文章目录
- 一.前言
- 二.核心技术&知识
-
- 1.PyQt5
- 2.YOLOv8
- 3.DeepSeek
- 4.Sqlite3
- 5.多线程
- 6.钢材焊接缺陷检测的意义
-
- [1. 保障结构安全性与工程可靠性](#1. 保障结构安全性与工程可靠性)
- [2. 提升产品质量与一致性水平](#2. 提升产品质量与一致性水平)
- [3. 降低生产成本与减少资源浪费](#3. 降低生产成本与减少资源浪费)
- [4. 推动制造业智能化与数字化升级](#4. 推动制造业智能化与数字化升级)
- 三.核心功能
- 四.数据集
- 五.关于项目
- 六.总结
本系统功能强大!支持对图片、视频、视频流、摄像头中的钢材焊接缺陷:包含月牙弯、折痕、丝斑、水斑、焊缝、异物、油斑、压痕、冲孔、咬折、其他,进行检测,支持多种数据数据源输入并且接入了AI实现了对当前分析结果的评估,欢迎了解!
@项目名称:基于PyQt+YOLO+DeepSeek的钢材焊接缺陷检检测系统
@仓库名称:yolov8-welding-defect-detect
@作者:懷淰メ
@主页地址:https://blog.csdn.net/a1397852386
@定制:A1397852386
@开发日期:2026年4月
关键字:#系统 #钢材焊接缺陷检测 #PyQt5 #YOLOv8 #DeepSeek #图像检测 #视频检测 #AI分析 #Sqlite3 #多线程 #数据集 #模型训练 #可视化 #登录注册 #历史数据 #系统设置 #缺陷类别 #月牙弯 #折痕 #丝斑 #水斑 #焊缝 #异物 #油斑 #压痕 #冲孔 #咬折 #其他
一.前言
在工业制造领域,焊接质量直接影响产品的安全性与可靠性。然而,在实际生产过程中,焊接表面常出现多种复杂缺陷,如月牙弯、折痕、丝斑、水斑、焊缝异常、异物附着、油斑污染、压痕、冲孔、咬折以及其他不规则缺陷。这些问题不仅依赖人工检测,效率低且易受主观因素影响,难以满足现代智能制造对高精度与高一致性的需求。
基于此,构建一套融合PyQt5界面开发、YOLOv8目标检测算法与DeepSeek智能分析能力的焊接表面缺陷检测系统具有重要意义。该系统通过高效的视觉识别模型,实现对多类别缺陷的快速定位与分类,同时借助友好的图形界面提升操作体验,并结合智能分析模块进行结果优化与辅助决策。
该系统的应用不仅能够显著提升检测效率与准确率,降低人工成本,还可推动生产过程向自动化、数字化与智能化升级,对于提升产品质量、减少返工率及增强企业竞争力具有重要的现实价值和广阔的应用前景。
二.核心技术&知识
在这章我将要介绍本系统的核心技术。
1.PyQt5
PyQt5 是一套用于创建跨平台桌面应用程序的 Python GUI 工具包,它是 Qt 应用框架的 Python 绑定。通过 PyQt5,开发者可以使用 Python 编写具有现代图形界面的应用程序,支持丰富的控件、信号与槽机制、窗口管理、事件处理等功能。它兼容主流操作系统(如 Windows、macOS 和 Linux),适用于开发各种规模的桌面软件,常与 Qt Designer 配合使用以加快开发效率。

2.YOLOv8
YOLOv8(You Only Look Once version 8)是由 Ultralytics 推出的最新一代实时目标检测模型,属于 YOLO 系列的改进版本。相比前代模型,YOLOv8 在精度、速度和灵活性上都有显著提升,支持目标检测、图像分割、姿态估计等多任务处理。它采用了更加高效的网络结构和训练策略,并提供开箱即用的 Python 接口和命令行工具,适用于边缘设备和云端部署,广泛应用于安防监控、自动驾驶、工业检测等场景。

3.DeepSeek
DeepSeek是由深度求索公司开发的AI大模型助手,作为纯文本模型,我擅长自然语言处理、文档分析和智能对话。当与YOLO(You Only Look Once)实时目标检测系统结合时,可以形成强大的多模态应用架构------YOLO系统负责实时视觉识别和目标检测,快速准确地识别图像或视频流中的物体;而我则对YOLO检测到的结果进行深度语义分析和上下文理解,提供物体属性的详细解读、场景描述、行为分析以及决策建议。这种结合使得计算机视觉的"看到"与AI的"理解"完美融合,可广泛应用于智能监控、自动驾驶、工业质检等领域,实现从视觉感知到智能决策的完整闭环。

4.Sqlite3
本系统使用Sqlite3进行数据的存储与管理。
SQLite3是一种轻量级的嵌入式关系型数据库管理系统,广泛应用于桌面软件、移动应用以及各类嵌入式设备中。与传统的客户端-服务器数据库(如MySQL、PostgreSQL)不同,SQLite3无需独立的数据库服务器进程,整个数据库以单一文件形式存储在本地,应用程序可直接通过库文件进行读写操作。这种架构使其具有部署简单、占用资源少、跨平台性强等显著优势。SQLite3遵循ACID事务特性,能够保证数据的一致性与可靠性,同时支持标准SQL语法,包括表的创建、查询、索引、触发器等常见功能,能够满足中小规模数据管理需求。在性能方面,SQLite3在读操作上表现高效,并通过锁机制实现多线程环境下的基本并发控制。由于其零配置特性和稳定性,SQLite3被广泛集成于Android、iOS等操作系统中,也常用于缓存数据存储、本地日志管理以及离线数据处理等场景。总体而言,SQLite3以其简洁高效的设计理念,在轻量级数据管理领域占据了重要地位。

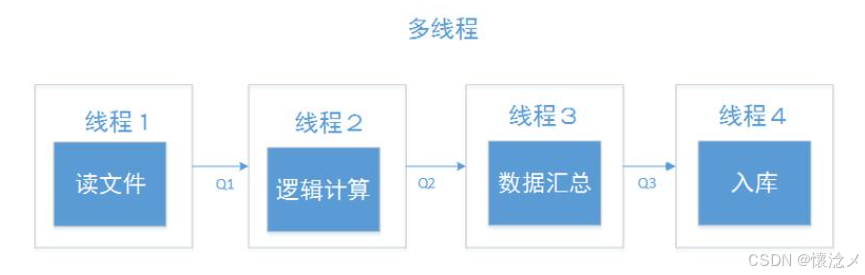
5.多线程
