摘要
现有前馈式3D重建模型(如VGGT、DUSt3R、MASt3R)虽然摆脱了后优化流程,但模型规模和数据规模对重建精度的影响尚未被系统探索。VGGT-Ω 在架构、数据和训练三个维度同时做了规模化改进:引入 Register Attention 替代部分全局注意力以降低计算开销,用单一 Dense Head + Pixel Shuffle 替代多头 DPT 以节省显存,并构建了覆盖4M序列(含动态场景)的高质量标注流水线。最终在 Sintel 上相机位姿估计 AUC@3° 从22.5提升到40.0(+77%),深度估计 δ 1.25 \delta_{1.25} δ1.25 从86.1提升到93.5,且推理速度比 MegaSaM 快 50 倍。
论文 :VGGT-Ω
代码 :vggt-omega
一、问题背景:前馈重建模型能否像LLM一样Scale?
VGGT 系列已经证明:纯前馈 Transformer 可以在不做 Bundle Adjustment 的情况下超越传统 SfM pipeline。但一个关键问题悬而未决------3D重建模型是否存在 Scaling Law?
LLM 领域已经确立了明确的幂律关系(模型越大、数据越多,loss 越低)。3D视觉领域面临的独特挑战:
- 数据标注成本极高:每条序列需要精确相机位姿 + 稠密深度,COLMAP 级别的标注流水线扩展到百万级序列代价巨大
- 动态场景处理困难:互联网视频绝大多数包含运动物体,传统多视图几何假设静态场景
- 全局注意力的二次复杂度:帧数增加时,跨帧注意力的计算和内存开销爆炸式增长
VGGT-Ω 针对这三个瓶颈给出了系统性解决方案。
二、核心方法
2.1 整体架构:DINOv3 Backbone + 交替注意力 + 单一Dense Head
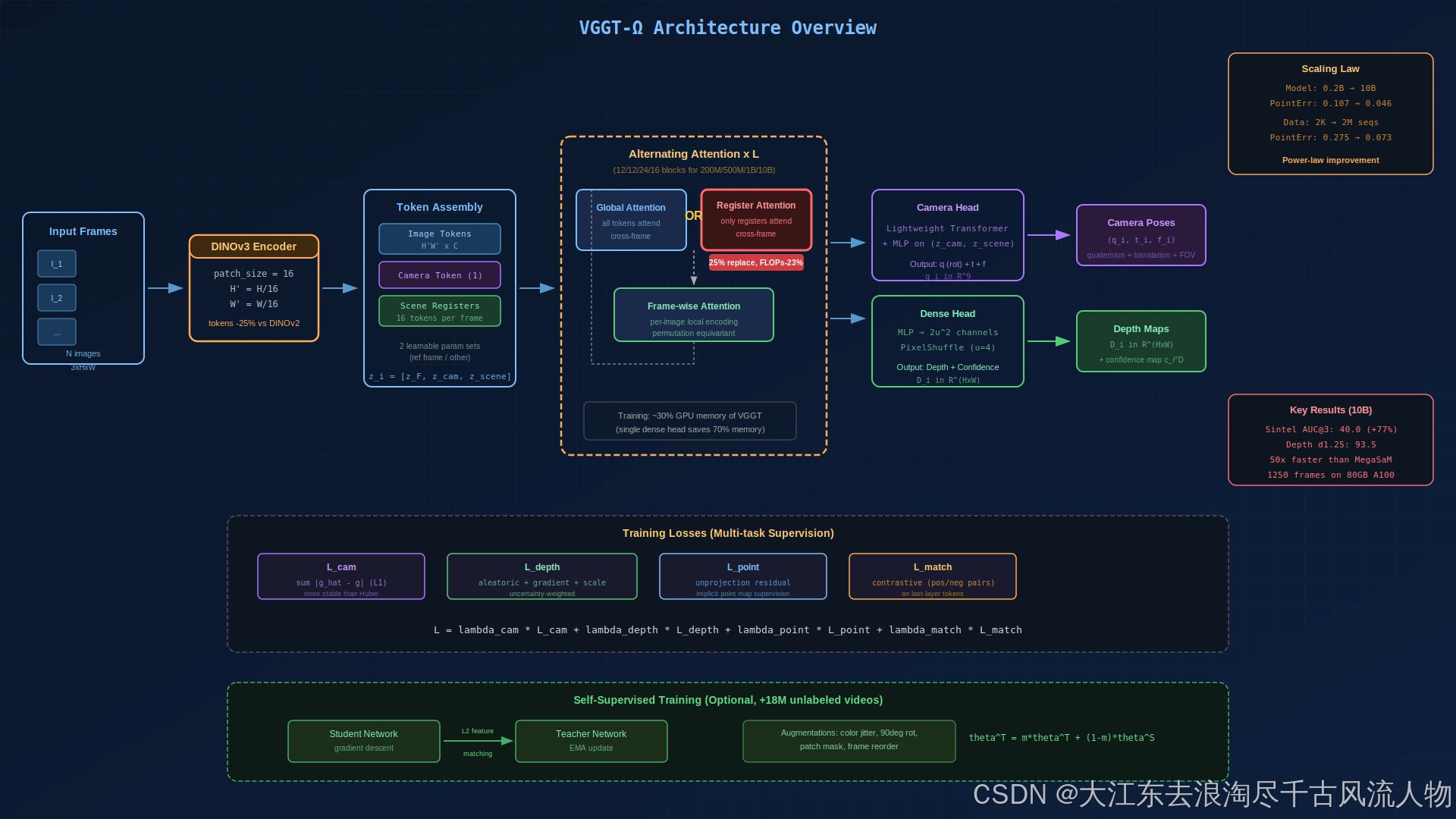
图 1:VGGT-Ω 系统整体架构。重点看红色高亮的 Register Attention 模块------它用仅 16 个 token 的跨帧交互替代了全量全局注意力,节省 23% FLOPs。右侧标注了关键性能数据。重绘自 design skill。
#mermaid-svg-MomQdIRD0HnlHbfb{font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}@keyframes edge-animation-frame{from{stroke-dashoffset:0;}}@keyframes dash{to{stroke-dashoffset:0;}}#mermaid-svg-MomQdIRD0HnlHbfb .edge-animation-slow{stroke-dasharray:9,5!important;stroke-dashoffset:900;animation:dash 50s linear infinite;stroke-linecap:round;}#mermaid-svg-MomQdIRD0HnlHbfb .edge-animation-fast{stroke-dasharray:9,5!important;stroke-dashoffset:900;animation:dash 20s linear infinite;stroke-linecap:round;}#mermaid-svg-MomQdIRD0HnlHbfb .error-icon{fill:#552222;}#mermaid-svg-MomQdIRD0HnlHbfb .error-text{fill:#552222;stroke:#552222;}#mermaid-svg-MomQdIRD0HnlHbfb .edge-thickness-normal{stroke-width:1px;}#mermaid-svg-MomQdIRD0HnlHbfb .edge-thickness-thick{stroke-width:3.5px;}#mermaid-svg-MomQdIRD0HnlHbfb .edge-pattern-solid{stroke-dasharray:0;}#mermaid-svg-MomQdIRD0HnlHbfb .edge-thickness-invisible{stroke-width:0;fill:none;}#mermaid-svg-MomQdIRD0HnlHbfb .edge-pattern-dashed{stroke-dasharray:3;}#mermaid-svg-MomQdIRD0HnlHbfb .edge-pattern-dotted{stroke-dasharray:2;}#mermaid-svg-MomQdIRD0HnlHbfb .marker{fill:#333333;stroke:#333333;}#mermaid-svg-MomQdIRD0HnlHbfb .marker.cross{stroke:#333333;}#mermaid-svg-MomQdIRD0HnlHbfb svg{font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;}#mermaid-svg-MomQdIRD0HnlHbfb p{margin:0;}#mermaid-svg-MomQdIRD0HnlHbfb .label{font-family:"trebuchet ms",verdana,arial,sans-serif;color:#333;}#mermaid-svg-MomQdIRD0HnlHbfb .cluster-label text{fill:#333;}#mermaid-svg-MomQdIRD0HnlHbfb .cluster-label span{color:#333;}#mermaid-svg-MomQdIRD0HnlHbfb .cluster-label span p{background-color:transparent;}#mermaid-svg-MomQdIRD0HnlHbfb .label text,#mermaid-svg-MomQdIRD0HnlHbfb span{fill:#333;color:#333;}#mermaid-svg-MomQdIRD0HnlHbfb .node rect,#mermaid-svg-MomQdIRD0HnlHbfb .node circle,#mermaid-svg-MomQdIRD0HnlHbfb .node ellipse,#mermaid-svg-MomQdIRD0HnlHbfb .node polygon,#mermaid-svg-MomQdIRD0HnlHbfb .node path{fill:#ECECFF;stroke:#9370DB;stroke-width:1px;}#mermaid-svg-MomQdIRD0HnlHbfb .rough-node .label text,#mermaid-svg-MomQdIRD0HnlHbfb .node .label text,#mermaid-svg-MomQdIRD0HnlHbfb .image-shape .label,#mermaid-svg-MomQdIRD0HnlHbfb .icon-shape .label{text-anchor:middle;}#mermaid-svg-MomQdIRD0HnlHbfb .node .katex path{fill:#000;stroke:#000;stroke-width:1px;}#mermaid-svg-MomQdIRD0HnlHbfb .rough-node .label,#mermaid-svg-MomQdIRD0HnlHbfb .node .label,#mermaid-svg-MomQdIRD0HnlHbfb .image-shape .label,#mermaid-svg-MomQdIRD0HnlHbfb .icon-shape .label{text-align:center;}#mermaid-svg-MomQdIRD0HnlHbfb .node.clickable{cursor:pointer;}#mermaid-svg-MomQdIRD0HnlHbfb .root .anchor path{fill:#333333!important;stroke-width:0;stroke:#333333;}#mermaid-svg-MomQdIRD0HnlHbfb .arrowheadPath{fill:#333333;}#mermaid-svg-MomQdIRD0HnlHbfb .edgePath .path{stroke:#333333;stroke-width:2.0px;}#mermaid-svg-MomQdIRD0HnlHbfb .flowchart-link{stroke:#333333;fill:none;}#mermaid-svg-MomQdIRD0HnlHbfb .edgeLabel{background-color:rgba(232,232,232, 0.8);text-align:center;}#mermaid-svg-MomQdIRD0HnlHbfb .edgeLabel p{background-color:rgba(232,232,232, 0.8);}#mermaid-svg-MomQdIRD0HnlHbfb .edgeLabel rect{opacity:0.5;background-color:rgba(232,232,232, 0.8);fill:rgba(232,232,232, 0.8);}#mermaid-svg-MomQdIRD0HnlHbfb .labelBkg{background-color:rgba(232, 232, 232, 0.5);}#mermaid-svg-MomQdIRD0HnlHbfb .cluster rect{fill:#ffffde;stroke:#aaaa33;stroke-width:1px;}#mermaid-svg-MomQdIRD0HnlHbfb .cluster text{fill:#333;}#mermaid-svg-MomQdIRD0HnlHbfb .cluster span{color:#333;}#mermaid-svg-MomQdIRD0HnlHbfb div.mermaidTooltip{position:absolute;text-align:center;max-width:200px;padding:2px;font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:12px;background:hsl(80, 100%, 96.2745098039%);border:1px solid #aaaa33;border-radius:2px;pointer-events:none;z-index:100;}#mermaid-svg-MomQdIRD0HnlHbfb .flowchartTitleText{text-anchor:middle;font-size:18px;fill:#333;}#mermaid-svg-MomQdIRD0HnlHbfb rect.text{fill:none;stroke-width:0;}#mermaid-svg-MomQdIRD0HnlHbfb .icon-shape,#mermaid-svg-MomQdIRD0HnlHbfb .image-shape{background-color:rgba(232,232,232, 0.8);text-align:center;}#mermaid-svg-MomQdIRD0HnlHbfb .icon-shape p,#mermaid-svg-MomQdIRD0HnlHbfb .image-shape p{background-color:rgba(232,232,232, 0.8);padding:2px;}#mermaid-svg-MomQdIRD0HnlHbfb .icon-shape .label rect,#mermaid-svg-MomQdIRD0HnlHbfb .image-shape .label rect{opacity:0.5;background-color:rgba(232,232,232, 0.8);fill:rgba(232,232,232, 0.8);}#mermaid-svg-MomQdIRD0HnlHbfb .label-icon{display:inline-block;height:1em;overflow:visible;vertical-align:-0.125em;}#mermaid-svg-MomQdIRD0HnlHbfb .node .label-icon path{fill:currentColor;stroke:revert;stroke-width:revert;}#mermaid-svg-MomQdIRD0HnlHbfb :root{--mermaid-font-family:"trebuchet ms",verdana,arial,sans-serif;} Global/Register
Frame-wise
输入帧 I1...IN
DINOv3 Encoder
Image Tokens + Camera Token + 16 Scene Registers
交替注意力 x L
跨帧信息交换
帧内局部编码
Camera Head: MLP
Depth Head: MLP + PixelShuffle
核心数据流:
- 输入 : N N N 张图像 I i ∈ R 3 × H × W I_i \in \mathbb{R}^{3 \times H \times W} Ii∈R3×H×W
- Tokenization :DINOv3(patch size 16)产出 z i F ∈ R H ′ W ′ × C \mathbf{z}_i^F \in \mathbb{R}^{H'W' \times C} ziF∈RH′W′×C,加上 1 个 camera token z i cam \mathbf{z}_i^{\text{cam}} zicam 和 16 个 scene registers z i scene \mathbf{z}_i^{\text{scene}} ziscene
- 输出 :深度图 D i ∈ R H × W D_i \in \mathbb{R}^{H \times W} Di∈RH×W,相机参数 g i = ( q i , t i , f i ) ∈ R 9 \mathbf{g}_i = (\mathbf{q}_i, \mathbf{t}_i, \mathbf{f}_i) \in \mathbb{R}^9 gi=(qi,ti,fi)∈R9(四元数旋转 + 平移 + FOV)
与 VGGT 的关键差异:
| 改动 | VGGT | VGGT-Ω |
|---|---|---|
| Backbone | DINOv2 (patch=14) | DINOv3 (patch=16, token数少25%) |
| 注意力 | 全局 + 帧内交替 | 25% 全局层替换为 Register Attention |
| Dense Head | 多个 DPT head(depth/point/track) | 单一 Dense Head + multi-task loss |
| 训练数据 | ~267K 序列 | 4M 序列(15x),含动态场景 |
| 自监督 | 无 | Teacher-Student with EMA |
2.2 Register Attention:用16个token聚合全局信息
VGGT 的全局注意力层开销巨大(所有帧的所有 token 互相 attend),但注意力矩阵实际上非常稀疏(参见论文 Fig.3)。这意味着大部分 token 对之间的信息交换是冗余的。
Register Attention 的核心思想:只让 register tokens 参与跨帧自注意力,然后通过帧内注意力把全局信息分发回 image tokens。
形式化表达:
z ′ = attn scene ( z ) \mathbf{z}' = \text{attn}_{\text{scene}}(\mathbf{z}) z′=attnscene(z)
其中 ( z 1 scene ′ , ... , z N scene ′ ) = attn ( z 1 scene , ... , z N scene ) (\mathbf{z}_1^{\text{scene}'}, \ldots, \mathbf{z}_N^{\text{scene}'}) = \text{attn}(\mathbf{z}_1^{\text{scene}}, \ldots, \mathbf{z}_N^{\text{scene}}) (z1scene′,...,zNscene′)=attn(z1scene,...,zNscene),即只有 register tokens 参与跨帧 self-attention。随后在帧内注意力层中,更新后的 registers 与 image tokens 交互,完成信息再分发。
实际效果:替换 25% 全局注意力层为 Register Attention,性能几乎不变(point error 0.073 vs 0.071),FLOPs 减少 23%,训练显存减少 16%。如果替换全部全局注意力层,FLOPs 降到原来的 6%,但性能退化到原始 VGGT 水平。
2.3 单一Dense Head + Pixel Shuffle
VGGT 为 depth/point map/tracking 各用一个 DPT head,高分辨率卷积层消耗大量 GPU 显存。VGGT-Ω 的解决方案:
- 只保留一个 Dense Head(预测 depth),通过 multi-task loss 隐式监督 point map 和 matching
- 替换 DPT 高分辨率卷积 为 MLP + Pixel Shuffle:输出 2 u 2 2u^2 2u2 通道( u = 4 u=4 u=4),shuffle 到 ( u H ′ ) × ( u W ′ ) × 2 (uH') \times (uW') \times 2 (uH′)×(uW′)×2(depth + confidence)
这三项改动合计节省 70% 训练显存,推理速度也有提升。
2.4 训练损失:四项联合监督
L = λ cam L cam + λ depth L depth + λ point L point + λ match L match \mathcal{L} = \lambda_{\text{cam}} \mathcal{L}{\text{cam}} + \lambda{\text{depth}} \mathcal{L}{\text{depth}} + \lambda{\text{point}} \mathcal{L}{\text{point}} + \lambda{\text{match}} \mathcal{L}_{\text{match}} L=λcamLcam+λdepthLdepth+λpointLpoint+λmatchLmatch
Camera loss : ℓ 1 \ell_1 ℓ1 距离(比 VGGT 的 Huber loss 更稳定)
L cam = ∑ i = 1 N ∣ g ^ i − g i ∣ \mathcal{L}{\text{cam}} = \sum{i=1}^{N} |\hat{\mathbf{g}}_i - \mathbf{g}_i| Lcam=i=1∑N∣g^i−gi∣
Depth loss:含 aleatoric uncertainty + 梯度一致性 + 相对尺度校正
L depth = ∑ i = 1 N ∥ c i D ⊙ ( 1 + D i − 1 ) ⊙ e i ∥ + ∥ c i D ⊙ ∇ e i ∥ − α ∑ i = 1 N log c i D \mathcal{L}{\text{depth}} = \sum{i=1}^{N} \left \\\|c_i\^D \\odot (1 + D_i\^{-1}) \\odot e_i\\\| + \\\|c_i\^D \\odot \\nabla e_i\\\| \\right - \alpha \sum_{i=1}^{N} \log c_i^D Ldepth=i=1∑N∥ciD⊙(1+Di−1)⊙ei∥+∥ciD⊙∇ei∥−αi=1∑NlogciD
其中 e i = D ^ i − D i e_i = \hat{D}_i - D_i ei=D^i−Di, c i D c_i^D ciD 为预测的不确定度图。
Point loss:将 depth 反投影到 3D,计算重投影残差,等效于通过 unprojection 间接监督 point map。
Matching loss:对最后一层 attention 的 token 特征做对比学习,正样本为对应同一3D点的token对,负样本随机配对。
L match = E pos − log σ ( s ) + E neg − log ( 1 − σ ( s ) ) \mathcal{L}{\text{match}} = \mathbb{E}{\text{pos}}-\\log \\sigma(s) + \mathbb{E}_{\text{neg}}-\\log(1 - \\sigma(s)) Lmatch=Epos−logσ(s)+Eneg−log(1−σ(s))
2.5 自监督训练:Teacher-Student 蒸馏
为利用海量无标注视频(18M),采用 DINO 风格的 teacher-student 协议:
- Teacher 和 Student 均从有监督 VGGT-Ω checkpoint 初始化
- 相同输入施加不同增强(color jitter, 90° rotation, patch masking, frame reorder)
- Student 通过 ℓ 2 \ell_2 ℓ2 feature-matching loss 对齐 teacher 的多层特征分布
- Teacher 通过 EMA 更新: θ T ← m θ T + ( 1 − m ) θ S \theta^T \leftarrow m\theta^T + (1-m)\theta^S θT←mθT+(1−m)θS
- Camera/depth head 冻结,防止自监督过程中预测坍塌
效果:将 10% 有监督步替换为自监督步,point error 从 0.073 降到 0.070,OOD 泛化能力明显改善。
2.6 数据标注流水线:从40M视频到0.8M高质量序列
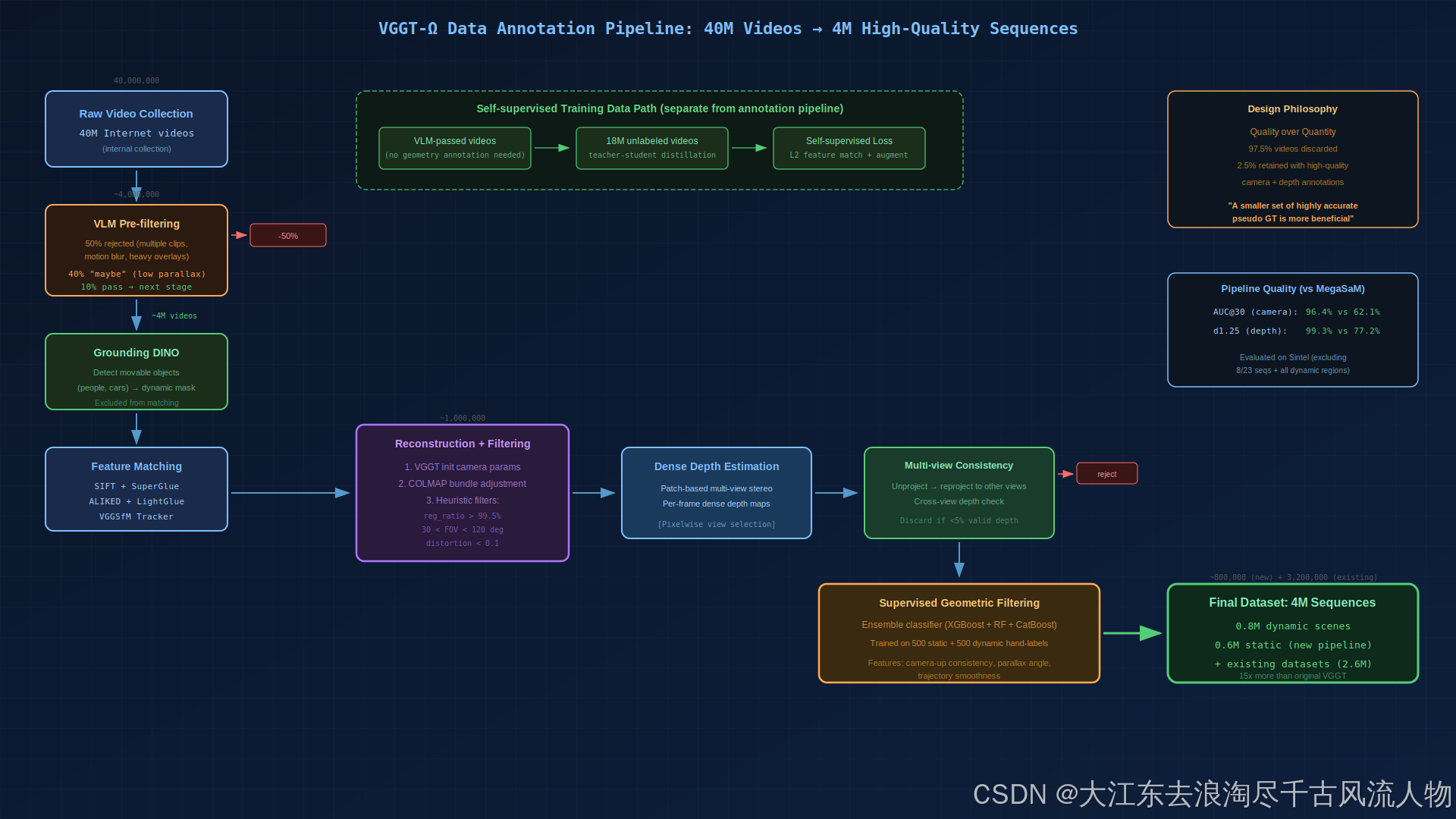
图 2:数据标注流水线全貌。重点看右上角的设计哲学------97.5% 视频被丢弃,只保留 2.5% 高质量标注。底部橙色高亮的 Supervised Geometric Filtering 是最后一道质量关卡。重绘自 design skill。
这是 VGGT-Ω 能做到 15x 数据量的关键基础设施:
#mermaid-svg-5lJFQ0qar060Rsc3{font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}@keyframes edge-animation-frame{from{stroke-dashoffset:0;}}@keyframes dash{to{stroke-dashoffset:0;}}#mermaid-svg-5lJFQ0qar060Rsc3 .edge-animation-slow{stroke-dasharray:9,5!important;stroke-dashoffset:900;animation:dash 50s linear infinite;stroke-linecap:round;}#mermaid-svg-5lJFQ0qar060Rsc3 .edge-animation-fast{stroke-dasharray:9,5!important;stroke-dashoffset:900;animation:dash 20s linear infinite;stroke-linecap:round;}#mermaid-svg-5lJFQ0qar060Rsc3 .error-icon{fill:#552222;}#mermaid-svg-5lJFQ0qar060Rsc3 .error-text{fill:#552222;stroke:#552222;}#mermaid-svg-5lJFQ0qar060Rsc3 .edge-thickness-normal{stroke-width:1px;}#mermaid-svg-5lJFQ0qar060Rsc3 .edge-thickness-thick{stroke-width:3.5px;}#mermaid-svg-5lJFQ0qar060Rsc3 .edge-pattern-solid{stroke-dasharray:0;}#mermaid-svg-5lJFQ0qar060Rsc3 .edge-thickness-invisible{stroke-width:0;fill:none;}#mermaid-svg-5lJFQ0qar060Rsc3 .edge-pattern-dashed{stroke-dasharray:3;}#mermaid-svg-5lJFQ0qar060Rsc3 .edge-pattern-dotted{stroke-dasharray:2;}#mermaid-svg-5lJFQ0qar060Rsc3 .marker{fill:#333333;stroke:#333333;}#mermaid-svg-5lJFQ0qar060Rsc3 .marker.cross{stroke:#333333;}#mermaid-svg-5lJFQ0qar060Rsc3 svg{font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;}#mermaid-svg-5lJFQ0qar060Rsc3 p{margin:0;}#mermaid-svg-5lJFQ0qar060Rsc3 .label{font-family:"trebuchet ms",verdana,arial,sans-serif;color:#333;}#mermaid-svg-5lJFQ0qar060Rsc3 .cluster-label text{fill:#333;}#mermaid-svg-5lJFQ0qar060Rsc3 .cluster-label span{color:#333;}#mermaid-svg-5lJFQ0qar060Rsc3 .cluster-label span p{background-color:transparent;}#mermaid-svg-5lJFQ0qar060Rsc3 .label text,#mermaid-svg-5lJFQ0qar060Rsc3 span{fill:#333;color:#333;}#mermaid-svg-5lJFQ0qar060Rsc3 .node rect,#mermaid-svg-5lJFQ0qar060Rsc3 .node circle,#mermaid-svg-5lJFQ0qar060Rsc3 .node ellipse,#mermaid-svg-5lJFQ0qar060Rsc3 .node polygon,#mermaid-svg-5lJFQ0qar060Rsc3 .node path{fill:#ECECFF;stroke:#9370DB;stroke-width:1px;}#mermaid-svg-5lJFQ0qar060Rsc3 .rough-node .label text,#mermaid-svg-5lJFQ0qar060Rsc3 .node .label text,#mermaid-svg-5lJFQ0qar060Rsc3 .image-shape .label,#mermaid-svg-5lJFQ0qar060Rsc3 .icon-shape .label{text-anchor:middle;}#mermaid-svg-5lJFQ0qar060Rsc3 .node .katex path{fill:#000;stroke:#000;stroke-width:1px;}#mermaid-svg-5lJFQ0qar060Rsc3 .rough-node .label,#mermaid-svg-5lJFQ0qar060Rsc3 .node .label,#mermaid-svg-5lJFQ0qar060Rsc3 .image-shape .label,#mermaid-svg-5lJFQ0qar060Rsc3 .icon-shape .label{text-align:center;}#mermaid-svg-5lJFQ0qar060Rsc3 .node.clickable{cursor:pointer;}#mermaid-svg-5lJFQ0qar060Rsc3 .root .anchor path{fill:#333333!important;stroke-width:0;stroke:#333333;}#mermaid-svg-5lJFQ0qar060Rsc3 .arrowheadPath{fill:#333333;}#mermaid-svg-5lJFQ0qar060Rsc3 .edgePath .path{stroke:#333333;stroke-width:2.0px;}#mermaid-svg-5lJFQ0qar060Rsc3 .flowchart-link{stroke:#333333;fill:none;}#mermaid-svg-5lJFQ0qar060Rsc3 .edgeLabel{background-color:rgba(232,232,232, 0.8);text-align:center;}#mermaid-svg-5lJFQ0qar060Rsc3 .edgeLabel p{background-color:rgba(232,232,232, 0.8);}#mermaid-svg-5lJFQ0qar060Rsc3 .edgeLabel rect{opacity:0.5;background-color:rgba(232,232,232, 0.8);fill:rgba(232,232,232, 0.8);}#mermaid-svg-5lJFQ0qar060Rsc3 .labelBkg{background-color:rgba(232, 232, 232, 0.5);}#mermaid-svg-5lJFQ0qar060Rsc3 .cluster rect{fill:#ffffde;stroke:#aaaa33;stroke-width:1px;}#mermaid-svg-5lJFQ0qar060Rsc3 .cluster text{fill:#333;}#mermaid-svg-5lJFQ0qar060Rsc3 .cluster span{color:#333;}#mermaid-svg-5lJFQ0qar060Rsc3 div.mermaidTooltip{position:absolute;text-align:center;max-width:200px;padding:2px;font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:12px;background:hsl(80, 100%, 96.2745098039%);border:1px solid #aaaa33;border-radius:2px;pointer-events:none;z-index:100;}#mermaid-svg-5lJFQ0qar060Rsc3 .flowchartTitleText{text-anchor:middle;font-size:18px;fill:#333;}#mermaid-svg-5lJFQ0qar060Rsc3 rect.text{fill:none;stroke-width:0;}#mermaid-svg-5lJFQ0qar060Rsc3 .icon-shape,#mermaid-svg-5lJFQ0qar060Rsc3 .image-shape{background-color:rgba(232,232,232, 0.8);text-align:center;}#mermaid-svg-5lJFQ0qar060Rsc3 .icon-shape p,#mermaid-svg-5lJFQ0qar060Rsc3 .image-shape p{background-color:rgba(232,232,232, 0.8);padding:2px;}#mermaid-svg-5lJFQ0qar060Rsc3 .icon-shape .label rect,#mermaid-svg-5lJFQ0qar060Rsc3 .image-shape .label rect{opacity:0.5;background-color:rgba(232,232,232, 0.8);fill:rgba(232,232,232, 0.8);}#mermaid-svg-5lJFQ0qar060Rsc3 .label-icon{display:inline-block;height:1em;overflow:visible;vertical-align:-0.125em;}#mermaid-svg-5lJFQ0qar060Rsc3 .node .label-icon path{fill:currentColor;stroke:revert;stroke-width:revert;}#mermaid-svg-5lJFQ0qar060Rsc3 :root{--mermaid-font-family:"trebuchet ms",verdana,arial,sans-serif;} 40M 互联网视频
VLM预过滤: 50%不可重建
10%进入下一步: ~4M
Grounding DINO: 动态区域检测
特征匹配: SIFT+SuperGlue+ALIKED+LightGlue
VGGT初始化 + COLMAP BA
Multi-view一致性检查
Supervised几何过滤: XGBoost+RF+CatBoost
0.8M动态 + 0.6M静态序列
关键设计决策:
- 质量优先于数量:宁可丢弃 97.5% 视频,也要保证剩余 2.5% 标注高度准确
- 动态场景处理:Grounding DINO 检测可运动物体 → 排除其特征匹配 → 允许保留动态视频的相机运动标注
- 多级过滤:手动标注 500 静态 + 500 动态序列训练 ensemble classifier(XGBoost + Random Forest + CatBoost),自动过滤低质量重建
三、实验分析
3.1 相机位姿估计
| Method | 7Scenes AUC@3° | Sintel AUC@3° | TUM-Dynamic AUC@3° |
|---|---|---|---|
| VGGT | 10.9 | 15.0 | 15.4 |
| MegaSaM | 10.6 | 22.5 | 16.6 |
| DA3 | 18.7 | 14.8 | 16.2 |
| Ours-1B | 29.6 | 35.3 | 30.2 |
| Ours-10B | 36.4 | 40.0 | 36.4 |
Sintel 上从 22.5 到 40.0,相对提升 77%。这是一个动态场景数据集,说明 VGGT-Ω 的数据流水线有效解决了动态场景问题。
3.2 深度估计
| Method | Sintel δ 1.25 \delta_{1.25} δ1.25↑ | Sintel AbsRel↓ | TUM-Dynamic δ 1.25 \delta_{1.25} δ1.25↑ |
|---|---|---|---|
| MegaSaM | 74.1 | 0.207 | 92.9 |
| DA3 | 86.1 | 0.118 | 94.3 |
| Ours-10B | 93.5 | 0.081 | 98.3 |
3.3 Scaling Law 验证
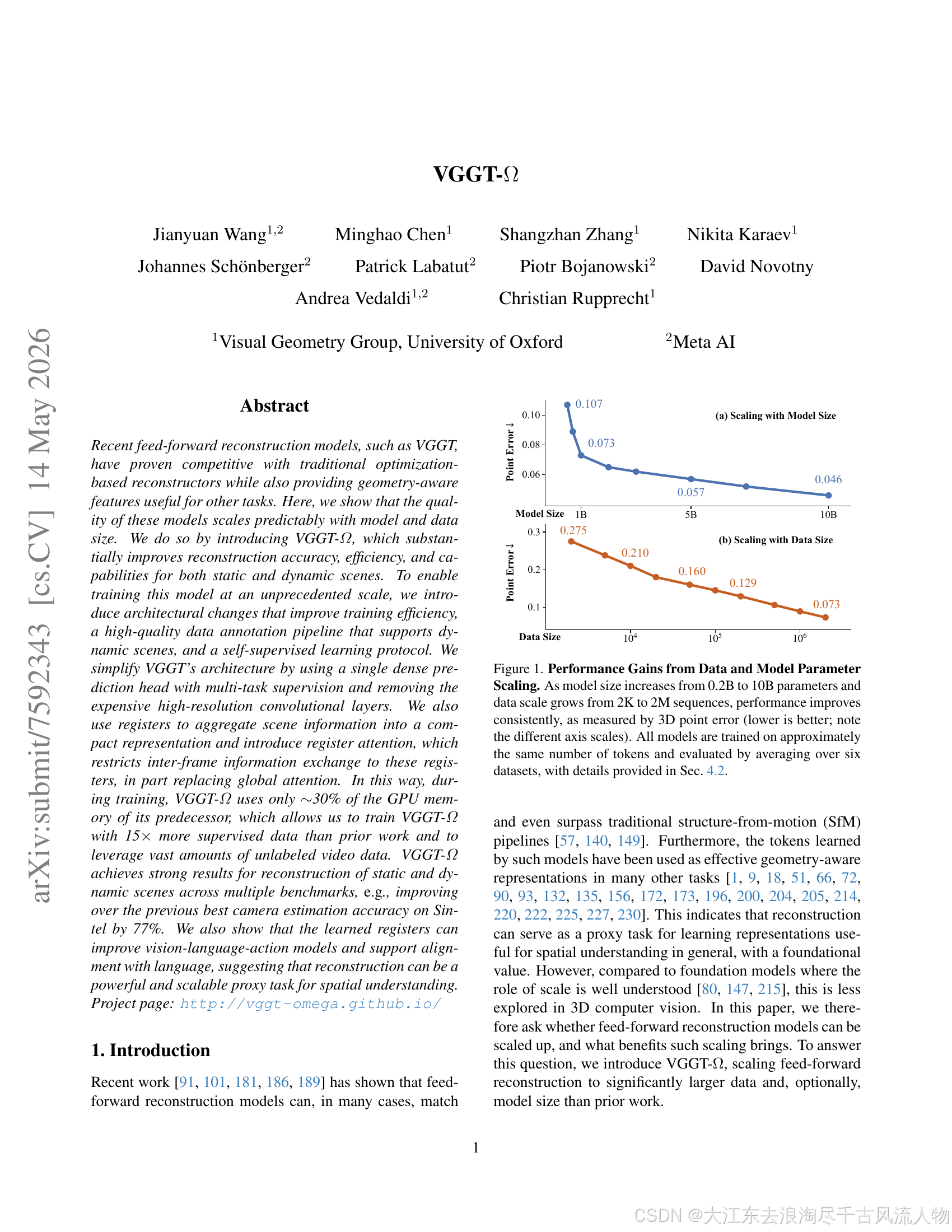
图 3:论文 Figure 1 原图------模型参数(0.2B→10B)和数据规模(2K→2M)的 Scaling 曲线。两条曲线均呈幂律下降,证实前馈重建模型存在 Scaling Law。来源:VGGT-Ω Fig 1。
论文 Fig.1 揭示两条清晰的 Scaling 曲线:
- Model scaling:0.2B → 1B → 5B → 10B,point error 从 0.107 → 0.073 → 0.057 → 0.046
- Data scaling:2K → 10K → 100K → 1M → 2M 序列,point error 从 0.275 → 0.210 → 0.160 → 0.129 → 0.073
两条曲线均呈现清晰的幂律下降趋势,强烈暗示前馈重建模型确实遵循 Scaling Law。
3.4 推理效率
在单张 80GB A100 GPU 上:
- VGGT-Ω 和 VGGT 均可处理 ~1000+ 帧(DA3 在 ~750 帧时 OOM)
- Register Attention Only 变体:1000 帧推理时间从 240s 降到 11.7s
- 内存增长近似线性(得益于 flash attention v2 的 tiled streaming 实现)
四、下游应用:Registers 作为几何感知表征

图 4:VGGT-Ω 在动态场景上的重建 Demo(视频海报截图)。模型能同时处理静态背景和运动前景,无需显式运动分割。来源:vggt-omega.github.io 项目页。
4.1 机器人 VLA 增强
将 VGGT-Ω 的 scene registers 拼接到 OpenVLA-OFT 的输入 token 中:
| Method | LIBERO Average SR |
|---|---|
| OpenVLA-OFT | 97.1% |
| + Our Frozen Scene Tokens | 98.5% |
冻结 VGGT-Ω 参数,仅用 registers 作为额外输入,所有 LIBERO 任务一致提升。
4.2 语言对齐
通过 CLIP 风格的对比学习,将 registers 与自然语言描述对齐:
- Top-1 retrieval accuracy: 76.8%(VLM embedding)/ 47.5%(zero-shot text-only)
- Top-3 accuracy: 97.0% / 77.8%
这说明 registers 自发地编码了高层语义信息(场景布局、物体类别),不仅仅是低层几何。
五、深入洞察:信息存储在哪里?
通过 Model Souping(直接平均 VGGT 和 VGGT-Ω 权重子集)发现:
| 权重子集 | 融合后效果 |
|---|---|
| FFN in frame attention blocks | 深度/FOV信息主要存储于此 |
| Q/K/V projection weights | 融合后无负面效果,说明相机外参编码在更高层 |
| Frame-wise attention blocks | 控制对可变帧数的泛化能力 |
Motion Awareness:对中间层 token 做 PCA + k-means 聚类,发现模型在无任何运动监督的情况下自发学会了分割运动物体。早期层(layer 4)分割最干净,深层(layer 23)更偏向语义级别的 grouping。
小结
VGGT-Ω 最核心的贡献不是某个单点技巧,而是系统性地回答了"前馈重建模型能否 scale"这个问题------答案是肯定的,且 Scaling Law 的形态与 LLM 类似。
从工程角度看,三个设计决策特别值得关注:
-
Register Attention 的 trade-off:25% 替换几乎无损,100% 替换 FLOPs 降到 6% 但精度退回 VGGT 水平。这意味着帧间全局信息交换确实重要,但大部分可以通过 16 个 register 瓶颈来完成。对于端侧部署,100% register attention + 蒸馏是值得探索的方向。
-
单头 vs 多头的选择:放弃 point map/tracking 的直接预测头,改用隐式监督(multi-task loss),换来了 70% 显存节省和更好的 scaling 特性。这验证了"强 backbone + 简单 head"范式在3D领域的有效性。
-
数据流水线的保守策略:97.5% 的视频被丢弃,这在追求"更多数据"的直觉下显得反直觉。但论文通过对比实验证明:高质量的 2.5% 比噪声满天的 100% 有效得多。对于自建数据集的团队,这是一个重要的工程参考。
局限性:论文未提供单张图像的重建能力对比(VGGT-Ω 至少需要2帧),10B 模型的推理延迟对实时应用仍然偏高(单帧约 100ms 级别),且动态场景下 point map 质量没有单独评估。