题目:VMamba: Visual State Space Model
论文链接:https://arxiv.org/pdf/2401.10166
核心贡献: 提出了 SS2D (Selective Scan in State Space Model) 机制,解决了 SSM 在视觉任务中的应用难题。
关键词: Mamba, SSM, 线性复杂度, 全局建模
1. Abstract
现有的视觉主干网络主要分为两类:卷积神经网络(CNN)和视觉Transformer(ViT)。CNN 具有线性计算复杂度,但受限于局部感受野;ViT 拥有全局感受野,但其自注意力机制(Self-Attention)的计算复杂度随分辨率呈二次方增长,难以处理高分辨率图像。本文提出了 VMamba ,一种基于状态空间模型(SSM)的视觉主干网络。VMamba 通过引入 二维选择性扫描 (SS2D) 机制,成功将 SSM 扩展到了视觉领域。实验表明,VMamba 在图像分类、目标检测和语义分割任务上均优于同量级的 Swin Transformer,且在高分辨率输入下具有显著的效率优势。
2. motivation
背景: 在视觉识别任务中,捕捉长距离依赖(Long-range Dependencies)至关重要。虽然 ViT 通过自注意力机制解决了这个问题,但其计算成本过高。
痛点: 状态空间模型(如 Mamba)在语言领域表现出色,因为它具有选择性状态(Selective State)机制,能根据输入调整参数,且计算效率高。然而,直接将一维的 SSM 应用于二维图像会面临两个主要挑战:
- 空间结构丢失: 一维扫描破坏了图像的二维结构。
- 方向性缺失: 图像具有四个方向(上下左右),单一方向的扫描无法捕捉完整的全局信息。
动机: 作者旨在设计一种既能保留 SSM 线性复杂度优势,又能适应图像二维特性的新架构。
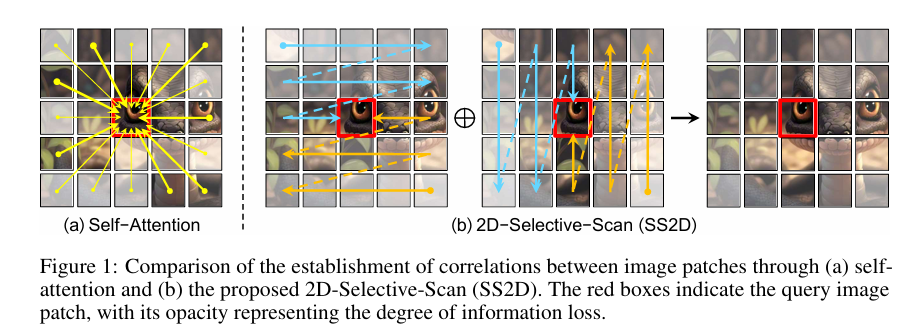
3. Methods
这是论文最核心的部分,作者提出了 SS2D (Selective Scan in 2D) 模块,这是 VMamba 的心脏。
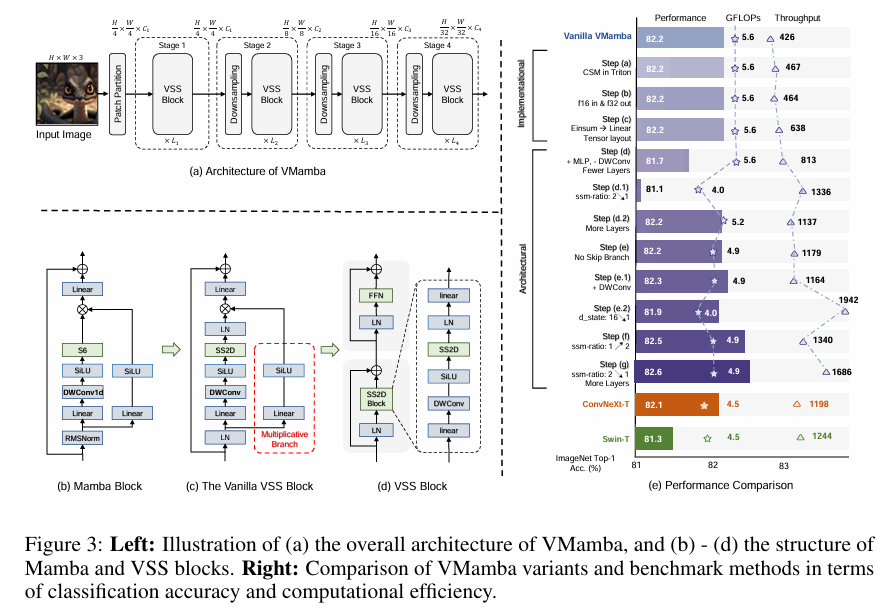
3.1 整体架构 (Architecture Overview)
VMamba 遵循分层架构(类似 ConvNets 和 Swin Transformer),包含四个阶段(Stage),随着网络加深,特征图分辨率降低,通道数增加。核心组件是 VSS Block ,其中包含了 SS2D 模块。
3.2 二维选择性扫描 (SS2D)
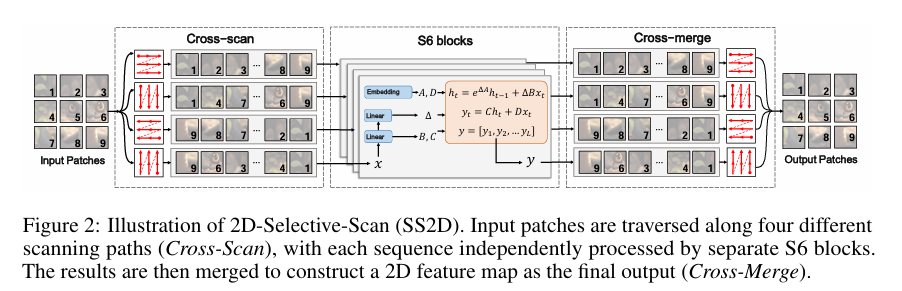
这是 VMamba 解决视觉任务的核心机制,包含三个步骤:
-
步骤一:投影 (Projection)
输入特征 xxx 首先被线性投影为三部分:用于计算的 xprojx_{proj}xproj,以及用于控制状态的 xBxBxB 和 xAxAxA。
-
步骤二:选择性扫描 (Selective Scan)
这是 Mamba 的核心。与传统的 SSM(如 HiPPO)不同,Mamba 的参数 AAA 和 BBB 是根据当前输入 xxx 动态计算的(即 xAxAxA 和 xBxBxB)。这使得模型具有选择性 ,能根据输入内容过滤无关信息,非常适合视觉任务中的复杂背景。
dhdt=Ax(t)+Bx(t) \frac{dh}{dt} = Ax(t) + Bx(t) dtdh=Ax(t)+Bx(t)
y(t)=Ch(t) y(t) = Ch(t) y(t)=Ch(t) -
步骤三:混合扫描机制 (Mixed Scan Mechanism)
为了解决"二维结构"问题,VMamba 没有直接使用一维扫描,而是采用了双向/多向扫描策略:
- 双向扫描: 对特征图进行正向(从左到右、从上到下)和反向(从右到左、从下到上)扫描。
- 特征融合: 将两个方向的扫描结果进行融合。这确保了模型在每一个位置都能获得完整的全局上下文信息,而不会因为扫描顺序导致信息丢失。
3.3 复杂度分析
得益于 SSM 的特性,VMamba 的计算复杂度与输入分辨率呈线性关系 O(N)O(N)O(N),而 Transformer 是 O(N2)O(N^2)O(N2)。这意味着在处理高分辨率图像(如 1024x1024)时,VMamba 的速度优势将成倍放大。
