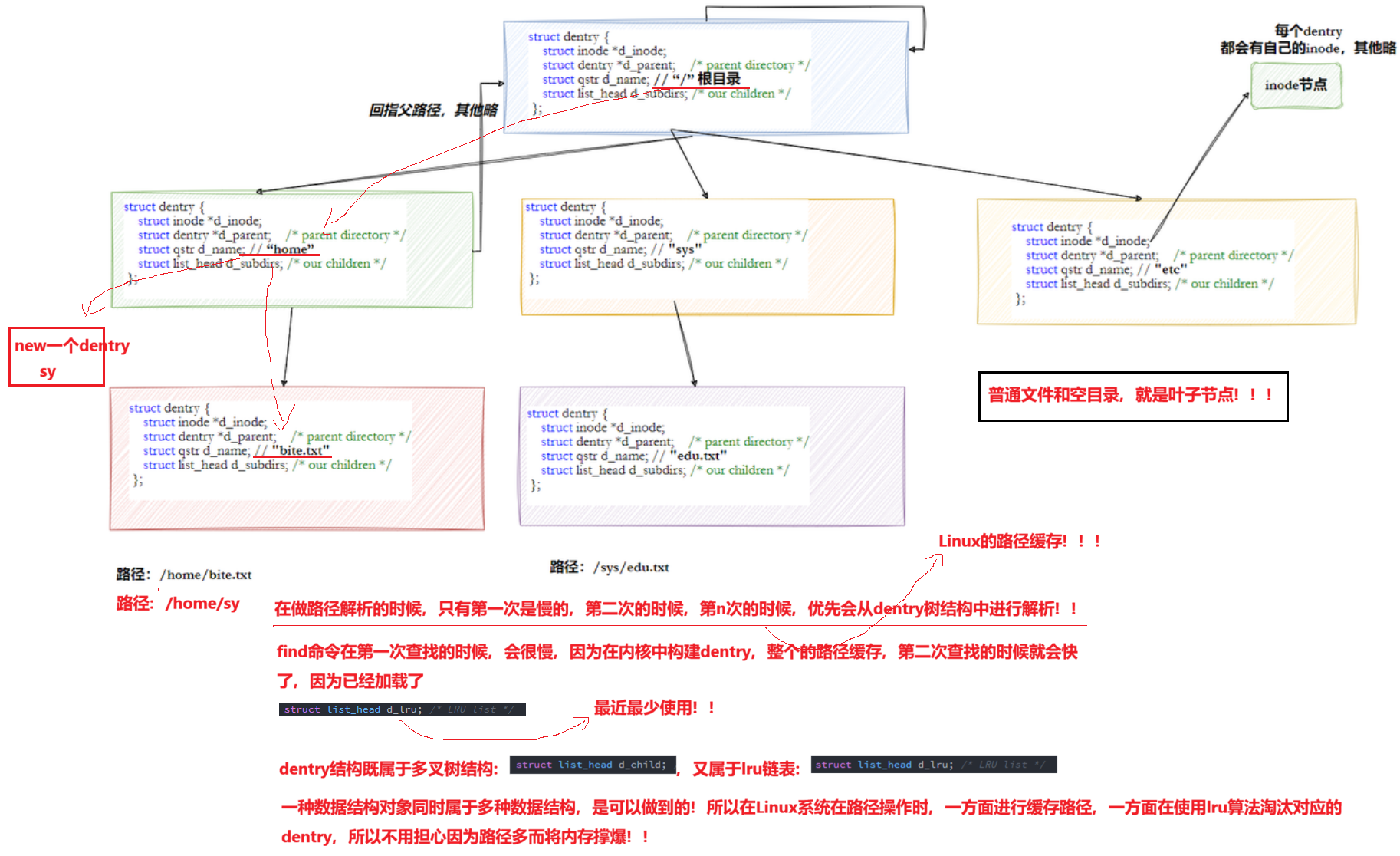
答案:打开的文件是目录的话,由OS自己在内存中进行路径维护
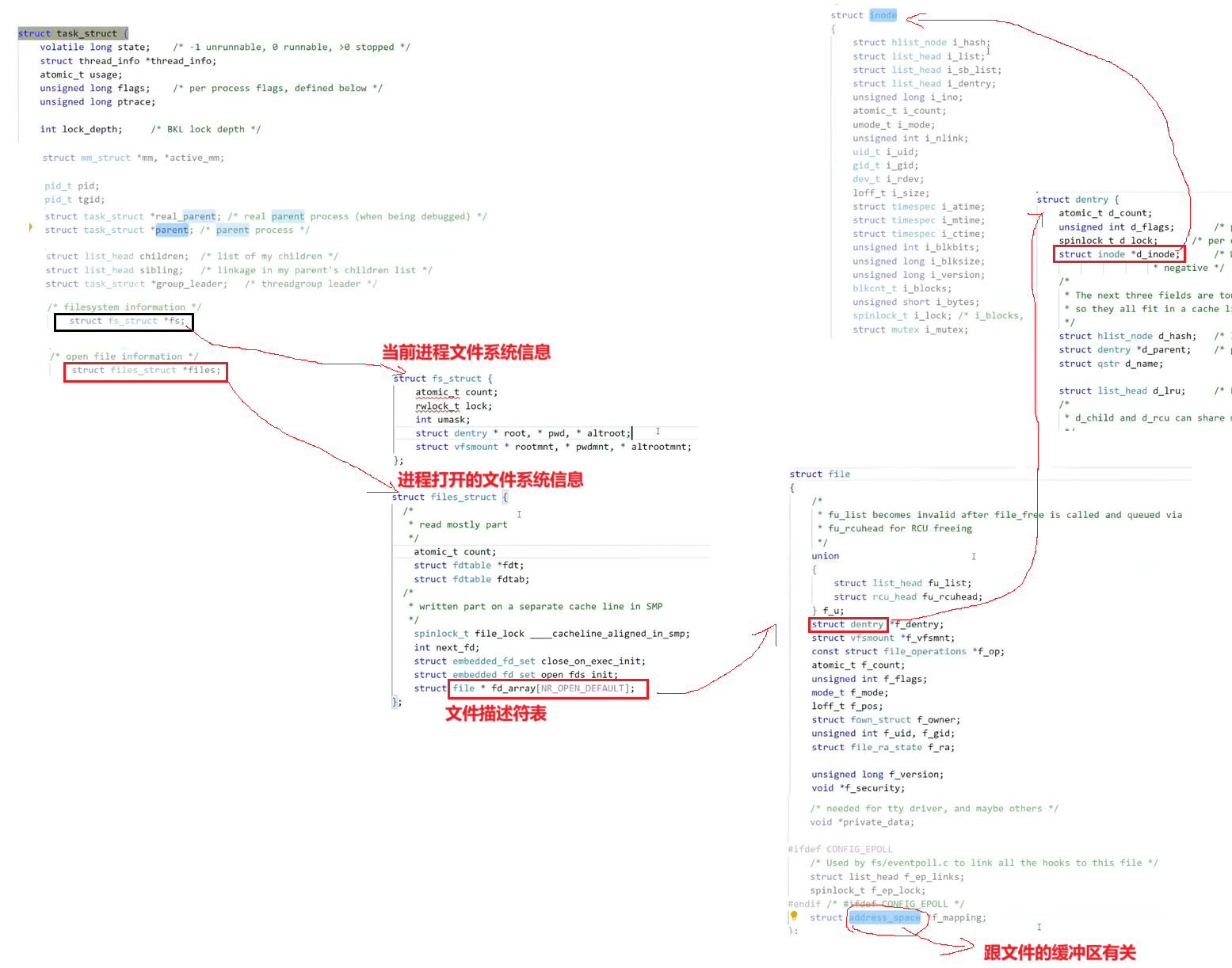
Linux中,在内核中维护树状路径结构的内核结构体叫做:struct dentry,struct dentry 表明当前的叶子节点
cpp
struct dentry {
atomic_t d_count;
unsigned int d_flags; /* protected by d_lock */
spinlock_t d_lock; /* per dentry lock */
struct inode* d_inode; /* Where the name belongs to - NULL is
* negative */
/*
* The next three fields are touched by __d_lookup. Place them here
* so they all fit in a cache line.
*/
struct hlist_node d_hash; /* lookup hash list */
struct dentry* d_parent; /* parent directory */
struct qstr d_name;
struct list_head d_lru; /* LRU list */
/*
* d_child and d_rcu can share memory
*/
union {
struct list_head d_child; /* child of parent list */
struct rcu_head d_rcu;
} d_u;
struct list_head d_subdirs; /* our children */
struct list_head d_alias; /* inode alias list */