QThread 是 PyQt5 提供的线程类,主要用于在图形界面程序中安全、高效地执行耗时任务,从而避免主线程阻塞导致界面卡顿或无响应的问题。在典型的GUI应用中,界面渲染与用户交互通常运行在主线程,一旦在该线程中直接执行诸如数据处理、深度学习模型推理、视频流分析或文件读写等耗时操作,就容易造成界面冻结,严重影响用户体验。QThread 的引入正是为了解决这一问题。
通过 QThread,开发者可以将这些计算密集型或IO密集型任务封装到子线程中独立运行,使主线程专注于界面更新与交互响应。同时,QThread 提供了基于信号与槽机制的线程间通信方式,能够在不同线程之间安全地传递数据与状态信息。例如,子线程在完成检测或处理任务后,可以通过发送信号将结果传递给主线程,由主线程负责更新界面控件,从而避免直接跨线程操作UI带来的风险。
此外,QThread 还支持线程的生命周期管理,包括启动、暂停、退出以及资源回收等,使得多线程程序结构更加清晰可控。合理使用 QThread 不仅可以显著提升应用程序的响应速度和运行效率,还能增强系统的稳定性与扩展能力。在涉及实时数据处理、视频监控或智能分析等复杂桌面应用开发场景中,QThread 已成为不可或缺的重要工具。
6.钢材焊接缺陷检测的意义
下面从多个角度分点说明"钢材焊接缺陷检测的意义",每点均为较完整阐述:
1. 保障结构安全性与工程可靠性
钢材焊接广泛应用于桥梁、建筑、压力容器、船舶及轨道交通等关键工程领域,这些结构通常承受复杂载荷和长期服役环境。一旦焊接区域存在月牙弯、咬折、折痕或未焊透等缺陷,极易在应力集中作用下引发裂纹扩展,进而导致结构失效甚至灾难性事故。因此,对焊接缺陷进行系统性检测,是确保整体结构安全性的核心环节。通过科学、精准的检测手段,可以在早期识别潜在风险,避免缺陷在服役过程中被放大,从源头上降低安全隐患。这不仅关系到设备本身的寿命,也直接影响人员生命安全和公共基础设施的稳定运行,是工业生产中不可忽视的基础保障。
2. 提升产品质量与一致性水平
在现代制造业中,产品质量的稳定性与一致性是企业核心竞争力的重要体现。焊接作为关键工艺,其质量波动会直接影响最终产品性能。传统依赖人工经验的检测方式容易受到疲劳、主观判断和技术水平差异的影响,难以实现标准化控制。而系统化的缺陷检测能够对丝斑、水斑、油斑、压痕、异物等多种细微缺陷进行统一识别与量化评估,从而形成可追溯的质量数据体系。这种标准化检测机制有助于企业建立稳定的质量控制流程,减少批次间差异,提高产品一致性。同时,通过对缺陷数据的统计分析,还可以反向优化焊接工艺参数,实现质量的持续改进。
3. 降低生产成本与减少资源浪费
焊接缺陷如果未能在早期被发现,往往会在后续工序甚至交付后暴露问题,导致返工、报废甚至召回,带来高昂的经济损失。尤其是在大型钢结构制造中,材料成本和加工成本占比较高,一次严重缺陷可能意味着整件产品作废。通过高效的缺陷检测手段,可以在生产早期及时识别问题,如冲孔偏差、焊缝异常或咬折等,从而快速进行修复或调整工艺,避免问题扩大。这种"前移质量控制"的方式能够显著减少不必要的资源浪费,提高原材料利用率。同时,自动化检测还能减少对大量人工检测的依赖,降低人力成本,实现整体生产效率与经济效益的双重提升。
4. 推动制造业智能化与数字化升级
随着工业4.0和智能制造的发展,传统制造模式正向数字化、自动化和智能化转型。焊接缺陷检测作为质量控制的重要环节,也逐渐从人工目检向基于视觉与人工智能的自动检测转变。通过引入先进检测技术,可以实现对多类型缺陷(如月牙弯、折痕、异物、油斑等)的实时识别与数据记录,并与生产系统进行联动,形成完整的数据闭环。这不仅提高了检测效率,还为企业积累了大量有价值的生产数据,可用于后续分析与决策支持。例如,通过缺陷分布分析,可以优化设备参数、改进工艺流程,甚至实现预测性维护。这种转变对于提升企业技术水平、增强市场竞争力具有深远意义,也是制造业迈向高端化的重要标志。
三.核心功能
1.登录注册
1.登录
软件启动后首先进入登录页面,用户需要输入正确的用户名和密码,经过系统验证后方可使用本系统的正式功能。登录页面整体采用垂直布局,使信息层次清晰、结构简洁,同时在局部区域辅以水平布局,以提升界面的灵活性与可读性。整体设计风格遵循"简约而不简单"的原则,在保证视觉美观的同时,也兼顾操作的直观性与易用性。
在功能实现方面,登录模块的后端采用sqlite3文件型数据库来存储用户信息,包括用户名、密码及相关基础数据。每次用户发起登录请求时,系统都会通过查询数据库进行身份校验,确保输入信息的准确性与安全性,从而实现规范化、标准化的登录流程。
同时,我们设计了统一风格的登录与注册界面,用于展示系统与用户交互所需的全部组件。界面顶部以醒目的标题形式展示系统名称,增强整体识别度与专业性。通过合理布局输入框、按钮及提示信息,使用户在使用过程中能够快速理解操作步骤,从而提升整体使用体验。
2.注册
对于尚未拥有账号的用户,需要先完成注册操作后才能使用系统功能。整体注册流程设计得较为简洁直观,用户只需在登录界面点击"注册"按钮,即可快速跳转至注册窗口,无需复杂的页面切换或额外步骤。在注册界面中,用户需要填写自定义的用户名,并输入两次一致的密码以完成身份信息的确认。这种双重密码输入机制可以有效避免因输入错误而导致的登录失败问题,从而提升系统的可靠性与用户体验。
在用户成功完成注册后,系统还提供了一项便捷的优化设计:自动将刚刚注册的用户名和密码填充到登录界面中。用户无需再次手动输入信息,即可直接进行登录操作。这一设计在一定程度上简化了登录流程路径,减少了重复操作,提高了整体使用效率。同时,该功能也体现了系统在交互细节上的人性化考虑,使用户在首次使用时能够获得更加顺畅和友好的体验。
