系列:本体论驱动的 AI 开发 · 第 02 篇 / 10
难度: ⭐⭐☆☆☆ 进阶入门
前置要求: 已读第 01 篇,理解"本体 = 概念 + 关系 + 规则"基本框架
环境准备:pip install rdflib owlrl
关键词: OWL、RDF、Class、ObjectProperty、DatatypeProperty、Individual、推理机、医院本体
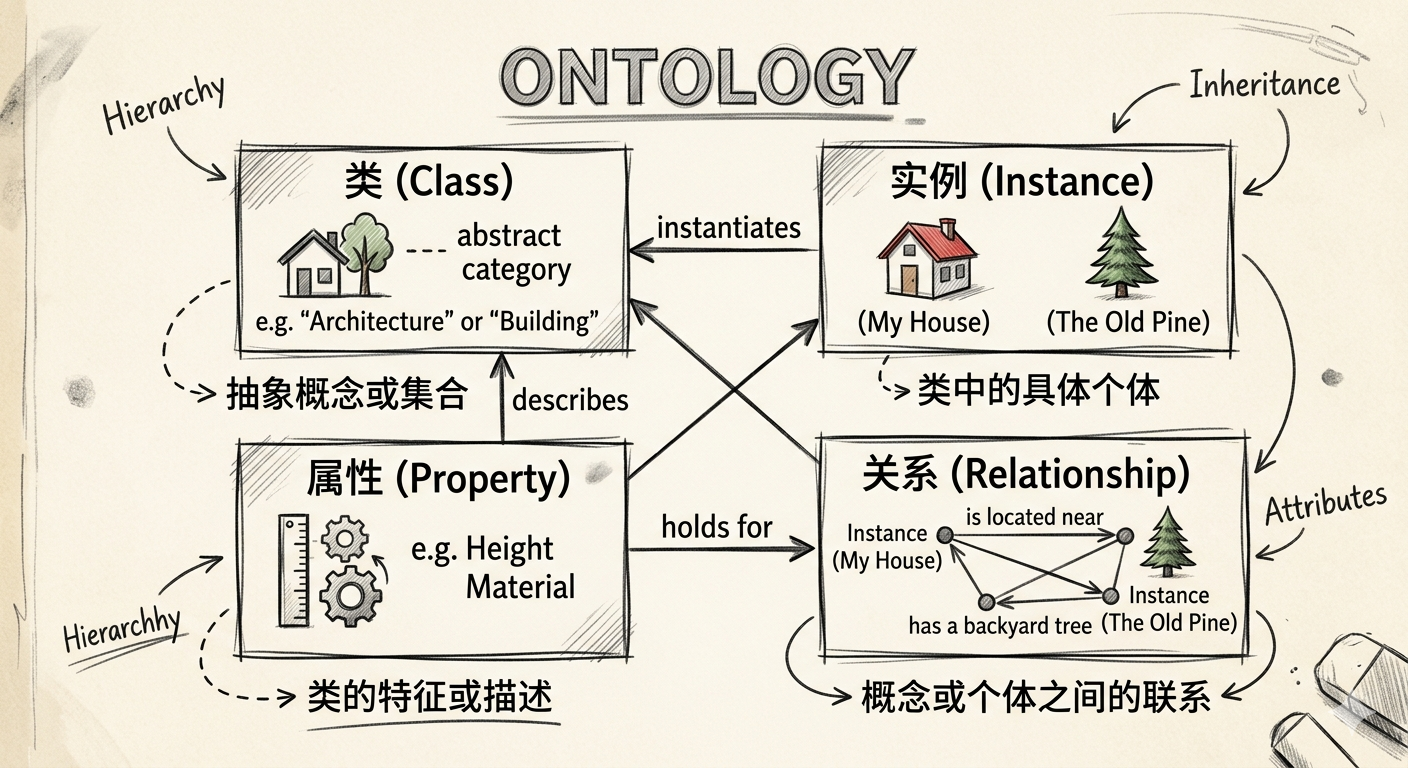
一、导语:医院系统为什么"各说各话"?
想象这样一个场景。
某三甲医院花了大力气上了三套核心系统------住院管理系统(HIS)、检验信息系统(LIS)、影像归档系统(PACS)。三套系统都存着"患者"相关的数据,但叫法各异:
| 系统 | "患者"字段 | "主治医生"字段 | 身份证号格式 |
|---|---|---|---|
| HIS | patient_id |
attending_doc |
字符串 |
| LIS | subject_no |
requesting_physician |
整数 |
| PACS | study_owner |
ref_physician |
带连字符字符串 |
这三套系统"各说各话"。一旦需要跨系统查询(比如"查询王医生本月所有住院患者的检验报告"),就要写一堆手工映射代码,脆弱、难维护、一改就崩。
解决方案:让三套系统共享一套本体。
本体定义了"患者"就是 HOS:Patient,"主治关系"就是 HOS:treatedBy,三套系统各自映射到这个共享语义层,跨系统查询变成标准语义查询,从此一劳永逸。
这就是本篇的主线任务:从零构建一个"医院核心本体"(Hospital Core Ontology),在这个过程中彻底吃透 OWL/RDF 的四大核心元素------类(Class)、属性(Property)、实例(Individual)、关系与公理(Relation & Axiom)。
本篇产出 :一个可运行的
hospital_ontology.py(约 70 行),配合 owlrl 推理库,能自动推断"王医生也是医院员工"等隐含事实,并实现跨系统属性传播。
1.1 先把 RDF / RDFS / OWL 的关系搞清楚
很多初学者在这里卡住:RDF、RDFS、OWL 到底什么关系?用编程语言类比最直观:
RDF ≈ 汇编语言 → 只有最基础的三元组:(主语, 谓语, 宾语)
RDFS ≈ C 语言 → 加入 Class、subClassOf、domain、range 等基础语义
OWL ≈ Python → 加入等价类、限制类、属性特性等丰富推理语义三者是叠加关系 ,不是替代关系。OWL 本体的底层存储格式就是 RDF 三元组,所以 rdflib 里写的每一行 g.add((s, p, o)) 本质上都是在操作 RDF 图,只不过用的谓词(owl:Class、owl:ObjectProperty 等)赋予了它 OWL 层面的语义。
二、第一块基石:类(Class)
2.1 类是什么
类(Class)是一组具有共同特征的个体的集合,是本体的骨架。它回答最基础的问题:在这个领域里,世界上有哪些种类的事物?
在医院领域,类的层次看起来像这样:
owl:Thing(所有事物的根类)
├── Person(人)
│ ├── Patient(患者)
│ │ ├── InPatient(住院患者)
│ │ └── OutPatient(门诊患者)
│ └── HospitalStaff(医院员工)
│ ├── Doctor(医生)
│ └── Nurse(护士)
├── Drug(药物)
│ ├── Antibiotic(抗生素)
│ └── Analgesic(镇痛药)
└── Diagnosis(诊断)子类自动继承父类的所有约束。一旦定义"Patient 必须有 hasAge 属性",InPatient 和 OutPatient 作为子类自动继承,不需要重复声明。这是本体相比数据库最直观的效率优势。
2.2 用 rdflib 定义类层次
python
# hospital_ontology.py --- Part 1:命名空间 & 类定义
from rdflib import Graph, Namespace, RDF, RDFS, OWL, XSD, Literal, BNode
from rdflib.collection import Collection
# ── 命名空间声明 ──────────────────────────────────────
g = Graph()
HOS = Namespace("http://hospital.org/ontology#")
LIS = Namespace("http://lis.hospital.org/data#")
g.bind("hos", HOS)
g.bind("lis", LIS)
# ── 类定义(紫色概念层)──────────────────────────────
g.add((HOS.Person, RDF.type, OWL.Class))
g.add((HOS.Person, RDFS.label, Literal("人", lang="zh")))
g.add((HOS.Patient, RDF.type, OWL.Class))
g.add((HOS.Patient, RDFS.subClassOf, HOS.Person)) # Patient is-a Person
g.add((HOS.Patient, RDFS.label, Literal("患者", lang="zh")))
g.add((HOS.InPatient, RDF.type, OWL.Class))
g.add((HOS.InPatient, RDFS.subClassOf, HOS.Patient)) # InPatient is-a Patient
g.add((HOS.InPatient, RDFS.label, Literal("住院患者", lang="zh")))
g.add((HOS.OutPatient, RDF.type, OWL.Class))
g.add((HOS.OutPatient, RDFS.subClassOf, HOS.Patient))
g.add((HOS.HospitalStaff, RDF.type, OWL.Class))
g.add((HOS.HospitalStaff, RDFS.subClassOf, HOS.Person))
g.add((HOS.HospitalStaff, RDFS.label, Literal("医院员工", lang="zh")))
# 关键层次:Doctor 和 Nurse 都是 HospitalStaff 的子类
# 后面推理机将利用这个层次自动推断
g.add((HOS.Doctor, RDF.type, OWL.Class))
g.add((HOS.Doctor, RDFS.subClassOf, HOS.HospitalStaff))
g.add((HOS.Nurse, RDF.type, OWL.Class))
g.add((HOS.Nurse, RDFS.subClassOf, HOS.HospitalStaff))
g.add((HOS.Drug, RDF.type, OWL.Class))
g.add((HOS.Diagnosis, RDF.type, OWL.Class))注意 RDFS.label 的使用------这是注解属性,给类加上人类可读的中文标签,不影响推理但对文档化极为重要(第 3.3 节会专门讲)。
2.3 开放世界假设(OWA)vs 封闭世界假设(CWA)------最容易踩的坑
这是 OWL 本体与关系数据库最根本的哲学差异,也是初学者最常犯错的地方,必须单独讲清楚。
关系数据库采用封闭世界假设(CWA):
数据库里没有的事实 = 假的。
查询"王医生有没有药物过敏记录",数据库返回空 = 王医生没有过敏。这在业务系统里是合理的------系统管理的数据范围是确定的。
OWL 本体采用开放世界假设(OWA):
本体里没有的事实 ≠ 假,只是未知。
同样的查询,本体推理机的态度是:"我没有见过王医生过敏的记录,但这不代表他没有------可能只是尚未录入。"
为什么 AI 场景需要 OWA?
