摘要------张量补全旨在基于部分观测值填补不完整张量的缺失元素,这是图像修复的一种流行方法。现有的大多数视觉数据恢复方法可分为传统的基于优化的方法和基于神经网络的方法。
- 前者通常采用低秩假设来处理这个不适定问题,具有良好的可解释性和泛化能力。然而,由于视觉数据仅仅是近似低秩的,手工设计的低秩先验可能无法恰当地捕捉复杂的细节,从而限制了恢复性能。
- 对于基于神经网络的方法,尽管它们在图像修复中表现出色,但参数学习需要充足的训练数据,并且它们在未见数据上的泛化能力令人担忧。
在本文中,结合这两种不同方法的优点,我们提出了一种用于视觉数据补全的张量补全神经网络 ( CNet )。 CNet 由两部分组成,即编码器和解码器。编码器通过利用 CANDECOMP/PARAFAC 分解来设计,以产生目标张量的低秩嵌入,其机制具有可解释性。为了弥补低秩约束的缺点,引入了由几个卷积层组成的解码器来细化低秩嵌入。
CNet 仅使用不完整张量的观测值来恢复其缺失项,因此摆脱了对大型训练数据集的依赖。在修复彩色图像、灰度视频序列、高光谱图像、彩色视频序列和光场图像方面进行了广泛的实验,以展示 CNet 在恢复性能方面优于最先进的方法。
文章目录
-
- [I. INTRODUCTION](#I. INTRODUCTION)
-
- [C. Tensor Completion Formulation](#C. Tensor Completion Formulation)
- [III. PROPOSED NEURAL NETWORK](#III. PROPOSED NEURAL NETWORK)
-
- [A. Algorithm Development](#A. Algorithm Development)
- [B. Network Structure](#B. Network Structure)
I. INTRODUCTION
最近,展开(unrolling) 1 ^1 1 在神经网络设计中引起了广泛关注 40,它将迭代算法映射到深度神经网络中。在这类神经网络中,数据流的含义是清晰的,从而分别在优化和学习方面保证了可解释性和有效性。在这项工作中,受展开概念的启发,我们设计了一种用于视觉数据恢复的张量补全神经网络(a tensor Completion neural Network),命名为 CNet。
我们将 CNet 构建为编码器-解码器架构。
- 给定一个张量,编码器通过利用 CP 分解来构建其低秩近似 11。低秩张量补全(TC)方法已被证明能够恢复不完整的张量 41, 42, 43。因此,CNet 恢复缺失元素具有理论基础。
- 另一方面,视觉数据近似为低秩,这表明低秩约束可能会导致细节信息退化甚至严重失真。为了弥补这一缺点,我们利用由卷积神经网络(CNN)组成的解码器来恢复复杂的细节。
给定不完整的图像或视频,CNet 仅使用其观测值来恢复缺失项,因此是无监督的,其中编码器和解码器都 没有经过预训练 (not pretrained)。如图 1 所示,所提出的 CNet 结合了基于优化和基于学习的方法的优势。本文的主要贡献总结如下:
-
据我们所知,CNet 是第一种通过恢复低秩潜变量并随后使用神经网络增强微小细节来处理近似低秩 TC 问题的方法。具体而言,不完整张量首先被恢复为低秩近似,并进一步细化以提高恢复性能,这两个步骤都采用了神经网络。
-
我们利用低秩 CP 分解来设计我们的编码器,使得编码器机制具有可解释性。基于 CP 分解,编码器构建了一个低秩近似,这是一种低维图像嵌入,并作为最终输出的粗略锚点。
-
我们引入了一种用于低秩 TC 的解码器,它弥补了将低秩模型应用于图像或视频的缺点。由于视觉数据仅是近似低秩的,我们的恢复性能优于基于低秩假设的方法。
-
大量实验结果表明,CNet 在彩色图像、灰度视频、高光谱图像(HSI)、彩色视频和光场图像修复方面优于最先进的 TC 算法。当仅观察到 5% 的元素时,光场图像 Lego Truck 的恢复结果预览如图 2 所示。
1 ^1 1 在神经网络设计中,"unrolling"也称为"unfolding"。事实上,这两个词也用于涉及张量矩阵化的文献中,例如"unfolding/unrolling a tensor"。为了避免混淆,在本文中,"unfolding"指的是张量的矩阵化,而"unrolling"指的是神经网络设计技术。
C. Tensor Completion Formulation
设 Y ∈ R I 1 × I 2 × I 3 \mathcal{Y} \in \mathbb{R}^{I_1 \times I_2 \times I_3} Y∈RI1×I2×I3 为一个在给定索引集 Ω \Omega Ω 下具有部分观测项 { y i 1 , i 2 , i 3 ∣ ( i 1 , i 2 , i 3 ) ∈ Ω } \{y_{i_1, i_2, i_3} | (i_1, i_2, i_3) \in \Omega\} {yi1,i2,i3∣(i1,i2,i3)∈Ω} 的张量。TC 旨在估计 Y \mathcal{Y} Y 中未观测到的元素。利用低秩假设,基于秩最小化的 TC 公式化为 7:
X ∗ = arg min X rank ( X ) , s.t. P Ω ( X ) = P Ω ( Y ) . (8) \mathcal{X}^* = \arg\min_{\mathcal{X}} \text{rank}(\mathcal{X}), \quad \text{s.t.} \ \mathfrak{P}{\Omega}(\mathcal{X}) = \mathfrak{P}{\Omega}(\mathcal{Y}). \tag{8} X∗=argXminrank(X),s.t. PΩ(X)=PΩ(Y).(8)
请注意,这里的 rank ( ⋅ ) \text{rank}(\cdot) rank(⋅) 可以是 CP 秩或多线性秩。基于因子分解,低秩 TC 可以表示为 7:
X ∗ = arg min X ∥ P Ω ( X ) − P Ω ( Y ) ∥ F 2 , s.t. X = RC ( F 1 , F 2 , ⋯ , F sup ) , (9) \mathcal{X}^* = \arg\min_{\mathcal{X}} \|\mathfrak{P}{\Omega}(\mathcal{X}) - \mathfrak{P}{\Omega}(\mathcal{Y})\|_F^2, \quad \text{s.t.} \ \mathcal{X} = \text{RC}(\mathcal{F}_1, \mathcal{F}2, \cdots, \mathcal{F}{\text{sup}}), \tag{9} X∗=argXmin∥PