【动手学深度学习】8.4. 循环神经网络
本节参考《动手学深度学习》第二版(PyTorch)8.4节,介绍循环神经网络的基本概念、隐状态机制以及基于RNN的字符级语言模型和困惑度评估。
nnn元语法模型中,xtx_txt的条件概率仅取决于前n−1n-1n−1个单词。增加nnn会导致参数量呈指数增长(∣V∣n|\mathcal{V}|^n∣V∣n)。
使用隐变量模型替代:
P(xt∣xt−1,...,x1)≈P(xt∣ht−1).(8.4.1)P(x_t \mid x_{t-1}, \ldots, x_1) \approx P(x_t \mid h_{t-1}). \tag{8.4.1}P(xt∣xt−1,...,x1)≈P(xt∣ht−1).(8.4.1)
其中ht−1h_{t-1}ht−1为隐状态 (hidden state),存储到时间步t−1t-1t−1的序列信息。隐状态计算:
ht=f(xt,ht−1).(8.4.2)h_t = f(x_{t}, h_{t-1}). \tag{8.4.2}ht=f(xt,ht−1).(8.4.2)
隐藏层 与隐状态的区别:
- 隐藏层:从输入到输出路径上隐藏的层(观测角度)
- 隐状态:通过先前时间步数据计算的输入(技术角度)
循环神经网络(RNNs)是具有隐状态的神经网络。
8.4. 循环神经网络
1)无隐状态的神经网络
单隐藏层多层感知机,设激活函数为ϕ\phiϕ,小批量样本X∈Rn×d\mathbf{X} \in \mathbb{R}^{n \times d}X∈Rn×d,隐藏层输出H∈Rn×h\mathbf{H} \in \mathbb{R}^{n \times h}H∈Rn×h:
H=ϕ(XWxh+bh).(8.4.3)\mathbf{H} = \phi(\mathbf{X} \mathbf{W}_{xh} + \mathbf{b}_h). \tag{8.4.3}H=ϕ(XWxh+bh).(8.4.3)
其中Wxh∈Rd×h\mathbf{W}_{xh} \in \mathbb{R}^{d \times h}Wxh∈Rd×h,bh∈R1×h\mathbf{b}_h \in \mathbb{R}^{1 \times h}bh∈R1×h,hhh为隐藏单元数。
输出层:
O=HWhq+bq,\mathbf{O} = \mathbf{H} \mathbf{W}_{hq} + \mathbf{b}_q,O=HWhq+bq,
其中O∈Rn×q\mathbf{O} \in \mathbb{R}^{n \times q}O∈Rn×q,Whq∈Rh×q\mathbf{W}_{hq} \in \mathbb{R}^{h \times q}Whq∈Rh×q,bq∈R1×q\mathbf{b}_q \in \mathbb{R}^{1 \times q}bq∈R1×q。分类问题用softmax(O)\text{softmax}(\mathbf{O})softmax(O)计算概率分布。
2)有隐状态的循环神经网络
时间步ttt的输入Xt∈Rn×d\mathbf{X}_t \in \mathbb{R}^{n \times d}Xt∈Rn×d,隐藏变量Ht∈Rn×h\mathbf{H}t \in \mathbb{R}^{n \times h}Ht∈Rn×h。引入权重参数Whh∈Rh×h\mathbf{W}{hh} \in \mathbb{R}^{h \times h}Whh∈Rh×h描述如何使用前一时间步的隐藏变量。
当前时间步隐藏变量计算:
Ht=ϕ(XtWxh+Ht−1Whh+bh).(8.4.4)\mathbf{H}t = \phi(\mathbf{X}t \mathbf{W}{xh} + \mathbf{H}{t-1} \mathbf{W}_{hh} + \mathbf{b}_h). \tag{8.4.4}Ht=ϕ(XtWxh+Ht−1Whh+bh).(8.4.4)
相比(8.4.3),(8.4.4)新增Ht−1Whh\mathbf{H}{t-1} \mathbf{W}{hh}Ht−1Whh项,实例化了(8.4.2)。隐状态捕获并保留序列直到当前时间步的历史信息。
(8.4.4)的计算是循环的 ,基于循环计算的隐状态神经网络称为循环神经网络 。执行(8.4.4)的层称为循环层。
时间步ttt的输出:
Ot=HtWhq+bq.\mathbf{O}_t = \mathbf{H}t \mathbf{W}{hq} + \mathbf{b}_q.Ot=HtWhq+bq.
循环神经网络的参数:
- 隐藏层权重Wxh∈Rd×h\mathbf{W}{xh} \in \mathbb{R}^{d \times h}Wxh∈Rd×h、Whh∈Rh×h\mathbf{W}{hh} \in \mathbb{R}^{h \times h}Whh∈Rh×h和偏置bh∈R1×h\mathbf{b}_h \in \mathbb{R}^{1 \times h}bh∈R1×h
- 输出层权重Whq∈Rh×q\mathbf{W}_{hq} \in \mathbb{R}^{h \times q}Whq∈Rh×q和偏置bq∈R1×q\mathbf{b}_q \in \mathbb{R}^{1 \times q}bq∈R1×q
关键优势: 不同时间步使用相同参数,参数开销不随时间步增加而增加。
图8.4.1展示三个相邻时间步的计算逻辑。时间步ttt的隐状态计算:
- 拼接当前输入Xt\mathbf{X}tXt和前一时间步隐状态Ht−1\mathbf{H}{t-1}Ht−1
- 送入带激活函数ϕ\phiϕ的全连接层,输出Ht\mathbf{H}_tHt
Ht\mathbf{H}tHt参与计算Ht+1\mathbf{H}{t+1}Ht+1,并送入输出层计算Ot\mathbf{O}_tOt。
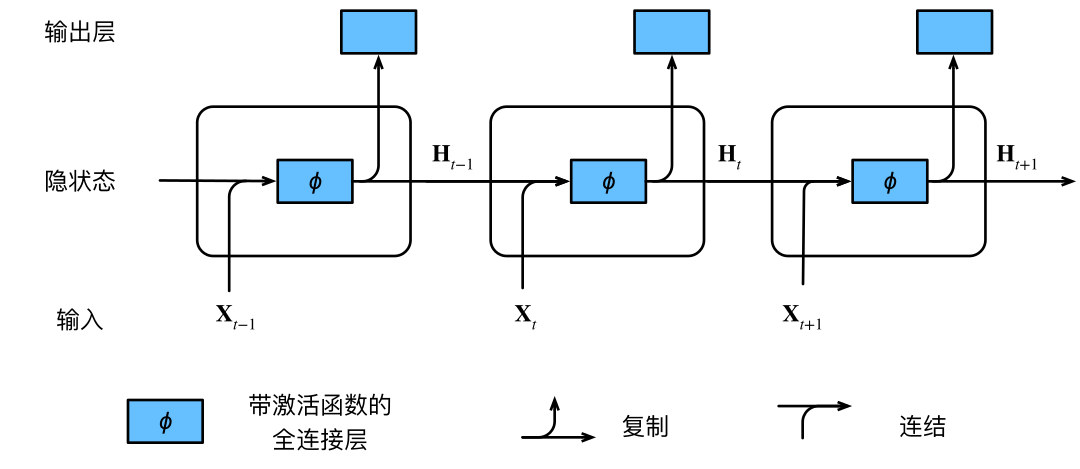
图8.4.1 具有隐状态的循环神经网络。
XtWxh+Ht−1Whh\mathbf{X}t \mathbf{W}{xh} + \mathbf{H}{t-1} \mathbf{W}{hh}XtWxh+Ht−1Whh等价于拼接后相乘:
python
from d2l import torch as d2l
import torch
# 定义矩阵及其形状
X, W_xh = d2l.normal(0, 1, (3, 1)), d2l.normal(0, 1, (1, 4))
H, W_hh = d2l.normal(0, 1, (3, 4)), d2l.normal(0, 1, (4, 4))
# 方法一:分别相乘再相加
result1 = d2l.matmul(X, W_xh) + d2l.matmul(H, W_hh)
print("结果形状:", result1.shape)
# 方法二:先拼接再相乘(等价)
result2 = d2l.matmul(d2l.concat((X, H), 1), d2l.concat((W_xh, W_hh), 0))
print("结果形状:", result2.shape)两种方法等价 ,后者实现更简洁,是PyTorch中torch.nn.RNN等模块的内部做法。
3)基于循环神经网络的字符级语言模型
语言模型目标:根据过去和当前词元预测下一个词元,将原始序列移位一个词元作为标签。
使用字符级语言模型 ,将文本词元化为字符。图8.4.2演示如何使用循环神经网络预测下一个字符。
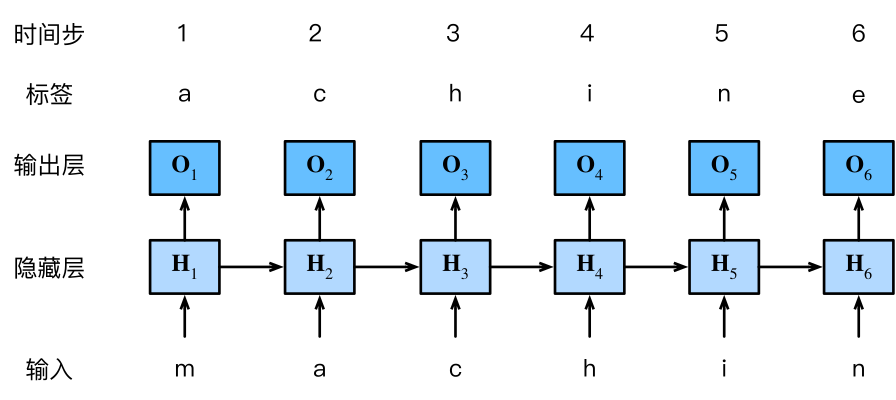
图8.4.2 基于循环神经网络的字符级语言模型。 输入序列和标签序列分别为"machin"和"achine"。
训练时,对每个时间步输出进行softmax,用交叉熵损失计算误差。第3个时间步输出O3\mathbf{O}_3O3由"m""a""c"确定,标签为"h",损失取决于基于"m""a""c"生成的下一个字符概率分布。
实践中批量大小为n>1n>1n>1,每个词元用ddd维向量表示,时间步ttt输入Xt\mathbf{X}_tXt为n×dn \times dn×d矩阵。
4)困惑度(Perplexity)
度量语言模型质量。通过计算序列的似然概率,使用交叉熵损失的平均值:
1n∑t=1n−logP(xt∣xt−1,...,x1).(8.4.5)\frac{1}{n} \sum_{t=1}^n -\log P(x_t \mid x_{t-1}, \ldots, x_1). \tag{8.4.5}n1t=1∑n−logP(xt∣xt−1,...,x1).(8.4.5)
其中PPP由语言模型给出,xtx_txt为时间步ttt观察到的实际词元。
困惑度(perplexity)为(8.4.5)的指数:
exp(−1n∑t=1nlogP(xt∣xt−1,...,x1)).(8.4.6)\exp\left(-\frac{1}{n} \sum_{t=1}^n \log P(x_t \mid x_{t-1}, \ldots, x_1)\right). \tag{8.4.6}exp(−n1t=1∑nlogP(xt∣xt−1,...,x1)).(8.4.6)
困惑度特性:
- 最好情况 :模型完美估计标签词元概率为1,困惑度为1
- 最坏情况 :模型预测标签词元概率为0,困惑度为正无穷大
- 基线情况 :模型预测为词表均匀分布,困惑度等于词表中唯一词元数量
困惑度越低,模型越好。
5)小结
- 对隐状态使用循环计算的神经网络称为循环神经网络(RNN)
- 循环神经网络的隐状态可以捕获直到当前时间步序列的历史信息
- 循环神经网络模型的参数数量不会随着时间步的增加而增加
- 可以使用循环神经网络创建字符级语言模型
- 可以使用困惑度来评价语言模型的质量,困惑度越低,预测越准确