高考志愿与职业规划本身就是一个高度复杂的问题,涉及专业、技能、行业、个人特质与长期发展等多个维度。如果分析逻辑缺乏约束,结果往往会变成信息堆叠而非有效判断。通过工程化方式重构分析流程,可以将复杂决策问题拆解为可执行、可复用的判断单元,从而显著提升输出质量与稳定性。
本文围绕一个实际可运行的智能体工作流案例,完整展示如何利用标准模式与 Multi-Agent 工作流,将升学与职业分析问题转化为单维度、结构化的分析结论。内容涵盖智能体创建、联网能力接入、变量贯穿设计、节点分流逻辑以及结果收口方式,适合希望通过真实项目理解智能体工程化落地的自学开发者。
文章目录
智能体介绍
这个工作流的目的很明确:让每次回答只做一个"可判断维度",通过"先分流、后检索、再分析、最后收口"的方式,把复杂问题拆开处理,避免一次回答里混杂专业、技能、行业、性格、前景等多条主线导致结论发散。落地时我先用标准模式把智能体建起来,并开启联网搜索能力来覆盖专业与行业等强时效信息,然后切换到 Multi-Agent 让工作流接管回答过程;工作流入口通过 API 参数贯穿数据,分流命中后进入对应的知识库检索节点,再由专项 LLM 节点在严格提示词约束下输出单维度结论,最后通过回复节点统一回传。
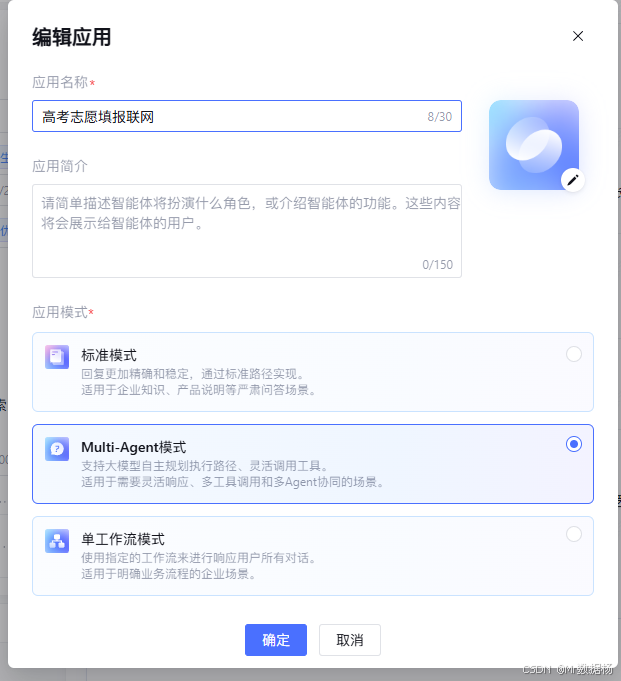
智能体的创建入口与模式选择。我这里先从"标准模式"起步,把智能体的基础能力先搭好,确保后续无论是接入搜索还是挂工作流,都有一个稳定的承载体,避免一开始就把流程复杂化导致配置困难或排查成本上升。
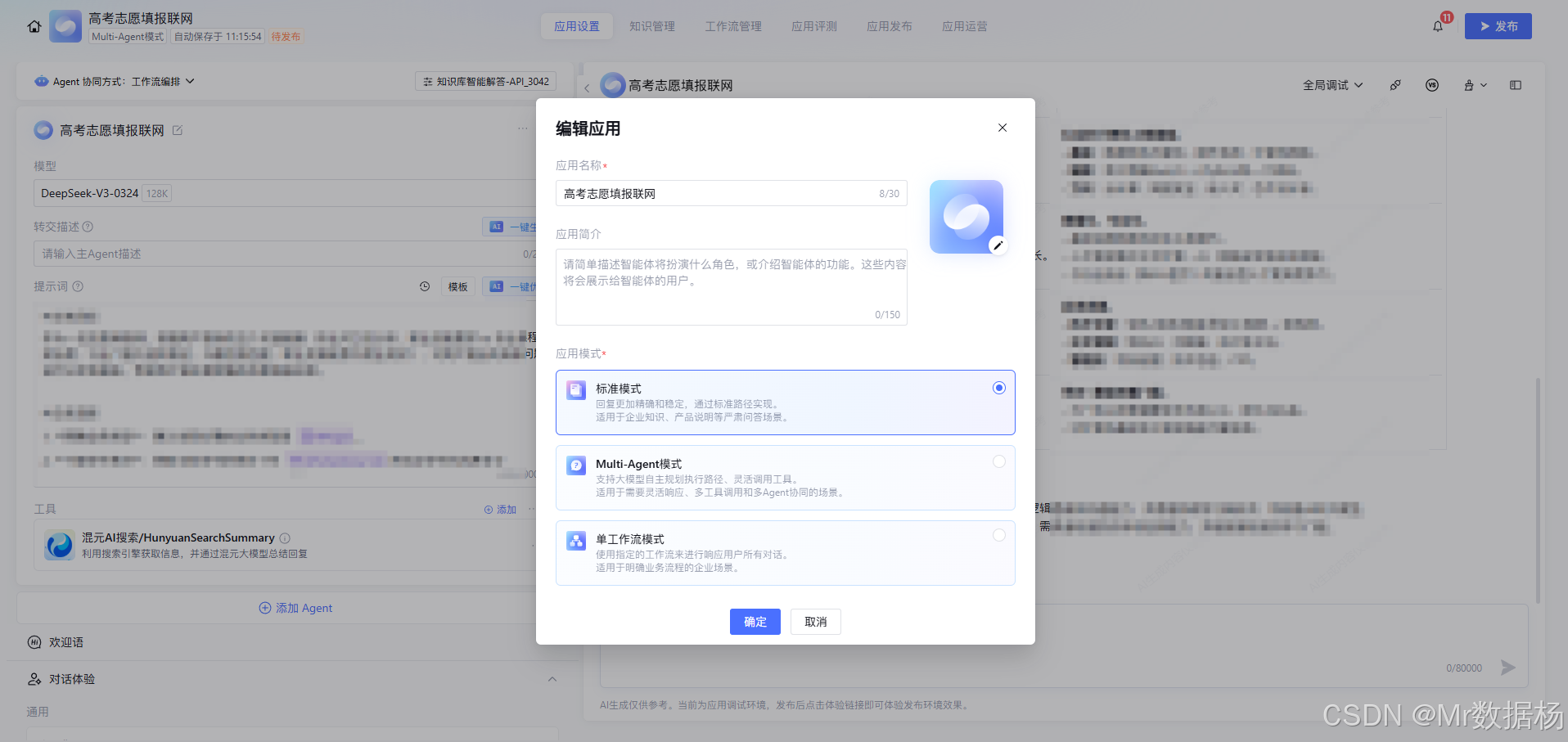
联网检索能力的接入位置。因为志愿与职业分析强依赖实时信息,例如专业介绍、行业门槛、岗位技能变化与就业现状等,所以我直接加了 混元AI搜索 来保证信息来源可更新、节点可调用;选它主要是为了省配置成本,系统计费也更省事,效果上能满足工作流检索环节的需求。
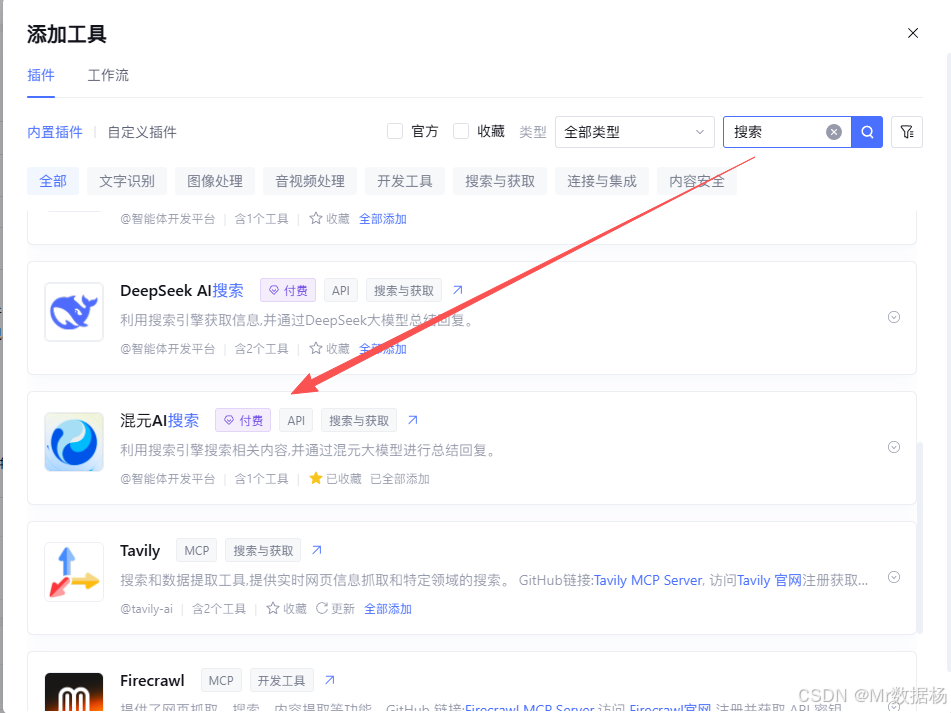
Multi-Agent 到这一步就不再依赖模型"自由发挥",而是让工作流接管回答过程,通过条件分流把问题锁定到单一分析维度,再按分支执行"检索→分析→输出"的闭环;这样每次输出都更像一段可交付的结论,而不是把多个维度揉在一起的泛化建议。
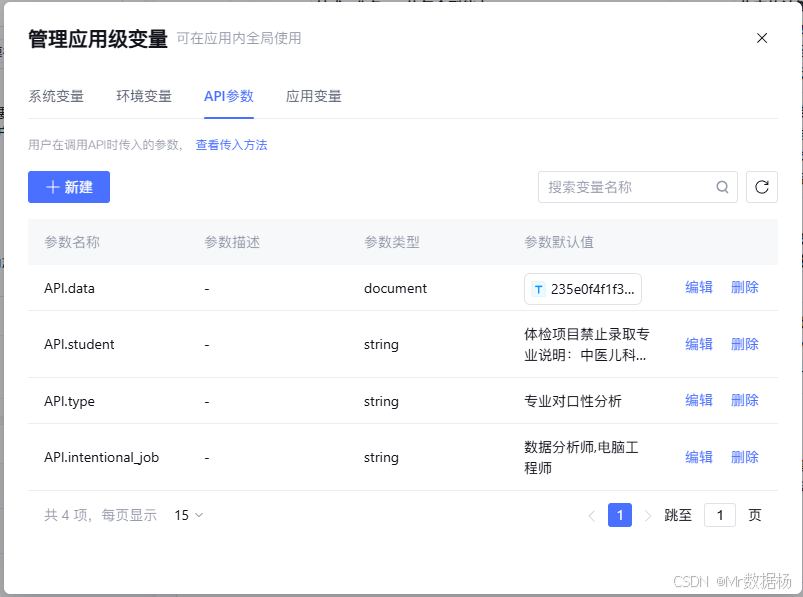
工作流在代码层的入口参数目前为 type、data、student,其中 type 用于分流,data 承载志愿相关信息,student 承载学生画像信息;如果你像我一样还希望把 intentional_job 这类字段贯穿整个链路,做法就是在工作流入口参数里补上对应变量并在分支提示词中引用,保证后续节点能稳定取数。
核心模型
这个工作流的"分流判断"和"五类专项分析"使用同一套模型配置,保证分流口径与分析口径一致;分流节点根据 API.type 将请求路由到固定分支,LLM 节点则在系统提示词里强约束分析边界,只产出该维度的结论文本,从而让输出结构稳定、可控。整体风格上更偏"结论式分析",而不是聊天式发散。
| 模型名称 | 说明 |
|---|---|
| Deepseek/deepseek-v3.2 | 用于条件分流(LOGIC_EVALUATOR)与五个专项分析(LLM)节点,输出单维度判断结论并保持分流与分析一致性 |
