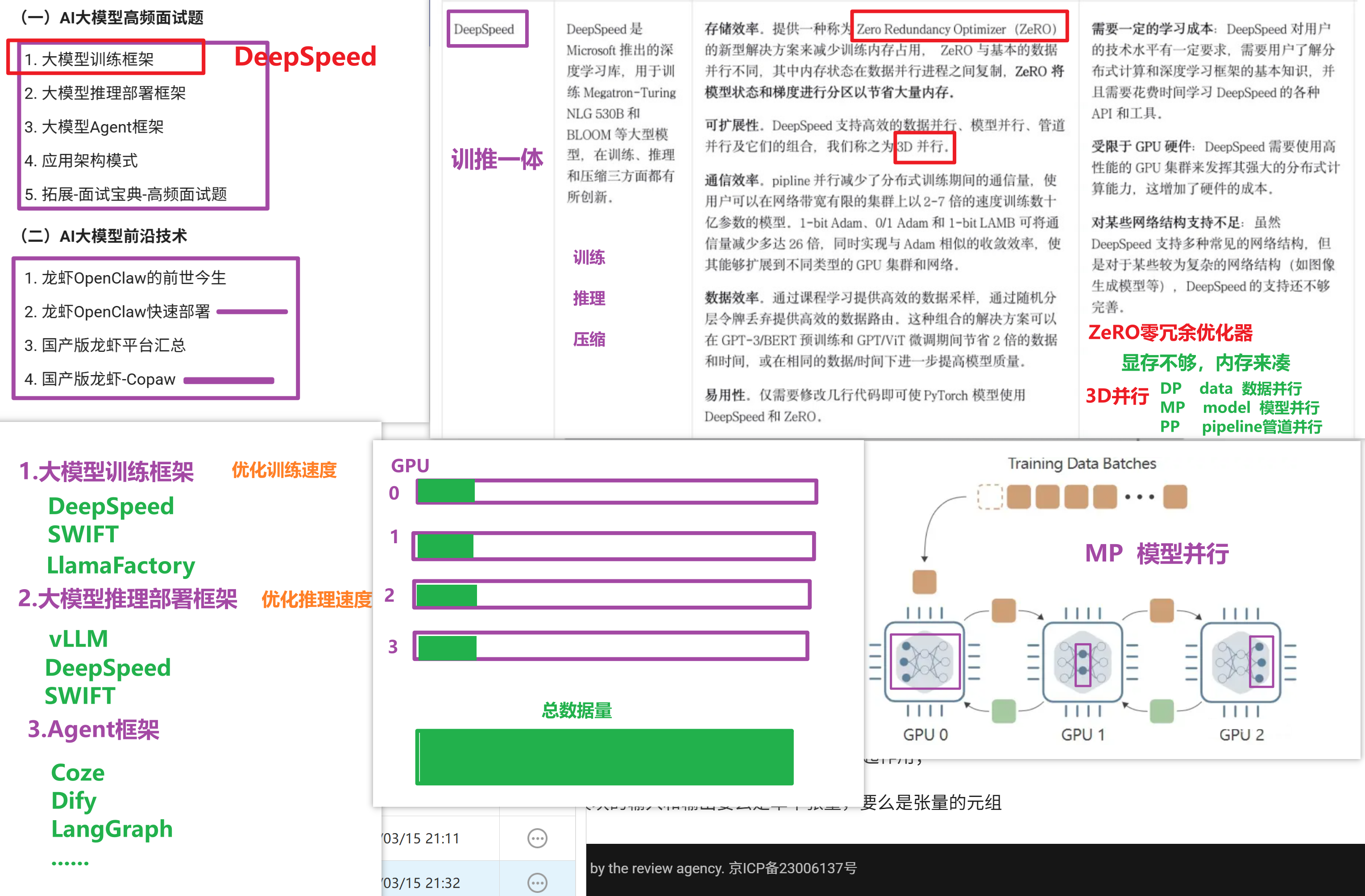
第一部分:大模型训练框架(怎么训)
训练用 DeepSpeed,推理选 vLLM 或 Ollama,入门看 Transformers,生产上 TGI。大模型从训到跑,一套框架全搞定。 🚀
DeepSpeed:训练推理一体
ZeRO:零冗余优化器,显存不够,内存来凑
3D并行:DP data数据并行
MP model模型并行
PP pipline管道并行

一、为什么需要训练框架?
模型太大,单张显卡装不下:
-
显存不够
-
训练太慢
-
简单数据并行浪费显存
👉 需要分布式训练框架
二、主流训练框架对比
| 框架 | 出品方 | 特点 |
|---|---|---|
| DeepSpeed | 微软 | ✅ 最主流,高效、易用 |
| Megatron-LM | 英伟达 | 张量并行强 |
| FairScale | Meta | PyTorch原生兼容 |
三、DeepSpeed 三大核心技术(面试必考)
1. ZeRO(零冗余优化器)
问题:每张卡都存完整模型参数、梯度、优化器状态 → 显存浪费
解法:切开存,谁用谁拿
| 阶段 | 切分内容 | 省显存效果 |
|---|---|---|
| ZeRO-1 | 优化器状态 | ✅ |
| ZeRO-2 | + 梯度 | ✅✅ |
| ZeRO-3 | + 模型参数 | ✅✅✅ |
进阶:
-
ZeRO-Offload:显存不够 → 放 CPU 内存
-
ZeRO-Infinity:甚至放 SSD
2. 3D 并行(三种并行组合)
| 并行方式 | 做什么 | 优点 | 缺点 |
|---|---|---|---|
| 数据并行 DP | 每张卡一份模型,分数据 | 快 | 显存浪费 |
| 模型并行 MP | 模型切分到多卡 | 能装超大模型 | 通信慢 |
| 流水线并行 PP | 微批次流水线作业 | 减少空闲 | 实现复杂 |
3. 梯度累积
问题:想要大 batch,但显存放不下
解法:多次前反向 → 累加梯度 → 一次更新
👉 小显存模拟大批次
四、DeepSpeed 实战(ChatGLM-6B 微调)
核心代码
python
# 初始化引擎
model_engine, optimizer, _, _ = deepspeed.initialize(
model=model, args=args
)
# 分布式采样(关键!)
if local_rank == -1:
sampler = RandomSampler(dataset)
else:
sampler = DistributedSampler(dataset)
# 训练循环
for batch in dataloader:
loss = model_engine(batch)
model_engine.backward(loss)
model_engine.step()启动命令
python
deepspeed --hostfile=myhostfile main.py \
--deepspeed deepspeed.json \
--fp16五、常见大坑与解法
| 问题 | 原因 | 解法 |
|---|---|---|
| 多机通信失败 | 环境依赖不全 | 重装 PyTorch + MPI |
| Loss 不降 | 官方代码问题 | 换 ChatGLM-Finetuning |
| 8 卡只用 6 卡 | 内存爆了 | 改 DistributedSampler + 惰性加载 |
| 百万数据跑不满 | 每卡加载全量数据 | 数据切分 + 落盘 |
第二部分:大模型推理部署框架(怎么跑)
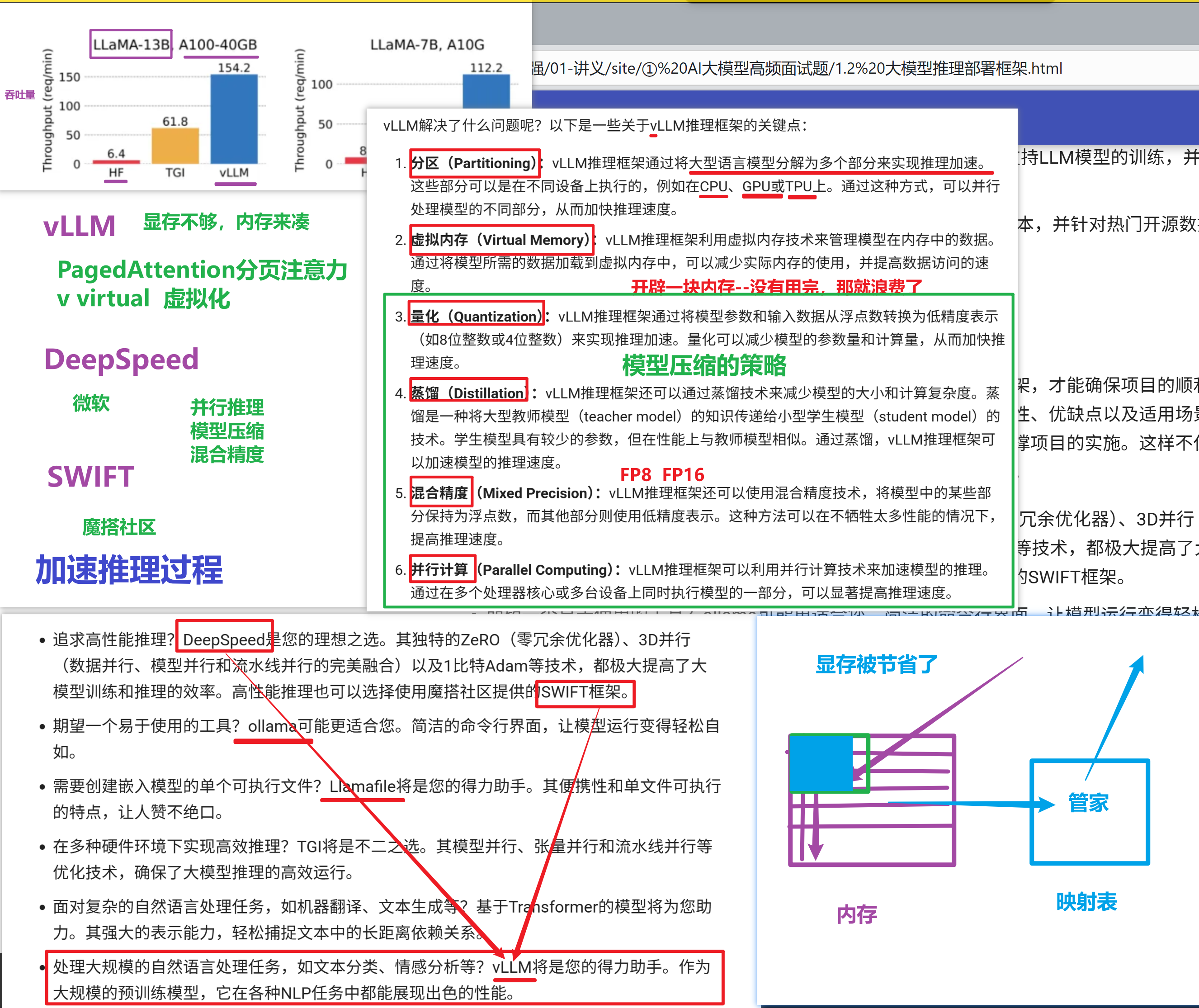
一、为什么需要推理框架?
训练好的模型要给别人用,需要解决:
-
响应要快
-
并发要高
-
显存要省
-
部署要简单
二、七种主流推理框架对比
| 框架 | 特点 | 适合场景 |
|---|---|---|
| Transformers | HuggingFace 官方,功能全 | 实验、学习 |
| Llama.cpp | C++ 实现,Apple Silicon 优化 | 本地跑 Llama |
| Llamafile | 单文件可执行,便携 | 嵌入模型 |
| Ollama | 一行命令安装,极简 | 新手、快速体验 |
| vLLM | 高吞吐、PagedAttention | 高并发、多请求 |
| TGI | HuggingFace 出品,Rust+Python | 生产环境 |
| DeepSpeed-Inference | 模型并行、张量并行 | 高性能推理 |
| SWIFT | 魔搭社区,轻量级 | 消费级显卡 |
三、技术名词解释
1. PagedAttention(vLLM 核心)
问题:
-
不同请求生成长度不同,短的要陪跑长的
-
新请求要排队
-
注意力机制的 K/V 存储浪费严重
解法:
-
像操作系统虚拟内存一样,把 K/V 切成固定大小的"页"
-
动态映射,不连续存储
-
结合调度策略:先来先服务 + 后来先抢占 + 内存不够就 swap 到 CPU
👉 效果:单卡 24G 显存,支持 5-10 个并发
2. TGI 的优化
-
Flash Attention
-
Paged Attention(也有)
-
支持 GPTQ 量化
-
容器化部署
⚠️ 当前速度略慢于 vLLM
3. 常见优化手段
| 技术 | 作用 |
|---|---|
| 量化 | FP16 → INT8/INT4,省显存 |
| 混合精度 | 部分用 FP16,部分用 FP32 |
| 蒸馏 | 大模型教小模型 |
| 并行计算 | 多核/多卡同时算 |
四、推理框架选型指南(面试高频)
| 你的需求 | 推荐框架 |
|---|---|
| 我就想最快跑起来 | Ollama |
| 我要最高吞吐、高并发 | vLLM |
| 我要生产级稳定 | TGI |
| 我要嵌入到 C++ 项目 | Llama.cpp |
| 我要搞一个单文件可执行 | Llamafile |
| 我要做实验、调模型 | Transformers |
| 我要极致性能 + 大模型并行 | DeepSpeed-Inference |
| 我只有消费级显卡 | SWIFT |
🎯 面试速记卡(背下来)
训练侧
-
DeepSpeed 是什么:微软的分布式训练框架
-
ZeRO 是什么:切分模型状态,省显存(三阶段由浅到深)
-
3D 并行是什么:DP + MP + PP 组合拳
-
Offload 是什么:显存不够,内存来凑
-
为什么 loss 不降:检查采样器、数据质量、框架版本
推理侧
-
vLLM 为什么快:PagedAttention + 虚拟内存思想
-
Ollama 为什么简单:一行命令安装,自动管理模型
-
TGI 和 vLLM 对比:TGI 更稳定,vLLM 更快
-
怎么选推理框架:新手用 Ollama,高并发用 vLLM,生产用 TGI
-
量化是什么:降低精度,节省显存
📌 一句话总结
训练用 DeepSpeed,推理选 vLLM 或 Ollama,入门看 Transformers,生产上 TGI。大模型从训到跑,一套框架全搞定。 🚀