4. Experiments
作者在多个主流视觉任务上验证了 VMamba 的有效性:
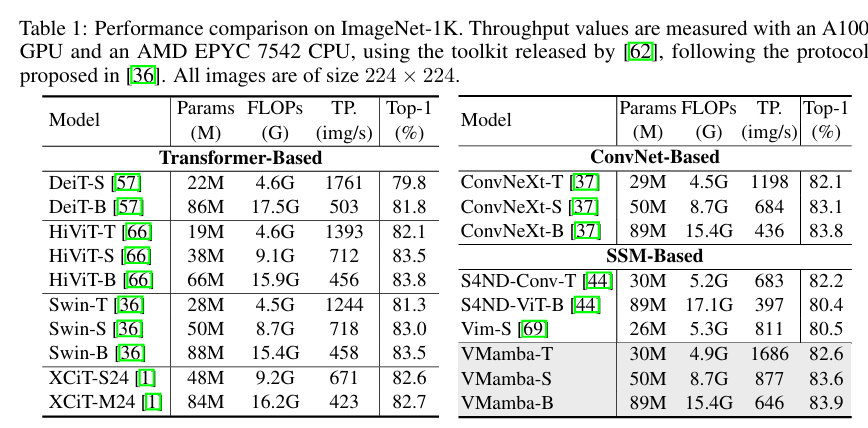
- 图像分类 (ImageNet-1K): 在同等参数量下,VMamba 的 Top-1 准确率超过了 Swin Transformer,且推理速度更快。
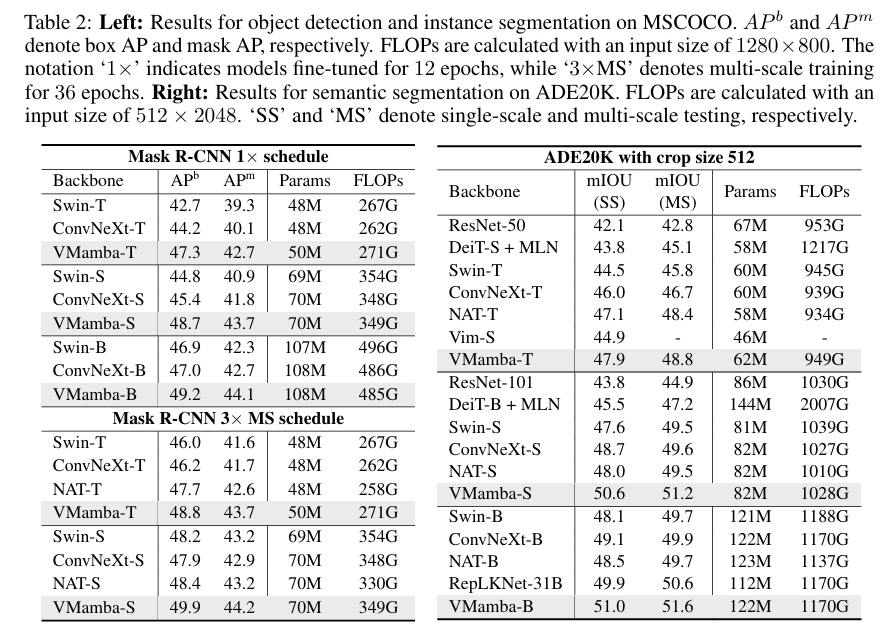
- 目标检测 (COCO): 作为检测器的骨干网络(Backbone),VMamba 在 Faster R-CNN 和 Mask R-CNN 框架下均取得了比 Swin 更高的 mAP 分数。
- 语义分割 (ADE20K): 在高分辨率的分割任务中,VMamba 的优势最为明显,证明了其在捕捉长距离依赖方面的能力。
关键发现: 随着输入图像尺寸的增加,VMamba 相比 Transformer 的速度优势愈发显著,证明了其在处理高分辨率视觉数据方面的巨大潜力。
5. 结论 (Conclusion)
VMamba 成功地将状态空间模型(SSM)引入了计算机视觉领域。通过提出的 SS2D 模块,它巧妙地解决了将一维序列模型应用于二维图像时的空间结构保持问题。VMamba 不仅在性能上媲美甚至超越了先进的 Transformer 模型,更重要的是,它实现了线性计算复杂度。这为构建高效、可扩展的视觉基础模型提供了一个全新的范式。
💡 核心方法论总结
| 核心组件 | 作用 | 解决的问题 |
|---|---|---|
| SSM (状态空间模型) | 核心计算单元 | 提供线性计算复杂度,替代二次方复杂度的 Attention。 |
| 选择性机制 (Selective) | 动态参数 A,BA, BA,B | 使模型能根据输入内容过滤噪声,具备非线性建模能力(传统 SSM 是线性的)。 |
| 双向扫描 (Bidirectional Scan) | 多方向特征提取 | 解决了图像二维结构在序列化过程中的信息丢失问题,捕捉全局上下文。 |
希望这篇对 VMamba 的深度解析能帮助你理解这一视觉领域的重要里程碑!