Node节点
节点设计围绕"入口接入、分流控制、知识检索、专项分析、统一输出"展开。入口节点负责接收 API 参数并进入 Agent;条件判断节点依据 API.type 命中五个固定分析维度之一,未命中则走兜底回复;每个维度都有独立的知识库检索节点与独立的 LLM 分析节点,保证语义纯净;输出统一通过回复节点回传并在结束节点收口。知识检索的查询模板统一为"请帮我检索 {{type}}相关内容",并采用文档与 QA 混合检索策略,文档召回与置信度阈值、QA 召回与置信度阈值也在节点内固定,保证同一维度下检索口径稳定。
| 节点名称 | 说明 |
|---|---|
| 开始 | 工作流入口,接收 type(STRING)、data(DOCUMENT)、student(STRING) 并启动链路 |
| Agent1 | 负责前置语境处理与问题承接,将请求交给分流节点 |
| 条件判断1 | 按 API.type 分流到五个维度分支,未命中则进入兜底回复 |
| 知识 专业对口性分析 | 知识库检索节点,查询模板为"请帮我检索 {{type}}相关内容",混合检索策略,文档召回 3/阈值 0.2,QA 召回 2/阈值 0.9 |
| Alignment|专业对口性分析 | 仅评估培养目标与知识结构对岗位要求的支持程度,不引入兴趣与行业前景,输出契合点与结构性差距 |
| 回复2 | 输出 {``{output}} 并进入结束节点 |
| 知识 职业技能要求 vs 专业课程契合度 | 知识库检索节点,同模板同策略,为课程-技能分析提供依据 |