现实世界的知识永远是不完整的。医学文献在持续更新,某种药物相互作用今天未发现不代表它不存在。如果用 CWA,推理机会错误地断言"布洛芬和阿司匹林不冲突"(因为今天的本体里没有这条冲突记录),这在医疗场景里是危险的。
OWA 让推理机保持谦逊:不知道 ≠ 不存在,这正是 AI 应有的认知态度。
2.4 三种类间约束:等价、互斥、覆盖
这三种约束是推理机能"推断新知识"的关键武器:
① 等价类(owl:equivalentClass)
"住院患者" ≡ "有住院记录的人"。一旦系统发现张三有住院记录,推理机自动把他归入 InPatient 类,无需手动声明。
② 互斥类(owl:disjointWith)
"医生 ∩ 患者 = ∅":在本系统的业务规则下,同一个人不能同时既是医生又是患者。如果有人被同时声明为 Doctor 和 Patient,推理机会报出矛盾,帮你发现数据错误------这相当于本体层面的数据验证。
③ 覆盖约束(owl:unionOf)
"医院员工 = 医生 ∪ 护士"。这是后面推理演示的关键:王医生被声明为 Doctor,Doctor 是 HospitalStaff 的子类,推理机会自动把他归为 HospitalStaff------这条事实从未被显式声明,却被自动推导出来。
python
# 互斥约束:Doctor 和 Patient 不能同时成立
g.add((HOS.Doctor, OWL.disjointWith, HOS.Patient))三、第二块基石:属性(Property)
如果说类是本体的"名词",属性就是"动词"和"形容词"------它描述事物有什么 以及事物之间的关系。OWL 有三种属性,各司其职:
| 属性类型 | OWL 关键词 | 连接对象 | 医院案例 |
|---|---|---|---|
| 对象属性 | owl:ObjectProperty |
个体 → 个体 | treatedBy: Patient → Doctor |
| 数据属性 | owl:DatatypeProperty |
个体 → 数值 | hasAge: Patient → 36 |
| 注解属性 | owl:AnnotationProperty |
任意 → 字符串 | rdfs:label: Doctor → "医生" |
3.1 对象属性(ObjectProperty):个体与个体的语义连接
对象属性不只是一条连线,还能附加各种属性特性(Property Characteristics) ,让推理机产生额外的推断。以 treatedBy(患者被谁主治)为例:
python
# hospital_ontology.py --- Part 2:属性定义
# ── 对象属性:treatedBy(橙色关系层)────────────────────
g.add((HOS.treatedBy, RDF.type, OWL.ObjectProperty))
g.add((HOS.treatedBy, RDFS.label, Literal("被主治", lang="zh")))
g.add((HOS.treatedBy, RDFS.domain, HOS.Patient)) # 主语必须是 Patient
g.add((HOS.treatedBy, RDFS.range, HOS.Doctor)) # 宾语必须是 Doctor
g.add((HOS.treatedBy, RDF.type, OWL.AsymmetricProperty)) # 不对称
g.add((HOS.treatedBy, RDFS.comment, Literal(
"患者被某位医生主治的关系。不对称属性:患者不能反过来主治医生。",
lang="zh")))
# 逆属性:treats(医生主治患者)通过 inverseOf 自动推导
g.add((HOS.treats, RDF.type, OWL.ObjectProperty))
g.add((HOS.treats, OWL.inverseOf, HOS.treatedBy))
# 有了这一行,推理机会自动推断:
# 张三 treatedBy 王医生 → 王医生 treats 张三
# ── 对象属性:prescribes(医生开药)──────────────────────
g.add((HOS.prescribes, RDF.type, OWL.ObjectProperty))
g.add((HOS.prescribes, RDFS.domain, HOS.Doctor))
g.add((HOS.prescribes, RDFS.range, HOS.Drug))
# ── 对象属性:hasDiagnosis(患者有诊断结论)──────────────
g.add((HOS.hasDiagnosis, RDF.type, OWL.ObjectProperty))
g.add((HOS.hasDiagnosis, RDFS.domain, HOS.Patient))
g.add((HOS.hasDiagnosis, RDFS.range, HOS.Diagnosis))六种属性特性速查,用医院场景直觉理解:
| 特性 | OWL 关键词 | 语义 | 医院案例 |
|---|---|---|---|
| 函数性 | FunctionalProperty |
每个主语最多一个宾语 | 每位患者只有一位主责医生 |
| 逆函数性 | InverseFunctionalProperty |
每个宾语最多一个主语 | 患者 ID 反向唯一标识患者 |
| 对称性 | SymmetricProperty |
A→B 则 B→A | isColleagueOf(同事关系) |
| 不对称性 | AsymmetricProperty |
A→B 则 B→A 不成立 | treatedBy(患者不能主治医生) |
| 传递性 | TransitiveProperty |
A→B, B→C 则 A→C | isSupervisorOf(上级关系) |
| 自反性 | ReflexiveProperty |
每个个体与自身相关 | isSameAgeGroupAs |
inverseOf 是最常用的特性之一:声明了 treatedBy,推理机就能自动处理 treats 的反向查询,不需要手动维护两个方向的数据。