unsigned long d_time; /* used by d_revalidate */
struct dentry_operations* d_op;
struct super_block* d_sb; /* The root of the dentry tree */
void* d_fsdata; /* fs-specific data */
#ifdef CONFIG_PROFILING
struct dcookie_struct* d_cookie; /* cookie, if any */
#endif
int d_mounted;
unsigned char d_iname[DNAME_INLINE_LEN_MIN]; /* small names */
};注意:
- 每个文件其实都要有对应的dentry结构,包括普通⽂件。这样所有被打开的文件,就可以在内存中形成整个树形结构
- 整个树形节点也同时会隶属于LRU(Least Recently Used,最近最少使用)结构中,进行节点淘汰
- 整个树形节点也同时会⾪属于Hash,⽅便快速查找
- 更重要的是,这个树形结构,整体构成了Linux的路径缓存结构,打开访问任何文件,都在先在这棵树下根据路径进行查找,找到就返回属性inode和内容,没找到就从磁盘加载路径,添加dentry结构,缓存新路径
3.7 挂载分区
3.7.1 一个实验
拿到inode在磁盘中找的时候,怎么知道是在哪一个分区下的呢?
Linux中,一般磁盘设备在 /dev下:


在这里(本篇文章)将vda当作物理盘,但这块物理盘不能被直接使用,使用这块物理盘得先分区,格式化,当前系统磁盘只有一块,分区也只分了一块,叫做vda1,如果将磁盘分为多块,就是vda2,vda3,vda4这样的磁盘的盘符。所以 /dev/vda 是物理磁盘,能看见的,/dev/vda1 是磁盘中的分区。而未来新建文件、删除文件、打开文件、文件操作,对应的分区,把文件系统写好,进行格式化,这个分区不能被直接使用,而是将分区挂载才能使用的!!!

如何查明挂载??
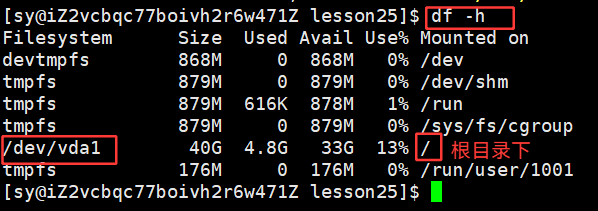
/dev/vda1 被挂载到了根目录下,所以我们只要在根目录下所作的所有的文件增删查改的操作都在vda1这个分区下进行的,如果要真正的使用vda1这个分区的话,是需要将/dev/vda1挂载到指定的一个目录下的。但是我们系统上面只有一个分区,还怎么观察呀?但是自己可以模拟出来一个分区:dd命令,就是二进制写入,形成一个大文件,通常用dd命令:
bash
dd if=/dev/zero of=./disk.img bs=1M count=5 #制作⼀个⼤的磁盘块,就当做⼀个分区
mkfs.ext4 disk.img # 格式化写⼊⽂件系统
mkdir /mnt/mydisk # 建⽴空⽬录
df -h # 查看可以使⽤的分区dd if =......,dd命令中的参数 if 表示的是import表示的是输入设备,从dev/zero,zero是Linux系统中提供的临时的设备文件,of是outputfile,将if中读到的数据写入到什么地方,形成一个大文件,bs=1M表示写入的块是1兆,一次写一兆,一共写5次,构建出一个5兆的大小。此时将形成的大文件也是磁盘的一个区域,当作一个磁盘块。
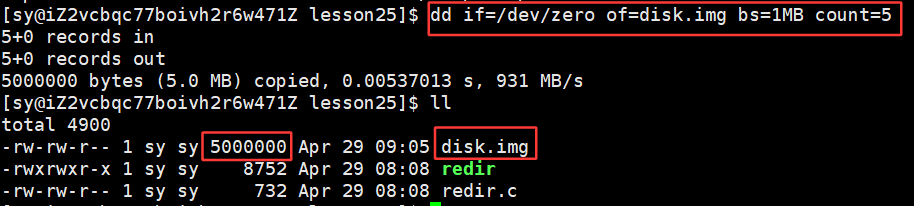
相当于磁盘上面有对应的数据块了,将这个小的磁盘块当作小的分区
写入文件系统:

bash
mkfs.ext4 disk.img # 格式化写⼊⽂件系统
