项目文件夹:llms
技术路线
1 LangChain
LangChain开发入门教程::llms/langchain_tutorial
- Model I/O(prompts、llms、chat model、output parsers) :专栏
- RAG/Retrieval(文档加载器、文本分割器、Embedding、向量数据库、检索) :专栏
- Tools/Agents(工具、function call、agent) :专栏
2 LLM训练
LLM训练:llms/train
- 尝试基于小模型复现DeepSeek-R1的思维链以及白话文介绍如何从零训练一个LLM :专栏
学习笔记
1.1 Model I/O(prompts、llms、chat model、output parsers)
Model IO:格式化和管理LLM的输入和输出。
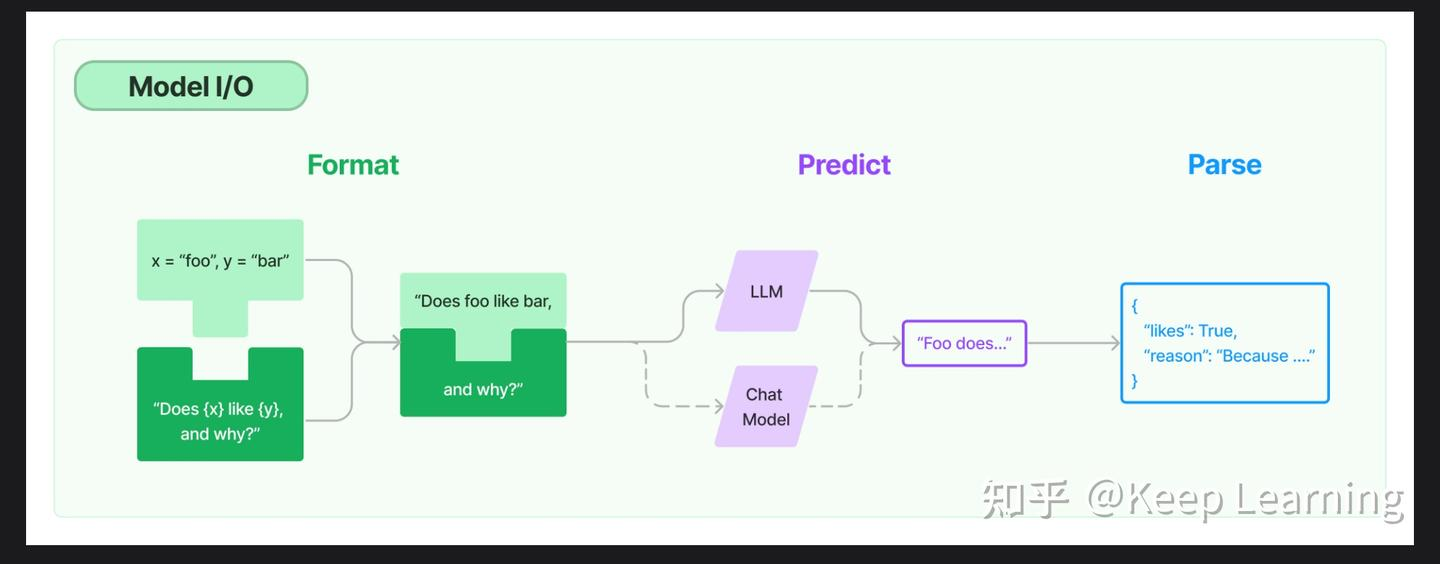
LLM 与 Chat Model
虚实线含义
-
LLM:实线箭头 ------ 代表基础、原生的流程
- 它是 LangChain 中 最基础、最核心的文本生成接口
- 输入是纯文本字符串,输出也是纯文本字符串
- 它是整个 Model I/O 流程的原始实现,所以用实线表示"主路径"
-
Chat Model:虚线箭头 ------ 代表在基础之上,衍生出的、同一目标的另一条路径
- 它是基于 LLM 封装的对话式接口,本质上还是在调用底层的 LLM 能力
- 输入是结构化的消息列表(如
HumanMessage/SystemMessage),输出是AIMessage对象 - 这里虚线的含义是:它不是一条独立的"新流程",而是对 LLM 主流程的一种"适配/封装",走的还是同一套 Predict 逻辑,只是包装了一层对话格式
-
它们不是同一个类,但共享同一个底层能力
LLM:LangChain 定义的「基础文本生成模型」接口,处理纯文本ChatModel:LangChain 定义的「对话模型」接口,处理结构化对话消息,底层依然依赖 LLM 生成文本
-
"一实一虚"的方式,就是想表达:它们是同一 Predict 环节的两种不同入口,LLM 是原生形态,Chat Model 是对话场景下的封装形态。
-
帮助理解:
- 实线的
LLM是"通用接口",不管是对话、续写、翻译都能用 - 虚线的
Chat Model是"对话专用接口",专门为多轮对话、角色设定优化,底层还是调用 LLM 的能力
- 实线的
总结
在 LangChain 的 Model I/O 模块中,LLM 与 Chat Model 并非两个完全独立的实体,而是同一底层能力的两种不同接口形态。
图中用实线标注的 LLM,是 LangChain 定义的「基础文本生成模型」接口,代表整个流程的原生主路径,负责最通用的文本生成任务,输入和输出均为纯字符串。
而用虚线标注的 Chat Model,则是基于 LLM 封装的「对话模型」接口,专门为多轮对话场景优化。它通过 HumanMessage、SystemMessage 等结构化消息对象来处理对话上下文,底层依然依赖 LLM 的文本生成能力。
这种 "一实一虚" 的设计,清晰地体现了 LangChain「接口分层、能力复用」的思想:LLM 是能力的基石,Chat Model 是面向对话场景的便捷封装。
Prompt
图中的 Prompt 其实隐藏在 Format(格式化)环节中。
注意看图,左侧的 x = "foo", y = "bar" 是业务变量,中间的绿色框 "Does {x} like {y}..." 是提示词模板(Prompt Template)。
经过模板渲染后,生成的最终字符串 "Does foo like bar, and why?",就是实际发送给大模型的 Prompt。
这张图省略了 "Prompt" 这个文字标签,而是用 "变量填充" 的具象化流程,直观地展示了 Model I/O 中,如何将原始数据转化为模型指令的核心过程。
MessagePromptTemplate 并不是 LangChain 中真实存在的一个类,而是对三类(System, AI, Human)对话消息模板的统称与抽象描述。
相关依赖、方法、数据结构可见 https://www.yuque.com/abigale-nhusl/kwiiq3/zot6tmrh3vh6ntmk
组件输入与输出
| Component | Input Type | Input Type 详解 | Output Type | Output Type 详解 | 示例场景 |
|---|---|---|---|---|---|
| Prompt | Dictionary | 接收一个 Python 字典,里面是模板需要的变量键值对,例如 {"name": "小明", "topic": "LangChain"}。 |
PromptValue | LangChain 的通用提示词对象,是模型输入的标准格式,既可以被解析为纯字符串,也可以被解析为对话消息列表。 | 用 PromptTemplate 生成提示词:prompt.format_prompt(name="小明", topic="LangChain"),输出一个 PromptValue 对象。 |
| ChatModel | Single string, list of chat messages or a PromptValue | 输入非常灵活,支持: 1. 纯字符串 2. 对话消息列表(如 [HumanMessage(...)]) 3. Prompt 输出的 PromptValue 对象。 |
ChatMessage | 输出是结构化的 ChatMessage 对象,包含: - 模型回复的文本内容 - 角色标识(AI) - 工具调用、元数据等扩展信息。 |
