
🎁个人主页:小张同学824
🎉欢迎大家点赞👍评论📝收藏⭐文章


文章目录:
- RAG检索增强生成实战:让智能体拥有企业级专属知识库,从文档处理到语义检索全流程解析
-
- 一、为什么Agent需要RAG?
-
- [LLM知识 vs RAG知识对比](#LLM知识 vs RAG知识对比)
- 二、RAG系统核心组件
-
- [2.1 文档处理Pipeline](#2.1 文档处理Pipeline)
- [2.2 向量索引构建](#2.2 向量索引构建)
- 三、构建RAG增强的Agent
-
- [3.1 RAG Agent完整实现](#3.1 RAG Agent完整实现)
- [3.2 高级检索策略](#3.2 高级检索策略)
- 四、Embedding模型选择指南
- 五、评估RAG系统质量
-
- [5.1 RAGAS评估框架](#5.1 RAGAS评估框架)
- [5.2 评估指标速查表](#5.2 评估指标速查表)
- 六、RAG优化技巧汇总
- 总结
RAG检索增强生成实战:让智能体拥有企业级专属知识库,从文档处理到语义检索全流程解析
不懂你公司业务的AI不是好Agent。RAG(检索增强生成)是让Agent真正"懂行"的关键技术。
一、为什么Agent需要RAG?
LLM的知识来自训练数据,存在时效性差、缺乏私有知识、幻觉问题三大短板。RAG通过实时检索外部知识库来弥补这些不足。
LLM知识 vs RAG知识对比
| 维度 | 纯LLM | LLM + RAG |
|---|---|---|
| 知识时效性 | 训练截止日期前 | 实时更新 |
| 私有数据 | 无法访问 | 安全集成 |
| 准确性 | 存在幻觉 | 基于事实文档 |
| 可溯源性 | 无法验证 | 引用来源 |
| 更新成本 | 重新训练 | 增量更新文档 |
| 法律合规 | 黑盒 | 可控可审计 |
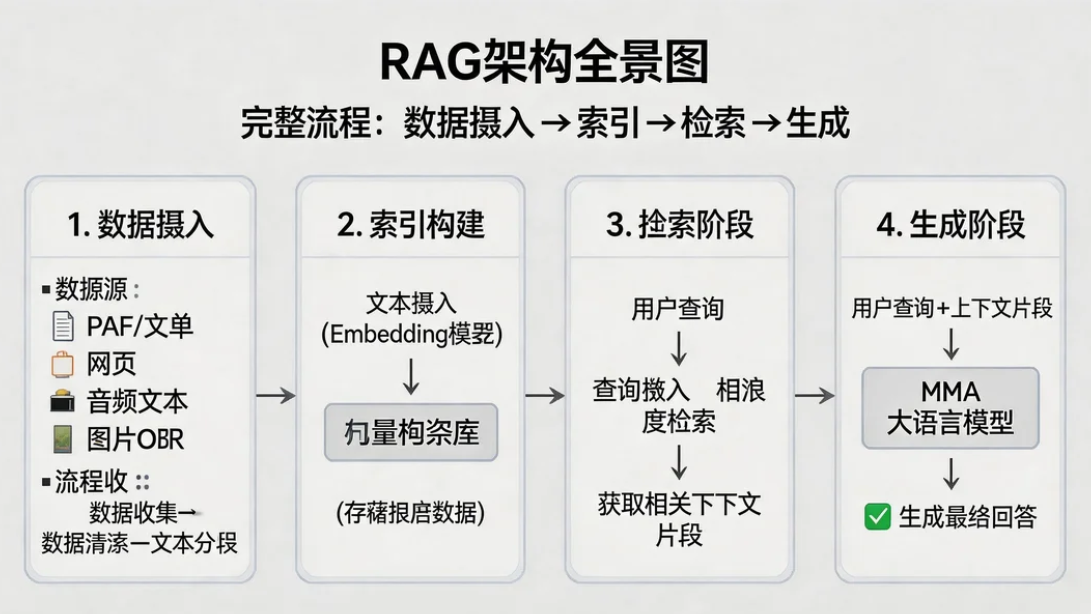
二、RAG系统核心组件
2.1 文档处理Pipeline
python
# rag/document_processor.py
from typing import List
from dataclasses import dataclass
import re
@dataclass
class Document:
content: str
metadata: dict
doc_id: str = ""
class DocumentProcessor:
"""文档处理Pipeline"""
def __init__(self, chunk_size: int = 500, chunk_overlap: int = 50):
self.chunk_size = chunk_size
self.chunk_overlap = chunk_overlap
def process_file(self, file_path: str) -> List[Document]:
"""处理单个文件,返回分块后的文档列表"""
# 支持多种文件格式
if file_path.endswith('.md'):
text = self._read_markdown(file_path)
elif file_path.endswith('.txt'):
text = self._read_text(file_path)
elif file_path.endswith('.pdf'):
text = self._read_pdf(file_path)
else:
raise ValueError(f"不支持的文件格式: {file_path}")
# 文本清洗
text = self._clean_text(text)
# 语义分块
chunks = self._semantic_chunk(text)
# 创建文档对象
documents = []
for i, chunk in enumerate(chunks):
doc = Document(
content=chunk,
metadata={
"source": file_path,
"chunk_index": i,
"total_chunks": len(chunks)
}
)
documents.append(doc)
return documents
def _clean_text(self, text: str) -> str:
"""文本清洗"""
text = re.sub(r'\n{3,}', '\n\n', text)
text = re.sub(r'[ \t]+', ' ', text)
return text.strip()
def _semantic_chunk(self, text: str) -> List[str]:
"""基于语义的分块策略"""
# 先按段落分割
paragraphs = text.split('\n\n')
chunks = []
current_chunk = ""
for para in paragraphs:
# 如果单个段落就超长,按句子再分
if len(para) > self.chunk_size:
sentences = re.split(r'[。!?.!?]', para)
for sentence in sentences:
if len(current_chunk) + len(sentence) > self.chunk_size:
if current_chunk:
chunks.append(current_chunk.strip())
current_chunk = sentence
else:
current_chunk += sentence
else:
if len(current_chunk) + len(para) > self.chunk_size:
chunks.append(current_chunk.strip())
