作者:洛水石
适用人群:3 年经验 Java 开发,面中级/高级岗位。本题库按模块分类,每题给出标准回答要点,可在面试前 3 天集中背诵。
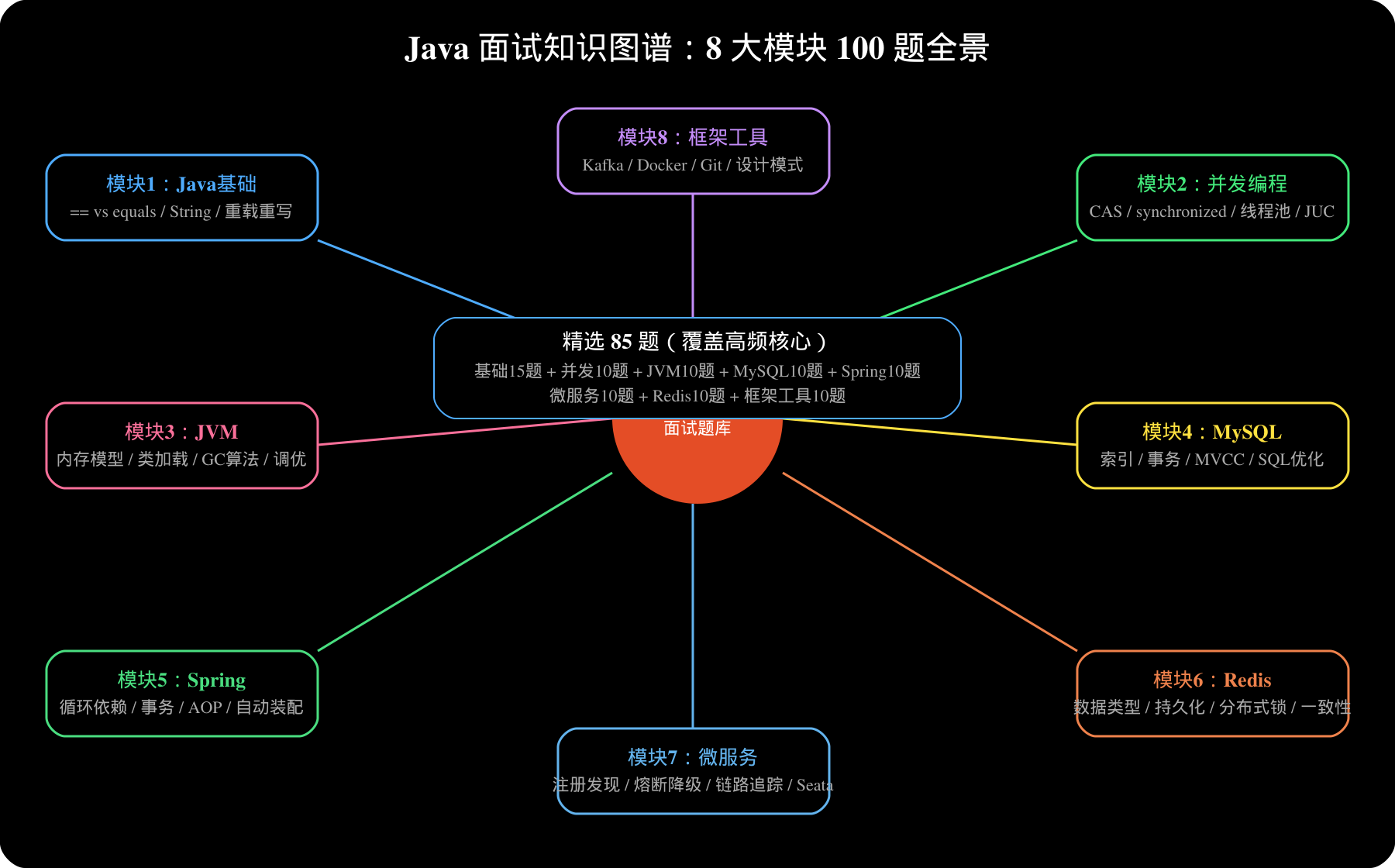
一、Java 基础(15题)
**Q1:== 和 equals 的区别?**
-
`==`:比较基本类型时比较值,比较引用类型时比较内存地址
-
`equals()`:默认 Object 实现比较地址,子类(String、Integer)通常重写为比较内容
-
常见坑:String pool 常量池导致 `new String("abc") == "abc"` 为 false
```java
String s1 = new String("hello");
String s2 = "hello";
System.out.println(s1 == s2); // false(new 的是新对象)
System.out.println(s1.equals(s2)); // true(内容相同)
```
**Q2:final、finally、finalize 的区别?**
-
`final`:修饰类(不可继承)、方法(不可重写)、变量(不可重新赋值)
-
`finally`:`try-catch-finally` 块中的代码,无论是否异常都执行(除非 System.exit())
-
`finalize()`:Object 的方法,GC 回收对象前调用,已废弃(不推荐使用)
**Q3:String、StringBuilder、StringBuffer 的区别?**
| 类 | 线程安全 | 性能 | 使用场景 |
|---|---|---|---|
| String | 安全 | 差(每次new) | 常量字符串 |
| StringBuilder | 不安全 | 好 | 单线程字符串拼接 |
| StringBuffer | 安全(synchronized) | 中 | 多线程字符串拼接 |
**Q4:重载(Overload)和重写(Override)的区别?**
-
**重载(Overload)**:同一个类中,方法名相同但参数列表不同(个数、类型、顺序),编译时多态
-
**重写(Override)**:子类重写父类方法,方法签名完全相同,运行时常多态
**Q5:接口和抽象类的区别?**
| 维度 | 接口 | 抽象类 |
|---|---|---|
| 关键字 | `interface` | `abstract class` |
| 方法 | JDK8前全抽象;JDK8+可default/static | 可抽象可普通 |
| 属性 | 只能是 public static final | 无限制 |
| 多继承 | 支持多接口 | 只支持单继承 |
| 构造器 | 无 | 有 |
面试加分:**JDK9 接口 private 方法**、**函数式接口 @FunctionalInterface**。
**Q6:ArrayList 和 LinkedList 的区别?**
| 维度 | ArrayList | LinkedList |
|---|---|---|
| 底层结构 | 动态数组 | 双向链表 |
| 随机访问 | O(1) | O(n) |
| 插入/删除 | O(n)(搬移元素) | O(1)(指针操作) |
| 内存占用 | 连续,浪费扩容空间 | 每个节点存前后指针 |
选择建议:频繁随机访问 → ArrayList;频繁中间插入删除 → LinkedList。
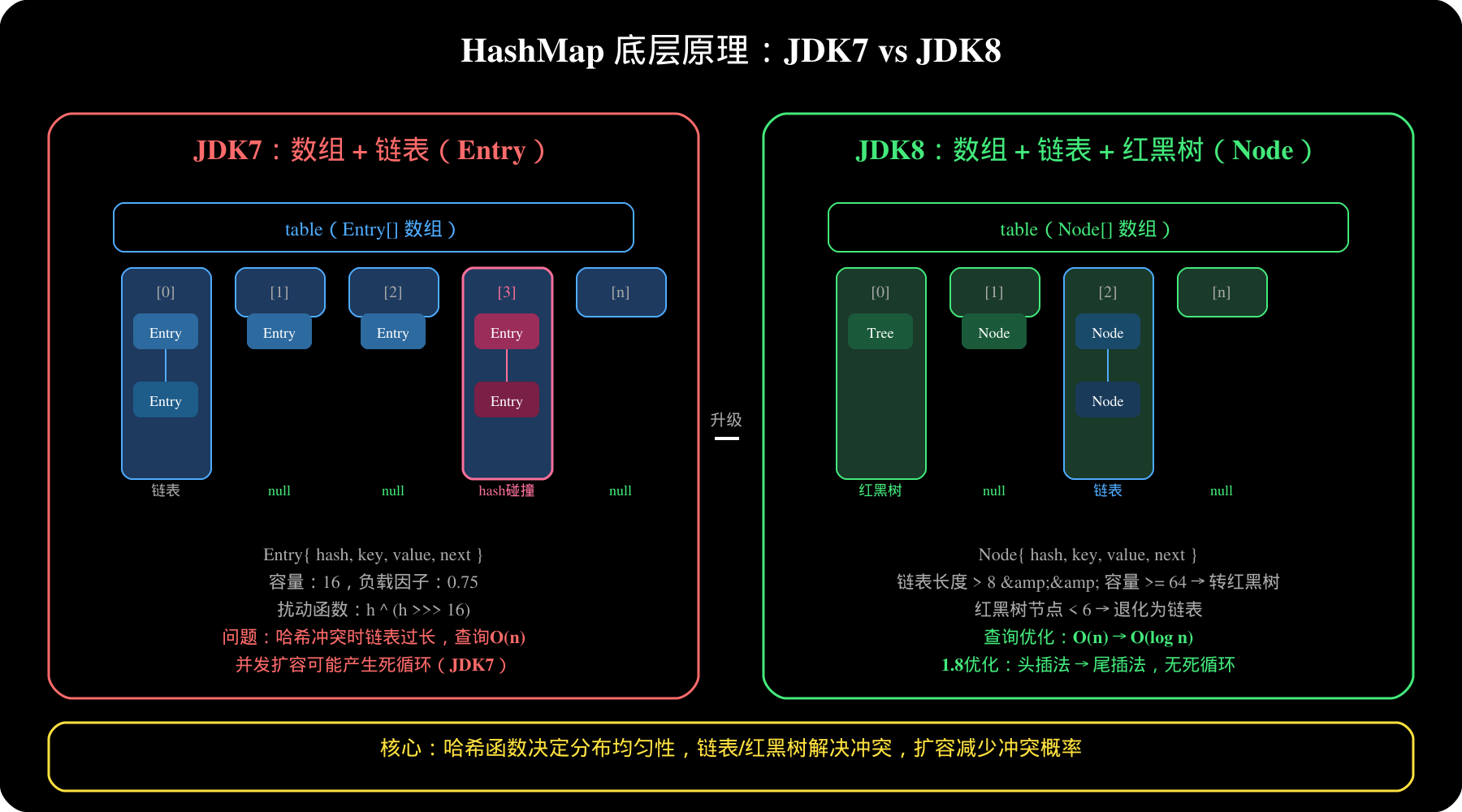
**Q7:HashMap 的底层实现原理?**
-
JDK7:`数组 + 链表`(Entry数组),哈希冲突用链表解决
-
JDK8:`数组 + 链表 + 红黑树`(链表长度 > 8 且容量 > 64 时转为红黑树)
-
扰动函数:`(h = key.hashCode()) ^ (h >>> 16)`,减少哈希碰撞
-
扩容因子:默认 0.75,扩容翻倍重新哈希
```java
// JDK8 红黑树转链表阈值
if (binCount >= TREEIFY_THRESHOLD - 1) // = 7,转为红黑树
