第一次打开 Claude Code 的时候,我像个拿到新玩具的小孩。
css
┌─────────────────────────────────────────────┐
│ Claude Code v1.1.113 - AI Programming Assistant │
├─────────────────────────────────────────────┤
│ ❯ claude-code │
│ │
│ Welcome to Claude Code! Ready to help you │
│ code. │
│ │
│ ❯ Help me create a React component █ │
└─────────────────────────────────────────────┘在对话框里敲下"帮我写个 React 组件",看着它噼里啪啦生成代码,心里那个美啊。但新鲜感过了之后,我发现自己一直在用最原始的方式跟它交互------就像买了辆特斯拉,却只用来在小区里兜圈。
直到有天深夜,我在 GitHub 上偶然看到一个开发者分享的配置,里面有个叫 /powerup 的命令。好奇心驱使下,我试了一下。
接下来的一个小时,我像是重新认识了 Claude Code。
/powerup:被忽略的官方教程
大多数人拿到 Claude Code 后的第一件事,就是开始干活。
问问题、写代码、改 bug,把它当成一个更聪明的搜索引擎。这种用法没错,但就像是用 iPhone 打电话------你能说它没用吗?当然不能。但你错过了太多。
/powerup 是 Claude Code 内置的交互式教程,分 10 个等级,循序渐进地教你核心功能。
我第一次运行时,以为就是个简单的 help 文档。结果它是个真正的互动课程,每个级别都有具体的练习和即时反馈。比如第三级会教你如何用上下文管理来保持对话的连贯性,第五级演示如何用子代理处理复杂任务。
最让我惊讶的是第九级,讲的是如何设计多角色代理团队来解决系统性问题。这个概念我之前在论文里看过,但从没想过能直接在 CLI 里实现。
很多人(包括之前的我)会觉得"教程?我自己摸索就行"。但说实话,Claude Code 的功能密度太高了,纯靠摸索很容易陷入局部最优。花一小时走完这个教程,比我之前三个月瞎琢磨学到的东西都多。
运行方式很简单
bash
/powerup然后跟着指引走就行。它不会占用你太多时间,每个级别大概 5-10 分钟。你可以随时暂停,下次继续。 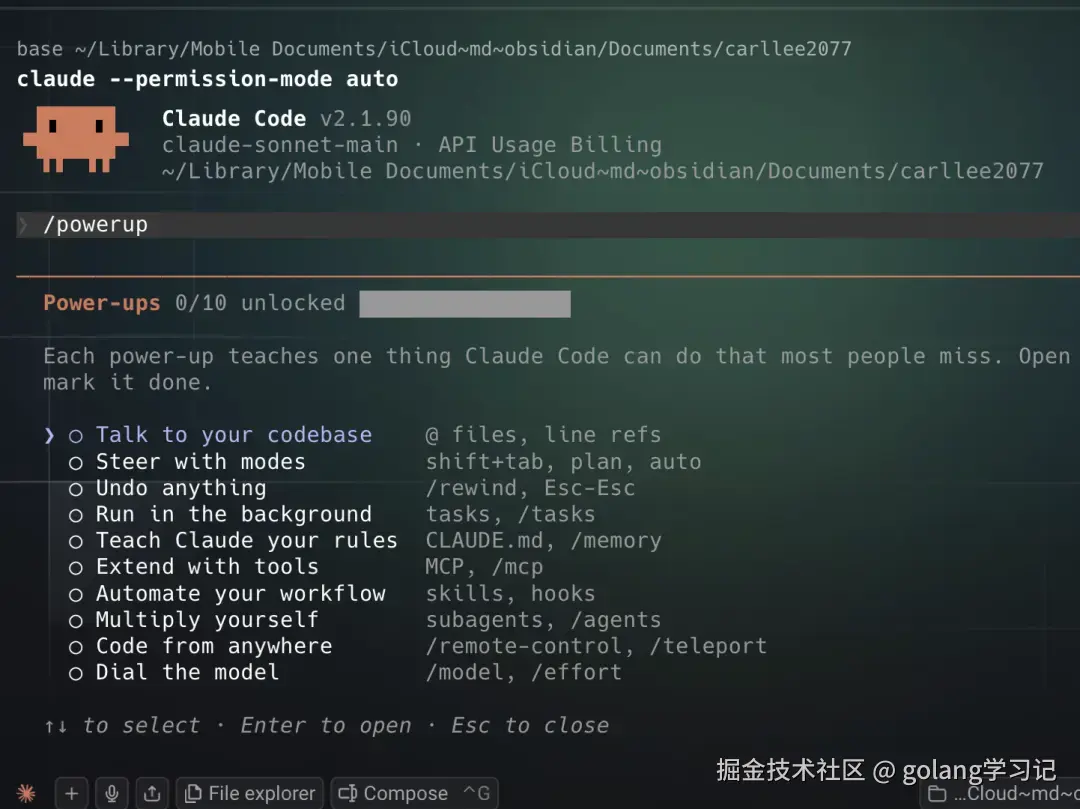
图2:/powerup 的交互式教程界面,10个等级循序渐进
/btw:侧边聊天,不污染主上下文
你有没有过这种体验?
正在让 Claude Code 帮你重构一个模块,突然想到一个问题"对了,Python 的装饰器是怎么工作的?"。你忍不住问了,它回答了,然后你们俩就聊起了装饰器的高级用法。
五分钟后你回过神来,发现主任务已经被忘到九霄云外。更糟的是,这段关于装饰器的对话占用了宝贵的上下文窗口,导致 Claude Code 开始遗忘前面的代码结构。
/btw 就是为了解决这个问题而生的。
当你需要问一个与当前任务无关的问题时,用 /btw 开头
bash
/btw Python 的装饰器是怎么工作的?
vbnet
┌─────────────────────────────────────────────┐
│ Main Task: Refactoring auth module │
├─────────────────────────────────────────────┤
│ Working on user authentication... │
│ │
│ ┌─ [Side Chat] ────────────────────────┐ │
│ │ ❯ /btw How do Python decorators work?│ │
│ │ │ │
│ │ Decorators wrap functions to add │ │
│ │ behavior without modifying code... │ │
│ └──────────────────────────────────────┘ │
│ │
│ ❯ Back to refactoring task █ │
└─────────────────────────────────────────────┘图3:使用 /btw 进行侧边聊天,主任务上下文保持纯净
Claude Code 会在一个隔离的"侧边频道"里回答这个问题,不会影响主任务的上下文。回答完后,它会无缝回到原来的任务,就像什么都没发生过一样。
这个功能看似简单,实则解决了大语言模型交互中的一个根本矛盾------人类思维是发散的,但 AI 需要聚焦。
我开始用 /btw 后,发现自己的工作效率明显提升了。以前每次跑题都要开个新窗口或者忍住不问,现在可以自然地满足好奇心,同时保持主任务的纯净。
更重要的是,它节省了 token。侧边聊天的内容不会被计入主对话的历史,这意味着你可以在不消耗额外配额的情况下探索各种分支问题。
双击 ESC:时光倒流
我第一次误触这个快捷键时,吓了一跳。
当时我正在调试一段复杂的逻辑,跟 Claude Code 来回讨论了十几轮。手指不小心按了两下 ESC,整个对话瞬间回到了十分钟前的状态。
我的第一反应是"完了,白聊了"。但冷静下来后,我发现这其实是个救命功能。
想象一下这个场景:你让 Claude Code 优化一个函数,它给出了方案 A。你觉得不太对劲,让它试试方案 B。接着是方案 C、D、E...半小时后,你回头看,发现方案 A 其实是最好的,但现在已经记不清具体细节了。
以前遇到这种情况,你只能靠记忆或者翻看聊天记录来恢复。有了双击 ESC,你可以直接"时光倒流"到任何一个时间点。
这个功能有两种模式
代码回滚:撤销最近的代码更改,回到上一个稳定状态。
对话回滚:将整个对话历史回退到之前的某个节点,就像那段时间的讨论从未发生过。
less
┌──────────────────────────────────────────────────────┐
│ Conversation History (Double ESC) │
├──────────┬─────────────────────────┬─────────────────┤
│ Time │ Action │ Status │
├──────────┼─────────────────────────┼─────────────────┤
│ 14:32 │ Optimize attempt E │ [Current] │
│ 14:28 │ Optimize attempt D │ [Restore] │
│ 14:25 │ Optimize attempt C │ [Restore] │
│ 14:20 │ Optimize attempt B │ [Restore] │
│ 14:15 │ Optimize attempt A │ [Recommended] ✓ │
└──────────┴─────────────────────────┴─────────────────┘
│ Press Enter to restore selected point │
└──────────────────────────────────────────────────────┘图4:双击 ESC 后可以查看和选择要恢复的历史节点
我现在的习惯是,每当要进行一个可能有风险的改动时,先在心里打个标记。如果方向错了,双击 ESC 就能快速回到安全区。
这种"可逆性"带来的心理安全感,让我更愿意尝试激进的方案。反正错了可以重来,为什么不试试呢?
Hook 和 /insight:自动化你的工作流
如果你用过 Git hooks,应该能立刻理解这个功能的价值。
Claude Code 的 hook 机制允许你在特定事件发生时自动触发某些操作。比如每次对话开始前自动加载项目上下文,或者每次生成代码后自动运行测试。
设置 hook 的方式很直观
bash
/hook set on:start load-context.sh
/hook set on:code-generated run-tests.sh但我真正爱上这个功能,是因为 /insight 命令。
/insight 会分析你过去一段时间的使用习惯,生成一份报告,告诉你
- 你最常问的问题类型是什么
- 哪些命令你用得最多
- 你的对话通常在什么时间段最活跃
- 有没有重复性的任务可以自动化
我第一次运行 /insight 时,报告说我 40% 的对话都是在询问类似的 API 用法。看到这个数据,我意识到可以把这些常见问题整理成一个本地知识库,然后用 hook 在对话开始时自动加载。
yaml
┌─────────────────────────────────────────────┐
│ /insight - Usage Analysis (Last 30 Days) │
├─────────────────────────────────────────────┤
│ Total conversations: 127 │
│ Average session: 18 minutes │
│ Most active time: 14:00-16:00 │
│ │
│ Top question types: │
│ ████████████████░░░░ API usage 40% │
│ ██████████░░░░░░░░ Code debug 25% │
│ ████████░░░░░░░░░░ Architecture 20% │
│ │
│ ✓ Recommendation: Create local API KB │
└─────────────────────────────────────────────┘图5:/insight 生成的使用习惯分析报告,帮助优化工作流
这样做之后,我的平均响应时间缩短了将近一半,因为 Claude Code 不再需要每次都重新学习那些基础概念。
hook 的真正威力在于它能让你从"被动响应"变成"主动设计"。你不是在等 Claude Code 回答问题,而是在设计一个智能的工作流,让它在你需要的时刻提供恰到好处的帮助。
/loop:定时循环任务
这个功能听起来有点奇怪------为什么要让 AI 循环执行任务?
但当你理解了它的应用场景,会发现这是个天才的设计。
/loop 让你可以设置一个任务在固定间隔重复执行。比如
bash
/loop 24h check GitHub issues and summarize new bugs这条命令会让 Claude Code 每天检查一次 GitHub 上的 issue,并总结新的 bug 报告。
我用它做了三件事
每日站会准备:每天早上 9 点,自动分析昨天的代码提交和评论,生成一份简洁的进度摘要。
依赖更新监控:每周检查一次项目的依赖包,如果有新版本且有重要的安全修复,通知我升级。
日志巡检:每两小时查看一次生产环境的错误日志,如果发现异常模式,立即报警。
sql
┌─────────────────────────────────────────────┐
│ Scheduled Tasks (/loop) │
├─────────────────────────────────────────────┤
│ 📅 Daily Standup Prep │
│ Every day at 09:00 │
│ ✓ Last run: Today 09:00 (Success) │
│ │
│ 📦 Dependency Monitor │
│ Every week on Monday │
│ ✓ Last run: 2 days ago (2 updates) │
│ │
│ 🔍 Log Patrol │
│ Every 2 hours │
│ ✓ Last run: 45 min ago (No issues) │
└─────────────────────────────────────────────┘图6:使用 /loop 设置的定时任务列表,自动化例行工作
这些任务单独拎出来都不复杂,但关键是"持续性"。人很容易忘记或者偷懒,但 /loop 不会。它像一个忠实的助手,按时按点地完成你交给它的例行公事。
有个细节需要注意------/loop 执行的任务应该是幂等的,也就是说,多次执行不会产生副作用。否则你可能会遇到一些奇怪的累积效应。
Ralph Wiggum:带停止条件的循环
如果说 /loop 是定时循环,那 Ralph Wiggum 就是条件循环。
这个名字来源于《辛普森一家》里的角色 Ralph Wiggum,他以天真无邪但又常常出错的形象著称。用它来命名这个功能,大概是暗示"让它一直试,直到做对为止"。
Ralph 的核心思想是:让 Claude Code 反复执行同一个任务,直到满足某个停止条件。
比如你想让 Claude Code 优化一段代码的性能,但不确定需要迭代多少次。你可以这样设置
bash
/ralph optimize this function for speed, max 15 retries, stop when benchmark > 1000 req/sClaude Code 会不断尝试不同的优化方案,每次运行基准测试,直到性能达到目标或者达到最大重试次数。
我在调试一个复杂的并发 bug 时用过这个功能。bug 的表现很不稳定,有时候出现,有时候不出现。我让 Ralph 反复运行测试套件,直到捕获到至少三次失败案例,然后自动收集堆栈信息和环境变量。
yaml
┌─────────────────────────────────────────────┐
│ Ralph Wiggum - Iterative Optimization │
├─────────────────────────────────────────────┤
│ Task: Optimize database query performance │
│ Target: >1000 req/s | Max retries: 15 │
│ │
│ Progress: █████████░░░░░ 53% │
│ Attempt 8 of 15 │
│ │
│ Attempt 1: 450 req/s ✗ │
│ Attempt 2: 520 req/s ✗ │
│ ... │
│ Attempt 7: 890 req/s ✗ │
│ Attempt 8: 945 req/s (Running...) ⚡ │
│ │
│ ⚡ Approaching target! Current: 945 req/s │
└─────────────────────────────────────────────┘图7:Ralph Wiggum 正在执行第 8 次尝试,距离目标还有差距
整个过程花了两个小时,但如果靠人工监控,我可能得守一整天。
Ralph 的适用场景是那些"不确定性高但验证成本低"的任务。你知道最终目标是什么,但不确定路径该怎么走,这时候就可以让 Ralph 去暴力探索。
不过要小心设置合理的停止条件,否则它可能会无限循环下去,烧光你的 token 配额。
Codex 插件:代码审查的利器
Codex 是 OpenAI 的代码生成模型,但你可能不知道,Claude Code 可以通过插件调用它。
听起来有点奇怪------为什么要用竞争对手的工具?
答案是:多样性。不同的模型有不同的强项,有时候 Codex 在某些类型的代码分析上表现更好。
安装 Codex 插件后,你可以这样使用
bash
/codex:review src/auth/login.ts这会调用 Codex 对指定文件进行代码审查,找出潜在的安全漏洞、性能问题和最佳实践违反。
我把这个集成到了 CI 流程中。每次 pull request 创建时,自动运行 /codex:review 对所有修改的文件进行检查。虽然会增加几分钟的构建时间,但它已经帮我发现了至少五个隐蔽的 bug。
csharp
┌─────────────────────────────────────────────┐
│ Codex Code Review Report │
├─────────────────────────────────────────────┤
│ File: src/auth/login.ts │
│ │
│ ⚠ Warning (Line 42) │
│ SQL injection risk - Use parameterized │
│ queries instead of string concatenation │
│ │
│ ✘ Critical (Line 67) │
│ Missing input validation - Validate email │
│ format before processing │
│ │
│ ℹ Suggestion (Line 23) │
│ Consider using async/await for better │
│ readability │
│ │
│ Summary: 1 critical, 1 warning, 1 suggestion│
└─────────────────────────────────────────────┘图8:Codex 插件生成的代码审查报告,标注了潜在问题和建议
除了代码审查,Codex 插件还可以作为通用代理入口。你可以让它执行任何需要深度代码理解的任务,比如
- 生成详细的代码文档
- 识别重复代码并提出重构建议
- 分析依赖关系图
- 评估代码复杂度
我不建议你完全依赖 Codex 的判断,但它确实是一个有价值的第二意见。就像写文章时需要编辑一样,写代码时也需要另一个视角来查漏补缺。
-c 和 --add-dir:恢复中断的对话
你有没有遇到过这种情况?
正在跟 Claude Code 深入讨论一个架构设计问题,突然网络断了,或者浏览器崩溃了。等你重新连接时,发现之前的对话全没了,得从头再来。
-c 参数就是为解决这个问题而设计的。
当你启动 Claude Code 时,加上 -c 参数,它会自动恢复到上一次中断的对话
bash
claude-code -c这个功能依赖于本地的会话持久化机制。Claude Code 会定期将对话历史保存到磁盘,即使程序意外退出,也能在下次启动时恢复。
我有一次在飞机上用 MacBook 跟 Claude Code 讨论系统设计,写到一半电脑没电关机了。落地后开机,运行 claude-code -c,所有内容和上下文都完好无损。那一刻我真的感受到了工具设计者的用心。
vbnet
┌─────────────────────────────────────────────┐
│ Session Recovery │
├─────────────────────────────────────────────┤
│ ✓ Successfully restored previous session │
│ │
│ Session interrupted: 2 hours ago │
│ Last activity: Designing microservices │
│ Messages recovered: 23 │
│ Context files: 8 │
│ │
│ Recent conversation: │
│ You: Let's discuss API gateway pattern │
│ AI: The API gateway acts as a single... │
│ You: How does it handle auth? │
│ AI: Authentication can be centralized... │
│ │
│ ❯ Continue from where we left off █ │
└─────────────────────────────────────────────┘图9:使用 -c 参数成功恢复到中断前的对话状态
--add-dir 则是另一个实用功能。它允许你将外部目录添加到当前对话的上下文中。
比如你正在讨论前端项目,但需要参考后端的 API 定义。你可以这样做
bash
claude-code --add-dir ../backend-api这样 Claude Code 就能同时访问两个目录的文件,给出更全面的建议。
这个功能在处理单体仓库(monorepo)时特别有用。你可以一次性添加多个子项目,让 Claude Code 理解它们之间的关联。
子代理:脏活累活的专家
有些任务很繁琐,但又不需要你亲自盯着。
比如在一个大型代码库里搜索所有使用了某个废弃 API 的地方,或者分析几千行日志找出异常模式。这些任务不需要创造性思维,但需要耐心和细致。
子代理(sub-agent)就是为这类任务而生的。
你可以创建一个临时代理,给它分配一个具体的任务,然后让它自己去完成。在此期间,你可以继续做其他事情,不用等待。
创建子代理的方式
bash
/spawn search all files for deprecated API usage and generate report这会启动一个专门的代理来执行搜索任务。完成后,它会返回一份报告,列出所有匹配的文件和行号。
yaml
┌─────────────────────────────────────────────┐
│ Sub-Agent Execution │
├─────────────────────────────────────────────┤
│ 🔍 Search Agent #42 [Running] │
│ Finding deprecated API usage │
│ │
│ Scanning: src/components/ ... │
│ Files checked: 127/342 │
│ Progress: █████████░░░░░ 37% │
│ Matches found: 8 │
│ │
│ Main conversation continues... │
│ ❯ Working on new feature █ │
└─────────────────────────────────────────────┘图10:子代理正在后台执行代码搜索任务,主对话不受影响
子代理的优势在于隔离性。它在独立的环境中运行,有自己的上下文和 token 配额,不会影响你的主对话。
我经常用子代理做这些事
日志分析:让它扫描最近一周的错误日志,分类统计各种异常的出现频率。
代码审计:让它检查所有新添加的代码是否符合团队的编码规范。
文档同步:让它对比代码和文档的差异,找出过时或缺失的部分。
测试用例生成:让它根据函数签名自动生成单元测试的骨架。
每个子代理完成任务后都会自动销毁,不会留下任何残留状态。这种"用完即弃"的模式非常适合处理一次性任务。
代理团队:多人协作解决复杂问题
最后一个技巧,也是最强大的一个------代理团队。
想象一下这个场景:你要设计一个完整的电商系统,包括用户认证、商品管理、订单处理、支付集成等多个模块。如果靠一个代理来做,要么上下文爆炸,要么顾此失彼。
代理团队的思路是:创建多个具有不同角色的代理,让它们分工协作。
比如你可以这样设置
bash
/team create \
--architect "负责整体架构设计" \
--frontend "负责前端实现" \
--backend "负责后端逻辑" \
--dba "负责数据库设计" \
--qa "负责测试和质量保证"然后给团队分配任务
bash
/team assign "设计一个支持百万用户的电商系统"这些代理会开始相互协作。架构师先给出整体方案,前端和后端根据方案分别设计各自的模块,DBA 设计数据模型,QA 提出测试策略。过程中它们会互相沟通,解决冲突,最终产出一个完整的解决方案。
ini
┌─────────────────────────────────────────────┐
│ Agent Team Collaboration │
├─────────────────────────────────────────────┤
│ Project: E-commerce System Design │
│ │
│ 👷 Architect [Completed] ✓ │
│ Overall system architecture │
│ │
│ 💻 Frontend Dev [In Progress] ▶ │
│ React + TypeScript implementation │
│ │
│ ⚙️ Backend Dev [In Progress] ▶ │
│ Node.js API services │
│ │
│ 🗄️ DBA [Waiting] ○ │
│ Database schema design │
│ │
│ 🧪 QA Engineer [Waiting] ○ │
│ Test strategy and automation │
│ │
│ ✓ Team coordination active │
│ ✓ 2 agents working in parallel │
└─────────────────────────────────────────────┘图11:多角色代理团队协同工作,各司其职解决复杂问题
我第一次看到这个功能时,觉得有点科幻。但实际使用后,发现它确实能解决一些单代理无法处理的复杂问题。
关键在于,每个代理都可以有专门的知识和视角。架构师代理可以加载系统设计模式的资料库,DBA 代理可以加载数据库优化的最佳实践,QA 代理可以加载常见测试场景。这样每个子问题都能得到最专业的处理。
当然,代理团队也不是万能的。它适合那些可以明确分解成多个子任务的复杂问题。对于需要全局一致性判断的任务,还是需要人类来做最终的整合和决策。
写在最后
我用 Claude Code 三个月,最大的感受是:工具的强大不在于它能做什么,而在于你如何用它。
刚开始时,我只把它当成一个代码生成器。问问题,拿答案,复制粘贴,完事。这种用法没问题,但就像是用智能手机刷短视频------你能说它没用吗?当然不能。但你错过了太多可能性。
这十个技巧,每一个都代表了一种不同的使用范式。/powerup 是系统化学习,/btw 是上下文管理,双击 ESC 是可逆性思维,hook 是自动化意识,/loop 和 Ralph 是持续执行,Codex 是多元视角,-c 是状态持久化,子代理是任务委托,代理团队是分布式协作。
把这些范式内化成自己的思维方式后,我发现自己不只是在用 Claude Code,而是在设计一个智能化的工作流。我不再是被动地等待答案,而是主动地编排各种能力,让它们在我需要的时刻以我需要的方式发挥作用。
这种感觉,就像是从一个普通司机变成了赛车工程师。你不再只是踩油门和打方向盘,而是在调校引擎、优化空气动力学、制定比赛策略。车还是那辆车,但你对它的理解和掌控,已经完全不在一个层次上了。
昨晚我又运行了一次 /insight。报告显示,我现在平均每次对话会使用 3.7 个高级功能,而三个月前这个数字是 0.2。更重要的是,我的任务完成时间缩短了 60%,而且代码质量反而提高了。
这不是因为 Claude Code 变聪明了,而是因为我学会了如何更好地与它协作。
也许这就是 AI 时代最重要的技能------不是知道怎么提问,而是知道怎么设计人与机器的协作模式。工具会越来越强大,这是必然的。但能否把它们变成自己能力的延伸,取决于我们是否愿意投入时间去理解和掌握。
就像任何一个值得精通的技艺一样,没有捷径,但有方法。这十个技巧,就是我的方法。希望它们也能帮到你。