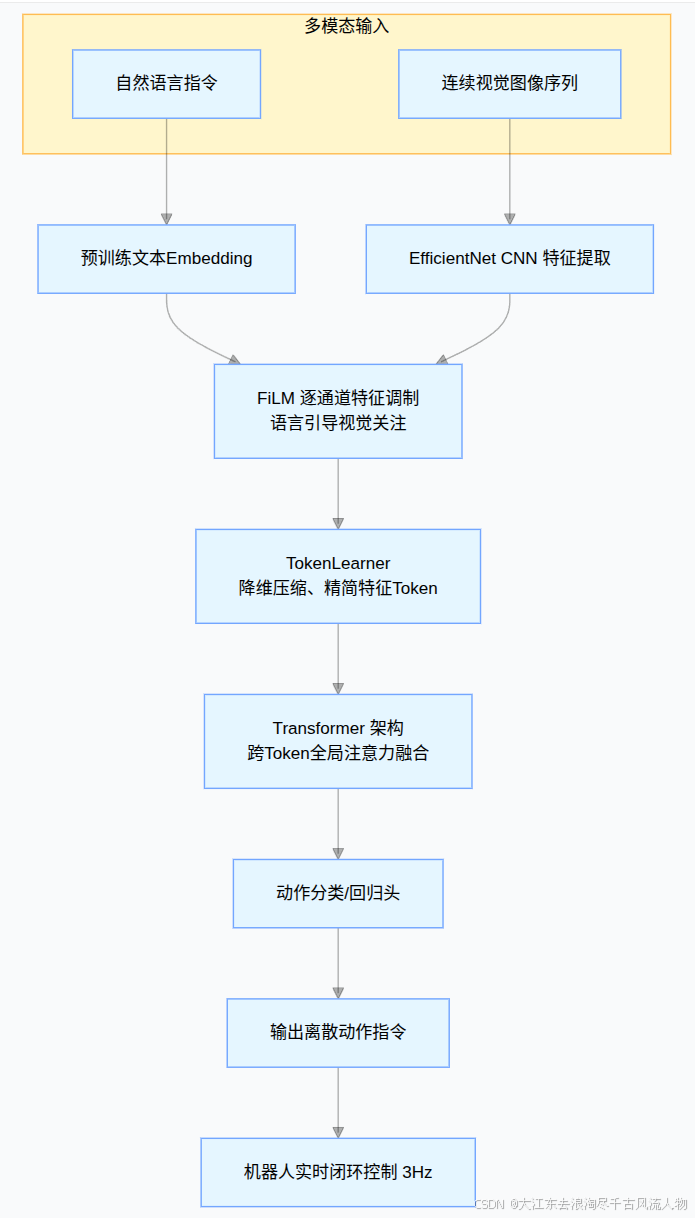
RT-1 架构图:每个模块的作用和数据流
1. 输入层:多模态输入(语言指令 + 图像序列)
- Instruction(语言指令)
比如图里的"Pick apple from top drawer and place on counter"(从顶层抽屉拿起苹果放到台面上),先送入 Universal Sentence Encoder(USE,通用句子编码器),输出一个 512 维的语言向量,作为后续 FiLM 调制的条件信号。 - Images(图像序列)
输入连续 6 帧图像,每帧分辨率为 300×300×3(RGB三通道),按时间顺序送入视觉骨干网络。
2. 核心视觉-语言融合:FiLM-EfficientNet-B3
这是 RT-1 的多模态融合核心,也是图中最主要的部分:
- 结构:基于 ImageNet 预训练的 EfficientNet-B3,包含 26 个 MBConv 模块,每个模块后都插入了一层 FiLM 调制层。
- FiLM 调制公式 :
\\text{Output} = (1+\\gamma) \\odot \\text{Feature} + \\beta
其中 (\gamma)(缩放因子)和 (\beta)(偏移因子)由 USE 输出的语言向量生成,让网络根据指令动态调整视觉特征。 - 输出:最终输出 9×9×512 的特征图,直接展平为 81 个视觉-语言融合令牌(Vision-Language Tokens)。
- 参数量:约 16M。
3. TokenLearner:高效特征压缩
- 输入:FiLM-EfficientNet 输出的 81 个令牌。
- 作用 :通过空间注意力机制,自动筛选关键特征,将 81 个令牌压缩为 8 个核心令牌,大幅减少后续 Transformer 的计算量,是实现 3Hz 实时控制的关键。
- 参数量:仅 34k,非常轻量。
4. Tokenized Inputs + 位置编码
- Tokenized Inputs:将 6 帧图像压缩后的令牌拼接,总共得到 6×8=48 个令牌(48 tokens × 512)。
- Positional Encoding(位置编码):给每个令牌加上时序位置信息,让 Transformer 理解图像序列的时间先后顺序。
5. Transformer 主干网络(Decoder-only)
- 结构:纯解码器(Decoder-only)Transformer,包含 8 层自注意力层。
- 作用:对 48 个令牌进行全局注意力建模,学习时序依赖和多模态上下文,理解完整的任务逻辑。
- 参数量:约 19M。
6. 输出层:离散动作令牌(11 维)
Transformer 输出的动作分为三部分,共 11 个离散维度:
- Mode(模式控制):3 个选项(控制机械臂、控制底盘、终止任务)。
- Arm(机械臂控制):7 个维度(x/y/z 平移、roll/pitch/yaw 旋转、夹爪开合)。
- Base(底盘控制):3 个维度(x/y 平移、偏航旋转)。
7. 闭环控制:动作输出
模型以 3Hz 的频率持续输出动作,直到输出"终止"指令或达到预设步数,实现机器人的闭环实时控制。
要不要我帮你把这个流程整理成一段可以直接写进论文的架构描述文字?