传入 [HumanMessage(content="你好")],返回 AIMessage(content="你好!有什么可以帮你的吗?")。 |
| LLM | Single string, list of chat messages or a PromptValue | 输入格式和 ChatModel 完全兼容,但主要面向传统文本补全模型,对对话格式的支持较弱。 |
String | 直接输出纯文本字符串,没有任何额外的对象结构,是模型最原始的文本回复。 | 传入字符串 "给我讲个笑话",直接返回纯文本 "为什么程序员喜欢用黑主题?因为light attracts bugs."。 |
| OutputParser | The output of an LLM or ChatModel | 输入就是 LLM 或 ChatModel 的原始输出: - 对 LLM 来说是字符串 - 对 ChatModel 来说是 ChatMessage 对象。 |
Depends on the parser | 输出格式完全由你选择的解析器决定: - StrOutputParser → 纯字符串 - JsonOutputParser → Python 字典 - PydanticOutputParser → 结构化数据对象。 |
用 JsonOutputParser 解析模型输出的文本,把 "{"name": "小明"}" 转换成 Python 字典 {"name": "小明"}。 |
| Retriever | Single string | 接收一个纯字符串作为用户查询,比如 "LangChain 的核心组件有哪些?"。 |
List of Documents | 输出是一个 Document 对象列表,每个对象包含: - page_content:检索到的文本片段 - metadata:来源、标题等元数据。 |
传入用户问题 "LangChain 组件有哪些",返回 3 条相关的 Document 片段。 |
| Tool | Single string or dictionary, depending on the tool | 输入不固定,由工具自身定义: - 简单工具(如计算器)接收字符串表达式 - 复杂工具(如数据库查询)接收字典格式的多参数。 | Depends on the tool | 输出也由工具定义,比如: - 计算器返回数字 - 搜索引擎返回结果列表 - 数据库查询返回结构化数据。 | 调用计算器工具,输入 "2 + 3 * 4",返回计算结果 14。 |
LLMs
LangChain自己并不进行LLMs的服务,而是提供一个标准接口去跟许多LLMs供应商(OpenAI,Cohere等)进行交互。
基础使用
使用通义千问来作为LLMs供应商,目前许多国产大模型都提供了几百万的免费tokens额度,这为我们的学习用途提供了很大的便利,主打一个白嫖。
自定义LLM
在LangChain生态中,无论是本地部署的模型(如Ollama、Xinference),还是线上第三方未被LangChain内置的模型(如小众厂商API、私有部署模型),都需要通过自定义封装,使其适配LangChain的标准调用方式,从而无缝使用LangChain的全部生态能力(如invoke、chain、agent等)。结合实操中的常见疑问,本节梳理自定义LLM封装的核心逻辑、实现要点及关键细节,快速吃透封装本质。
一、封装核心前提:继承LangChain的LLM基类
自定义LLM封装的第一步,是继承LangChain提供的标准基类------langchain.llms.base.LLM。这一步的核心作用的是:让自定义模型自动继承LangChain的Runnable特性,无需额外实现,就能直接使用invoke、batch等LangChain标准调用方法。
这里需要明确一个关键认知:我们继承的基类就是LLM(全称langchain.llms.base.LLM),它是LangChain所有大模型的统一父类,规定了模型调用的标准接口规范,相当于所有LLM的"模板"。
二、必须重写的核心方法(二选一,推荐前者)
继承LLM基类后,有两个核心内容必须实现(硬性要求,不实现会报错),其中核心方法支持二选一,具体差异及推荐用法如下:
- 推荐写法:重写
_generate方法(现代标准)
目前主流的大模型(如通义千问、OpenAI、文心一言等)均采用这种方式,核心原因是_generate方法支持返回完整的LLMResult结构体,除了模型回答,还能附带token消耗、停止原因、模型信息等关键元数据------这也是我们购买大模型套餐时,计费token的核心来源。
重写_generate的核心逻辑:在方法内部,向目标模型(本地/Ollama/线上API)发送请求,获取返回结果后,按照LangChain要求的标准格式({"generations": [{"text": 回答内容}]})封装返回,同时可携带token使用信息。
- 兼容写法:重写
_call方法(旧版写法)
如果仅需要模型返回简单的文本回答,也可以重写_call方法。这种方法的优势是简单直观,只需接收字符串提示、返回字符串结果即可,但局限性极强------无法获取token消耗、停止原因等额外信息,仅适用于极简场景。
- 必写标识:
_llm_type属性
无论重写哪种核心方法,都必须实现_llm_type属性(用@property装饰),返回一个自定义的模型类型字符串(如"ollama_custom"、"my_local_llm"),用于LangChain内部识别模型类型,方便日志输出和后续扩展。
三、关键调用逻辑:为什么重写_generate就够了?