2.主界面
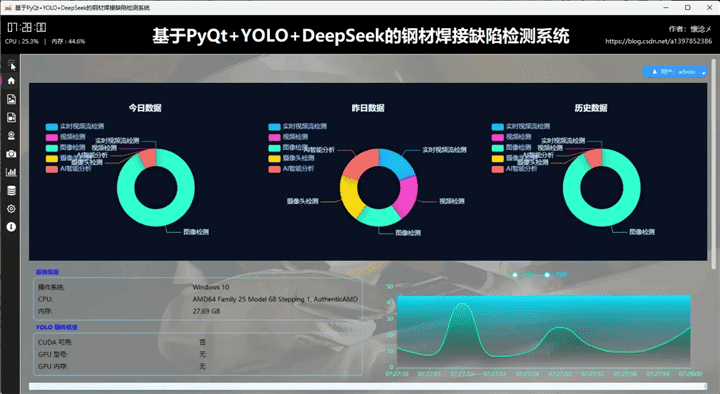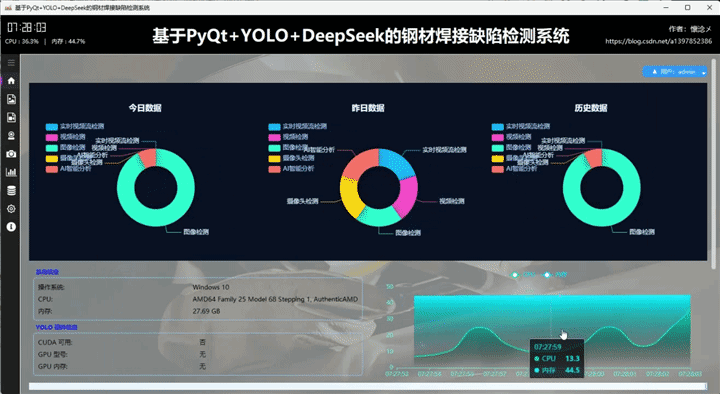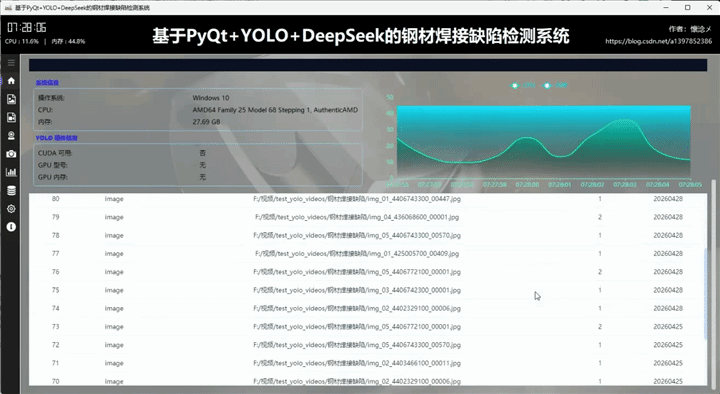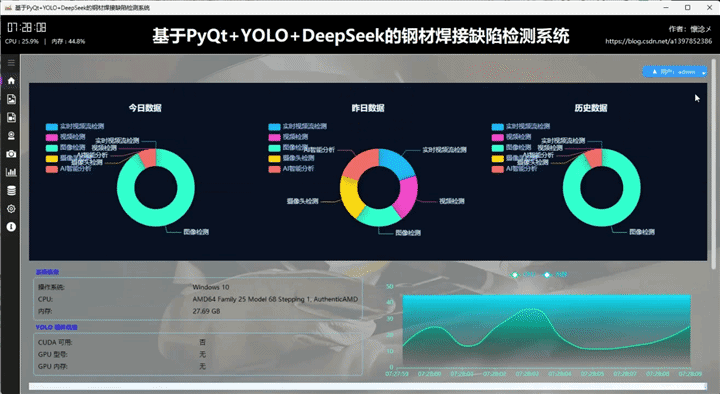
用户通过输入自己的用户名和密码登录到本系统后进入主界面,主界面内容十分丰富,我来一一介绍:首先软件整体是垂直布局,顶部是系统的标题,从左到右依次展示了系统的作者信息、系统名称、当前时间以及CPU内存占用情况,下方为水平布局,左侧是系统的导航区域,我们设计了windows风格支持展开与收缩的内容导航区域,右侧是内容核心区域,通过点击导航按钮切换展示内容,主界面主要展示了以日期为维度统计的数据、用户信息操作按钮、系统信息、系统环境信息以及实时CPU、内存可视化折线图
3.图像检测界面
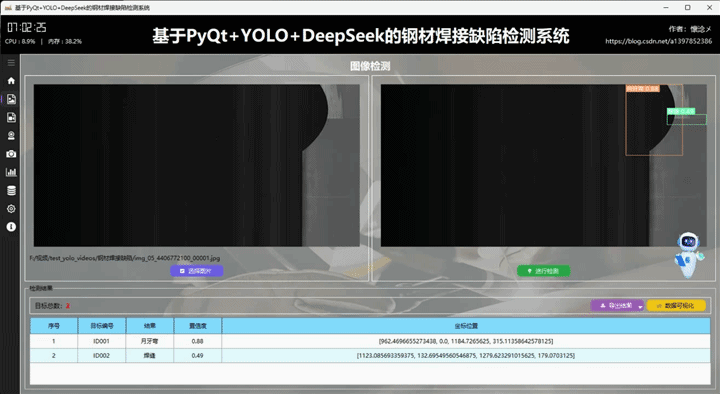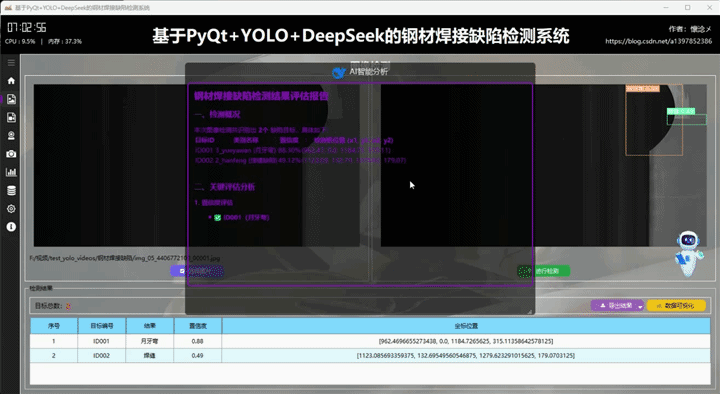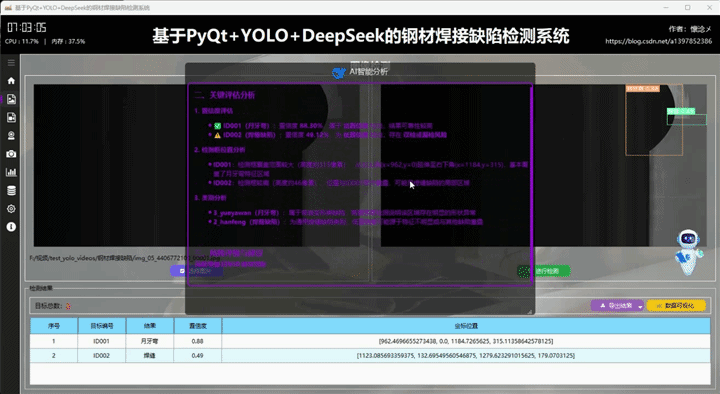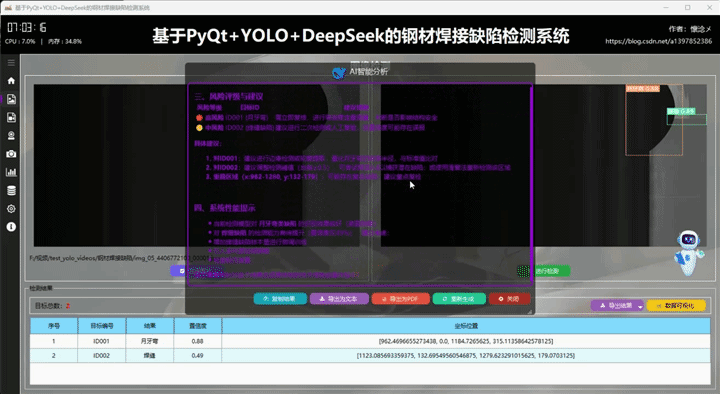
1.检测结果展示
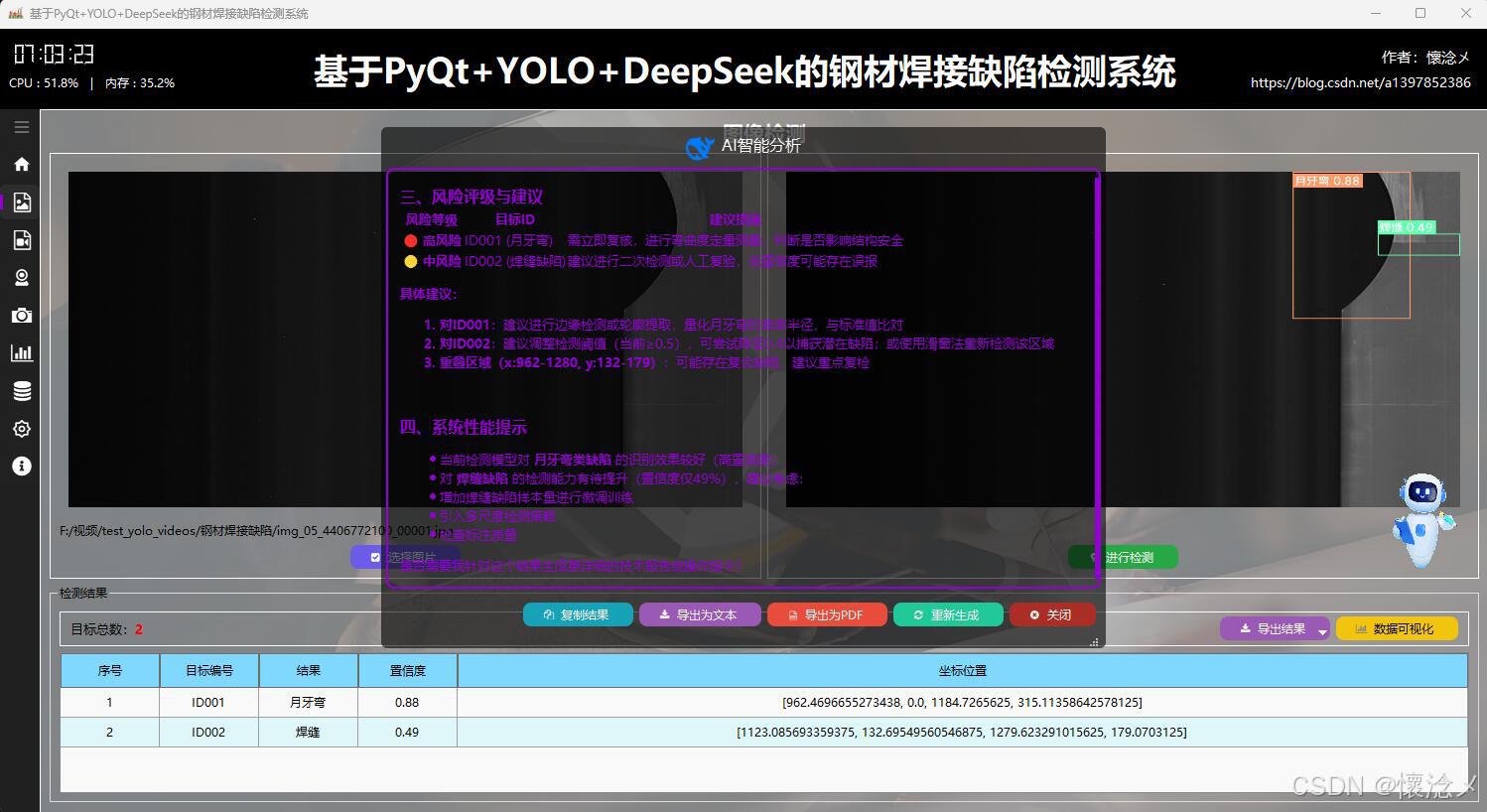
用户通过点击左侧导航栏按钮切换到图像检测界面,在此界面支持选择图像进行输入,用户选择完之后被选择的图像会展示在左侧并且展示图像绝对路径信息,用户可以通过点击右侧的"进行检测"按钮对输入的图像数据进行检测,系统会自动调用YOLOv8相关算法根据指定的参数对输入图像内容进行检测,最后将检测结果展示到右侧,这样用户可以通过比对左右图像的区别得到直观的检测结果,系统自动使用红色边框框选出目标区域并且使用红色文字展示出目标类别以及它的置信度,这些参数和展示效果都可以在设置页面进行详细设置。
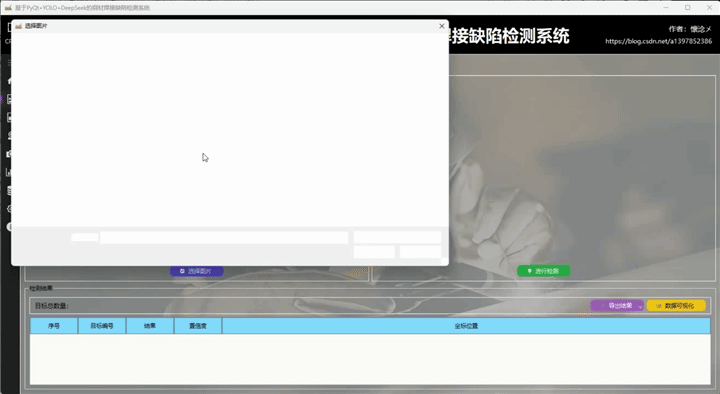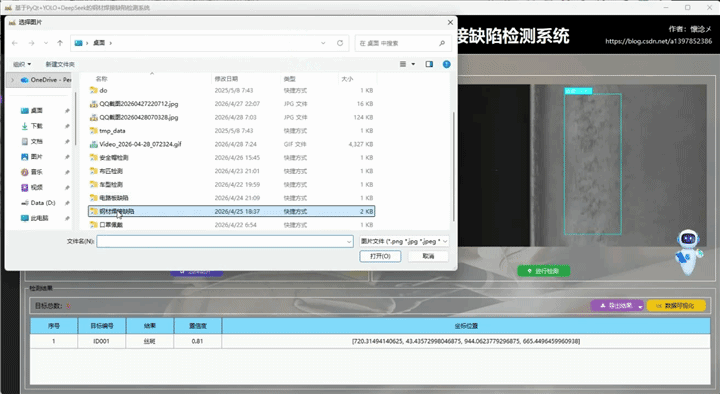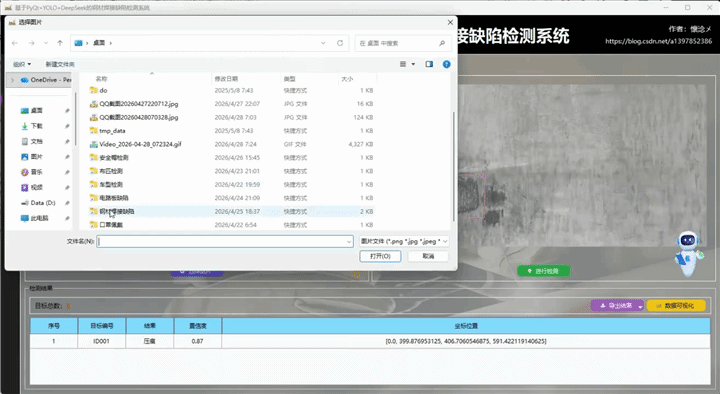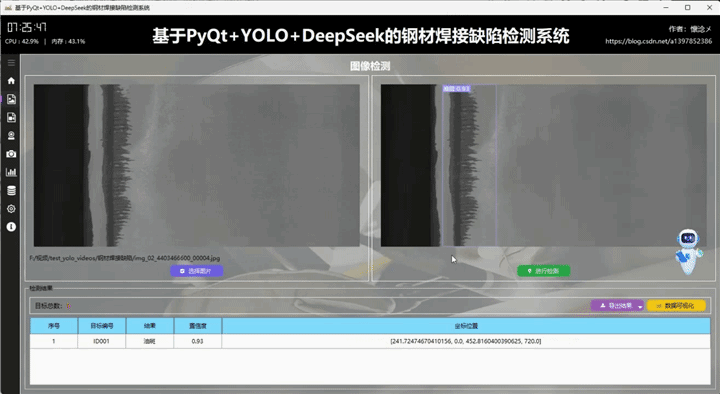
2.导出检测结果
我们在界面中专门设置了检测结果展示区域,用于集中呈现系统输出的信息。该区域不仅包含检测目标数量的统计展示,还提供了结构清晰的详细检测结果表格。通过这种方式,用户可以直观地查看每一条检测数据,包括目标类别、置信度以及对应位置信息等内容,从而更全面地了解检测情况。整体布局兼顾信息密度与可读性,使数据展示既完整又不显杂乱。
此外,在检测任务完成之后,界面右侧的三个功能按钮会自动由不可用状态切换为可点击状态,避免用户在未生成结果前进行误操作。这三个按钮分别承担不同的功能,其中"导出结果"按钮允许用户将检测数据保存到本地。系统支持多种导出格式,包括Excel、CSV以及TXT,用户可以根据实际需求灵活选择合适的文件类型,以便后续分析或归档使用。以Excel格式为例,导出的文件通常采用表格结构,对应字段清晰排列,便于用户进一步查看与处理数据。

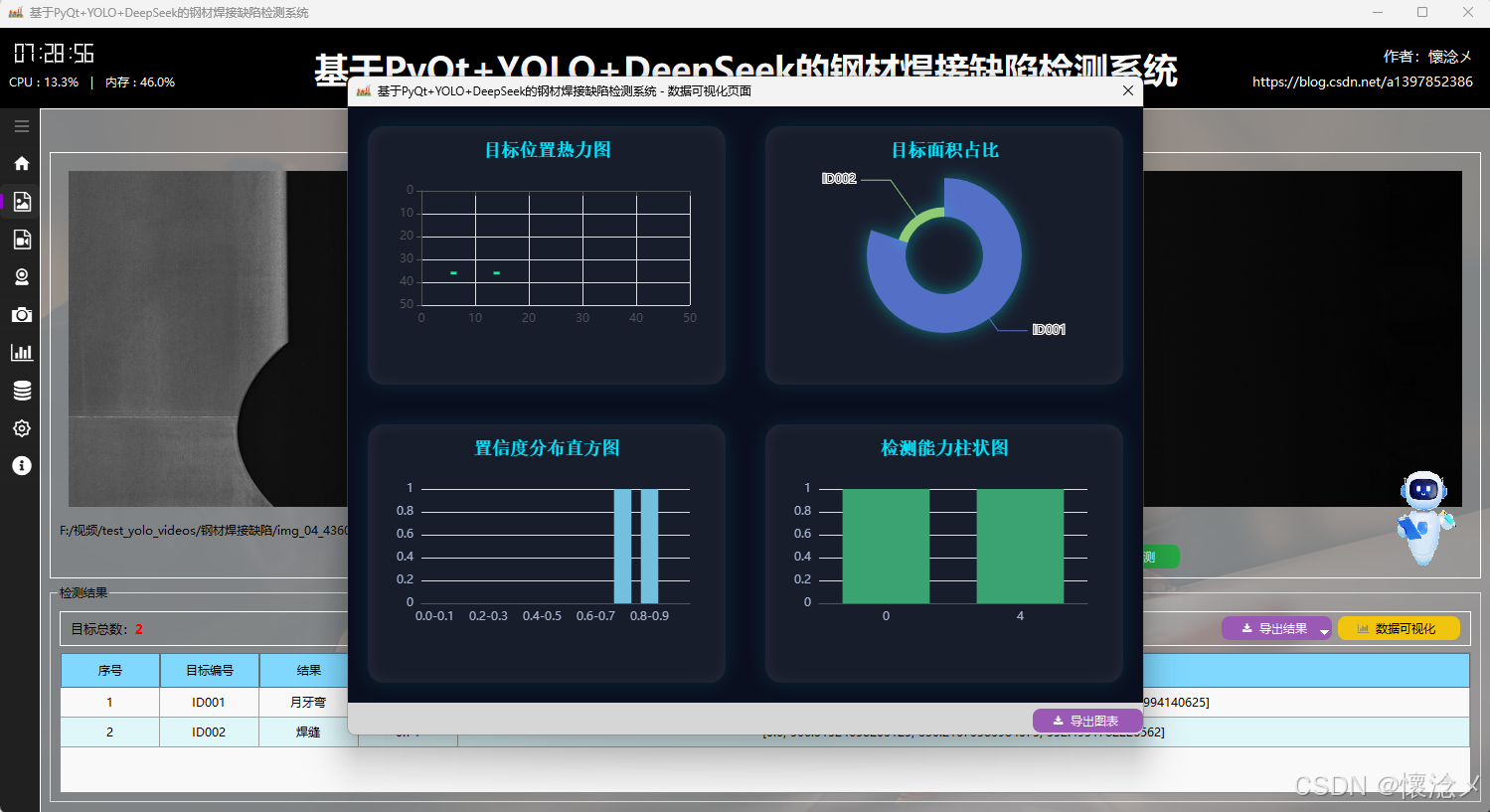
3.可视化展示
然后就是可视化展示,用户可以点击进行可视化按钮,查看对于本次检测的可视化效果,系统内置了四种可视化效果:分别是:目标位置热力图、目标面积占比、置信度分布直方图、检测能力柱状图,这些图标通过不同维度对当前数据进行了可视化展示,更便于用户理解,这里指的一体的是,支持可视化图表进行导出操作,用户可以点击紫色的导出按钮,对当前的可视化效果图表进行导出,生成一张本地的PNG图像文件。
4.AI(DeepSeek)智能分析
在每次检测任务完成并展示检测结果之后,系统为用户提供了一种便捷且智能的交互方式:用户只需点击界面右下角悬浮的机器人图标,即可触发对当前检测结果的深度AI分析功能。系统会自动将本次检测所得到的所有关键信息------包括检测到的目标类别、置信度分数、目标位置坐标、数量统计以及可能存在的异常或遮挡情况等------完整地作为输入传递给后端AI大模型。AI模型接收到这些数据后,会基于其强大的语义理解与逻辑推理能力,对本次检测结果进行多维度的智能评估。评估内容可以包括:检测结果的准确性与可靠性判断、识别结果中可能存在的误检或漏检风险提示、针对当前场景的优化建议、对异常情况的详细解释,甚至能够根据历史检测数据的模式给出趋势分析或预警信息。这一设计不仅使用户无需手动复制或整理检测数据就能获得即时的专业分析反馈,更重要的是,它实现了一种通用化的AI能力接入机制:检测模块与分析模块实现了解耦,任何检测结果都可以以统一格式传递给AI进行分析,而AI的具体分析逻辑可以根据需要灵活替换、升级或定制。这使得系统在未来可以轻松扩展更多智能功能,例如接入不同的大模型、增加多模态分析能力、实现检测策略的自适应调整等,极大地提升了整个系统的可扩展性与智能化水平。
这里是软件的另外一个核心:AI智能分析,我们的目标检测系统接入了DeepSeek大模型,支持对当前检测结果数据进行AI分析,AI会通过不同维度对当前检测结果进行多角度分析,最后生成检测结果分析报告,用户可以根据这个结果对系统进行调整,不断完善系统功能和目标检测准确度!
在AI分析结束后下方会展示一些按钮,用户可以方便地复制结果、导出文本内容、生成PDF报告、重新生成以及关闭,多重的操作方式给于用户了多种选择!
