Genie 论文解读
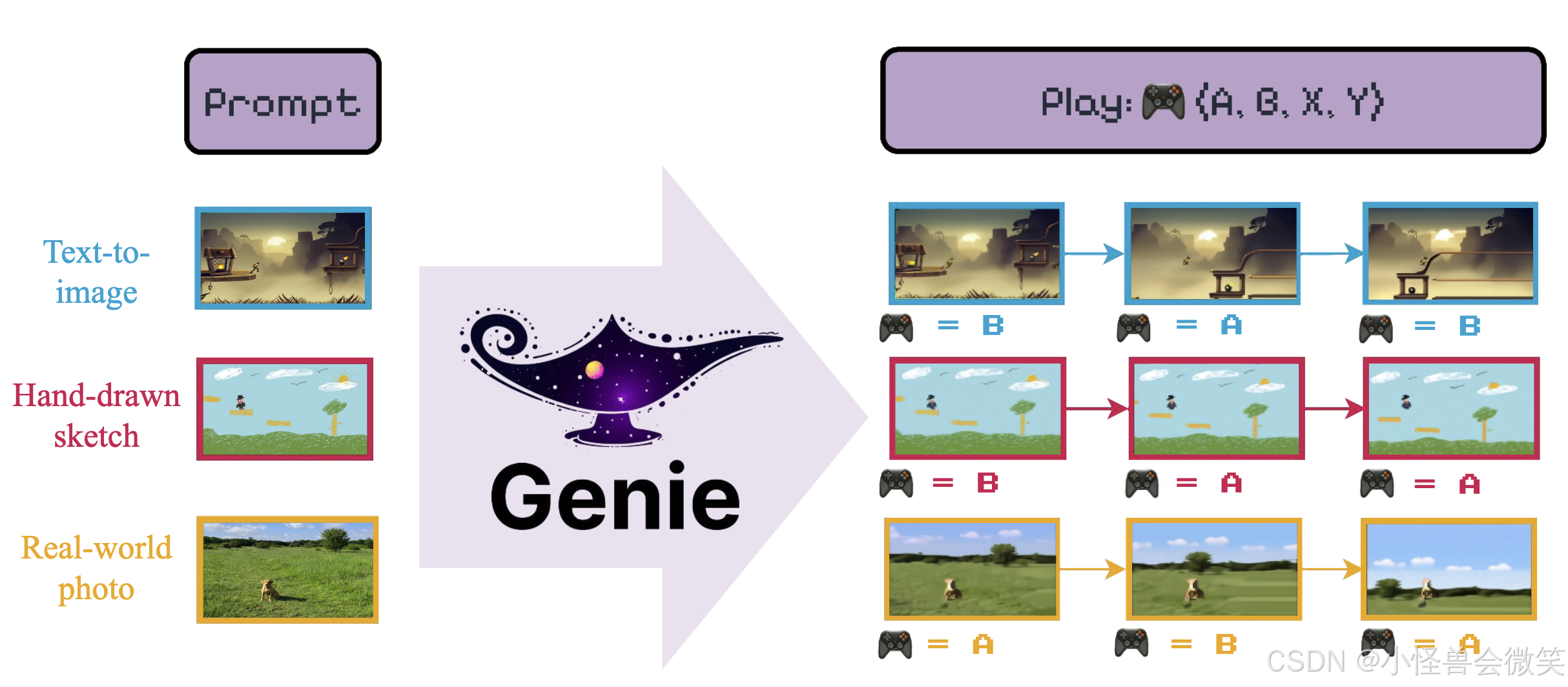
输入是prompt+play的玩法。prompt可以是文生图得到的图片,或者手绘稿,或者是真实的照片。play是几个可以玩的操作按钮(一个"盲盒"手柄,具体按钮数量等于VQ-VAE 密码本的词汇表大小,然后由模型学会每个按钮代表什么)。
背景1:VQ-VAE
VQ-VAE(Vector Quantized Variational Autoencoder,向量量化变分自编码器)是由 DeepMind 在 2017 年提出的一种生成模型架构。要理解它,最关键的是抓住它的核心创新:将传统 VAE 中连续的潜在空间(Continuous Latent Space)变成了离散的潜在空间(Discrete Latent Space)。
在人类的认知中,很多概念本身就是离散的(比如语言中的单词、图像中的特定物体)。VQ-VAE 试图让模型学习一种类似于"字典"的离散表示,从而能更好地捕捉数据的高级语义特征,同时避免了传统 VAE 中常见的"后验坍塌"(Posterior Collapse)问题。
以下是 VQ-VAE 核心原理的详细拆解:
一、 核心架构:三大组件
VQ-VAE 的结构可以分为三个主要部分:
- 编码器 (Encoder) :
输入原始数据 x x x(如图像或音频),编码器将其映射为一个连续的特征向量 z e ( x ) z_e(x) ze(x)。 - 密码本与向量量化 (Codebook & Vector Quantization) :
这是 VQ-VAE 的灵魂。模型内部维护着一个"密码本"(Codebook),里面包含 K K K 个可学习的离散向量(假设为 e 1 , e 2 , ... , e K e_1, e_2, \dots, e_K e1,e2,...,eK)。
量化过程就是 "找最近邻" :模型会计算编码器的输出 z e ( x ) z_e(x) ze(x) 与密码本中所有向量的距离,并挑选出距离最近的那个向量 e k e_k ek。
k = argmin j ∣ ∣ z e ( x ) − e j ∣ ∣ 2 k = \text{argmin}_j ||z_e(x) - e_j||_2 k=argminj∣∣ze(x)−ej∣∣2
然后,将连续的 z e ( x ) z_e(x) ze(x) 强制替换为这个离散的密码本向量 z q ( x ) = e k z_q(x) = e_k zq(x)=ek。 - 解码器 (Decoder) :
接收替换后的离散向量 e k e_k ek,并尝试重建出原始输入 x ^ \hat{x} x^。
二、 训练难点与"直通估计器" (Straight-Through Estimator)
在上述流程中有一个致命的数学问题:量化操作( argmin \text{argmin} argmin)是不可导的。如果梯度断了,神经网络就无法使用反向传播(Backpropagation)来更新编码器的权重。