//向刚刚构建的disk.img磁盘里面构建文件系统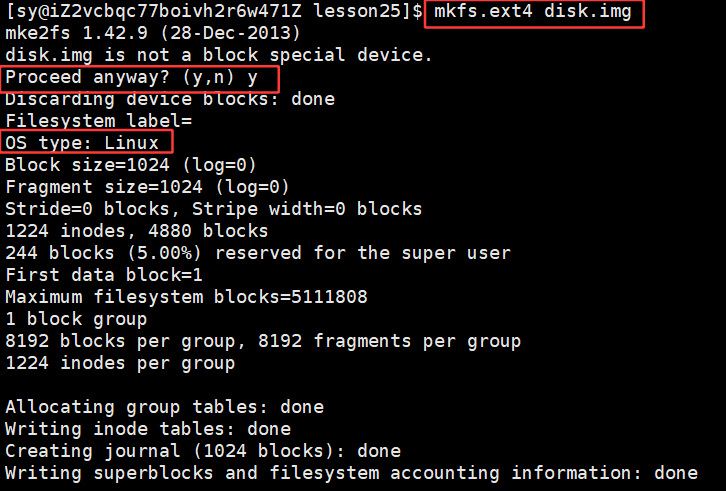

得挂载起来才能使用:
bash
$ sudo mount -t ext4 ./disk.img /home/sy/linux/lesson25/hello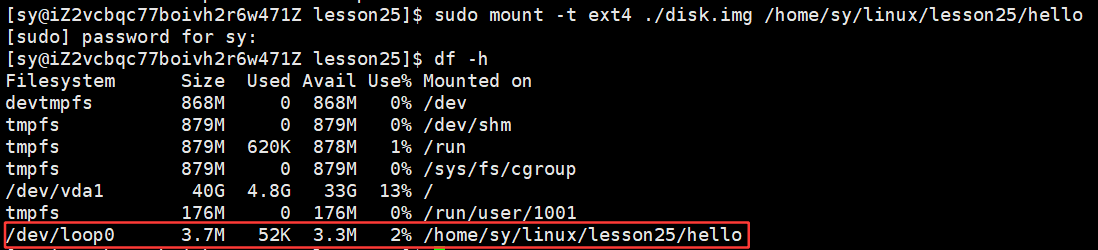
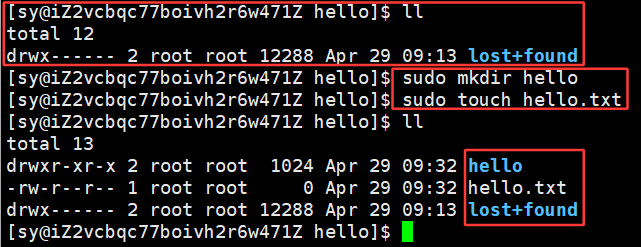

其实在/home/sy/linux/lesson25/hello这个文件中给所作的所有操作都是在 disk.img这块盘中做操作。因为我们是模拟出来的分区,Linux识别是把他当成dev/loop0,一种循环的测试设备,如果挂载的是真正的分区,/dev/vda1这个名字是不变的
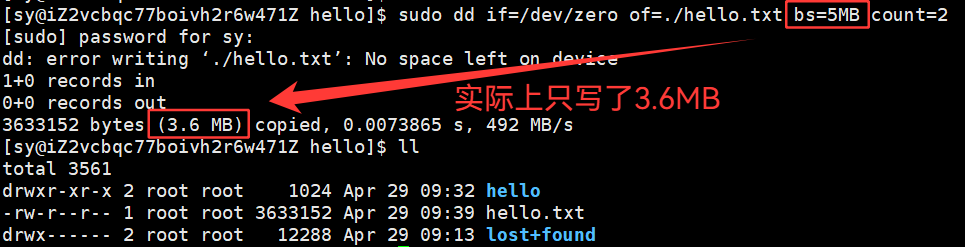

模拟出来的磁盘分区:disk.img 比较小,dd命令想弄一个10MB的数据,将分区写满就没再弄了。只写了3.6MB的大小,部分的inode占用的,inode还在,但是数据却被写满了。
分区要被使用就得被挂载,挂载在指定的目录下,进入这个目录才能访问对应的指定的分区了。
如果不想用的话,用umount命令:
bash
sudo umount /home/sy/linux/lesson25/hello此时,关联关系就没有了:
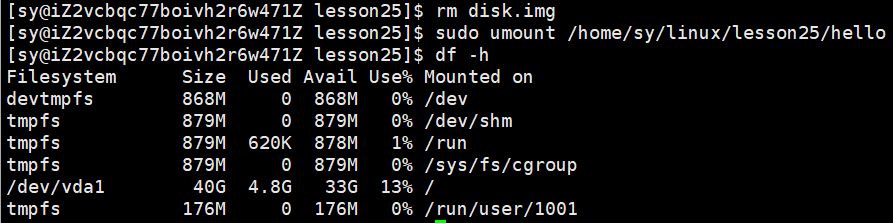

3.7.2 一个结论:
- 分区写入文件系统,无法直接使用,需要和指定的目录关联,进行挂载才能使用。
- 所以,可以根据访问目标文件的**"路径前缀"**准确判断我在哪⼀个区。(最多理解到这个层面)
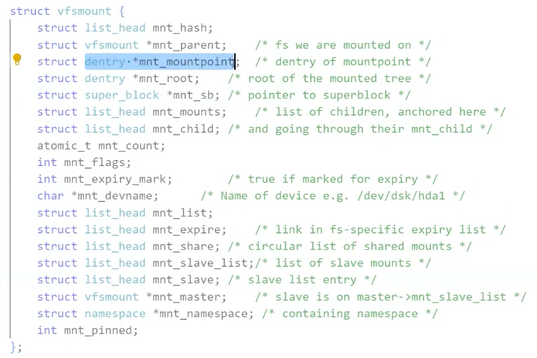
- linux是可以存在很多个分区的,每一个分区可以存在多个文件系统,每一个文件系统都可以挂载到指定的目录下,所以OS怎么会知道它有多少个文件系统呢?多少个分区呢?每一个分区分别挂载到哪一个目录下呢?文件系统是多个的,因为分区是多个的,每一个文件系统加载到目录下也是多个的。所以,在OS内要对文件系统做管理,先描述,在组织!!!在Linux内核中,对应的文件系统数据结构是 struct SB,就是super block,其中一个文件系统就有一个挂载点,同时也是对挂载点有管理的,在Linux内核中struct mount数据结构,对应的struct mount数据结构和文件系统是Linux中的一些全局对象,新增一个文件系统,新增一个挂载点,就会将mount数据结构和文件数据关联起来,后续打开对应的文件,打开对应的dentry结构:
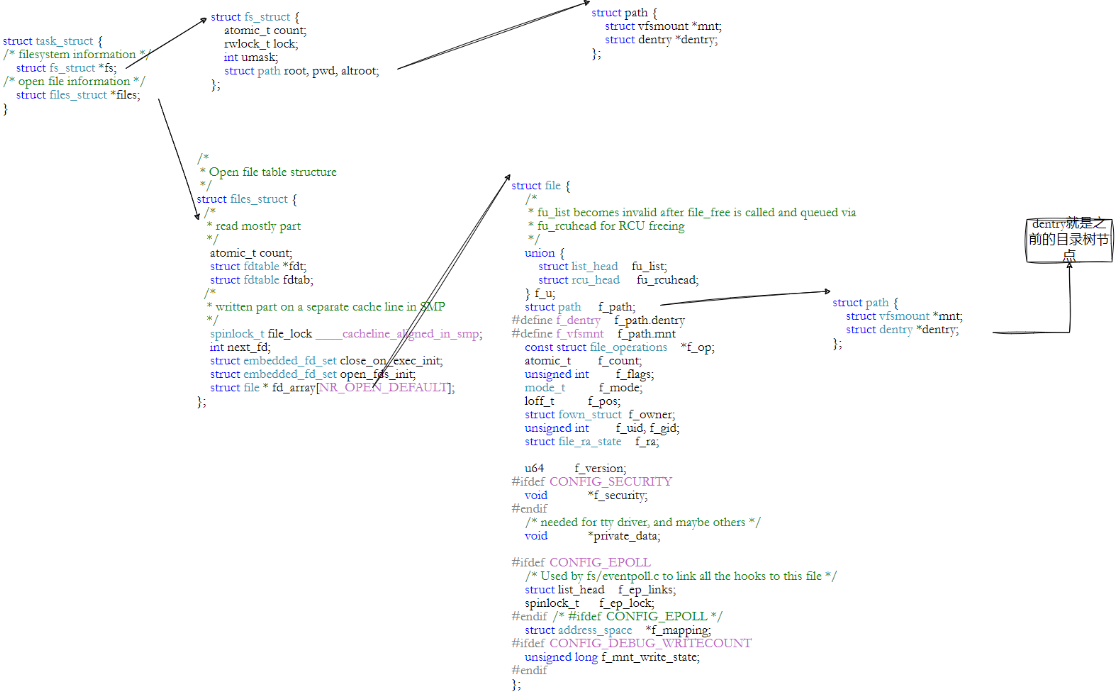
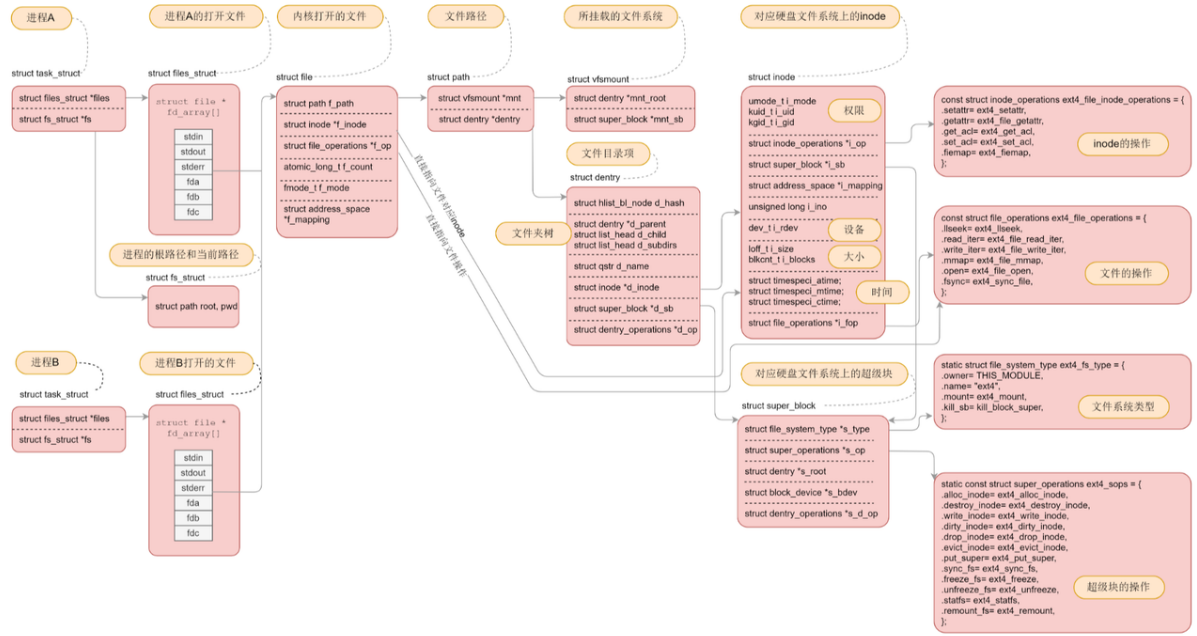
3.8 文件系统总结
主要想从不同角度说明:
4. 软硬连接