RT-1:面向真实世界规模化控制的机器人Transformer
RT-1全文详细翻译与解读,这篇论文是大模型落地实体机器人 的里程碑之作,首次把Transformer架构真正做到实时控制、海量任务泛化、跨域数据吸收,彻底改变了传统机器人单任务训练的范式。
现代机器学习模型通过从大规模、多样化、与任务无关的数据集中迁移知识,能够以零样本方式,或仅依靠少量任务专属数据集,高效完成各类下游任务并实现高性能表现。尽管这种能力已在计算机视觉、自然语言处理、语音识别等领域得到验证,但在机器人领域中仍未被充分证实 ------ 由于真实世界机器人数据采集难度极高,模型的泛化能力在此显得尤为关键。我们认为,这类通用机器人模型取得成功的核心要点之一,是采用开放式、无任务约束的训练方式,并搭配能够容纳全部多样化机器人数据的高容量架构。本文提出一类被命名为 ** 机器人 Transformer(Robotics Transformer)** 的模型,其展现出极具潜力的可扩展特性。我们基于真实机器人执行现实任务的大规模数据采集,研究了不同类型模型,以及它们的泛化能力随数据规模、模型规模和数据多样性变化的规律,从而验证了本文结论。项目网站与演示视频可访问:robotics-transformer1.github.io。
摘要(翻译)
通过从大规模、多样化、与任务无关的数据集中迁移知识,现代机器学习模型能够以零样本或仅使用少量任务专属数据,高效解决各类下游任务。尽管这种能力已在计算机视觉、自然语言处理、语音识别等领域得到验证,但在机器人领域仍未实现------由于真实世界机器人数据采集极为困难,模型的泛化能力显得尤为关键。
我们认为,通用机器人模型成功的关键在于:开放式无任务约束训练 + 高容量架构 ,让模型能够吸收海量多样化机器人数据。本文提出一类新模型,命名为机器人Transformer(RT-1),具备优秀的可扩展特性。我们基于真实机器人执行真实任务的大规模数据采集,研究了不同模型类别,以及它们随数据规模、模型规模、数据多样性变化的泛化能力,验证了上述结论。
项目主页与视频:robotics-transformer1.github.io
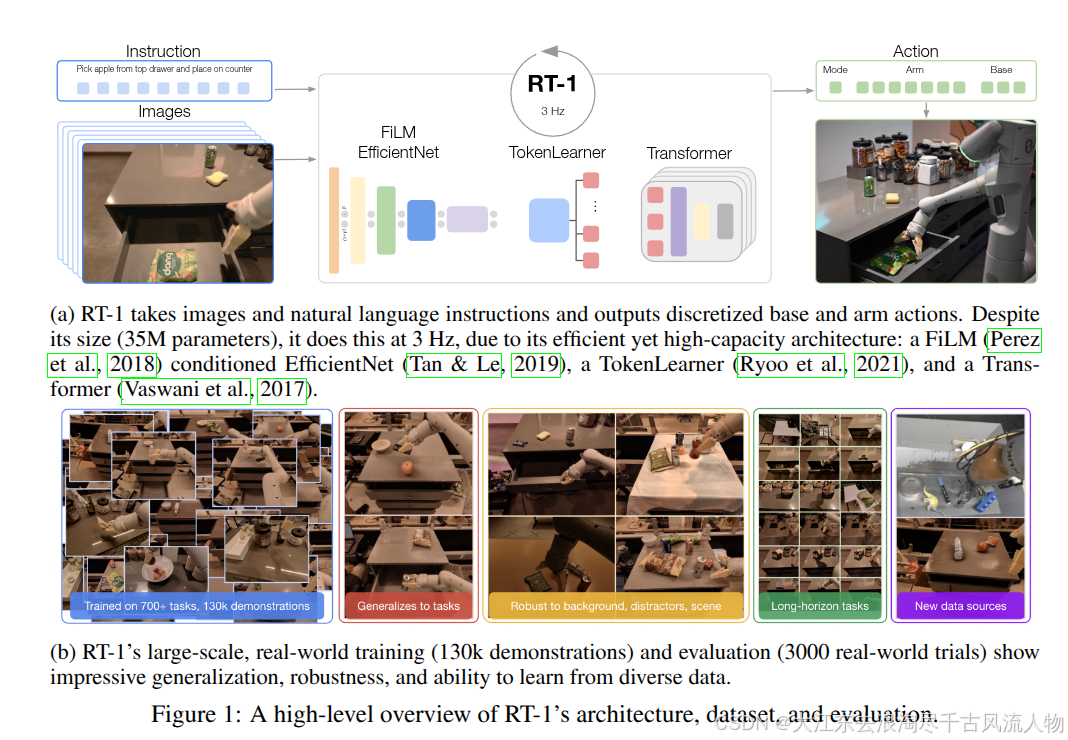
(a) RT-1 接收图像与自然语言指令,输出离散化的底盘与机械臂动作。尽管模型参数量达到 3500 万,它仍能以 3 赫兹(每秒 3 次) 的频率运行,这得益于其高效且高容量的架构:
基于 FiLM 条件调制 的 EfficientNet
TokenLearner 模块
Transformer 序列模型
cpp
通俗解释
1. 这句话在说什么?
这是对 RT-1 模型功能 + 速度 + 架构 的一句话总结:
输入:相机图片 + 你说的自然语言指令(如 "把可乐拿起来")
输出:机器人可执行的离散动作(底盘怎么动、手臂怎么动、爪子怎么张合)
亮点:35M 参数量不算小,但能实时跑 3Hz,够机器人 real-time 控制
靠什么做到:三大组件高效配合
2. 关键词拆解
① takes images and natural language instructions
输入:视觉图像 + 自然语言指令
这是 ** 语言条件机器人策略(language-conditioned policy)** 最标准的输入
② outputs discretized base and arm actions
输出离散动作,而不是连续值
base actions:移动底盘的动作(前后左右、转向)
arm actions:机械臂动作(位置、角度、夹爪开合)
离散化好处:更容易拟合多模态、复杂的人类演示分布
③ Despite its size (35M parameters), it does this at 3 Hz
35M 参数:在 Transformer 里属于轻量级,但在机器人实时控制里不算小
3 Hz:每秒输出 3 次动作,满足真实机器人闭环控制的最低要求
④ efficient yet high-capacity architecture
efficient(高效):推理快、能实时跑
high-capacity(高容量):能学大量任务、泛化强
机器人模型最难的就是同时满足这两点
⑤ 三大核心架构(论文灵魂)
FiLM-conditioned EfficientNet
EfficientNet:轻量级图像特征提取主干
FiLM:把语言指令 "注入" 图像特征,让视觉特征关注指令相关的物体
→ 实现早期语言 - 视觉融合
TokenLearner
把图像特征从 81 个 token 压缩到 8 个
→ 大幅提速,降低计算量
Transformer
对时序图像 + 语言 token 做自注意力
输出最终离散动作
→ 强泛化、强序列建模能力1 引言(翻译)
端到端机器人学习(包括模仿学习与强化学习)通常需要为特定任务采集数据,分为单任务或多任务设置,数据与目标任务高度绑定。这套流程与其他领域(CV/NLP)传统监督学习一致:采集专属数据集、标注、部署,任务之间几乎没有关联。
近年来,视觉、NLP等领域发生了巨大转变:从孤立、小规模数据集与专用模型,转向在海量通用数据上预训练的大模型。这类模型成功的核心是:
- 开放式无任务约束训练
- 高容量架构,吸收大规模数据中的全部知识
如果模型能"吸收"经验,学习语言或感知中的通用模式,就能更高效地应用到具体任务。在机器人领域,这种无需大量任务专属数据的特性更加重要------机器人数据集往往需要高度工程化的自主运行或昂贵的人类演示。
因此我们提出两个核心问题:
- 能否在包含海量机器人任务的数据上,训练一个单一、强大的多任务基座模型?