| Fit|技能要求与课程契合度 | 仅评估课程体系对岗位技能形成的支撑度与实践培养覆盖,不讨论行业趋势与性格因素 |
| 回复3 | 输出 {``{output}} 并进入结束节点 |
| 知识 行业门槛与进阶路径 | 知识库检索节点,同模板同策略,为门槛与路径分析提供依据 |
| Barrier|行业门槛与进阶路径 | 聚焦准入条件、能力要求、竞争结构与发展阶段,仅评估客观难度,避免确定性成败断言 |
| 回复4 | 输出 {``{output}} 并进入结束节点 |
| 知识 兴趣性格匹配 | 知识库检索节点,同模板同策略,为兴趣性格分析提供依据 |
| Profile|兴趣与性格匹配 | 围绕工作方式、压力特征、协作模式做适配分析,结论以"匹配假设"呈现,不涉及薪资与社会评价 |
| 回复5 | 输出 {``{output}} 并进入结束节点 |
| 知识 职业发展前景与就业现状 | 知识库检索节点,同模板同策略,为就业与趋势分析提供依据 |
| Outlook|职业发展前景与就业现状 | 基于供需趋势与长期稳定性讨论客观环境影响,强调不确定性与趋势判断,不引入个人能力评估 |
| 回复6 | 输出 {``{output}} 并进入结束节点 |
| 回复1 | 兜底回复,默认文案为"当前模块不支志愿填报问答。" |
| 结束 | 统一收口输出并结束流程 |
工作流程