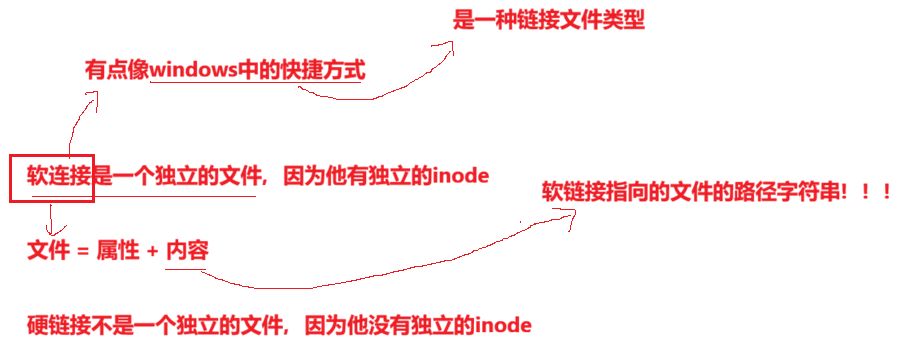
4.1 软链接
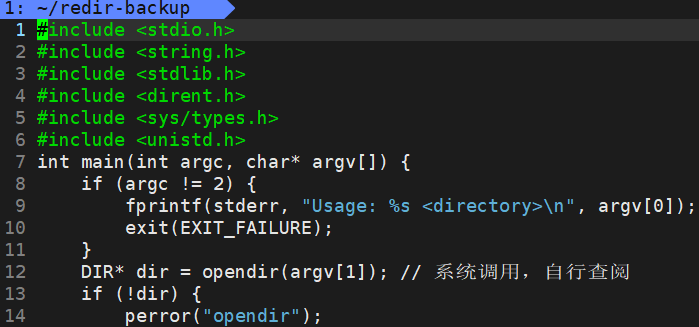
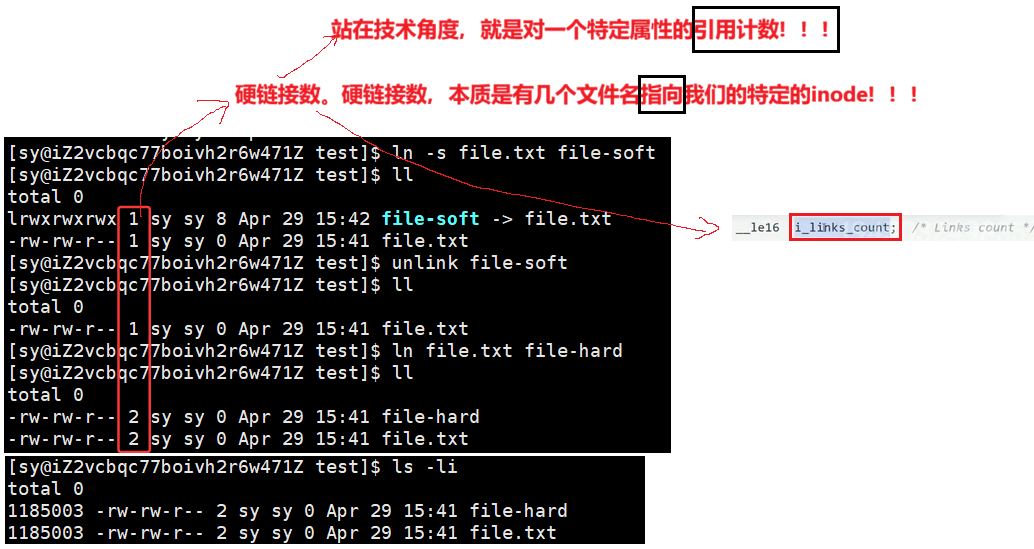
硬链接时通过inode引用另外一个文件,软链接时通过名字引用另外一个文件,但实际上,新的文件和被引用的文件的inode不同,应用创建上可以想象成一个快捷方式。
bash
ln -s redir.c redir-soft # 建立软链接,用后者链接前者
4.2 硬链接
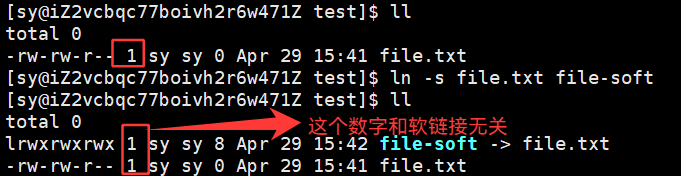
真正找到磁盘上文件的并不是文件名,而是inode。其实在linux中可以让多个文件名对应于同一个inode。
bash
ln redir.c redir-hard #建立硬链接,用后者链接前者
从运行的结果中,可以发现:

4.3 软硬链接的区别

4.3 软硬链接的应用场景(重点)
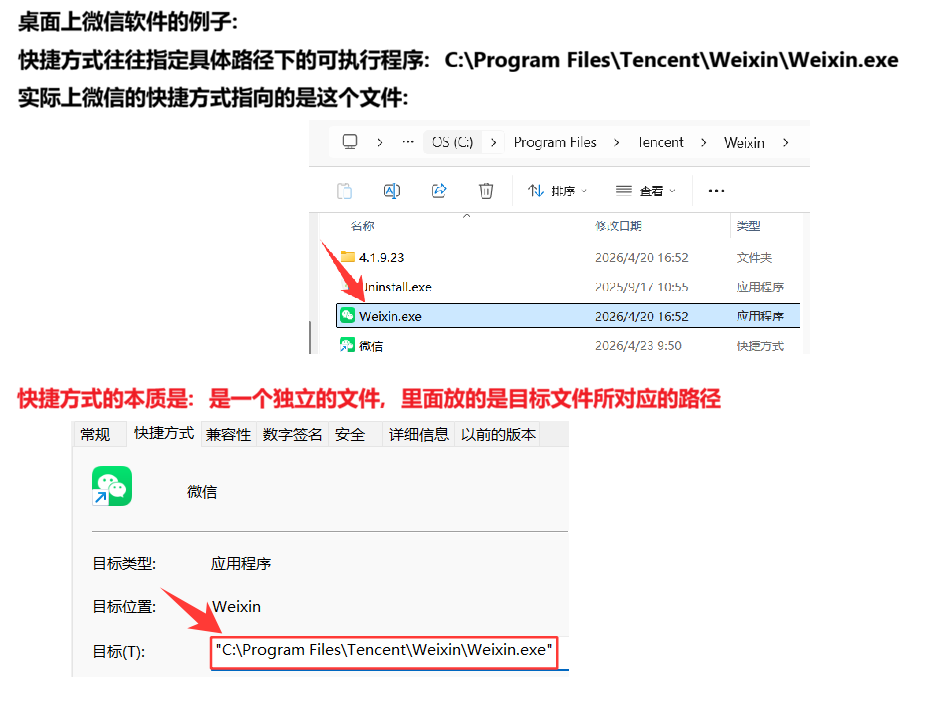
软链接的应用场景之一就是快捷方式
之前有环境变量来解决找不到路径的问题,但是一般发布一款软件,一款软件有项目结构
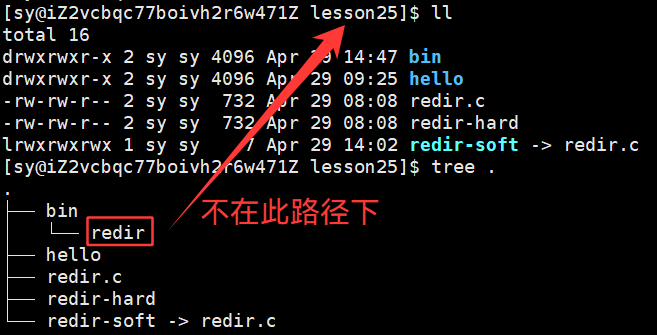
redir不在当前路径下,但是就是想在当前路径下执行对应的程序
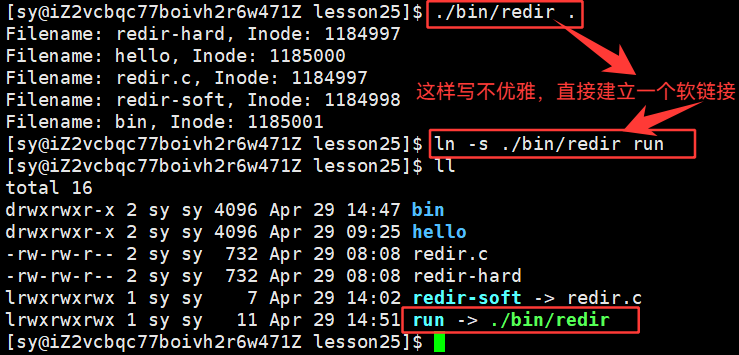
