论文总结
1. 解决了什么问题?
-
核心问题 :多模态深度学习在实际部署中常遇到模态缺失 。现有方法要么丢弃缺失模态 (损失任务相关信息),要么恢复缺失模态 (可能引入低质量或语义错配的噪声),导致 "丢弃-恢复困境"。
-
目标 :在推理时自适应地筛选出可靠、任务相关的恢复模态并融合,同时避免不可靠模态的干扰。
2. 怎么解决的?(提出的 DyMo 框架)
-
动态选择算法 :基于增量式任务相关信息增益 ,迭代选取最有价值的恢复模态。由于推理时无法直接估计信息量,理论上证明降低任务损失可提高任务相关信息的下界 ,从而用测试时交叉熵损失下降作为信息增益的代理。
-
新奖励函数(MTIR) :根据加入模态后表示向量与类原型的距离变化计算奖励,并引入类内相似度校准(ICS) 提高可靠性。
-
灵活的多模态网络架构:支持任意模态组合的输入,包含模态专属编码器、多模态Transformer和分类器。
-
定制训练策略:通过采样多种模态子集进行训练,使模型对任意模态组合鲁棒。
3. 效果如何?
-
在 PolyMNIST、MST、CelebA、DVM、UK Biobank 等5个不同模态数据集上显著优于现有静态/动态融合方法及不完整多模态学习方法。
-
尤其在严重缺失场景(如80%模态缺失)下优势明显。
-
消融实验验证了迭代选择、校准项等各组件有效。
-
对不同恢复方法(MoPoE、MMVAE+、CMVAE、TIP、IMI)均表现鲁棒。
4、和Retrieval-Augmented Dynamic Prompt Tuning for Incomplete Multimodal Learning对比:
之前看论文看到Retrieval-Augmented Dynamic Prompt Tuning for Incomplete Multimodal Learning这篇论文也是针对不完整多模态数据去处理的,然后我就用AI把这两篇论文做了下对比:


摘要
多模深度学习(MDL)在多个领域取得了显著成功,但其实际应用常常受限于不完整的多模态数据。现有不完整的MDL方法要么丢弃缺失模态,冒丢失宝贵任务相关信息的风险,要么恢复它们,可能引入无关噪声,导致丢弃-补缺困境。为解决这一困境,本文提出了DyMo,一种新的推理时间动态模态选择框架,自适应识别并融合可靠的恢复模态,全面探索任务相关信息,超越传统的丢弃或补值范式。DyMo的核心是一种新颖选择算法,最大化每个测试样本多模态任务相关信息。由于数据分布未知,测试时直接估计此类信息难以处理,我们理论上建立了信息与任务丢失之间的联系,任务丢失在推断时作为可处理代理计算。基于此,提出了一种新颖的原则性奖励函数来指导模态选择。此外,我们设计了兼容任意模态组合的灵活多模态网络架构,并结合了针对稳健表示学习的定制训练策略。在多种自然和医学图像数据集上的广泛实验表明,DyMo在各种缺失数据场景下显著优于最先进的不完全/动态MDL方法。我们的代码可在 https://github.com//siyi-wind/DyMo 获取。
引言
多模态/多视角深度学习(MDL)整合多种模态/视角,实现类似人类的多感官感知,近年来在医疗保健(Acosta等,2022)、市场营销(Liu等,2024)和具身智能(Duan等,2022)等多个领域受到关注并取得了重大进展。然而,由于数据假设简化,这些MDL模型在实际世界的部署仍然有限。现有的MDL方法通常假设推断过程中具备完整的模态可用性。然而,实际上由于不同中心的异构采集协议、传感器故障或传输错误,样品常常缺乏一种或多种模态(Wu 等,2024a),导致模型性能下降。