KG²RAG
KG²RAG是南大和阿里2025年2月提出的RAG新框架,在基于语义检索的RAG上融合了知识图谱,过程是先将切分的文本块和知识图谱构建关联图谱,用嵌入模型查询语义相似的文本块,关联图谱+文本块-->子图-->关联子图-->基于知识图谱过滤组织-->拓展块。
- 发表时间:2025.02.8
- 论文名称:Knowledge Graph-Guided Retrieval Augmented Generation、项目代码
目前的 RAG 研究主要侧重于应用基于语义的方法来检索孤立的相关片段,而忽略了它们之间的内在联系。
文章提出了一种知识图谱引导的检索增强生成(KG2RAG)框架,该框架利用知识图谱(KGs)提供chunk之间的事实级关系,提高检索结果的多样性和连贯性。
具体而言,在执行基于语义的检索以提供种子片段后,KG2RAG采用知识图谱引导的片段扩展过程、基于知识图谱的片段组织过程,以结构良好的段落形式呈现相关且重要的知识。
一、论文动机
- 关联性缺失:忽略文本块间的内在事实关联,无法激活LLMs的推理能力;
- 组织混乱:检索结果按相似度直接拼接,信息孤立,难以生成全面、连贯的响应。
二、论文思路
-
KG²RAG引入知识图谱,通过事实级关系关联文本块 ,提升检索结果的多样性、连贯性与准确性。
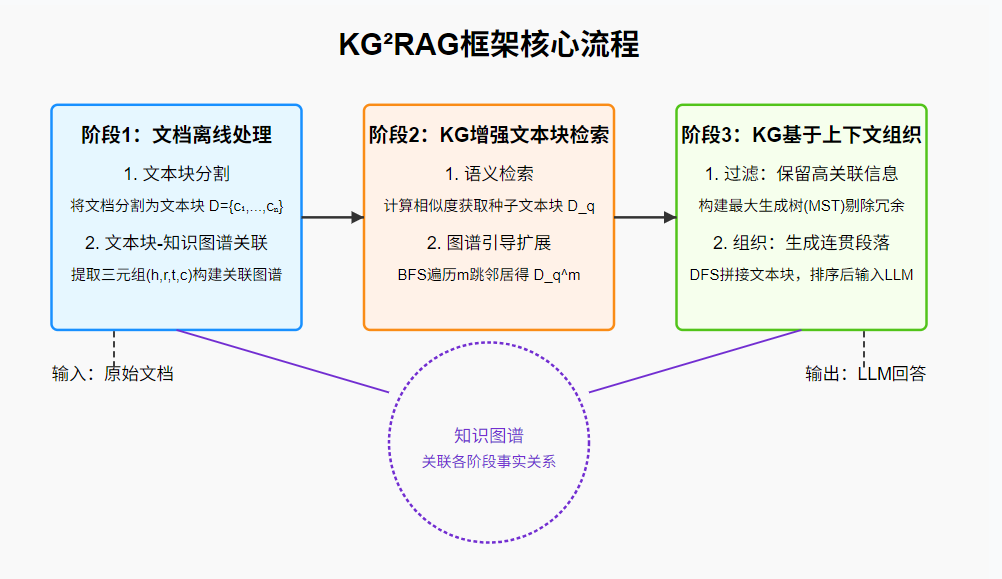
1. 阶段1:文档离线处理
(1)文本块分割
按句子/段落结构将文档分割为若干文本块(记为( D = { c 1 , . . . , c n } D=\{c_1,...,c_n\} D={c1,...,cn})),可附加元信息(如标题、摘要)或生成关联问题以增强文本块信息。
(2)文本块-知识图谱关联
为捕捉文本块间的事实关系,通过LLM提取文本块中的实体与关系,构建块与特定知识图谱之间的关联 G = ( h , r , t , c ) ∣ c ∈ D G = {(h, r, t, c) | c ∈ D} G=(h,r,t,c)∣c∈D,其中(h)(头实体)、®(关系)、(t)(尾实体)、©(三元组衍生的块),最终形成关联图谱。优势在于此构建与查询无关,仅需构建一次,支持新文档增量更新。
2. 阶段2:KG增强文本块检索
采用"语义检索+图谱引导扩展"两阶段模式,解决传统RAG检索结果孤立的问题。
(1)基于语义的检索
- 用嵌入模型将查询(q)与文本块转换为高维向量,计算语义相似度;
- 选取Top-k相似度最高的文本块作为"种子文本块"(记为( D q Dq Dq))。
(2)图引导的扩展
- 从关联图谱( G \mathcal{G} G)中提取种子文本块对应的子图( G q 0 \mathcal{G}_q^0 Gq0);
- 通过广度优先搜索遍历子图的m跳邻居,得到扩展子图( G q m \mathcal{G}_q^m Gqm);
- 提取扩展子图关联的所有文本块,得到扩展块(记为 ( D q m ) (D_q^m) (Dqm)),实现跨文档的事实关联扩展,避免结果同质化。
3. 阶段3:基于知识图谱的上下文组织
作为"过滤器"和"组织器",解决扩展后文本块数量过多、噪声大的问题,提升输入LLM的上下文质量。
(1)过滤:保留高关联信息
- 将扩展子图 G q m \mathcal{G}_q^m Gqm 转换为加权无向图 U q m \mathcal{U}_q^m Uqm(权重为文本块与查询的相似度);
- 按连通分量分割图,对每个分量构建最大生成树(MST),剔除冗余边,保留核心事实关联。
(2)组织:生成连贯段落
- 文本表示:对每个MST,以最高权重边为根,通过深度优先搜索拼接文本块,形成语义连贯的段落;
- 三元组表示:用交叉编码器计算MSTs与查询的相关性,按相关性排序段落,选取Top-k文本块输入LLM。
三、实验设计与结果
1. 实验设置
(1)数据集
- 基准数据集:HotpotQA(包含Distractor(10个文档,含干扰项)和Fullwiki(66,581个文档)两个设置);
- 变体数据集:Shuffle-HotpotQA(随机替换实体类别,削弱LLM先验知识依赖,强制依赖RAG检索);
- 额外验证数据集:MuSiQue(多跳问答)、TriviaQA(长文本问答,平均单文档2895词)。
(2)基线方法
- LLM-only:无检索,直接生成;
- Semantic RAG:仅基于语义检索;
- Hybrid RAG:语义+关键词检索(如BM25);
- GraphRAG/LightRAG:其他基于图谱的RAG方法。
(3)评价指标
- 响应质量:F1、精确率(Precision)、召回率(Recall)(与标准答案对比);
- 检索质量:F1、精确率、召回率(与参考事实对比);
- 效率指标:KG构建的token成本、LLM调用次数、检索/生成时间。
2. 核心实验结果
(1)响应质量(表1、表7、表8)
- 在HotpotQA-Dist中,KG²RAG的F1达0.663,高于Hybrid RAG(0.653)、GraphRAG(0.400);
- 在Fullwiki设置(更具挑战性)中,KG²RAG F1达0.631,比基线高至少8%;
- 在Shuffle-HotpotQA中,因削弱先验知识,KG²RAG优势更显著(Distractor设置F1 0.545,比基线高2.5%+);
- 在MuSiQue(F1 0.419)和TriviaQA(F1 0.273)中,均保持最优。
(2)检索质量(表2)
- HotpotQA-Dist中,KG²RAG检索F1达0.436,精确率0.301,比Semantic RAG(精确率0.224)高7.7%;
- Fullwiki设置中,兼顾精确率与召回率,优于其他RAG方法。
(3)消融实验(表3、表4)
- 无组织模块(w/o organization):响应质量略降(F1 0.660→0.663),检索精确率大幅下降(0.153→0.301),证明组织模块可过滤噪声;
- 无扩展模块(w/o expansion):响应F1降至0.626,检索召回率下降(0.842→0.908),证明扩展模块可捕捉关键遗漏信息。
(4)效率对比(表9、表10)
- KG构建成本:KG²RAG每文本块输入token 561、输出token 22、耗时1s,远低于GraphRAG(输入2791token、耗时6s);
- 检索/生成时间:KG²RAG平均检索25ms、生成2300ms,接近Semantic RAG,远快于GraphRAG(检索42ms、生成5500ms)。
3. 鲁棒性验证
- 随机删除5%/10%图谱三元组后,KG²RAG响应F1仍保持0.654+,检索F1 0.432+,优于Hybrid RAG,证明对图谱质量不敏感。
四、对比分析
1. 相关工作差异
- 传统RAG:依赖文本块物理位置(如滑动窗口)扩展,无法跨文档关联事实;
- 其他图谱RAG(如GraphRAG):聚焦摘要任务,图谱构建成本高;
- KG²RAG:以事实级关系为核心扩展文本块,兼顾效率与质量。
2. 局限性
- 仅优化RAG的"检索"环节,未涉及查询重写、多轮对话等其他模块;
- 未来方向:开发插件化工具,与其他RAG优化模块兼容。
五、核心贡献
- 框架创新:首次将知识图谱引入RAG的"检索-组织"全流程,通过事实关联提升结果连贯性;
- 性能优势:在多数据集、多设置下,响应与检索质量均优于现有RAG方法;
- 效率保障:KG构建与检索/生成耗时低,适合实际应用。