很多同学会疑惑:LangChain的调用入口是invoke,为什么表格中不需要重写invoke?核心原因是:invoke方法已经在LLM基类中实现好了,我们无需额外编写。
完整的调用顺序(现代写法,重写_generate)如下:
BaseLLM.invoke → LLM.generate → LLM._generate(我们重写的方法)
llm.invoke()时的实际调用情况
可以看到,invoke的底层会自动调用generate,而generate又会调用我们重写的_generate,因此只要实现_generate,整个调用链路就会自动打通,无需再关注_call或invoke。
若重写_call(旧版写法),调用顺序则为:
BaseLLM.invoke → LLM.generate → LLM._generate(基类默认实现) → LLM._call(我们重写的方法)
LangChain基类已做双向兼容,两种写法都能正常运行,但优先推荐重写_generate。
四、常见认知误区澄清
误区1:封装仅适用于本地模型
错误!封装LLM接口不分本地/线上,核心是"LangChain不认识的模型API,都需要封装"。无论是本地部署的Ollama、Xinference,还是公司内网部署的模型、第三方小众模型API,只要LangChain没有内置对应的实现类,都需要通过相同的方式封装------本质是做一个"翻译器",将LangChain的标准调用,转化为目标模型能识别的请求格式,再将模型返回结果转化为LangChain能识别的格式。
误区2:token消耗是LangChain计算的
错误!token的计数的是由模型官方(如通义千问、OpenAI)计算的,LangChain仅负责将模型返回的token信息(prompt_tokens、completion_tokens、total_tokens)提取并展示,不参与任何计数逻辑。而我们购买的大模型套餐,正是按照这个total_tokens进行扣费的------问题越简单、输入输出越短,token消耗越少,扣费也越少(原则上完全成立)。
误区3:必须同时重写_generate和_call
错误!二者二选一即可。重写_generate后,基类会自动兼容_call(无需额外编写);重写_call后,基类也会自动用_call实现_generate,无需重复开发。
五、极简封装模板(可直接复用)
以下是LangChain 自定义大语言模型的最简标准模板,只需继承官方 LLM 基类、实现核心方法,就能快速打造兼容 LangChain 全生态的自定义模型,新手也能直接套用。
python
from typing import Any, Dict, Iterator, List, Optional
from langchain_core.callbacks.manager import CallbackManagerForLLMRun
from langchain_core.language_models.llms import LLM
from langchain_core.outputs import GenerationChunk
# 自定义 LLM 类,继承 LangChain 官方 LLM 基类
class CustomLLM(LLM):
# 自定义参数:截取前 n 个字符返回
n: int
# 【必须实现】同步调用核心方法
def _call(
self,
prompt: str,
stop: Optional[List[str]] = None,
run_manager: Optional[CallbackManagerForLLMRun] = None,
**kwargs: Any,
) -> str:
# 不支持停止词,直接抛异常
if stop is not None:
raise ValueError("stop kwargs are not permitted.")
# 核心逻辑:返回输入文本的前 n 个字符
return prompt[: self.n]
# 【可选实现】流式输出方法
def _stream(
self,
prompt: str,
stop: Optional[List[str]] = None,
run_manager: Optional[CallbackManagerForLLMRun] = None,
**kwargs: Any,
) -> Iterator[GenerationChunk]:
# 逐个字符返回,实现流式效果
for char in prompt[: self.n]:
chunk = GenerationChunk(text=char)
if run_manager:
run_manager.on_llm_new_token(chunk.text, chunk=chunk)
yield chunk
# 【可选实现】模型标识参数(日志/监控用)
@property
def _identifying_params(self) -> Dict[str, Any]:
return {"model_name": "CustomChatModel"}
# 【必须实现】模型类型(日志用)
@property
def _llm_type(self) -> str:
return "custom"快速使用示例
python
# 1. 初始化自定义 LLM,设置截取前 5 个字符
llm = CustomLLM(n=5)
# 2. 同步调用:直接返回结果
print(llm.invoke("This is a foobar thing")) # 输出:This
# 3. 流式调用:逐字输出结果
for token in llm.stream("hello"):
print(token, end="|") # 输出:h|e|l|l|o|
# 4. 批量调用:同时处理多个输入
print(llm.batch(["woof woof woof", "meow meow meow"])) # 输出:['woof ', 'meow ']极简改造思路
只需修改 _call 方法里的 return prompt: self.n,替换成你自己的模型调用逻辑,就能快速生成专属 LLM。
六、总结
自定义LLM封装的核心,是"遵循LangChain标准,适配目标模型API"------继承LLM基类,二选一重写_generate(推荐)或_call,补充_llm_type属性,即可让任何模型(本地/线上/私有)像LangChain内置LLM一样使用。
其中,重写_generate是现代标准写法,既能满足基础的文本生成需求,又能获取token消耗等关键计费信息,适配绝大多数生产场景;而理解invoke的底层调用逻辑、区分token计数的责任方,能帮我们避开实操中的常见坑,更高效地完成封装开发。
缓存
缓存的使用场景是存在多次相同的文本生成请求,直接从缓存中获取结果进行回复,既可以提升性能,又可以减少对LLM供应商的请求,从而节省费用。
其中,最为简单的缓存方式便是内存,对应的实现类为:InMemoryCache,每次的prompt和结果都会存储在内存中。
此外还有SQLiteCache 和 RedisCache 持久性存储方案。
记录消耗tokens
python
from callbacks.manager import get_generic_llms_callback
with get_generic_llms_callback() as cb:
llm.invoke("有什么关于失业和通货膨胀的相关性的理论")
print(cb)Chat Model
Messages类型
Chat models使用chat message作为输入和输出,除了上述提到的三种基本messages类型,还有另外两种:
- SystemMessage:用于制作此次对话的人设;
- HumanMessage:用户的输入;
- AIMessage:模型的输出;
- FunctionMessage:函数调用(function call)的结果,除了对应的role和content参数外,还有一个name参数,表示对应名称的函数的执行结果
- ToolMessage:工具调用(tool call)的结果,同样有额外的参数tool_call_id,表示对应id的工具的执行结果。
函数和工具的调用暂且不在这个章节进行阐述,留到后续有专门的章节。
内置 Chat Model = LangChain 自带的、标准的 Chat Model 接口 / 类
模型关键参数
- max_tokens
模型返回的最大输出 token 数
- 控制回答最长能写多少字
- 公式很好记:输入模型上下文上限
- 举例:gpt-3.5-turbo-16k 上下文总长 16k,你提问用了 2k,那回答最多还能写 14k。
- 设太小:回答被强行截断、没说完
- 设太大:浪费开销、延迟变高
- 所有历史上下文、系统提示、当前提问,全部算作输入 Token 并计费;
- temperature 温度
控制随机性 / 创造性
-
取值一般:0~2
-
越接近 0:** deterministic 确定性极强 **,回答固定、严谨、适合代码 / 推理 / 问答
-
越接近 2:脑洞大、随机、发散,适合文案创作、写诗、脑洞内容
业务场景口诀:
- 写代码、数据分析、知识库问答 → 0.1~0.3
- 日常聊天、文案写作 → 0.7~1.0
- top_p 核采样
从概率总和前 top_p 的词里选,压缩候选词范围
-
和 temperature 是两套控制随机的方案:
- top_p=0.1:只选概率极高的一小撮词,回答保守、稳定
- top_p=0.9:允许纳入更多低概率新词,回答更多样
行业常用搭配:
- 一般只调 temperature,top_p 固定 0.9 不动
- 两个同时乱调容易效果混乱
- frequency_penalty 频率惩罚
降低重复用词、重复句式
-
针对:已经反复出现过的词语加大惩罚
-
值越高:越讨厌老生常谈、反复叠词
-
作用:减少复读机、句子循环、话术重复
- presence_penalty 存在惩罚
鼓励新开话题、拓展新内容
-
针对:只要上文出现过的内容就轻微打压
-
值越高:越倾向多说新观点、新角度、不局限前文
-
作用:避免模型一直围着一个点绕圈,提升内容丰富度
极简总结版
全部都可以手动设置temperature / top_p / max_tokens / frequency_penalty / presence_penalty
- max_tokens:限制模型最大输出长度,结合输入 Token 不能超过模型上下文上限。
- temperature:温度,控制输出随机性,越低越严谨,越高越有创造性。
- top_p:核采样,从累计概率靠前的 Token 中采样,用于控制输出多样性。
- frequency_penalty:频率惩罚,抑制词语重复出现,减少文本复读。
- presence_penalty:存在惩罚,弱化已有内容,鼓励模型输出新观点、新内容。
Output Parsers
自定义解析器
Runnable Lambdas.
