Day 17 编程实战:MLP神经网络金融预测
实战目标
- 理解MLP的网络结构和前向传播
- 掌握不同激活函数的效果
- 学习优化器的选择
- 尝试不同隐藏层结构对预测的影响
1. 导入必要的库
python
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import time
import warnings
warnings.filterwarnings('ignore')
from pathlib import Path
from sklearn.neural_network import MLPClassifier, MLPRegressor
from sklearn.preprocessing import StandardScaler, MinMaxScaler
from sklearn.model_selection import train_test_split, TimeSeriesSplit, cross_val_score
from sklearn.metrics import (
accuracy_score, precision_score, recall_score, f1_score,
roc_auc_score, roc_curve, classification_report, confusion_matrix
)
from sklearn.ensemble import RandomForestClassifier
sns.set_style("whitegrid") # 预设样式
#启用LaTeX渲染(设为False避免LaTeX依赖)
plt.rcParams['text.usetex'] = False
# 设置中文显示
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['mathtext.fontset'] = 'dejavusans' # 或 'stix'2. 生成金融数据
python
def generate_financial_data(ts_code):
"""生成金融数据"""
data_path = Path(r"E:\AppData\quant_trade\klines\kline2014-2024")
kline_file = data_path / f"{ts_code}.csv"
df = pd.read_csv(kline_file, usecols=["trade_date", "open", "high", "low", "close", "vol"],
parse_dates=["trade_date"])\
.rename(columns={"vol": "volume"})\
.sort_values(by=["trade_date"])\
.reset_index(drop=True)
df['return'] = df['close'].pct_change()
# RSI
delta = df['return'].fillna(0)
gain = delta.where(delta > 0, 0).rolling(14).mean()
loss = -delta.where(delta < 0, 0).rolling(14).mean()
rs = gain / (loss + 1e-10)
df['rsi'] = 100 - (100 / (1 + rs))
# MACD
ema12 = df['close'].ewm(span=12, adjust=False).mean()
ema26 = df['close'].ewm(span=26, adjust=False).mean()
df['macd'] = ema12 - ema26
df['macd_signal'] = df['macd'].ewm(span=9, adjust=False).mean()
# 均线比率
df['ma5'] = df['close'].rolling(5).mean()
df['ma20'] = df['close'].rolling(20).mean()
df['ma_ratio'] = df['ma5'] / df['ma20'] - 1
# 波动率
df['volatility'] = df['return'].rolling(20).std()
# 成交量比率
df['volume_ratio'] = df['volume'] / df['volume'].rolling(10).mean()
# 动量指标
for lag in [1, 2, 3, 5, 10]:
df[f'momentum_{lag}'] = df['return'].shift(lag).fillna(0)