4.视频检测界面
1.视频文件检测
我们的系统支持视频内容中的球体检测,支持输入的视频类型包括:视频文件、视频流以及摄像头,通过识别视频画面的内容对内容中的目标球体进行检测,试试标注与展示,通过相关帧率控制保证了视频的流畅性,用户可以通过比对左右两侧的画面使用肉眼评估当前检测结果,我们的视频检测界面拥有图像检测界面相同的操作功能,这里不多赘述。
2.摄像头内容检测
用户点击"进行检测"按钮之后系统会自动调用摄像头,打开摄像头展示摄像头画面,实时检测目标画面中的球体,通过左右画面比对让用户看到检测结果,这里本人就不露脸啦~
5.模型指标评估
在这个页面中我们通过三个tab展示了模型训练结果评估,分别是:训练结果图、训练结果详情、整体评估,所有的训练结果文件(夹)以及相关作用可见下面图标:
| 文件/文件夹名 | 类型 | 作用说明 |
|---|---|---|
weights/ |
文件夹 | 存放训练得到的模型权重 |
├─ best.pt |
文件 | 在验证集上表现最好的模型(推荐用于推理/部署) |
├─ last.pt |
文件 | 最后一轮训练结束时的模型(包含最新状态) |
results.csv |
文件 | 每个 epoch 的训练与验证指标(loss、mAP、precision 等) |
results.png |
图片 | 训练过程中各类指标变化曲线(loss、mAP 等可视化) |
confusion_matrix.png |
图片 | 混淆矩阵,展示类别预测情况 |
confusion_matrix_normalized.png |
图片 | 归一化后的混淆矩阵 |
PR_curve.png |
图片 | Precision-Recall 曲线 |
P_curve.png |
图片 | Precision 曲线 |
R_curve.png |
图片 | Recall 曲线 |
F1_curve.png |
图片 | F1-score 曲线 |
labels.jpg |
图片 | 数据集中标签分布(类别统计) |
labels_correlogram.jpg |
图片 | 标签相关性图(用于分析数据分布) |
train_batch*.jpg |
图片 | 训练批次样本可视化(带标注框) |
val_batch*.jpg |
图片 | 验证批次样本可视化 |
args.yaml |
文件 | 本次训练的完整参数配置(超参数、路径等) |
hyp.yaml(部分版本) |
文件 | 超参数配置(学习率、增强策略等) |
opt.yaml(旧版本可能有) |
文件 | 训练选项记录(已逐渐被 args.yaml 替代) |
events.out.tfevents.* |
文件 | TensorBoard 日志文件(用于可视化训练过程) |
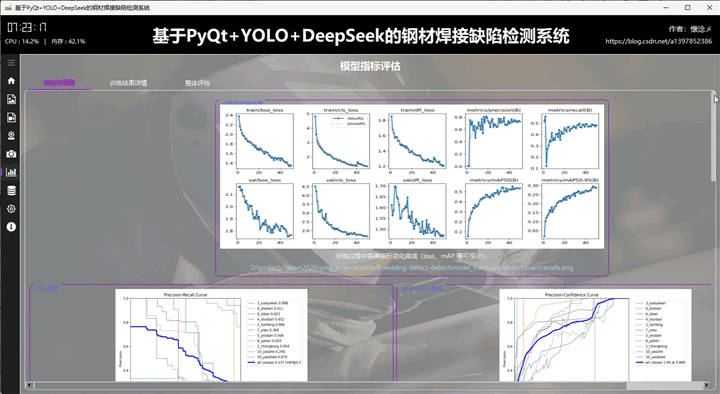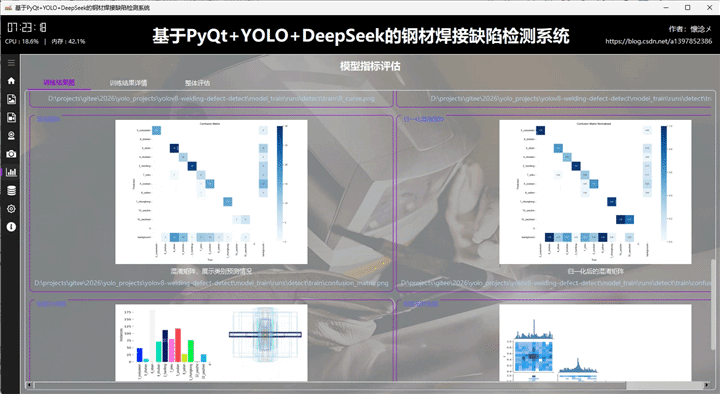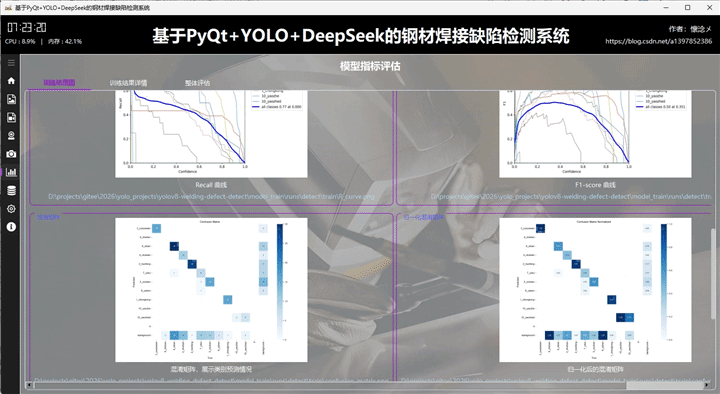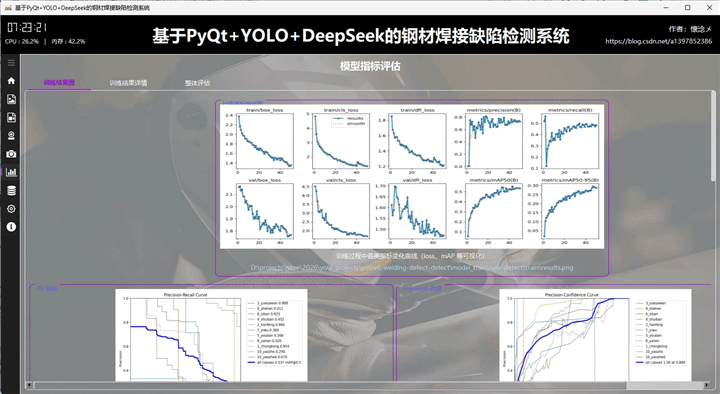
1.训练结果图tab
本系统基于 PyQt5 + YOLOv8 + DeepSeek 构建,实现对口罩佩戴状态的智能检测与可视化分析。在结果展示模块的该 tab 页面中,集中呈现模型训练与评估阶段生成的多维度指标图像,包括训练损失与性能指标曲线图、PR 曲线、Precision 曲线、Recall 曲线、F1 曲线,以及混淆矩阵与归一化混淆矩阵。同时还提供标签分布图与标签相关性图,用于分析数据集结构与类别关系。
这些图像以直观的方式嵌入界面中,用户无需额外操作即可快速浏览模型整体表现。例如,PR 曲线可反映模型在不同阈值下的查准率与召回率平衡,F1 曲线用于综合衡量模型性能,而混淆矩阵则清晰展示分类正确与误判情况。标签分布与相关性图则有助于判断数据是否均衡及类别间的潜在关联。
