DM用户权限、表、约束等对象的基本操作
一、掌握 DM 模式对象
掌握 DM 模式对象:表;视 图;索引;约束;触发器;序列;同义词等的基本操作。
1.1 普通表(聚集索引表)
管理表
DM 普通表默认为聚簇索引表 ,除列存储表、堆表外,均采用 B 树结构存储数据。未手动指定聚簇索引时,系统默认以ROWID作为聚簇键;合理自定义聚簇索引,可大幅提升数据查询效率。
ROWID 是 B 树为记录(可以理解为某条数据)生成的逻辑递增序号,表上不同记录的 ROWID 是不一样的,即记录默认以 ROWID 在页面中排序,但业务极少通过 ROWID 检索数据,因此业务表需手动指定聚簇索引。
sql
-- 查看表的rowid
SELECT ROWID, t.* FROM "TEST_EXBASE"."STUDENT" t;DM 支持的表类型包括普通表、临时表、水平分区表、堆表和列存储表。
默认创建的都是聚簇B-tree索引表
sql
CREATE TABLE "TEST_EXBASE"."STUDENT"
(
"ID" NUMERIC(38,0) NOT NULL,
"NAME" VARCHAR(50 CHAR),
"AGE" NUMERIC(38,0),
"GENDER" VARCHAR(10 CHAR),
CONSTRAINT "STUDENT_PKEY" NOT CLUSTER PRIMARY KEY("ID")) ;
-- 查看表的定义
CALL SP_TABLEDEF('TEST_EXBASE', 'STUDENT');
CREATE TABLE "TEST_EXBASE"."STUDENT"
(
"ID" NUMERIC(38,0) NOT NULL,
"NAME" VARCHAR(50 CHAR),
"AGE" NUMERIC(38,0),
"GENDER" VARCHAR(10 CHAR),
CONSTRAINT "STUDENT_PKEY" NOT CLUSTER PRIMARY KEY("ID")) STORAGE(ON "MAIN", CLUSTERBTR) ;指定主键为聚簇索引键
- CLUSTER PRIMARY KEY:指定列为聚集索引键,并同时指定为主键,称为聚集主键;
- CLUSTER KEY:指定列为聚集索引键,但是是非唯一的;
- CLUSTER UNIQUE KEY:指定列为聚集索引键,并且是唯一的。
也可以在配置文件中修改参数PK_WITH_CLUSTER =1,会自动把表的主键当成聚簇索引建。
sql
CREATE TABLE STUDENT(
STUNO INT CLUSTER PRIMARY KEY,
STUNAME VARCHAR(15) NOT NULL,
TEANO INT,
CLASSID INT
);指定表的填充因子
每个普通表都含有一个聚集索引,即指定聚集索引的填充因子,填充因子用于控制聚集索引页数据填充占比,预留空间供数据更新使用,减少页拆分。填充因子过低,数据分页增多、查询性能下降;过高则更新易触发大量页拆分,消耗 CPU 与 IO。只读表建议高填充因子,高频更新表设置低值。DM 默认填充因子为 100,可按需调整。
查询建表
CTAB_SEL_WITH_CONS 参数
0 = 最小拷贝(默认),仅拷贝显式 NOT NULL 非主键列、自增列的非空属性
1 = 拷贝约束属性(不含索引,不支持 HUGE)
2 = 完整克隆(含索引 / 分区,同类型表之间)
sql
CREATE TABLE NEW_EMP
AS
SELECT * FROM EMPLOYEE;DM自支持增列
DM 支持 INT、BIGINT 和 DEC(n, 0)三种数据类型的 IDENTITY 自增列
- IDENT_CURRENT:获得表上自增列的当前值;
- IDENT_SEED:获得表上自增列的种子信息;
- IDENT_INCR:获得表上自增列的增量信息。
sql
CREATE TABLE IDENT_TABLE (
C1 INT IDENTITY(100, 100),
C2 INT
);
SELECT IDENT_CURRENT('SYSDBA.IDENT_TABLE');
SELECT IDENT_SEED('SYSDBA.IDENT_TABLE');
SELECT IDENT_INCR('SYSDBA.IDENT_TABLE');查看表空间使用情况