```
**Q8:HashMap 是线程安全的吗?有什么替代方案?**
-
HashMap 线程不安全,并发下可能死循环(JDK7 扩容时)
-
替代方案:
-
`Hashtable`:全局 synchronized,锁粒度大,不推荐
-
`Collections.synchronizedMap()`:同 Hashtable
-
`ConcurrentHashMap`:**推荐**,JDK7分段锁,JDK8+CAS+synchronized
**Q9:ConcurrentHashMap JDK7 和 JDK8 的区别?**
-
**JDK7**:Segment数组 + HashEntry 数组,锁住一个 Segment,其他 Segment 可并发
-
**JDK8**:取消 Segment,改为 `Node数组 + CAS + synchronized`,锁粒度细化到每个桶
**Q10:什么是 CAS?有什么问题?**
-
CAS(Compare-And-Swap):无锁并发,CPU 提供原子指令
-
三个操作数:内存位置V、预期值A、新值B;V==A 时才更新为B
-
问题:
-
**ABA问题**:加版本号(AtomicStampedReference)解决
-
自旋开销:竞争激烈时大量空转
-
只能保证一个共享变量原子性
**Q11:synchronized 和 ReentrantLock 的区别?**
| 维度 | synchronized | ReentrantLock |
|---|---|---|
| 锁类型 | 悲观锁/可重入 | 可重入 |
| 等待可中断 | 否 | 是(tryLock) |
| 公平锁 | 否(默认非公平) | 可选(fair=true) |
| 条件变量 | 内置(wait/notify) | 多个(newCondition) |
| 释放方式 | 自动释放 | 必须 finally unlock() |
**Q12:ThreadLocal 有什么用?有什么坑?**
-
**作用**:为每个线程提供独立的变量副本,实现线程隔离
-
**典型场景**:SimpleDateFormat(线程不安全)、数据库连接、Session管理
-
**坑**:
-
内存泄漏:`ThreadLocalMap` Entry 弱引用 `WeakReference<ThreadLocal>`,但Value是强引用。正确做法:用完 `remove()`。
-
父子线程:InheritableThreadLocal 可继承,但线程池场景下不行(用 Alibaba TransmittableThreadLocal)
**Q13:volatile 关键字的作用?**
-
**可见性**:每次读取强制从主内存读,每次写入强制刷新到主内存
-
**有序性**:禁止指令重排序(内存屏障)
-
**不保证原子性**:`volatile int count++;` 仍不是线程安全的(需要 AtomicInteger)
**Q14:sleep() 和 wait() 的区别?**
| 维度 | sleep() | wait() |
|---|---|---|
| 所属 | Thread 静态方法 | Object 实例方法 |
| 锁释放 | 不释放 | 释放锁 |
| 唤醒方式 | 超时自动醒 | notify()/notifyAll() 或超时 |
| 使用场景 | 模拟延迟、轮询 | 生产者-消费者等待 |
**Q15:线程池的七大参数?拒绝策略?**
```java
public ThreadPoolExecutor(
int corePoolSize, // 核心线程数
int maximumPoolSize, // 最大线程数
long keepAliveTime, // 空闲线程存活时间
TimeUnit unit, // 时间单位
BlockingQueue<Runnable> workQueue, // 任务队列
ThreadFactory threadFactory, // 线程工厂
RejectedExecutionHandler handler // 拒绝策略
)
```
拒绝策略:
-
`AbortPolicy`(默认):抛RejectedExecutionException
-
`CallerRunsPolicy`:调用者线程执行
-
`DiscardPolicy`:丢弃任务
-
`DiscardOldestPolicy`:丢弃队列最老的任务
二、Java 并发(10题)
**Q16:线程的创建方式?哪种最好?**
-
继承 `Thread`(单继承局限)
-
实现 `Runnable`(无返回值)
-
实现 `Callable + FutureTask`(有返回值,可抛异常)
-
**线程池**(最佳,资源复用、线程管理)
生产环境严禁 `new Thread()`,统一使用线程池。
**Q17:线程的生命周期?**
```
NEW → RUNNABLE → BLOCKED → WAITING → TIMED_WAITING → TERMINATED
```
-
NEW:创建未启动
-
RUNNABLE:就绪(Ready)或运行中(Running)
-
BLOCKED:等待锁(synchronized)
-
WAITING:wait()/join()/LockSupport.park()
-
TIMED_WAITING:sleep(n)/wait(n)/await(n,TimeUnit)
**Q18:Synchronized 锁升级过程?**
无锁 → 偏向锁 → 轻量级锁 → 重量级锁(不可降级)
-
**偏向锁**:Mark Word 记录线程ID,同一线程进入轻量级锁CAS替换Mark Word
-
**轻量级锁**:自旋 CAS 抢锁,自旋失败一定程度后膨胀
-
**重量级锁**:ObjectMonitor,线程阻塞,用户态→内核态切换,开销大
**锁粗化、锁消除**是JIT编译器的优化手段。
**Q19:什么是死锁?四个必要条件?如何排查?**
四个必要条件:互斥、占有并等待、不可抢占、循环等待
**排查命令**:
```bash
jstack <pid> # 查找死锁线程
或 VisualVM / Arthas
```
**避免死锁**:统一加锁顺序、使用锁超时、使用并发工具(Phaser、CyclicBarrier)
**Q20:JUC 常用并发工具?**
| 类 | 作用 |
|---|---|
| `CountDownLatch` | 倒计时闩,某线程等待N个操作完成 |
| `CyclicBarrier` | 循环栅栏,N个线程相互等待到齐后一起执行 |
| `Semaphore` | 信号量,控制并发访问资源数量 |
| `Exchanger` | 两个线程交换数据 |
三、JVM(10题)
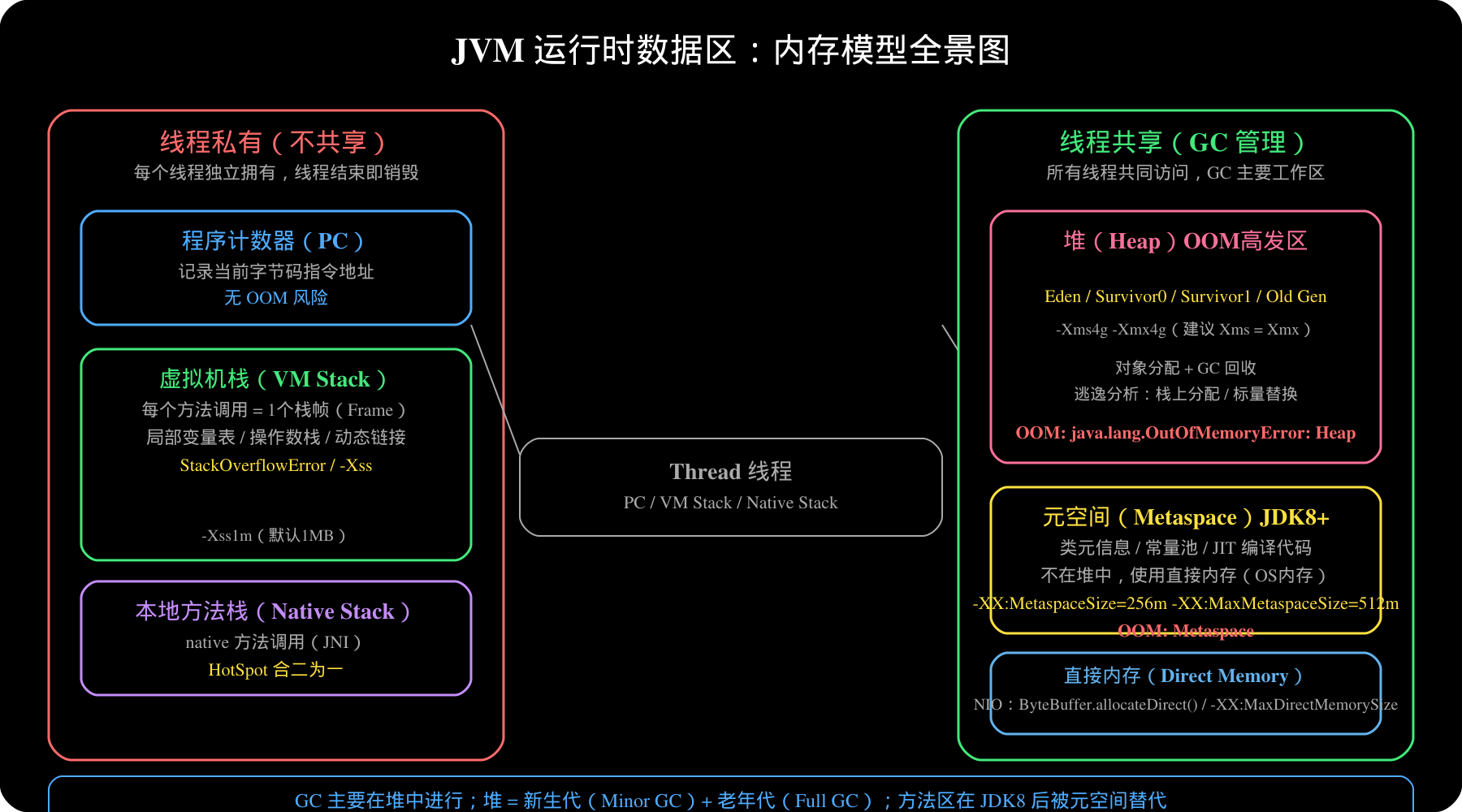
**Q21:JVM 内存区域划分?**
-
**线程私有**:程序计数器(无OOM)、虚拟机栈(StackOverflowError)、本地方法栈
-
**线程共享**:堆(OOM高发区)、方法区/元空间(OOM)
JDK8 将方法区改为元空间(Metaspace),使用直接内存,不在堆中。
**Q22:对象的创建过程?**
-
类加载检查(常量池)
-
分配内存(指针碰撞 / 空闲列表)
-
初始化零值
-
设置对象头(Mark Word、类型指针)
-
执行构造器
并发分配:CAS + 失败重试 / TLAB(线程本地分配缓存)
**Q23:Minor GC 和 Full GC 的触发条件?**
-
**Minor GC**:Eden区满,Survivor区交换
-
**Full GC**:
-
老年代空间不足
-
System.gc()(建议触发,不一定)
-
Metaspace 不足
-
Minor GC 前的安全检查(-XX:PretenureSizeThreshold)
**Q24:CMS 和 G1 的区别?**
| 维度 | CMS | G1 |
|---|---|---|
| 收集范围 | 老年代 | 全堆(老年代+年轻代) |
| 回收方式 | 标记-清除(内存碎片) | 标记-整理(无碎片) |
| 停顿时间 | STW时间长 | 可控制(-XX:MaxGCPauseMillis) |
| 分代方式 | 物理分代 | 逻辑分代(Region) |
**G1 是 JDK9+ 默认收集器**,适合大堆(>6GB)低延迟场景。
**Q25:什么对象会进入老年代?**
-
大对象(`-XX:PretenureSizeThreshold`,直接进老年代)
-
长期存活对象(Survivor 中年龄 >= `-XX:MaxTenuringThreshold`,默认15)
-
动态年龄判断:Survivor 中相同年龄所有对象总和 > Survivor 空间一半,则 >= 该年龄的直接进老年代
**Q26:类加载过程?双亲委派模型?**
加载 → 验证 → 准备 → 解析 → 初始化
**双亲委派**:类加载请求委派给父类加载器处理,最终顶层的 BootstrapClassLoader。若父类找不到,才自己加载。
好处:类唯一性保证、安全性(防止核心API被篡改,如自定义String)
**Q27:什么情况下会触发类初始化?**
-
new、读取/设置静态字段(final已在编译期放入常量池的除外)
-
调用静态方法
-
反射 `Class.forName()`
-
初始化子类时先初始化父类
-
主类(main方法所在类)先初始化
**Q28:常用的 JVM 调优参数?**
```bash
-Xms512m -Xmx512m # 堆初始/最大
-Xss1m # 线程栈大小
-XX:MetaspaceSize=256m # 元空间
-XX:+UseG1GC # 使用G1收集器
-XX:MaxGCPauseMillis=200 # 最大GC停顿时间
-XX:+HeapDumpOnOutOfMemoryError # OOM时导出堆dump
-XX:HeapDumpPath=/tmp/heap.hprof
```
**Q29:如何定位 OOM 问题?**
-
添加参数 `-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=`
-
MAT(Memory Analyzer Tool)分析堆 dump
-
** Arthas dashboard** 查看内存使用
-
查看 GC 日志:`GCLogFileSize`、`PrintGCDetails`
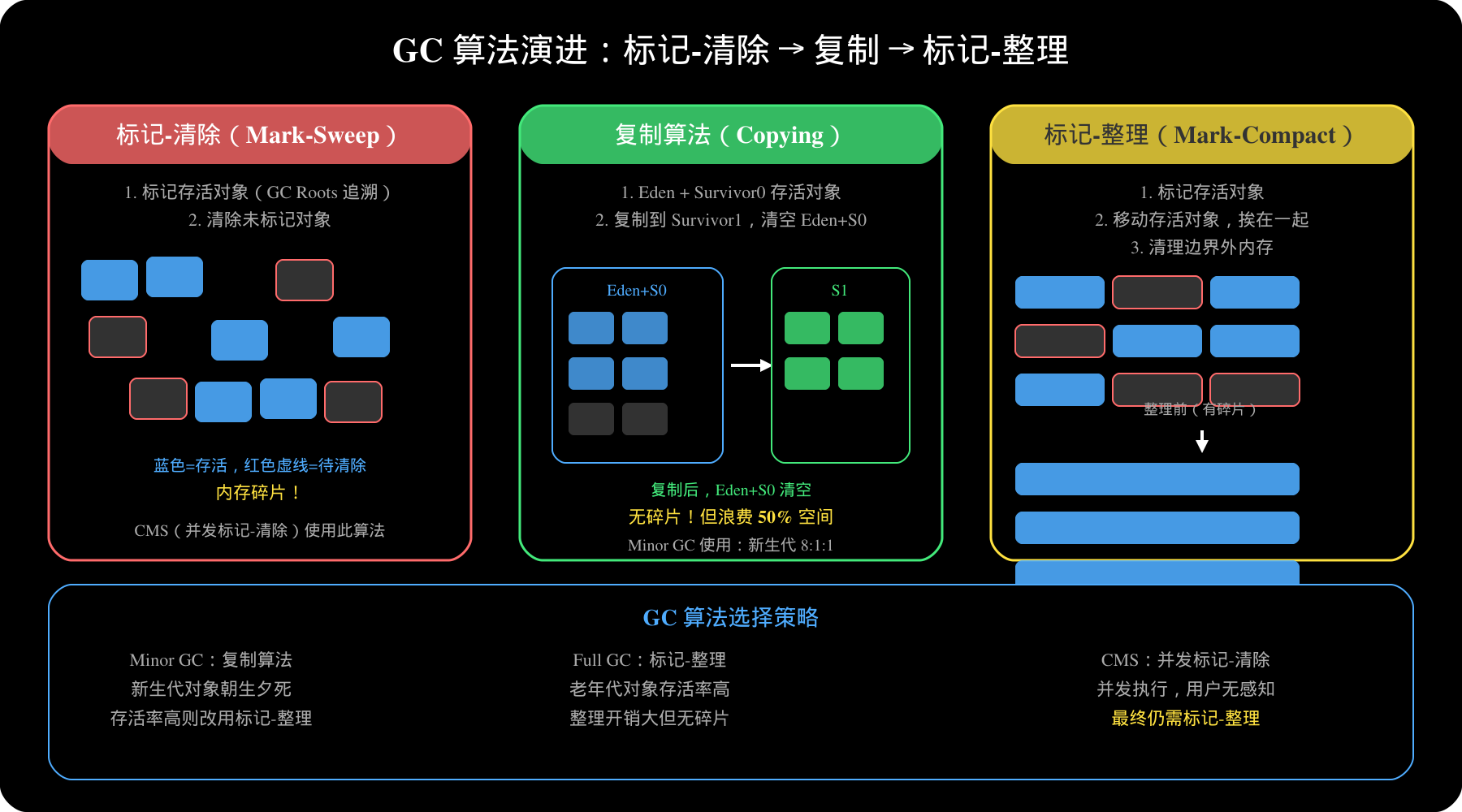
**Q30:JVM 三色标记算法?**
-
白色:未标记,垃圾
-
灰色:自身已标记,但引用的对象未标记
-
黑色:自身和引用对象都已标记
**并发问题**:漏标(漏标对象被当作垃圾)和多标(不该回收的对象被回收)。解决方案:**SATB(Snapshot-At-The-Beginning,G1使用)** 和 **增量更新(CMS使用)**。
四、MySQL(10题)
**Q31:MySQL 存储引擎?InnoDB 和 MyISAM 的区别?**
| 维度 | InnoDB | MyISAM |
|---|---|---|
| 事务 | 支持 | 不支持 |
| 外键 | 支持 | 不支持 |
| 锁粒度 | 行锁(高并发) | 表锁 |
| 全文索引 | 5.6+ 支持 | 支持 |
| 崩溃恢复 | 自动恢复(redo log) | 差 |
| 主键 | 必须有主键,无则自动生成 | 可无 |
**Q32:索引失效的常见场景?**
-
`WHERE id + 1 = 10`(计算)
-
`WHERE name LIKE '%abc'`(前导%)
-
`WHERE age > 18 ORDER BY name`(违反最左前缀)
-
`WHERE status = 1 AND id > 5`(范围之后全失效)
-
`WHERE IS NULL`(允许NULL但可能失效)
-
`WHERE LENGTH(name) > 5`(函数)
**Q33:什么是回表?如何避免?**
回表:先查普通索引拿到主键ID,再回主键索引查完整行数据(2次B+树)。
避免方法:
-
覆盖索引:查询字段全部在索引中,无需回表
-
`SELECT *` 容易回表,尽量 `SELECT 具体字段`
```sql
-- 覆盖索引示例(无需回表)
SELECT name, age FROM user WHERE name = 'Tom';
-- 索引:(name, age) 即可覆盖
```
**Q34:事务隔离级别?各有什么问题?**
| 级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| READ UNCOMMITTED | 可能 | 可能 | 可能 |
| READ COMMITTED | 不可能 | 可能 | 可能 |
| REPEATABLE READ(MySQL默认) | 不可能 | 不可能 | 可能 |
| SERIALIZABLE | 不可能 | 不可能 | 不可能 |
InnoDB 在 RR 级别通过 MVCC + Next-Key Lock 基本解决幻读问题。
**Q35:MVCC 原理?**
-
隐藏列:`trx_id`(事务版本号)、`roll_pointer`(指向undo log链)
-
ReadView:快照读时生成,包含 `m_ids`(活跃事务ID列表)、`min_trx_id`、`max_trx_id`
-
可见性判断:`trx_id < min_trx_id` → 可见;`trx_id > max_trx_id` → 不可见(其他事务提交);中间则检查是否在活跃列表中
**Q36:一条 SQL 执行很慢,如何排查?**
-
`EXPLAIN` 查看执行计划(type、key、rows、Extra)
-
检查是否全表扫描(type=ALL)
-
检查索引是否失效
-
`SHOW STATUS LIKE 'Slow_queries'` 查看慢查询
-
开启慢查询日志(`slow_query_log`)
-
`SHOW OPEN TABLES` 检查锁等待
**Q37:什么是主从复制?原理?**
```
Master → Binlog → Dump线程 → Relay Log → SQL线程 → Slave
```
-
Master:记录数据变更到 Binlog
-
Slave:IO线程读取Binlog写入Relay Log,SQL线程重放Relay Log
-
同步方式:异步复制 / 半同步复制(5.7+)
**Q38:分库分表后,如何保证 ID 全局唯一?**
-
UUID(无序、存储大)
-
数据库自增(单库没问题,跨库需独立ID服务)
-
**雪花算法(Snowflake)**:41位时间戳+10位机器ID+12位序列号,趋势递增
-
百度 UidGenerator / 美团 Leaf
**Q39:InnoDB 锁有哪些类型?**
-
行锁:共享锁(S)、排他锁(X)
-
意向锁:表级,IS/IX(防止加表锁时逐行检查)
-
Gap锁:间隙锁,锁定范围(左开右开区间)
-
Next-Key锁:记录锁+间隙锁,左开右闭(解决幻读)
-
插入意向锁(Insert Intention Lock)
**Q40:一条 UPDATE 语句的执行过程?**
-
解析器解析 SQL
-
优化器选择索引
-
执行器调用存储引擎接口
-
写入 redo log(Prepare)→ 写入 undo log
-
修改 Buffer Pool 中的数据页
-
事务提交时写入 binlog
-
redo log 标记为 Commit
**两阶段提交**:保证 redo log 和 binlog 一致性。
五、Spring(10题)
**Q41:Spring 循环依赖如何解决?**
三级缓存:
-
**singletonObjects**(一级):完全初始化好的单例Bean
-
**earlySingletonObjects**(二级):提前暴露,未完全初始化的Bean
-
**singletonFactories**(三级):ObjectFactory,提前暴露的Bean工厂
```
A创建 → 提前暴露A工厂 → A发现依赖B → B创建 → 提前暴露B工厂
→ B发现依赖A → 从三级缓存拿到A的ObjectFactory → 创建代理 → 放入二级缓存
```
**构造器注入导致的循环依赖无法解决**,必须改用 Setter 注入或 @Lazy。
**Q42:@Autowired 和 @Resource 的区别?**
| 维度 | @Autowired | @Resource |
|---|---|---|
| 来源 | Spring | JDK(JSR-250) |
| 注入方式 | byType → byName | byName → byType |
| required属性 | 支持(默认true) | 不支持 |
| 位置 | 字段/构造器/setter | 字段/setter |
**Q43:BeanFactory 和 FactoryBean 的区别?**
-
**BeanFactory**:Spring IOC容器最底层接口,负责Bean的创建和依赖注入
-
**FactoryBean**:工厂Bean,用于创建复杂Bean(如MyBatis SqlSessionFactory)
MyBatis `MapperFactoryBean` 实现了 FactoryBean,这就是为什么 `@MapperScan` 后可以直接注入 Mapper。
**Q44:Spring 事务失效的场景?**
-
方法非public(代理限制)
-
自调用(同类内部方法调用,不经过代理)
-
异常被 catch 吞掉了(需 `TransactionAspectSupport.currentTransactionStatus().setRollbackOnly()`)
-
事务传播行为不当(PROPAGATION_REQUIRES_NEW)
-
非Spring管理的Bean(new出来的对象)
-
数据库不支持事务(MySQL MyISAM)
**Q45:Spring MVC 请求处理流程?**
```
请求 → DispatcherServlet → HandlerMapping → HandlerExecutionChain
→ HandlerAdapter → Handler(Controller)
→ ViewResolver 解析视图名 → View 渲染响应
```
**Q46:Spring Boot 自动装配原理?**
-
`@SpringBootApplication` = `@Configuration` + `@EnableAutoConfiguration` + `@ComponentScan`
-
`META-INF/spring.factories` 或 `META-INF/spring/org.springframework.boot.autoconfigure.AutoConfiguration.imports`
-
`EnableAutoConfiguration` 导入所有 `AutoConfigurationImportSelector`
-
`@Conditional` 系列注解按需实例化Bean
**Q47:Spring Bean 的生命周期?**
```
实例化 → 属性填充(@Autowired) → BeanNameAware → BeanFactoryAware
→ ApplicationContextAware → BeanPostProcessor.postProcessBeforeInitialization
→ @PostConstruct → InitializingBean.afterPropertiesSet → 自定义init-method
→ BeanPostProcessor.postProcessAfterInitialization → 使用中
→ @PreDestroy → DisposableBean.destroy → 自定义destroy-method
```
**Q48:Spring 用了哪些设计模式?**
| 模式 | 应用 |
|---|---|
| 单例模式 | Bean默认单例 |
| 工厂模式 | BeanFactory |
| 代理模式 | AOP(@AspectJ) |
| 策略模式 | Resource实现 |
| 模板方法 | JdbcTemplate、HibernateTemplate |
| 观察者模式 | ApplicationEvent、ApplicationListener |
**Q49:MyBatis #{} 和 ${} 的区别?**
-
`#{}`:**预编译参数**,防止SQL注入,用 `?` 占位
-
`${}`:**直接拼接**,有SQL注入风险,仅适用于表名/列名动态传入
```java
// #{} 安全
SELECT * FROM user WHERE id = #{id} → SELECT * FROM user WHERE id = ?
// ${} 有注入风险
SELECT * FROM ${tableName} → 直接拼接
```
**Q50:MyBatis 一级缓存和二级缓存?**
-
**一级缓存**(SqlSession级别):同一个 SqlSession 中,查询结果缓存(Map),事务提交/关闭时清空
-
**二级缓存**(Mapper级别):跨 SqlSession,需手动开启;`cacheEnabled=true`;注意:实体类需实现 Serializable
-
缓存失效:任何增删改操作(`flushCache=true`)
六、微服务与分布式(10题)
**Q51:Dubbo 和 Spring Cloud 的区别?**
| 维度 | Dubbo | Spring Cloud |
|---|---|---|
| 通信协议 | RPC(Dubbo协议/Netty) | HTTP(RESTful) |
| 性能 | 高(二进制序列化) | 较低(JSON序列化) |
| 功能完整性 | 缺配置/网关等 | 全家桶,生态完整 |
| 适用场景 | 高并发内部微服务 | 异构系统、开放API |
**选型建议**:内部高性能通信选Dubbo;需要快速集成、异构系统选Spring Cloud Alibaba。
**Q52:Nacos 的注册与发现原理?**
-
服务启动时向 Nacos 注册自身(IP、Port、实例ID)
-
Nacos 心跳检测(默认5秒),超时15秒标记为不健康,30秒删除
-
消费者从 Nacos 获取服务列表,本地缓存 + 定时更新
-
Nacos 支持临时实例(心跳)和永久实例(不主动删除)
**Q53:Sentinel 的三大功能?**
-
**流量控制**:QPS/并发线程数限流,滑动窗口算法
-
**熔断降级**:RT阈值/异常比例触发熔断,Sentinel 采用半开状态恢复
-
**系统自适应保护**:根据系统 Load、CPU、入口QPS自适应限流
**Q54:分布式 ID 方案对比?**
| 方案 | 优点 | 缺点 |
|---|---|---|
| UUID | 无中心 | 无序、存储大 |
| 数据库自增 | 简单有序 | 单库瓶颈 |
| 雪花算法 | 高效、有序 | 依赖时钟 |
| Redis INCR | 高性能 | 依赖Redis |
**Q55:幂等性如何保证?**
-
**数据库唯一索引**:重复插入会报错
-
**状态机**:订单状态只能正向流转(待支付→已支付)
-
**Token 机制**:Redis 存Token,只用一次
-
**乐观锁/悲观锁**:版本号控制
**Q56:接口超时怎么处理?**
-
**重试**:接口幂等,重试间隔递增(指数退避)
-
**熔断**:Sentinel/Hystrix,超时比例高时熔断
-
**降级**:返回兜底数据或缓存旧数据
-
**超时设置**:读服务 200-500ms,写服务 100-200ms
**Q57:如何保证接口的幂等性?**
-
Token 机制:前端获取Token → 提交时携带 → 后端 Redis 扣减(SETNX)
-
唯一键:数据库唯一索引(如 orderId + actionType)
-
悲观锁/乐观锁:`SELECT ... FOR UPDATE` 或 `version` 字段
-
消息队列:消费端去重
**Q58:Feign 的超时配置?**
```yaml
feign:
client:
config:
default:
connectTimeout: 2000 # 连接超时
readTimeout: 5000 # 读取超时
```
Ribbon 的默认超时是 1 秒,易导致超时,需要合理配置。
**Q59:Sleuth + Zipkin 链路追踪原理?**
-
每个请求生成 `TraceID`(全局唯一)
-
每经过一个服务,在 HTTP Header 中传递 `TraceID` 和 `SpanID`
-
采样率:`-Dspring.sleuth.sampler.probability=0.1`
-
Zipkin 收集器汇总数据,提供可视化 UI
**Q60:Seata AT 模式的原理?**
-
解析业务SQL,记录**前镜像**(修改前数据快照)
-
执行 SQL,记录**后镜像**(修改后数据快照)
-
事务成功 → 前后镜像无操作,提交;失败 → 用前镜像反向更新(undo log)
-
全局锁保证事务隔离
七、Redis(10题)
**Q61:Redis 数据类型及底层实现?**
| 类型 | 底层实现 | 常用场景 |
|---|---|---|
| String | SDS(动态字符串) | 缓存、计数器、分布式锁 |
| List | quicklist(压缩链表) | 消息队列、任务队列 |
| Hash | dict(哈希表)+ ziplist | 对象存储 |
| Set | intset/dict | 标签、好友关系 |
| ZSet | 压缩列表/跳表 | 排行榜、延时队列 |
| Bitmap | 位图 | 签到、布隆过滤器前置 |
| HyperLogLog | PFADD/PFCOUNT | UV统计 |
**Q62:Redis 过期 key 的删除策略?**
-
**惰性删除**:访问时检查过期,过期才删(内存浪费但不占用CPU)
-
**定期删除**:每隔100ms随机抽查,过期则删除(平衡方案)
-
**定时删除**(主动):设置expire时同时创建定时器,TTL到期立即删除(占用CPU)
Redis 实际采用:**惰性删除 + 定期删除**组合。
**Q63:Redis 持久化机制?RDB 和 AOF 的区别?**
| 维度 | RDB | AOF |
|---|---|---|
| 方式 | 定时快照,生成dump.rdb | 记录每个写命令 |
| 文件大小 | 小(二进制) | 大(文本) |
| 恢复速度 | 快 | 慢 |
| 数据完整性 | 可能丢失最近数据 | 取决于刷盘策略(always/everysec/no) |
| 资源消耗 | fork子进程BGSAVE | 主线程追加文件 |
**建议**:同时开启 RDB + AOF,优先用 AOF 恢复。
**Q64:Redis 内存淘汰策略?**
| 策略 | 说明 |
|---|---|
| noeviction | 不淘汰,返回错误(默认) |
| allkeys-lru | 所有Key,LRU |
| allkeys-random | 所有Key,随机 |
| volatile-lru | 有过期Key,LRU |
| volatile-random | 有过期Key,随机 |
| volatile-ttl | 有过期Key,TTL最短优先 |
| allkeys-lfu | 所有Key,LFU(Redis4.0+) |
**Q65:Redis 主从复制原理?**
```
Master → SYNC/PSYNC → RDB + 缓冲区 → 全量同步
Master → 命令传播 → 增量同步(Repl Backlog Buffer)
```
-
旧版:SYNC(全量),开销大
-
新版:PSYNC(部分重同步),通过 `repl_backlog_buffer` 支持增量
**Q66:Redis 集群方案?**
-
**主从复制**:一主多从,读写分离(从节点最终一致)
-
**哨兵(Sentinel)**:自动故障转移,监控/选主/通知(3节点以上)
-
**Codis/Redis Cluster**:数据分片(16384槽),每个分片一主多从
**Q67:Redis Cluster 的数据分片原理?**
-
16384 个槽(slot)
-
每个节点负责一部分槽:`slot = CRC16(key) % 16384`
-
MOVED 重定向:客户端请求到错误节点,节点返回正确节点地址
-
ASK 重定向:集群迁移中使用(临时)
**Q68:Redis 分布式锁?Redisson 原理?**
基础版(不推荐):`SETNX + EXPIRE`(非原子性,可能死锁)
**正确方案**:`SET key value NX PX 30000`(原子性)
Redisson 原理:
-
看门狗(Watchdog):自动续期,每10秒检查
-
可重入锁:`hash {uuid:threadId -> count}`
-
RedissonLock 底层:Lua 脚本保证原子性
**Q69:Redis 和 MySQL 如何保持一致性?**
| 模式 | 说明 | 一致性 |
|---|---|---|
| Cache Aside(旁路缓存) | 读:Cache Miss → DB → 写Cache;写:DB → 删除Cache | 最终一致 |
| Read Through | 读:Cache自动从DB加载 | 最终一致 |
| Write Through | 写:先写Cache再写DB | 强一致 |
| Write Behind | 写:先写Cache,异步批量写DB | 不一致 |
**推荐**:Cache Aside(旁路缓存),先删Cache再更新DB(双删解决并发问题)。
**Q70:Redis 大 Key 问题?**
-
**发现**:`redis-cli --bigkeys`、`SCAN + STRLEN`
-
**影响**:阻塞单线程、内存不均匀、集群倾斜
-
**解决**:拆分为多个小Key(hash slot分散)、压缩(ziplist)、删除时用 UNLINK(异步)
八、框架与工具(10题)
**Q71:Kafka 为什么这么快?**
-
**顺序写入**:追加写磁盘,顺序IO速度接近内存
-
**页缓存(Page Cache)**:利用OS缓存,热点数据在内存
-
**零拷贝**:sendfile + DMA,直接内核空间传输,无需应用层Copy
-
**批量处理**:批量发送、批量压缩(降低网络开销)
-
**分区并行**:Producer/Consumer以Partition为单位并行
**Q72:RabbitMQ 消息顺序性如何保证?**
-
**问题来源**:多消费者并发消费
-
**解决方案**:
-
单分区(牺牲性能)
-
消息加序列号,消费端按序列号重排序
-
同一个业务Key路由到同一队列(使用 routingKey 哈希)
**Q73:ES 查询流程?**
```
Query Phase:协调节点 → 所有分片并行搜索 → 收集TopN → 排序
Fetch Phase:协调节点 → 各分片获取完整文档 → 合并返回客户端
```
-
分片副本:可配置 `replication=sync/async`
-
深度分页:`search_after` 替代 `from+size`
**Q74:Docker 常用命令?**
```bash
docker build -t myapp:1.0 . # 构建镜像
docker run -d -p 8080:8080 myapp # 运行容器
docker ps -a # 查看所有容器
docker exec -it <id> /bin/bash # 进入容器
docker logs -f <id> # 查看日志
docker-compose up -d # 启动编排
```
**Q75:Git 常用命令?**
```bash
git checkout -b feature/login # 创建并切换分支
git stash / git stash pop # 暂存工作区
git rebase -i HEAD~3 # 合并提交
git cherry-pick <commit> # 摘取单个提交
git reset --soft HEAD~1 # 撤销提交(保留改动)
```
**Q76:Linux 常用排查命令?**
```bash
top / htop # CPU/内存
vmstat 1 # 系统监控
netstat -tunlp | grep port # 端口占用
iostat -x 1 # 磁盘IO
ss -s # Socket统计
curl -v http://api/health # HTTP健康检查
```
**Q77:GitFlow 工作流?**
```
main → hotfix(紧急修复)→ main
↑ ↓
release develop → feature → develop
```
-
**main**:生产环境代码,只接受 hotfix 和 release
-
**develop**:开发主分支
-
**feature**:功能分支,从 develop 拉出
-
**release**:发布分支,测试修复后合并到 main + develop
**Q78:Nginx 反向代理和负载均衡配置?**
```nginx
upstream backend {
server 127.0.0.1:8080 weight=3;
server 127.0.0.1:8081 weight=1;
ip_hash; # IP哈希会话保持
}
server {
listen 80;
location / {
proxy_pass http://backend;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
}
}
```
**Q79:如何设计一个高并发系统?**
-
**分层设计**:CDN → Nginx → 网关 → 应用 → 缓存 → 数据库
-
**缓存**:本地缓存(Caffeine)+ 分布式缓存(Redis)
-
**异步化**:消息队列(削峰、解耦)
-
**数据库优化**:读写分离、分库分表、索引优化
-
**限流熔断**:Sentinel / Redis 令牌桶
-
**弹性伸缩**:K8s HPA
**Q80:用过哪些设计模式?举例说明?**
| 模式 | 示例 |
|---|---|
| 单例 | ApplicationContext、Runtime |
| 工厂 | BeanFactory、SqlSessionFactory |
| 代理 | Spring AOP、MyBatis Mapper |
| 策略 | Redis 序列化策略、支付方式 |
| 装饰器 | BufferedInputStream 包装 FileInputStream |
| 观察者 | ApplicationEvent、Spring Lifecycle |
| 模板方法 | JdbcTemplate、RestTemplate |
| 建造者 | StringBuilder、Alert.builder() |
九、智力 & 综合(5题)
**Q81:如何设计一个抢红包功能?**
-
**Redis List** 预存红包金额,LPOP 原子领取
-
**数据库乐观锁**:版本号控制,防止超卖
-
**MQ 异步**:异步写订单,避免雪崩
-
**限流**:单用户 QPS 限制
**Q82:接口压测怎么做?**
-
JMeter /wrk / ab 压测
-
关注指标:QPS、RT(P50/P99)、错误率、CPU/内存
-
逐步加压,找到系统瓶颈
-
`redis-benchmark -q -c 100 -n 10000`
**Q83:如何保证消息不丢失?**
-
**生产者**:confirm 回调确认
-
**MQ**:持久化(durable)+ 集群多副本(Raft)
-
**消费者**:手动 ACK 确认,处理完再 ACK
**Q84:你最近在学什么?**
这个问题必问。回答策略:说一个跟公司业务相关的前沿技术(e.g. WebAssembly、云原生、AI辅助编程),展示学习热情和方向性。
**Q85:你有什么问题想问我的?**
绝对不能不问,也不要问薪酬福利(等HR面)。推荐问:
1. 团队规模和使用的技术栈?
2. 这个岗位最大的挑战是什么?
3. 团队的技术成长路径?
十、面试加分话术(3条)
**当被问到"你还有什么要补充的"时:**
"我想补充一点我对这个岗位的理解。刚才聊到的这些技术栈中,我对 XX 特别感兴趣,也做过一些实践,比如 XX 项目。如果有幸加入,我希望能在这个方向深入。"
**当被问到"你的离职原因"时:**
"前公司业务发展到了稳定期,我个人更希望到一家快速成长的公司,学习大规模高并发系统的实践经验。"
**当被问到"你的优点/缺点"时:**
"优点:我喜欢系统性思考,做需求时会先梳理清楚边界和异常情况再动手,代码质量意识比较强。
缺点:有时候追求完美,可能会在细节上花比较多时间。后来我学会了用番茄工作法来平衡质量和效率。"
本题库覆盖 Java 基础、并发、JVM、MySQL、Spring、Redis、微服务、框架工具8大模块。建议面试前3天,每天过一遍对应模块。完整版100题可在回复「Java100」获取。
>
觉得有用?关注更多硬核技术文章每周更新。