20260422《013师幼互动》风格:CG动画
背景需求:
之前做了非32种风格的"唐卡"和"浮世绘",感觉不是很理想。
还是继续测试32种风格的模型。


改成文字生成脚本
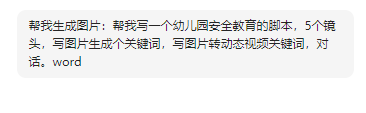



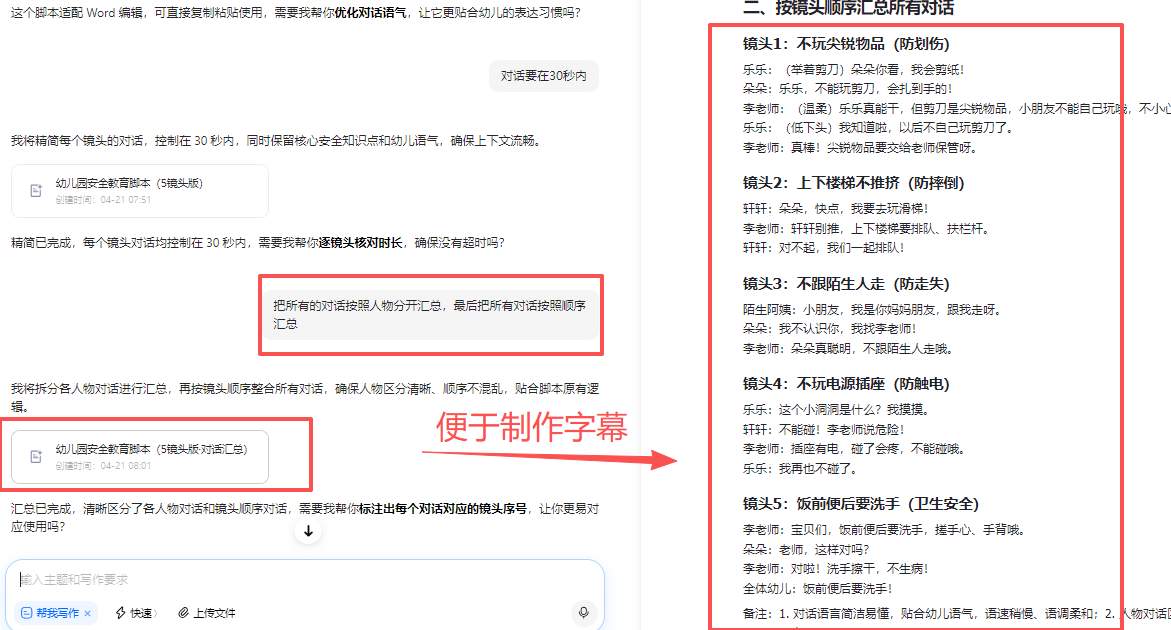
图片生成











楼梯推人这个图片很难做到我满意的效果
视频生成
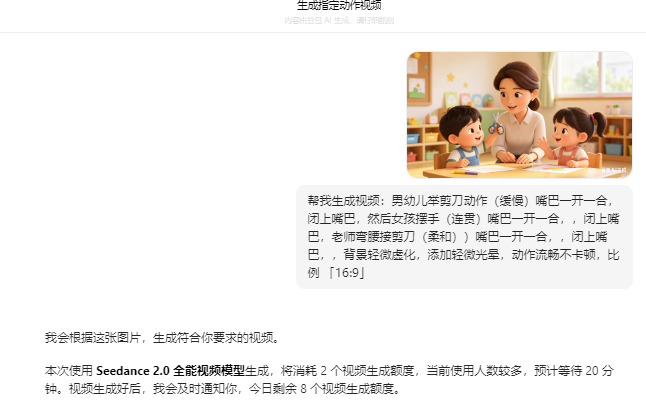


最后只生成了三个视频

还有两个视频无论如何也做不出,不知道是内容关键词(推人、陌生人)还是图片的问题




由于只有三个视频共30秒,所以我就放弃这个《校园安全》的主题
重新做CG故事绘本
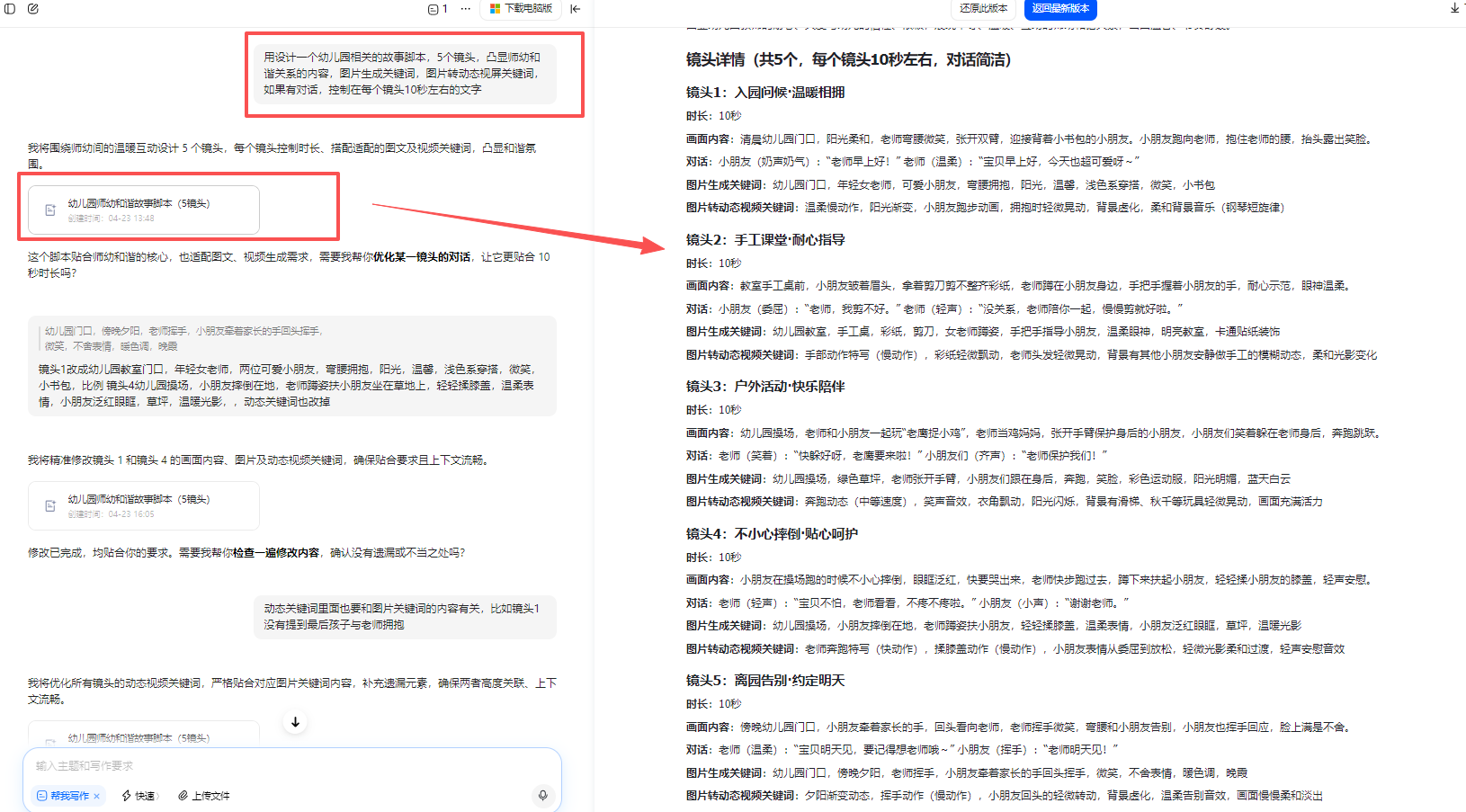
图片生成




有些图片看不出师幼互动的动作,手动修改关键词


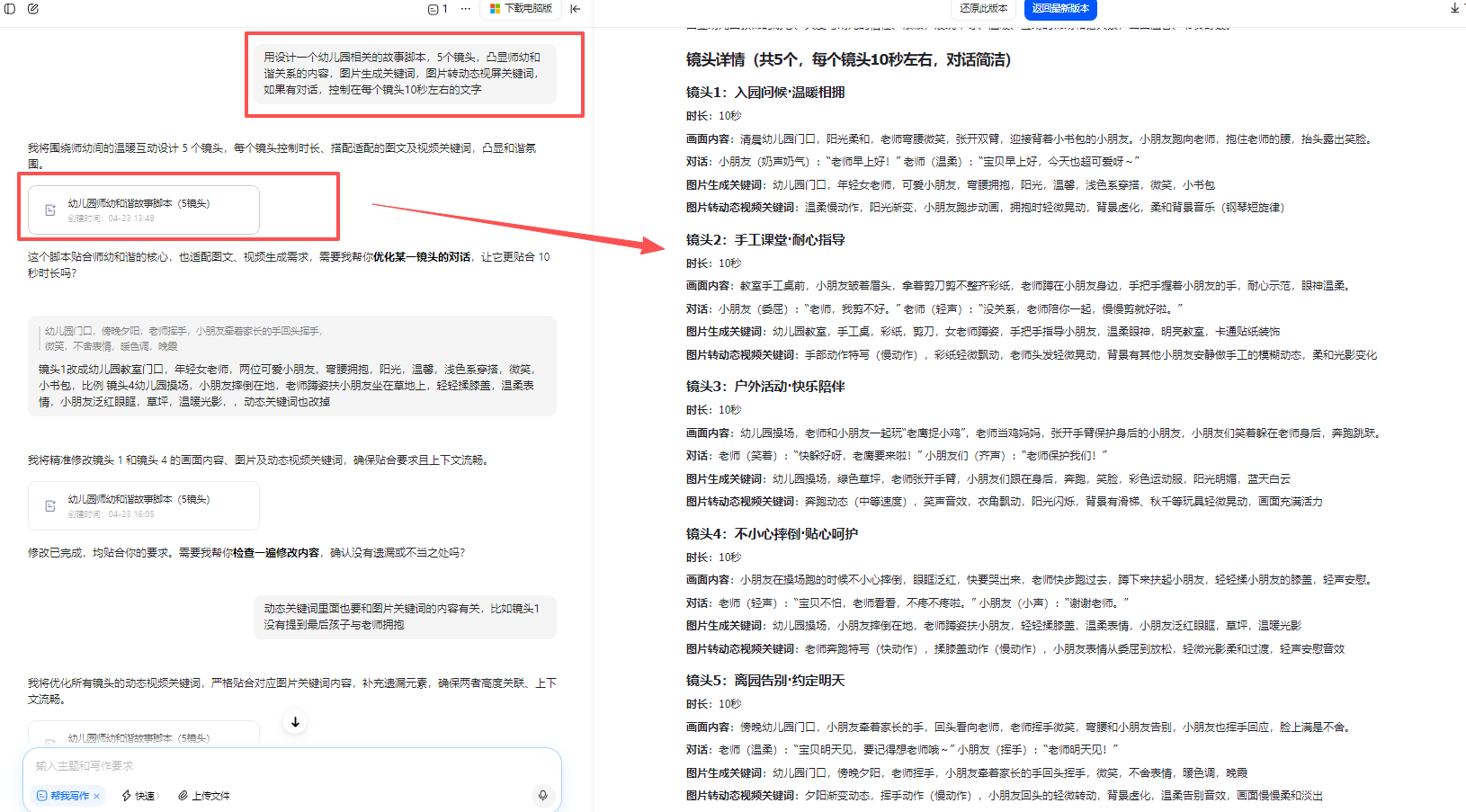

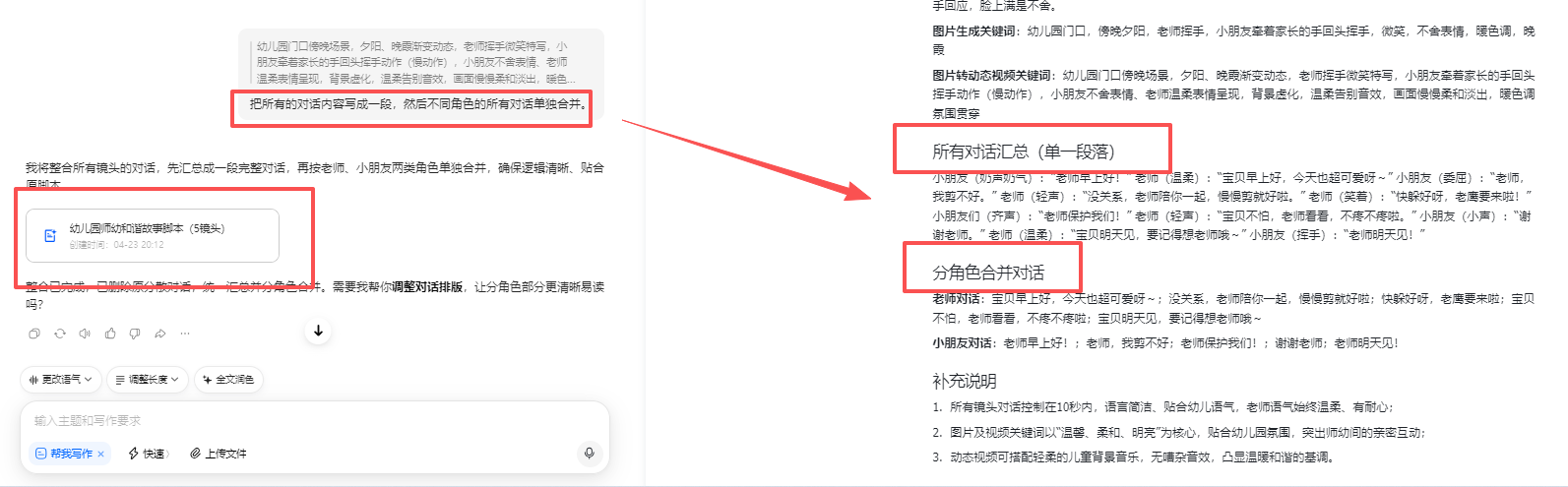


下载图片
有些图片生成不了视频,就选4图中的另外1张做测试(所以镜头2会有3张测试、镜头4有2张做测试,明明都是差不多的图片,就是会有一些图片无法视频化,换一张差不多的图片就可以)
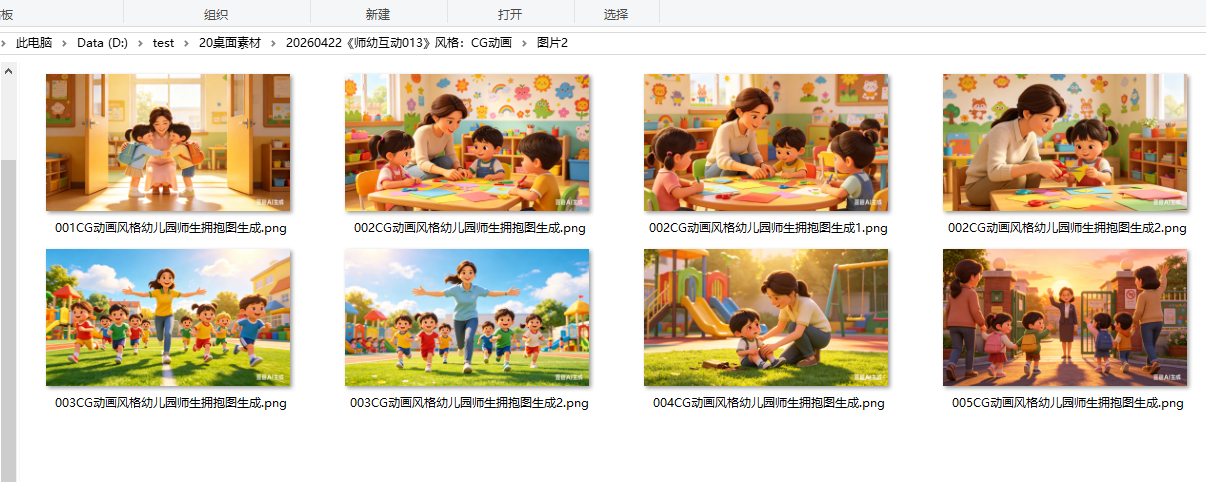




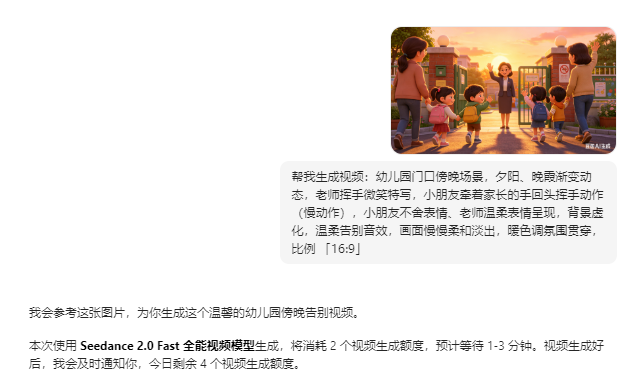







最后选了这五张
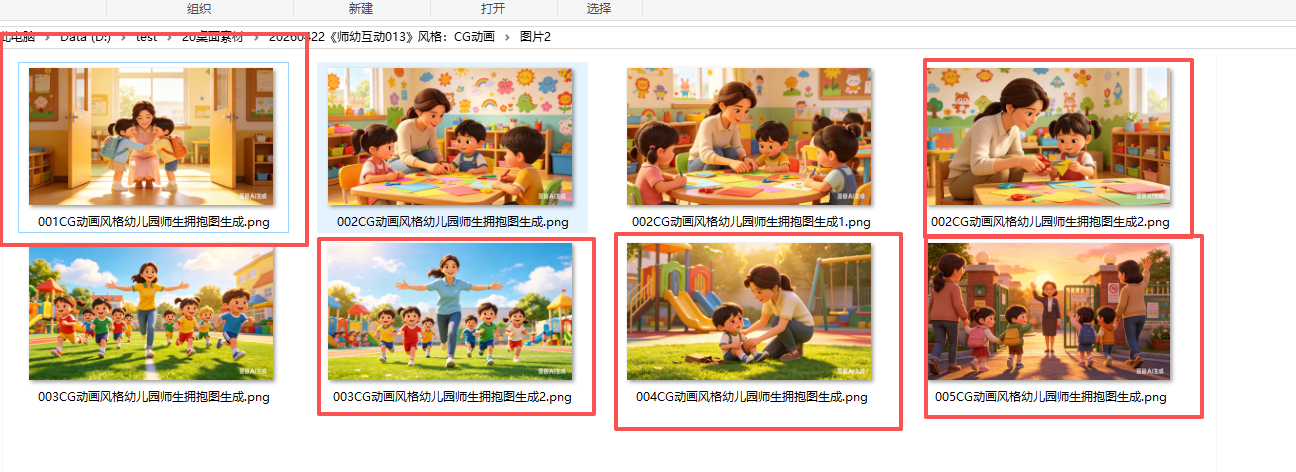
视频下载
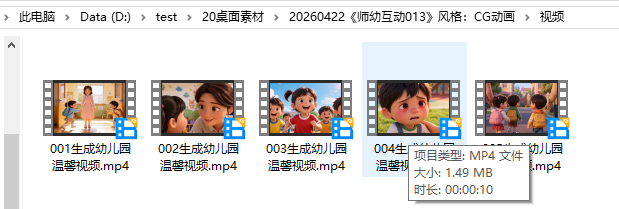




音频制作
python
# 老师的声音
from pathlib import Path
import edge_tts
import asyncio
# 教师常用台词(可改成你要的文本)
TEXT = "宝贝早上好,今天也超可爱呀~;没关系,老师陪你一起,慢慢画,你一定行!;快躲好呀,老鹰要来啦;宝贝不怕,老师看看,不疼不疼啦;宝贝明天见,早点来幼儿园哦~"