3.2 数据属性(DatatypeProperty):个体与具体数值的连接
数据属性连接个体与 XSD 具体值------年龄、日期、名字、体重......
python
# ── 数据属性(蓝色数值层)────────────────────────────────
g.add((HOS.hasName, RDF.type, OWL.DatatypeProperty))
g.add((HOS.hasName, RDFS.range, XSD.string))
g.add((HOS.hasAge, RDF.type, OWL.DatatypeProperty))
g.add((HOS.hasAge, RDFS.domain, HOS.Person))
g.add((HOS.hasAge, RDFS.range, XSD.integer))
g.add((HOS.hasAge, RDF.type, OWL.FunctionalProperty)) # 每人只有一个年龄
g.add((HOS.hasDOB, RDF.type, OWL.DatatypeProperty))
g.add((HOS.hasDOB, RDFS.range, XSD.date)) # 日期类型
g.add((HOS.hasWeight, RDF.type, OWL.DatatypeProperty))
g.add((HOS.hasWeight, RDFS.range, XSD.decimal)) # 体重可能是 62.5kg
g.add((HOS.hasPatientID, RDF.type, OWL.DatatypeProperty))
g.add((HOS.hasPatientID, RDFS.range, XSD.string))
g.add((HOS.hasPatientID, RDF.type, OWL.FunctionalProperty)) # 患者 ID 唯一一个工程判断题:血型应该是 DataProperty 还是独立的 Class?
这是实际建模中最常见的两难问题。判断标准只有一条:
如果这个值需要附加自己的属性,或者需要参与复杂推理,就建类;否则用 DatatypeProperty。
- 血型只是一个标签(A/B/O/AB)→ 用
DatatypeProperty,hasBloodType: Patient → xsd:string - 血型需要参与推理(B 型患者不能接受 A 型血的输血)→ 建
BloodType类,BloodType_A owl:disjointWith BloodType_B,推理机能自动检测输血冲突
在医疗本体里,血型应该建类------因为它需要参与安全推理规则。
3.3 注解属性(AnnotationProperty):给本体"写注释"
注解属性不参与推理,但对工程实践极其重要。常用的内置注解属性:
python
# 注解属性示例(直接使用 RDFS/OWL 内置谓词,无需额外定义)
# rdfs:label → 人类可读的名称(支持多语言)
g.add((HOS.treatedBy, RDFS.label, Literal("被主治", lang="zh")))
g.add((HOS.treatedBy, RDFS.label, Literal("is treated by", lang="en")))
# rdfs:comment → 详细说明
g.add((HOS.treatedBy, RDFS.comment, Literal(
"表示患者被某位医生主治的关系。"
"该属性为不对称属性(AsymmetricProperty):患者不能主治医生。"
"一位患者可有多位主治医生,但建议不超过 3 位(业务规则)。",
lang="zh"
)))
# owl:versionInfo → 版本信息
g.add((HOS.treatedBy, OWL.versionInfo, Literal("v1.0 · 2025-01")))好的本体和糟糕的本体,差别往往不在技术层面,而在注解的质量。两年后接手这个本体的工程师(很可能就是你自己),会感谢现在认真写注解的你。
四、第三块基石:实例(Individual)
类是模板,实例是按模板创建的具体对象。类定义了"患者是什么样的",实例就是那位叫张三的、36 岁的、住在 301 床的具体患者。
4.1 声明实例并赋予属性值
python
# hospital_ontology.py --- Part 3:实例声明(绿色数据层)
# ── 患者实例:张三 ────────────────────────────────────────
g.add((HOS.Patient_001, RDF.type, OWL.NamedIndividual))
g.add((HOS.Patient_001, RDF.type, HOS.InPatient)) # 住院患者
# InPatient is-a Patient is-a Person → 推理机会自动推断后两个类型
g.add((HOS.Patient_001, HOS.hasName, Literal("张三", lang="zh")))
g.add((HOS.Patient_001, HOS.hasAge, Literal(36, datatype=XSD.integer)))
g.add((HOS.Patient_001, HOS.hasPatientID, Literal("P20240101")))
g.add((HOS.Patient_001, HOS.hasDOB, Literal("1988-03-15", datatype=XSD.date)))
# ── 医生实例:王大夫 ──────────────────────────────────────
g.add((HOS.Dr_Wang, RDF.type, OWL.NamedIndividual))
g.add((HOS.Dr_Wang, RDF.type, HOS.Doctor))
# 注意:没有显式声明 HospitalStaff / Person
# 推理机将从"Doctor subClassOf HospitalStaff subClassOf Person"自动推断
g.add((HOS.Dr_Wang, HOS.hasName, Literal("王大夫", lang="zh")))
g.add((HOS.Dr_Wang, HOS.hasAge, Literal(44, datatype=XSD.integer)))
# ── 护士实例:李护士 ──────────────────────────────────────
g.add((HOS.Nurse_Li, RDF.type, OWL.NamedIndividual))
g.add((HOS.Nurse_Li, RDF.type, HOS.Nurse))
g.add((HOS.Nurse_Li, HOS.hasName, Literal("李护士", lang="zh")))
# ── 药物实例:布洛芬 ──────────────────────────────────────
g.add((HOS.Drug_IBU, RDF.type, OWL.NamedIndividual))
g.add((HOS.Drug_IBU, RDF.type, HOS.Drug))
g.add((HOS.Drug_IBU, RDFS.label, Literal("布洛芬 Ibuprofen")))
# ── 关系断言 ──────────────────────────────────────────────
g.add((HOS.Patient_001, HOS.treatedBy, HOS.Dr_Wang)) # 张三被王大夫主治
g.add((HOS.Dr_Wang, HOS.prescribes, HOS.Drug_IBU)) # 王大夫开了布洛芬4.2 同一性声明:owl:sameAs 跨系统数据融合
现实工程中最头疼的问题:HIS 系统的 Patient_001 和 LIS 系统的 subject_007 是同一个人,本体怎么处理?
python
# 跨系统同一性声明
g.add((LIS.subject_007, RDF.type, OWL.NamedIndividual))
g.add((LIS.subject_007, RDF.type, HOS.Patient))
# 核心:声明语义等价,两个 URI 指向同一个真实个体
g.add((HOS.Patient_001, OWL.sameAs, LIS.subject_007))
# 效果:关于 Patient_001 的所有属性(年龄、诊断、主治医生)
# 都会自动传播到 subject_007,无需任何 ETL 脚本!
# 批量声明医生们互不相同,避免推理歧义
diff_node = BNode()
diff_list = BNode()
Collection(g, diff_list, [HOS.Dr_Wang, HOS.Dr_Li, HOS.Dr_Zhang])
g.add((diff_node, RDF.type, OWL.AllDifferent))
g.add((diff_node, OWL.distinctMembers, diff_list))owl:sameAs 就是跨系统数据集成的语义"桥梁"。它比数据库 JOIN 更强大------JOIN 靠 ID 匹配,sameAs 是语义等价,会触发推理机在两个 URI 之间双向传播所有已知属性。
五、第四块基石:关系与公理(Relation & Axiom)
属性描述了连接,公理赋予这种连接语义约束 和推理规则。两者的组合,才是本体真正超越数据库的地方。
5.1 限制类(Restriction Class):用关系定义类的成员资格
这是 OWL 最强大、也最难理解的特性:用属性限制来自动定义谁属于这个类,无需手动维护成员列表。
python
# 定义"主治住院患者的医生"这个限制类
# 语义:"所有 treats 关系的主体中,至少有一个值是 InPatient 的"
restriction = BNode()
g.add((restriction, RDF.type, OWL.Restriction))
g.add((restriction, OWL.onProperty, HOS.treats))
g.add((restriction, OWL.someValuesFrom, HOS.InPatient))
# ↑ someValuesFrom = "存在限制":至少有一个 treats 的目标是 InPatient
# AttendingDoctor = Doctor AND 满足上述限制
attending_def = BNode()
members_bnode = BNode()
Collection(g, members_bnode, [HOS.Doctor, restriction])
g.add((attending_def, RDF.type, OWL.Class))
g.add((attending_def, OWL.intersectionOf, members_bnode))
g.add((HOS.AttendingDoctor, OWL.equivalentClass, attending_def))someValuesFrom vs allValuesFrom 是最容易混淆的点:
owl:someValuesFrom(存在限制):
"treats someValuesFrom InPatient"
→ 该医生至少治疗过一位住院患者
→ 允许他同时也治疗门诊患者(OutPatient)
owl:allValuesFrom(全称限制):
"treats allValuesFrom InPatient"
→ 该医生治疗的所有患者都必须是住院患者
→ 如果他治疗了一位门诊患者,推理机报矛盾!类比理解:someValuesFrom 是"至少有一个",allValuesFrom 是"所有都必须是"。选错了会导致推理机把大量正常数据判定为矛盾------这是生产环境中最常见的本体建模 bug 之一。
六、实战:完整代码 + 推理演示
把前五节所有内容整合为一个完整可运行的文件,然后启动推理机,看它能自动推断出什么。
6.1 完整代码:hospital_ontology.py
python
