ASM 到底是怎么做到"更快、更稳、几乎无感迁移"的?
在上篇里,我们已经把一个核心背景讲清楚了:
Redis Cluster 过去不是不能迁 Slot,而是迁移过程本身并不够适合生产环境。
问题的根源,在于旧迁移机制会让 Slot 长时间处于"部分 Key 已迁、部分 Key 未迁"的中间态,从而把复杂性直接暴露给客户端、请求路径和线上业务。
也正因为如此,Redis 8.4 引入的 Atomic Slot Migration(ASM),才不只是一个"命令增强",而是一项真正值得单独解读的底层能力升级。
这一篇,我们就继续往下看:
ASM 到底改了什么?它是怎么工作的?又为什么它会显著改善 Redis Cluster 的运维体验?
Redis 8.4 ASM 的核心变化:把迁移从"搬运"变成"复制 + 交接"
Redis 8.4 引入 ASM 后,Slot 迁移的执行语义发生了根本变化。
它的核心思想可以概括为一句话:
先把整个 Slot 的数据复制到目标节点,再在一个极短窗口内完成所有权切换。
这就是 ASM 名字里 Atomic(原子化) 的真正含义。
需要注意的是,这里的"原子化"并不是说整个迁移过程瞬间完成,而是说:
对于客户端和集群所有权语义而言,Slot 的归属切换是一次性的,不再长期暴露中间态。
这和旧机制下"边迁边切"的逻辑完全不同。
Redis 8.4 如何使用 ASM?
为此,Redis 8.4 新增了一组新的命令族:
Bash
CLUSTER MIGRATION这意味着 Slot 迁移终于不再只是"多个底层命令拼起来的流程",而是被 Redis 正式抽象成一个标准化的集群运维动作。
1. 从目标主节点发起迁移
ASM 的入口是:
Bash
CLUSTER MIGRATION IMPORT <start-slot> <end-slot> [<start-slot> <end-slot>]...这个命令需要发送到 目标主节点。
这点非常重要,因为它说明 Redis 对 ASM 的建模方式更接近:
REPLICAOF- 或某种"目标端主动拉取数据"的复制行为
而不再是传统意义上的"源端一边迁、一边改状态"。
执行后,Redis 会返回一个 task ID,用于后续追踪迁移任务状态。
2. 查询迁移状态
可以通过以下命令查看迁移任务进度:
Bash
CLUSTER MIGRATION STATUS <ID id | ALL>这让 Slot 迁移从过去"命令执行中但过程不透明"的状态,升级为一种更可观测的任务化运维模型。
这对于生产环境非常重要,因为你终于可以更明确地知道:
- 哪个任务正在执行
- 当前迁移到了什么阶段
- 是否已经完成
- 是否存在异常
3. 取消迁移任务
如果需要中止迁移,可以在目标节点上执行:
Bash
CLUSTER MIGRATION CANCEL <ID id | ALL>这意味着 ASM 也更适合纳入真实运维流程中,例如:
- 避开业务高峰
- 中止窗口内未完成任务
- 应对突发资源波动
Redis Cluster 的 Slot 迁移,从此不再只是"命令跑一下",而更像一个完整的运维任务。
ASM 到底是怎么工作的?
如果只停留在"有了个新命令",其实很容易低估 ASM 的价值。
它真正值得关注的,是它背后的执行模型。
因为你会发现,Redis 8.4 实际上是把 Slot 迁移做成了一种:
按 Slot 粒度的临时复制接管流程。
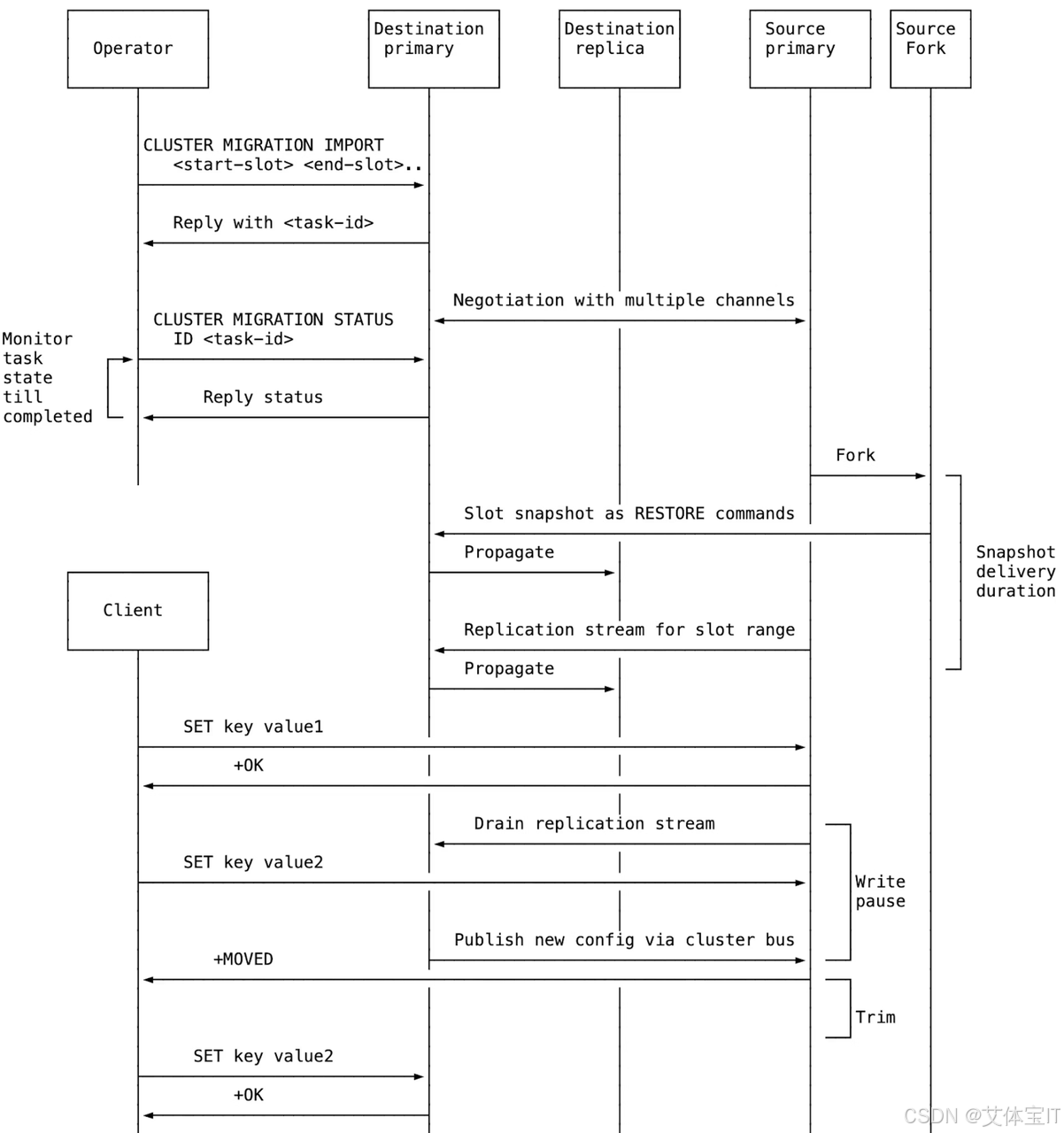
下面按执行过程拆开看。
第 1 步:目标节点发起迁移请求
迁移从目标节点开始,这一点和传统迁移流程完全不同。
目标节点通过:
Bash
CLUSTER MIGRATION IMPORT <start-slot> <end-slot>向源节点发起指定 Slot 的导入请求。
这意味着 Redis 把迁移理解为:
目标端主动拉取这些 Slot 的数据。
第 2 步:目标节点建立迁移任务与专用复制连接
目标节点会按"源节点"维度创建迁移任务。
也就是说,即使你一次性指定多个 Slot 范围,只要它们都来自同一个源节点,Redis 也会把它们归并为一个迁移任务。
随后目标节点会建立专用连接,用于接收这些 Slot 的数据。
更关键的是,Redis 并不是只建立一条连接,而是:
- 一条用于传输 快照(snapshot)
- 一条用于传输 增量写入流(live delta)
这其实已经非常接近 Redis 的复制模型。
第 3 步:源节点开始发送 Slot 快照
源节点会 fork 出快照流程,将目标 Slot 对应的数据导出给目标节点。
通常情况下,这些数据会以类似逐 Key RESTORE 的方式发送。
但 Redis 8.4 还针对大对象做了额外优化:
对于较大的非模块类型 Key,Redis 会自动切换到类似 AOF chunk 的分段传输方式。
例如一个非常大的 Hash,不一定会被一次性打包成一个超大的恢复命令,而可能被拆成多批 HSET。
这带来的好处很直接:
- 降低峰值内存占用
- 减少超大对象迁移时的阻塞风险
- 提升大 Key 场景下的迁移平滑性
这也是 ASM 在工程实现上非常实用的一点。
第 4 步:目标节点一边应用快照,一边追平增量写入
在快照传输期间,源节点上的业务流量并不会停止。
因此 Redis 必须同时保证两件事:
- 旧数据能被完整复制过去
- 迁移期间的新写入不会丢失
这时第二条连接就起作用了:
它会持续同步这些 Slot 上发生的增量写入。
于是目标节点会同时进行两件事:
- 应用快照数据
- 接收并追平增量更新