为了解决这个问题,VQ-VAE 引入了一个非常巧妙的技巧,叫做直通估计器 (Straight-Through Estimator, STE) 。
它的逻辑很简单:在前向传播时,解码器正常接收量化后的离散向量 e k e_k ek;但在反向传播计算梯度时,直接绕过量化步骤,把解码器传回来的梯度"原封不动"地复制并传给编码器的输出 z e ( x ) z_e(x) ze(x) 。
因为 e k e_k ek 和 z e ( x ) z_e(x) ze(x) 在空间中非常接近,这种梯度的近似传递在实际训练中被证明是非常有效的。
三、 损失函数 (Loss Function)
为了让编码器、解码器和密码本都能被正确训练,VQ-VAE 的总损失函数由三部分组成:
L = ∣ ∣ x − D ( e k ) ∣ ∣ 2 2 + ∣ ∣ sg z e ( x ) − e k ∣ ∣ 2 2 + β ∣ ∣ z e ( x ) − sg e k ∣ ∣ 2 2 L = ||x - D(e_k)||_2^2 + ||\text{sg}z_e(x) - e_k||_2^2 + \beta ||z_e(x) - \text{sg}e_k||_2^2 L=∣∣x−D(ek)∣∣22+∣∣sgze(x)−ek∣∣22+β∣∣ze(x)−sgek∣∣22
- 重建损失 (Reconstruction Loss) : ∣ ∣ x − D ( e k ) ∣ ∣ 2 2 ||x - D(e_k)||_2^2 ∣∣x−D(ek)∣∣22
驱动解码器根据密码本向量重建出原始输入,同时通过 STE 将梯度传给编码器。 - 密码本损失 (Codebook Loss) : ∣ ∣ sg z e ( x ) − e k ∣ ∣ 2 2 ||\text{sg}z_e(x) - e_k||_2^2 ∣∣sgze(x)−ek∣∣22
sg \text{sg} sg 代表停止梯度(stop-gradient)。这一项固定住编码器的输出,只更新密码本向量 e k e_k ek,使其向编码器的输出 z e ( x ) z_e(x) ze(x) 靠近。 - 承诺损失 (Commitment Loss) : β ∣ ∣ z e ( x ) − sg e k ∣ ∣ 2 2 \beta ||z_e(x) - \text{sg}e_k||_2^2 β∣∣ze(x)−sgek∣∣22
这一项固定住密码本向量,只更新编码器。它的目的是惩罚编码器的输出偏离密码本向量太远,促使编码器"承诺"输出尽量靠近密码本中的某个向量,防止训练过程中频繁跳跃到其他的密码本向量上( β \beta β 是一个控制权重的超参数)。
四、 为什么 VQ-VAE 如此重要?(结合 Genie 论文)
VQ-VAE 开启了现代生成模型的一种重要范式:先通过 VQ-VAE 将高维的连续数据(如高清图像、视频)压缩成一串低维的、离散的 Token 序列,然后再使用擅长处理离散序列的模型(如 Transformer)来进行自回归生成。
在 《Genie》 论文中,VQ-VAE 扮演了极其关键的基石角色:
- 视频分词器 (Video Tokenizer):通过带有 ST-Transformer 的 VQ-VAE,将庞大且连续的视频像素帧压缩成离散的 Token 序列,让 Transformer 引擎能够像处理文本单词一样去预测视频的下一帧。
- 潜在动作模型 (Latent Action Model) :这是最精妙的应用。Genie 使用 VQ-VAE 将推断出的连续动作向量强行量化为只有 8 个离散选项的 Codebook(词汇表大小 ∣ A ∣ = 8 |A|=8 ∣A∣=8)。这就相当于用深度学习硬生生地逼迫模型从无监督视频中"发明"出了一个包含 8 个按键的虚拟游戏手柄,从而实现了对视频的可控生成。
Genie 能够实现如此惊艳的交互式世界生成,主要归功于其优雅且高效的模型架构。为了处理视频这种包含海量上下文信息的多模态数据,研究团队从底层架构到三大核心组件进行了精心的设计。
以下是 Genie 模型架构的详细技术拆解:
一、 核心基础引擎:时空 Transformer (ST-Transformer,spatiotemporal Transformer )
在深入三大组件之前,需要先了解贯穿 Genie 始终的底层架构模块。视频数据如果使用传统的 Vision Transformer (ViT) ,其注意力机制的内存和计算成本会随着视频帧数的增加呈平方级爆炸。
为了解决长视频序列带来的算力瓶颈,Genie 的所有组件都采用了**时空 Transformer(ST-Transformer)**架构:
- 交错注意力机制 :它包含 L L L 个时空块(Spatiotemporal blocks),将注意力的计算拆分为空间层 和时间层。
- 线性计算复杂度 :空间注意力仅在单一时间步(单帧)内对 1 × H × W 1 \times H \times W 1×H×W 的 Token 进行计算;时间注意力则采用因果掩码(Causal Mask),在 T T T 个时间步的同一空间位置上对 T × 1 × 1 T \times 1 \times 1 T×1×1 的 Token 进行计算。这种设计使得计算复杂度最高的空间注意力层与帧数呈线性关系,而非平方关系。
- 前馈网络(FFW)优化:为了进一步提升规模扩展性,团队在 ST 块中省略了空间层之后的前馈层,仅在空间和时间组件共同完成之后保留一个 FFW。
基于这个高效的 ST-Transformer 引擎,Genie 构建了以下三个核心组件:
二、 组件 1:视频分词器 (Video Tokenizer)
为了让模型能够高效学习,必须先对原始的高维视频像素进行降维和离散化处理。
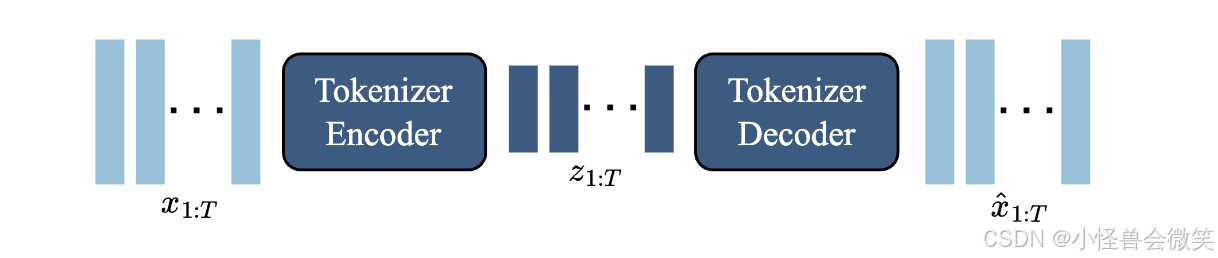
- 工作原理 :它采用了基于 VQ-VAE(向量量化变分自编码器)的方法,接收连续的视频帧 x 1 : T x_{1:T} x1:T,并将其压缩为离散的 Token 表示 z 1 : T z_{1:T} z1:T。
- 架构创新 (ST-ViViT) :与以往仅在空间维度上压缩 Token 的工作不同,Genie 在其分词器的编码器和解码器中都使用了 ST-Transformer。
- 优势 :这种具有时间感知能力的架构使得每一个离散编码 z t z_t zt 都包含了之前所有帧 x 1 : t x_{1:t} x1:t 的时序动态信息,极大提升了视频生成的质量。
三、 组件 2:潜在动作模型 (Latent Action Model, LAM)
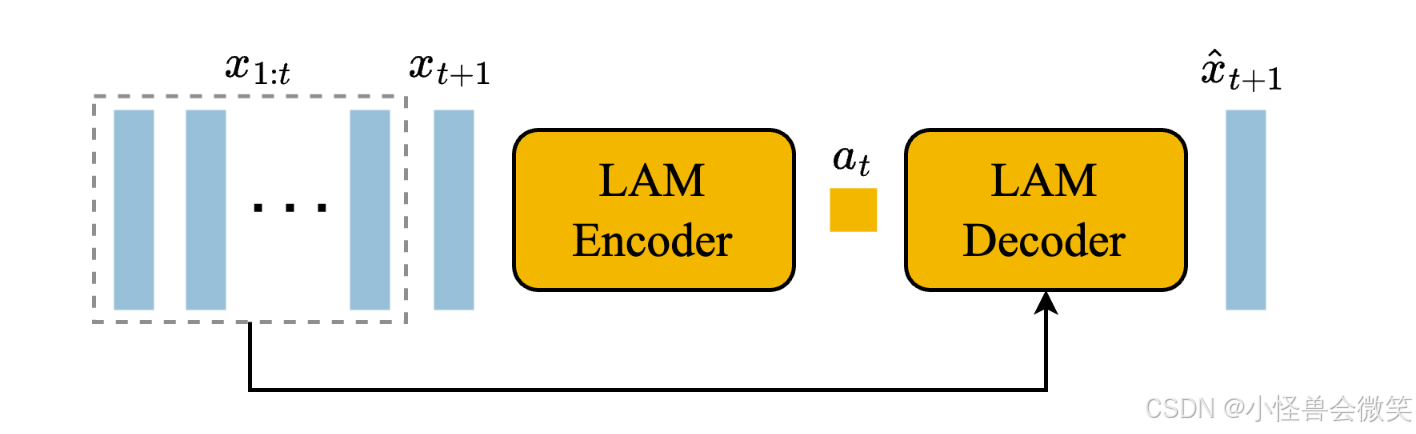
这是 Genie 能够实现"无监督提取可交互控制按键"的灵魂所在。它的目标是在没有人类真实按键标签的情况下,自己推理出帧与帧之间的"动作"。
- 编码器与解码器 :编码器观察视频的历史帧 x 1 : t x_{1:t} x1:t 和未来的下一帧 x t + 1 x_{t+1} xt+1,推断出它们之间发生的连续潜在动作 a ~ 1 : t \tilde{a}{1:t} a~1:t。解码器则试图仅依靠历史帧和这个潜在动作,重建出下一帧画面 x ^ t + 1 \hat{x}{t+1} x^t+1。
- 离散动作瓶颈 :为了让模型学出像游戏手柄一样人类可控的动作,LAM 使用了 VQ-VAE 目标函数,将推断出的动作强行限制在一个极小的离散词表中(词表大小 ∣ A ∣ = 8 |A|=8 ∣A∣=8)。这迫使模型只能用这 8 个"按键"来解释画面中发生的最关键变化。
- 用完即弃:有趣的是,除了那个包含 8 个动作的离散词表(Codebook),整个 LAM 的编码器和解码器在模型训练完成后就会被丢弃。在用户实际游玩(推理)时,这一部分由用户真实的键盘或手柄输入来替代。
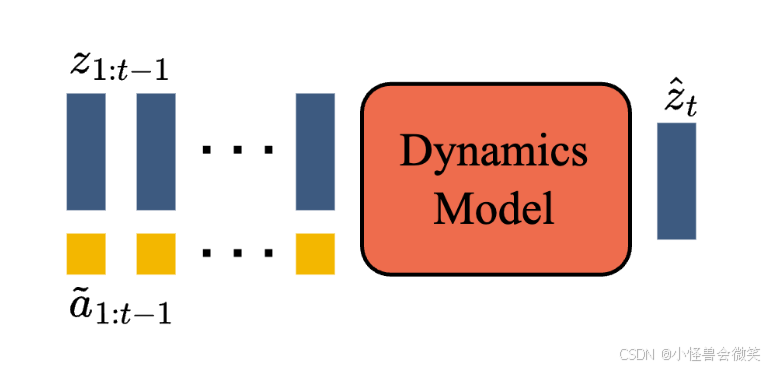
四、 组件 3:动力学模型 (Dynamics Model)
如果说 LAM 是游戏手柄,那么动力学模型就是游戏的主机/引擎,负责根据你的输入渲染出下一个画面。
- 自回归生成 :这是一个仅包含解码器的 MaskGIT Transformer。在每一个时间步 t t t,它接收已经被 Token 化的视频历史 z 1 : t − 1 z_{1:t-1} z1:t−1,以及 LAM 推理出(或用户输入)的潜在动作 a ~ 1 : t − 1 \tilde{a}_{1:t-1} a~1:t−1。
- 预测未来 :基于这些输入,它以前向自回归的方式,预测出下一帧画面的 Token z ^ t \hat{z}_t z^t。
- 动作嵌入:模型没有简单地将动作拼接在帧上,而是将潜在动作作为附加特征嵌入(Additive embeddings)融合进模型,这被证明能有效提升生成视频的可控性。
总结:它是如何协同工作的?
当你上传一张草图并按下"向右"键时:
- 分词器 将你的草图编码为初始的 Token z 1 z_1 z1。
- 你输入的离散动作 a 1 a_1 a1(比如"向右")通过查表转化为潜在动作 嵌入 a ~ 1 \tilde{a}_1 a~1。
- 动力学模型 接收 z 1 z_1 z1 和 a ~ 1 \tilde{a}_1 a~1,预测出下一帧的 Token z 2 z_2 z2。
- 最后,分词器的解码器 将 z 2 z_2 z2 解码为真实的图像像素显示在屏幕上。
这套架构优雅地将无监督动作发现与高效的大规模视频生成结合在了一起。
视频分词器 (Video Tokenizer)详解
这里有一个关键的认知差需要先澄清:在这篇论文中,所谓"加上时间层面的压缩",指的并不是物理上把时间维度 T T T 降维(比如把 16 帧压缩成 4 帧),而是指把过去的时间线上的"物理运动信息",压缩并融合到了当前帧的特征向量(Token)中。
为了让你看得更清晰,我们代入论文中使用的具体数值来推演整个过程。
初始设定:输入变量
根据论文,模型输入是一段连续的视频帧。为了方便理解 Patch 的整除关系,我们稍微对齐一下空间分辨率(假设输入为 160x160):
- T = 16 T = 16 T=16 (每次输入 16 帧的视频序列)
- H = 160 H = 160 H=160 (视频高度像素)
- W = 160 W = 160 W=160 (视频宽度像素)
- C = 3 C = 3 C=3 (RGB 图像通道)
输入张量维度 :[16, 160, 160, 3]
第 1 步:Patch Embedding(与普通 ViT 类似)
首先,我们要把连续的像素切块,变成 Transformer 认识的序列。
根据论文的设定,视频分词器使用的 patch_size = 4。
- 每帧图像被切成 4 × 4 4 \times 4 4×4 的小块。
- 单帧的 Token 数量 = ( 160 / 4 ) × ( 160 / 4 ) = 40 × 40 = 1600 (160 / 4) \times (160 / 4) = 40 \times 40 = 1600 (160/4)×(160/4)=40×40=1600 个位置。
- 每个位置的特征通过线性层映射到一个隐藏维度
d_model = 512(基于论文中编码器的设定)。
经过 Embedding 后的张量维度 :[16, 1600, 512]。
你可以把它看作:一共有 16 帧,每帧有 1600 个 Token,每个 Token 是一个 512 维的向量。
第 2 步:纯空间压缩 (Spatial-only) vs. Genie 的时空压缩 (Spatiotemporal)
这一步就是你最关心的核心差异。在进入 VQ 离散化之前,特征需要通过多层注意力网络(Genie 的 Encoder 有 12 层)。
【对比对象】:如果是"纯空间压缩" (Prior Works) 会怎么做?
纯空间压缩模型完全忽略了视频的连续性。
它会把这 16 帧看作是 16 张毫无关联的独立图片。在计算 Self-Attention 时,操作是在单帧内部进行的:
- 张量视图:将
[16, 1600, 512]视为Batch=16,对[1600, 512]进行标准的 Self-Attention。 - 结果 :第 t t t 帧里的某个 Token,只会和第 t t t 帧的其他像素做交互。算完之后,第 16 帧的特征里,一丝一毫前 15 帧的运动轨迹都没有。
【Genie 的做法】:ST-Transformer 架构的交错注意力
Genie 在这里使用了时空注意力块(ST-block),并且为了算力优化,采用了交错结构(Interleaved):
动作 A:空间注意力 (Spatial Attention)
- 操作:和纯空间模型一样,在各自的帧内部做 Self-Attention,提取一帧内物体的位置和外观信息。
- 维度变化 :维持
[16, 1600, 512]。
动作 B:时间注意力 (Temporal Attention) ------ 魔法发生的地方
- 操作 :模型做了一个转置(Transpose)。它不再关注一帧里的 1600 个位置,而是把 16 帧里的同一个物理位置串成一条线。
- 张量视图 :转置为
[1600, 16, 512]。相当于模型现在看着 1600 个独立的"时间管道",每个管道里有 16 个时刻的 512 维特征。 - 因果掩码 (Causal Mask) :在这个时间序列上做 Self-Attention 时,Genie 加上了因果掩码 。这意味着,第 t t t 时刻的特征,只能看到第 1 1 1 到 t t t 时刻的特征,不能看未来。
- 维度变化 :经过计算并转置回去,依然维持
[16, 1600, 512]。
(注:在跑完空间和时间注意力后,统一通过一个单独的 Feed-Forward 层,以优化规模扩展效率)。
第 3 步:Vector Quantization 离散化(进入"字典")
经过上面 12 层交错的时空注意力提取后,我们依然拿着一个 [16, 1600, 512] 的连续特征。
最后一步,VQ-VAE 要把这些连续向量变成论文中提到的离散的 z 1 : T ∈ Z T × D z_{1:T} \in \mathbb{Z}^{T \times D} z1:T∈ZT×D。
- Genie 会把 512 维的特征投影到
latent_dim = 32。张量变成[16, 1600, 32]。 - 它设定了一个大小为 1024 的密码本(Codebook,里面有 1024 个 32 维的基准向量)。
- 对于这 16 帧里的每一个(一共 16 × 1600 = 25600 16 \times 1600 = 25600 16×1600=25600 个)特征,模型都在密码本里找最相似的那个基准向量,并用它的 ID(0~1023 之间的一个整数)来代替原来的特征。
总结:什么是"时间层面的压缩"?
在这个 [T, H, W, C] 的变换旅程中:
- 物理维度上 :由于
patch_size = 4的卷积操作, H H H 和 W W W 的维度被大大压缩了(从 160 × 160 160 \times 160 160×160 变成了 40 × 40 40 \times 40 40×40)。时间 T T T 的维度并没有缩短,依然是 16 帧。 - 信息维度上(真正的"时间压缩") :得益于时间注意力机制里的因果掩码(Causal Mask),当模型输出第 t t t 帧的离散 Token z t z_t zt 时,这个 z t z_t zt 内部实际上已经被"压缩打包"并融合了从 x 1 x_1 x1 到 x t x_t xt 之前所有帧的物理动态历史。
这就是 Genie 分词器的核心优势:用它压缩出来的 Token 送给下游去预测下一帧时,下游模型不仅能"看见"当前屏幕上有什么,还能直接感受到画面里的实体是"从哪飞过来的"。
需要注意,很多早期的网络模型确实会采用"奇数层做 A,偶数层做 B"的交替设计!但在 Genie 这篇论文中,它的结构并不是把 12 层对半劈开,而是每一层(Layer/Block)内部都打包包含了这两者。
准确地说,论文中设定的"12层"(例如视频分词器编码器的 num_layers = 12)实际上是指 12 个完整的"时空块"(Spatiotemporal Blocks)。
根据论文的架构描述(对应原文的图 4),在每一个这样的时空块内部,操作的交错是这样进行的:
- 第一步:空间注意力(Spatial Attention) ------ 先在单帧内部提取图像特征。
- 第二步:时间注意力(Temporal Attention) ------ 紧接着在不同帧之间提取时序动态特征。
- 第三步:前馈神经网络(Feed-Forward Layer, FFW) ------ 对融合后的特征进行非线性变换。
所以,当这 12 层网络串联起来时,数据流动的真实形态是这样的:
[空间 -> 时间 -> FFW] ✖️ 第1块
⬇️
[空间 -> 时间 -> FFW] ✖️ 第2块
⬇️
... 一直循环到第 12 块。
总结一下,模型并没有把空间和时间的计算拆分到不同的层级中,而是确保在每一步的特征提取中,空间信息和时间动态都能立刻产生化学反应并融合在一起。相当于总共执行了 12 次空间注意力和 12 次时间注意力。
动力学模型 (Dynamics Model)详解
其实这里有一个非常关键的设计细节,刚好能纠正一个常见的直觉误区:
在 Genie 的动力学模型(Dynamics Model)中,视频信号 z z z 和动作信号 a a a 并不是在序列长度或特征维度上进行拼接(Concatenation)的,而是通过"加性嵌入"(Additive Embeddings)的方式进行融合的。
研究团队在论文中明确提到,与通常把动作拼接到对应帧后面的做法不同,将潜在动作作为附加特征直接"加"进去,能够显著提高生成视频的可控性。
既然你对网络底层很熟悉,我们继续用具体张量(Tensor)维度的推演来看看这究竟是怎么做的。
前提假设(与上文保持一致)
- T = 16 T = 16 T=16(视频帧数)
- S = 1600 S = 1600 S=1600 (每帧被切分成的 Token 数量,即 40 × 40 40 \times 40 40×40)
- D = 5120 D = 5120 D=5120 (这是 Genie 最终 110 亿参数动力学模型的隐藏层维度
d_model)
维度推演:从离散输入到融合张量
第 1 步:视频 Token 嵌入 (Video Token Embedding)
视频分词器输出的是离散的字典索引(0~1023)。
- 输入张量 :动力学模型接收的视频序列 z z z 的维度是
[16, 1600](16帧,每帧1600个整数索引)。 - Embedding 操作:模型内部有一个独立的 Token 嵌入层(Embedding Table),将这些离散的整数映射为连续的高维向量。
- 输出维度 :
[16, 1600, 5120]。
第 2 步:动作嵌入 (Action Embedding)
动作也是离散的整数(0~7,代表 8 个潜在动作)。在生成第 t t t 帧到第 t + 1 t+1 t+1 帧时,有一个对应的动作。
- 输入张量 :动作序列 a a a 的维度是
[16](16个整数,代表每帧对应的动作)。 - Embedding 操作 :通过动作嵌入层,将这 16 个离散动作映射到与动力学模型完全相同 的隐藏层维度 D D D。
- 输出维度 :
[16, 5120]。
第 3 步:广播与相加 (Broadcasting & Addition)
既然是"加性嵌入",就需要把动作张量加到视频张量上。但这两个张量的形状不一样(一个是 [16, 5120],另一个是 [16, 1600, 5120]),怎么办?
- 广播机制 (Broadcasting) :模型会在序列长度维度上对动作向量进行复制(广播),把
[16, 5120]隐式扩充为[16, 1600, 5120]。
(直白地说:第 t t t 帧对应的那个动作向量,被复制了 1600 份。) - 按元素相加 (Element-wise Addition):将两者直接相加,再加上时空位置编码(Positional Embeddings)。
Input f i n a l = TokenEmb ( z ) + ActionEmb ( a ) + PosEmb \text{Input}_{final} = \text{TokenEmb}(z) + \text{ActionEmb}(a) + \text{PosEmb} Inputfinal=TokenEmb(z)+ActionEmb(a)+PosEmb
融合后的最终输入张量维度依然保持纯净的:[16, 1600, 5120]。
为什么用"相加"而不是"拼接"?
在传统的强化学习或早期的世界模型中,大家习惯的做法是拼接 (比如变成 [16, 1601, 5120],把动作当成一个额外的 Token 放在每帧的开头)。
但 Genie 团队发现,加性嵌入(Additive Embeddings)效果更好。从注意力机制的角度来理解:
如果拼接成一个单独的 Token,画面中的 1600 个图像 Patch 需要通过 Attention 机制去"看"那个动作 Token 才知道发生了什么。
但如果使用相加 ,动作信号就像"染料"一样,被直接注入到了这一帧画面的每一个像素块(Patch)的底层特征中。这就使得动力学模型在计算空间和时间注意力时,每一个位置从一开始就带着强烈的"动作意图"(比如所有 Patch 都知道我现在要向右走了),从而让生成的画面对动作的响应更加敏感、可控。
玩的时候情况详解
Genie 在实际应用中最特别(也最反直觉)的一点。
当用户真正在屏幕前"玩"这个生成的环境时,情况是这样的:
- 只有数字代码 :玩家在每一帧需要指定一个离散的整数值来代表动作,例如输入 0 到 7 之间的数字(对应设定的词表大小 ∣ A ∣ = 8 |A|=8 ∣A∣=8)。由于模型是在完全没有动作标签的情况下进行无监督训练的,连模型自己都没有"向左"、"跳跃"这样带有明确语义的标签。
- 初始的"盲盒"体验:论文作者在描述推理过程时特别提到,当玩家第一次与模型交互时,是完全不清楚每个潜在动作具体会如何影响下一帧画面生成的。
- 摸索新按键:作者打了一个非常贴切的比方:这就好比你拿到了一把全新的游戏控制手柄,你需要通过按下按钮并观察屏幕上的反应,来"学习"和适应这把手柄的按键映射。
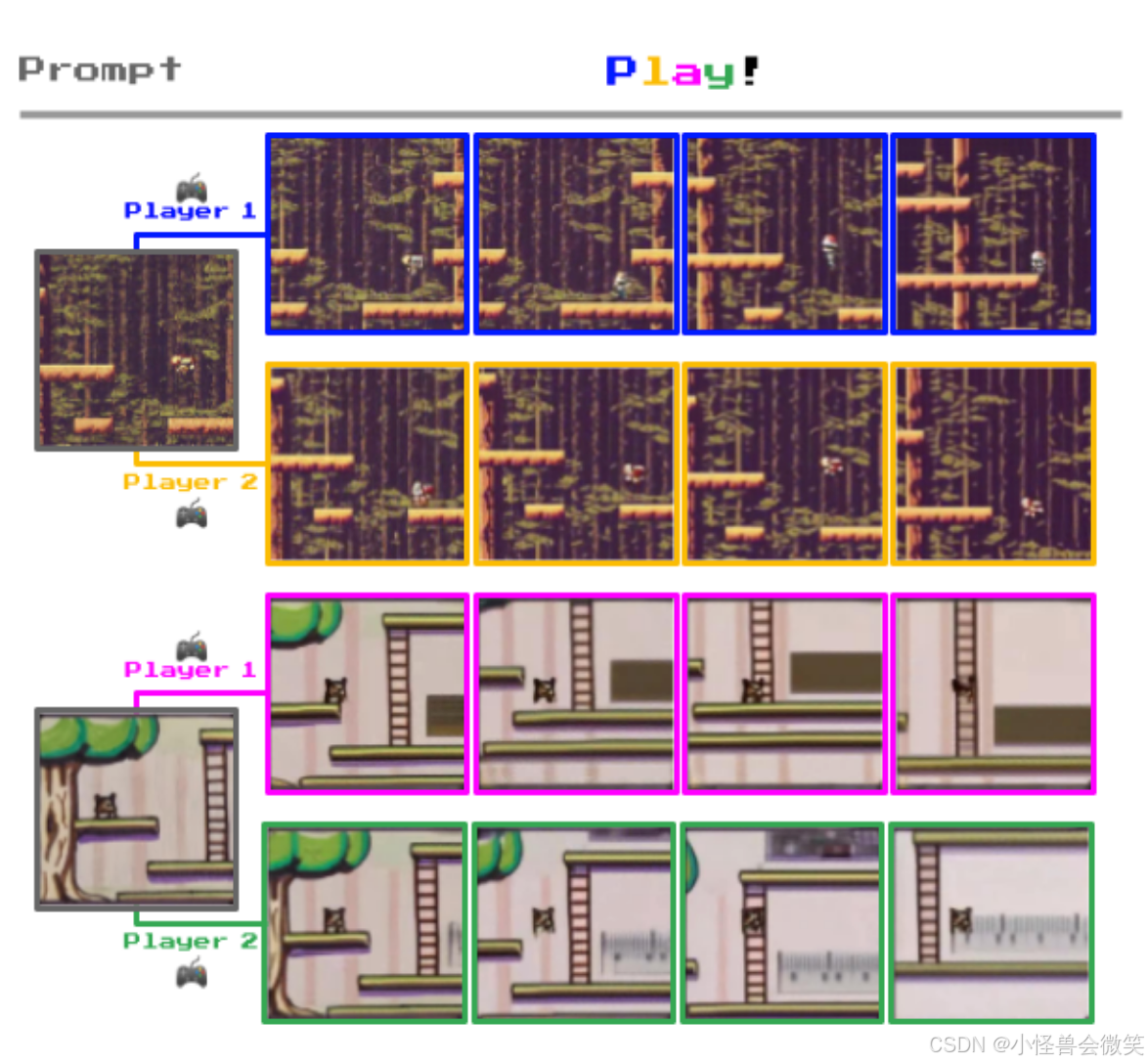
- 动作的一致性:幸运的是,模型学到的这些动作非常有规律。作者发现,无论输入什么不同的画面,每个动作的含义都保持一致。一旦你试出来某个键代表某个特定动作(比如向右走),那么在接下来的游玩中它依然会稳定地代表这个物理含义。
这就是为什么它被称为"潜在动作(Latent Actions)"------动作真实的物理意义隐藏在这些干瘪的数字背后,等待着人类玩家去"试错"并赋予它们意义。
每一次按下按钮,下一帧画面都是由一个百亿参数规模的大模型实时"凭空"计算和渲染出来的,所以它真的非常慢。
在论文的结尾部分,DeepMind 团队非常坦诚地指出了这个局限性:Genie 目前的运行帧率大约只有 1 FPS(每秒生成 1 帧)。
为了实现顺畅的人机交互,目前它迫切需要未来的技术突破来提升帧率。我们可以从底层的角度来看看,为什么它会卡成"定格动画":
- 巨大的计算量(110亿参数):你是在用一个 11B 参数的庞然大物来当游戏引擎。传统的游戏引擎是基于物理引擎和预先做好的贴图来渲染多边形;而 Genie 是让庞大的神经网络做矩阵乘法,硬生生"算"出画面,这本身就是极度消耗算力的。
- 自回归与多次采样(MaskGIT 步骤):在生成下一帧时,动力学模型并不是"唰"地一下就把所有 Token 吐出来。论文中提到,在推理阶段,模型需要对每一帧进行 25 次 MaskGIT 采样步骤。这意味着为了憋出一帧画面,模型内部要进行多轮迭代。
- 解码的开销:好不容易算出了下一帧的 Token,最后还需要通过视频分词器(ST-ViViT)的解码器,将这些高度压缩的 Token 重新还原成你在屏幕上看到的像素画面。
所以,现阶段的 Genie 与其说是一个能玩 60 帧丝滑连招的"动作游戏",不如说它更像是一个 "回合制"游戏或是概念验证(Proof of Concept)。你输入一个动作,等个一秒钟,画面动一下。
不过,这也是所有生成式大模型发展初期的常态。就像早期的文生图模型画一张图要几分钟,现在只要几秒甚至毫秒级。未来随着推测解码(Speculative Decoding)、模型蒸馏(Distillation)以及专用硬件(如下一代 TPU/GPU)的进步,这种"实时生成式引擎"的渲染速度一定会迎来指数级的提升。