- 这样的模型能否像其他领域一样,具备零样本泛化到新任务、新环境、新物体的能力?
在机器人领域构建这类模型非常困难。尽管已有不少多任务机器人策略提出,但普遍存在局限:
- 真实世界任务广度不足(如Gato)
- 专注训练任务而非泛化新任务
- 在新任务上性能偏低
两大核心挑战:
- 构建合适的数据集 :泛化需要规模+广度,覆盖多样任务与场景,且任务之间具备关联性,让模型发现结构相似性。
- 设计合适的模型 :多任务学习需要高容量模型,但机器人控制器必须实时运行,Transformer推理效率是巨大挑战。
本文提出RT-1架构:将高维输入(图像、指令)与输出(电机动作)编码为紧凑Token,让Transformer实现实时推理控制。
本文贡献
2大挑战 + 解决方案: 机器人通用大模型主要面临数据集构建 与模型设计 两大核心挑战:一方面需要兼具规模、广度与关联性的真实机器人数据才能支撑强泛化;另一方面多任务学习所需的高容量Transformer模型难以满足机器人实时控制的效率要求。为此,本文提出RT-1机器人Transformer架构,通过构建13万条真实演示、700+任务的大规模多样化数据集,并将图像、指令与动作编码为紧凑Token以实现高效推理,在保持高容量与强泛化的同时满足实时控制需求,显著超越现有方法。
- 提出RT-1模型,在大规模真实机器人任务数据集上验证效果。
- 实验证明:RT-1泛化与鲁棒性显著优于现有方法。
- 系统消融模型设计与数据集构成。
- 结果:RT-1在700+训练指令上成功率97% ,在新任务、干扰物、新背景上分别比最优基线高25%、36%、18%。
- 支持最长50步超长视野任务(SayCan框架)。
- 可吸收仿真数据、其他机器人数据,不损失原任务性能,同时提升泛化。
2 相关工作(翻译)
近期不少工作基于Transformer做机器人控制策略,将语言指令与Transformer结合,用于指定任务并泛化到新任务。
本文更进一步:将语言+视觉观测到机器人动作的映射建模为序列问题,用Transformer学习映射。灵感来自游戏AI、仿真机器人导航/移动/操作。
在真实世界Transformer操作方面,现有工作多聚焦高效学习,而Gato、Behavior Transformer等尝试在大规模数据上训练单一模型,但真实任务有限、泛化评估不足。
本文技术重点:如何把高容量、强泛化的Transformer策略,做到实时控制所需的计算效率。

3 预备知识(翻译)
机器人学习
目标:从视觉中学习语言条件下 的机器人策略。
形式化:时序决策环境。t=0时,策略接收语言指令i与初始图像x₀,输出动作分布π(·|i,x₀),采样动作a₀执行。循环至终止条件。
一个交互片段(episode):i, {(xⱼ,aⱼ)}ⱼ=0^T
奖励r∈{0,1}表示是否完成指令。
目标:最大化平均奖励。
Transformer
RT-1使用Transformer建模策略π。
Transformer是序列模型:输入序列{ξₕ} → 输出序列{yₖ},由自注意力层与全连接层组成。
本文流程:输入(i,{xⱼ})→序列{ξₕ};动作aₜ→序列{yₖ};再用Transformer学习映射。
模仿学习
使用行为克隆(Behavior Cloning),最小化给定图像与指令下动作的负对数似然。
数据集D为成功演示片段。
4 系统总览(翻译)
目标:构建能吸收大量数据、有效泛化的通用机器人学习系统。
硬件与环境
使用Everyday Robots移动操作臂:7自由度臂、二指夹爪、移动底座。
评估环境:3个厨房场景(2个真实办公厨房 + 1个仿真训练环境)。
训练数据
- 人类演示
- 每条片段标注文本指令
- 指令结构:动词 + 物体名词
- 总数据:13万条演示 ,700+ distinct任务指令
- 采集:13台机器人,历时17个月
RT-1核心架构(一句话)
输入:短序列图像 + 自然语言指令
输出:机器人实时动作(3Hz)
架构:
- FiLM-conditioned EfficientNet(图像+语言编码)
- TokenLearner(压缩Token)
- Transformer(输出离散动作Token)
动作空间:
- 手臂7维(x/y/z/滚/仰/偏/夹爪开合)
- 底座3维(x/y/偏航)
- 1维模式(臂/底座/终止)
5 RT-1:机器人Transformer(核心翻译)
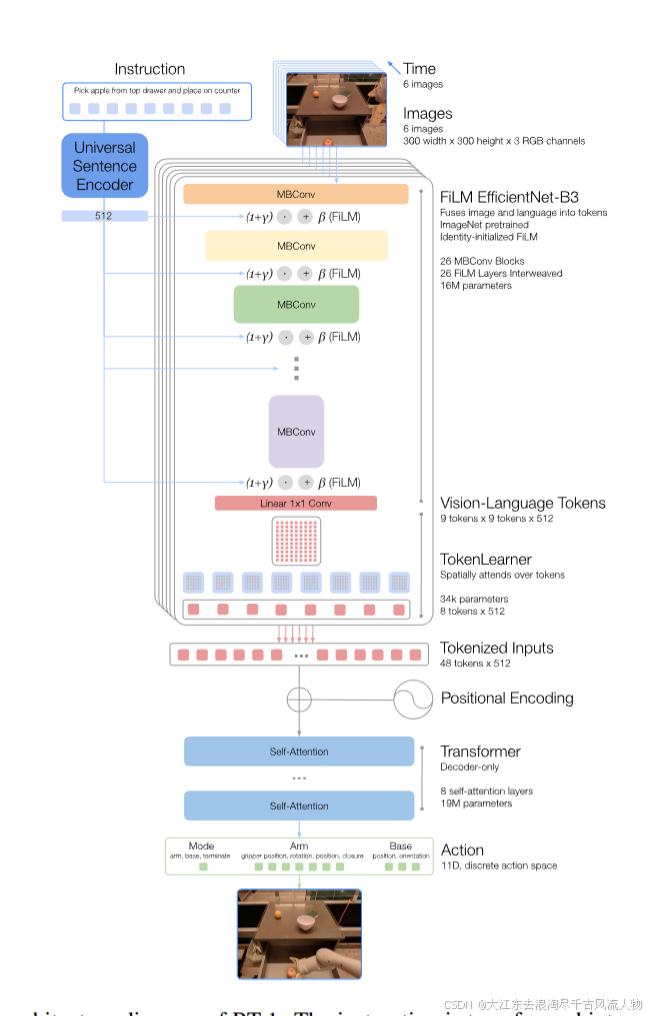
5.1 模型结构
(1)指令与图像Token化
- 输入6张300×300图像
- 经过ImageNet预训练EfficientNet-B3,输出9×9×512特征图
- 展平为81个视觉Token
- 语言指令用Universal Sentence Encoder编码
- 通过FiLM层 将语言信息注入EfficientNet,实现早期语言-视觉融合
FiLM初始化技巧:将仿射变换层初始化为0,保持预训练权重功能,避免破坏特征。
图像+指令Token模块总参数量:16M
(2)TokenLearner
将81个视觉Token压缩到8个Token ,大幅加速推理。
TokenLearner是元素级注意力模块,自适应选择重要信息。
(3)Transformer
- 8个Token/帧 × 6帧历史 = 48个Token
- 加入位置编码
- 解码器-only Transformer,8层自注意力
- 总参数量:19M
- 输出:离散动作Token
(4)动作Token化
每个动作维度离散化为256个bin,统一映射到范围内。
(5)损失函数
标准分类交叉熵 + 因果掩码。

(6)推理速度
机器人实时控制要求:≥3Hz ,推理<100ms。
RT-1推理耗时15ms ,满足要求。
提速关键:
- TokenLearner压缩Token(×2.4)
- 重叠窗口复用Token(×1.7)
5.2 数据集
- 总规模:~13万条机器人演示
- 13台机器人,17个月
- 任务:744条指令,覆盖拾取、放置、开关抽屉、直立放置、碰倒、抽纸、开罐子等
- 物体高度多样化
技能分类(核心表格):
| 技能 | 数量 | 描述 | 示例指令 |
|---|---|---|---|
| 拾取物体 | 130 | 举起物体 | pick iced tea can |
| 移动物体到附近 | 337 | 把A移到B旁 | move pepsi can near rxbar |
| 直立放置 | 8 | 长形物体直立 | place water bottle upright |
| 碰倒 | 8 | 碰倒长形物 | knock redbull can over |
| 开关抽屉 | 6 | 开关橱柜抽屉 | open the top drawer |
| 放入容器 | 84 | 把物体放进容器 | place chip bag into bowl |
| 从容器取出放台面 | 162 | 取出并放置 | pick from bowl and place |
| 长视野任务 | 9 | 真实复杂指令 | pull napkin、open jar |
6 实验(关键数据)
实验回答5大问题:
- RT-1能否执行大量指令,并零样本泛化新任务/物体/环境?
- 能否吸收仿真数据、其他机器人数据?
- 长视野任务表现如何?
- 数据量/多样性对泛化的影响?
- 模型设计的关键决策?
评估超过3000次真实世界试验。
6.1 实验设置
- 环境:训练教室 + Kitchen1 + Kitchen2
- 评估维度:
- 见过任务(Seen Tasks)
- 未见过任务(Unseen Tasks)
- 干扰物鲁棒性(Distractors)
- 背景鲁棒性(Backgrounds)
- 真实厨房长视野任务
6.2 泛化能力(核心结果)
对比基线:Gato、BC-Z、BC-Z XL(同数据训练)
| 模型 | 见过任务 | 未见过任务 | 干扰物 | 背景 |
|---|---|---|---|---|
| Gato | 65% | 52% | 43% | 35% |
| BC-Z | 72% | 19% | 47% | 41% |
| BC-Z XL | 56% | 43% | 23% | 35% |
| RT-1 | 97% | 76% | 83% | 59% |
结论:
- RT-1见过任务97%成功率
- 未见过任务76%,远超基线
- 干扰/背景鲁棒性分别提升36%/18%
真实厨房三级泛化(L1/L2/L3):
RT-1依旧大幅领先,L3达50%,Gato直接掉到0%。
6.3 吸收异构数据
(1)吸收仿真数据
加入仿真物体数据:
- 真实任务性能几乎不变(92%→90%)
- 仿真物体任务:23%→87%(+64%)
- 未见过指令:7%→33%(+26%)
证明RT-1具备强大跨域迁移能力。
(2)吸收其他机器人数据(Kuka + EDR)
- 原教室任务仅下降2%(92%→90%)
- 箱内拾取任务:22%→39%(接近翻倍)
证明RT-1可跨形态迁移,吸收其他机器人经验。
6.4 长视野任务(SayCan)
在Kitchen1/Kitchen2执行15条长指令,平均~10步。
| 模型 | Kitchen1执行 | Kitchen2执行 |
|---|---|---|
| SayCan+Gato | 33% | 0% |
| SayCan+BC-Z | 53% | 13% |
| SayCan+RT-1 | 67% | 67% |
关键 :Kitchen2是完全陌生环境,RT-1不下降,支持最长50步任务。
6.5 数据规模与多样性消融
核心结论:数据多样性 > 数据数量
- 减少25%任务(保留97%数据)→泛化大幅下降
- 减少50%数据(保留全部任务)→下降更小
7 结论、局限与未来工作(翻译)
结论
RT-1是面向规模化机器人学习的Transformer模型:
- 在13万条真实演示上训练
- 700+任务成功率97%
- 泛化、鲁棒性显著优于SOTA
- 可吸收仿真/跨机器人数据
- 支持超长视野任务(50步)
- 已开源:github.com/google-research/robotics_transformer
局限
- 基于模仿学习,无法超越演示者水平
- 泛化限于已有概念的新组合,无法全新运动
- 操作任务不够灵巧
未来方向
- 更快扩展技能,支持普通人数据采集
- 提升环境/背景鲁棒性
- 提升反应速度与记忆能力
- 规模化跨机器人数据融合
📌 博主总结(适合CSDN发布)
RT-1是实体机器人大模型 的开山之作,它第一次证明:
Transformer + 早期语言视觉融合 + 高效Token压缩 + 海量多样化真实数据
可以让单一模型在真实世界700+任务上接近完美执行,并零样本泛化新场景、新物体、新背景。
对于做机器人、具身智能、大模型落地的同学,RT-1提供了一套可直接复用的工程范式:
- 用EfficientNet+FiLM做轻量多模态编码
- 用TokenLearner压缩视觉序列
- 用Decoder-only Transformer做序列策略
- 离散动作空间更适合多模态模仿
- 数据多样性比数据量更关键
- 异构数据(仿真/其他机器人)可以直接"喂"给模型提升泛化
如果你在研究具身智能、机器人大模型、模仿学习、Transformer落地,这篇论文必须精读。