因此,开发对不完整多模态数据的强化MDL模型已成为关键研究重点。 当前处理缺失模态的方法大致可分为两类:(1)基于恢复的方法旨在通过检索或生成在输入层面或潜在空间中归因缺失的模态,使MDL模型能够在所有模态都存在的情况下运作(马等,2021;Xu 等,2025);(2)无恢复方法旨在忽略缺失的模态,仅使用现有模态进行预测(Lee 等,2023;Wu 等,2024b)。 然而,这些不完整的MDL方法在模态异质性下捕捉任务相关信息时面临内在挑战(Zhang 等,2024)。具体来说,模态在任务相关性上存在差异,这取决于任务相关信号的强度和干扰程度的不同,任务无关噪声(Huang 等,2022b)。如图1(a)所示,当缺乏高度信息量的模态时,早期无恢复方法仅依赖剩余模态中较不易区分的特征,而忽视缺失模态中宝贵的任务相关信息,导致模型性能下降。以往基于恢复的方法似乎通过重建缺失的模态来缓解这一问题。然而,由于跨模态异质性和多样缺失情景,补充性质常因样本间而异。如图1(b),一些恢复的模态可能是低保真度(即模糊或损坏的橙色框)或语义错位(即其标签与输入模态黄色框不一致)。整合这些不可靠的模式会注入与任务无关的噪音,影响决策。因此,丢弃缺失的模式有可能丢失宝贵的任务相关信息,而恢复它们则可能注入有害信息,这种权衡限制我们称之为"丢弃-补值困境"。 为解决不完整MDL中的这一困境,我们引入了一种新视角,基于任务相关性动态选择并融合恢复的模态,超越了传统的丢弃与推算缺失数据的二分法。在这种动态系统中,一个关键的技术挑战是如何估算每种模态的任务相关信息量,并在推断时识别不可靠的模态。尽管如此,现有的动态聚变方法(Cao 等,2024;Gao 等,2024)主要为低保真度模态设计,依赖模态特有特征进行权重,因此在识别语义错位模态方面受限。 在本研究中,我们提出了DyMo,一种新型推断时间动态模态选择框架,能够自适应融合可靠的恢复模态,以最大化不完全MDL中多模态相关信息(见图1(c))。为避免集成不可靠(低保真度或错位)的恢复,我们提出了一种新的动态算法,基于多模态任务相关信息增量,迭代选择最具信息量的恢复模态。由于推断时数据分布未知,我们理论上推断出减少任务丢失可以提高任务相关信息的下限。这促使我们将损失减少作为信息获取的实际代理指标,并引入一种新的原则性奖励函数来指导模态选择。此外,为了支持灵活的多模态输入,我们设计了一种多模态网络架构,能够预测任意模态的任务目标。我们还提出了一种定制化的训练策略,以学习适合DyMo动态选择过程的稳健潜在特征。 我们的贡献可以总结如下。(1)据我们所知,我们是第一个研究不完全MDL中丢弃-补值难题并引入动态神经网络来解决该问题的机构。(2)我们提出了DyMo,一种新颖的动态框架,通过基于多模态任务相关信息增益的新选择算法,结合多模态网络和定制训练算法,实现从任意模态组合中稳健提取特征的定制训练算法,实现恢复的模态。(3) 在5个不同数据集上的实验显示,DyMo在严重缺失场景下,在不完整/动态MDL SOTA中表现出显著优异表现。DyMo 也易于使用(灵活支持多种模态恢复方法),且其动态算法无需额外架构开销即可部署。
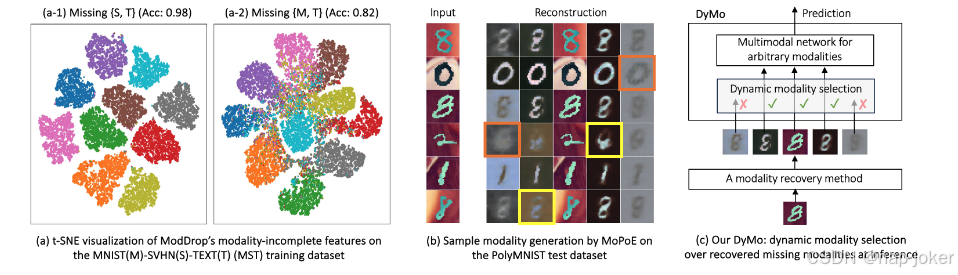
图1:(a-b)丢弃-补缺困境的证据:(a-1)与(a-2)无恢复方法(例如ModDrop(Neverova等,2015))学习的判别性较少,因为它们忽略了高度相关的缺失模态{M,T};(b)基于恢复的方法(例如MoPoE(Sutter等,2021))会产生不可靠的重建,例如低保真度(橙色)或错位(黄色)。(c) 我们的DyMo,通过动态融合任务相关的恢复模态来解决这一难题,PolyMNIST的准确率提升了1.61%,MST的准确率提升了1.68%,CelebA的准确率提升了3.88%(标签1)。
相关工作
**不完全多模深度学习(MDL)**方法(Zhan 等,2025;Wu 等,2024a)大致分为两类:基于回收的和无回收的。基于恢复的方法还可以根据补值发生的时间进一步细分为离线和在线两种。离线方法通常预训练分离的重建网络,例如变分自编码器(VAE)(Sutter 等,2021;Gao 和 Pu, 2025),然后将重建数据用于下游任务。在线方法(Wang 等,2023b;Shou 等,2025)在培训期间共同学习模态恢复和下游任务(Wang 等,2023a)。例如,SMIL(马等,2022)采用贝叶斯元学习来推断潜在特征,而M3Care(张等,2022)则检索类似样本以补偿缺乏的模态。在无恢复方法中,缺失无关性技术通过随机模态遗失(如ModDrop(Neverova等,2015)和MMANet(Wei等,2023)或对比学习(Wu等,2024b)来学习模态不变特征;而缺失感知方法则引入缺失特定参数来处理不同的缺失模式(马等,2022;Li 等,2025)。然而,之前不完整的MDL方法要么完全恢复,要么忽略缺失模态,而不考虑丢弃-插补难题。
与静态模型不同,动态深度神经网络可以根据单个输入调整其架构和参数,从而显著提升计算效率、准确性和可解释性(Han 等,2021;郭等,2024)。动态架构方法根据每个样本调整网络深度、宽度或路由路径(Fedus 等,2022;Yue等,2024;Bayasi 等,2022;Zhao 等,2025),而动态参数算法则调制网络权重或特征缩放而不改变架构(Zhang 等,2023;Bolya 等,2023;Du 等,2023)。我们的DyMo能够根据每个实例动态路由模态数据,属于动态架构类别。
多模态融合是MDL中的一个关键研究问题(Baltruˇsaitis 等,2018)。现有方法可按融合阶段分为早期(数据级)、中间(特征级)和晚期(决策级)融合。近年来,动态多模融合方法出现,以应对实例特异性模态可靠性的差异。这些方法为每种模态赋予不同的权重(Zhang 等,2023;Gao 等,2024)或选择性地使用部分模态(Xue 和 Marculescu,2023;马等,2025)。然而,这类方法通常假设所有模态都可用,主要关注模态内噪声(即低保真度数据),缺乏对模态间错误(即语义错位)的鲁棒性。虽然MICINet(Zhang等,2025)探讨了这两种噪声类型,但需要基于真实的标签,且不能在推断时应用。相比之下,DyMo动态融合观测和恢复的模态来处理不完整数据,同时有效处理模态内外的噪声,无需依赖标签。
方法
本节介绍了DyMo,一种新的推断时间动态模态选择框架,用于不完全多模态分类,通过充分探索从恢复模态中获得的任务相关信息,同时解决丢弃-补缺难题(见图1(c))。为此,DyMo包含三个关键组件:(1)灵活的多模态架构,能够从任意模态中做出预测(第3.1节,图2);(2)一种新型动态选择算法,整合有价值的恢复模态,以最大化每个样本多模态任务相关信息(第3.2节,算法1);以及(3)一种定制化的训练策略,增强表征学习,确保在推断过程中动态模态配置下的特征鲁棒性(第3.3节)。
任意模态的多模态架构