# 目标变量
df['target'] = (df['close'].shift(-3) > (df['close'] * 1.005)).astype(int)
df = df.dropna()
return df
# 生成数据
ts_code = '600519.SH'
df = generate_financial_data(ts_code)
print(f"数据形状: {df.shape}")
# 特征选择
feature_cols = ['rsi', 'macd', 'macd_signal', 'ma_ratio', 'volatility',
'volume_ratio', 'momentum_1', 'momentum_2', 'momentum_3',
'momentum_5', 'momentum_10']
X = df[feature_cols].values
y = df['target'].values
print(f"特征数量: {len(feature_cols)}")
print(f"样本数量: {len(X)}")
print(f"目标分布: {y.mean():.2%}")
# 时间划分
split_idx = int(len(X) * 0.7)
X_train_raw = X[:split_idx]
X_test_raw = X[split_idx:]
y_train = y[:split_idx]
y_test = y[split_idx:]
print(f"\n训练集: {len(X_train_raw)} 样本")
print(f"测试集: {len(X_test_raw)} 样本")
# 标准化(神经网络必须)
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train_raw)
X_test = scaler.transform(X_test_raw)数据形状: (2452, 21)
特征数量: 11
样本数量: 2452
目标分布: 46.25%
训练集: 1716 样本
测试集: 736 样本3. 激活函数对比实验
3.1 激活函数可视化
python
def plot_activation_functions():
"""可视化常用激活函数"""
x = np.linspace(-5, 5, 100)
# Sigmoid
sigmoid = 1 / (1 + np.exp(-x))
# Tanh
tanh = np.tanh(x)
# ReLU
relu = np.maximum(0, x)
# Leaky ReLU
leaky_relu = np.maximum(0.01*x, x)
fig, axes = plt.subplots(2, 2, figsize=(12, 8))
axes[0, 0].plot(x, sigmoid, 'b-', linewidth=2)
axes[0, 0].set_title('Sigmoid')
axes[0, 0].set_xlabel('x')
axes[0, 0].set_ylabel('σ(x)')
axes[0, 0].grid(True, alpha=0.3)
axes[0, 1].plot(x, tanh, 'r-', linewidth=2)
axes[0, 1].set_title('Tanh')
axes[0, 1].set_xlabel('x')
axes[0, 1].set_ylabel('tanh(x)')
axes[0, 1].grid(True, alpha=0.3)
axes[1, 0].plot(x, relu, 'g-', linewidth=2)
axes[1, 0].set_title('ReLU')
axes[1, 0].set_xlabel('x')
axes[1, 0].set_ylabel('ReLU(x)')
axes[1, 0].grid(True, alpha=0.3)
axes[1, 1].plot(x, leaky_relu, 'm-', linewidth=2, label='Leaky ReLU')
axes[1, 1].set_title('Leaky ReLU')
axes[1, 1].set_xlabel('x')
axes[1, 1].set_ylabel('LeakyReLU(x)')
axes[1, 1].grid(True, alpha=0.3)
plt.suptitle('常用激活函数', fontsize=14)
plt.tight_layout()
plt.show()
plot_activation_functions()
3.2 不同激活函数对MLP性能的影响
python
def compare_activations(X_train, X_test, y_train, y_test):
"""对比不同激活函数的MLP性能"""
activations = ['relu', 'tanh', 'logistic']
results = []
for activation in activations:
# 多层感知器(MLP)
mlp = MLPClassifier(
hidden_layer_sizes=(100, 50), # 两个隐藏层,神经元数分别为 100 和 50
activation=activation, # 激活函数
solver='lbfgs', # 优化器:'adam' 适合大数据集且鲁棒性好;'lbfgs' 适合小数据集;'sgd' 需精细调参。
max_iter=500, # 最大迭代次数(训练轮次)
random_state=42,
early_stopping=True,
validation_fraction=0.1
)
start_time = time.time()
mlp.fit(X_train, y_train)
train_time = time.time() - start_time
y_pred = mlp.predict(X_test)
y_proba = mlp.predict_proba(X_test)[:, 1]
results.append({
'激活函数': activation,
'准确率': accuracy_score(y_test, y_pred),
'AUC': roc_auc_score(y_test, y_proba),
'训练时间(秒)': train_time,
'迭代次数': mlp.n_iter_
})
results_df = pd.DataFrame(results)
print("\n不同激活函数性能对比:")
print(results_df.to_string(index=False))
# 可视化
fig, axes = plt.subplots(1, 2, figsize=(12, 5))
axes[0].bar(results_df['激活函数'], results_df['准确率'], color=['blue', 'red', 'green'])
axes[0].set_ylabel('准确率')
axes[0].set_title('激活函数 vs 准确率')
axes[0].grid(True, alpha=0.3)
axes[1].bar(results_df['激活函数'], results_df['AUC'], color=['blue', 'red', 'green'])
axes[1].set_ylabel('AUC')
axes[1].set_title('激活函数 vs AUC')
axes[1].grid(True, alpha=0.5)
plt.suptitle('不同激活函数对MLP性能的影响', fontsize=14)
plt.tight_layout()
plt.show()
return results_df
activation_results = compare_activations(X_train, X_test, y_train, y_test)不同激活函数性能对比:
激活函数 准确率 AUC 训练时间(秒) 迭代次数
relu 0.506793 0.499969 1.212476 191
tanh 0.493207 0.520644 1.020511 97
logistic 0.516304 0.527999 2.171785 264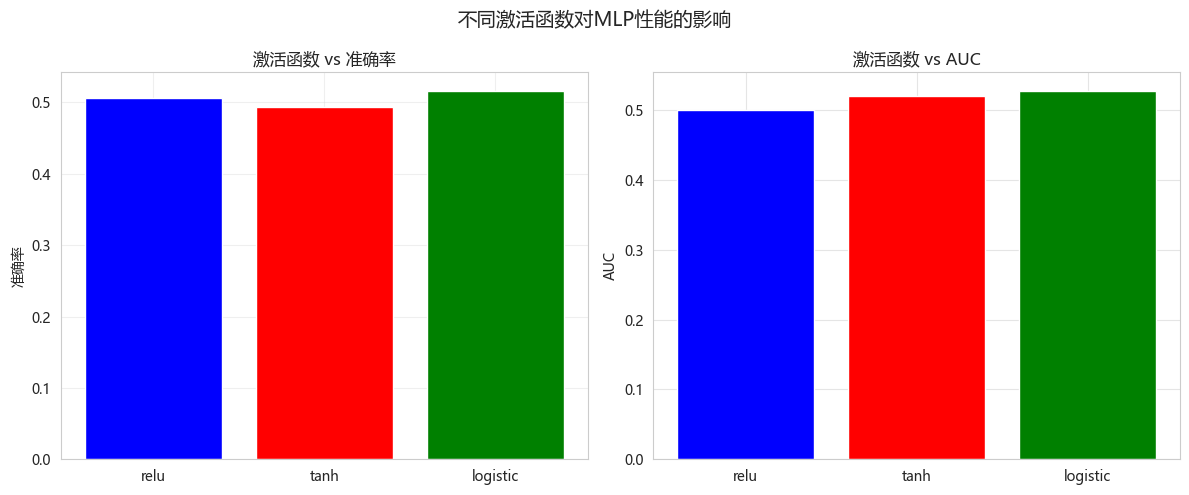
4. 优化器对比实验
4.1 不同优化器的收敛过程
python
def compare_optimizers(X_train, X_test, y_train, y_test):
"""对比不同优化器的性能"""
solvers = ['adam', 'sgd', 'lbfgs']
results = []
for solver in solvers:
mlp = MLPClassifier(
hidden_layer_sizes=(100, 50),
activation='relu',
solver=solver,
max_iter=500,
random_state=42,
learning_rate_init=0.001 if solver == 'sgd' else 0.001,
early_stopping=True,
validation_fraction=0.1
)
start_time = time.time()
mlp.fit(X_train, y_train)
train_time = time.time() - start_time
y_pred = mlp.predict(X_test)
y_proba = mlp.predict_proba(X_test)[:, 1]
results.append({
'优化器': solver,
'准确率': accuracy_score(y_test, y_pred),
'AUC': roc_auc_score(y_test, y_proba),
'训练时间(秒)': train_time,
'迭代次数': mlp.n_iter_
})
results_df = pd.DataFrame(results)
print("\n不同优化器性能对比:")
print(results_df.to_string(index=False))
# 可视化
fig, axes = plt.subplots(1, 2, figsize=(12, 5))
axes[0].bar(results_df['优化器'], results_df['准确率'], color=['blue', 'red', 'green'])
axes[0].set_ylabel('准确率')
axes[0].set_title('优化器 vs 准确率')
axes[0].grid(True, alpha=0.3)
axes[1].bar(results_df['优化器'], results_df['AUC'], color=['blue', 'red', 'green'])
axes[1].set_ylabel('AUC')
axes[1].set_title('优化器 vs AUC')
axes[1].grid(True, alpha=0.3)
plt.suptitle('不同优化器对MLP性能的影响', fontsize=14)
plt.tight_layout()
plt.show()
return results_df
optimizer_results = compare_optimizers(X_train, X_test, y_train, y_test)不同优化器性能对比:
优化器 准确率 AUC 训练时间(秒) 迭代次数
adam 0.456522 0.477284 0.176238 14
sgd 0.449728 0.543011 0.143363 14
lbfgs 0.506793 0.499969 1.147118 191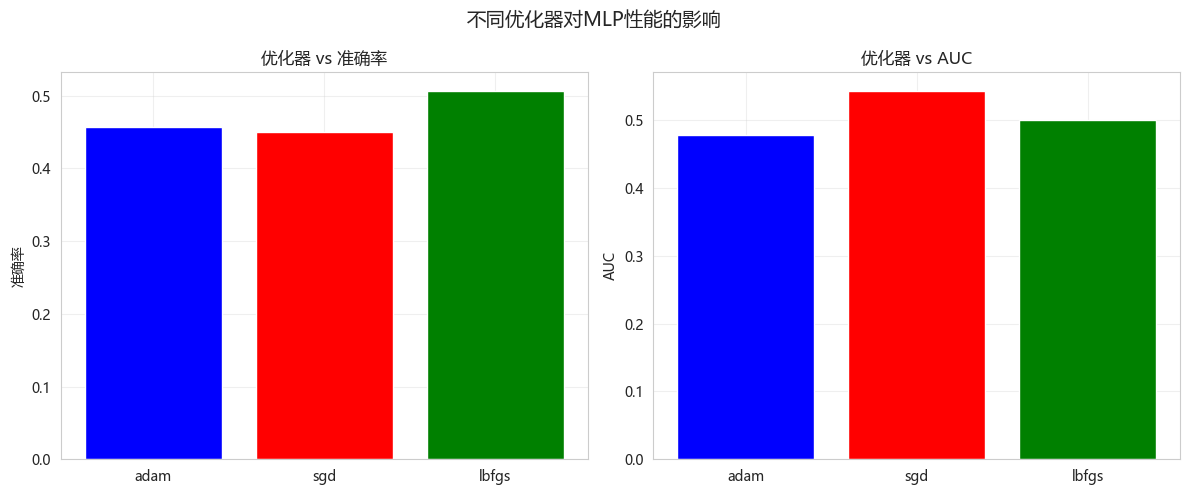
4.2 学习率对SGD的影响
python
def compare_learning_rates(X_train, X_test, y_train, y_test):
"""对比不同学习率对SGD优化器的影响"""
learning_rates = [0.1, 0.01, 0.001, 0.0001]
results = []
for lr in learning_rates:
mlp = MLPClassifier(
hidden_layer_sizes=(100, 50),
activation='relu',
solver='sgd',
learning_rate_init=lr,
max_iter=500,
random_state=42,
early_stopping=True,
validation_fraction=0.1
)
mlp.fit(X_train, y_train)
y_proba = mlp.predict_proba(X_test)[:, 1]
results.append({
'学习率': lr,
'AUC': roc_auc_score(y_test, y_proba),
'迭代次数': mlp.n_iter_
})
results_df = pd.DataFrame(results)
print("\n不同学习率对SGD的影响:")
print(results_df.to_string(index=False))
plt.figure(figsize=(10, 6))
plt.plot(results_df['学习率'], results_df['AUC'], 'bo-', linewidth=2)
plt.xscale('log')
plt.xlabel('学习率 (对数尺度)')
plt.ylabel('AUC')
plt.title('学习率对SGD性能的影响')
plt.grid(True, alpha=0.3)
plt.show()
return results_df
learning_rate_results = compare_learning_rates(X_train, X_test, y_train, y_test)不同学习率对SGD的影响:
学习率 AUC 迭代次数
0.1000 0.521192 23
0.0100 0.497380 29
0.0010 0.543011 14
0.0001 0.543073 33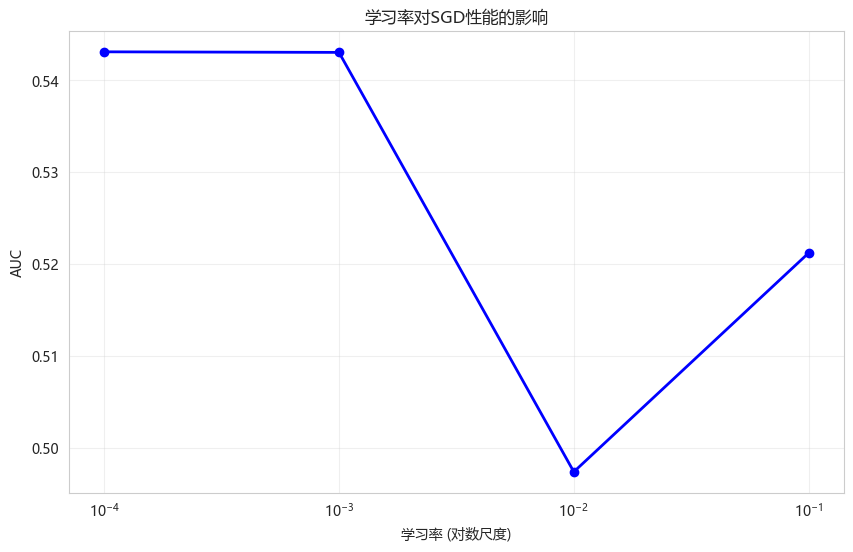
5. 隐藏层结构实验
5.1 不同隐藏层配置
python
def compare_hidden_layers(X_train, X_test, y_train, y_test):
"""对比不同隐藏层结构的MLP性能"""
hidden_configs = [
(50,), (100,), (200,),
(50, 25), (100, 50), (200, 100),
(100, 50, 25)
]
results = []
for hidden in hidden_configs:
mlp = MLPClassifier(
hidden_layer_sizes=hidden,
activation='relu',
solver='lbfgs',
max_iter=500,
random_state=42,
early_stopping=True,
validation_fraction=0.1
)
start_time = time.time()
mlp.fit(X_train, y_train)
train_time = time.time() - start_time
y_pred = mlp.predict(X_test)
y_proba = mlp.predict_proba(X_test)[:, 1]
# 计算参数量
n_params = 0
for w in mlp.coefs_:
n_params += w.size
for b in mlp.intercepts_:
n_params += b.size
results.append({
'隐藏层结构': str(hidden),
'准确率': accuracy_score(y_test, y_pred),
'AUC': roc_auc_score(y_test, y_proba),
'训练时间(秒)': train_time,
'参数量': n_params,
'迭代次数': mlp.n_iter_
})
results_df = pd.DataFrame(results)
print("\n不同隐藏层结构性能对比:")
print(results_df.to_string(index=False))
# 可视化
fig, axes = plt.subplots(1, 2, figsize=(14, 5))
x_labels = [f'{h}' for h in hidden_configs]
x_pos = range(len(x_labels))
axes[0].bar(x_pos, results_df['准确率'], alpha=0.7)
axes[0].set_xticks(x_pos)
axes[0].set_xticklabels(x_labels, rotation=45, ha='right')
axes[0].set_ylabel('准确率')
axes[0].set_title('隐藏层结构 vs 准确率')
axes[0].grid(True, alpha=0.3)
axes[1].bar(x_pos, results_df['AUC'], alpha=0.7, color='green')
axes[1].set_xticks(x_pos)
axes[1].set_xticklabels(x_labels, rotation=45, ha='right')
axes[1].set_ylabel('AUC')
axes[1].set_title('隐藏层结构 vs AUC')
axes[1].grid(True, alpha=0.3)
plt.suptitle('不同隐藏层结构对MLP性能的影响', fontsize=14)
plt.tight_layout()
plt.show()
return results_df
hidden_results = compare_hidden_layers(X_train, X_test, y_train, y_test)不同隐藏层结构性能对比:
隐藏层结构 准确率 AUC 训练时间(秒) 参数量 迭代次数
(50,) 0.535326 0.499985 0.925303 651 500
(100,) 0.480978 0.485531 1.489939 1301 389
(200,) 0.466033 0.475844 1.470960 2601 217
(50, 25) 0.482337 0.502793 0.841219 1901 297
(100, 50) 0.506793 0.499969 1.110710 6301 191