- TABLE_USED_SPACE:已分配给表的页面数;
- TABLE_USED_PAGES:表已使用的页面数;
- TABLE_FREE_PAGE_STACK_USED_SPACE:表空闲页堆栈拥有的页面数
sql
SELECT TABLE_USED_SPACE('SYSDBA','SPACE_TABLE');
SELECT TABLE_USED_PAGES('SYSDBA','SPACE_TABLE');
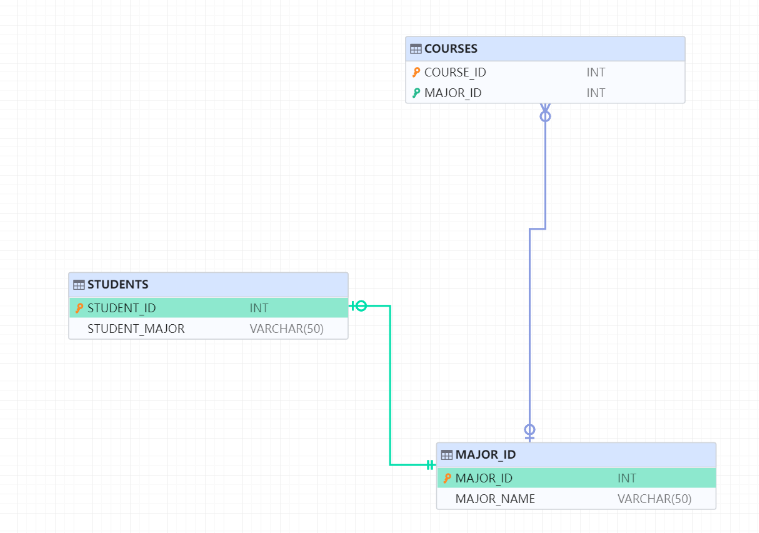
SELECT table_free_page_stack_used_space ('SYSDBA','SPACE_TABLE');现如今有三张表,表结构如下所示:
- MAJORS(专业表)
主键:MAJOR_ID
MAJOR_ID INT 主键 非空
MAJOR_NAME VARCHAR(50) - COURSES(课程表)
主键:COURSE_ID外键:MAJOR_ID 关联 MAJORS.MAJOR_ID
COURSE_ID INT 主键 非空
MAJOR_ID INT 外键 - STUDENTS(学生表)
主键:STUDENT_ID外键:STUDENT_MAJOR 关联 MAJORS.MAJOR_ID
STUDENT_ID INT 主键 非空
STUDENT_MAJOR INT 外键
使用图形化界面创建表
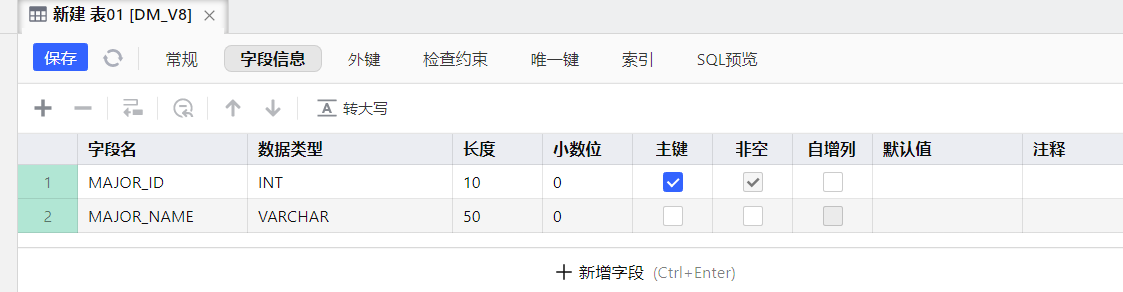
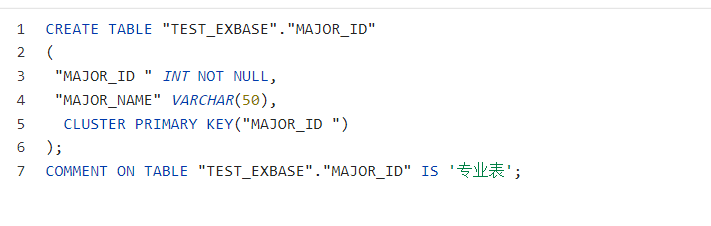
sql
CREATE TABLE "TEST_EXBASE"."MAJOR_ID"
(
"MAJOR_ID " INT NOT NULL,
"MAJOR_NAME" VARCHAR(50),
CLUSTER PRIMARY KEY("MAJOR_ID ")
);
COMMENT ON TABLE "TEST_EXBASE"."MAJOR_ID" IS '专业表';创建带有外键的表
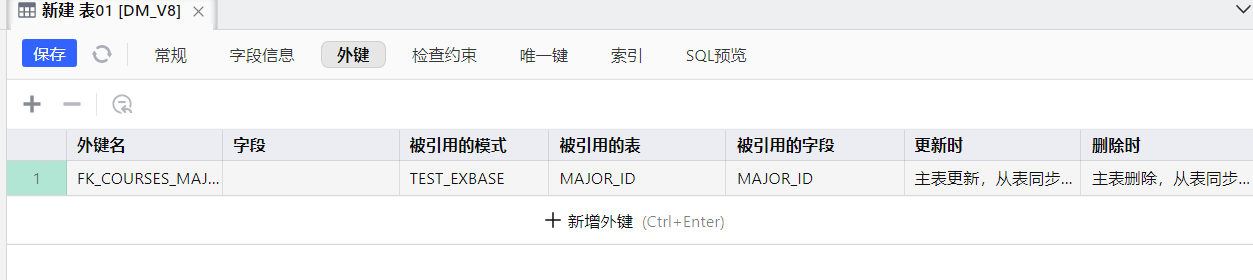
sql
CREATE TABLE "TEST_EXBASE"."COURSES"
(
"COURSE_ID" INT NOT NULL,
"MAJOR_ID" INT,
CLUSTER PRIMARY KEY("COURSE_ID"),
CONSTRAINT "FK_COURSES_MAJOR_ID" FOREIGN KEY("") REFERENCES "TEST_EXBASE"."MAJOR_ID"("MAJOR_ID ") ON UPDATE CASCADE ON DELETE CASCADE
);
COMMENT ON TABLE "TEST_EXBASE"."COURSES" IS '课程表';表三
sql
CREATE TABLE "TEST_EXBASE"."STUDENTS"
(
"STUDENT_ID" INT NOT NULL,
"STUDENT_MAJOR" VARCHAR(50),
CLUSTER PRIMARY KEY("STUDENT_ID"),
CONSTRAINT "FK_STUDENTS_MAJORS" FOREIGN KEY("STUDENT_ID") REFERENCES "TEST_EXBASE"."MAJOR_ID"("MAJOR_ID ")
);
COMMENT ON TABLE "TEST_EXBASE"."STUDENTS" IS '学生表';ER图(Entity-Relationship,关系-实体图)
1.2 视图
创建视图
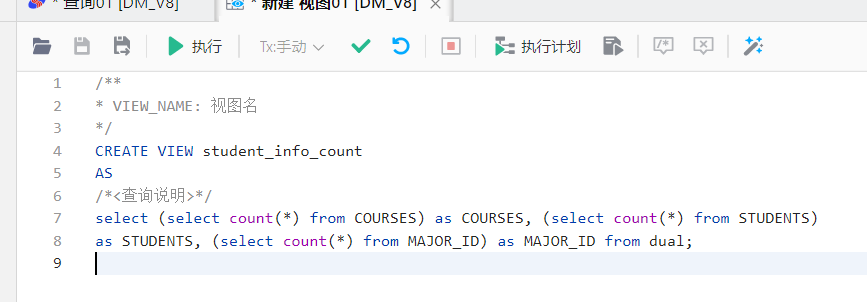
sql
/**
* VIEW_NAME: 视图名
*/
CREATE VIEW student_info_count
AS
/*<查询说明>*/
select (select count(*) from COURSES) as COURSES, (select count(*) from STUDENTS)
as STUDENTS, (select count(*) from MAJOR_ID) as MAJOR_ID from dual;获取这个试图实际的执行计划
bash
服务器 [192.168.157.140:5236]:处于普通打开状态
登录使用时间 : 3.763(ms)
disql V8
SQL> SET SCHEMA "TEST_EXBASE";
操作已执行
已用时间: 1.904(毫秒). 执行号:0.
SQL> SET DEFINE OFF;
SQL> SF_SET_SESSION_PARA_VALUE('MONITOR_SQL_EXEC',1);
DMSQL 过程已成功完成
已用时间: 0.655(毫秒). 执行号:9601.
SQL> SET AUTOTRACE TRACEONLY;
SQL> explain select * from STUDENT_INFO_COUNT;
1 NSET2:[1, 1, 1]
2 PIPE2:[1, 1, 1]
3 PIPE2:[1, 1, 1]
4 PIPE2:[1, 1, 1]
5 PRJT2:[1, 1, 1];exp_num(3), is_atom(FALSE); INFO_BITS(0)
6 CSCN2:[1, 1, 1];SYSINDEXSYSDUAL2(SYSDUAL2 as DUAL); btr_scan(1); need_slct(0)
7 SPL2:[1, 1, 0];key_num(1), spool_num(2), is_atom(TRUE), has_var(0), sites(-), result_cache(FALSE)
8 PRJT2:[1, 1, 0];exp_num(1), is_atom(TRUE); INFO_BITS(0)
9 FAGR2:[1, 1, 0];sfun_num(1)
10 SPL2:[1, 1, 0];key_num(1), spool_num(1), is_atom(TRUE), has_var(0), sites(-), result_cache(FALSE)
11 PRJT2:[1, 1, 0];exp_num(1), is_atom(TRUE); INFO_BITS(0)
12 FAGR2:[1, 1, 0];sfun_num(1)
13 SPL2:[1, 1, 0];key_num(1), spool_num(0), is_atom(TRUE), has_var(0), sites(-), result_cache(FALSE)
14 PRJT2:[1, 1, 0];exp_num(1), is_atom(TRUE); INFO_BITS(0)
15 FAGR2:[1, 1, 0];sfun_num(1)1.3 索引
概念
索引是为了快速检索和定位数据行而创建的一种数据结构,索引是由表中索引列数据进行排序后的集合和指向这些值的物理标识(例如:ROWID 等聚集索引键)共同组成。
DM的B树索引用的是 B+ 树结构进行存储。
B 树 :所有节点(叶子 + 非叶子)都存数据 + 索引键,查询快磁盘io高;
B + 树 :只有叶子节点存完整数据 ,非叶子节点只存索引键 + 路由指针,所有叶子节点双向链表串联 ,范围查询读写收敛性好。
从物理存储角度进行分类,可分为聚集索引和非聚集索引。
-
聚集索引(又称为一级索引、主索引):表数据存储在 B+ 树叶子节点上,通过定位索引可直接在 B+ 树中找到数据。每一个表有且只有一个聚集索引。
-
非聚集索引(又称为二级索引、辅助索引,就是普通索引):将
二级索引列和聚集索引列共同存储在 B+ 树叶子节点上。如果查找索引键值以外的数据,则需要回到一级索引中进行查找。每一个表可以有多个非聚集索引。
从索引功能角度进行分类,可分为唯一索引、函数索引、位图索引、位图连接索引、全文索引、数组索引、普通索引。
位图连接索引:针对两个或者多个表连接的位图索引,主要用于数据仓库中;
数组索引:在一个只包含单个数组成员的对象列上创建的索引;
建议:CLOB 和 TEXT 只能建立全文索引、BLOB 不能建立任何索引。
当建表语句未指定聚集索引键时,DM8 的默认聚集索引键是 ROWID。若指定索引键,表中数据都会根据指定索引键排序。
建表后,DM8 也可以用创建新聚集索引的方式来重建表数据,并按新的聚集索引排序。
sql
CREATE CLUSTER INDEX clu_emp_name ON emp(ename);创建位图索引:
位图索引主要针对含有大量相同值的列而创建,位图索引被广泛引用到数据仓库中,,对低基数(不同的值很少)的列创建位图索引,能够有效提高基于该列的查询效率。且执行查询语句的 where 子句中带有 AND 和 OR 谓词时,效率更加明显。
- 不支持在 UNIQUE 列和 PRIMARY KEY 上创建位图索引;
- 不支持对存在 CLUSTER KEY 的表创建位图索引;
- 包含位图索引的
表不支持并发的插入、删除和更新操作; - 不支持在间隔分区表上创建位图索引。
sql
CREATE BITMAP INDEX S1 ON PURCHASING.VENDOR (VENDORID);创建位图连接索引:
位图连接索引多用于数据仓库,专为多表关联查询优化;不同于单表位图索引,它基于多表关联创建,存储关联后的位图结果。针对索引列每个值,该索引会保存对应数据行 ROWID,大幅提升海量数据联查效率。
sql
CREATE BITMAP INDEX SALES_CUSTOMER_NAME_IDX
ON SALES.SALESORDER_HEADER(SALES.CUSTOMER.PERSONID)
FROM SALES.CUSTOMER, SALES.SALESORDER_HEADER
WHERE SALES.CUSTOMER.CUSTOMERID = SALES.SALESORDER_HEADER.CUSTOMERID;创建索引
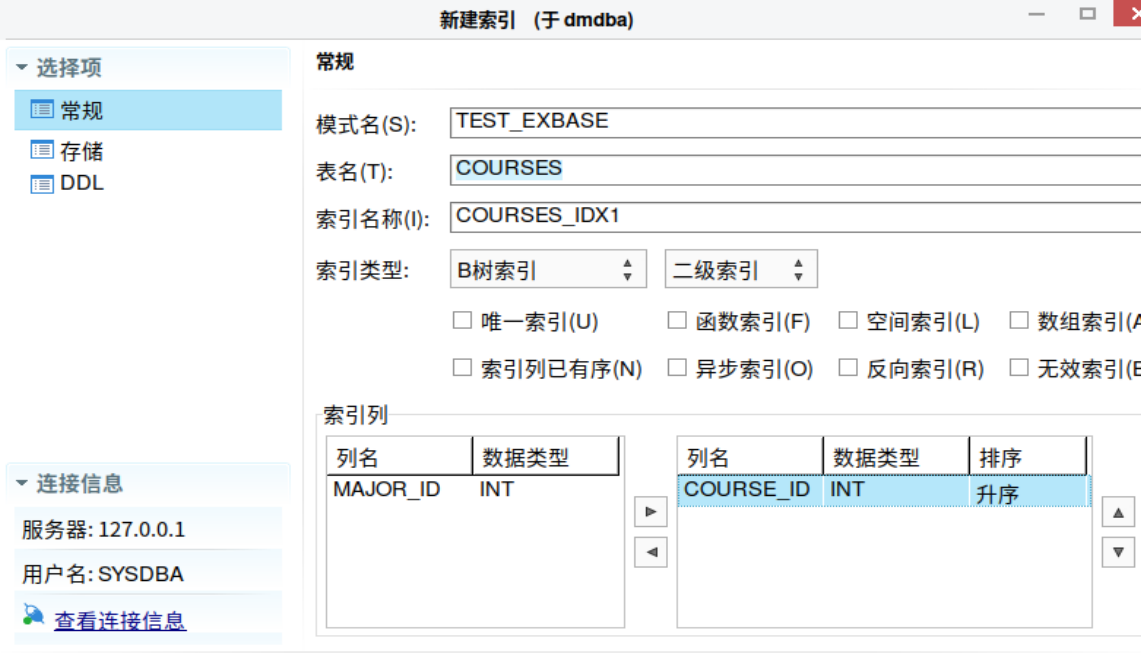
bash
create index "TEST_EXBASE".COURSES_IDX1 on TEST_EXBASE.COURSES("COURSE_ID") storage(initial 1,next 1,minextents 1);1.4 分区表
DM 支持对大表进行水平分区,一个表被分区后,对表的查询操作可以局限于某个分区进行,而不是整个表,这样可以大大提高查询速度。
主表本身不存储数据,所有数据只存储在子表中,从而实现不同分区的完全独立性。水平分区子表删除后,会将子表上的数据一起删除。可以将同一个表中的数据分布在不同的磁盘上,从而均衡磁盘上的 I/O 操作;
达梦 DM 支持表的水平分区,包含三类基础分区方式
范围分区:对表中的某些列上值的范围划分数据存储分区。
哈希分区:通过哈希散列均匀分发数据,平衡各分区存储与 I/O。
列表分区:通过指定表中的某个列的离散值集,来确定应当存储在一起的数据。例如,可以对表上的 status 列的值在('A','H','O')放在一个分区,值在('B','I','P')放在另一个分区,以此类推;
多级分区:将以上分区方式自由组合,实现多层复合分区。
范围分区,大多数使用时间字段作为分区列,时序数据库timescaledb借助超表、时间桶等技术实现了自动时间分区管理
sql
-- 以下语句创建一个范围分区表 callinfo,用来记录用户的 2010 年的电话通讯信息,包括主叫号码、被叫号码、通话时间和时长,并且根据季度进行分区。
CREATE TABLE callinfo(
caller CHAR(15),
callee CHAR(15),
time DATETIME,
duration INT
)
PARTITION BY RANGE(time)(
PARTITION p1 VALUES LESS THAN ('2010-04-01'),
PARTITION p2 VALUES LESS THAN ('2010-07-01'),
PARTITION p3 VALUES LESS THAN ('2010-10-01'),
PARTITION p4 VALUES EQU OR LESS THAN ('2010-12-31') //'2010-12-31'也可替换为MAXVALUE
);列表list分区
sql
-- 创建一个产品销售记录表 sales,记录产品的销量情况。由于产品只在几个固定的城市销售,所以可以按照销售城市对该表进行分区。
CREATE TABLE sales(
sales_id INT,
saleman CHAR(20),
saledate DATETIME,
city CHAR(10)
)
PARTITION BY LIST(city)(
PARTITION p1 VALUES ('北京', '天津'),
PARTITION p2 VALUES ('上海', '南京', '杭州'),
PARTITION p3 VALUES ('武汉', '长沙'),
PARTITION p4 VALUES ('广州', '深圳')
);哈希分区表
在很多情况下,用户无法预测某个列上的数据变化范围,因而无法实现创建固定数量的范围分区或 LIST 分区。
DM 哈希分区提供了一种在指定数量的分区中均等地划分数据的方法,基于分区键的散列值将行映射到分区中。当用户向表中写入数据时,数据库服务器将根据一个哈希函数对数据进行计算,把数据均匀地分布在各个分区中。在哈希分区中,用户无法预测数据将被写入哪个分区中。
sql
CREATE TABLE sales01(
sales_id INT,
saleman CHAR(20),
saledate DATETIME,
city CHAR(10)
)
PARTITION BY HASH(city)(
PARTITION p1,
PARTITION p2,
PARTITION p3,
PARTITION p4
);创建索引
sql
//其次,指定GLOBAL创建全局索引idx1
create index idx1 on t1(c2) GLOBAL;分区表维护
sql
-- 添加range分区
ALTER TABLE callinfo
ADD PARTITION p5 VALUES LESS THAN ('2011-4-1') STORAGE (ON ts5);
-- 添加list分区
ALTER TABLE sales
ADD PARTITION p5 VALUES ('拉萨', '呼和浩特') STORAGE (ON ts5);
-- 删除分区,注意:不能直接使用drop table名字去删除子表。
ALTER TABLE callinfo DROP PARTITION p5;1.5 列存储表
达梦表存储分为行存储 和列存储:
- 行存储:以整条记录为单位存储,数据页存放多条完整记录。
- 列存储:以列为单位存储,同一列的所有行数据集中存放。
列存储是以列为单位进行存储的,每一个列的所有行数据都存储在一起,而且一个指定的页面中存储的都是某一个列的连续数据。
列存储表(也称为 HUGE 表),下图为基表使用列存、行存在页的图片。
| NAME 列 | ID 列 |
|---|---|
| SYSCLASSES | 268435457 |
| SYSCOLUMNS | 268435458 |
| SYSCONS | 268435459 |
| SYSDUAL | 268435460 |
| SYSGRANTS | 268435461 |

HUGE 表是建立在混合表空间上的,一个混合表空间最多可以添加 127 个 HUGE 数据文件路径,使用V$HUGE_TABLESPACE 动态视图查看。
普通的表空间,数据是通过段、簇、页 来管理的,并且以固定大小(4KB、8KB、16KB、32KB)的页面为管理单位;而混合表空间存储 HUGE 表是通过 HFS (Huge File System,针对海量数据进行分析的一种高效、简单的列存储机制)存储机制来管理的,它相当于一个文件系统。
为混合表空间指定一个 HUGE 数据文件路径,其实就是创建一个空的 HUGE 数据文件目录。
系统中有一个默认的混合表空间 MAIN,其 HUGE 数据文件目录名为 HMAIN
bash
[dmdba@localhost DAMENG]$ pwd
/dmdata/data/DAMENG
[dmdba@localhost DAMENG]$ ll | grep HM
drwxr-xr-x 2 dmdba dmdba 6 4月 22 15:11 HMAIN在创建一个 HUGE 表并插入数据时,数据库会在指定的混合表空间的 HUGE 数据文件目录下创建一系列的目录及文件。
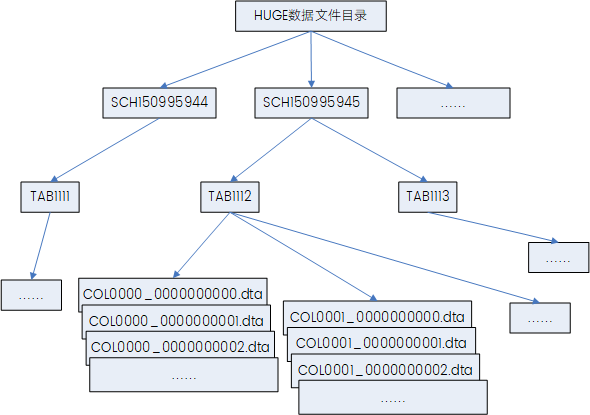
达梦 HUGE 表在 HUGE 数据目录下创建,分三层存储结构与管理规则:
- 创建模式目录 :命名为
SCH+9位ID,目录已存在则复用。 - 创建表目录 :命名为
TAB+4位ID,存放该表所有数据文件。 - 生成列数据文件 :每列对应一个
.dta文件,默认大小 64MB;文件名格式为COL+4位列号_10位文件号,数据量溢出时自动新建文件扩容。 - 文件内部按区管理 :区是 HUGE 文件最小管理单位;单区存储行数建表时指定且不可修改,定长数据区大小固定、变长数据区大小不一,各区起始位置和长度均按 4KB 对齐。
sql
CREATE HUGE TABLE test(name VARCHAR, sno INT) COMPRESS LEVEL 1 (sno);
-- 创建非事务型的huge表
CREATE HUGE TABLE T1 (A INT, B INT) STORAGE(WITHOUT DELTA);1.6 堆表
PostgreSQL数据库默认创建的表就是堆表,在DM数据库中普通表都是以 B 树形式存放的,ROWID 都是逻辑 的 ROWID,即从 1 一直增长下去。在并发情况下,每次插入过程中都需要逻辑生成 ROWID,这样影响了插入数据的效率 ;对于每一条数据都需要存储 ROWID 值,也会花费较大的存储空间。堆表就是基于上述两个理由而提出的。
堆表是指采用了物理 ROWID 形式的表,即使用文件号、页号和页内偏移而得到 ROWID 值,提高了效率,这样就不需要存储 ROWID 值,可以节省空间。
普通表都是以 B 树形式存储在物理磁盘上,而堆表则采用一种"扁平 B 树"方式存储,结构如下图所示。
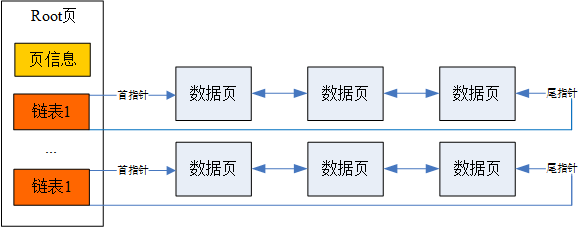
"扁平 B 树",数据页都是通过链表形式存储,扁平 B 树最多支持128 条数据页链表,分为 64 个并发分支、64 个非并发分支,由控制页记录各链表首尾页地址。
非并发分支按事务 ID 随机选链表插入;并发分支用户优先占用不同分支,仅同分支时需等待锁释放。
通过多链表分支隔离写入,大幅提升堆表并发插入性能。
在INI 参数中添加 LIST_TABLE 参数,LIST_TABLE = 1,默认为堆表,LIST_TABLE = 0默认为聚集索引表(索引组织表)。
sql
-- 创建堆表,并发分支 2 个,非并发分支 4 个
CREATE TABLE LIST_TABLE(C1 INT) STORAGE(BRANCH (2,4));堆表优缺点:
-
堆表扫描天然优势:通过 ROWID 可直接解析出文件号、页号、页内偏移,快速定位数据行。
-
建议在高频查询列上建二级索引,先通过索引查到 ROWID,再直接定位数据,大幅提升查询效率。
-
DM 服务器暂时不支持堆表的列存储。
-
如果用户需要借助聚集索引主键对数据进行排序则不推荐使用堆表。
1.7 触发器
达梦具备主动特性 ,由约束机制 和触发器机制实现;约束校验列数据有效性与完整性,触发器在数据库事件触发时自动执行预设操作。
触发器是特殊存储过程,存储模块需手动调用,触发器由事件自动隐式触发。
触发器是触发语句的组成部分:触发器执行完毕,原语句才算结束;触发器执行失败会导致原语句回滚。
列举的案例功能:
- 利用触发器实现表约束机制(如:PRIMARY KEY、FOREIGN KEY、CHECK 等)无法实现的复杂的引用完整性;
- 利用触发器实现复杂的事务规则(如:想确保薪水增加量不超过 25%);
- 利用触发器防止非法的操作。
DM 提供了三种类型的触发器:
- 表级触发器:基于表中的数据进行触发;
- 事件触发器:基于特定系统事件进行触发;
- 时间触发器:基于时间而进行触发。
sql
CREATE OR REPLACE TRIGGER DEL_TRG
BEFORE DELETE
ON emp
BEGIN
PRINT '您正在对表emp进行删除操作';
END;
/
SQL> DELETE FROM EMP;
您正在对表EMP进行删除操作
-- 案例,比如:想确保薪水增加量不超过 25%
CREATE TABLE EMP (
EMPNO INT PRIMARY KEY,
ENAME VARCHAR(20),
SALARY NUMBER(8,2)
);
INSERT INTO EMP VALUES (1,'张三',10000.00);
INSERT INTO EMP VALUES (2,'李四',8000.00);
COMMIT;
CREATE OR REPLACE TRIGGER TRI_CHECK_SAL_RISE
BEFORE UPDATE ON EMP
FOR EACH ROW
DECLARE
v_ratio NUMBER(6,4);
BEGIN
-- 只处理涨薪场景,降薪不限制
IF :NEW.SALARY > :OLD.SALARY THEN
-- 计算涨幅比例
v_ratio := (:NEW.SALARY - :OLD.SALARY) / :OLD.SALARY;
-- 超过25%抛异常,终止并回滚
IF v_ratio > 0.25 THEN
RAISE_APPLICATION_ERROR(-20001, '错误:薪水涨幅不能超过25%');
END IF;
END IF;
END;
/
-- 测试1
UPDATE EMP SET SALARY=12500 WHERE EMPNO=1;
COMMIT;
-- 执行成功,可查询验证
SELECT EMPNO,ENAME,SALARY FROM EMP;
-- 测试2
UPDATE EMP SET SALARY=15750 WHERE EMPNO=1;
[-20001]:错误:薪水涨幅不能超过25%
-20001: TRI_CHECK_SAL_RISE line 14 事件触发器
可以触发的事件包含以下两类:
- DDL 事件,包括 CREATE、ALTER、DROP、GRANT、REVOKE 以及 TRUNCATE;
- 系统事件,包括 LOGIN/LOGON、LOGOUT/LOGOFF、AUDIT、NOAUDIT、BACKUP DATABASE、RESTORE DATABASE、TIMER、STARTUP、SHUTDOWN 以及 SERERR(即执行错误事件)。
与数据触发器不同,事件触发器不能影响对应触发事件的执行。它的主要作用是帮助管理员监控系统运行发生的各类事件,进行一定程度的审计和监视工作。某些国产数据库,是通过实践触发器来完成数据库的DDL语句同步的。
时间触发器
时间触发器实用性很强,如在凌晨(此时服务器的负荷比较轻)做一些数据的备份操作,对数据库中表的统计信息的更新操作等类似的事情。同时也可以作为定时器通知一些用户在未来的某些时间要做哪些事情。
1.8 序列、同义词
序列是一个数据库对象,可以让不同用户获取不重复的序列值,主流关系型数据库都有涉及。
同义词
同义词(Synonym)让用户能够为数据库的一个模式下的对象提供别名。
实际的应用场景上,可以使用同义词完成跨模式访问。
sql
-- 创建同义词
CREATE SYNONYM "TEST_EXBASE"."DM_TABLES" FOR "SYS"."ALL_ALL_TABLES";
select count(*) from DM_TABLES;
-- 删除同义词
DROP SYNONYM "TEST_EXBASE"."DM_TABLES"1.9 查看用户、表、索引的使用情况
sql
-- 可以使用系统函数 USER_USED_SPACE 得到用户占用空间的大小,可以理解为模式
SELECT USER_USED_SPACE('TEST_USER');
-- 可以使用系统函数 TABLE_USED_SPACE 得到表对象占用空间的大小
SELECT TABLE_USED_SPACE('SYSDBA', 'TEST');
-- 可以使用系统函数 INDEX_USED_SPACE 得到索引占用空间的大小
SELECT INDEX_USED_SPACE(33555463);
-- 可以使用系统函数 INDEX_USED_PAGES 得到索引实际使用页的数目
SELECT INDEX_USED_PAGES(33555463);
-- 重建索引,当一个表经过大量的增删改操作后,表的数据在物理文件中可能存在大量碎片,从而影响访问速度。另外,当删除表的大量数据后,若不再对表执行插入操作,索引所处的段可能占用了大量并不使用的簇,从而浪费了存储空间。
SP_REBUILD_INDEX('SYSDBA', 1547892);二、掌握 DM 非模式对象
2.1 用户
sql
-- 1. 创建用户 TETS
CREATE USER TETS IDENTIFIED BY "test@2026"
PASSWORD_POLICY READONLY
LIMIT GLOBAL_SESSION_PER_USER 1000, FAILED_LOGIN_ATTEMPTS 5
DEFAULT TABLESPACE "ROLL";
-- 2. 授予角色 PUBLIC 和 SOI
GRANT "PUBLIC", "SOI" TO TETS;
-- 3. 授予查询权限
GRANT SELECT ANY TABLE, SELECT ANY VIEW TO TETS;2.2 表空间
创建表空间
sql
-- 常规数据文件SQL预览
CREATE TABLESPACE "MAIN" DATAFILE '/dmdata/data/DAMENG/MAIN.DBF' SIZE 128 AUTOEXTEND ON MAXSIZE 67108863(最大可以达到的容量67TB,生产环境上一定要限制一下) CACHE = NORMAL;
-- 创建表空间
CREATE TABLESPACE "TEST" DATAFILE '/dmdata/data/DAMENG/TEST1.DBF' SIZE 128 AUTOEXTEND ON MAXSIZE 67108863 CACHE = NORMAL;
-- 创建表空间包含多个文件
CREATE TABLESPACE "TEST" DATAFILE '/dmdata/data/DAMENG/TEST1.DBF' SIZE 128 AUTOEXTEND ON NEXT 64 MAXSIZE 67108863,'/dmdata/data/DAMENG/TEST2.DBF' SIZE 128 AUTOEXTEND ON NEXT 64 MAXSIZE 67108863,'/dmdata/data/DAMENG/TEST3.DBF' SIZE 128 AUTOEXTEND ON NEXT 64 MAXSIZE 1280 CACHE = NORMAL;
-- 给表空间添加文件
ALTER TABLESPACE "TEST" ADD DATAFILE '/dmdata/data/DAMENG/TEST3.DBF' size 128 autoextend on next 64 maxsize 1280;
-- 删除表空间
drop TABLESPACE "TEST";2.3SQL日志的开启和关闭
跟踪日志内容包含系统各会话执行的 SQL 语句、参数信息、错误信息、执行时间等。跟踪日志主要用于分析错误和分析性能问题。
跟踪日志记录配置
配置 dm.ini 文件,设置 SVR_LOG = 1 以启用 sqllog.ini 配置,或者调用存储过程
sql
SP_SET_PARA_VALUE(1,'SVR_LOG',1);
--查询v$dm_ini
select * from v$dm_ini where para_name LIKE 'SVR_LOG%'配置数据文件目录下的 sqllog.ini 文件
ini
BUF_TOTAL_SIZE = 10240 #SQLs Log Buffer Total Size(K)(1024~1024000)
BUF_SIZE = 1024 #SQLs Log Buffer Size(K)(50~409600)
BUF_KEEP_CNT = 6 #SQLs Log buffer keeped count(1~100)
[SLOG_ALL]
FILE_PATH = ../log
PART_STOR = 0
SWITCH_MODE = 1
SWITCH_LIMIT = 100000
ASYNC_FLUSH = 0
FILE_NUM = 200
ITEMS = 1:4:8 #记录执行时间,用户,客户端ip
SQL_TRACE_MASK = 2:7 #全部 DML 类型语句,SELECT 类型语句
MIN_EXEC_TIME = 0 #详细模式下,记录的最小语句执行时间,单位为毫秒。执行时间小于该值的语句不记录在日志文件中。
USER_MODE = 0
USERS =可以调用存储过程,无需重启数据库
sql
SP_REFRESH_SVR_LOG_CONFIG();可以看到采集到的信息
txt
[dmdba@localhost log]$ tail -f dmsql_DMSERVER_20260429_154915.log
2026-04-29 16:01:12.411 (EP[0] sess:0x7f3ae47b5020 thrd:187382 user:SYSDBA trxid:0 stmt:NULL appname:SQLark Client ip:::ffff:192.168.157.1) [LGN] FREE SESSION
2026-04-29 16:01:12.411 (EP[0] sess:0x7f3adbef2210 thrd:187388 user:SYSDBA trxid:0 stmt:NULL appname:SQLark Client ip:::ffff:192.168.157.1) [LGN] FREE SESSION关闭SQL日志
sql
SP_SET_PARA_VALUE(1,'SVR_LOG',0);