这种方法非常简单,仅需定义一个基本方法,接收Chat model的输出AIMessage,下面示例的解析器是将Chat model的回复文本转换大小写。
bash
#%%
from typing import Iterable
from langchain_core.messages import AIMessage, AIMessageChunk
def parse(ai_message: AIMessage) -> str:
"""Parse the AI message."""
return ai_message.content.swapcase()
chain = chat | parse
chain.invoke("hello")Runnable Generators
流式模式支持同样简单,仅需要定义一个方法,接收Chat model的输出AIMessageChunk迭代器,遍历对每次Chat model的流式返回进行处理,即streaming_parse方法是对每一块chunk进行处理,而非上面的parse方法是对LLM返回的完整数据进行处理。
bash
#%%
from langchain_core.runnables import RunnableGenerator
def streaming_parse(chunks: Iterable[AIMessageChunk]) -> Iterable[str]:
for chunk in chunks:
yield chunk.content.swapcase()
streaming_parse = RunnableGenerator(streaming_parse)
chain = chat | streaming_parse
for chunk in chain.stream("tell me about yourself in one sentence"):
print(chunk, end="|", flush=True)输出
bash
i| AM| AN| ai| ASSISTANT DESIGNED TO HELP| WITH INFORMATION, ANSWER| QUESTIONS, AND PROVIDE| SUPPORT IN A VARIETY| OF TOPICS.|||streaming_parse 理解:
- 一次流式调用 = 一个唯一 chunks 碎片流;
- chunks 是整条流,chunk 是流里的每一小片;
- 函数只跑一次,循环持续消费同一个流
总结
| 方式 | 处理时机 | 输入 | 写法 | 调用 |
|---|---|---|---|---|
| RunnableLambda | 模型说完一整句再处理 | AIMessage(完整) | 普通 return 函数 | invoke() |
| RunnableGenerator | 模型边说边处理 | AIMessageChunk(碎片) | yield 生成器 | stream() |
类命名实体识别NER技术
一、先纠正概念:什么是「类 NER 技术」
-
传统 NER
命名实体识别:
- 从文本里固定抽取预设实体:
- 人名、地名、时间、物品、机构...
-
LangChain 里的「类 NER」
不是模型原生NER ,是大模型 + 结构化输出解析 实现的通用信息抽取:- 你自定义需要抽取哪些「字段/实体」
- 用
Pydantic定义结构 - 用
get_format_instructions()强制模型按结构输出 - 解析器自动反向转为结构化对象
👉 本质:自定义字段的轻量化实体抽取 = 类NER
Joke 案例,就是最简Demo:
- 限定抽取两个「实体/模块」:
setup:问题片段punchline:回答片段
换成业务场景就是:
- 抽取:商品名、价格、规格、地址、联系方式
- 完全等价 自定义NER实体抽取
二、结合代码,逐行拆解 类NER 完整流程
- 第一步:自定义「抽取实体结构」(NER 实体定义)
python
from pydantic import field_validator
class Joke(BaseModel):
setup: str = Field(description="开启一个笑话的问题")
punchline: str = Field(description="解答笑话的答案")
# You can add custom validation vblogic easily with Pydantic.
@field_validator("setup")
# def question_ends_with_question_mark(cls, field):
def test(cls, field):
if field[-1] != "?":
raise ValueError("Badly formed question!")
return field对应 NER 思维:
- 手动定义需要抽取的两类实体
description= 给大模型看的「实体抽取规则说明」@validator= 实体合法性校验,过滤脏数据
- 第二步:绑定解析器,生成「抽取格式约束」
python
parser = PydanticOutputParser(pydantic_object=Joke)
# 核心:自动生成 NER 抽取规则提示词
format_instructions = parser.get_format_instructions()关键作用
get_format_instructions()自动生成一段自然语言,发给LLM:
你必须输出 JSON
必须包含 setup / punchline 字段
严格遵守字段含义,不要多余内容
👉 这就是大模型类NER的核心 :用提示词强约束模型,按指定实体字段做抽取
- 第三步:把抽取规则注入 Prompt
python
prompt = PromptTemplate(
template="根据用户的输入进行解答.\n{format_instructions}\n{query}\n",
input_variables=["query"],
partial_variables={"format_instructions": parser.get_format_instructions()},
)Prompt 最终结构:
根据用户的输入进行解答.