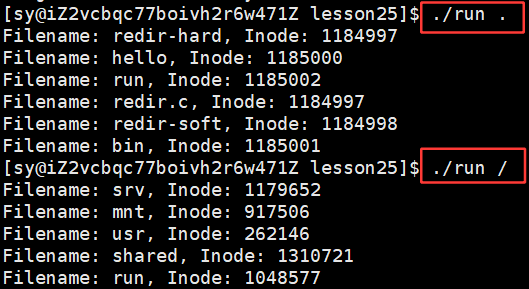
以此,用快捷方式直接访问目标程序了,这个是软链接最典型的应用之一。
软链接的应用场景:让用户无感知的进行软件升级
升级的时候将exe给替换掉,就升级成功了。相当于就是OS和用户之间增加了一个软链接,这样的话就多了一层软件层。对底层做修改、更新,软链接都不变,对软甲进行无感知的升级。
硬链接典型的应用场景:对文件进行备份!!
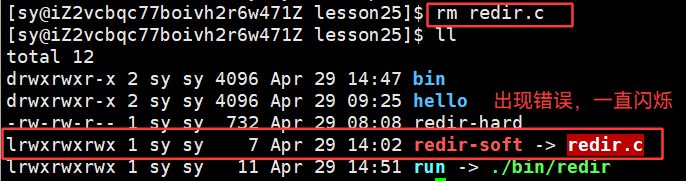
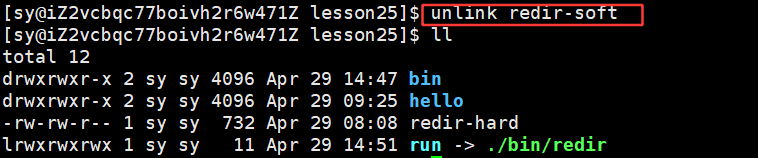
将 redir.c 删掉了,此时的 redir-hard是不会被删掉的。因为inode的还存在,inode存在,属性在,属性在,内容就还在
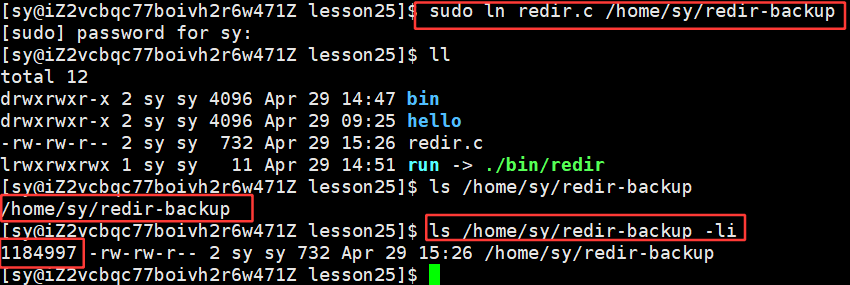
与当前 redir.c 文件的 inode 号一致:
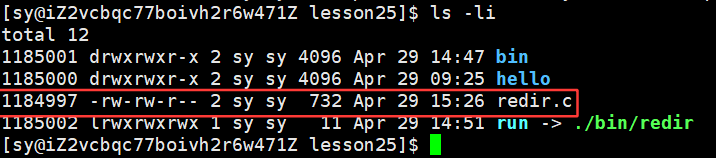
说明两者是同一个文件。将 redir.c 删掉,当前目录下是没有了,但是这个文件是没有被删掉的,因为我们做了备份:
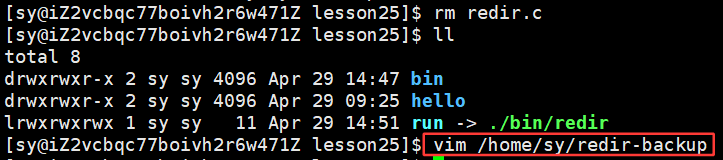
所以,今天进行备份的时候是不会占用两份对应的内容和属性的空间,备份文件只是在指定目录下建立了文件名和inode映射关系。文件属性和文件内容永远都只有一份,而在指定目录下删文件时,只是删了当前目录下的对应的文件名和inode的映射关系。