这套流程在使用上是"搭建动作"和"运行链路"两条线同时闭环:搭建动作上,我先在标准模式创建智能体并接入联网搜索(用于覆盖强时效信息),再切换 Multi-Agent 用工作流控制回答过程,然后把入口变量配置好并发布启用;运行链路上,开始节点接入 type/data/student 后进入 Agent 处理语境,条件判断节点严格依赖 API.type 命中五个维度之一,命中后先通过知识库检索补齐该维度的客观信息,再由对应 LLM 节点在单维度约束下生成结论,最后通过回复节点回传并在结束节点收口。
| 流程序号 | 流程阶段 | 工作描述 | 使用节点 |
|---|---|---|---|
| 1 | 创建与能力准备 | 用标准模式创建智能体并启用联网检索能力,保证可获取实时信息来源 | 标准模式配置 → 混元AI搜索 |
| 2 | 工作流接管 | 切换 Multi-Agent,让工作流控制回答过程,避免多维混杂导致结论发散 | Multi-Agent |
| 3 | 参数贯穿 | 通过入口参数贯穿数据,当前工作流入口为 type/data/student,并以 type 作为分流依据 |
开始 |
| 4 | 语境处理 | 承接用户问题并将请求导入分流逻辑,保证后续节点在同一决策语境中工作 | Agent1 |
| 5 | 意图分流 | 按 API.type 命中五个维度之一:专业对口性分析、职业技能要求与专业课程契合度、行业门槛与进阶路径、兴趣性格匹配、职业发展前景与就业现状;未命中则走兜底 |
条件判断1 |
| 6 | 知识检索 | 命中分支后按统一模板检索知识库,混合检索策略,文档召回 3/阈值 0.2,QA 召回 2/阈值 0.9,为分析提供依据 | 知识(对应分支) |
| 7 | 单维分析 | 在系统提示词约束下只输出该维度结论,不引入其他维度,保证结论清晰且可复用 | Alignment / Fit / Barrier / Profile / Outlook |
| 8 | 输出收口 | 将 {``{output}} 直接回传并在结束节点统一收口,保证接口输出稳定 |
回复2--6 → 结束 |
| 9 | 兜底返回 | 当 type 不在支持范围内时直接返回固定文案并结束,避免不受控泛化输出 |
回复1 → 结束 |
你在调试页看到的效果,关键验收点不是"说得多不多",而是"每次是否只聚焦一个维度、分支是否走对、输出结构是否稳定"。
专业对口性分析
职业技能要求与专业课程契合度
行业门槛与进阶路径
兴趣性格匹配
职业发展前景与就业现状
未命中支持范围
创建智能体并启用联网检索
切换 Multi-Agent
由工作流接管回答过程
开始节点
接收 type / data / student
Agent1
承接问题并导入分流语境
条件判断1
按 API.type 分流
知识检索
专业对口性分析
Alignment
专业对口性分析
回复2
结束
知识检索
课程与技能契合度
Fit
技能要求与课程契合度
回复3
知识检索
行业门槛与进阶路径
Barrier
行业门槛与进阶路径
回复4
知识检索
兴趣性格匹配
Profile
兴趣与性格匹配
回复5
知识检索
职业发展前景与就业现状
Outlook
职业发展前景与就业现状
回复6
回复1
兜底返回固定文案
工作流的整体编排视图,也就是"运行链路"的全貌。你可以在这里直观看到从开始节点到分支分流、再到知识检索与专项分析、最后到回复与结束的串联关系,这张图主要用于核对链路是否闭合、分支是否完整、节点连接是否正确。