【自动插入的结构化抽取规则】
讲一个笑话大模型看到规则,就会压制自由文本生成,改为:
从回答中拆分、提取、整理成指定两个字段
- 第四步:LLM 生成 + 结构化解析(NER结果落地)
python
# LCEL 链路:提示词 → 大模型
prompt_and_model = prompt | chat
# 大模型输出带格式的文本
output = prompt_and_model.invoke({"query": "讲一个笑话"})
# 解析器:文本 → 强类型实体对象(最终NER结果)
res = parser.invoke(output)最终拿到:
python
res.setup # 抽取出来的问题实体
res.punchline # 抽取出来的答案实体三 极简NER
python
output_parser = CommaSeparatedListOutputParser()
format_instructions = output_parser.get_format_instructions()这是极简版类NER:
- 不定义复杂对象
- 只要求模型「按列表形式批量抽取多个实体」
- 适合:批量关键词、标签、物品抽取
LangChain 内置的、固定格式的解析器,只认这一种格式,解析出来就是 Python 的 list:英文逗号 + 无空格 + 纯文本列表。
四、总结:LangChain 类NER 核心公式
自定义Pydantic实体结构
+ 字段描述+校验规则
+ get_format_instructions 生成格式约束
+ Prompt注入规则
+ 输出解析器反向结构化
= 轻量化、可自定义的 类NER信息抽取和传统NER区别
- 传统NER:固定实体、小模型、速度快
- 大模型类NER:任意自定义字段、无需标注、灵活极强
- 依赖:
格式指令约束 + 输出解析器整套机制
LangChain 阶段一 核心汇总表
一、模型层|LLM 与 ChatModel 核心区分
| 类名 | 类型 | 入参格式 | 配套模板 | 核心特点 | 自定义重写方法 |
|---|---|---|---|---|---|
Tongyi |
普通LLM | 纯字符串 | PromptTemplate |
无角色、纯文本生成 | _call / _stream |
ChatTongyi |
对话ChatModel | 消息列表List[BaseMessage] |
ChatPromptTemplate |
支持多角色、多轮对话、System人设 | _generate / _stream |
二、Message 消息全家族
| 消息类 | 归属 | 固定role | 适用场景 | 等价关系 |
|---|---|---|---|---|
BaseMessage |
顶层父类 | 无 | 所有消息基类 | 全部消息的父类 |
SystemMessage |
专属角色消息 | system |
设定AI人设、规则、约束 | ✅ 等价:ChatMessage(role="system") |
HumanMessage |
专属角色消息 | human |
终端用户提问、输入 | ✅ 等价:ChatMessage(role="human") |
AIMessage |
专属角色消息 | ai |
AI 历史回复内容 | ✅ 等价:ChatMessage(role="ai") |
AIMessageChunk |
流式分片消息 | ai | 流式输出逐字块 | 对话流式专用 |
ChatMessage |
通用万能消息 | 自定义任意 | 角色扮演、非常规角色(Jedi/老师) | 自由指定 role,兼容上面所有角色 |
核心结论:
SystemMessage / HumanMessage / AIMessage只是 固定role的语法糖底层本质 = 预制好角色的
ChatMessage
三、Template 模板全家族
| 模板类 | 用途 | 搭配对象 | 核心功能 | 使用场景 |
|---|---|---|---|---|
PromptTemplate |
纯文本模板 | 普通LLM | 普通字符串变量渲染 {xxx} |
单轮简单文本提问 |
ChatPromptTemplate |
对话组合模板 | ChatModel | 拼接多条角色消息(system+human+ai) | 多轮对话、常规AI开发 |
HumanMessagePromptTemplate |
单条人类模板 | ChatModel | 只能生成 human 角色、带变量 | 用户动态输入模板 |
ChatMessagePromptTemplate |
自定义角色模板 | ChatModel | 手动指定任意 role + 变量模板 | 特殊角色对话、角色扮演 |
FewShotChatMessagePromptTemplate |
少样本模板 | ChatModel | 注入示例问答,给AI模仿 | 格式统一、规则强化 |
MessagesPlaceholder |
消息占位容器 | ChatPromptTemplate | 专门存放历史消息列表 | 上下文记忆、多轮连贯对话 |
四、OutputParser 输出解析器大全
| 解析器类型 | 代表类 | 能力 | 适用场景 |
|---|---|---|---|
| 结构化解析 | PydanticOutputParser |
强制结构 + 数据校验 + 自动生成对象 | 企业开发、严格格式、字段校验 |
| 轻量JSON解析 | JsonOutputParser |
输出标准JSON字典,无强校验 | 简单结构化、快速开发 |