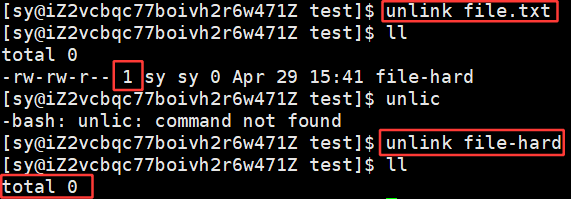
此时文件的引用计数变为0,将该文件删除了。
创建出普通文件、目录,为什么对应默认的引用计数不一样??
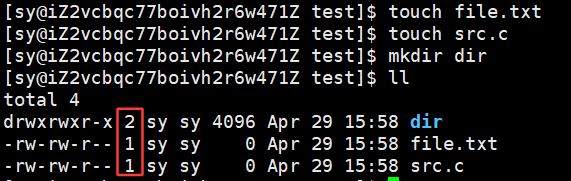
普通文件所对应的文件名和inode的映射关系只有一组,所以引用计数就是1,但是为什么空目录的引用计数是2呢?因为自己的dir名字和inode是一组映射关系,因为dir目录下还有一个 **. ,点也是一个文件名,**指向的也是 dir:
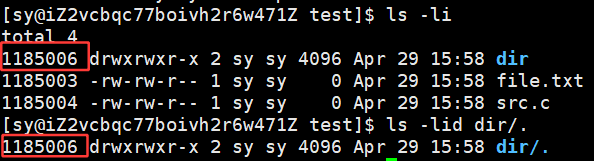
所以,终于理解为什么 . 表示的也是当前目录了,因为 . 和 当前目录dir指向同一个 inode,因为 . 是当前目录的硬链接,又因为任意一个目录永远都有自己的目录名和 . ,所以一个空目录的引用计数是2。
在dir目录下新建另一个目录:

此时,在查看dir的引用计数时,显示的是3:
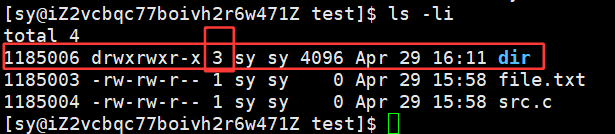
这是因为otherdir目录下有 **..**指向的是上级目录,就是dir目录

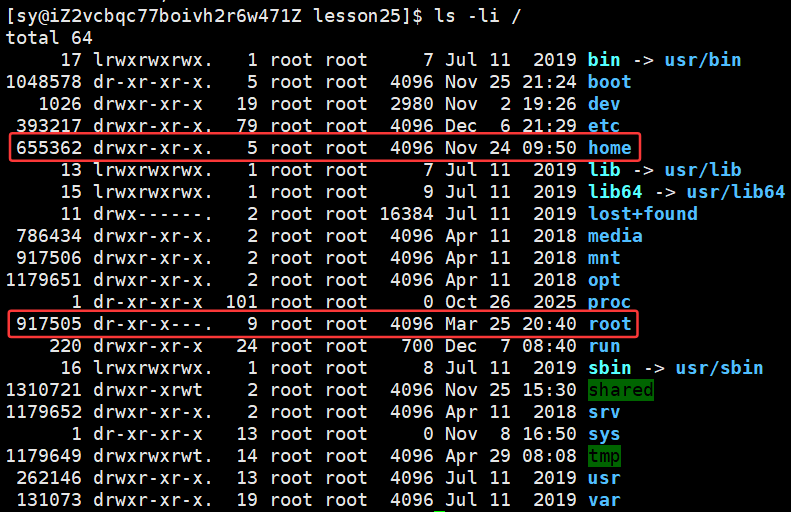
查看根目录的inode为19:

根目录下有多少个子目录?(直接引用计数-2 = 子目录的个数)
自身占了2个,一个是 . ,一个是/ ,就有17个子目录: