摘要 :ALBEF(Li et al., 2021)是一个典型的 "先对齐(Align)再融合(Fuse)" 的视觉-语言预训练框架:先在 单模态编码器 上加入 图文对比学习(ITC) ,把图像与文本拉到同一个语义空间;再用带 跨模态注意力 的 多模态编码器 去做 图文匹配(ITM) 和 掩码语言建模(MLM) ,让模型学到更"落地"的细粒度对齐。为了应对网页图文对的噪声,ALBEF 进一步引入 Momentum Distillation(动量蒸馏):用 EMA 的动量模型做教师,生成软目标(pseudo-targets),引导学生在 ITC/MLM 等任务上更稳健地学习。
一句话理解 ALBEF:先用 CLIP 式的对比学习把图文"翻译到同一种语言",再让跨注意力去做细粒度融合;遇到网页噪声,就让一个"慢更新的老师模型"给出更软、更可靠的学习目标。
关键词:ALBEF;Align before Fuse;图文对比学习(ITC);图文匹配(ITM);掩码语言建模(MLM);跨模态注意力;动量蒸馏(Momentum Distillation);MoCo 队列;难负样本挖掘
系列文章:
- Transformer 30. MoCo:用「动量编码器 + 队列字典」把对比学习做成可扩展的"字典查找"
- Transformer 29. ViLT:Vision-and-Language Transformer 所有细节
- Transformer 28. CLIP(Contrastive Language--Image Pre-training)
- Transformer 27. Vision Transformer(ViT):把图像当作「词序列」的编码器
- (完整系列文章列表参见文章末尾)
0. ALBEF 速览:输入什么?输出什么?
ALBEF 的核心并不是"换了一个更复杂的 encoder",而是 训练流程的拆分 :先对齐 (unimodal encoders)→ 再融合(multimodal encoder)。
0.1 输入(Input)
- 图像 :一张图片 I I I(通常经 resize、normalize 后送入视觉编码器)。
- 文本 :一句 caption / 描述 T T T(BERT tokenizer 后送入文本编码器)。
0.2 输出(Output)
预训练时模型输出主要用于三类损失:
- ITC(Image-Text Contrastive) :输出 图像全局向量 与 文本全局向量 (一般取各自的 CLS 表示,经过投影/归一化后做相似度矩阵)。
- ITM(Image-Text Matching) :输出一个二分类概率,判断图文是否匹配(多模态 encoder 的 CLS 作为 pair 表示)。
- MLM(Masked Language Modeling):输出被 mask 的 token 在词表上的分布(多模态 encoder 的 token 位置输出)。
💡 理解要点:ALBEF 把"图文对齐"拆成两层含义:
粗粒度对齐:图像全局语义 ↔ 文本全局语义(ITC)。
细粒度对齐:具体词与具体视觉区域/patch 的交互(MLM/ITM 的跨注意力里发生)。
💡 CLS 是什么?
[CLS](classification token)指的是序列最前面的一个特殊 token :模型会通过自注意力把整段输入的信息"汇聚"到它对应的隐藏向量上,所以它经常被当作全局表示来用。在 BERT/文本编码器 里:
[CLS]是一个特殊符号 token,对应的向量常用作句子级表示。在 ViT/视觉编码器 里:通常也会加一个 class token (很多文章也沿用记号写成
[CLS]),用来汇聚整张图的 patch 信息。
1. 背景:什么是 Fusion?为什么要 "Align before Fuse"?
1.1 关于融合(Fusion):早融合 / 中融合 / 晚融合(最重要的三分法)
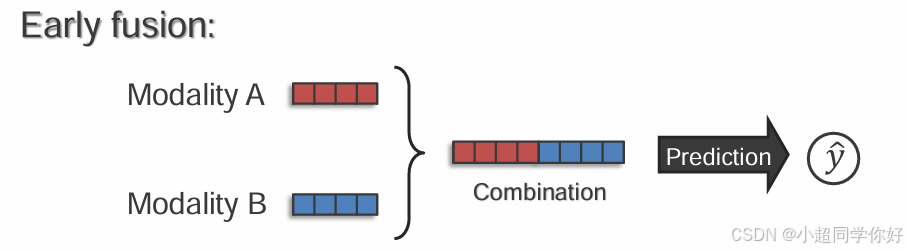
我们可以将 fusion 分成三类(Early / Intermediate / Late fusion):
-
早融合(Early fusion):在模型很早就把两种模态拼起来,再一起过一个大模型。
-
直觉:像"把图和文打成一锅粥一起煮"。
-
风险:如果两种输入一开始就没对齐,这锅粥可能越煮越糊(优化更难)。
-
-
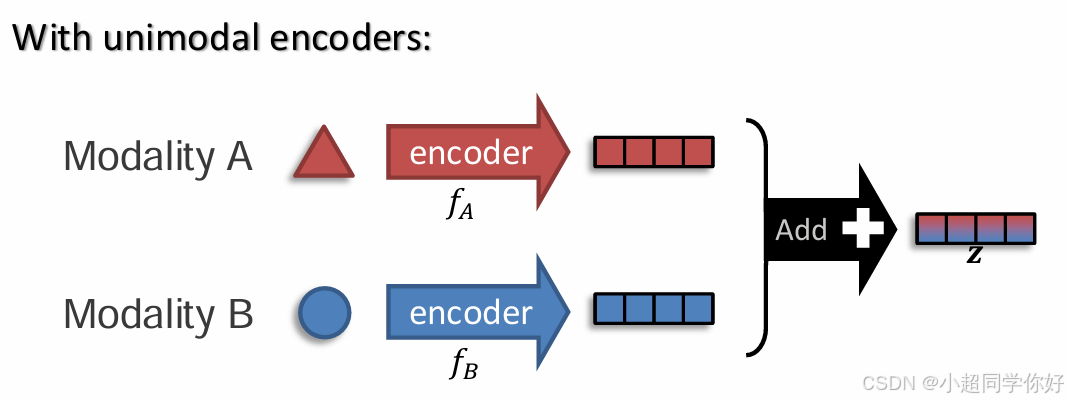
中融合(Intermediate fusion):先各自用 unimodal encoder 抽特征,再在中间层做交互(cross-attention / co-attention / gated fusion 等)。
-
直觉:像"先各自写好摘要,再在会议上互相提问对齐"。
-
-
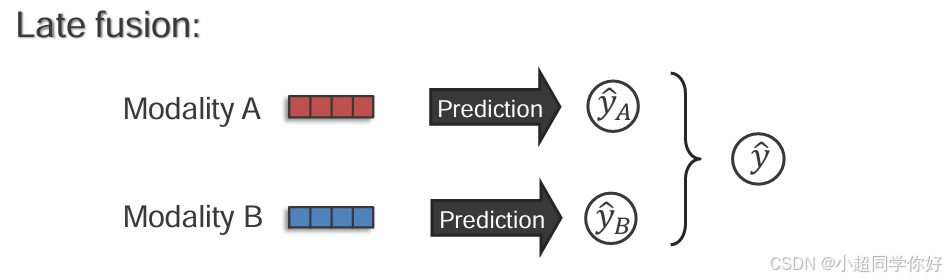
晚融合(Late fusion):各自独立做预测,再把两个预测合起来(加权/投票/再学习一个组合器)。
-
直觉:像"两个专家各写一份结论,最后合并投票"。
-
💡 理解要点:ALBEF/CLIP/ViLT 的区别,本质就在"什么时候融合":
- CLIP:几乎不做融合,只做 对齐(alignment);
- ViLT:属于 早融合(把图 token + 文 token 直接拼一起进 Transformer);
- ALBEF:属于 中融合 ,但它强调 先把表示对齐好(align),再去做 cross-attention 融合(fuse)。
1.2 为什么要 "Align before Fuse"?
很多早期 VLP 方法把"视觉 token(通常是 region 特征)"与"文本 token"直接塞进一个多模态 Transformer 里做交互。但现实是:
- 视觉 token 与文本 token 在训练初期 并不天然对齐;
- 跨注意力一上来就要学"谁对应谁",学习目标会很难、也很不稳;
- 网页数据噪声巨大:caption 未必真的描述图像主内容。
ALBEF 的策略是:
- 先用 ITC(Image-Text Contrastive) 把两种模态拉到一个共同语义空间(就像先把两个人教会同一种语言)。
- 再在多模态 encoder 里做融合任务(跨注意力才有更好的"对齐起点")。
🔍 类比:想象你要让一位中文老师和一位英文老师共同讲一门课。
- 直接让他们在台上即兴合作(Fuse-first)会很混乱。
- 先让他们把关键概念翻译成一致的术语表(Align-first),再共同授课(Fuse),效果会稳定得多。
2. 模型结构:三段式(图像编码器 + 文本编码器 + 多模态编码器)
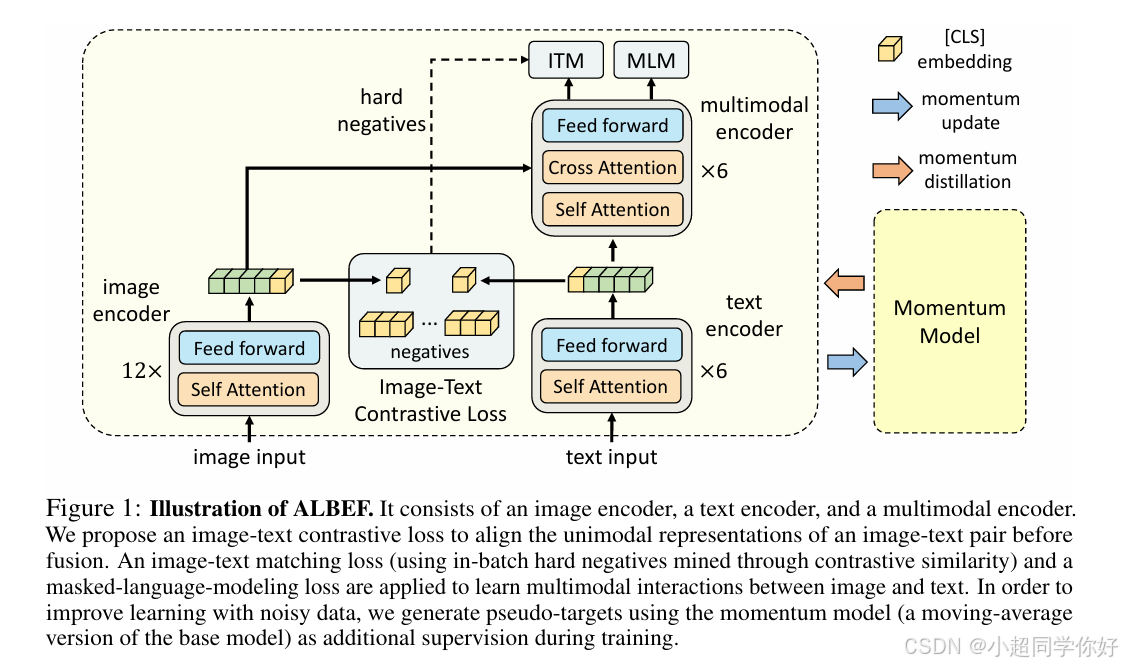
ALBEF 的结构可以概括为三部分:
- 图像编码器 :通常用 ViT-B/16 (参见 ViT),输出视觉 token 序列 { v c l s , v 1 , ... , v N } \{v_{cls}, v_1,\dots,v_N\} {vcls,v1,...,vN}。
- 文本编码器 :Transformer(可初始化自 BERT 的前几层),输出文本 token 序列 { w c l s , w 1 , ... , w L } \{w_{cls}, w_1,\dots,w_L\} {wcls,w1,...,wL}。
- 多模态编码器 :Transformer(可初始化自 BERT 的后几层),每层通过 cross-attention 把视觉 token 融入文本 token,得到融合后的序列表示,用于 ITM/MLM(Image-Text Matching/Masked Language Modeling)。
💡 理解要点:
- ITC (Image-Text Contrastive) 只看"各自的 CLS"(单模态编码器)。
- ITM/MLM(Image-Text Matching/Masked Language Modeling)才真正需要跨模态交互(多模态编码器)。
下面,我们来一步一步解释一下这张图。
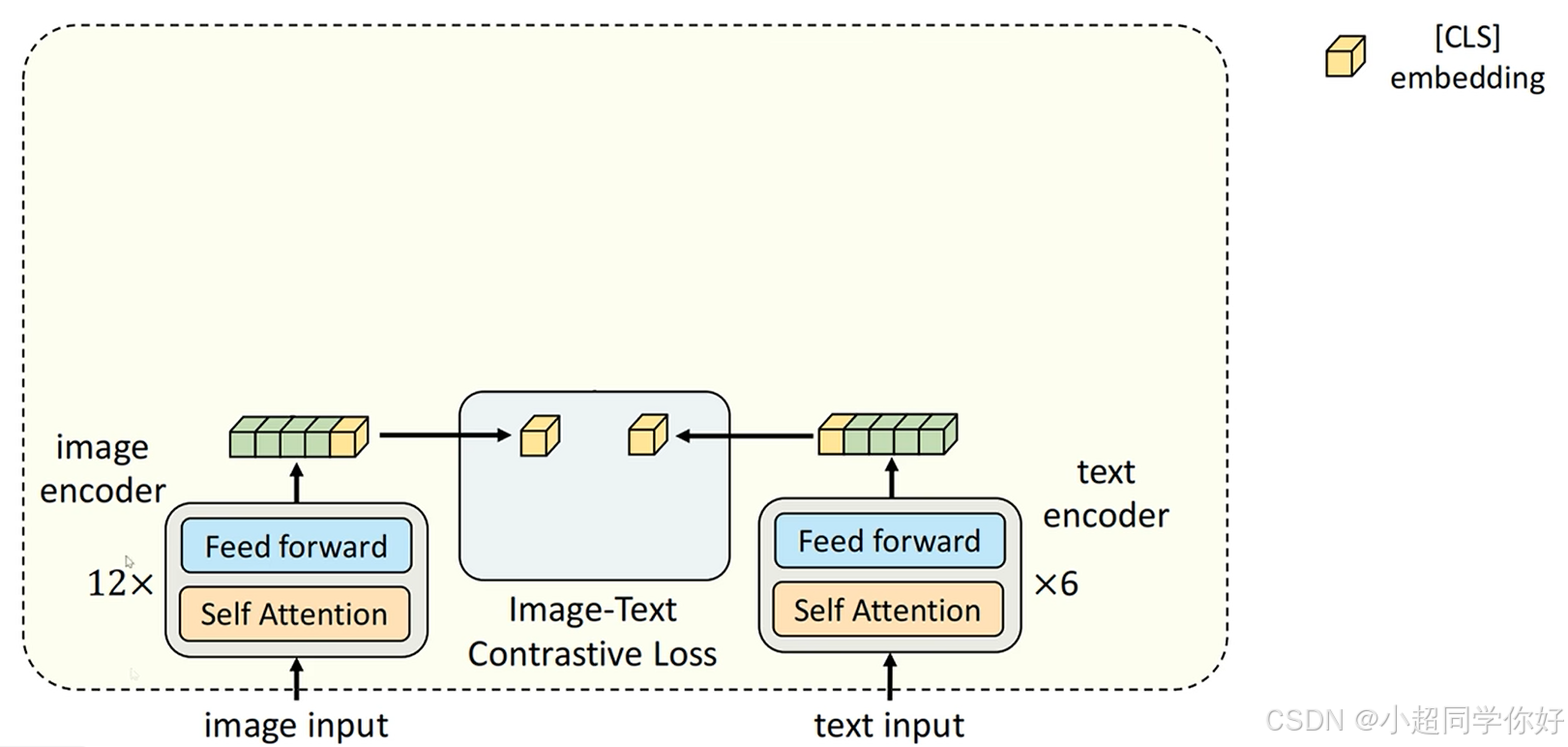
首先,左边是一个图片编码器,采用的是ViT结构,右边是一个文本编码器,采用的是BERT结构。可以看到,图像这边采用了12层,文本编码器采用了6层。图片编码器网络层数是大于文版编码器的。然后,每个编码器都有一个额外的CLS token,用来分别提取图片和文本的特征。接着,用它们提取的特征计算余弦相似度,计算Loss。目前的这个结构和CLIP是非常相似的。不同的是,CLIP文本编码器部分用的是带mask的注意力机制,提取最后一个token的向量来代表整个文本;而这里用的是双向注意力机制,提取的是第一个CLS token的向量来代表整个文本。除此之外,其他都是完全一致的。所以到目前位置,ALBEF里有一个CLIP模型,通过对图像和文本的对比学习,对齐了模型文本和图像的特征的表示,这也是这篇论文最重要的部分之一。
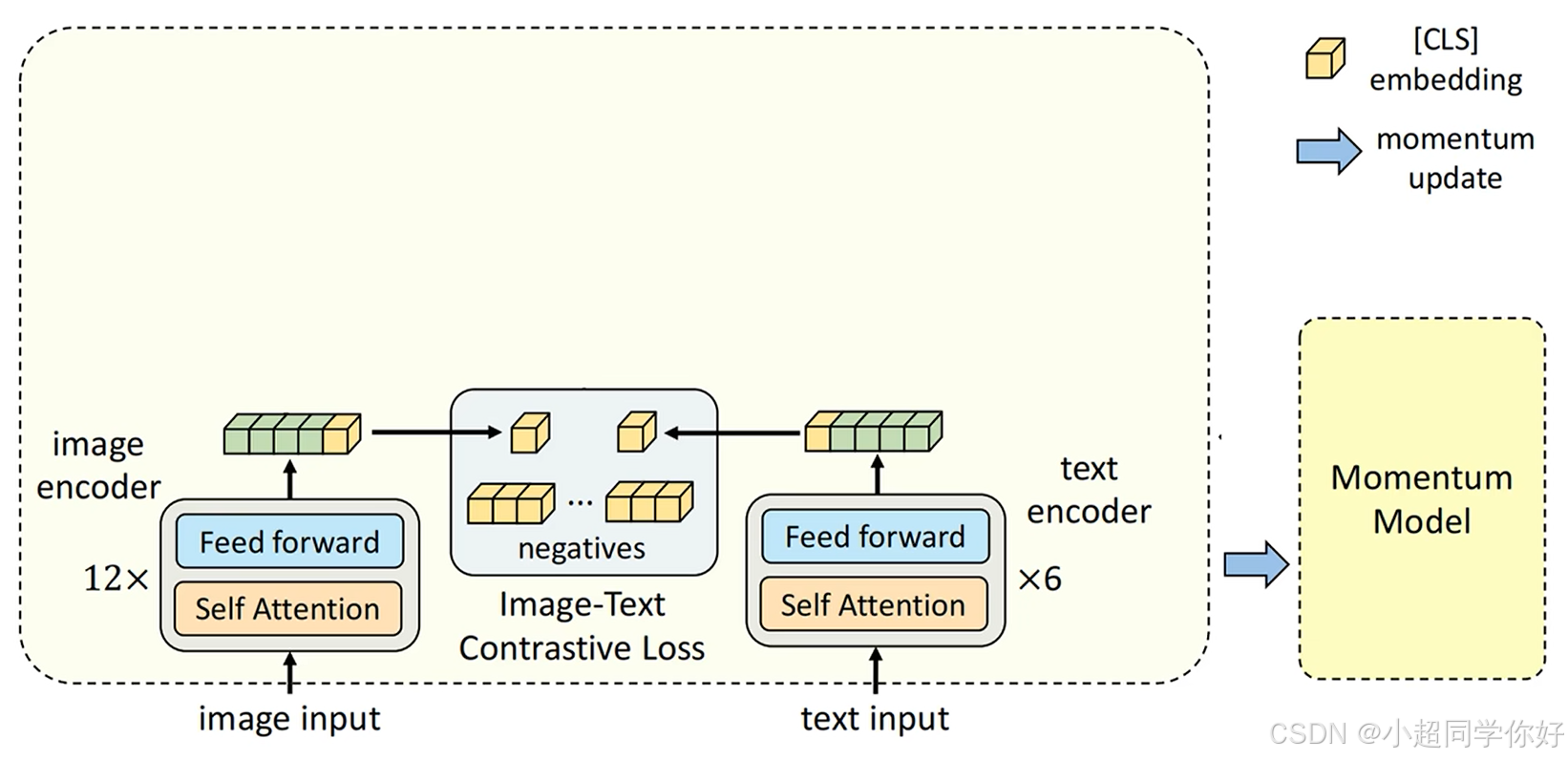
另外,ALBEF结合了 MOCO 的思想,对CLIP进行了改进。增加了动量模型。这个动量模型既有图片encoder的参数,又有文本encoder的参数。这样,动量模型就可以通过队列缓存,给图片和文本提供又多又一致的负例了。需要注意的是,这里训练模型生成的图像向量是和动量模型生成的文本向量队列进行对比,反过来,训练模型生成的文本向量是和动量模型生成的图片向量队列进行对比。每个batch训练模型跟新完自己的参数后,会去动量跟新动量模型的参数。
接下来,就进入到了 ALBEF 多模态融合的网络部分:
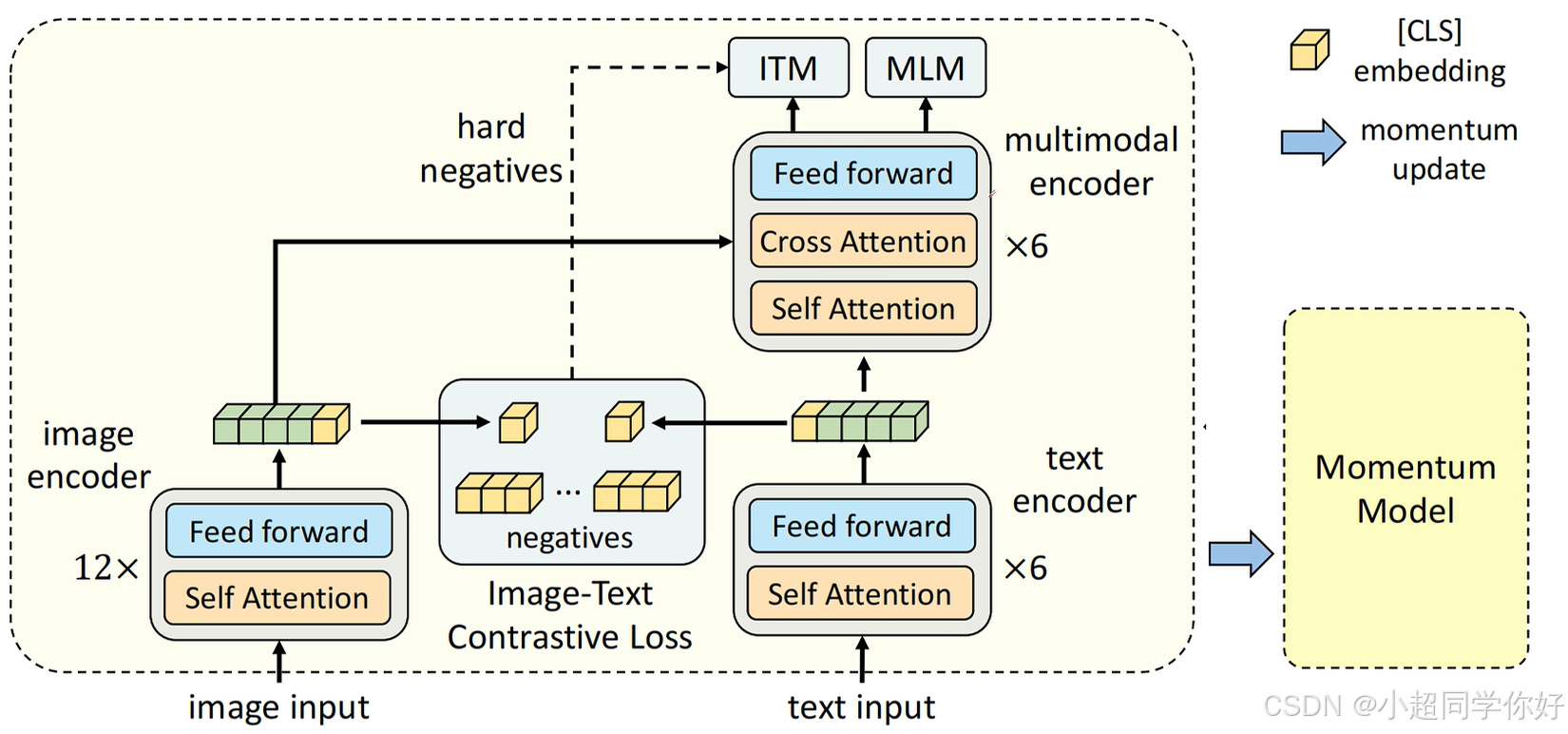
可以看到,它在文本编码器已经有了6层的基础上,又增加了6层。不同的是,新增加的这6层,每一层都有一个 cross attention。cross attention 里的query是来自文本编码器,K和V是来自图像编码器,这样就实现了多模态的融合。其实这里的 cross attention 就是 encoder-decoder transformer 架构里面的 decoder 里面的多头子注意力机制模块。
下面,我们就来详细介绍图中的三个任务:
- ITC(Image-Text Contrastive)
- ITM(Image-Text Matching)
- MLM(Masked Language Modeling)
3. 预训练目标:ITC + ITM + MLM
ALBEF 的论文叙事非常清晰:先用 ITC(Image-Text Contrastive) 让语义空间对齐,再用 ITM/MLM(Image-Text Matching/Masked Language Modeling) 让对齐更"落地"。
实际上,ITC、ITM、MLM 各自都有一个对应的 loss(cost function),训练时通常是把它们加权求和成总目标来最小化:
L t o t a l = λ i t c L i t c + λ i t m L i t m + λ m l m L m l m . \mathcal{L}{total}=\lambda{itc}\mathcal{L}{itc}+\lambda{itm}\mathcal{L}{itm}+\lambda{mlm}\mathcal{L}_{mlm}. Ltotal=λitcLitc+λitmLitm+λmlmLmlm.
先用一句话把三项的"分工"说清楚(先有全局地图,后面再看公式就不容易迷路):
- ITC:用对比学习把"整图 vs 整句"的全局语义拉到同一空间(粗粒度对齐,主要依赖单模态编码器的 CLS)。
- ITM:做"这对图文匹不匹配"的二分类(更偏判别,依赖多模态 encoder 的融合表征,常配 hard negatives)。
- MLM:mask 掉一些词,让模型在"图 + 上下文"条件下把词补回来(细粒度约束,逼跨注意力把视觉信息注入词级表示)。
💡 理解要点 : λ \lambda λ 是"配方旋钮"。三种 loss 的尺度/难度不同,训练时往往需要用 λ \lambda λ 调节谁的梯度更主导;很多论文也会先用 λ = 1 \lambda=1 λ=1 写成简单相加,方便表述(我们在 3.4 会再详细解释)。
3.1 ITC(Image-Text Contrastive):图文对比学习(对齐全局语义)
3.1.1 从 CLS 到对比空间
这一小节你只要抓住一个核心:ITC 只关心"整张图"和"整句话"像不像,不关心词和区域怎么对齐。它提供的是"粗粒度对齐",让后面的跨注意力不至于从零开始学。
从图像编码器与文本编码器取全局表示(通常是 CLS):
h i v ∈ R d v , h i t ∈ R d t \mathbf{h}^v_i \in \mathbb{R}^{d_v},\quad \mathbf{h}^t_i \in \mathbb{R}^{d_t} hiv∈Rdv,hit∈Rdt
再经线性投影并做 L2 归一化,映射到同一个维度 d d d(例如 256):
z i v = g v ( h i v ) ∥ g v ( h i v ) ∥ 2 , z i t = g t ( h i t ) ∥ g t ( h i t ) ∥ 2 . \mathbf{z}^v_i = \frac{g_v(\mathbf{h}^v_i)}{\|g_v(\mathbf{h}^v_i)\|_2},\quad \mathbf{z}^t_i = \frac{g_t(\mathbf{h}^t_i)}{\|g_t(\mathbf{h}^t_i)\|_2}. ziv=∥gv(hiv)∥2gv(hiv),zit=∥gt(hit)∥2gt(hit).
此时点积就是余弦相似度:
s i , j = ( z i v ) ⊤ z j t . s_{i,j} = (\mathbf{z}^v_i)^\top \mathbf{z}^t_j. si,j=(ziv)⊤zjt.
3.1.2 动量队列:让负样本更"多"
与 CLIP(in-batch negatives)不同,ALBEF 参考 MoCo 思路,用 动量编码器 产生 key,并维护 队列(queue) 存储最近的图文表示(详见 Sik-Ho Tsang 的 1.2.1 小节)。
设动量模型产生的图/文向量记为 z ′ v , z ′ t \mathbf{z'}^v, \mathbf{z'}^t z′v,z′t,并放入队列作为负样本集合。
于是对某个图像 i i i,它与"文本集合(队列 + 当前 batch)"的 softmax 概率为:
p i , j v → t = exp ( s i , j / τ ) ∑ k exp ( s i , k / τ ) . p^{v\to t}{i,j} = \frac{\exp(s{i,j}/\tau)}{\sum_k \exp(s_{i,k}/\tau)}. pi,jv→t=∑kexp(si,k/τ)exp(si,j/τ).
同理可得 p t → v p^{t\to v} pt→v(对称方向)。其中 τ \tau τ 是可学习温度。
L i t c = 1 2 ( H ( y v → t , p v → t ) + H ( y t → v , p t → v ) ) , \mathcal{L}_{itc} = \frac{1}{2}\Big(H(\mathbf{y}^{v\to t}, \mathbf{p}^{v\to t}) + H(\mathbf{y}^{t\to v}, \mathbf{p}^{t\to v})\Big), Litc=21(H(yv→t,pv→t)+H(yt→v,pt→v)),
其中 y \mathbf{y} y 为 one-hot:只有正配对为 1,其余为 0。
💡 理解要点:ALBEF 的 ITC 你可以把它理解为"CLIP + MoCo":
- CLIP 用 batch 做负样本;
- ALBEF 用 队列 把负样本数量变得更大、更稳定(尤其当 batch 不够大时)。
🔍 实际例子:如果一个 batch 只有 64,对比学习看到的负样本也只有 63 个;但如果你维护一个队列(比如几千/几万条历史样本),那么"这张图要从更多候选文本里选对的那一句",学习信号会更强。
3.2 ITM (Image-Text Matching):图文匹配(二分类)
ITM 的目标是判断图文是否匹配。关键在于:负样本不能太简单 。
ALBEF 用 ITC 的相似度在 batch 内做 hard negative mining:
- 对每个图像,按 p v → t p^{v\to t} pv→t 采样一个"最像但不匹配"的文本作为负例;
- 对每个文本,按 p t → v p^{t\to v} pt→v 采样一个"最像但不匹配"的图像作为负例。
得到正负 pair 后,送入多模态 encoder,取融合后的 CLS 表示 h c l s m m \mathbf{h}^{mm}_{cls} hclsmm,接一个二分类头:
p i t m = s o f t m a x ( W i t m h c l s m m ) , L i t m = H ( y i t m , p i t m ) . p_{itm} = \mathrm{softmax}(W_{itm}\,\mathbf{h}^{mm}{cls}), \quad \mathcal{L}{itm} = H(\mathbf{y}{itm}, p{itm}). pitm=softmax(Witmhclsmm),Litm=H(yitm,pitm).
🔍 实际例子 :如果正样本是"海边的狗"配上沙滩狗图,随机负样本可能是"一辆汽车"配上狗图(太简单)。
而 hard negative 更可能是"草地上的狗"或"海边的狼"这类------语义接近但细节不对,ITM 才会被迫学到更细粒度的对齐。
3.3 MLM:掩码语言建模(但用图像做条件)
MLM 与 BERT 相同:随机 mask 一部分词,让模型预测原词。但在 ALBEF 中,预测依赖的是 图文融合后的表示 。
设被 mask 的位置集合为 M \mathcal{M} M,对每个位置输出词表分布 p θ ( x m ∣ I , T ^ ) p_\theta(x_m \mid I, \hat{T}) pθ(xm∣I,T^):
L m l m = − ∑ m ∈ M log p θ ( x m ∣ I , T ^ ) . \mathcal{L}{mlm} = -\sum{m\in\mathcal{M}} \log p_\theta(x_m \mid I, \hat{T}). Lmlm=−m∈M∑logpθ(xm∣I,T^).
💡 理解要点:这一步是"让文字去看图"------如果只靠文本上下文就能猜出来(比如固定搭配),那 MLM 信号会弱;但当 mask 的词与图像内容强相关时,跨注意力会被迫把视觉信息注入文本 token。
🔍 实际例子:caption 是 "a dog is playing with a MASK"。只靠文本你可能猜 "ball/toy" 都行;但图像里如果清楚是一只飞盘,那么跨注意力就能让模型更偏向 "frisbee"。
3.4 总损失(不含蒸馏)
更通用的写法是加权和((\lambda) 用来平衡不同任务的梯度贡献):
L t o t a l = λ i t c L i t c + λ i t m L i t m + λ m l m L m l m . \mathcal{L}{total}=\lambda{itc}\mathcal{L}{itc}+\lambda{itm}\mathcal{L}{itm}+\lambda{mlm}\mathcal{L}_{mlm}. Ltotal=λitcLitc+λitmLitm+λmlmLmlm.
如果你在论文/复现里看到"直接相加",通常只是把权重设为 1(或把权重吸收到学习率/实现细节里)得到一个更简洁的记号:
L = L i t c + L i t m + L m l m . \mathcal{L} = \mathcal{L}{itc} + \mathcal{L}{itm} + \mathcal{L}_{mlm}. L=Litc+Litm+Lmlm.