在交互设计上,用户可通过点击图像本身,或点击底部提供的图像路径,调用系统默认图像查看工具进行放大查看,提升细节分析能力。每张图像下方均附有简明且专业的说明文案,帮助用户理解其评估意义及应用价值,从而更全面地掌握模型训练效果与优化方向。
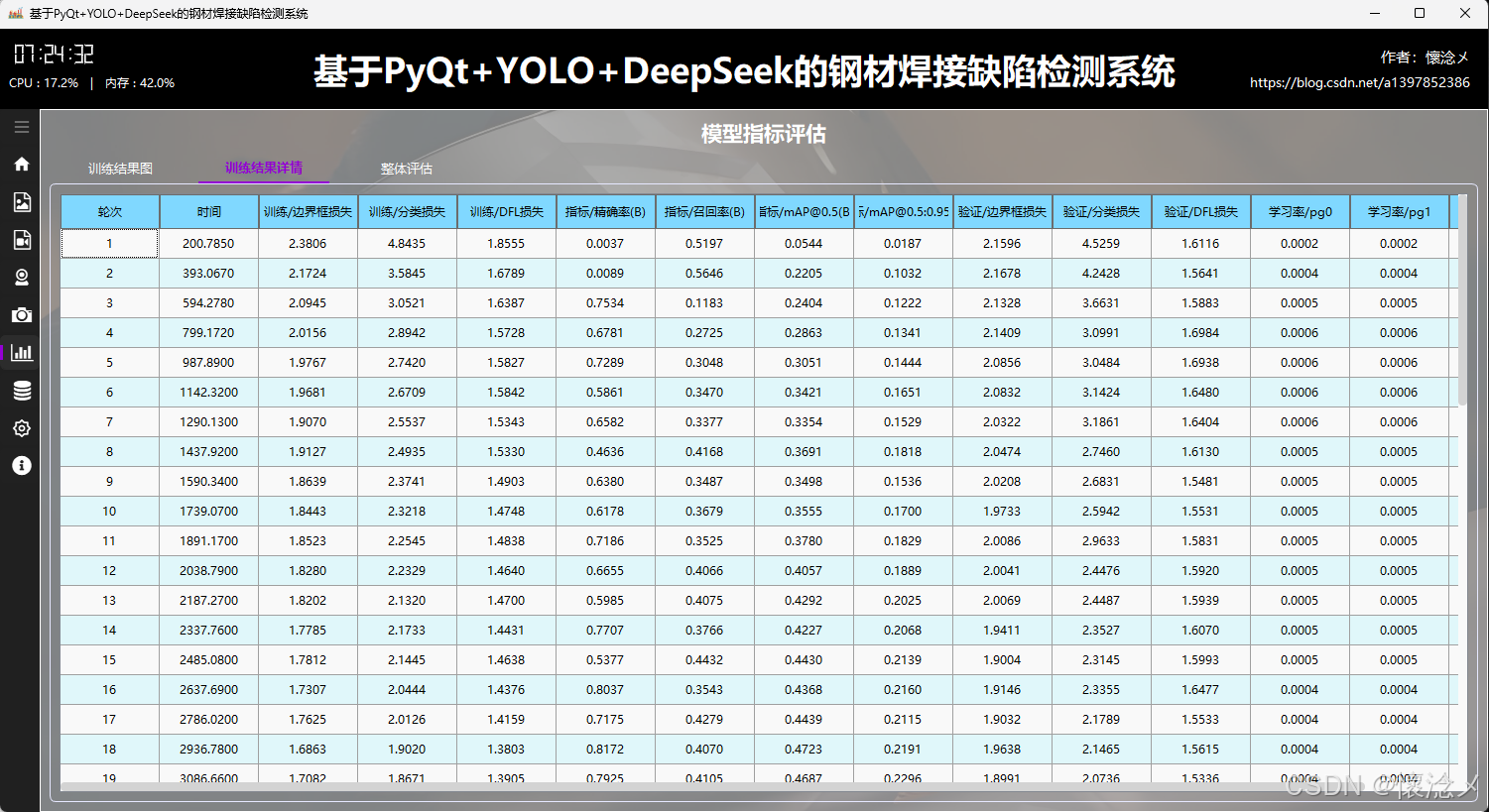
2.训练结果详情tab
在该子 tab 页面中,系统进一步对训练过程中的 results.csv 数据进行了结构化展示。通过将原始训练日志解析为二维表格,完整呈现模型在每一轮(epoch)中的关键指标变化情况,使用户能够以更加清晰、系统化的方式回顾训练全过程。界面设计上采用了简洁清新的视觉风格,并结合横向渐变配色对不同数值区间进行区分,使数据变化趋势更加直观,重点指标一目了然。
表格中包含了完整的字段信息,例如"轮次"和"时间"用于标识训练进度;"训练/边界框损失""训练/分类损失""训练/DFL损失"反映模型在训练阶段的收敛情况;"指标/精确率(B)""指标/召回率(B)"以及"指标/mAP@0.5(B)"和"指标/mAP@0.5:0.95(B)"用于综合评估模型检测性能;对应的"验证/边界框损失""验证/分类损失""验证/DFL损失"则用于判断模型的泛化能力与是否存在过拟合现象。此外,"学习率/pg0""学习率/pg1""学习率/pg2"展示了不同参数组在训练过程中的学习率动态变化,有助于分析优化策略的效果。
在交互体验方面,表格支持滚动浏览与高亮显示,用户可以快速定位关键轮次的数据变化。同时结合渐变色视觉编码,能够快速识别性能提升或波动区间。通过这一模块,用户不仅可以精确掌握模型训练的细节,还能够为后续参数调优与模型改进提供可靠的数据支撑,实现从"可视化观察"到"数据驱动优化"的有效过渡。
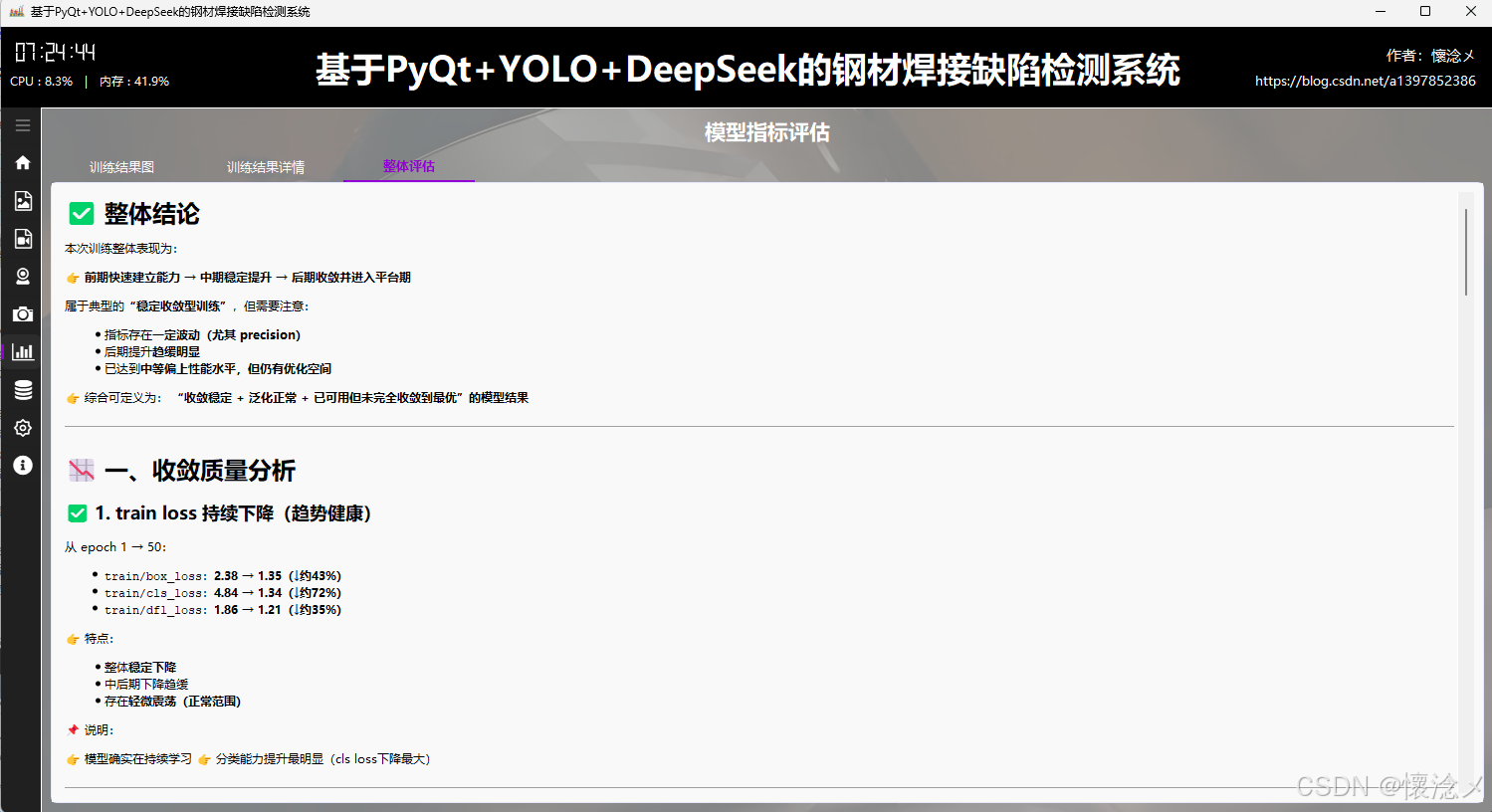
3.整体评估tab
在该页面中,系统对模型训练结果进行了更高层次的综合评估与总结分析。通过对关键指标进行统一整理与可视化表达,结合细致的颜色编码机制,将不同阶段的性能变化趋势清晰呈现出来,使用户能够从整体上把握模型训练的动态过程,而不仅仅停留在单一指标的观察。
在评估维度上,系统重点围绕多个核心方面展开。首先是收敛质量 ,通过训练与验证损失曲线的变化趋势,判断模型是否稳定收敛以及是否存在震荡或过早收敛的问题;其次是检测性能 ,结合 Precision、Recall 以及 F1 等指标,分析模型在目标检测任务中的准确性与覆盖能力;在泛化能力 方面,通过对比训练集与验证集指标差异,评估模型是否存在过拟合或欠拟合现象;同时利用 mAP 综合表现 (包括 mAP@0.5 与 mAP@0.5:0.95)对模型整体检测能力进行量化衡量,从多阈值角度反映检测精度的稳定性。
此外,系统还对学习率调度策略 进行了分析,通过展示不同参数组学习率随训练轮次的变化情况,帮助用户判断当前优化策略是否合理,以及是否需要进一步调整以提升训练效率或稳定性。所有评估结果均通过分层颜色与趋势变化进行突出展示,使关键结论更加直观易读。
在页面的最后部分,系统基于上述多维度分析结果,自动生成整体评估结论,并从工程应用视角给出总结性判断。例如模型是否已达到可部署标准、是否需要继续训练或优化数据集、以及在实际口罩检测场景中的预期表现。这种从数据到结论的完整闭环设计,有助于用户快速完成模型质量评估,并为后续系统部署与迭代提供明确依据。
6.数据查看界面
"历史数据"页面是系统中用于集中查看与管理过往记录的重要模块,整体设计清晰直观,通过两个独立的 Tab 实现不同维度数据的分类展示,方便用户快速切换与定位信息。
总体而言,"历史数据"页面通过清晰的结构划分与完善的功能设计,实现了检测记录与用户信息的高效管理与展示,为系统的运维与决策提供了有力支持。
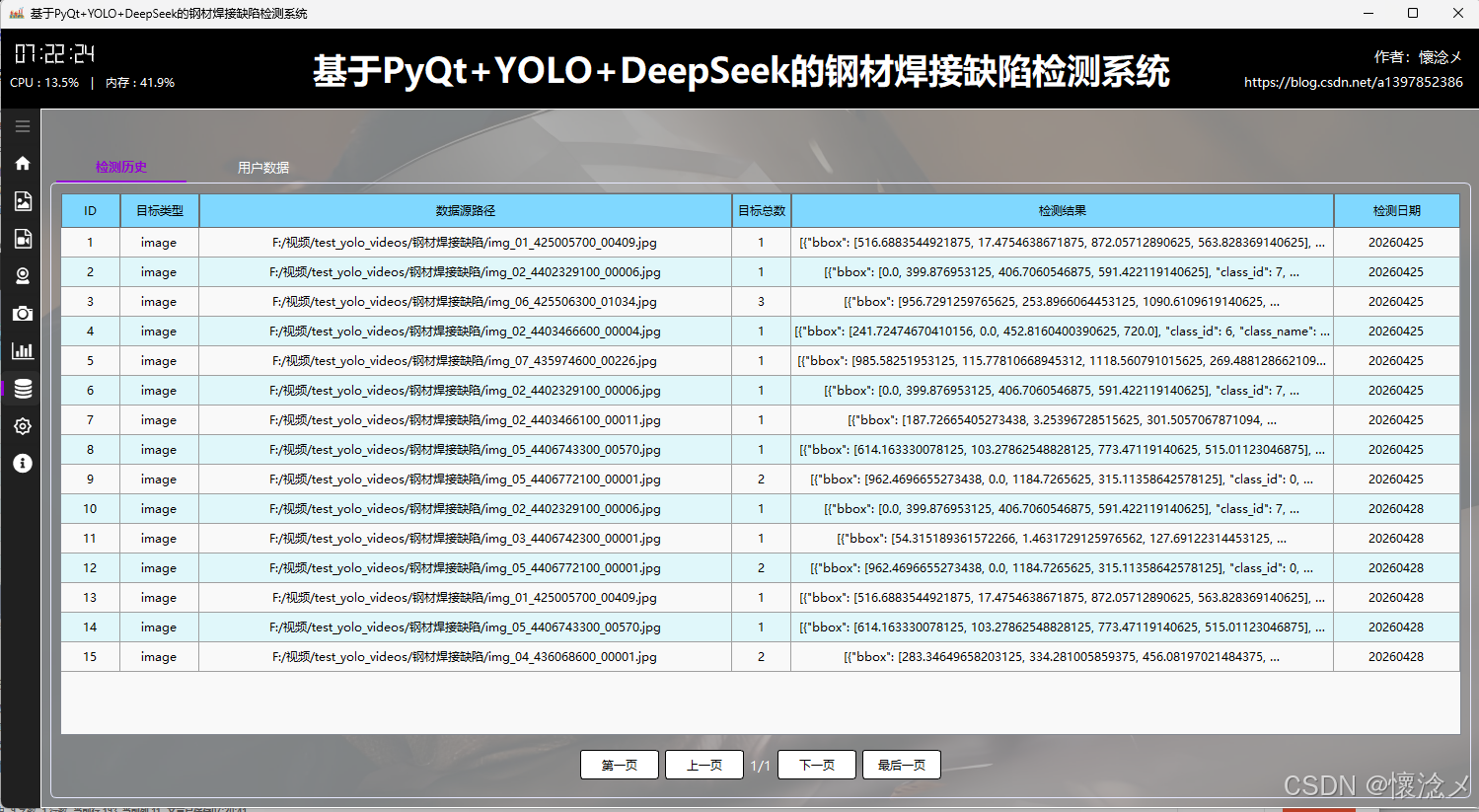
1.历史数据tab
在"检测历史数据"Tab中,页面以结构化表格的形式呈现所有检测相关记录。每一条数据都包含关键字段:数据库ID用于唯一标识记录,目标类型用于说明检测对象的类别,检测结果用于反馈检测结论,检测日期则记录具体的时间信息。该模块不仅实现了数据的完整展示,还特别强化了可用性与交互体验------支持分页浏览功能,用户可以根据数据量分批查看内容,同时提供"跳转到第一页"、"上一页"、"下一页"以及"最后一页"等操作按钮,便于在大量数据中高效导航。这种分页机制有效避免了数据过载带来的性能问题,同时也提升了界面的响应速度和用户体验。
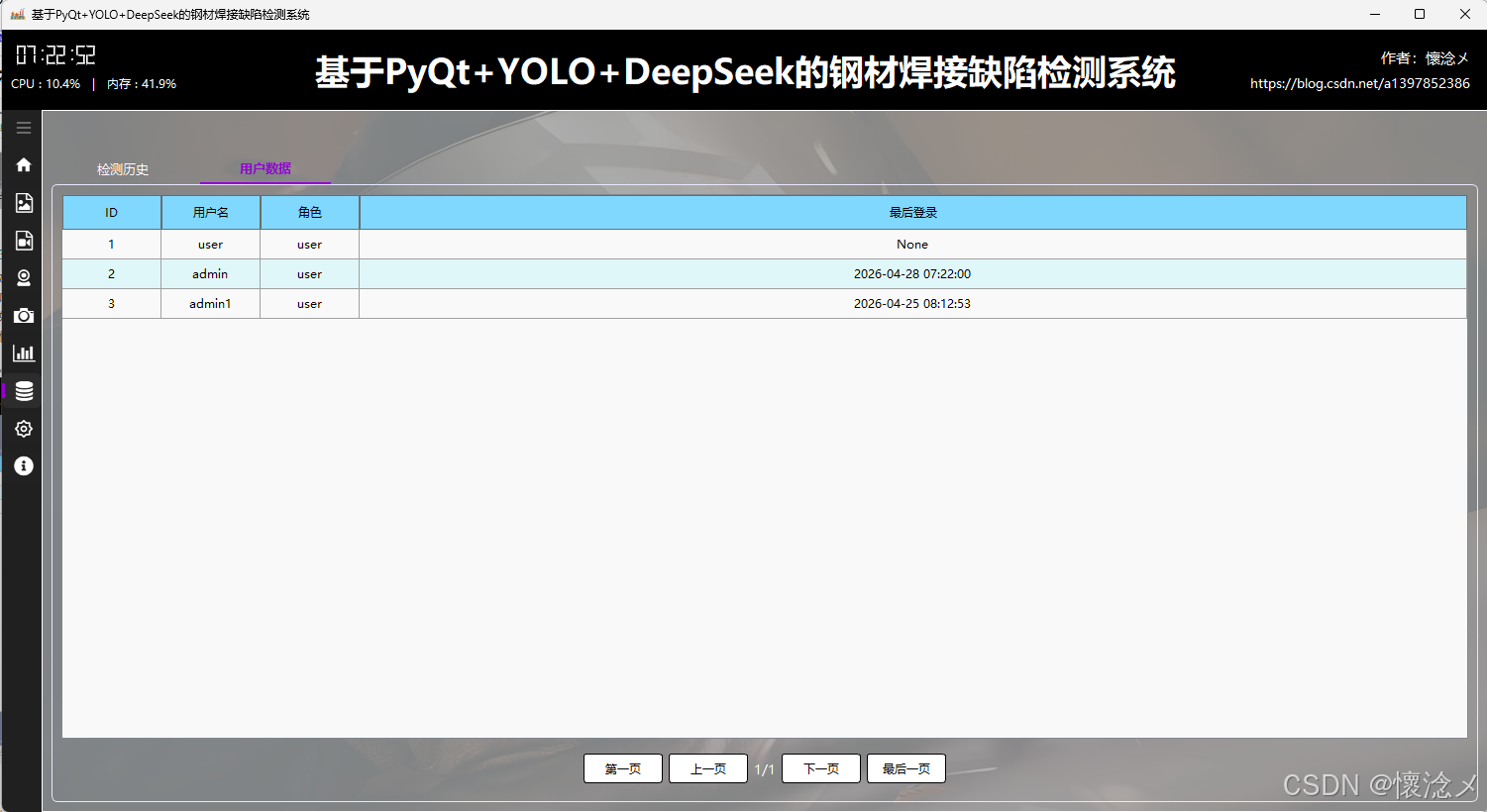
2.用户数据tab
其次,在"用户数据"Tab中,系统汇总展示了所有已注册用户的信息,是一个用于用户管理与审计的重要视图。页面同样采用表格形式,列出了数据库ID、用户名、用户角色以及最后登录日期时间等核心字段。通过这些信息,管理员可以快速了解系统用户的基本情况及活跃状态,例如判断某些用户是否长期未登录,从而进行进一步管理操作。该部分数据覆盖范围全面,确保系统管理者能够掌握整体用户分布与使用情况。
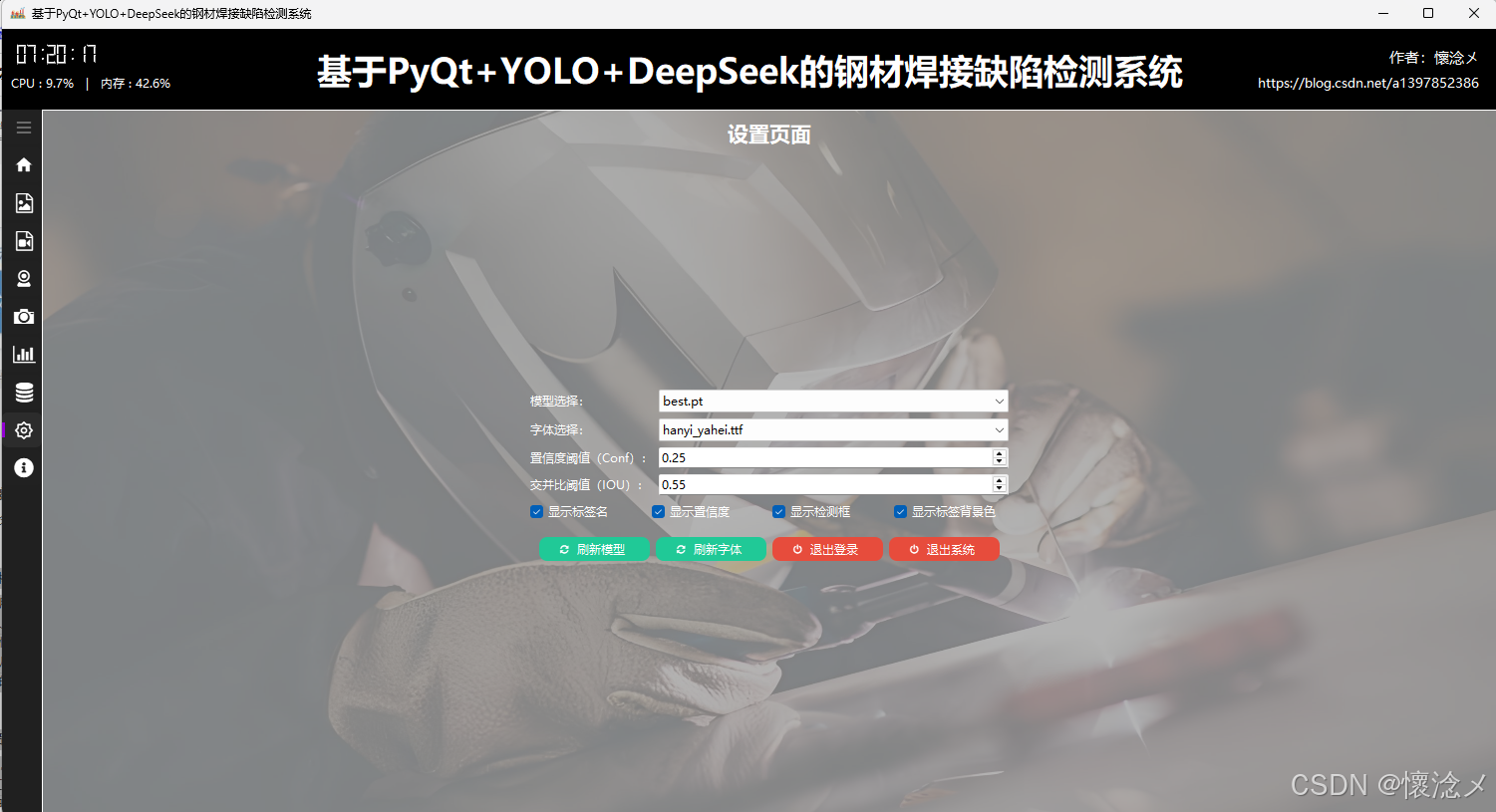
7.系统设置界面
本系统提供了较为完善且直观的参数配置功能,能够满足用户在目标检测过程中的多样化需求。用户可以根据实际应用场景,自由选择和切换不同的目标检测模型,以获得更合适的检测效果。同时,系统支持对字体位置进行灵活调整,方便在界面中展示检测结果信息。此外,还可以设置关键的检测参数,例如置信度阈值(Conf)和交并比阈值(IOU),从而在检测精度与召回率之间取得平衡。
在检测结果的展示方面,系统同样提供了多种控制选项,包括是否显示检测框、是否展示目标类别标签、是否显示目标置信度数值,以及是否启用文字背景等。这些细致的配置可以帮助用户根据需求优化可视化效果,提高信息的清晰度和可读性。
为了提升使用体验,系统还设计了便捷的操作按钮。用户可以点击绿色的刷新按钮以更新当前可用的模型列表,也可以通过刷新字体功能加载新的字体文件。此外,系统支持通过点击退出按钮快速退出当前界面或直接退出登录。整体而言,该设置页面实现了目标检测参数的灵活配置与高效管理,兼顾实用性与易用性。
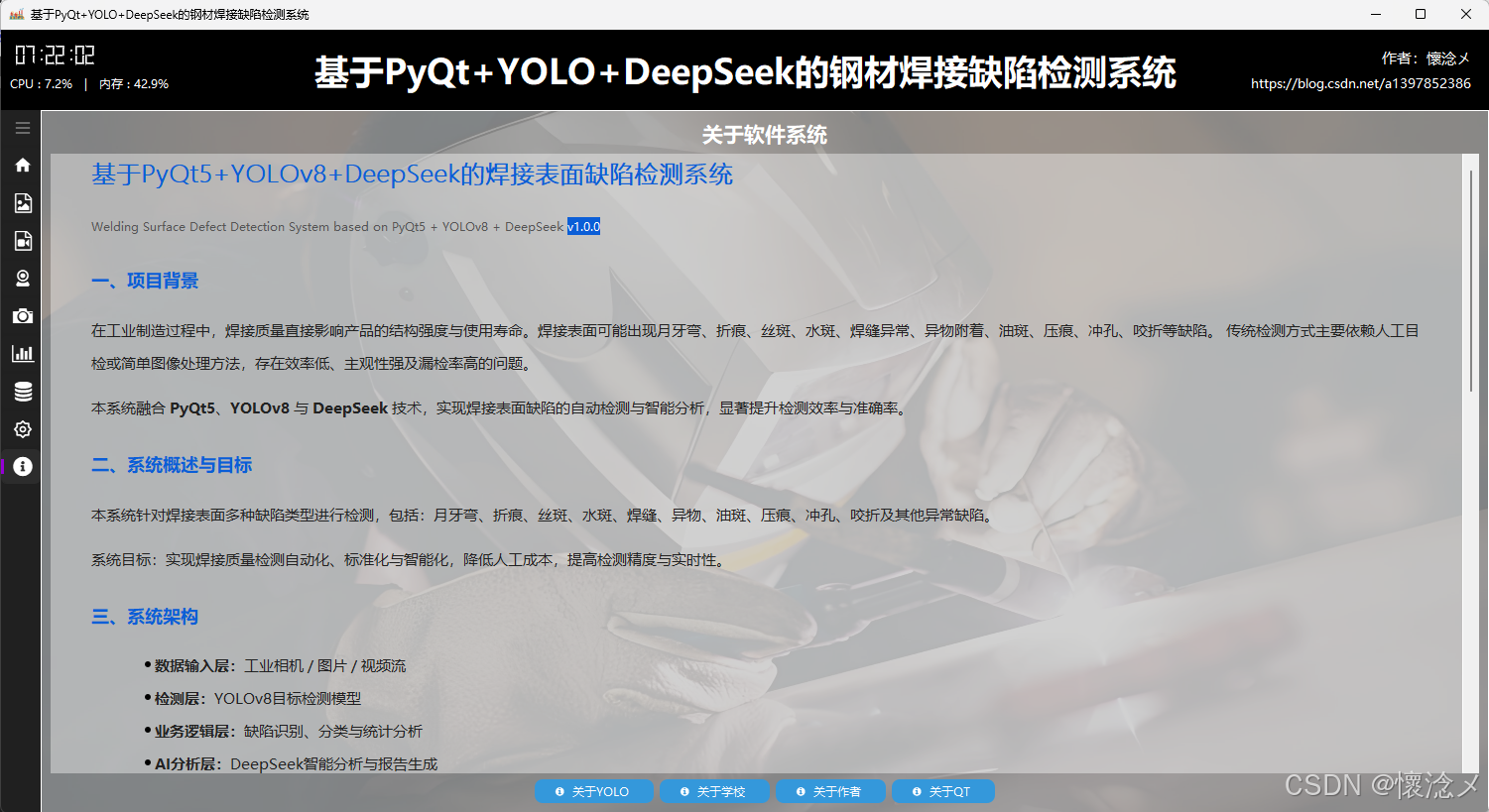
8.关于软件界面
我们使用富文本html的形式展示了软件相关的信息,包括系统用到的相关技术,对于二维的数据使用二维表进行了展示,最底部放置了四个按钮,分别是:关于YOLO、关于软件、关于作者、关于QT,点击之后都会弹出对应的信息提示框,这个页面的作用是让用户更多的了解软件和创作者信息,跨过技术的鸿沟!
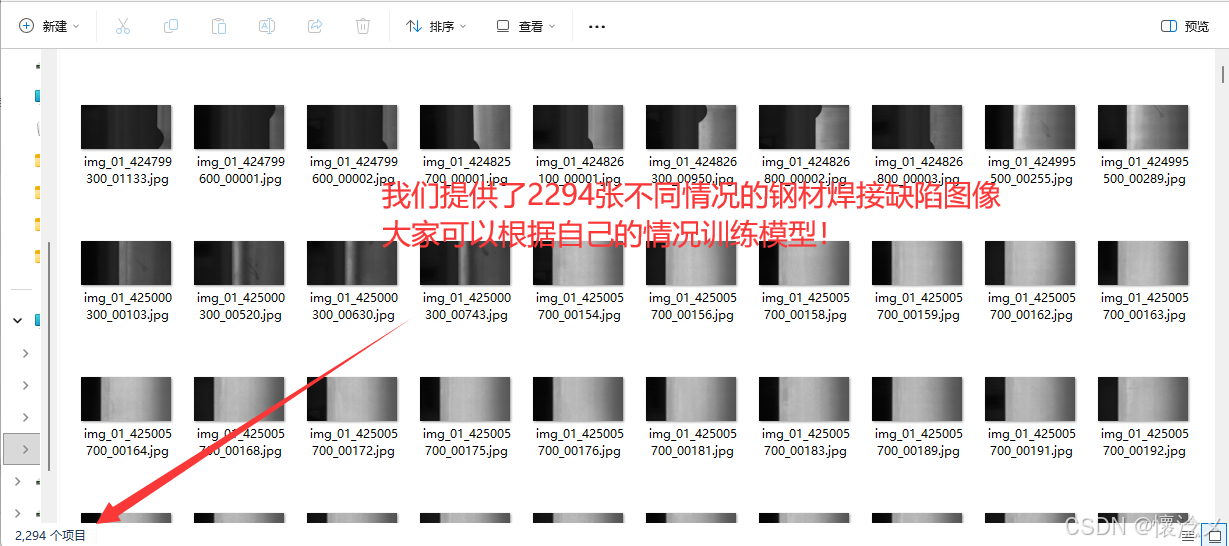
四.数据集
本系统所使用的数据集围绕刚才缺陷目标检测的多场景、多角度、多状态采集构建而成,旨在提升模型在真实环境中的适应性与鲁棒性。数据来源涵盖多类复杂场景,结合不同光照条件、摄像头分辨率、遮挡程度与背景干扰,使模型能够学习到多样化的外观特征与环境变化。图像中包含站立、奔跑、觅食、半遮挡、远距离、小尺寸目标等多种姿态,并覆盖不同体型、颜色与运动模糊情况下的样本。数据集中不仅包含清晰标注的边界框,还对类别与置信度进行了严格校验,以确保训练时标签可信度和质量的一致性。经过清洗、去重、增强与格式化处理后,最终数据集能够满足 YOLOv8 等高性能检测模型的训练需求,使模型在实际部署中具备更强的泛化能力,即便在光照不足、目标部分遮挡或背景复杂的情况下,也能保持稳定识别效果。该数据集为系统实现高精度、高实时性的老鼠检测奠定了坚实基础。
1.数据准备
本系统附带699张不同车型图像和699个数据标注文件,大家可以根据自己的情况自行训练数据自己的模型!