# 保存路径
# SAVE_DIR = Path(r"C:\Users\jg2yXRZ\OneDrive\桌面\20260409豆包AI幼儿吵架\mp3")
SAVE_DIR = Path(r"D:\test\20桌面素材\20260422《幼儿园安全013》风格:CG动画/声音")
SAVE_DIR.mkdir(parents=True, exist_ok=True)
# 温柔女教师音色(2种风格)
TEACHER_VOICES = [
# ("zh-CN-XiaoxiaoNeural", f"{TEXT}_晓晓.mp3"),
("zh-CN-XiaoyiNeural", f"{TEXT}_老师 晓伊.mp3"),
]
async def generate_teacher_voice():
for voice, filename in TEACHER_VOICES:
out = SAVE_DIR / filename
tts = edge_tts.Communicate(
TEXT, voice,
rate="-30%", # 温柔慢一点
pitch="-5Hz", # 更温柔
volume="+15%" # 清晰
)
await tts.save(str(out))
print(f"✅ 已生成:{filename}")
await asyncio.sleep(0.5)
if __name__ == "__main__":
asyncio.run(generate_teacher_voice())
print("\n🎉 温柔女教师声音生成完成!")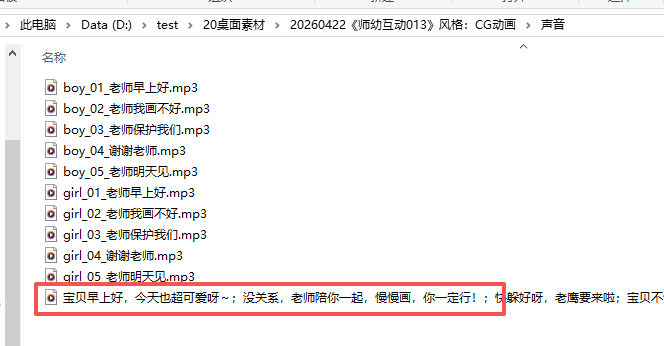
python
from pathlib import Path
import edge_tts
import asyncio
import os
# ==================== 配置区域 ====================
SAVE_DIR = r"D:\test\20桌面素材\20260422《幼儿园安全013》风格:CG动画\声音"
os.makedirs(SAVE_DIR, exist_ok=True)
# 女孩的句子列表(用分号分隔)
GIRL_TEXTS = [
"老师早上好!",
"老师,我画不好",
"老师保护我们!",
"谢谢老师",
"老师明天见!"
]
# 男孩的句子列表
BOY_TEXTS = [
"老师早上好!",
"老师,我画不好",
"老师保护我们!",
"谢谢老师",
"老师明天见!"
]
# ==================== 音色配置 ====================
# 女孩配置(3-4岁小女孩)
GIRL_CONFIG = {
"voice": "zh-CN-XiaoxiaoNeural", # 最尖最小女孩
"rate": "+0%", # 超快,急切
"pitch": "+20Hz", # 尖锐
"volume": "+40%"
}
# 男孩配置(3-4岁小男孩)
BOY_CONFIG = {
"voice": "zh-CN-YunxiaNeural", # 最小男孩
"rate": "+0%", # 快、急
"volume": "+25%",
"pitch": "+12Hz" # 超奶
}
# ==================== 核心函数 ====================
async def text_to_speech(text, config, output_path):
"""将文本转换为语音"""
communicate = edge_tts.Communicate(
text,
config["voice"],
rate=config["rate"],
volume=config["volume"],
pitch=config["pitch"]
)
await communicate.save(str(output_path))
return output_path
async def generate_girl_audios():
"""生成所有女孩音频"""
print("\n🎀 开始生成女孩音频...")
results = []
for i, text in enumerate(GIRL_TEXTS, 1):
# 清理文件名中的特殊字符
safe_text = text.replace("!", "").replace("?", "").replace(";", "").replace(",", "").replace("!", "")
filename = f"girl_{i:02d}_{safe_text}.mp3"
output_path = os.path.join(SAVE_DIR, filename)
print(f" 生成中 ({i}/{len(GIRL_TEXTS)}): {text}")
await text_to_speech(text, GIRL_CONFIG, output_path)
results.append(output_path)
print(f" ✅ 已完成: {filename}")
return results
async def generate_boy_audios():
"""生成所有男孩音频"""
print("\n🦸 开始生成男孩音频...")
results = []
for i, text in enumerate(BOY_TEXTS, 1):
# 清理文件名中的特殊字符
safe_text = text.replace("!", "").replace("?", "").replace(";", "").replace(",", "").replace("!", "")
filename = f"boy_{i:02d}_{safe_text}.mp3"
output_path = os.path.join(SAVE_DIR, filename)
print(f" 生成中 ({i}/{len(BOY_TEXTS)}): {text}")
await text_to_speech(text, BOY_CONFIG, output_path)
results.append(output_path)
print(f" ✅ 已完成: {filename}")
return results
async def generate_all():
"""生成所有音频"""
print("=" * 50)
print("🎤 幼儿AI对话音频生成器")
print("=" * 50)
print(f"📁 保存路径: {SAVE_DIR}")
# 生成女孩音频
girl_files = await generate_girl_audios()
# 生成男孩音频
boy_files = await generate_boy_audios()
# 汇总结果
print("\n" + "=" * 50)
print(f"✨ 全部生成完成!共 {len(girl_files) + len(boy_files)} 个文件")
print(f"🎀 女孩音频: {len(girl_files)} 个")
print(f"🦸 男孩音频: {len(boy_files)} 个")
print(f"📁 保存在: {SAVE_DIR}")
print("=" * 50)
return girl_files + boy_files
# ==================== 单独生成函数(可选)====================
async def generate_single_girl(text):
"""生成单个女孩音频(自定义文本)"""
safe_text = text.replace("!", "").replace("?", "")
filename = f"girl_custom_{safe_text}.mp3"
output_path = os.path.join(SAVE_DIR, filename)
await text_to_speech(text, GIRL_CONFIG, output_path)
print(f"✅ 女孩音频已生成: {filename}")
return output_path
async def generate_single_boy(text):
"""生成单个男孩音频(自定义文本)"""
safe_text = text.replace("!", "").replace("?", "")
filename = f"boy_custom_{safe_text}.mp3"
output_path = os.path.join(SAVE_DIR, filename)
await text_to_speech(text, BOY_CONFIG, output_path)
print(f"✅ 男孩音频已生成: {filename}")
return output_path
# ==================== 主程序 ====================
if __name__ == "__main__":
# 方式1:批量生成所有预设音频
asyncio.run(generate_all())
# 方式2:如果需要生成自定义文本,可以取消下面的注释
# 生成单个自定义女孩音频示例
# asyncio.run(generate_single_girl("老师,我想上厕所"))
# 生成单个自定义男孩音频示例
# asyncio.run(generate_single_boy("让我先玩"))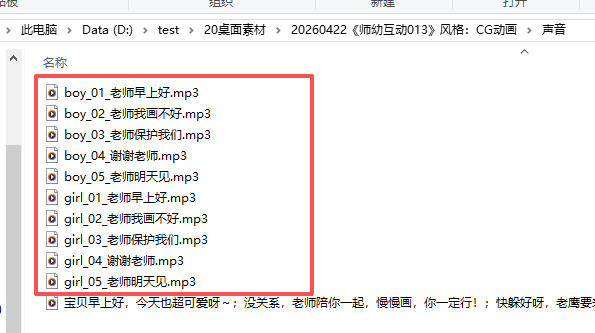
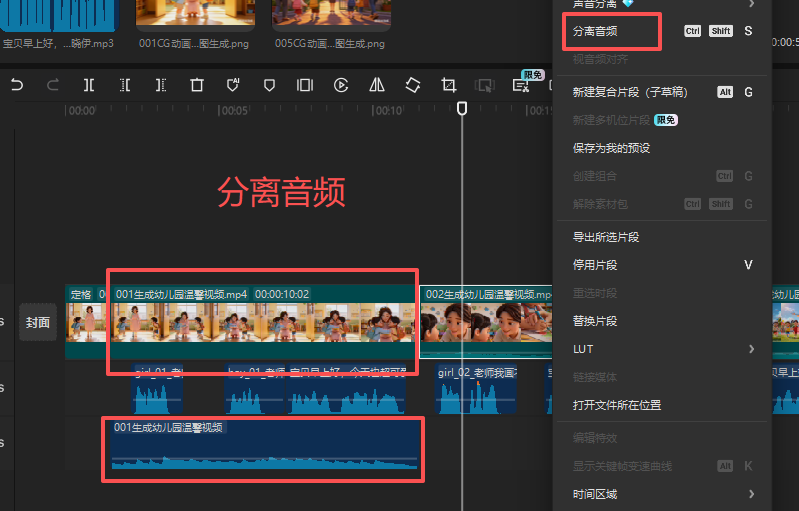
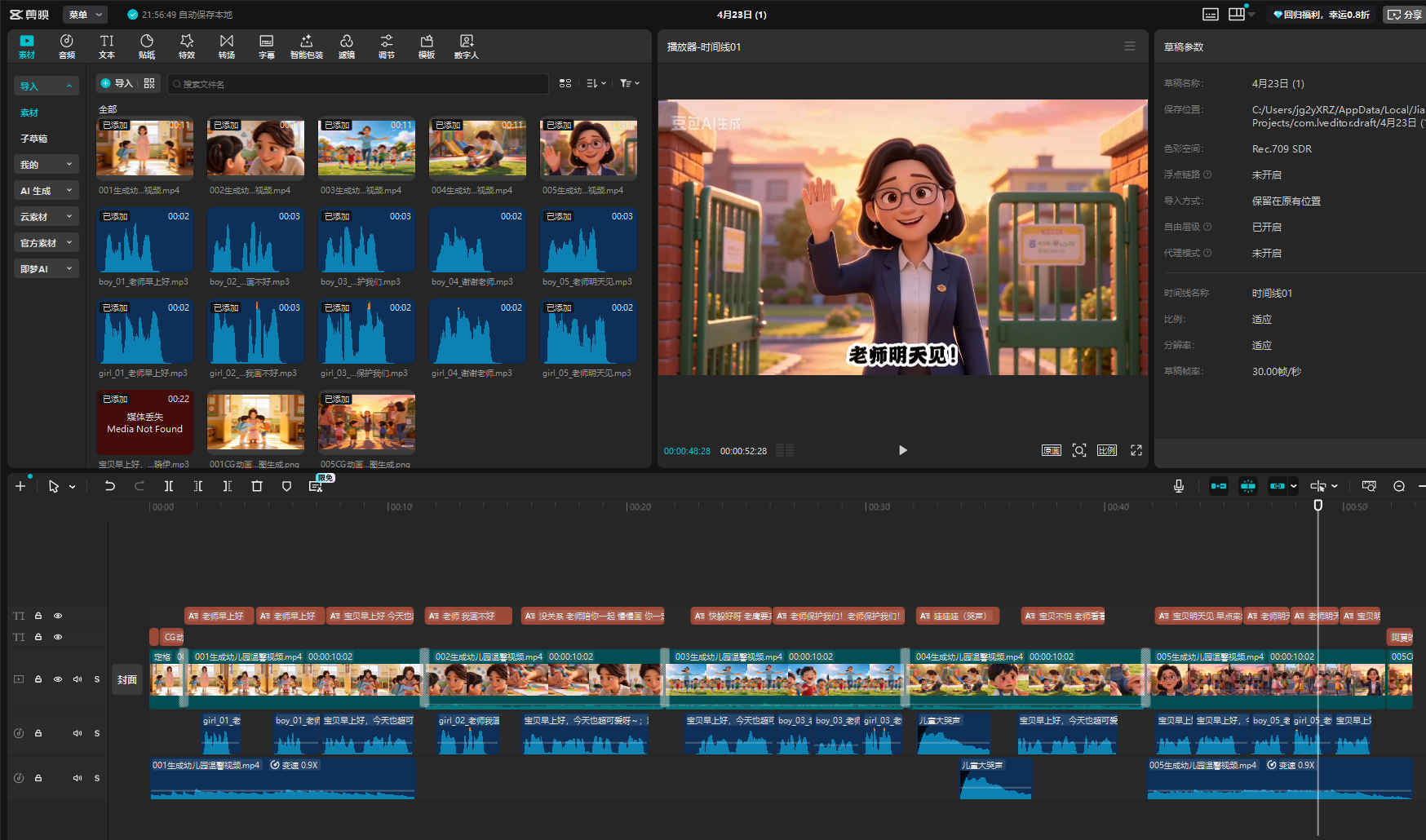
视频合成(剪映)
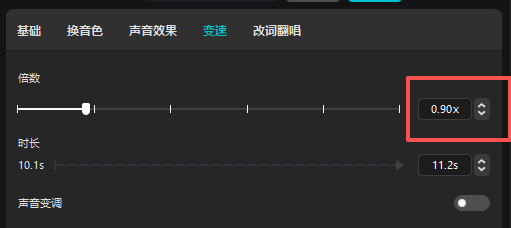
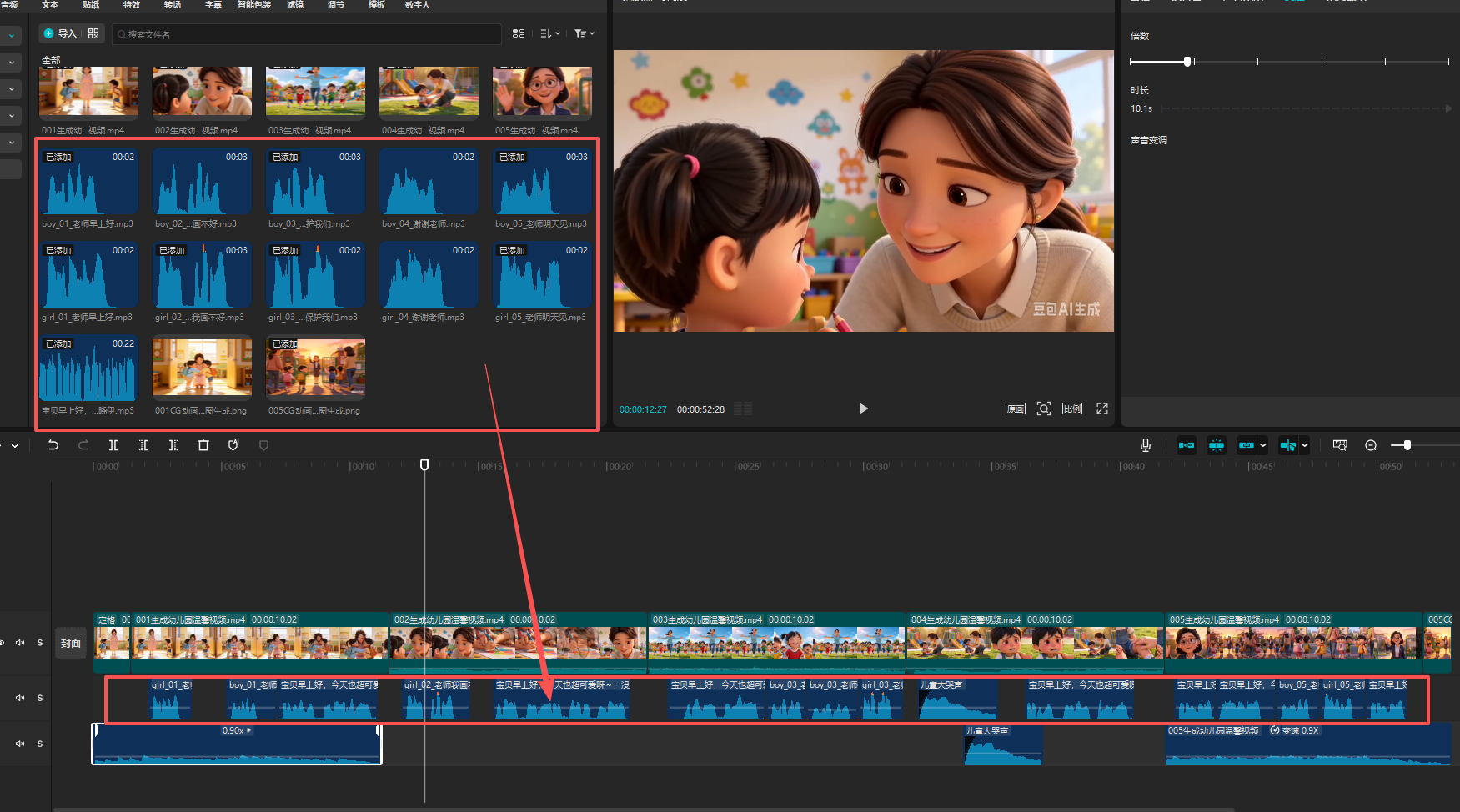
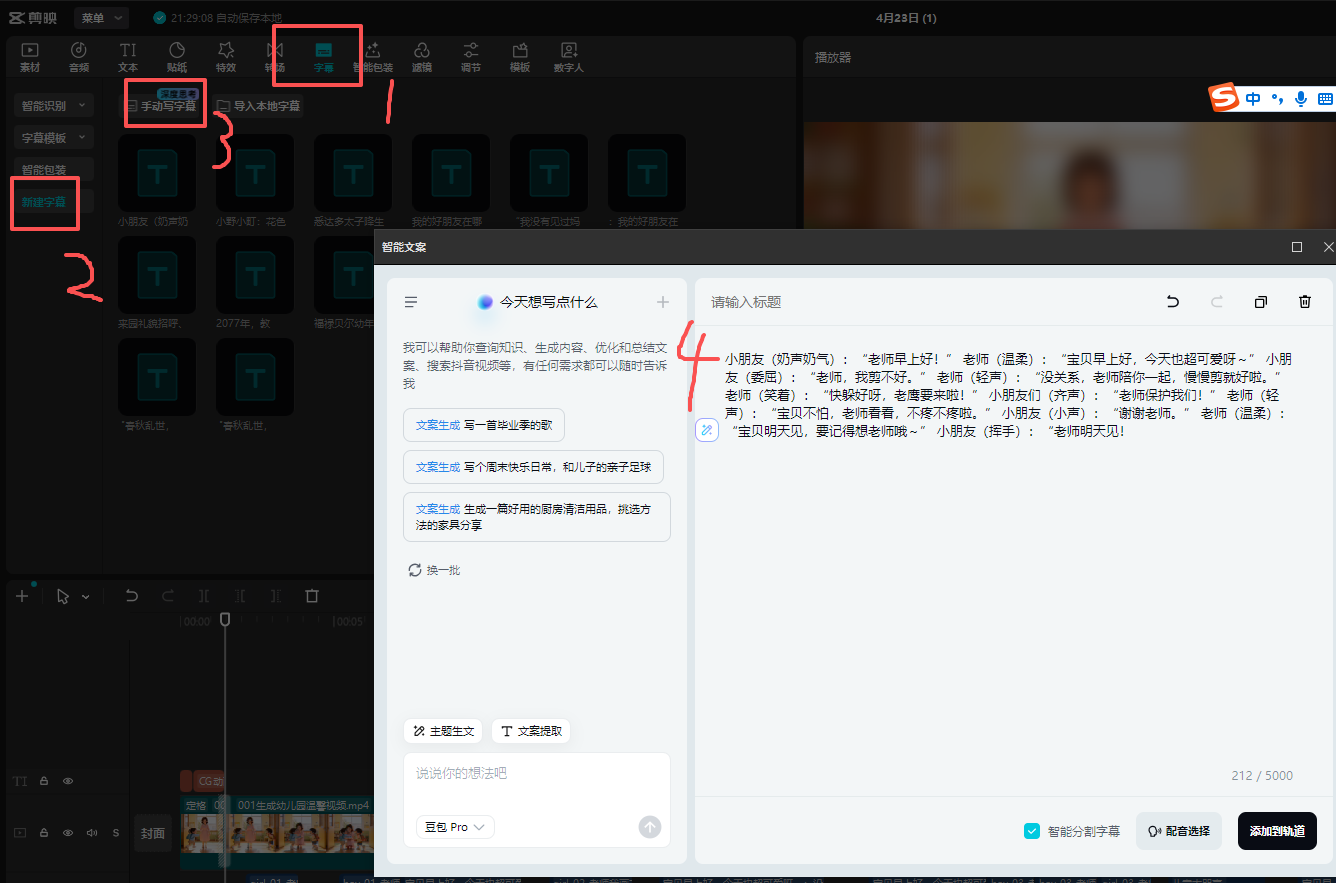
字幕制作
复制字幕文字

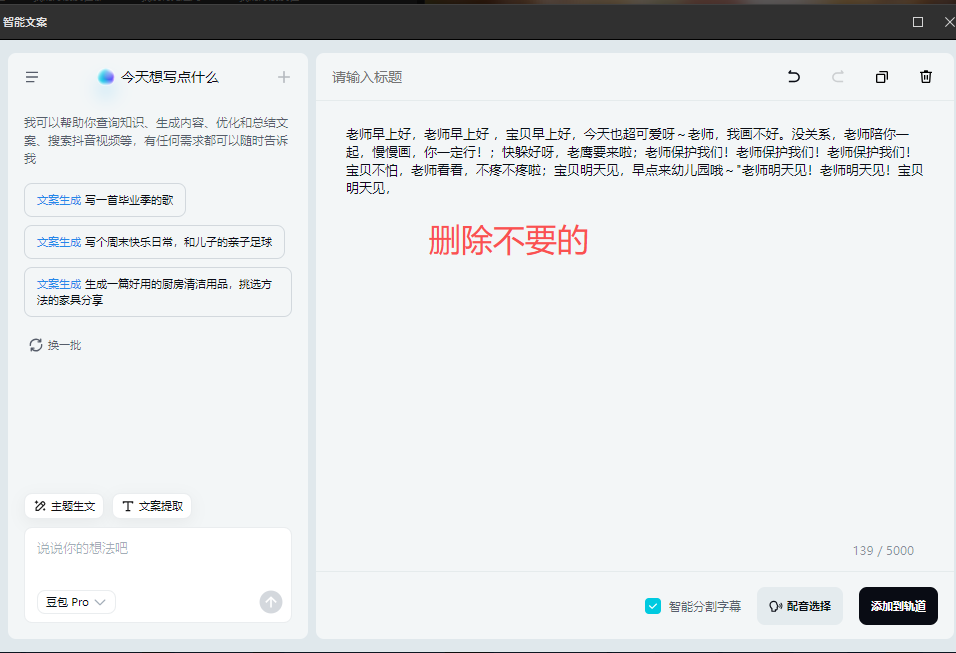
把对应的音频、字幕贴入,
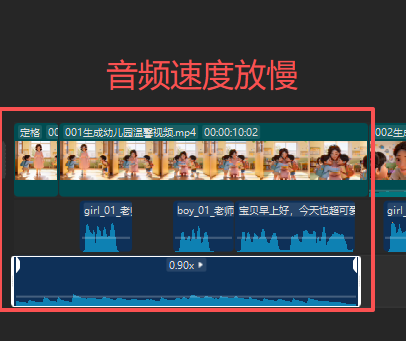
只做了男幼儿、女幼儿声音,如果有很多孩子,就把声音拉长或缩短。做成其他音频
20260422《013师幼互动》风格:CG动画