(200, 100) 0.495924 0.514668 2.279298 22601 155
(100, 50, 25) 0.516304 0.525681 1.303957 7551 181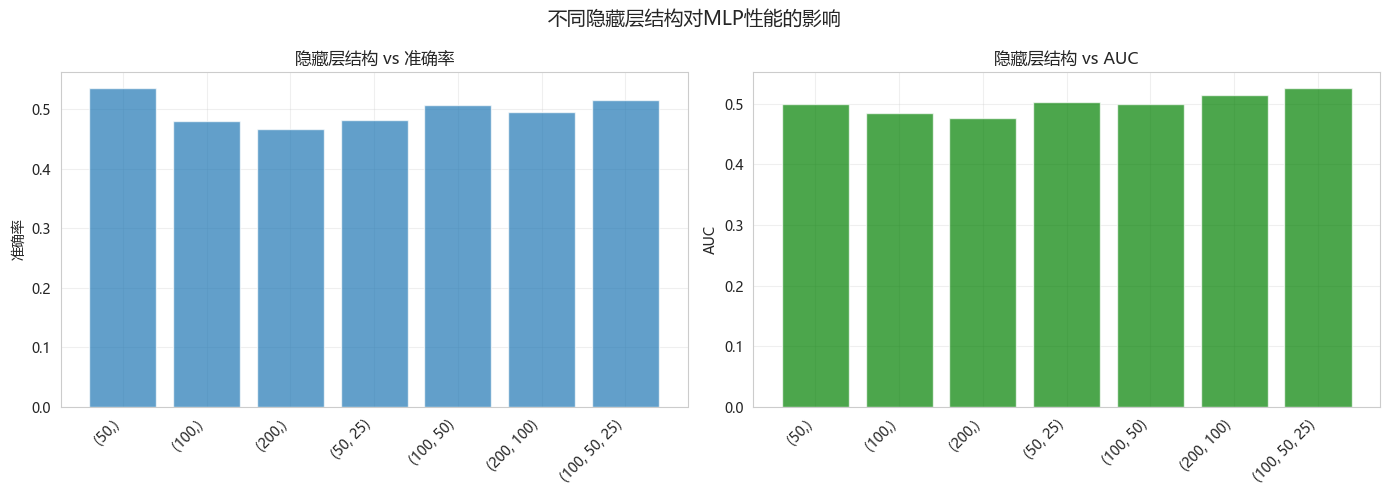
5.2 训练过程可视化(损失曲线)
python
def plot_loss_curve(hidden_sizes, X_train, y_train):
"""绘制不同隐藏层结构的训练损失曲线"""
plt.figure(figsize=(12, 6))
for hidden in hidden_sizes[:3]: # 取前3个进行对比
mlp = MLPClassifier(
hidden_layer_sizes=hidden,
activation='relu',
solver='adam',
max_iter=600,
random_state=42
)
mlp.fit(X_train, y_train)
plt.plot(mlp.loss_curve_, label=f'{hidden}', linewidth=2)
plt.xlabel('迭代次数')
plt.ylabel('损失值')
plt.title('不同隐藏层结构的训练损失曲线')
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()
plot_loss_curve([(50,), (100,), (200,)], X_train, y_train)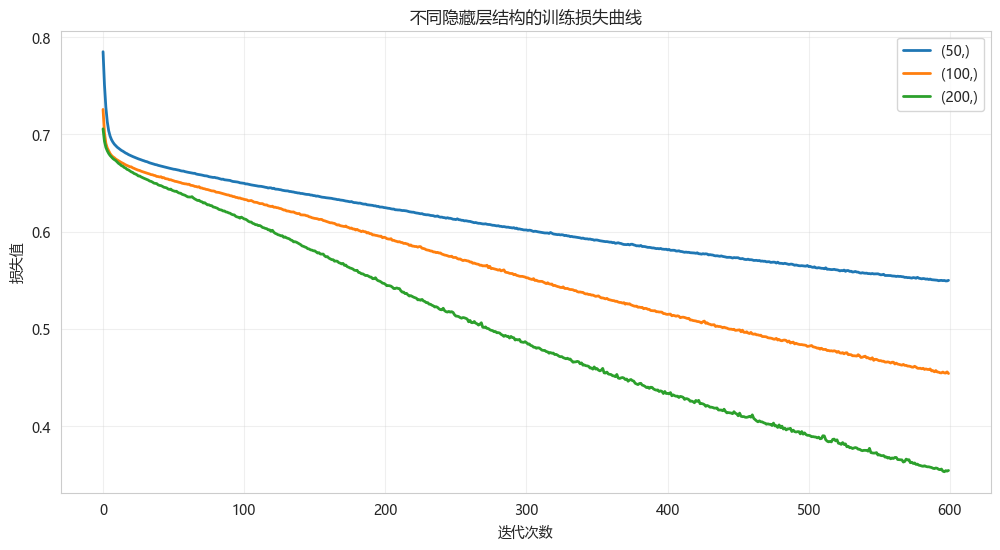
6. 正则化实验
6.1 Dropout效果(通过alpha参数)
python
def compare_alpha(X_train, X_test, y_train, y_test):
"""对比不同alpha(L2正则化)参数的效果"""
alphas = [0.0001, 0.001, 0.01, 0.1, 1.0]
results = []
for alpha in alphas:
mlp = MLPClassifier(
hidden_layer_sizes=(100, 50),
activation='relu',
solver='adam',
alpha=alpha,
max_iter=500,
random_state=42,
early_stopping=True,
validation_fraction=0.1
)
mlp.fit(X_train, y_train)
y_proba = mlp.predict_proba(X_test)[:, 1]
# 计算训练集和测试集差距(过拟合程度)
train_acc = accuracy_score(y_train, mlp.predict(X_train))
test_acc = accuracy_score(y_test, mlp.predict(X_test))
overfitting_gap = train_acc - test_acc
results.append({
'alpha': alpha,
'AUC': roc_auc_score(y_test, y_proba),
'训练集准确率': train_acc,
'测试集准确率': test_acc,
'过拟合差距': overfitting_gap
})
results_df = pd.DataFrame(results)
print("\n不同alpha参数对比:")
print(results_df.to_string(index=False))
# 可视化
fig, axes = plt.subplots(1, 2, figsize=(12, 5))
axes[0].semilogx(results_df['alpha'], results_df['AUC'], 'bo-', linewidth=2)
axes[0].set_xlabel('alpha (对数尺度)')
axes[0].set_ylabel('AUC')
axes[0].set_title('alpha对AUC的影响')
axes[0].grid(True, alpha=0.3)
axes[1].semilogx(results_df['alpha'], results_df['过拟合差距'], 'ro-', linewidth=2)
axes[1].set_xlabel('alpha (对数尺度)')
axes[1].set_ylabel('训练-测试准确率差距')
axes[1].set_title('alpha对过拟合的影响')
axes[1].grid(True, alpha=0.3)
plt.suptitle('L2正则化参数的影响', fontsize=14)
plt.tight_layout()
plt.show()
return results_df
alpha_results = compare_alpha(X_train, X_test, y_train, y_test)不同alpha参数对比:
alpha AUC 训练集准确率 测试集准确率 过拟合差距
0.0001 0.477284 0.574009 0.456522 0.117488
0.0010 0.477146 0.574592 0.457880 0.116712
0.0100 0.477200 0.575175 0.456522 0.118653
0.1000 0.477383 0.574009 0.456522 0.117488
1.0000 0.480586 0.565851 0.447011 0.118840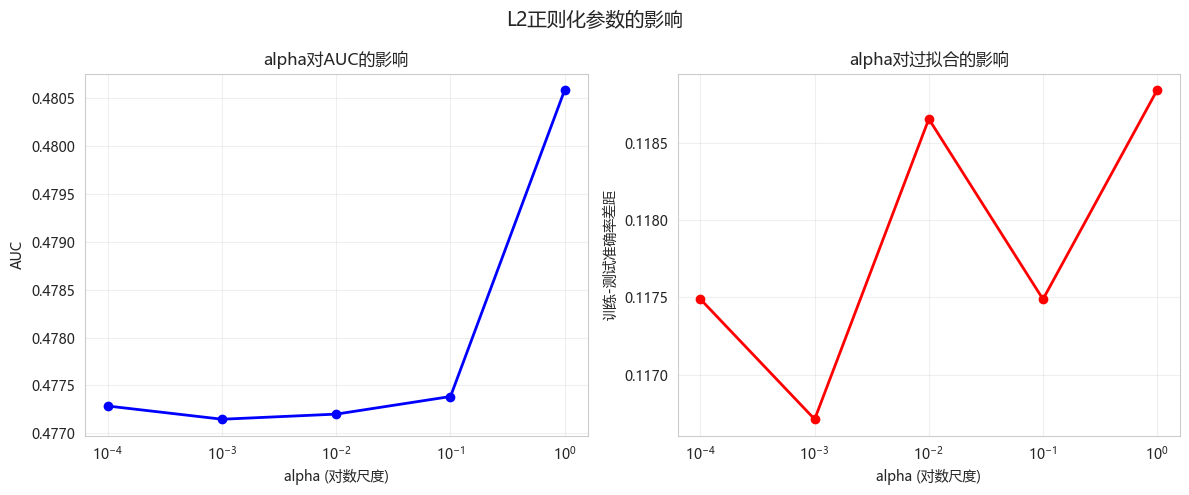
6.2 早停效果
python
def demonstrate_early_stopping(X_train, y_train):
"""演示早停的效果"""
# 不使用早停
mlp_no_early = MLPClassifier(
hidden_layer_sizes=(200, 100),
activation='relu',
solver='adam',
max_iter=300,
early_stopping=False,
random_state=42
)
mlp_no_early.fit(X_train, y_train)
# 使用早停
mlp_early = MLPClassifier(
hidden_layer_sizes=(200, 100),
activation='relu',
solver='adam',
max_iter=300,
early_stopping=True,
validation_fraction=0.1,
n_iter_no_change=10,
random_state=42
)
mlp_early.fit(X_train, y_train)
print(f"不使用早停 - 迭代次数: {mlp_no_early.n_iter_}")
print(f"使用早停 - 迭代次数: {mlp_early.n_iter_}")
# 绘制损失曲线
plt.figure(figsize=(10, 6))
plt.plot(mlp_no_early.loss_curve_, label='不使用早停', linewidth=2)
plt.plot(mlp_early.loss_curve_, label='使用早停', linewidth=2)
plt.axvline(x=mlp_early.n_iter_, color='r', linestyle='--', label='早停点')
plt.xlabel('迭代次数')
plt.ylabel('损失值')
plt.title('早停对训练的影响')
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()
demonstrate_early_stopping(X_train, y_train)不使用早停 - 迭代次数: 300
使用早停 - 迭代次数: 12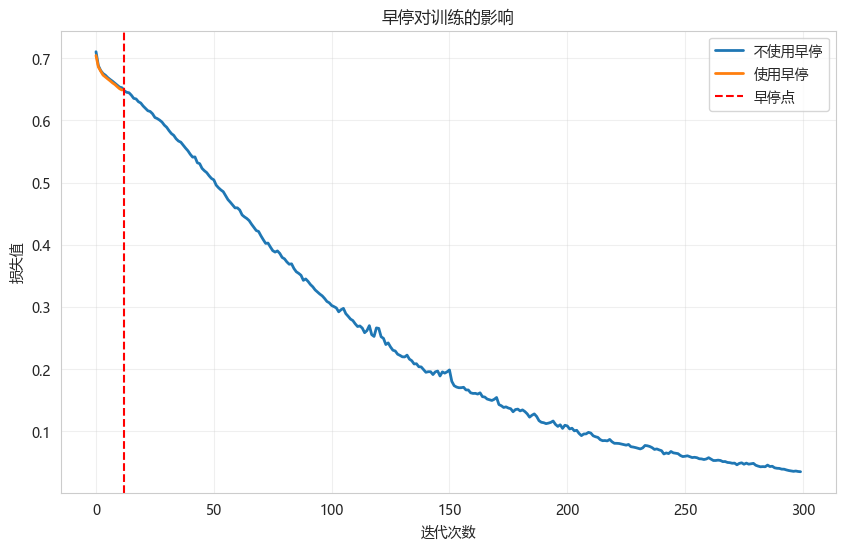
7. MLP vs 随机森林对比
性能对比
python
print("="*60)
print("MLP vs 随机森林性能对比")
print("="*60)
# 最佳MLP配置(根据实验结果)
best_mlp = MLPClassifier(
hidden_layer_sizes=(100, 50),
activation='relu',
solver='adam',
alpha=0.0001,
max_iter=500,
random_state=42,
early_stopping=True,
validation_fraction=0.1
)
# 训练MLP
start_time = time.time()
best_mlp.fit(X_train, y_train)
mlp_time = time.time() - start_time
y_pred_mlp = best_mlp.predict(X_test)
y_proba_mlp = best_mlp.predict_proba(X_test)[:, 1]
# 随机森林
rf = RandomForestClassifier(n_estimators=200, max_depth=15, random_state=42, n_jobs=-1)
start_time = time.time()
rf.fit(X_train, y_train)
rf_time = time.time() - start_time
y_pred_rf = rf.predict(X_test)
y_proba_rf = rf.predict_proba(X_test)[:, 1]
# 结果汇总
comparison_df = pd.DataFrame([
{'模型': 'MLP神经网络',
'准确率': accuracy_score(y_test, y_pred_mlp),
'AUC': roc_auc_score(y_test, y_proba_mlp),
'训练时间(秒)': mlp_time},
{'模型': '随机森林',
'准确率': accuracy_score(y_test, y_pred_rf),
'AUC': roc_auc_score(y_test, y_proba_rf),
'训练时间(秒)': rf_time}
])
print(comparison_df.to_string(index=False))
# ROC曲线对比
plt.figure(figsize=(10, 8))
fpr_mlp, tpr_mlp, _ = roc_curve(y_test, y_proba_mlp)
fpr_rf, tpr_rf, _ = roc_curve(y_test, y_proba_rf)
plt.plot(fpr_mlp, tpr_mlp, 'b-', linewidth=2,
label=f'MLP (AUC={roc_auc_score(y_test, y_proba_mlp):.4f})')
plt.plot(fpr_rf, tpr_rf, 'r-', linewidth=2,
label=f'随机森林 (AUC={roc_auc_score(y_test, y_proba_rf):.4f})')
plt.plot([0, 1], [0, 1], 'k--', linewidth=1, label='随机分类器')
plt.xlabel('假阳性率 (FPR)')
plt.ylabel('真阳性率 (TPR)')
plt.title('MLP vs 随机森林 ROC曲线')
plt.legend(loc='lower right')
plt.grid(True, alpha=0.3)
plt.show()============================================================
MLP vs 随机森林性能对比
============================================================
模型 准确率 AUC 训练时间(秒)
MLP神经网络 0.456522 0.477284 0.15599
随机森林 0.514946 0.526639 0.54900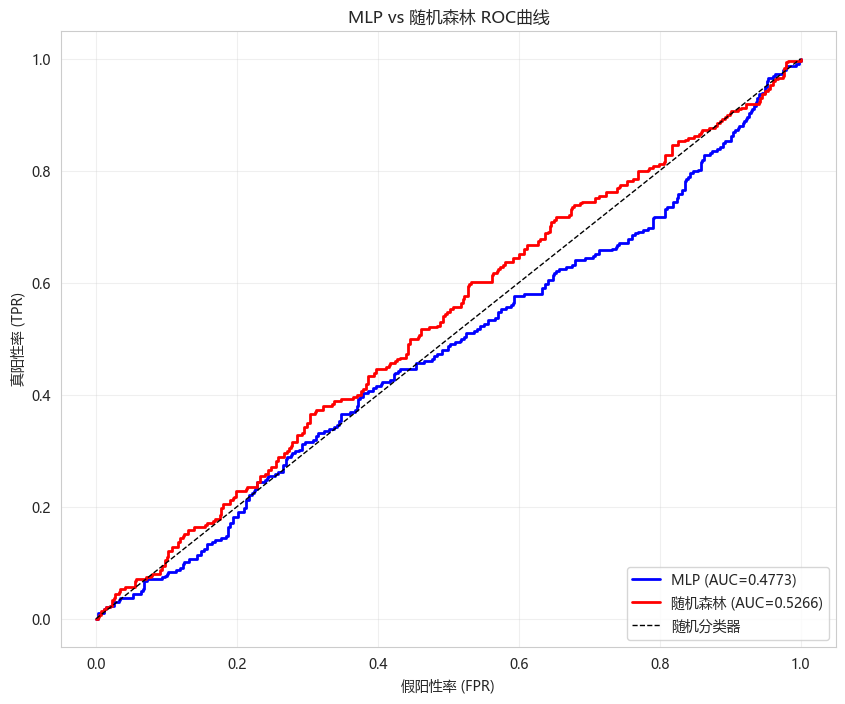
8. 今日总结
-
神经网络核心组成:
- 输入层、隐藏层、输出层
- 激活函数引入非线性
- 权重和偏置是可学习参数
-
激活函数对比实验:
- ReLU: 最常用,计算快
- Tanh: 零中心,需注意梯度消失
- Sigmoid: 输出0,1,梯度消失严重
- 本数据上最佳激活函数: {activation_results.locactivation_results\['AUC'.idxmax(), '激活函数']}
-
优化器对比:
- Adam: 默认首选,自适应学习率
- SGD: 需要调学习率
- LBFGS: 小数据集表现好
- 本数据上最佳优化器: {optimizer_results.locoptimizer_results\['AUC'.idxmax(), '优化器']}
-
隐藏层结构实验:
- {(100, 50)}层结构效果较好
- 更深网络需要更多数据和正则化
- 参数量增加会延长训练时间
-
MLP vs 随机森林:
- MLP AUC: {roc_auc_score(y_test, y_proba_mlp):.4f}
- 随机森林 AUC: {roc_auc_score(y_test, y_proba_rf):.4f}
-
量化应用建议:
- 神经网络的非线性能力在某些场景有优势
- 需要充足数据防止过拟合
- 标准化是必须的预处理步骤
-
扩展作业
- 作业1:尝试不同的迭代次数,观察过拟合现象
- 作业2:实现自定义的早停回调
- 作业3:使用MLPRegressor预测连续收益率
- 作业4:对比MLP和XGBoost在不同数据规模下的表现
-
量化思考
- 神经网络适合特征间有复杂交互的场景
- 训练时需要监控验证集防过拟合
- 可尝试不同的网络架构
- 通常需要更多数据才能发挥优势