| 列表解析 | CommaSeparatedListOutputParser |
逗号文本自动转为 List | 批量名词、清单提取 |
| 极简自定义 | 普通函数 | 自定义简单文本处理 | 大小写转换、简单清洗 |
| 流式自定义 | RunnableGenerator |
逐Chunk流式加工处理 | 流式输出二次改造 |
| 标准自定义 | BaseOutputParser |
规范重写parse方法 |
通用文本自定义解析 |
| 底层自定义 | BaseGenerationOutputParser |
解析模型原始结果(含metadata) | 需要获取响应元数据、耗时、token |
五、自定义模型两大分类
| 自定义模型类型 | 继承父类 | 核心实现方法 |
|---|---|---|
| 自定义普通LLM | LLM |
_call(阻塞)、_stream(流式) |
| 自定义对话ChatModel | BaseChatModel |
_generate(阻塞)、_stream(流式) |
六、全局统一工作流(所有代码通用)
模板Template → 渲染变量 → 组装Message → ChatModel/LLM推理 → OutputParser结构化解析1.2 Retrieval
总结: 本节讲了RAG(Retrieval Augmented Generation,检索增强生成):在生成过程中,外部的数据会通过检索然后传递给LLM,让LLM能够利用这些新知识作为上下文。
许多LLM应用需要使用到用户特定的数据,比如某些私域/垂直领域的数据,但它并不包含在LLM的训练样本集合,因此LLM无法在这些领域很好地发挥它的能力。
对于近期的资讯信息,由于训练样本的滞后性,无法实时更新最新资讯语料,因此LLM是无法获知临近的资料信息的,有时甚至会一本正经的胡说八道。
垂直 = 做的窄、做的精,人群专一
私域 = 抓在自己手里,反复利用
垂直领域实体:猫咪喂养、前端工程、露营装备
私域相关实体:社群、企微、用户沉淀、复购运营
而针对这种数据情况,目前最主要的解决方式则是RAG(Retrieval Augmented Generation,检索增强生成):在生成过程中,外部的数据会通过检索然后传递给LLM,让LLM能够利用这些新知识作为上下文。
LangChain提供了全部RAG应用的构建模板,覆盖了与检索流程相关的所有步骤,例如获取外部数据等。它主要包含以下几个核心模块:
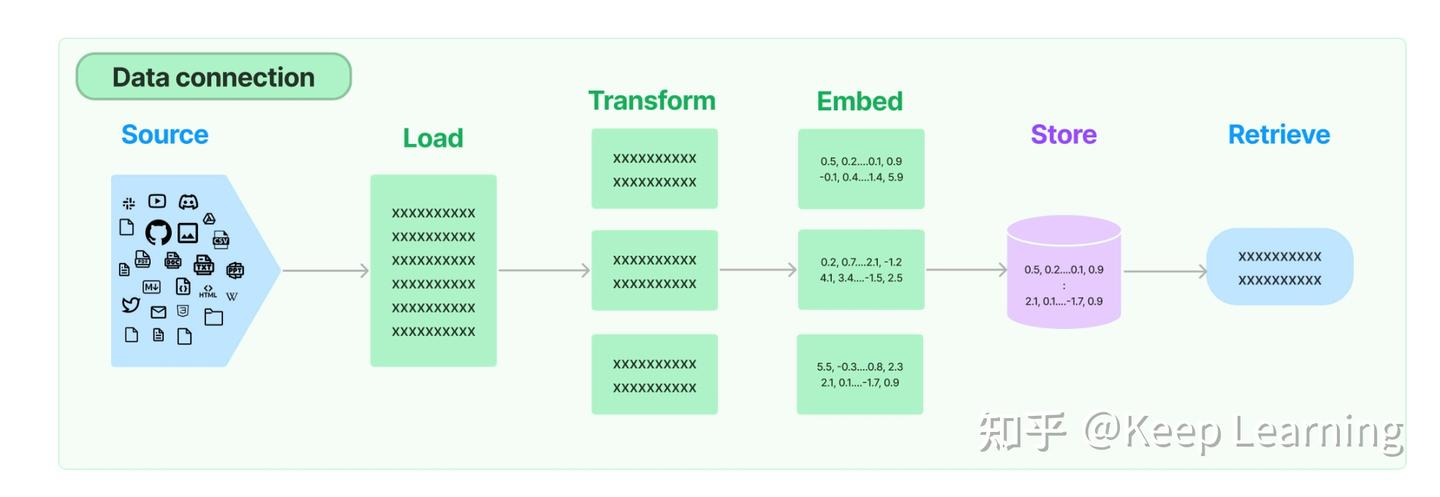
Source 模块
对应文字:Document loaders 里的「不同的数据源」
图里的蓝色图标(PDF、HTML、视频、代码、CSV、网页等),就是 LangChain Document Loaders 支持的各种数据源类型。
- Document loaders:LangChain内置100多种document loaders,可以从许多不同的数据源加载数据,支持所有类型包括HTML、PDF和code等,也支持各种地址包括S3 buckets、公开的网站等等。
- Text Splitting:检索的一个关键部分就是只获取文档中相关的那一部分,这涉及到多个转换步骤来为检索准备文档。其中主要的一个步骤就是将一个大型文档拆分为更小的chunks(块)。
Transform 模块
对应文字:Text Splitting(文本分割)
这里的多个绿色块,就是把 Load 进来的完整文档,拆分成更小的 chunks(文本块)。
目的:避免长文本的语义丢失,也能让检索只拿到和问题相关的片段。
- Text Embedding Models:检索的另外一个关键部分就是为文档创建embeddings。embeddings可以捕获文本的语义信息,让你可以快速高效的寻找到相似的文本。
- Vector Stores:随着embeddings数量增加,便需要一个向量数据库来高效地存储和检索这些embeddings,像之前介绍过的支持本地内存: Annoy & Faiss、chroma,或者C/S架构:milvus、weaviate、qdrant等等
- Retrievers:一旦数据存入数据库,接下来要做的便是检索。LangChain提供了许多不同的检索算法,能够很轻松的实现语义相似检索。
- Indexing:LangChain提供了Indexing API来同步数据源到向量数据库。
Indexing(索引 API)
它是对 Load → Transform → Embed → Store 整个流程的统一封装,用来做「数据源和向量数据库的同步」,避免重复加载、重复嵌入,让整个索引构建过程更高效、更可控。
文档加载器
自定义加载器
文档加载主要包括以下几个抽象组件:
| Component | Description |
|---|---|
| Document | Contains text and metadata |
| BaseLoader | Use to convert raw data into Documents(将原始数据转换为Documents) |
| Blob | A representation of binary data that's located either in a file or in memory(表示一个文件或内存里的二进制数据) |
| BaseBlobParser | Logic to parse a Blob to yield Document objects(将 Blob解析为Document) |
Loader 负责拿数据 → 变成 Blob → Parser 负责解析 → 变成 Document
