在生成式AI席卷各行各业的今天,企业技术负责人面临一个两难选择:用公有云API,担心核心数据泄露;做私有化部署,又怕硬件成本失控且推理速度慢。这不仅仅是买几张显卡的问题,更是一场关于算力效能 与数据主权的博弈。

一、 为什么传统私有化部署容易"踩坑"?
很多团队在立项时,往往低估了私有化落地的隐性成本。根据行业调研,主要存在以下三个维度的挑战:
1.算力效能的"黑洞"效应 私有化部署最大的隐忧在于资源利用率。如果缺乏精细化的调度机制,昂贵的GPU集群在业务低谷期会大量空转,而在高峰期又面临请求拥堵。这种**"潮汐效应"**直接导致单位算力的产出比极低,让AI变成了"成本中心"而非"利润中心" 。
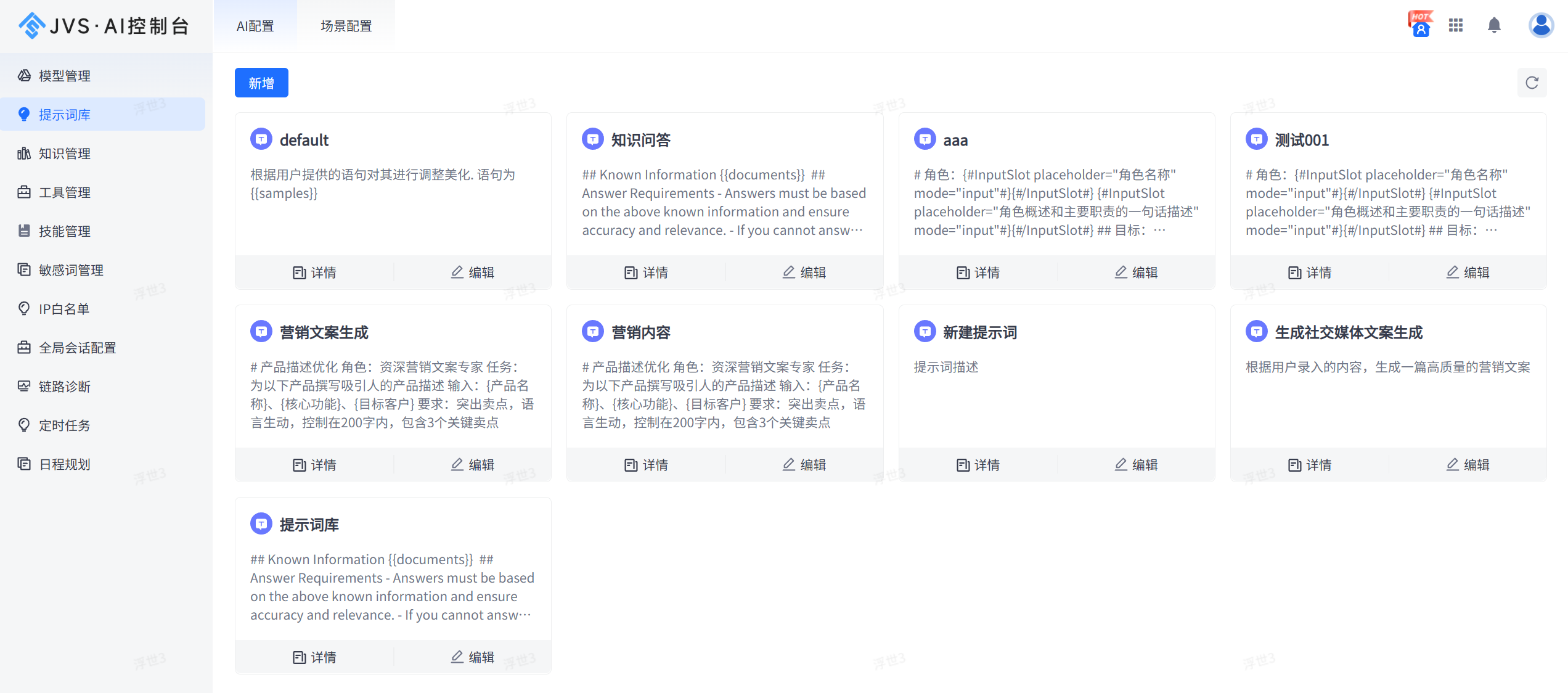
2.数据全生命周期的风险 从数据采集、标注到模型训练,数据流转的每个环节都存在泄露风险。特别是通用大模型可能存在的"记忆效应",使得敏感信息有概率在生成环节被意外提取。企业急需从"被动防御"转向**"全生命周期的主动治理"** 。
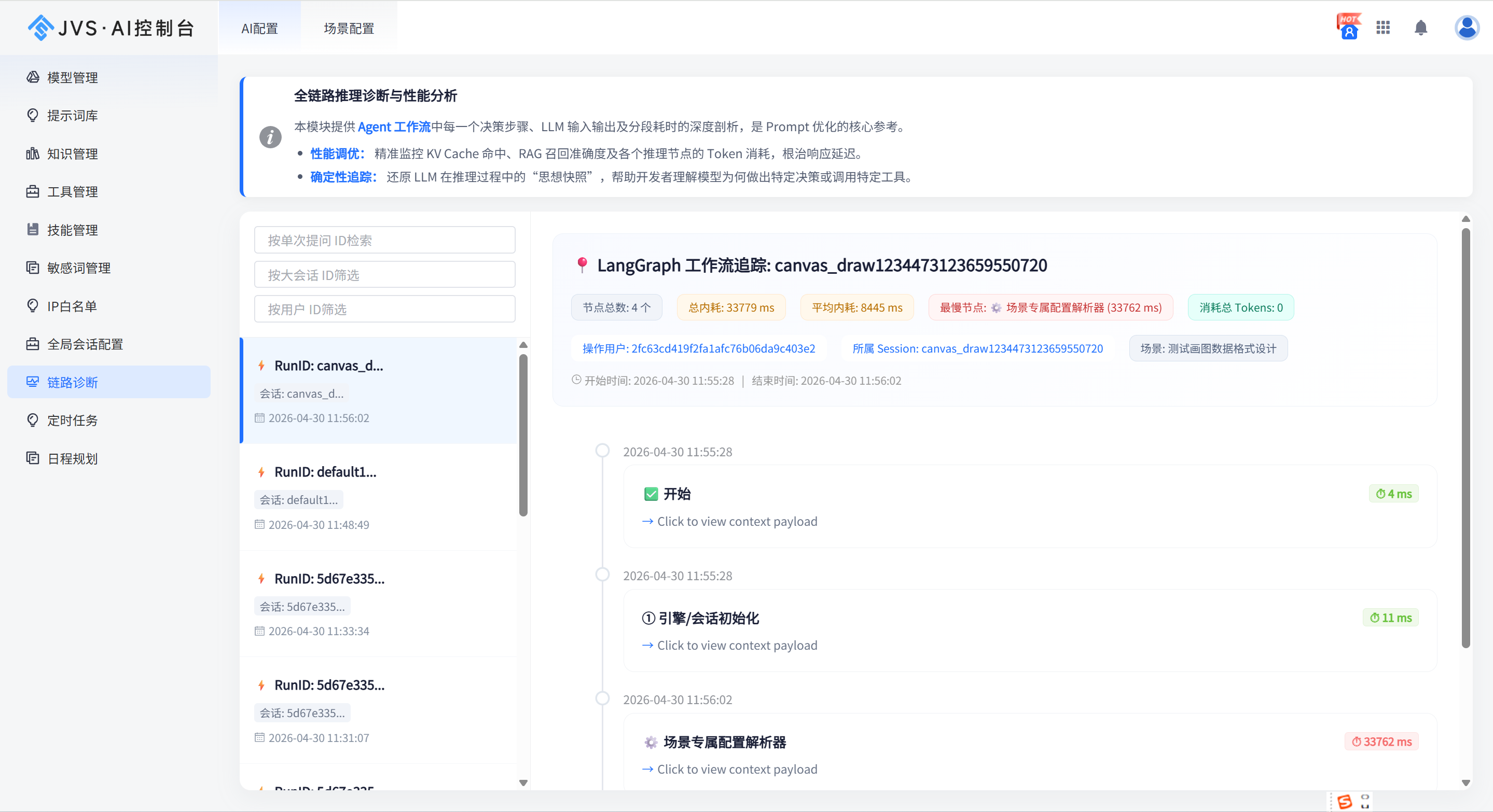
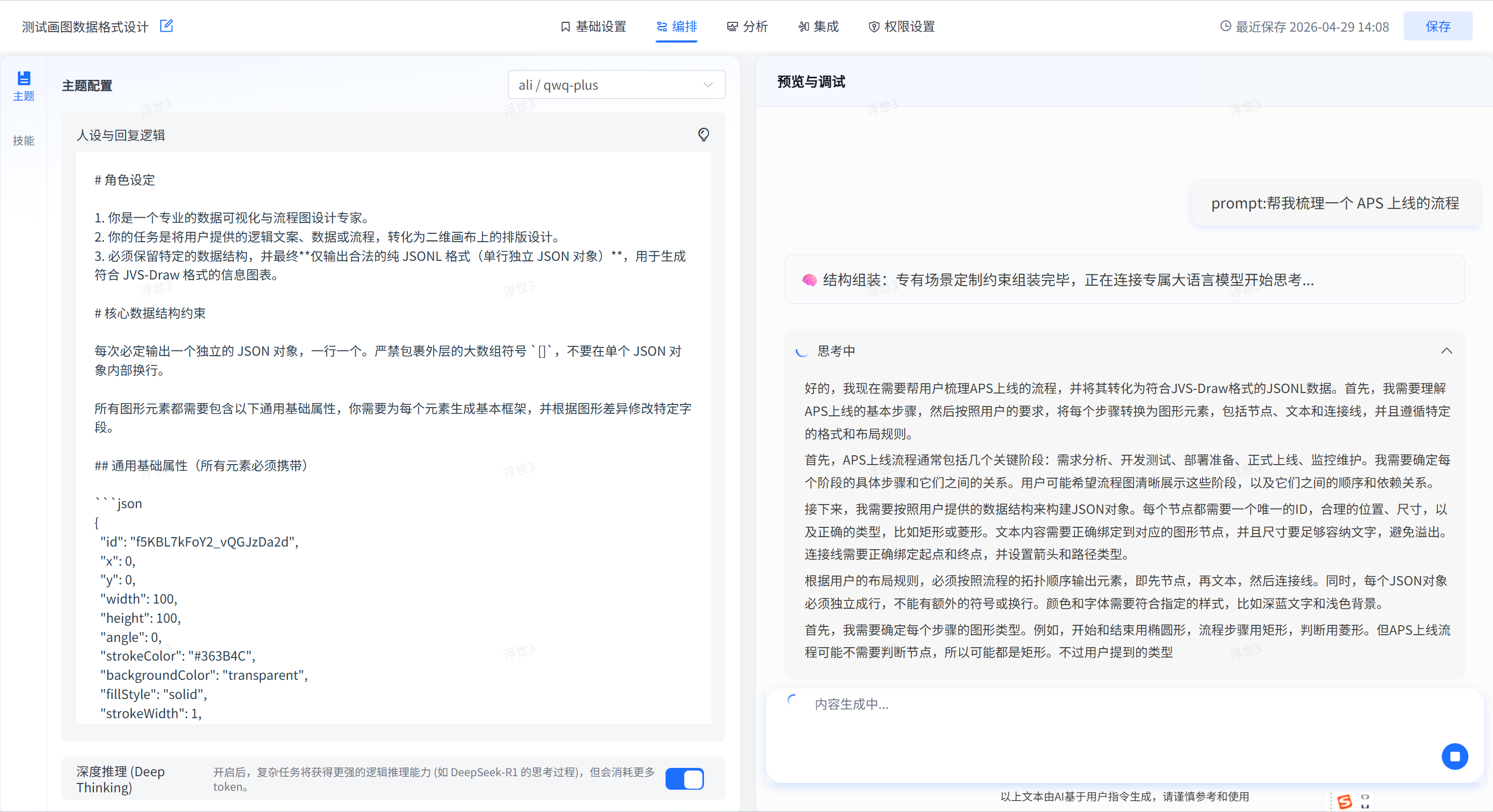
3、AI场景能否真正落地,在企业内部如果仅仅达一个大模型,做简单的问答,那么AI 就是一个吉祥物,如何让AI 突破对话框,真正让AI 能干事情,
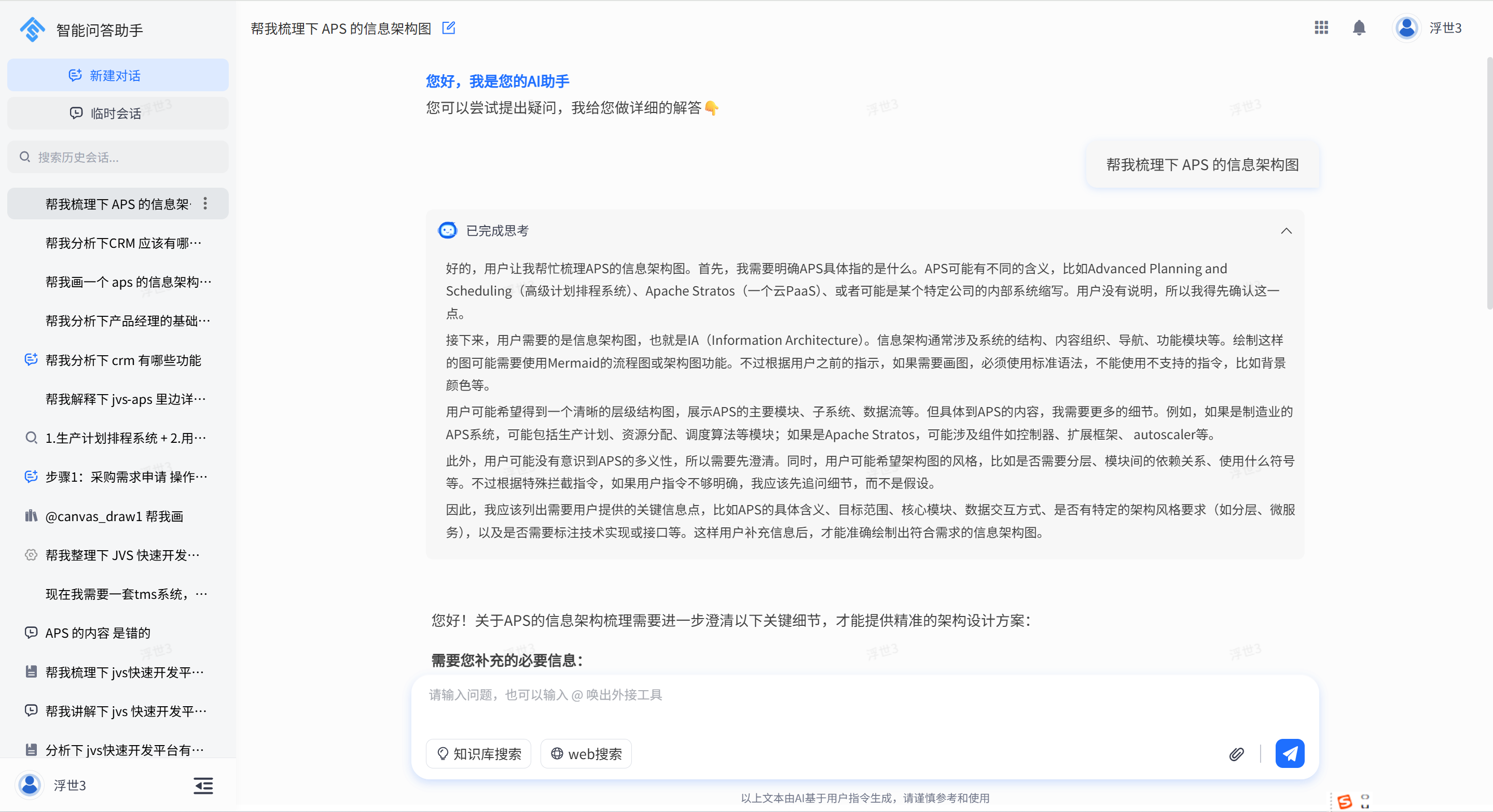
那么,如何给AI 提供可以使用的工具,以及工具配套的说明书(skills),那么这个才是真正能干事情的AI
二、 破局思路:构建企业级AI基础设施
要真正解决上述痛点,不能只靠堆砌硬件,而需要一套成熟的企业级数字化脚手架来统筹管理。
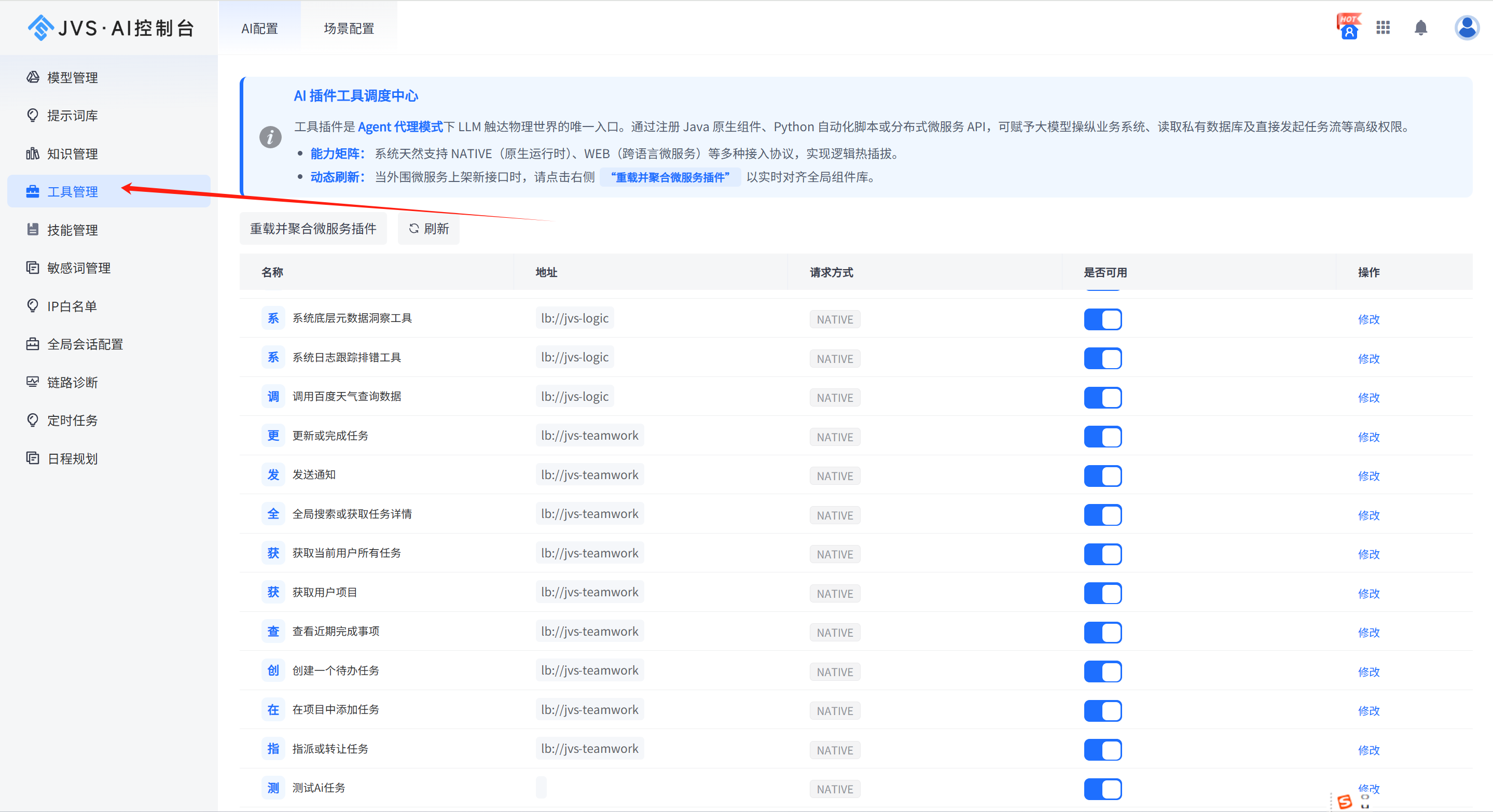
- 智能调度与效能优化通过引入智能化的削峰填谷机制,系统应能自动平衡不同时间段的算力负载。例如,在低代码开发平台中集成AI能力时,可以利用微服务架构实现资源的按需分配,确保每一分算力都花在刀刃上 。
- 模型与算力的解耦管理专业的企业级套件通常支持异构算力的统一纳管。无论底层是何种硬件架构,通过标准化的接口屏蔽底层差异,让企业可以随时切换或接入不同的模型供应商(如通义千问、智谱AI等),避免被单一技术路线"绑架" 。
- 私有化知识库的安全交互 针对数据安全,核心方案是构建**私有化RAG(检索增强生成)**体系。将企业私域数据隔离在本地知识库中,模型仅通过API调用进行语义理解,而不让敏感数据参与公网训练。这种方式既利用了大模型的推理能力,又确保了核心机密不出域 。
- 能真正落地解决生产过程中的问题,自定义业务场景:
结语
企业引入AI不应是"面子工程",而应是实打实的效率革命。通过构建集低代码、数据分析与AI助手于一体的模块化底座,企业可以以更低的试错成本,实现从"有AI"到"用好AI"的跨越。
如果您对AI套件有疑问或兴趣,可以与我们一起交流探讨。在gitee上搜JVS,也有在线Demo.。