💡 理解要点 :优化上它们并不是"三次独立训练",而是同一次反向传播里同时最小化一个总目标 。总梯度会把三项梯度加起来:
∇ L t o t a l = λ i t c ∇ L i t c + λ i t m ∇ L i t m + λ m l m ∇ L m l m \nabla \mathcal{L}{total}=\lambda{itc}\nabla \mathcal{L}{itc}+\lambda{itm}\nabla \mathcal{L}{itm}+\lambda{mlm}\nabla \mathcal{L}_{mlm} ∇Ltotal=λitc∇Litc+λitm∇Litm+λmlm∇Lmlm。所以 λ \lambda λ 真正影响的是"更新方向更像哪一个任务"。
4. 动量蒸馏 Momentum Distillation
因为在进行多模态模型的训练时,图文对都是在互联网采集的。这些图文对未必非常匹配。而我们利用这些数据构造的带掩码的语言模型会有什么问题呢?我们来看几个例子:

第一个例子里说的是北极熊在哪里。采集数据给的Ground Truth答案是Wild,即,野外。但模型预测的前五个答案分别是动物园,水池,水,池塘,野外。实际上,模型预测的前几个比标准答案还要好。如果我们用one-hot的标签去做模型调整,反而会削弱模型性能。
我们再看第二个例子:在夏天的大自然里,一个人沿着一条路在干什么?采集数据给的Ground Truth答案是standing,就是,站着。模型给出的答案有,走路,跑步等。模型其实预测的也很准确。
我们再看第二行左边这张图。采集到的数据是,抛锚的车停在路上。而模型输出的,前几个匹配的文本为,年轻的女人从车里出来;一个女人在检查坏了的车,等等。正确的答案仅仅排在第五位。
可以看到,如果在图片文本对比的ITC任务,one-hot 也会有问题。动量蒸馏就是用来解决这个问题。它的方法就是,在计算loss时不光考虑采集数据中的标准答案,且考虑当前训练模型和缓慢稳定跟新的动量模型分布不能差别太大。
- 维护一个动量模型(teacher):参数是学生参数的 EMA(Exponential Moving Average)。
- teacher 用当前输入生成 软目标(pseudo-targets),学生学习时除了拟合 one-hot 标签,也要贴近 teacher 的软分布。
4.1 ITC 的蒸馏:从 one-hot 到 soft target
teacher 计算得到相似度 s i , j ′ s'_{i,j} si,j′,再得到 soft 分布 q v → t , q t → v q^{v\to t}, q^{t\to v} qv→t,qt→v(与 p p p 同形,只是用 teacher 的表征/相似度):
q i , j v → t = exp ( s i , j ′ / τ ) ∑ k exp ( s i , k ′ / τ ) . q^{v\to t}{i,j} = \frac{\exp(s'{i,j}/\tau)}{\sum_k \exp(s'_{i,k}/\tau)}. qi,jv→t=∑kexp(si,k′/τ)exp(si,j′/τ).
学生端除了原本的交叉熵,还加入与 q q q 的 KL 距离(形式上就是 distillation):
L i t c M o D = λ H ( y , p ) + ( 1 − λ ) K L ( q ∥ p ) . \mathcal{L}^{MoD}_{itc} = \lambda\,H(\mathbf{y},\mathbf{p}) + (1-\lambda)\, \mathrm{KL}(q \,\|\, p). LitcMoD=λH(y,p)+(1−λ)KL(q∥p).
4.2 MLM 的蒸馏:teacher 给出更稳的词分布
对 masked token,teacher 给出词表分布 q m s k ( ⋅ ) q_{msk}(\cdot) qmsk(⋅)。学生端在交叉熵外,再对齐该软分布:
L m l m M o D = λ H ( y t o k e n , p θ ) + ( 1 − λ ) K L ( q m s k ∥ p θ ) . \mathcal{L}^{MoD}{mlm} = \lambda\,H(\mathbf{y}{token}, p_\theta) + (1-\lambda)\,\mathrm{KL}(q_{msk}\,\|\,p_\theta). LmlmMoD=λH(ytoken,pθ)+(1−λ)KL(qmsk∥pθ).
💡 理解要点:
- one-hot 标签 强硬,但在噪声数据上可能"错得很硬";
- soft target 更像"老师说:这题答案 80% 是 A、15% 是 B...",能缓冲噪声带来的梯度震荡。
参考:Sik-Ho Tsang 对 Momentum Distillation 的公式梳理与图示;论文也在摘要中强调该机制用于 noisy web data(见 arXiv:2107.07651)。
4.5 通过一段伪代码把 ALBEF 训练步骤连起来
现在,我们通过下面这段伪代码把整件事"串起来"。(它不是官方实现,只是把论文流程用工程视角表达出来。)
python
# 输入:一批 (image, text) 配对数据
# 输出:总损失 L = L_itc + L_itm + L_mlm (再加上 MoD 的 KL 项)
# 1) 单模态编码器(用于对齐)
v_cls = vision_encoder(image).cls # [B, d_v]
t_cls = text_encoder(text).cls # [B, d_t]
# 2) 投影 + 归一化(对比空间)
z_v = l2norm(g_v(v_cls)) # [B, d]
z_t = l2norm(g_t(t_cls)) # [B, d]
# 3) 相似度矩阵 + ITC(可配合 queue/momentum encoder 扩大负样本)
sim = z_v @ z_t.T / tau # [B, B] (或 [B, B+Q])
L_itc = symmetric_cross_entropy(sim)
# 4) 基于 ITC 相似度采 hard negatives,构造 ITM 的正负对
neg_text = sample_hard_text(sim) # 对每个 image 选一个"最像但不匹配"的 text
neg_img = sample_hard_image(sim) # 对每个 text 选一个"最像但不匹配"的 image
pairs = build_pairs(pos=(image, text), neg=(image, neg_text), neg2=(neg_img, text))
# 5) 多模态编码器(用于融合与细粒度学习)
mm_out = multimodal_encoder(pairs.image_tokens, pairs.text_tokens)
# ITM:用 [CLS] 做二分类
L_itm = cross_entropy(itm_head(mm_out.cls), pairs.itm_label)
# MLM:mask 掉一部分 token,让模型在"看图的条件下"预测
L_mlm = masked_lm_loss(mlm_head(mm_out.text_tokens), pairs.masked_labels)
# 6) Momentum distillation:用 EMA teacher 产生 soft targets,再加 KL 项
L_mod = KL(student_probs, teacher_probs)
L_total = L_itc + L_itm + L_mlm + L_mod💡 理解要点 :记住一个节奏:先对齐(ITC) → 再用对齐结果挑难负样本(ITM) → 再用融合表示做条件 MLM(MLM) → 最后用动量老师稳住训练(MoD)。
5. 与 CLIP、ViLT 的关系
| 模型 | 核心思路 | 训练目标侧重点 | 你该记住的一句话 |
|---|---|---|---|
| CLIP | 双塔对比学习 | 全局对齐(ITC) | "只把图文拉到同一空间" |
| ViLT | 单流融合 Transformer | 直接融合(ITM/MLM/WPA) | "把图文 token 直接拼一起学" |
| ALBEF | 先对齐再融合 | ITC + ITM + MLM + MoD | "先学共同语言,再做细粒度交互" |
🔍 现实含义:如果你把多模态学习看作"搭积木":
- CLIP 给了你一块非常好用的"对齐底座";
- ViLT 证明"不靠检测框也能融合";
- ALBEF 进一步告诉你:融合之前先把表示对齐好,会让跨注意力更好学、也更抗噪。
6. 小结
- ALBEF 的核心贡献 :引入 ITC 让单模态表示先对齐,再用跨注意力做 ITM/MLM 融合学习(Align before Fuse)。
- 训练技巧 :ITM 的 在线难负样本挖掘 让负样本更"有信息量";ITC 用 动量队列 放大负样本集合。
- 抗噪关键 :Momentum Distillation 用 EMA teacher 产生软目标,用 KL 引导学生,显著提升 noisy web data 下的学习稳定性。
参考与引用:
- 论文(PDF):Align before Fuse: Vision and Language Representation Learning with Momentum Distillation
- 论文(摘要页):arXiv:2107.07651
- 代码仓库(论文页面给出):salesforce/ALBEF
- 入门综述:Brief Review --- ALBEF | Sik-Ho Tsang, Medium, 2023
- B站视频:一次学懂多模态算法:ALBEF模型
系列文章:
- Transformer 30. MoCo:用「动量编码器 + 队列字典」把对比学习做成可扩展的"字典查找"
- Transformer 29. ViLT:Vision-and-Language Transformer 所有细节
- Transformer 28. CLIP(Contrastive Language--Image Pre-training)
- Transformer 27. Vision Transformer(ViT):把图像当作「词序列」的编码器
- Transformer 26. Gated DeltaNet 架构详解与 Qwen 3.5 的联系:把「精准改写」的 Delta Rule 和「一键清空」的 Gating 组合起来
- Transformer 25. Gemma 2 架构详解:交替局部/全局注意力、GQA、双层 RMSNorm 与 Logit Soft-Capping
- Transformer 24. Linear Transformer(Linear Attention)详解:用核技巧把 O(L^2) 注意力变成 O(L)
- Transformer 23. Qwen 3.5 架构介绍:混合线性/全注意力、MoE 与相对 Qwen 1 / 2 / 3 的演进
- Transformer 22. Gemma 1 架构详解:Decoder-only、GeGLU、RoPE 与每一步计算
- Transformer 21. 从 LLaMA 到 Qwen:Rotary Position Embedding(RoPE)与 YaRN 一文读懂
- Transformer 20. Qwen 3 架构介绍:模块详解与相对 Qwen 1 / Qwen 2 的演进
- Transformer 19. Qwen 2 架构介绍:相对 Qwen 1 / Qwen 1.5 的演进与 MoE 扩展
- Transformer 18. DeepSeek-R1 解析:用强化学习激励推理能力------架构、训练与「为什么看起来更聪明」
- Transformer 17. Qwen 1 / Qwen 1.5 架构介绍以及与 Transformer、LLaMA 的对比
- Transformer 16. DeepSeek-V3 架构解析:在 MLA + DeepSeekMoE 上的规模化与训练/系统创新
- Transformer 15: DeepSeek-V2 架构解析:MLA + DeepSeekMoE 与主流架构对比
- Transformer 14. DeepSeekMoE 架构解析:与 LLaMA 以及 Transformer 架构对比
- Transformer 13. DeepSeek LLM 架构解析:与 LLaMA 以及 Transformer 架构对比
- Transformer 12. LLaMA 架构介绍以及与 Transformer 架构对比
- Transformer 11. Encoder-Decoder Transformer 经典架构以及每一步骤的详细计算
- Transformer 10. Decoder Only Transformer 架构以及每一步骤的详细计算
- Transformer 9. Decoder-Encoder 层多头自注意力机制
- Transformer 8. Decoder: 掩码注意力机制以及数学推导
- Transformer 7. Decoder:架构选择、Teacher Forcing 与并行计算
- Transformer 6. Encoder 模块总结 以及 Autoencoder 介绍
- Transformer 5. Transformer中的残差连接、归一化与前馈神经网络
- Transformer 4. Embedding层与位置编码技术
- Transformer 3. Transformer的整体架构
- Transformer 2. Attention 注意力机制
- Transformer 1. 讲在 Transformer 之前:序列模型的基本思路与根本诉求