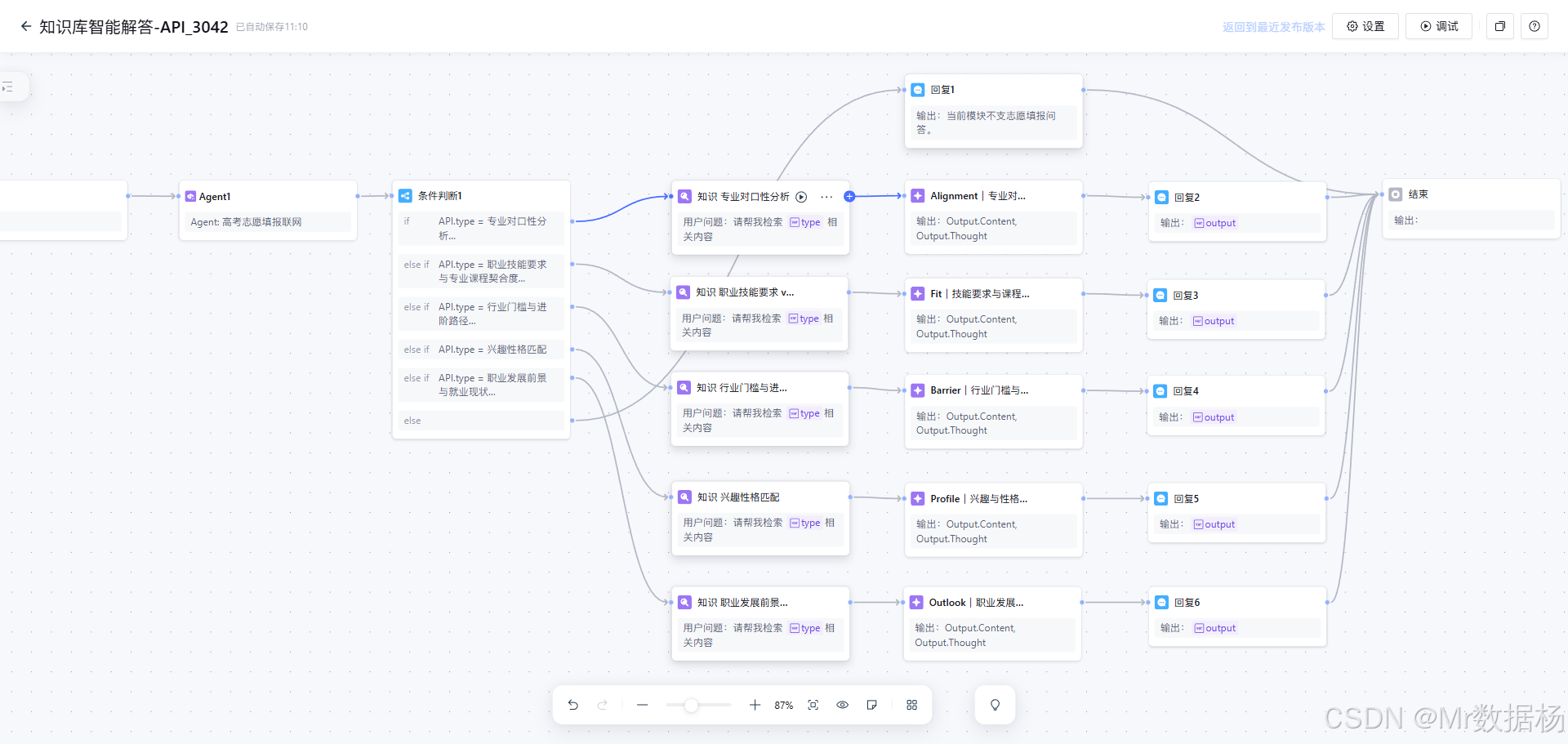
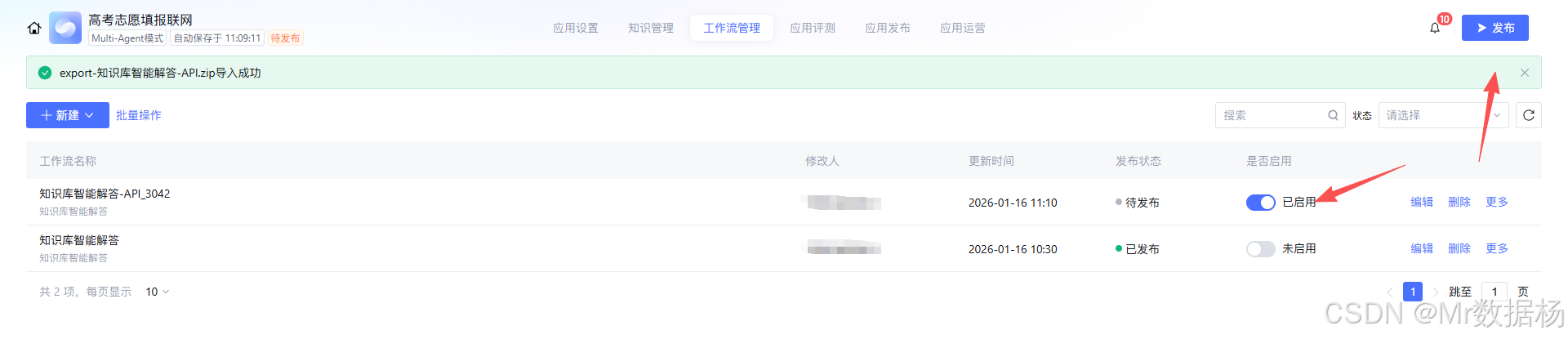
工作流启用与发布的位置,属于"搭建动作"的最后一步。这里的重点不是点一下发布那么简单,而是确认你已经把入口参数、分支条件与节点配置都固定下来,发布后外部调用才能拿到稳定一致的执行结果,避免上线后出现"跑不到分支"或"取不到变量"的问题。
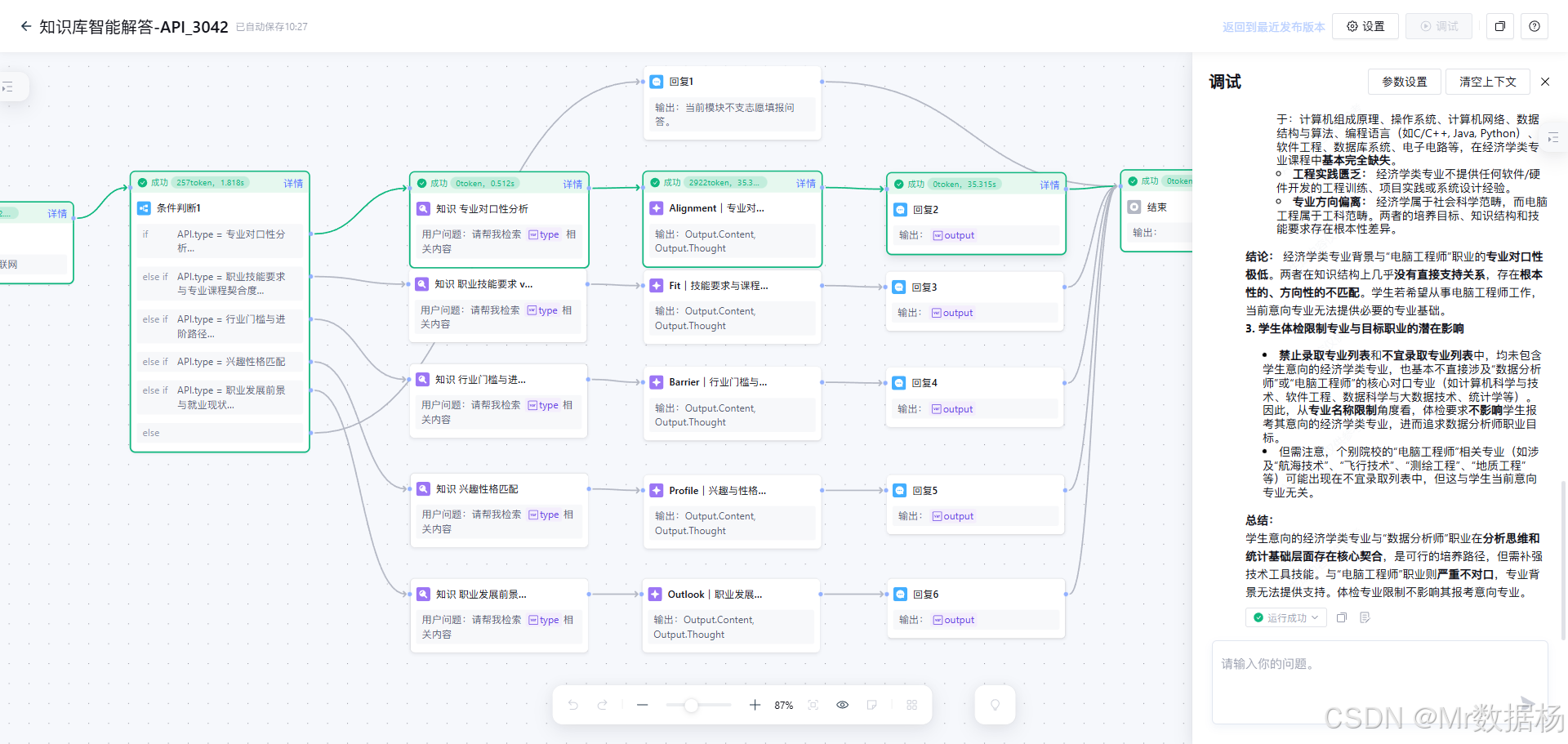
样例调试的输出效果,主要用于验收"分支是否走对、输出是否单维、结论是否可复用"。我在这里更关注输出结构是否稳定,例如同一个 type 多次调用是否保持同样的结论组织方式,以及是否严格遵守该维度边界而不混入其他维度内容。
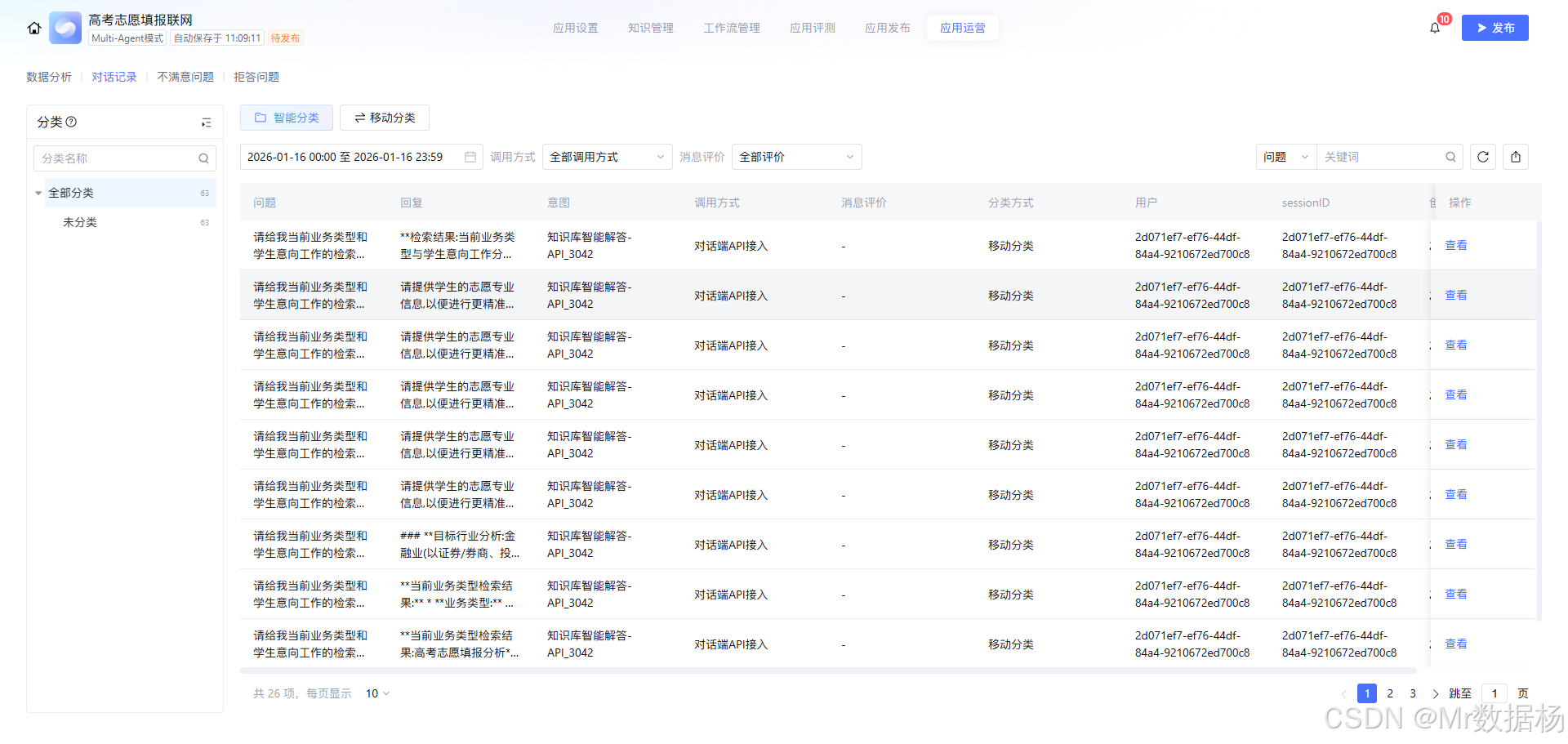
应用使用记录入口,用于上线后的复盘与迭代。它能帮我快速定位"用户到底触发了哪条链路、命中了哪个分支、输出是否异常",也方便统计最常被调用的维度,从而决定后续应该优先补充哪类知识库内容或优化哪条提示词。
应用场景
这个工作流最适合的场景是需要"结论稳定、结构统一、可卡片化展示"的升学与职业决策产品形态。由于它把复杂问题拆成单维度输出,你可以把同一学生的输入分别跑五次不同 type,得到五段可直接拼装成报告的内容,也可以在对话产品里把不同维度做成独立入口,让用户明确选择自己要看的分析方向;结合使用记录回溯,你还能持续优化分流文案、补充入口变量字段,逐步提升个性化判断的精度与一致性。
| 应用场景 | 使用目标 | 典型用户 | 展示内容 | 实现效果 |
|---|---|---|---|---|
| 专业对口性分析 | 判断专业培养目标与岗位要求是否同向 | 高三学生、家长、升学顾问 | 契合点、结构性差距、方向支持度结论 | 输出聚焦"专业匹配",不混入前景与性格讨论 |
| 课程-技能契合度 | 判断课程体系是否支撑岗位技能形成 | 学生、教务/课程顾问 | 技能覆盖、实践培养、缺口提示 | 让"学什么能干什么"更可解释、可落地 |
| 行业门槛与进阶路径 | 解释准入条件与发展阶段并评估客观难度 | 学生、家长、职业规划师 | 门槛要素、竞争结构、典型路径、难度评估 | 输出偏"现实约束",避免鸡汤式建议 |
| 兴趣性格匹配 | 用个体特质解释工作方式适配性 | 学生、测评用户 | 工作方式、压力特征、协作模式、匹配假设 | 结论以假设呈现,降低绝对化误导风险 |
| 就业现状与发展前景 | 从供需趋势判断外部环境影响 | 学生、家长、内容运营 | 供需趋势、不确定性点、环境影响说明 | 输出偏"趋势判断",利于做对比与复用 |
总结
该工作流通过明确的分流机制,将原本混杂的多维问题拆解为专业对口性、课程与技能契合度、行业门槛路径、兴趣性格匹配以及就业前景等独立分析链路。每条链路在统一的变量体系与节点规范下运行,确保输出内容具备清晰边界、稳定结构与可交付属性,从工程角度解决了智能体分析结果不可控的问题。
在现有结构基础上,工作流具备良好的扩展空间,可通过新增变量字段、细化分流条件或引入更精细的知识库内容持续增强分析深度。随着应用数据的积累,进一步结合调用记录与分支命中情况进行优化,有助于构建更具个性化与长期演进能力的智能决策系统。