current_chunk = para
else:
current_chunk += "\n\n" + para
if current_chunk:
chunks.append(current_chunk.strip())
return chunks
def _read_markdown(self, path: str) -> str:
with open(path, 'r', encoding='utf-8') as f:
return f.read()
def _read_text(self, path: str) -> str:
with open(path, 'r', encoding='utf-8') as f:
return f.read()
def _read_pdf(self, path: str) -> str:
# 需要安装 PyPDF2 或 pdfplumber
import pdfplumber
text = ""
with pdfplumber.open(path) as pdf:
for page in pdf.pages:
text += page.extract_text() or ""
return text2.2 向量索引构建
python
# rag/vector_store.py
import chromadb
from chromadb.utils import embedding_functions
from typing import List, Optional
import uuid
class VectorStore:
"""向量存储与检索"""
def __init__(self, persist_dir: str = "./rag_db"):
self.client = chromadb.PersistentClient(path=persist_dir)
self.embed_fn = embedding_functions.DefaultEmbeddingFunction()
self.collection = None
def create_index(self, documents: List[Document],
collection_name: str = "knowledge_base"):
"""创建向量索引"""
self.collection = self.client.get_or_create_collection(
name=collection_name,
metadata={"hnsw:space": "cosine"}
)
ids = [str(uuid.uuid4()) for _ in documents]
texts = [doc.content for doc in documents]
metadatas = [doc.metadata for doc in documents]
# 批量添加
batch_size = 100
for i in range(0, len(texts), batch_size):
self.collection.add(
documents=texts[i:i+batch_size],
metadatas=metadatas[i:i+batch_size],
ids=ids[i:i+batch_size]
)
print(f"✅ 已索引 {len(documents)} 个文档块")
def search(self, query: str, top_k: int = 5,
filter_metadata: Optional[dict] = None) -> List[dict]:
"""语义检索"""
results = self.collection.query(
query_texts=[query],
n_results=top_k,
where=filter_metadata
)
retrieved = []
for doc, meta, distance in zip(
results["documents"][0],
results["metadatas"][0],
results["distances"][0]
):
retrieved.append({
"content": doc,
"metadata": meta,
"score": 1 - distance
})
return retrieved
三、构建RAG增强的Agent
3.1 RAG Agent完整实现
python
# rag/rag_agent.py
from openai import OpenAI
from typing import List, Optional
class RAGAgent:
"""RAG增强的AI Agent"""
SYSTEM_PROMPT = """你是一个拥有专业知识库的AI助手。
回答问题时请遵循以下规则:
1. 优先基于检索到的知识库内容回答
2. 在回答中标注信息来源 [来源: 文件名]
3. 如果知识库中没有相关信息,明确告知用户
4. 不要编造不存在的信息
5. 回答要准确、详细、有条理"""
def __init__(self, api_key: str, vector_store: VectorStore):
self.llm = OpenAI(api_key=api_key)
self.vector_store = vector_store
self.conversation_history = []
def chat(self, user_message: str, top_k: int = 5) -> str:
# 步骤1:检索相关文档
search_results = self.vector_store.search(user_message, top_k=top_k)
# 步骤2:构建上下文
context = self._build_context(search_results)
# 步骤3:构建消息
messages = [
{"role": "system", "content": self.SYSTEM_PROMPT},
]
# 添加上下文
if context:
messages.append({
"role": "system",
"content": f"[知识库检索结果]\n{context}"
})
# 添加对话历史
messages.extend(self.conversation_history[-6:]) # 最近3轮对话
# 添加当前问题
messages.append({"role": "user", "content": user_message})
# 步骤4:调用LLM生成回答
response = self.llm.chat.completions.create(
model="gpt-4o",
messages=messages,
temperature=0.3 # 较低的温度保证准确性
)
answer = response.choices[0].message.content
# 更新对话历史
self.conversation_history.append({"role": "user", "content": user_message})
self.conversation_history.append({"role": "assistant", "content": answer})
return answer
def _build_context(self, results: List[dict]) -> str:
context_parts = []
for i, result in enumerate(results, 1):
source = result["metadata"].get("source", "未知来源")
score = result["score"]
content = result["content"]
context_parts.append(
f"[文档{i}] (来源: {source}, 相关度: {score:.2%})\n{content}"
)
return "\n\n---\n\n".join(context_parts)3.2 高级检索策略
python
# rag/advanced_retrieval.py
class AdvancedRAGAgent(RAGAgent):
"""带高级检索策略的RAG Agent"""
def chat(self, user_message: str) -> str:
# 策略1:查询改写 - 优化用户查询
rewritten_query = self._rewrite_query(user_message)
# 策略2:多路召回
results = []
# 语义检索
results.extend(self.vector_store.search(rewritten_query, top_k=3))
# 关键词检索(可以并行)
results.extend(self._keyword_search(user_message, top_k=3))
# 策略3:重排序
reranked = self._rerank(user_message, results)
# 策略4:构建上下文并生成
context = self._build_context(reranked[:5])
return self._generate(user_message, context)
def _rewrite_query(self, query: str) -> str:
"""使用LLM改写查询"""
prompt = f"""将以下用户查询改写为更适合检索的形式:
原始查询:{query}
要求:
1. 提取核心关键词
2. 补充隐含的上下文
3. 使用更精确的术语
4. 生成2-3个变体查询
输出格式(每行一个):
- 改写查询1
- 改写查询2
- 改写查询3"""
response = self.llm.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": prompt}],
temperature=0.3
)
return response.choices[0].message.content
def _rerank(self, query: str, results: List[dict]) -> List[dict]:
"""使用LLM对检索结果重新排序"""
if not results:
return results
docs_text = "\n".join([
f"[{i}] {r['content'][:200]}"
for i, r in enumerate(results)
])
prompt = f"""根据查询的相关性对以下文档重新排序:
查询: {query}
文档:
{docs_text}
返回排序后的文档编号(从最相关到最不相关),格式: [0, 3, 1, 2]"""
response = self.llm.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": prompt}],
temperature=0
)
import json, re
try:
order = json.loads(re.search(r'\[.*\]', response.choices[0].message.content).group())
return [results[i] for i in order if i < len(results)]
except:
return results # 排序失败则返回原始顺序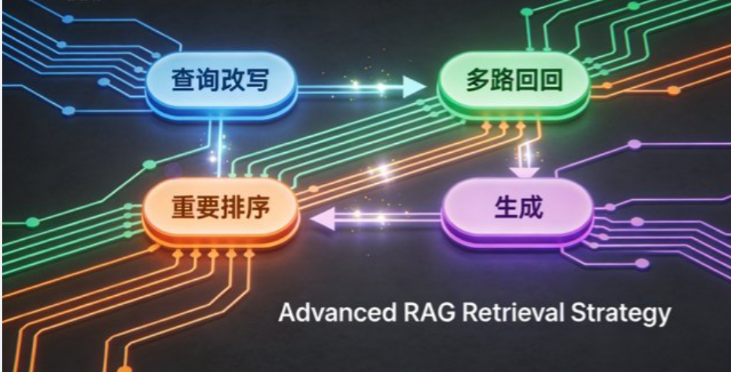
四、Embedding模型选择指南
| 模型 | 维度 | 性能(MTEB) | 速度 | 中文支持 | 成本 |
|---|---|---|---|---|---|
| OpenAI text-embedding-3-large | 3072 | ⭐⭐⭐⭐⭐ | 快 | 良好 | $0.13/1M tokens |
| OpenAI text-embedding-3-small | 1536 | ⭐⭐⭐⭐ | 很快 | 良好 | $0.02/1M tokens |
| BGE-large-zh-v1.5 | 1024 | ⭐⭐⭐⭐⭐ | 快 | 极好 | 免费 |
| M3E-large | 1024 | ⭐⭐⭐⭐ | 快 | 极好 | 免费 |
| Cohere embed-v3 | 1024 | ⭐⭐⭐⭐⭐ | 快 | 良好 | $0.10/1M tokens |
| GTE-Qwen2 | 1536 | ⭐⭐⭐⭐⭐ | 中 | 极好 | 免费 |
各场景推荐
| 场景 | 推荐模型 | 理由 |
|---|---|---|
| 企业知识库(中文) | BGE-large-zh | 中文效果最好 |
| 多语言项目 | OpenAI text-embedding-3 | 多语言平衡 |
| 成本敏感 | text-embedding-3-small | 性价比最高 |
| 离线部署 | BGE / M3E | 开源可本地部署 |
五、评估RAG系统质量
5.1 RAGAS评估框架
python
# rag/evaluation.py
class RAGEvaluator:
"""RAG系统质量评估"""
def evaluate(self, questions: list, answers: list,
contexts: list, ground_truths: list) -> dict:
"""
评估指标:
- Faithfulness (忠实度): 回答是否基于检索的上下文
- Relevancy (相关性): 回答是否切题
- Context Precision (上下文精度): 检索结果是否相关
- Context Recall (上下文召回): 是否检索到了所有必要信息
"""
metrics = {
"faithfulness": self._eval_faithfulness(answers, contexts),
"relevancy": self._eval_relevancy(questions, answers),
"context_precision": self._eval_context_precision(
questions, contexts
),
"answer_correctness": self._eval_correctness(
answers, ground_truths
)
}
return metrics
def _eval_faithfulness(self, answers, contexts):
"""评估回答是否忠实于上下文"""
scores = []
for answer, context in zip(answers, contexts):
prompt = f"""评估以下回答是否忠实于提供的上下文。
回答中的每个论点是否都能在上下文中找到依据?
上下文: {context}
回答: {answer}
忠实度评分 (0-1): """
# 实际使用时调用LLM评分
scores.append(0.85) # 示例值
return sum(scores) / len(scores)
def _eval_relevancy(self, questions, answers):
scores = [0.90] # 示例
return sum(scores) / len(scores)
def _eval_context_precision(self, questions, contexts):
scores = [0.80] # 示例
return sum(scores) / len(scores)
def _eval_correctness(self, answers, ground_truths):
scores = [0.88] # 示例
return sum(scores) / len(scores)5.2 评估指标速查表
| 指标 | 含义 | 计算方式 | 合格线 |
|---|---|---|---|
| Faithfulness | 回答忠实度 | 声明与上下文匹配比例 | > 0.85 |
| Answer Relevancy | 回答相关性 | 回答与问题的语义相似度 | > 0.80 |
| Context Precision | 检索精度 | 相关结果在排序中的位置 | > 0.75 |
| Context Recall | 检索召回率 | 关键信息被检索到的比例 | > 0.80 |
| Answer Correctness | 回答正确性 | 与标准答案的匹配度 | > 0.85 |
六、RAG优化技巧汇总
| 优化方向 | 具体方法 | 效果提升 |
|---|---|---|
| 分块策略 | 语义分块 > 固定长度分块 | 15-30% |
| 查询优化 | 查询改写 + HyDE | 10-25% |
| 检索策略 | 混合检索(向量+关键词) | 10-20% |
| 重排序 | Cross-encoder重排 | 15-30% |
| 压缩 | 上下文压缩与过滤 | 减少token 30-50% |
| 缓存 | 相似查询缓存 | 减少50%调用 |
总结
RAG是让Agent从"通才"变为"专家"的关键技术:
- 文档处理是基础------分块质量直接决定检索质量
- 向量检索是核心------选择合适的Embedding模型和检索策略
- 高级策略是提升------查询改写、多路召回、重排序
- 持续评估 是保障------用RAGAS框架量化系统质量