这一步非常关键,因为它意味着:
ASM 不是边迁边切,而是先尽可能把目标节点的数据状态追平。
这正是它能显著降低迁移扰动的核心原因。
第 5 步:进入极短暂停写窗口,完成原子交接
当快照传输完成、增量积压下降到阈值以内后,Redis 会进入最终收尾阶段。
此时源节点会:
- 短暂停止相关 Slot 的写入
- 将最后剩余的增量同步给目标节点
- 通知目标节点可以接管 Slot 所有权
这一步就是 ASM 的核心:
Atomic Handoff(原子交接)
它的价值在于:
Slot 的所有权变化不再伴随长时间中间态,而是发生在一个非常短、可控的切换窗口内。
这也是为什么迁移期间客户端不再需要长期处理"有些 Key 在这里,有些 Key 在那里"的混乱状态。
第 6 步:目标节点正式接管 Slot 所有权
当目标节点确认所有数据和增量都已应用完成后,它会:
- 更新集群配置
- 通过 cluster bus 广播新的 Slot 归属关系
从这一刻开始,这个 Slot 的正式 owner 就变成了目标节点。
客户端后续如果仍访问旧节点,收到的是标准的:
Plain
-MOVED但这里的 -MOVED 已经不再表示"迁移进行中",而是表示:
迁移已经完成,请以后统一访问新节点。
这和旧机制下迁移过程中频繁出现的 -ASK、TRYAGAIN 有本质区别。
第 7 步:源节点后台清理旧数据
迁移完成后,源节点上的旧 Slot 数据需要删除。
Redis 8.4 在这里同样做了一个非常重要的优化:
尽量把旧数据清理放到后台线程异步完成。
由于 Redis Cluster 在内部维护了按 Slot 组织的数据结构,因此它可以在很多场景下:
- 先把整个 Slot 对应的数据"整体摘下"
- 再由后台线程异步删除
这个思路有点类似:
FLUSHALL ASYNCFLUSHDB ASYNC
它的直接收益是:
- 减少主线程阻塞
- 避免清理过程再次制造延迟尖峰
- 让迁移完成后的尾部成本更平滑
当然,Redis 也说明并不是所有场景都能完全走这条最优路径。
例如:
- 某些 module 不支持 per-slot 数据结构
- 开启了
CLIENT TRACKING
这时 Redis 会自动回退到主线程 cron loop 中做增量清理。
这也说明 ASM 是一次非常实用的工程增强,而不是"所有情况下都零成本"的理想化设计。
Redis 官方测试结果说明了什么?
官方这次也给出了一组比较有代表性的 benchmark,用于衡量 ASM 对生产负载的影响。
虽然这类测试结果不应该机械照搬到所有线上环境,但它至少可以帮助我们理解 ASM 的行为边界。
测试负载
官方使用的工作负载如下:
- 1000 万个 Key
- Value 大小 512 字节
- 数据总量约 5GB
- 写:读 = 1:10
- 10 个线程
- 每个线程 50 个客户端
- 总计 500 个连接
这是一种比较典型的缓存型业务负载模型,比较接近很多线上 Redis 场景。
测试环境
- Redis 8.4 Cluster
- 部署在 GCP 多台
c4-standard-8实例上- 8 vCPU
- 32GB RAM
- 每个 shard 独占一台实例
- 使用
memtier_benchmark持续施压 - 所有实例部署在同一可用区
场景一:从 3 个 shard 扩容到 4 个 shard
这个场景模拟的是一个很典型的线上动作:集群在线扩容。
在集群稳定运行约 85 秒后,新增第 4 个 shard,并使用 ASM 将原有每个节点中约 三分之一的 Slot 迁移到新节点。
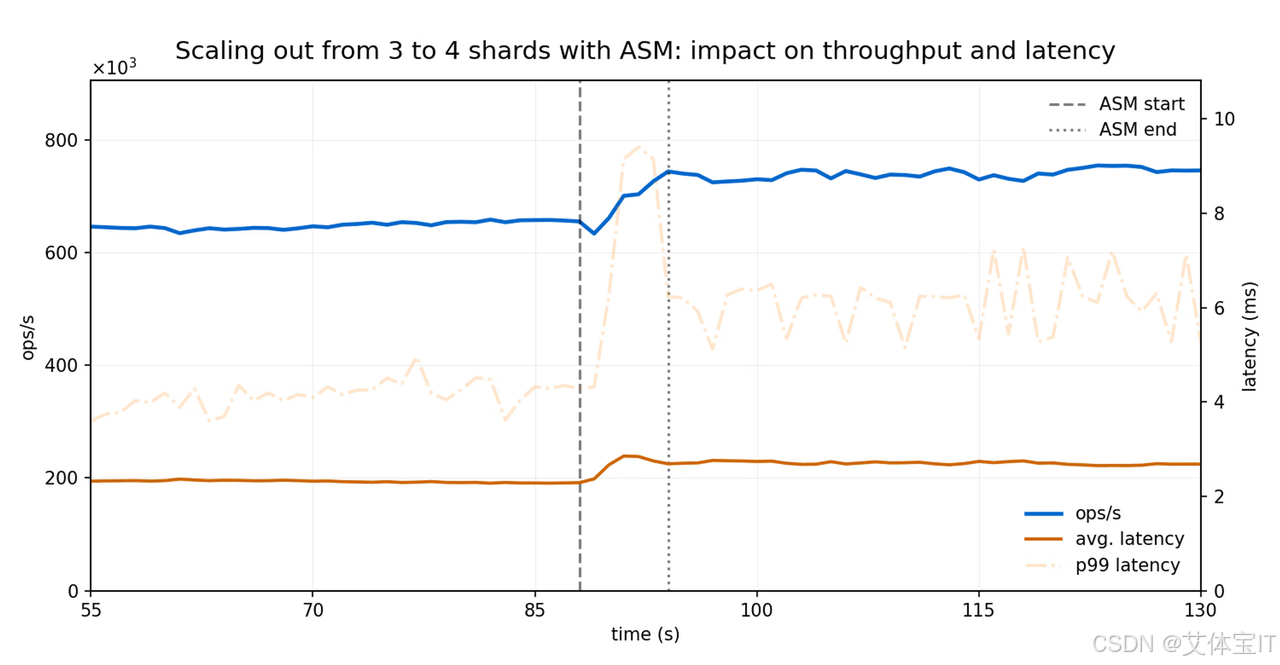
1. 迁移完成非常快
整个扩容迁移过程总耗时:
6.4 秒
具体分布为:
- 第 1 个 shard:0.9 秒
- 第 2 个 shard:2.7 秒
- 第 3 个 shard:2.8 秒
这意味着 Redis 可以在持续业务流量下,快速完成一轮相当规模的在线 Slot 重分布。
2. 吞吐量没有被迁移拖垮,反而很快体现扩容收益
随着 Slot 迁移完成,集群整体 ops/sec 持续提升,很快体现出新增 shard 带来的吞吐能力改善。
这说明:
扩容收益几乎可以在迁移完成后立即兑现,而不是先经历一轮明显的迁移期性能折损。
3. 延迟影响很轻,持续时间也很短
平均延迟只出现了短暂轻微波动:
- 持续约 2 秒
- 增幅 不到 5%
主要来自短时的 p99 tail latency 上扬。
这说明 ASM 在扩容场景下对线上流量的影响非常克制。
场景二:从 4 个 shard 缩容到 3 个 shard
官方也测试了另一个更敏感的场景:在线缩容。
在这个场景下,Redis Cluster 从 4 个节点缩减为 3 个节点,并使用 ASM 将第 4 个节点上的 Slot 迁移回剩余三个 shard。
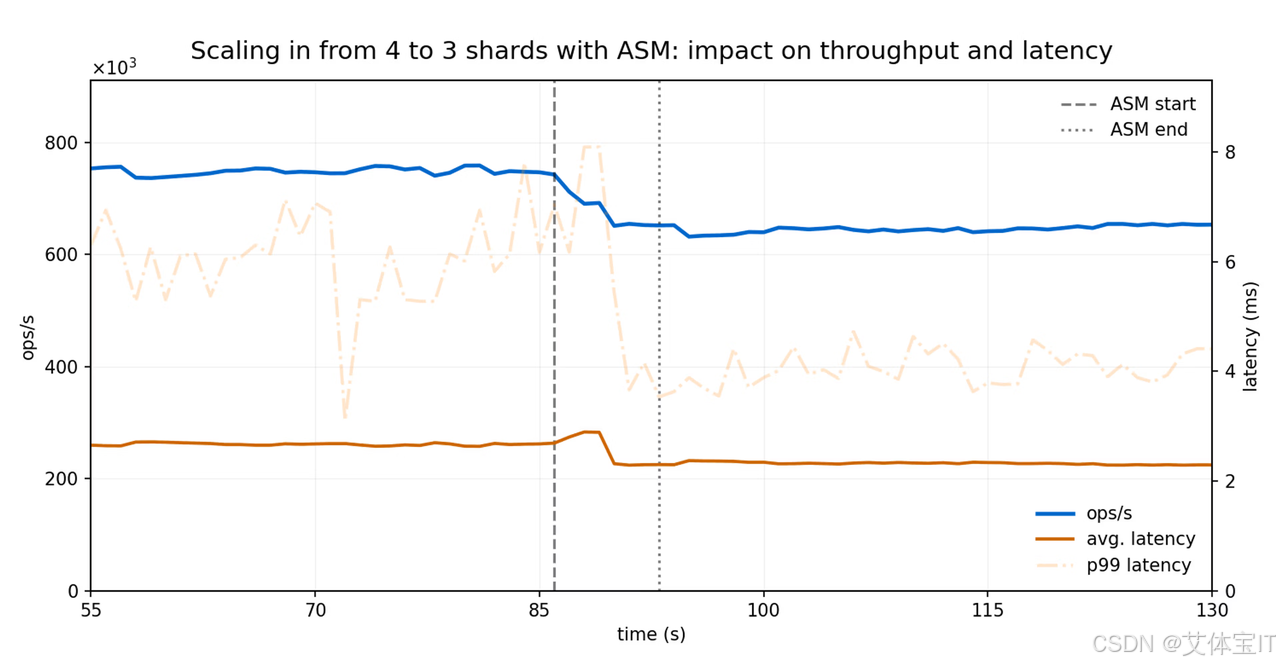
1. 总迁移耗时为 8.6 秒
三个目标 shard 的迁移时间分别为:
- 3.1 秒
- 2.8 秒
- 2.7 秒
这个耗时略高于扩容场景,也符合直觉:
因为缩容本质上是把一个节点上的数据"完整回收"进剩余节点,负载回灌更集中。
2. 吞吐变化主要来自节点数减少,而不是 ASM 本身
官方特别指出,缩容过程中看到的吞吐变化,主要是因为活跃节点数量变少,而不是 ASM 自身造成了显著额外开销。
这意味着 ASM 在迁移动作本身上的附加成本相对可控。
3. 延迟影响依然很小
延迟从:
- 2.3 ms
上升到:
- 2.8 ms
持续约 3 秒。
对大多数线上缓存业务而言,这仍然是一个相对温和的扰动水平。
ASM 相比传统 Slot 迁移,到底强在哪?
Redis 官方给出的结论很直接:
- 迁移速度最高可提升 30 倍
- 延迟尖峰最高可降低 73%
- 客户端重定向几乎可以忽略
- 集群内部状态消息开销显著下降
但如果从技术角度解读,这些结果真正说明的是:
ASM 的优势,不只是"更快",而是"迁移方式本身更合理"。
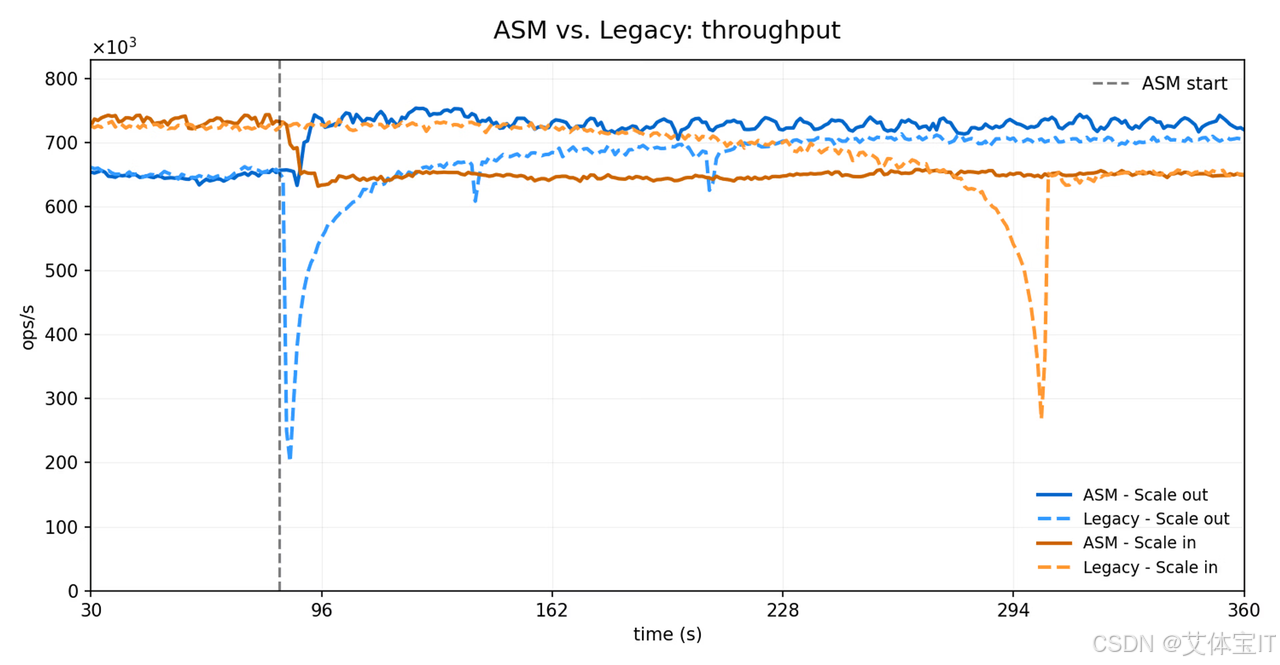
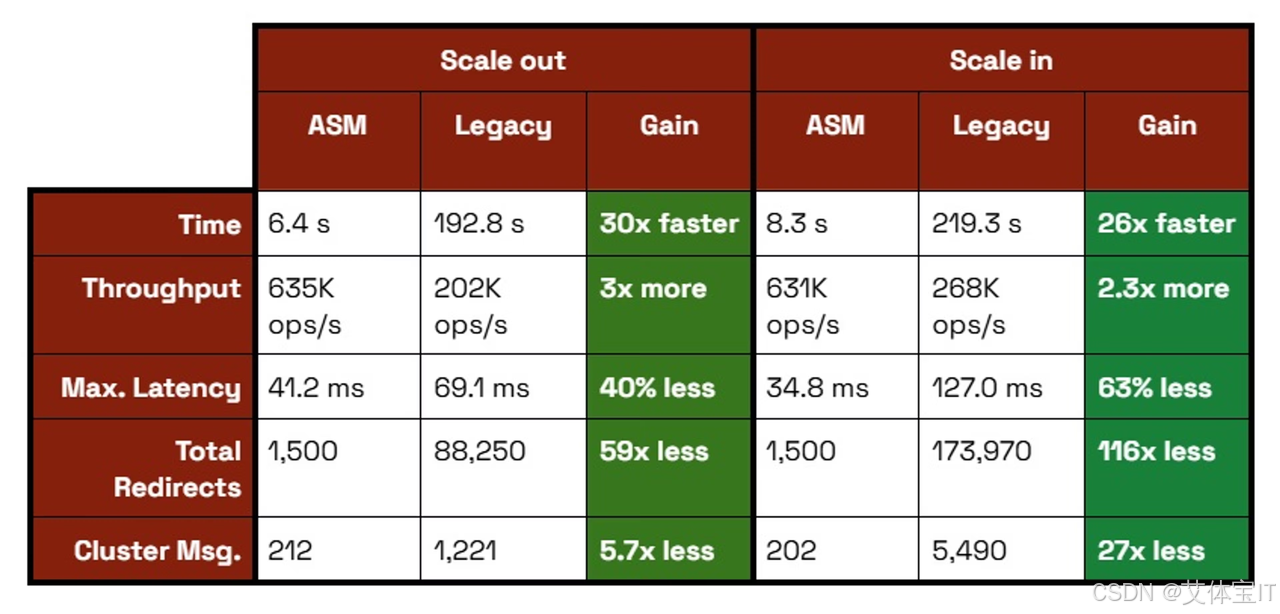
1. 更快:因为它不再是逐 Key 迁移
传统方式完成同类迁移,可能需要:
192~219 秒
而 ASM 在官方测试中通常只需要:
6~8 秒
也就是说,迁移效率可以从大约:
- 21 slots/sec
提升到:
- 640 slots/sec
这不是"调优"层面的提升,而是因为 ASM 避开了旧机制最昂贵的成本:
- 逐 Key 查找
- 逐 Key 搬迁
- 逐 Key 状态扰动
所以它快,不是因为"把旧方法写得更快",而是因为:
它换了一种更适合在线迁移的方法。
2. 更稳:因为客户端不再长期暴露在迁移中间态
这是 ASM 最重要、也最容易被低估的价值。
在旧机制下,迁移过程会不断暴露给客户端:
ASKTRYAGAIN- pipeline 中断
- 多 Key 语义不稳定
而 ASM 的设计,尽量把这些中间态"包在 Redis 内部"。
所以从客户端和业务角度看,迁移期间的体验更接近:
"系统内部在做重分布,但业务流量路径大部分时间保持稳定。"
这比"迁得快一点"更有生产价值。
3. 更平滑:因为它改善的是尾延迟,而不是只看平均值
很多线上系统在迁移时,并不是平均延迟不可接受,而是:
尾延迟突然飙高。
而真正伤害业务体验的,往往正是这些瞬时 spike。
ASM 的设计通过以下方式收敛了这类问题:
- 数据复制阶段尽量不干扰主请求路径
- 所有权切换窗口尽量缩短
- 旧数据清理尽量异步化
所以它改善的不是"实验室里的平均数",而是:
生产环境中更关键的服务质量连续性。
4. 更适合大规模生产集群
旧迁移方式在小规模集群、低频变更场景下勉强够用,但随着集群规模、数据规模、业务复杂度上升,其问题会越来越明显。
而 ASM 更适合下面这类环境:
- 集群节点较多
- 数据规模较大
- 扩缩容较频繁
- 热点负载明显
- 客户端链路复杂
- 对延迟抖动敏感
也就是说,ASM 并不是"锦上添花",而是 Redis Cluster 面向中大型生产环境的一次关键补强。
这项能力对实际生产运维意味着什么?
说到底,一个新特性值不值得关注,不取决于它名字有多新,而取决于它是否真的改变了日常运维体验。
从这个角度看,ASM 的价值非常实际。
1. 扩缩容终于更像真正的"在线操作"
过去很多团队虽然理论上支持 Redis Cluster 在线扩缩容,但实际操作时依然会非常谨慎,因为迁移过程本身会扰动业务。
ASM 不能让扩缩容变成"完全零成本",但它显著降低了这类操作的风险感和复杂度。
这会让 Redis Cluster 更接近我们对现代分布式系统的预期:
资源可以动态调整,而不是每次变更都像做一次风险操作。
2. 更适合做主动式负载治理
过去很多团队即使发现某个 shard 明显偏热,也不一定愿意频繁迁 Slot,因为迁移本身可能带来新的问题。
ASM 之后,这类操作更有可能从"被动止损"变成"主动优化"。
例如:
- 热点 Slot 分流
- 高内存 Slot 再均衡
- 高网络出流量 Slot 迁移
- 节点压力提前疏导
这会直接提升 Redis Cluster 的长期可运维性。
3. 客户端与业务侧可以少背一些历史复杂度
很多 Redis Cluster 客户端之所以实现复杂,很大程度上就是为了适配各种迁移中间态。
ASM 虽然不会让 Cluster 客户端完全"无感知",但它确实减少了:
- 迁移期特殊路径
- 重定向噪声
- pipeline 易碎性
- 多 Key 操作的不稳定窗口
这意味着整个系统的操作复杂度在下降,而不只是 Redis 服务端"性能更好"。
谁最应该关注 Redis 8.4 的 ASM?
如果你的 Redis 还停留在:
- 单实例
- 很小的集群
- 很少扩缩容
- 几乎不做在线再均衡
那么 ASM 对你的短期感知可能不会特别强。
但如果你符合下面任意一种情况,ASM 的价值会非常直接:
- Redis Cluster 节点规模较大
- 经常做扩容 / 缩容
- 线上负载不均比较常见
- 热点 Slot 或热点业务明显
- 对延迟抖动敏感
- 数据集较大,迁移窗口成本高
- 业务高峰长,难以安排低风险维护时间
这类场景下,ASM 不只是"值得看看"的新功能,而是:
很可能会直接提升你对 Redis Cluster 可运维性的整体评价。
写在最后:ASM 是 Redis Cluster 走向"更成熟在线运维"的标志性一步
Redis 8.4 的 Atomic Slot Migration,表面上看是一个集群特性增强,实际上它解决的是 Redis Cluster 长期以来一个非常现实的问题:
数据要迁,但业务最好别感知。
过去 Redis 在这件事上的答案是:
"可以迁,但过程不够优雅。"
而 ASM 给出的新答案是:
把迁移做成一种更接近复制切换的受控过程,让业务流量尽可能留在正常路径里。
这类升级真正重要的地方,不在于"多了多少命令",而在于它改善了 Redis Cluster 作为生产级分布式系统的工程完整性:
- 线上操作更稳
- 扩缩容更自然
- 再均衡更敢做
- 运维复杂度更低
- 客户端干扰更少
如果说 Redis 早期最擅长的是"单节点极致快",那么像 ASM 这样的能力正在说明一件事:
Redis 正在持续补齐它作为生产级分布式数据系统的运维成熟度。
而对于真正跑在生产环境里的 Redis Cluster 用户来说,这显然是一次非常值得欢迎的升级。
推荐阅读
如果你想继续深入了解 Redis 8.4 中 ASM 的实现细节,可以进一步关注:
CLUSTER MIGRATION新命令族CLUSTER SLOT-STATS在 Slot 级负载治理中的用法- Redis 8.0 引入的新复制机制如何被 ASM 复用
- ASM 在大 Key、热点 Slot 与高并发迁移场景中的实际收益