我们使用VOC的格式存储数据标注文件,单数据标注文件内容如下:
bash
<annotation>
<folder>4</folder>
<filename>img_01_424995500_00255.jpg</filename>
<path>E:\002_Data\suface dectect\2-fuxinzhe\msos1\4\img_01_424995500_00255.jpg</path>
<source>
<database>Unknown</database>
</source>
<size>
<width>2048</width>
<height>1000</height>
<depth>1</depth>
</size>
<segmented>0</segmented>
<object>
<name>4_shuiban</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>1169</xmin>
<ymin>317</ymin>
<xmax>1577</xmax>
<ymax>809</ymax>
</bndbox>
</object>
</annotation>2.数据集处理
1.数据集标注文件类型转换
直接使用VOC格式的数据标注文件进行训练是不行的,需要我们将xml转成txt文件,
这段代码的作用是将指定文件夹中的 Pascal VOC 格式的 XML 标注文件批量转换为 YOLO 格式的 TXT 标注文件。它会先遍历所有 XML 自动统计有效类别并生成类别到 ID 的映射表,忽略类别名为 "not" 的标注,然后读取对应图片的尺寸,将 XML 中的边界框坐标转换为 YOLO 的归一化格式(class_id x_center y_center width height),最后将生成的 TXT 文件保存到指定目录中,便于直接用于 YOLO 训练。
大家首先执行step1_voc_to_txt.py
python
import os
import xml.etree.ElementTree as ET
from PIL import Image
from train_conf import BASE_DIR
# 原始路径
xml_dir = BASE_DIR + r"Annotations"
img_dir = BASE_DIR + r"JPEGImages"
# YOLO标签输出路径
yolo_txt_dir = BASE_DIR + r"labels"
os.makedirs(yolo_txt_dir, exist_ok=True)
# ===== 自动生成类别映射 =====
class_map = {}
next_class_id = 0
# 支持的图像扩展
img_exts = [".jpg", ".jpeg", ".png", ".bmp"]
# 遍历 XML 文件
for xml_file in os.listdir(xml_dir):
if not xml_file.endswith(".xml"):
continue
xml_path = os.path.join(xml_dir, xml_file)
tree = ET.parse(xml_path)
root = tree.getroot()
# --- 以 XML 文件名匹配图像 ---
base = os.path.splitext(xml_file)[0]
img_path = None
for ext in img_exts:
candidate = os.path.join(img_dir, base + ext)
if os.path.exists(candidate):
img_path = candidate
break
if img_path is None:
print(f"Warning: 图像文件与 {xml_file} 同名的图片不存在,跳过")
continue
# 获取图像尺寸
try:
with Image.open(img_path) as img:
w, h = img.size
except Exception as e:
print(f"无法打开图片 {img_path}: {e}")
continue
txt_lines = []
# 遍历目标
for obj in root.findall("object"):
name_node = obj.find("name")
if name_node is None:
continue
label = name_node.text.strip()
# === 自动分配 class_id ===
if label not in class_map:
class_map[label] = next_class_id
next_class_id += 1
class_id = class_map[label]
bndbox = obj.find("bndbox")
if bndbox is None:
continue
xmin = float(bndbox.find("xmin").text)
ymin = float(bndbox.find("ymin").text)
xmax = float(bndbox.find("xmax").text)
ymax = float(bndbox.find("ymax").text)
x_center = ((xmin + xmax) / 2) / w
y_center = ((ymin + ymax) / 2) / h
box_width = (xmax - xmin) / w
box_height = (ymax - ymin) / h
txt_lines.append(
f"{class_id} {x_center:.6f} {y_center:.6f} {box_width:.6f} {box_height:.6f}"
)
# 保存 YOLO txt
txt_file_path = os.path.join(yolo_txt_dir, base + ".txt")
with open(txt_file_path, "w") as f:
f.write("\n".join(txt_lines))
# ===== 输出类别映射 =====
print("\n类别映射 class_map:")
for k, v in class_map.items():
print(f"{v}: {k}")
print(f"\n转换完成!YOLO TXT 文件已保存在: {yolo_txt_dir}")2.数据集拆分
YOLO 推荐训练集和测试集按 8:2 划分,主要是因为目标检测对样本量非常依赖,需要尽可能多的训练数据来学习特征,同时又必须保留足够的独立测试数据来评估模型的真实泛化能力。8:2 被证明在"训练数据够多"与"测试评估足够稳定"之间取得了较好平衡,因此成为默认且通用的实践比例。
这个脚本的作用是从已有的图片和 YOLO 标注文件中随机抽取 200 张图片,并将它们按照训练集和验证集的比例进行划分,然后将对应的图片和 TXT 标注文件复制到新的数据集目录中,方便直接用于训练 YOLO 模型。脚本会先创建训练集和验证集的图片、标签子目录,然后随机选择 指定数量的张图片,其中 五分之一作为验证集,其余 五分之四作为训练集,复制过程中会保证每张图片对应的标注文件也被同步复制,如果标注文件不存在,会生成一个空的 TXT 文件,以保持文件结构完整。运行完成后,新的数据集就整理好了,可以直接用于训练和验证。。最终会在目标目录下生成:

执行脚本step2_auto_part.py
bash
import os
import random
import shutil
from train_conf import BASE_DIR
# 原始数据路径
img_dir = BASE_DIR + "JPEGImages"
label_dir = BASE_DIR + "labels"
# 新数据集路径
dataset_dir = BASE_DIR + "dataset"
MAX_IMAGE_COUNT = 600
SP_COUNT = int(MAX_IMAGE_COUNT * 0.2)
train_img_dir = os.path.join(dataset_dir, "train", "images")
train_label_dir = os.path.join(dataset_dir, "train", "labels")
val_img_dir = os.path.join(dataset_dir, "val", "images")
val_label_dir = os.path.join(dataset_dir, "val", "labels")
# 创建目录
for dir_path in [train_img_dir, train_label_dir, val_img_dir, val_label_dir]:
os.makedirs(dir_path, exist_ok=True)
# 获取所有图片文件
all_images = [f for f in os.listdir(img_dir) if f.lower().endswith((".jpg", ".png", ".jpeg"))]
# 随机抽取MAX_IMAGE_COUNT张
if len(all_images) < MAX_IMAGE_COUNT:
raise ValueError(f"图片数量不足MAX_IMAGE_COUNT张,当前数量: {len(all_images)}")
selected_images = random.sample(all_images, MAX_IMAGE_COUNT)
# 分割训练集和验证集
random.shuffle(selected_images)
val_images = selected_images[:SP_COUNT]
train_images = selected_images[SP_COUNT:]
def copy_files(image_list, target_img_dir, target_label_dir):
for img_file in image_list:
# 复制图片
src_img_path = os.path.join(img_dir, img_file)
dst_img_path = os.path.join(target_img_dir, img_file)
shutil.copy(src_img_path, dst_img_path)
# 对应的txt
label_file = os.path.splitext(img_file)[0] + ".txt"
src_label_path = os.path.join(label_dir, label_file)
if os.path.exists(src_label_path):
dst_label_path = os.path.join(target_label_dir, label_file)
shutil.copy(src_label_path, dst_label_path)
else:
# 如果没有对应txt文件,创建一个空文件
open(os.path.join(target_label_dir, label_file), "w").close()
# 复制训练集
copy_files(train_images, train_img_dir, train_label_dir)
# 复制验证集
copy_files(val_images, val_img_dir, val_label_dir)
print(f"随机抽取完成!训练集: {len(train_images)} 张,验证集: {len(val_images)} 张")
print(f"数据集路径: {dataset_dir}")3.模型训练
数据集准备好之后就可以开始模型训练了,我们首先准备一个训练的配置文件,比如说是data.yaml

然后就可以开始模型训练了,直接执行我们准备好的train.bat文件,内容就是下面的内容
bash
yolo task=detect mode=train model=../data/model/yolov8n.pt data=./data.yaml epochs=30 imgsz=640 batch=16 lr0=0.01用户亦可执行step4_train_model.py脚本进行模型训练
python
from ultralytics import YOLO
def main():
# 加载模型
model = YOLO("../data/model/yolov8n.pt")
# 开始训练
model.train(
data="./data.yaml", # 数据集配置
epochs=50, # 训练轮数
imgsz=640, # 输入尺寸
batch=16, # batch size
lr0=0.01, # 初始学习率
task="detect" # 任务类型
)
if __name__ == "__main__":
main()然后模型就开始训练了
这里我贴一些训练验证结果截图




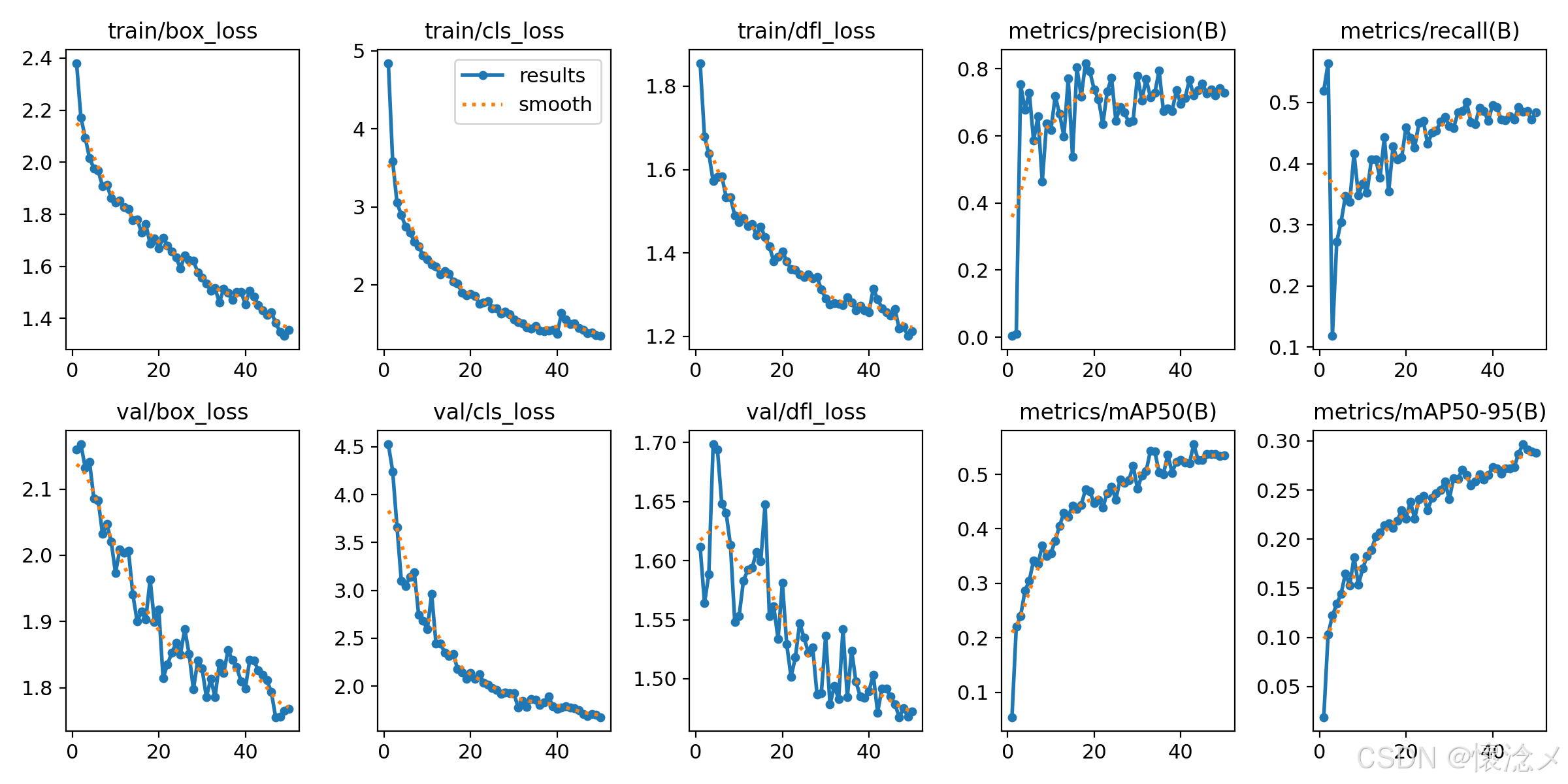
最后的results.png见下图,训练效果还是可以的!
bash
# ✅ **整体结论**
本次训练整体表现为:
👉 **前期快速建立能力 → 中期稳定提升 → 后期收敛并进入平台期**
属于典型的**"稳定收敛型训练"**,但需要注意:
* 指标存在**一定波动(尤其 precision)**
* 后期提升**趋缓明显**
* 已达到**中等偏上性能水平,但仍有优化空间**
👉 综合可定义为:
**"收敛稳定 + 泛化正常 + 已可用但未完全收敛到最优"的模型结果**
---
# 📉 **一、收敛质量分析**
## ✅ 1. train loss 持续下降(趋势健康)
从 epoch 1 → 50:
* `train/box_loss`:**2.38 → 1.35(↓约43%)**
* `train/cls_loss`:**4.84 → 1.34(↓约72%)**
* `train/dfl_loss`:**1.86 → 1.21(↓约35%)**
👉 特点:
* 整体**稳定下降**
* 中后期下降趋缓
* 存在**轻微震荡(正常范围)**
📌 说明:
👉 模型确实在持续学习
👉 分类能力提升最明显(cls loss下降最大)
---
## ✅ 2. 验证集 loss 同步下降(泛化正常)
从 epoch 1 → 50:
* `val/box_loss`:**2.16 → 1.77**
* `val/cls_loss`:**4.53 → 1.68**
* `val/dfl_loss`:**1.61 → 1.47**
👉 特点:
* 与 train **整体同趋势**
* 无明显发散
* 后期基本趋于稳定
📌 结论:
✅ **没有明显过拟合**
⚠️ 但**val下降幅度小于train** → 泛化提升有限
---
# 🚀 **二、检测性能演化**
## ✅ 1. 前期(1--5 epoch):快速建立基础能力
* mAP50:**0.05 → 0.30**
* recall:**0.52 → 0.30(波动较大)**
* precision:**极低 → 快速上升**
👉 特点:
* 模型迅速"学会检测"
* 指标不稳定(正常现象)
---
## ⚠️ 2. 中期(10--25 epoch):稳定提升阶段
* mAP50:**0.35 → 0.47**
* mAP50-95:**0.17 → 0.24**
* recall:**0.36 → 0.47**
👉 特点:
✔ 提升连续
✔ 无断崖波动
✔ 学习有效
但:
⚠️ precision 波动明显(0.53--0.81区间反复)
---
## ⚠️ 3. 后期(30 epoch 之后):进入平台期
关键指标:
* **mAP50:约 0.50 -- 0.55(峰值≈0.555)**
* **mAP50-95:约 0.26 -- 0.29(峰值≈0.296)**
* **recall:稳定在 0.46 -- 0.50**
* **precision:0.67 -- 0.79(波动较大)**
👉 特点:
✔ 指标总体稳定
✔ 无明显退化
⚠️ 提升幅度非常有限(已接近瓶颈)
📌 说明:
👉 模型**基本收敛,但尚未完全榨干性能**
---
# 🎯 **三、Precision / Recall 结构分析**
整体区间:
* precision:**0.64 -- 0.80(波动较大)**
* recall:**0.34 -- 0.50(逐步稳定)**
👉 特征:
✅ recall 提升稳定(漏检逐步减少)
⚠️ precision 不够稳定(误检控制波动)
📌 结论:
👉 当前模型属于:
**"召回优先 + 精度可优化型"模型**
---
# 📊 **四、mAP 表现(真实水平)**
最终能力:
* **mAP50 ≈ 0.53(稳定)**
* **mAP50-95 ≈ 0.28(稳定)**
👉 特点:
✔ 持续训练得到(非偶然峰值)
✔ 与 loss / PR 走势一致
✔ 后期无明显回退
但:
⚠️ 提升进入瓶颈区
⚠️ 尚未达到高精度模型(>0.6 mAP50)
---
# ⚙️ **五、学习率策略评估**
学习率变化:
* 初期:**1.8e-4 → ~5.8e-4**
* 后期:**衰减至 ~1.8e-5**
👉 表现:
✔ 前期快速收敛
✔ 中期稳定优化
✔ 后期细节收敛
📌 未出现:
* loss 爆炸 ❌
* 指标震荡 ❌
👉 结论:
✅ 学习率策略**合理且有效**
---
# 🧠 **六、工程视角评价**
## ✅ 优点
### 1. 训练过程稳定
* 无异常波动
* 曲线连续
👉 可复现性强
---
### 2. 泛化能力正常
* train / val 同趋势
* 无明显过拟合
---
### 3. 已具备实际可用性
当前水平:
👉 可用于:
✔ baseline模型
✔ 工程初版部署
✔ 后续优化起点
---
## ⚠️ 不足
### 1. 后期进入平台期
👉 说明:
* 模型容量 / 数据 /增强可能存在瓶颈
---
### 2. precision 不稳定
👉 可能原因:
* 数据噪声
* 类别不平衡
* NMS/置信度阈值未调优
---
# 🏁 **最终评价**
本次训练可以定义为:
👉 **一次"稳定收敛 + 泛化正常 + 达到可用水平,但仍存在优化空间"的训练结果**
---
## ✅ 核心优点
✔ loss 持续下降(训练有效)
✔ 无过拟合(泛化正常)
✔ mAP 稳定提升(结果可信)
✔ 后期无性能崩塌(稳定性好)
---
## ⚠️ 关键改进点
👉 可继续优化方向:
* 提升 precision 稳定性
* 突破 mAP 瓶颈
* 延长训练或调整策略
---
# 📌 一句话结论
👉
**该模型训练过程稳定,已实现有效收敛并具备实际应用能力,但后期性能提升趋于平台,整体精度仍有进一步优化空间。**4.模型验证
模型训练结束后需要验证一下模型训练效果,我们准备了step4_test_model.py
这段代码实现了一个基于 YOLO 模型的目标检测可视化流程:首先加载训练好的模型权重,然后定义每个类别对应的中文名称和显示颜色,并加载中文字体用于标注;接着读取输入图片并进行目标检测推理,得到每个目标的边界框、类别和置信度;随后将 OpenCV 图像转换为 PIL 格式,在图像上绘制检测框和带中文标签的背景文字(包括类别名和置信度);最后再将图像转换回 OpenCV 格式并显示检测结果窗口,实现带中文标注的检测结果可视化。
python
from ultralytics import YOLO
import cv2
import numpy as np
from PIL import Image, ImageDraw, ImageFont
# ========== 1. 加载模型 ==========
model = YOLO("./runs/detect/train/weights/best.pt")
# ========== 2. 类别配置(名称 + 颜色)==========
CLASS_INFO = {
0: {"name": "月牙弯", "color": (255, 153, 102)},
1: {"name": "折痕", "color": (255, 204, 102)},
2: {"name": "丝斑", "color": (0, 255, 255)},
3: {"name": "水斑", "color": (102, 204, 255)},
4: {"name": "焊缝", "color": (102, 255, 178)},
5: {"name": "异物", "color": (204, 102, 255)},
6: {"name": "油斑", "color": (153, 153, 255)},
7: {"name": "压痕", "color": (255, 102, 204)},
8: {"name": "冲孔", "color": (255, 102, 102)},
9: {"name": "咬折", "color": (255, 178, 102)},
10: {"name": "咬折", "color": (255, 140, 102)},
11: {"name": "其他", "color": (180, 180, 180)},
}
# ========== 3. 加载中文字体 ==========
font_path = "../data/font/hanyi_yahei.ttf"
font = ImageFont.truetype(font_path, 20)
# ========== 4. 读取图片 ==========
img_path = "./test_images/img_05_4406743300_00478.jpg"
img = cv2.imread(img_path)
assert img is not None, "图片路径错误"
# ========== 5. YOLO 推理 ==========
results = model(img, conf=0.15)
# OpenCV → PIL
img_pil = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
draw = ImageDraw.Draw(img_pil)
# ========== 6. 画框 & 中文标签 ==========
for box in results[0].boxes:
x1, y1, x2, y2 = map(int, box.xyxy[0])
cls_id = int(box.cls)
conf = float(box.conf)
cls_info = CLASS_INFO.get(
cls_id,
{"name": "未知", "color": (255, 255, 255)}
)
label = f"{cls_info['name']} {conf:.2f}"
color = cls_info["color"]
# 画检测框
draw.rectangle([x1, y1, x2, y2], outline=color, width=2)
# 文字尺寸
text_bbox = draw.textbbox((0, 0), label, font=font)
text_w = text_bbox[2] - text_bbox[0]
text_h = text_bbox[3] - text_bbox[1]
# 文字背景
draw.rectangle(
[x1, y1 - text_h - 6, x1 + text_w + 6, y1],
fill=color
)
# 文字
draw.text(
(x1 + 3, y1 - text_h - 4),
label,
fill=(255, 255, 255),
font=font
)
# PIL → OpenCV
result_img = cv2.cvtColor(np.array(img_pil), cv2.COLOR_RGB2BGR)
# ========== 7. 显示 ==========
cv2.imshow("detect result", result_img)
cv2.waitKey(0)
cv2.destroyAllWindows()五.关于项目
1.开发环境
本系统是在 Windows 11 操作系统上进行开发的,Python 环境采用的是 Python 3.8 版本,硬件方面使用的是 AMD 处理器 ,未配备独立显卡,开发工具为 PyCharm 2021.3 版本。在整个开发与测试过程中,我们严格遵循了上述环境配置,确保了系统的稳定运行。在此特别建议所有使用者:为了避免出现因版本过新而导致的"不兼容"情况,请大家尽量不要使用过高的 Python 版本(如 Python 3.11 及以上),也不要使用最新的 PyCharm 或操作系统版本。因为较新的环境可能对部分依赖库或语法特性支持不佳,容易引发意外的报错或功能异常。遵循本项目所推荐的版本配置,能够最大程度地保证系统的顺利部署与稳定运行。
2.项目部署
1.项目依赖
博主是在Windows电脑上使用Python3.8开发的本系统,建议大家使用的Python版本别太高。
其中项目依赖为:
bash
PyQt5==5.15.11
QtAwesome==1.3.1
torch==2.4.1
torchvision==0.19.1
Pillow==9.3.0
pyqtgraph===0.13.3
PyQtWebEngine==5.15.5
opencv-python==4.10.0.82
ultralytics==8.3.234
Requests==2.32.5
pandas==2.0.3
numpy==1.24.4
Markdown==3.4.4我已经整理到了requirements.txt,大家直接使用命令
pip install -r requirements.txt
即可一键安装项目依赖,其中的torch和torchvision只要匹配即可,不一定非要和博主开发环境的版本一致。
2.项目结构
很多小伙伴担心拿到代码后项目看不懂,这个大家不必担心,我们采用文件+类名对相关功能进行了模块化定义,大家见名知意。
下图博主采用tree命令生成了文件、目录树
bash
tree "D:\projects\gitee\2026\yolo_projects\yolov8-welding-defect-detect" /f /a
bash
D:\PROJECTS\GITEE\2026\YOLO_PROJECTS\yolov8-welding-defect-detect
| main.py(系统入口)
| requirements.txt(项目依赖)
|
+---data(数据目录)
| +---database(数据库)
| | data.db
| |
| |
| +---font(字体目录)
| | hanyi_yahei.ttf
| |
| \---model(模型目录)
| best.pt
| yolov8n.pt
|
+---model_train(模型训练脚本目录)
| | data.yaml
| | step1_yolo_to_txt.py
| | step2_auto_part.py
| | step3_train_model.py
| | step4_test_model.py
| | train.bat
| |
| +---runs
| | \---detect
| | \---train
| | | args.yaml
| | | confusion_matrix.png
| | | confusion_matrix_normalized.png
| | | events.out.tfevents.1776169070.Admin.10148.0
| | | F1_curve.png
| | | labels.jpg
| | | labels_correlogram.jpg
| | | PR_curve.png
| | | P_curve.png
| | | results.csv
| | | results.png
| | | R_curve.png
| | | train_batch0.jpg
| | | train_batch1.jpg
| | | train_batch2.jpg
| | | train_batch400.jpg
| | | train_batch401.jpg
| | | train_batch402.jpg
| | | val_batch0_labels.jpg
| | | val_batch0_pred.jpg
| | | val_batch1_labels.jpg
| | | val_batch1_pred.jpg
| | |
| | \---weights
| | best.pt
| | last.pt
| |
| \---test_images
| train_5.jpg
|
+---script
| create_qrc.py
|
\---src(项目源码目录)
+---conf(配置目录)
| icon_conf.py
| style_conf.py
| system_conf.py
| test_data.py
| __init__.py
|
+---engine(引擎目录)
| engines.py
| __init__.py
|
+---resource(资源目录)
| | resource.qrc
| | resource_rc.py
| | __init__.py
| |
| +---imgs
| | ai.gif
| | ai.svg
| | bg.jpeg
| | login_gif.gif
| |
| \---js
| echarts.min.js
|
+---threads(线程目录)
| main_threads.py
| signal_bus.py
| __init__.py
|
+---utils(工具目录)
| custom_utils.py
| user_manager.py
| __init__.py
|
\---widgets(核心组件目录)
base_widgets.py
custom_pages.py
custom_widgets.py
main_page.py
unique_widgets.py
__init__.py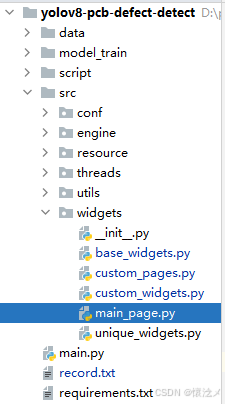
3.项目启动
本系统的项目启动十分简单:在安装好所有相关依赖之后,直接执行 main.py 文件,即可自动打开系统的登录注册页面。用户进入该页面后,通过输入匹配的用户名和密码完成登录操作。为方便初次体验,系统内置了一个默认账号,用户名为 admin,密码也为 admin,用户可以直接使用这组账号进行快速登录。当用户成功登录后,系统主界面会完整展示出来,而之前的登录注册页面则会自动隐藏,从而为用户提供清晰、流畅的操作体验。
4.往期优秀作品
六.总结
本程序主要实现了一个集成化的目标检测与分析平台,提供图像检测、视频检测(支持本地视频、实时流媒体和摄像头)等多种输入方式,并能够实时展示检测结果与目标数量统计。同时,系统支持检测结果的保存与历史记录管理,可将数据导出为 CSV、Excel 或 TXT 文件,方便后续使用。
此外,程序还提供结果可视化展示功能,以及基于 AI 的智能分析评估功能,用于对检测数据进行进一步解读。用户可以通过界面进行模型参数配置、切换不同功能页面,并完成登录、登出等基本操作。整体功能涵盖数据采集、检测处理、结果展示、数据管理与智能分析等完整流程。
本次给大家介绍了我使用PyQt5+YOLOv8+DeepSeek的钢材焊接缺陷检测系统,本系统功能强大,支持多种数据源输入,包含多种用户交互按钮以及模式,内置数据可视化方案、大模型AI加持,是您学习、工作使用的不错选择!
需要代码的朋友可以点击箭头下方的二维码加我好友,欢迎您了解!
如需帮助请私聊博主!