blob内容可见 xxxxx ------ 待补充
同步懒加载和异步懒加载:
同步懒加载lazy_load与异步懒加载alazy_load同属懒加载机制 ,均基于生成器逐一生成Document、按需加载数据、不会一次性将全部文档载入内存;lazy_load是同步阻塞 执行,读取文件、解析数据时会阻塞当前线程,任务顺序串行执行,为自定义加载器必须实现的核心方法;alazy_load是对应的异步非阻塞版本,依托异步IO实现数据读取,IO等待阶段可释放线程资源处理其他任务,适配高并发异步业务场景,该方法可选择性实现,若不手动重写,BaseLoader会自动将同步懒加载逻辑包装为异步兜底方案。
文本分割器
语义分割
核心逻辑
- 切单句 → 2. 窗口组合 → 3. 算向量距离 → 4. 阈值判断 → 5. 分块
具体示例
1 原始长文本
人工智能快速发展。大模型改变各行各业。向量数据库是知识库核心。明天早上八点开会。记得带上纸质文件。2 步骤拆解
- 切单句(代码:re.split):A(人工智能), B(大模型), C(向量数据库), D(开会), E(带文件)
- 窗口组合(buffer_size=1,代码:combine_sentences):
- A窗口:无前置 + A + B → 人工智能快速发展。大模型改变各行各业。
- B窗口:A + B + C → 人工智能快速发展。大模型改变各行各业。向量数据库是知识库核心。
- C窗口:B + C + D → 大模型改变各行各业。向量数据库是知识库核心。明天早上八点开会。
- D窗口:C + D + E → 向量数据库是知识库核心。明天早上八点开会。记得带上纸质文件。
- 生成Embedding(代码:embed_documents):给每个窗口生成语义向量
- 算距离+定阈值(代码:calculate_cosine_distances + np.percentile):
- 相邻窗口距离:A-B(小,同话题)、B-C(小,同话题)、C-D(大,话题跳转)
- 阈值(95分位):只认定C-D为语义断点
- 分块结果(代码:循环分组):
- 块1:A+B+C(AI技术话题)
- 块2:D+E(会议通知话题)
核心结论
语义分块:不靠字数/标点,靠「窗口上下文+向量距离」,自动识别话题跳转,实现语义连贯分块。
Embedding
Embedding 模型作用:普通文字 → Embedding 模型 → 一串纯数字向量语义越像,数字向量越接近;语义无关,向量差距很大。
许多主流的大模型供应商都会有其对应的Embedding模型。下面仍然以通义千问的免费tokens额度来作为演示案例,它支持最大2048的字符长度,生成的向量维度为1536。
支持最大2048的字符长度 : 单次最多只能传 2048 个汉字 / 字符,一次性转向量。文本 ≤2048:直接整段向量化文本 >2048:不能一次性处理,必须截断 / 拆分后再转。
生成的向量维度为1536(1*1536):2 维、3 维:只能表达简单特征,1536 维:可以精细储存:词义、语气、话题、逻辑、上下文风格 👉 维度越高,语义表达越精细,判断两段文字「像不像」就越准
LangChain没有内置通义千问的Embedding实现,因此需要自己实现,比较简单,可以参考内置的BaichuanTextEmbeddings实现。
embedding也可以设置缓存,包括本地缓存,内存缓存和redis缓存。
向量数据库
- 选择Embedding模型,对源数据进行批量文档生成的表征向量,存储到向量数据库
- 在查询的时候,对非结构化的查询文本使用同样的Embedding模型生成表征向量,然后去向量数据库召回与查询文本的表征向量相似的向量对应的文档。
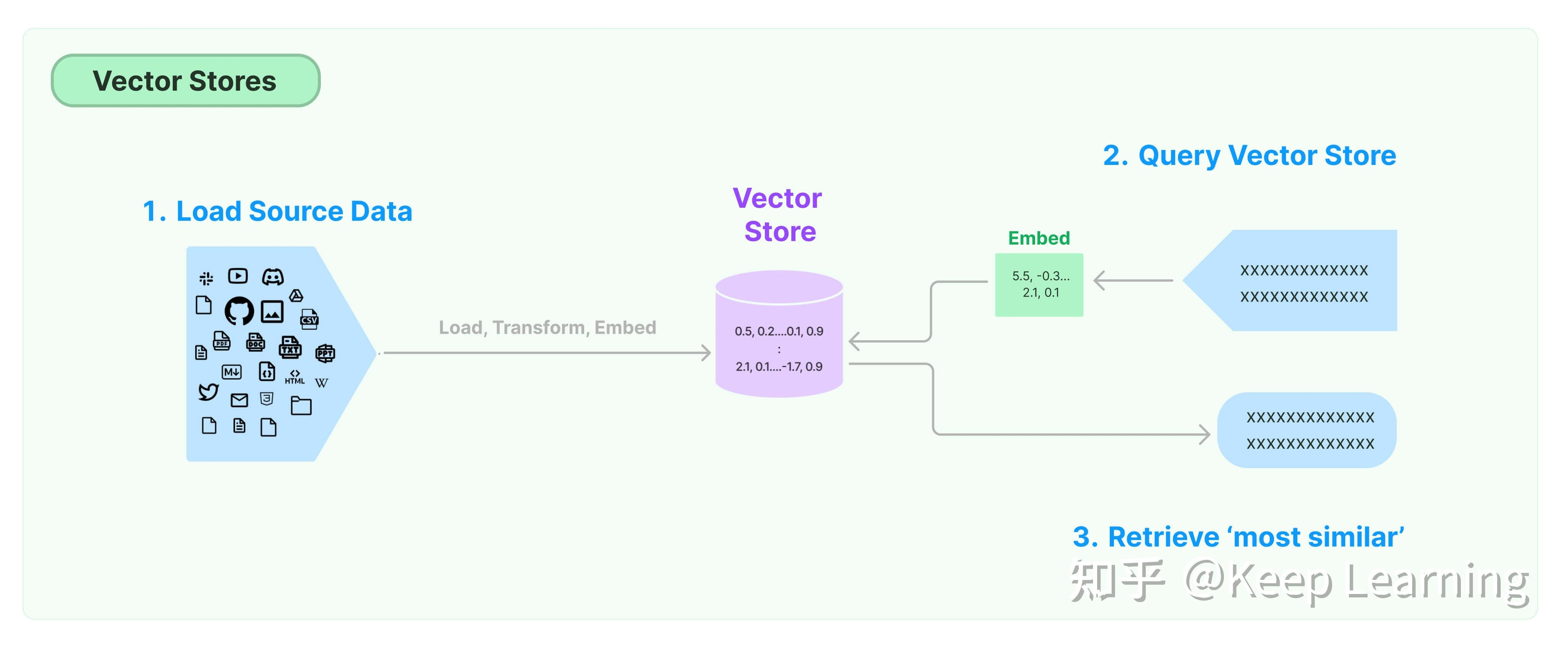
以faiss作为向量数据库进行实例演示。(LangChain支持的向量数据库十分丰富,可以根据自己的需求进行选择)
RAG(检索增强生成)的核心流程
- 加载文件 → 切小片段 → 转向量 → 存向量库
- 用户提问 → 转向量 → 搜最相似的文本片段
MMR
一句话核心
MMR 就是在选文档的时候,既要和用户问题"像",又要和已经选过的文档"不像",避免结果全是重复内容。
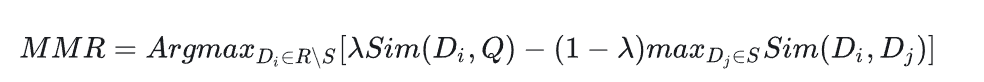
分步骤拆解(对应公式逻辑)
-
先选出和问题最像的文档,作为初始集合 S
- 先按普通相似度排序,挑出和查询 Q 最相关的文档,放进已选集合
S。 - 剩下的文档,都在未选集合
R\S里。
- 先按普通相似度排序,挑出和查询 Q 最相关的文档,放进已选集合
-
每次循环,从剩下的文档里,选"综合得分最高"的那一条
公式里的得分是:
得分 = λ × 和查询的相似度 − (1−λ) × 和已选文档的最大相似度这个公式的意思是:
λ × 和查询的相似度:奖励和问题本身很相关的文档。(1−λ) × 和已选文档的最大相似度:惩罚和已经选过的文档太像的内容。- 最后取
argmax,就是挑出综合得分最高的文档,加入到S里。
-
重复第2步,直到选够你要的数量
- 每次选新文档时,都会和所有已经选过的文档比相似度,避免重复。
- 最终得到的结果,就是既和问题相关,又彼此内容多样的列表。
举个生活化的例子
你要找"高考成绩查询方式",数据库里有5条结果:
- 教育局官网查询
- 教育局官网查询(换了个说法)
- 学校教务处查询
- 学校教务处查询(不同措辞)
- 短信推送查询
- 普通相似度搜索,可能会把前两条"官网查询"都排到最前面,结果全是重复的。
- MMR 会怎么做?
- 先把"教育局官网查询"放进
S。 - 选下一条时,"教育局官网查询(换说法)"和已选的相似度太高,被扣分,得分变低;而"学校教务处查询"和已选的相似度低,扣分少,得分更高,会被优先选中。
- 最终结果会是:官网 → 教务处 → 短信,既相关又不重复。
- 先把"教育局官网查询"放进
λ 参数的作用
λ=1:只看和问题的相似度,和普通搜索完全一样,不做去重。λ=0:只看和已选文档的差异度,完全不管和问题相不相关,结果会很偏。- 一般取 0.3~0.7,平衡相关性和多样性。
多文档比较的关键规则
当已选集合 S 里有多个文档时:
- 对于每个候选文档,只取它与 S 中所有文档的最大相似度来计算惩罚项,而非平均值或总和。
- 目的是:只要和其中任何一个已选文档高度相似,就会被认为是重复内容,从而被扣分。
检索
上下文压缩
上下文压缩:修改文档,但只删除无关内容、不改动原文文字、不创作新内容。
集成检索
spare retriever(即全文检索)
BM25 给文档打分,本质是做了三件事:
- 词频越高,分越高;
- 词越稀有(越有信息量),分越高;
- 太长的文档会被 "拉平",不会因为词多就占便宜。
多向量检索-分块
原理:把一篇大文档拆成多个小片段向量去检索匹配,但命中片段后,最终返回原始完整大文档,兼顾细粒度匹配 + 完整上下文。
具体实现:
- 先把原始长文本,预先分割成固定块(chunk);
- 对每一个分割后的文档块,再额外生成:小片段 / 摘要 / 关键短句,单独向量化存储;
- 检索:用 Query 去匹配粒度更细的碎片向量(更容易命中细节);
- 命中细碎片 → 关联找到它所属的那一块文档,只返回这个分割块
多向量检索-总结
核心原理
对同一个原始文本块,存两套向量 :
原文块向量 + 摘要精简向量;用无噪声的摘要向量 做高精度检索,命中后映射还原返回原始完整文本块,兼顾检索精准度与上下文完整度。
执行步骤
- 切块:原始长文档,提前分割为标准文本块;
- 生成摘要:对每个文本块,提炼精简总结(剔除冗余、噪声);
- 双向量入库:给「原文块」「摘要文本」分别生成 Embedding,绑定关联存储;
- 摘要检索 :用户 Query 向量化,只用摘要向量库做匹配(摘要语义更聚焦,检索更准);
- 映射还原 :命中摘要向量后,通过绑定关系,找到并返回对应的原始文本块。
多向量检索-假设问题
场景痛点
- 用户输入:问句(问题形式)
- 库里文档:陈述句(答案、说明文、资料)
- 问题:问句 ↔ 陈述句,句式结构差太大
- 后果:Embedding 语义匹配拉胯,搜不到、匹配不准
解决方案核心
用户用问题 来搜,那就给每份答案文档 ,让 LLM 反向生成多条:「这篇文档能回答哪些问题?」 → 产出一堆人造假设性问题
整套流程(对应多向量检索)
- 原始文档块:陈述句(答案)
- LLM 基于当前文档,批量生成多条假设提问
- 入库存两组向量:
- 原文答案向量
- 【LLM生成的假设问题】向量
- 用户提问(问句)进来
- 优先用「问题向量库」匹配
- 匹配到人造问题 → 映射找回原本的答案文档返回
一句话本质
把答案文档,反向翻译成一堆问题;
用「问题匹配问题」,消除句式差异,大幅提升检索准确率。
Self-querying检索
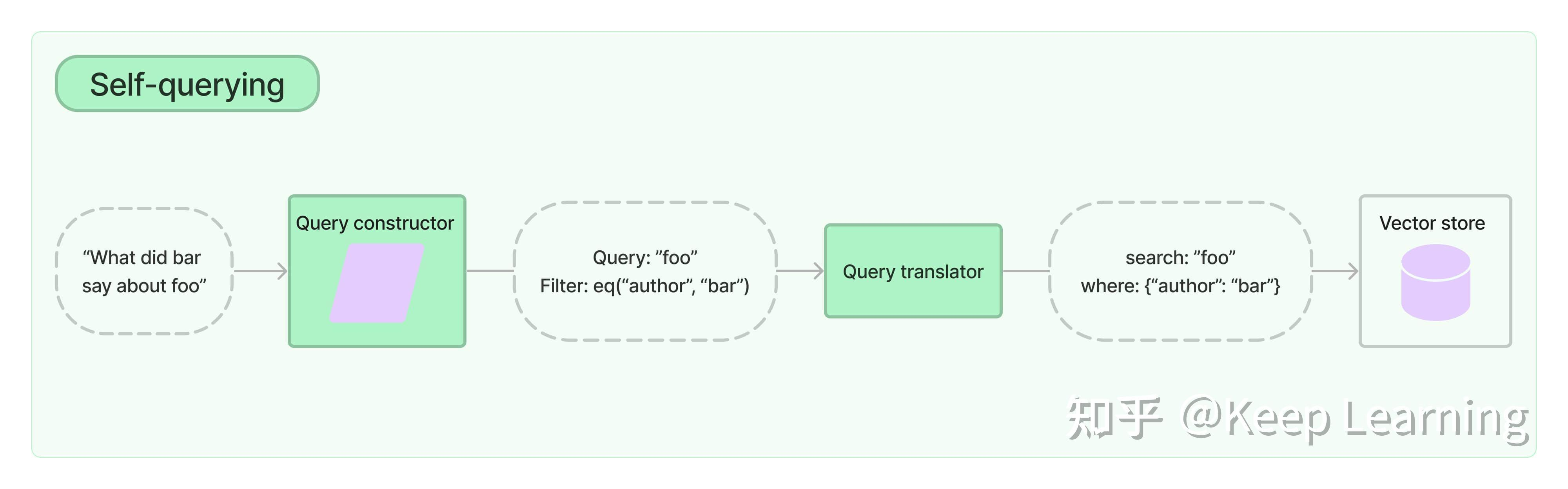
- 核心能力
- 不用手写筛选规则,LLM 自动把自然语言问句 ,拆成两部分:
- 语义检索关键词(用于向量模糊匹配正文)
- 结构化过滤条件(元数据精准筛选:评分、年份、导演、类型等)
- 工作流程
- 给大模型告知:文档描述 + 所有元数据字段/类型/含义
- LLM 将自然语言 → 翻译成标准化结构化查询
- 向量库先做语义向量检索 ,再叠加元数据条件过滤
- 最终返回同时满足「语义相似 + 规则筛选」的文档
- 解决的痛点
- 普通向量检索只能靠语义匹配,没法处理数值、范围、分类筛选;
- 自查询检索结合「向量语义 + 元数据结构化过滤」,
- 适合带明确限制条件的场景(价格、评分、时间、类别)。
- 关键特点
- 依靠 LLM 理解并生成过滤语法
- 向量做模糊语义,元数据做精准硬规则
- 大幅减少手动写过滤代码,天然适合知识库、商品、影视等带字段数据的RAG
应用
利用多向量搜索的假设问题方式,帮助大模型回答关于时事(高考)的问题。
1.3 Agent
- Chains:固定硬编码的动作执行序列,流程、步骤写死在代码里,按既定顺序跑 LLM、检索、函数调用。
- Agents:靠LLM 自主推理,动态从工具集合里自选动作、自定执行顺序,流程不写死,由模型实时决策。
Agents
结构化Agents
支持function call的LLM可通过接收tools参数原生生成工具调用格式,而LangChain的结构化Agent则不依赖该能力,它通过设计包含工具说明与固定输出格式的提示词,引导不支持function call的LLM按指定文本格式(如Action: 工具名, Action Input: 参数)输出工具调用指令,再由框架解析文本并执行工具,从而让无原生工具能力的模型也能实现Agent效果。