# ============================================================
# hospital_ontology.py
# 医院核心本体 · 完整版
# 运行前:pip install rdflib owlrl
# ============================================================
from rdflib import Graph, Namespace, RDF, RDFS, OWL, XSD, Literal, BNode
from rdflib.collection import Collection
# ═══ ① 命名空间 ═════════════════════════════════════════════
g = Graph()
HOS = Namespace("http://hospital.org/ontology#")
LIS = Namespace("http://lis.hospital.org/data#")
g.bind("hos", HOS)
g.bind("lis", LIS)
# ═══ ② 类定义 ═══════════════════════════════════════════════
g.add((HOS.Person, RDF.type, OWL.Class))
g.add((HOS.Person, RDFS.label, Literal("人", lang="zh")))
g.add((HOS.Patient, RDF.type, OWL.Class))
g.add((HOS.Patient, RDFS.subClassOf, HOS.Person))
g.add((HOS.Patient, RDFS.label, Literal("患者", lang="zh")))
g.add((HOS.InPatient, RDF.type, OWL.Class))
g.add((HOS.InPatient, RDFS.subClassOf, HOS.Patient))
g.add((HOS.InPatient, RDFS.label, Literal("住院患者", lang="zh")))
g.add((HOS.OutPatient, RDF.type, OWL.Class))
g.add((HOS.OutPatient, RDFS.subClassOf, HOS.Patient))
g.add((HOS.HospitalStaff, RDF.type, OWL.Class))
g.add((HOS.HospitalStaff, RDFS.subClassOf, HOS.Person))
g.add((HOS.HospitalStaff, RDFS.label, Literal("医院员工", lang="zh")))
g.add((HOS.Doctor, RDF.type, OWL.Class))
g.add((HOS.Doctor, RDFS.subClassOf, HOS.HospitalStaff)) # ← 推理关键
g.add((HOS.Nurse, RDF.type, OWL.Class))
g.add((HOS.Nurse, RDFS.subClassOf, HOS.HospitalStaff)) # ← 推理关键
g.add((HOS.Drug, RDF.type, OWL.Class))
g.add((HOS.Diagnosis, RDF.type, OWL.Class))
# 互斥约束
g.add((HOS.Doctor, OWL.disjointWith, HOS.Patient))
# ═══ ③ 属性定义 ═════════════════════════════════════════════
# 对象属性
g.add((HOS.treatedBy, RDF.type, OWL.ObjectProperty))
g.add((HOS.treatedBy, RDFS.domain, HOS.Patient))
g.add((HOS.treatedBy, RDFS.range, HOS.Doctor))
g.add((HOS.treatedBy, RDF.type, OWL.AsymmetricProperty))
g.add((HOS.treatedBy, RDFS.label, Literal("被主治", lang="zh")))
g.add((HOS.treats, RDF.type, OWL.ObjectProperty))
g.add((HOS.treats, OWL.inverseOf, HOS.treatedBy)) # 自动双向推导
g.add((HOS.prescribes, RDF.type, OWL.ObjectProperty))
g.add((HOS.prescribes, RDFS.domain, HOS.Doctor))
g.add((HOS.prescribes, RDFS.range, HOS.Drug))
g.add((HOS.hasDiagnosis, RDF.type, OWL.ObjectProperty))
g.add((HOS.hasDiagnosis, RDFS.domain, HOS.Patient))
g.add((HOS.hasDiagnosis, RDFS.range, HOS.Diagnosis))
# 数据属性
g.add((HOS.hasName, RDF.type, OWL.DatatypeProperty))
g.add((HOS.hasName, RDFS.range, XSD.string))
g.add((HOS.hasAge, RDF.type, OWL.DatatypeProperty))
g.add((HOS.hasAge, RDFS.domain, HOS.Person))
g.add((HOS.hasAge, RDFS.range, XSD.integer))
g.add((HOS.hasAge, RDF.type, OWL.FunctionalProperty))
g.add((HOS.hasPatientID, RDF.type, OWL.DatatypeProperty))
g.add((HOS.hasPatientID, RDFS.range, XSD.string))
g.add((HOS.hasPatientID, RDF.type, OWL.FunctionalProperty))
g.add((HOS.hasDOB, RDF.type, OWL.DatatypeProperty))
g.add((HOS.hasDOB, RDFS.range, XSD.date))
# ═══ ④ 实例声明 ═════════════════════════════════════════════
# 患者:张三
g.add((HOS.Patient_001, RDF.type, OWL.NamedIndividual))
g.add((HOS.Patient_001, RDF.type, HOS.InPatient))
g.add((HOS.Patient_001, HOS.hasName, Literal("张三", lang="zh")))
g.add((HOS.Patient_001, HOS.hasAge, Literal(36, datatype=XSD.integer)))
g.add((HOS.Patient_001, HOS.hasPatientID,Literal("P20240101")))
g.add((HOS.Patient_001, HOS.hasDOB, Literal("1988-03-15", datatype=XSD.date)))
# 医生:王大夫(未声明 HospitalStaff / Person,留给推理机)
g.add((HOS.Dr_Wang, RDF.type, OWL.NamedIndividual))
g.add((HOS.Dr_Wang, RDF.type, HOS.Doctor))
g.add((HOS.Dr_Wang, HOS.hasName, Literal("王大夫", lang="zh")))
g.add((HOS.Dr_Wang, HOS.hasAge, Literal(44, datatype=XSD.integer)))
# 护士:李护士
g.add((HOS.Nurse_Li, RDF.type, OWL.NamedIndividual))
g.add((HOS.Nurse_Li, RDF.type, HOS.Nurse))
g.add((HOS.Nurse_Li, HOS.hasName, Literal("李护士", lang="zh")))
# 药物:布洛芬
g.add((HOS.Drug_IBU, RDF.type, OWL.NamedIndividual))
g.add((HOS.Drug_IBU, RDF.type, HOS.Drug))
g.add((HOS.Drug_IBU, RDFS.label, Literal("布洛芬 Ibuprofen")))
# 关系断言
g.add((HOS.Patient_001, HOS.treatedBy, HOS.Dr_Wang))
g.add((HOS.Dr_Wang, HOS.prescribes, HOS.Drug_IBU))
# 跨系统同一性:LIS 的 subject_007 = 张三
g.add((LIS.subject_007, RDF.type, OWL.NamedIndividual))
g.add((LIS.subject_007, RDF.type, HOS.Patient))
g.add((HOS.Patient_001, OWL.sameAs, LIS.subject_007))
# ═══ ⑤ 序列化导出 ═══════════════════════════════════════════
before_count = len(g)
g.serialize("hospital.ttl", format="turtle")
print(f"本体已导出 hospital.ttl | 推理前三元组数:{before_count}")6.2 推理演示:38 条 → 112 条,推理机干了什么?
python
# reasoning_demo.py --- 在上面代码末尾追加,或单独运行
import owlrl
print(f"\n{'─'*52}")
print(f" 推理前:图中共有 {len(g)} 条三元组")
print(f"{'─'*52}")
# 启动 OWL-RL 推理机(RDFS + OWL 规则子集,适合本地运行)
owlrl.DeductiveClosure(owlrl.OWLRL_Semantics).expand(g)
print(f" 推理后:图中共有 {len(g)} 条三元组")
print(f" 新增隐含事实:{len(g) - before_count} 条")
print(f"{'─'*52}\n")
# ── 验证 1:王大夫的类型是否被自动扩展?──────────────────
print("【验证 1】Dr_Wang 的所有 rdf:type(推理后):")
for _, _, cls in g.triples((HOS.Dr_Wang, RDF.type, None)):
label = str(cls).split("#")[-1]
if label not in ("", "NamedIndividual"):
print(f" Dr_Wang is-a {label}")
# ── 验证 2:inverseOf 是否推导出 treats?────────────────
print("\n【验证 2】王大夫主治了谁?(inverseOf 自动推断):")
for _, _, patient in g.triples((HOS.Dr_Wang, HOS.treats, None)):
print(f" Dr_Wang treats {str(patient).split('#')[-1]}")
# ── 验证 3:sameAs 是否传播了张三的属性?────────────────
print("\n【验证 3】LIS subject_007 的年龄(sameAs 属性传播):")
for _, _, age in g.triples((LIS.subject_007, HOS.hasAge, None)):
print(f" subject_007 hasAge {age} ← 从 Patient_001 自动传播!")
# ── 验证 4:李护士是否被推断为 HospitalStaff?──────────
print("\n【验证 4】Nurse_Li 的类型(Nurse subClassOf HospitalStaff):")
for _, _, cls in g.triples((HOS.Nurse_Li, RDF.type, None)):
label = str(cls).split("#")[-1]
if label not in ("", "NamedIndividual"):
print(f" Nurse_Li is-a {label}")预期输出:
────────────────────────────────────────────────────
推理前:图中共有 38 条三元组
────────────────────────────────────────────────────
推理后:图中共有 112 条三元组
新增隐含事实:74 条
────────────────────────────────────────────────────
【验证 1】Dr_Wang 的所有 rdf:type(推理后):
Dr_Wang is-a Doctor ← 显式声明
Dr_Wang is-a HospitalStaff ← 推理机推断!
Dr_Wang is-a Person ← 推理机推断!
【验证 2】王大夫主治了谁?(inverseOf 自动推断):
Dr_Wang treats Patient_001 ← 推理机推断!(inverseOf treatedBy)
【验证 3】LIS subject_007 的年龄(sameAs 属性传播):
subject_007 hasAge 36 ← 从 Patient_001 自动传播!
【验证 4】Nurse_Li 的类型(Nurse subClassOf HospitalStaff):
Nurse_Li is-a Nurse ← 显式声明
Nurse_Li is-a HospitalStaff ← 推理机推断!
Nurse_Li is-a Person ← 推理机推断!38 条 → 112 条 ,推理机新增了 74 条我们从未手写的事实。这就是本体的核心价值------知识的杠杆效应:输入少量精确的结构化知识,输出成倍的隐含知识。
七、总结:四大元素速查表
| 元素 | OWL 关键词 | 医院案例 | 最常见错误 | 推理作用 |
|---|---|---|---|---|
| 类 Class | owl:Class rdfs:subClassOf |
Patient Doctor InPatient |
忘记声明 subClassOf,类变成孤岛 |
类层次传递:InPatient → Patient → Person |
| 对象属性 | owl:ObjectProperty domain/range |
treatedBy: Patient→Doctor |
domain/range 搞反 | inverseOf 双向推断,属性特性规则 |
| 数据属性 | owl:DatatypeProperty XSD 类型 |
hasAge: Patient→36 |
用错 XSD 类型(字符串当整数) | FunctionalProperty 唯一性约束 |
| 实例 Individual | owl:NamedIndividual rdf:type |
Patient_001(张三) |
忘记声明 rdf:type,实例游离在类外 |
sameAs 跨系统属性双向传播 |
| 公理 Axiom | owl:disjointWith someValuesFrom |
医生 ∩ 患者 = ∅ | someValuesFrom 与 allValuesFrom 混淆 |
矛盾检测、限制类成员自动归类 |
八、三个思考题 + 动手挑战
Q1 :owl:someValuesFrom 和 owl:allValuesFrom 的根本区别是什么?如果在医疗本体中把 treatedBy allValuesFrom Doctor 误写成了 someValuesFrom,会产生什么推理错误?
Q2 :如果"血型"需要参与输血相容性推理(B 型患者不能接受 A 型血),你会把它设计为 DatatypeProperty 还是独立的 Class?请具体描述你的设计方案。
Q3(动手挑战) :在 hospital_ontology.py 的基础上:
- 为
Nurse_Li添加assignedPatient属性(Patient → Nurse 方向,需先定义该属性) - 为
Dr_Li、Dr_Zhang添加两个新的医生实例 - 用
owl:AllDifferent声明三位医生互不相同 - 运行推理机,验证三位医生都被自动归为
HospitalStaff
欢迎把代码或 GitHub Gist 链接发在评论区,我会逐一回复!
下篇预告
第 03 篇:用 Protégé 动手构建你的第一个本体
抛开代码,用图形化工具 Protégé 5.x 打开本篇生成的
hospital.ttl,在可视化界面里管理类层次、编辑属性,并启动内置推理机 HermiT 做完整的 OWL-DL 推理演示。
前置准备 :从 protege.stanford.edu 免费下载 Protégé 5.6.x
如果这篇文章对你有帮助,欢迎 ⭐ 点赞收藏!评论区的思考题答案和动手挑战成果我都会认真回复。
参考资料
- W3C OWL Working Group. (2012). OWL 2 Web Ontology Language Primer. W3C Recommendation.
- Horridge, M. (2011). A Practical Guide to Building OWL Ontologies Using Protégé 4. University of Manchester.
- rdflib Documentation. https://rdflib.readthedocs.io/
- owlrl Library. https://owl-rl.readthedocs.io/
- Noy, N. F., & McGuinness, D. L. (2001). Ontology Development 101. Stanford KSL.