我们的多模态网络设计用于从任意输入模态子集中产生可靠预测,实现基于每个恢复模态任务相关性的自适应融合。为此,我们构建了一个多模态网络f(见图2),包括用于单模态特征提取的模态特定编码器、用于建模跨模态交互并学习可用模态的多模态表示的多模态变换器,以及用于最终预测的分类器。 多模分类数据集可以定义为{习, yi}N i=1,其中N为样本数,yi ∈{1, ..., K}为类标签,习 = {x(m)}m∈Ii 表示一个(可能不完整的)多模态输入,包括图像和文本等模态。这里,Ii 表示完备模态指标 M = {1, 2, ..., M } 的一个子集。如图2所示,每个可用的模态 m ∈ ii 都由一个特定模态编码器的编码器 h(m) 编码,产生一系列特征符号 H(m) ∈ RL(m)×C ,其中 L(m) 是序列长度,C 表示特征维度。然后我们将这些令牌与可学习的CLS令牌串接,形成多模序列嵌入。CLS 令牌的输出嵌入 z 作为分类的多模态表示,如 (Devlin 等,2019) 所示。为了保持样本间的序列结构,我们将假标记分配给缺失模态的位置。 借助变换器能够从序列中可变长度捕捉长距离依赖关系的能力,我们构建了一个由T层叠加变压器层组成的多模态变换器网络ψ(Vaswani 等,2017),以学习观察到的模态中的跨模态关系。
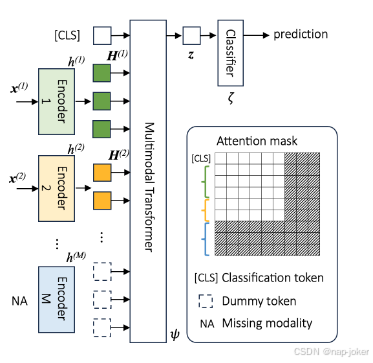
图2:任意模态的多模态网络架构f。
这些变换器层对多模态序列嵌入进行自我关注,并应用注意力掩码,确保缺失模态不会扭曲表征学习。从变换器提取的多模表示z = ψh(习) 会通过线性软极大分类器ζ以得到最终预测。
推断时的动态模态选择
为解决丢弃-补缺难题,我们提出了一种新型动态模态选择算法,能够自适应地发现有价值的任务相关恢复模态。我们方法的核心思想是一个新颖的奖励函数,用于估计每个恢复模态所贡献的增量多模态任务相关信息。我们建立了信息与任务(即分类)损失之间的理论联系,从而形成了与潜在空间表征转移相关联的有效奖励表述。为进一步增强鲁棒性,我们提出基于训练数据进行类别内相似度校准以优化奖励。最后,我们引入了一种可靠的动态多模融合的迭代选择机制。
多模态任务相关信息奖励(MTIR)旨在估算通过向现有观测模态添加恢复模态所获得的增量多模态任务相关信息。MTIR的灵感来源于信息增益的概念(马等,2019;Jolliffe,2011)并旨在表明每种恢复模态对多模态表征的边际影响:(1)正向奖励表明恢复的模态引入了额外的任务相关信息,从而增强表征;(2)零奖励表示回收保真度低,主要引入噪声且收益微乎其微;以及(3)负奖励意味着恢复包含与任务相关但语义不一致的信息,可能降低表征性。该表述使得识别低保真和错位模态成为可能,而这些模态在此前的动态MDL研究中大多被忽视。 为了量化多模表示中包含的任务相关信息,我们考虑多模表示Z与目标标签Y之间的互信息:

其中H(Y)是目标标记的熵,G是每个样本CE损失的保守上界,|D|是测试数据集的大小,δ ∈(0, 1)控制界限保持的概率(详细推导见附录A.1)。该界限形式化了直觉:减少Lˆce可以增加I(Y;Z),从而有可能增加任务相关信息基于这一见解,我们提出将经验测试时间CE损失的下降作为信息获取的可处理代理指标,形成我们MTIR奖励的理论基础。 给定一个不完整的多模态测试样本 Xj = {x(m)}m∈Ij(符号遵循第3.1节),我们通过恢复函数 Υ(例如一个 VAE)恢复缺失模态,表示为 X ̃ j = {x ̃(u)}u∈(M\Ij)。DyMo g 的测试时间经验 CE 损失,包括多模网络 f 和动态选择算法,定义为:

其中XO表示观察到的模态(初始为X),lce = − log pf (y|z),z = ψh(XO),zu = ψh(XO, x ̃(u))。由于推断时真实标签y未知,我们用预测标签yˆ = argmax f(XO)和yˆu = argmax f(XO, x ̃(u))替代。然而,这种替代可能会削弱MTIR的可靠性,尤其是在预测错误或过拟合的情况下。为了缓解这一问题,受到度量学习的鲁棒性和可推广性(Vinyals 等,2016;Chen 等,2020),我们进一步研究了在潜空间测量的训练分布下的表示变化。具体来说,我们将分类视为特征空间中的混合密度估计问题,每个类别对应一个分量。假设等于类别的先验概率和指数族分布,给定 z 时 y = k 的后验概率为:

该公式表明,当表征在纳入恢复模态后接近类别原型时,可以获得更高的MTIR奖励,这与融合有效信息能提升模型预测确定性的直觉一致(Dai等,2023)。
类内相似度校准:第6式定义了基于样本表示与预测类别原型之间距离变化的MTIR奖励。当 yˆ 和 yˆu 不同,而 z 和 zu 距离各自原型相近时,就会出现一个具有挑战性的情况,从而获得近乎零的奖励。为解决这个问题并提升MTIR奖励的可靠性,我们引入了新颖的校准项α,通过考虑样本在其预测类别簇中的代表性来细化奖励。校准的MTIR奖励R∗为
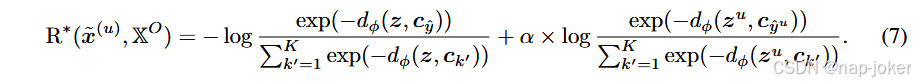
计算α,首先定义k类的z的类内相似度(ICS)分数。与许多需要计算k类训练样本距离的非参数统计方法(Hastie等,2009)不同,我们提出了一种高效的近似方法。具体来说,我们将从k类样本到类原型ck的距离分布近似为截断正态分布dφ ∼ N (0, σ2 k), dφ > 0,其中σk是从训练数据估计的。ICS分数随后写成如下:
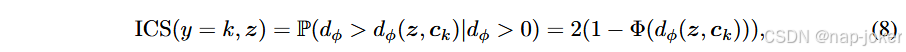
其中 Φ 是正态分布的累积分布函数。ICS量化了类簇中z的代表性,值越高表示与该簇训练样本的对齐度越高。校准项定义为 zu 和 z 的 ICS 分数之比:ICS(y=yˆu,zu) ICS(y=yˆ,z)。由于观察到XO是任务相关的模态,而x(u)是合成的,可能引入不可靠的信息,当ICS(y = yˆu, zu)>ICS(y = yˆ, z)时,DyMo应保持保守。为此,我们引入一个非对称α:
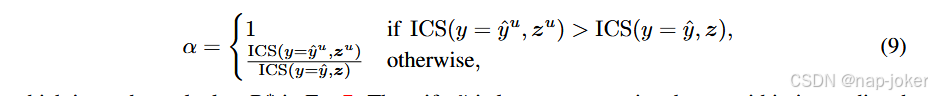
该方程用于计算方程7中的R∗。因此,如果zu在其预测类簇内的代表性低于z(即α <1),则R中的第二项被下加权,从而降低校准后的MTIR。
迭代模态选择:为提高DyMo动态过程的可靠性,我们引入了一种迭代选择算法,以最大化每个样本多模态任务相关信息(算法1)。每一步,给定一组观察到的XO和一组候选XC,我们将MTIR奖励最高的恢复模态加入XO,同时剔除所有无效且奖励非正的模态。这种分阶段的选择确保DyMo只包含最具信息量的模态,有效减少噪声积累。

训练算法
DyMo的动态推理依赖于表示转移,因此必须正确训练我们的多模态网络f,以学习一个稳健的潜在特征空间,即同类样本即使缺失模态仍聚集在一起。为此,我们设计了不完全模态模拟训练和辅助缺失无关对比损失。 模拟训练不完整。为确保f能在各种缺失模式中提取稳健的任务相关特征,我们提出了一种简单但有效的随机抽样策略。具体来说,每个完备多模样本 {x(1), ..., x(M)} 有 2M −1 个非空模态子集。在每个小批次中,我们随机抽样A,如下子集用于分类损失计算:

实验
数据集与评估指标:我们在5个不同模态数据集(如图像、文本和结构化表格)上进行了广泛实验,包括3个模拟基准数据集(Sutter等,2021):PolyMNIST、MST和生物模态CelebA,以及两个大型现实世界数据集:一个自然图像数据集,数据可视化营销(DVM)(Huang等,2022a),以及一个医学图像数据集, 英国生物样本库(UKBB)(Sudlow 等,2015)。对于UKBB,我们重点关注两项心脏疾病分类任务:冠状动脉疾病(CAD)和心肌梗死,利用磁共振(MR)图像和疾病相关的表格特征。后续(Du 等,2025;Sutter 等,2020),我们报告了 UKBB 的曲线下面积(AUC),以及其余数据集的准确性。数据集详情见附录B.1。
实现细节:在DyMo中,我们采用了MoPoE(Sutter等,2021),一种多模态VAE网络,用于PolyMNIST、MST和CelebA。然后,对于DVM和UKBB,我们使用了TIP(Du等,2024),一种图像表重建框架。注意,DyMo可以搭配任何恢复方式部署。为确保公平比较,所有比较方法均使用与DyMo相同的模态特定编码器。模型在完整数据集上训练,并在各种缺失情景下进行评估:(i) 对于PolyMNIST,我们设置了5个缺失率 η = {0, 0.2, 0.4, 0.6, 0.8},其中每个样本随机漏掉η ×100%模态;(ii)对于MST和CelebA,我们测试了不同的缺失模组组合;(iii) 对于DVM和UKBB,由于TIP是表重建网络,我们评估了全表和表内(即部分模态内)缺失。具体来说,我们设置了7个缺失的表格率 γ = {0, 0.1, 0.3, 0.5, 0.7, 0.9, 1},其中每个样本随机错过γ ×100%的表格特征。注意,DyMo 也可以处理不完全模态训练,因为我们的多模态网络支持任意模态。所有模型的详细实现设置见附录B.2。
总体结果
与多模态静态/动态融合SOTA比较:为评估DyMo在推断时选择有价值任务相关恢复模态的有效性,我们将其与SOTA多模融合技术进行比较,包括基于静态连接的融合(CONCAT)(Baltrusˇaitis等,2018)和三种动态融合方法QMF(Zhang等,2023)、DynMM(Xue 和 Marculescu,2023)和PDF(Cao 等,2024)。所有方法在推断时均提供相同的非缺失和恢复模态。值得注意的是,以往的动态方法通常需要额外的模态特定分支来估计模态贡献或多阶段训练,而DyMo则直接基于多模态表示,无需额外的模态特定参数,依赖单阶段训练。我们使用余弦距离(DyMoc)和平方欧几里得距离(DyMoe)报告DyMo的结果。 如图3所示,DyMo在大多数数据集上取得了显著改进,尤其是在严重缺失场景下。例如,DyMo在PolyMNIST上缺少80%模态时准确率提升13.12%,在DVM中准确率提升4.11%,当全表缺失时。DyMoc 和 DyMoe 在大多数数据集上都持续优于以往的 SOTA,显示出 DyMo 在距离指标选择上的鲁棒性。我们还观察到(1)不同缺失模态组合的表现下降(图3(b,c))不同,表明任务相关性存在差异;(2)先前的动力学方法在DVM上优于静态聚变(见图3(d)),但在3个模拟基准测试中仅获得有限的提升(见图3(a-c))。这一局限性在于基于VAE的重建往往产生视觉上可信但类别错位的恢复模态,而以往的动态方法难以应对此类问题。相比之下,DyMo通过估算增量多模态任务相关信息获得来解决这一问题,从而获得更优的结果。此外,DyMo和CONCAT在CAD上的表现类似,可能是因为回收的表模态在各样品间信息量一致,导致动态融合空间有限,无法进一步提升性能。 比较不完全MDL SOTA:为评估DyMo处理缺失模态的有效性,我们将其与SOTA不完全MDL方法进行了比较,包括5种基于恢复的方法(MultiAE(Ngiam等,2011)、MoPoE(Sutter等,2021)、M3Care(Zhang等,2022)、OnlineMAE(Woo等,2023)和CMVAE(Palumbo等,2024))以及4种无恢复方法(ModDrop(Neverova等, 2015年)、MTL(马等,2022年)、MAP研究(Lee等人,2023年)和MUSE(吴等人,2024b)。
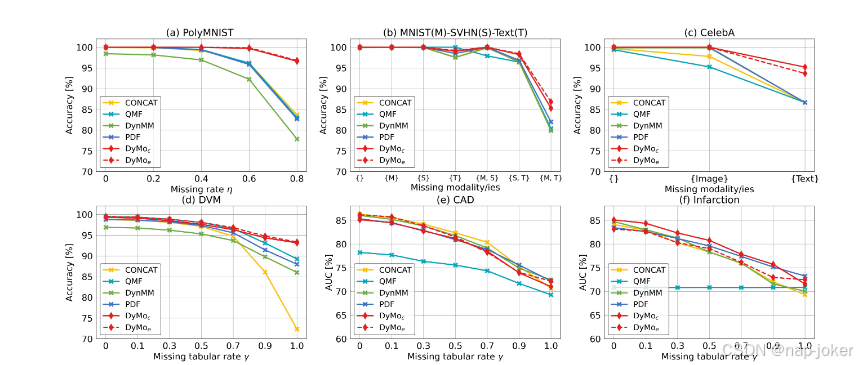
图3:在6个多模态分类任务中,在各种缺失情景下,DyMo与静态/动态多模融合技术的比较。DyMoc 和 DyMoe 分别表示使用余弦和平方欧几里得距离。
表1:在不同缺失情景下,DyMo与基于恢复和无恢复的不完整MDL方法在6个多模态分类任务中的比较。用†标记的模型是通过我们提出的不完全模态模拟训练的。所有缺失情景的完整结果见附录C.1。
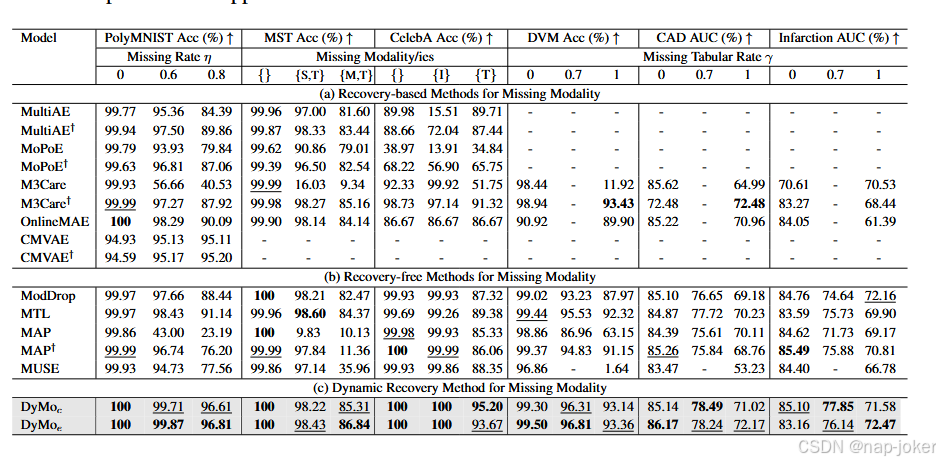
对于训练中不模拟不同缺失情景的模型,我们会通过我们不完整的模拟训练,直接报告他们的结果。由于ModDrop是一种训练方案而非独立架构,我们将其应用于与DyMo相同的多模态骨干网,以便进行公平对比。需要任务特定解码器或限制于全模态缺失设置的方法,仅在提供此类解码器且处于全模态缺失状态的数据集上进行评估。 在标签1中,整合我们不完整的仿真训练提升了模型表现(与无†相比),展示了其在学习对缺失数据有韧性的特征时的有效性。我们还观察到丢弃-补缺困境:(i)无恢复方法在缺少高度任务相关的模态时性能大幅下降,例如MST中缺少{M,T}比对{S,T}的MST中MUSE准确率下降61.18%(注意CMVAE在缺失率上相对稳定,因为它使用单一随机选择的观测模态进行分类);(ii) 基于恢复的方法在严重缺失场景下表现不佳,例如,OnlineMAE在PolyMIST上的准确率下降9.91%,当η = 0 = 0时,η = 0,表明恢复结果不可靠。相比之下,DyMo有效解决了这一困境,在全模态和模态内缺失条件上显著优于以往的SOTA,例如在缺失80%模态的情况下,PolyMNIST的准确率提高了5.67%;在缺失70%的表特征缺失情况下,梗死的AUC提高了1.97%。
表2:DyMo消融研究。基线整合所有回收的模态,无需选择。S可以同时整合所有正奖励(r > 0)的模态。I 迭代添加 r 最高的模态。C 使用通过类内相似度校准获得的校准奖励 r∗。当 η = 1 时,在 DVM 和 CAD 上匹配 M3Care†,这很可能是由于 TIP 对全表重建有限;更强劲的复苏将进一步提升结果。

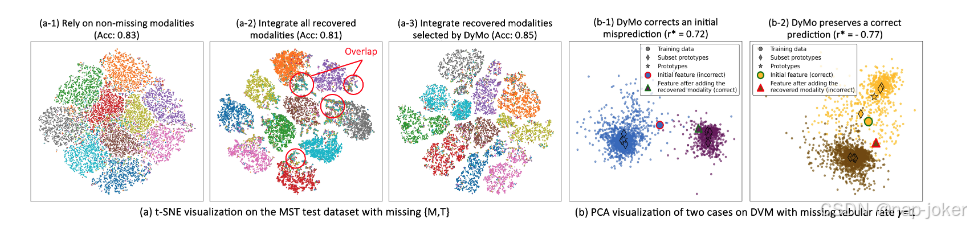
图4:(a) MST上DyMoc的t-SNE可视化,采用不同模态输入:(a-1)仅使用非缺失模态;(a-2)无选择地整合所有恢复的模态;(a-3)纳入DyMoc选定的回收方式。(b) DyMoc在DVM上成功测试案例的PCA可视化:(b-1)通过引入恢复模态纠正的误判;(b-2)通过忽略不可靠的恢复模态来维持的正确预测。
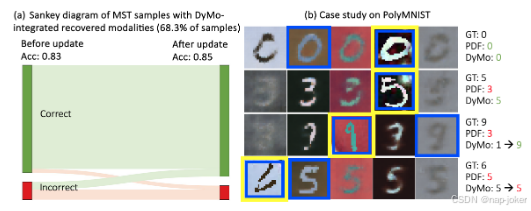
图5:(a) 缺少{M,T}的MST上DyMoc预测转变的桑基图。(b) PolyMNIST 案例研究,黄色表示非缺失模态,蓝色表示由 DyMoc 选定的模态。
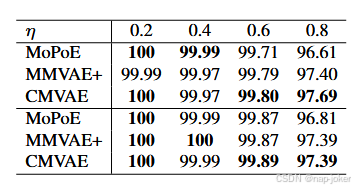
表3:在PolyMNIST上使用不同模态恢复方法,在不同缺失模态率η下,DyMoc(前三行)和DyMoe(后三行)的分类准确率(百分比)。
消融实验与可视化
关键模型组件的有效性:我们在第2页中消融了DyMo的关键成分,包括MTIR奖励、迭代选择和校准项。结果显示,整合所有恢复的模态而不选择会引入与任务无关的信息并降低绩效。每个组成部分都有积极贡献,而将所有元素结合起来的DyMo取得了最佳的整体效果。在CAD和梗死方面,我优于I+C。这很可能是因为校准项在0和1之间界定,使模型在模态选择上更为保守。在这些情况下,恢复的表始终提供与任务相关的信息,因此省略C可以让更多样本受益。在应用 C 之前调整数据集特异的超标量超参数可能缓解这个问题,我们将留待后续研究。关于我们不完整模拟训练、DyMo的泛化性分析和自适应推断分析的进一步消融研究可见附录C.2-C.3。测试时间任务损失分析见附录。C.4. 不同模态恢复方法间的DyMo鲁棒性:我们使用三种不同的模态恢复方法(包括MoPoE、MM)进行了不完整的多模态实验VAE+(Palumbo等,2023)和CMVAE(Palumbo等,2024),并定量评估了它们在PolyMNIST上的重建表现。如表3所示,DyMo与上述任何恢复方法结合时,表现始终优于以往的SOTA动态/不完整MDL方法(见图3和表1),尽管CMVAE和MoPoE的重建质量存在差异(附录C.6图S6)。为了进一步评估DyMo对重建质量的稳健性,我们还评估了DVM和UKBB的另一种基于机器学习的恢复方法,并进行了以受控正确恢复率进行极端模拟实验。结果和详细分析见附录。C.2. 多模态表示的可视化与案例研究:为了考察DyMo选定的恢复模态整合对潜空间塑造的影响,我们使用t-SNE(Maaten & Hinton, 2008)来可视化测试集的多模态嵌入。图4(a)显示,整合所有恢复的模态会增加类间分离;然而,恢复不可靠的样本可能被嵌入错误的类别簇中,导致错误分类和性能下降。相比之下,DyMo的动态融合缓解了这一问题,产生了更具辨别性的潜空间和更好的分类结果。此外,我们在特征层面(PCA(Jolliffe, 2011)可视化,见图4(b))和输入层面(图5(b))进行了案例研究,展示了DyMo有效选择可靠且与任务相关的恢复模态,从而提升模型性能。图5(b)第四行展示了一个具有挑战性的例子,所有动态方法因观测模态噪声大且恢复模态语义错位而难以应对。附录C.5提供了额外的可视化和详细分析。 预测转换:我们利用桑基图分析动态模态选择前后预测变化。如图5(a)所示,DyMo纠正了许多初始错误预测,实现了性能提升,凸显了恢复模态的优势。少数正确预测在更新后出现错误,可能是由于恢复质量有限,这表明更强的恢复方法可以减少此类错误。模态恢复方法的重建分析见附录C.6。
总结
总之,我们提出了首个关于模态恢复后动态多模融合的研究,旨在解决缺失的模态问题。我们提出了DyMo,一种新的推理时间动态模态选择框架,能够通过自适应识别和融合有价值的恢复模态,全面探索任务相关信息,同时解决丢弃补缺问题。DyMo 引入了一种基于最大化多模态任务相关信息的新选择算法,并提出了一个原则性的奖励函数。我们还设计了灵活的多模态网络架构和定制化的训练策略,以实现在任意模态组合下稳健的多模态表示学习。对各种自然和医学数据集的实验显示了DyMo的SOTA性能及其组件的有效性。随着多模态深度学习需求的增长,DyMo在不完整数据的实际应用方面具有巨大潜力。未来工作将探索扩展至其他任务(如分割)和模态(如视频)。关于任务扩展的补充讨论见附录。D.