快速了解部分
基础信息(英文):
- 题目: RISE: Self-Improving Robot Policy with Compositional World Model
- 时间:2026.02
- 机构: The Chinese University of Hong Kong, Kinetix AI, Tsinghua University, Horizon Robotics 等
- 3个英文关键词: Compositional World Model, Reinforcement Learning, Self-improving Robot
1句话通俗总结本文干了什么事情
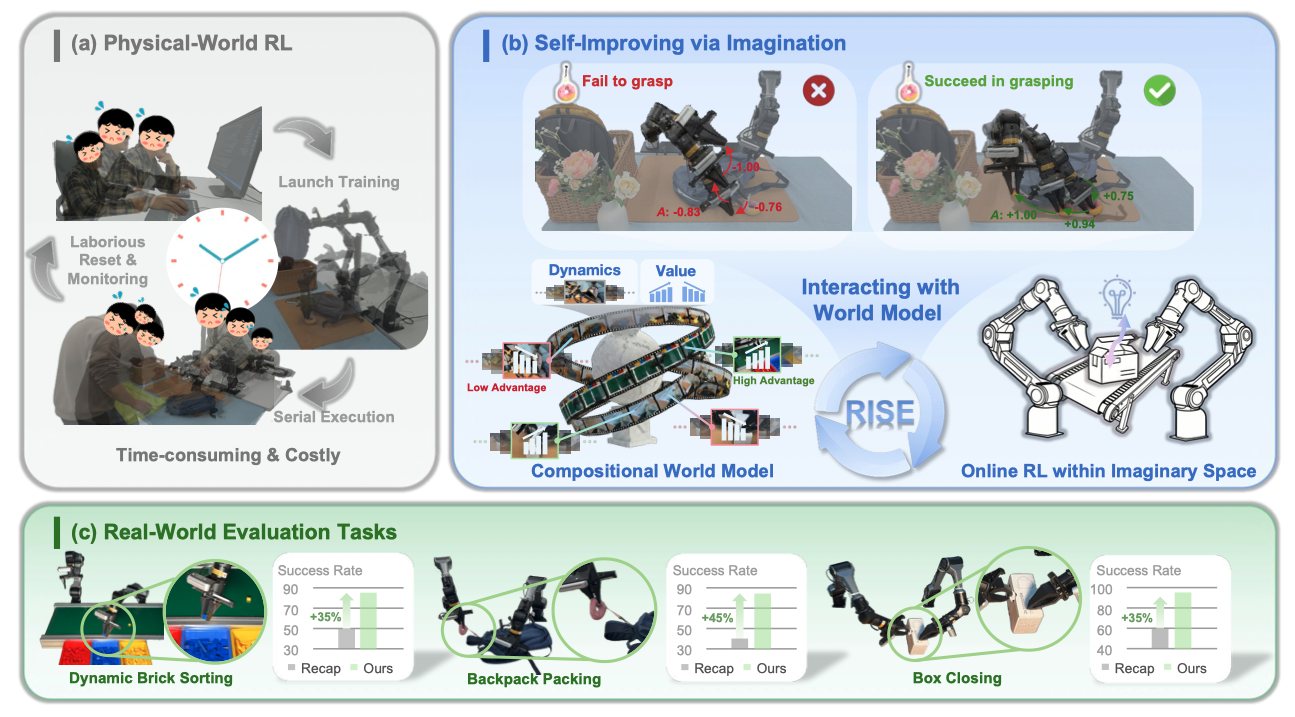
让机器人在"想象空间"里通过世界模型做梦练习,用预测未来+评估好坏的组合方式自我提升策略,避免真实世界中昂贵的试错成本。
研究痛点:现有研究不足 / 要解决的具体问题
- VLA模型在contact-rich、动态操作任务中脆弱,小偏差会累积成失败
- 物理世界做on-policy RL成本高:硬件贵、交互串行、手动reset费时
- 现有世界模型要么视觉真实但动作不可控,要么奖励信号稀疏,无法支撑长时序策略优化
核心方法:关键技术、模型或研究设计(简要)
- Compositional World Model:解耦dynamics prediction(预测未来观测)和value estimation(评估想象状态),各自用最适合的架构优化
- Dynamics Model:基于Genie Envisioner视频Diffusion,Task-Centric Batching策略提升动作可控性
- Value Model:从预训练VLA初始化,progress regression + TD learning联合训练,输出密集且对失败敏感的advantage信号
- Self-Improving Loop:在想象空间迭代rollout生成→advantage计算→策略更新,零真实交互成本
深入了解部分
作者想要表达什么
世界模型可以成为真实世界操作任务的有效"学习环境",通过想象空间中的on-policy RL,能高效bootstrapping策略在high-dynamics、dexterous任务上的表现,实现scalable的self-improving。
相比前人创新在哪里
- 首次将learned world model作为真实世界manipulation的interactive training environment,而非仅用于planning或数据增强
- Compositional设计:dynamics和value解耦,避免单一架构兼顾多目标的妥协,dynamics专注可控生成,value专注密集评估
- 直接为action chunk输出advantage,无需模拟到终端状态获取稀疏reward,降低对长时序生成准确性的依赖
- Task-Centric Batching策略:预训练时优先同场景下的动作多样性,显著提升fine-tuning效率和动作可控性
解决方法/算法的通俗解释
机器人先学会"做梦":给定当前画面和动作,预测接下来会看到什么(dynamics);再学会"打分":看这个预测画面离成功还有多远(value);然后用"预测画面+打分"算出这个动作好不好(advantage);最后用这些想象出来的经验更新策略。全程在脑子里练,不用真动手。
解决方法的具体做法
- Dynamics Model训练:Genie Envisioner初始化→Agibot World+Galaxea大规模预训练(Task-Centric Batching)→任务数据fine-tune,Flow Matching损失,50步Euler采样
- Value Model训练:π0.5 VLA backbone初始化→前10k步progress regression学习时序单调性→后40k步加入TD learning区分成功/失败,输出标量value
- Advantage计算:对action chunk预测的H帧未来,取value均值减当前value,离散化为10个bin作为策略训练条件
- Policy Warm-up:offline数据(expert+rollout+correction)上训练advantage-conditioned策略,expert数据强制标最高advantage
- Self-Improving Loop:采样offline状态→策略+最优advantage提示生成动作→dynamics生成未来→value评估得实际advantage→混合offline数据训练策略→EMA更新rollout策略,迭代10k步
基于前人的哪些方法
- Genie Envisioner视频Diffusion架构
- π0.5预训练VLA backbone
- Progress estimate(VLM as in-context value learner)
- TD learning经典RL方法
- Advantage-conditioned policy optimization(RECAP)
- Flow matching策略训练(π系列)
实验设置、数据、评估方式、结论
- 硬件:dual 7-DoF AgileX robot,30Hz控制,3视角观测(top+双wrist)
- 任务:Dynamic Brick Sorting(移动传送带分拣)、Backpack Packing(柔性物体操作)、Box Closing(双手精密协调)
- 数据:每任务2-3k expert演示 + 500-600 policy rollout,Box Closing额外540 DAgger修正
- 评估:20次自主执行,Success Rate + 分阶段Score(满分10)
- 结论:RISE成功率85%/85%/95%,相比RECAP等baseline绝对提升+35%/+45%/+35%;ablation验证Task-Centric Batching、progress+TD联合训练、online state+action整合的必要性
提到的同类工作
- World Model方向:Dreamer系列、Genie、Cosmos、Ctrl-world、AdaWorld
- VLA+RL方向:RECAP(π*0.6)、DSRL、VLA-RL、SimpleVLA-RL、GR-RL
- 数据/仿真方向:LIBERO、RoboCasa、BridgeData、Agibot World、Galaxea
和本文相关性最高的3个文献
- RECAP (π*0.6): advantage-conditioned offline RL for VLA post-training,本文warm-up阶段直接借鉴
- Genie Envisioner: 视频Diffusion world model,本文dynamics model的初始化基础
- π0.5: 开源VLA backbone,本文policy和value model的共同初始化来源
我的
- 将world model作为simulator,支持on policy强化学习训练。
- 所谓Compositional world model 就是分2个,一个是视频生成模型作为simulator,一个是Value model用来打分。
- 所谓Task-Centric Batching 就是训视频生成的时候拿同一个场景下的训,别加其他场景的,过拟合在这个任务之下,然后对这个任务做RL。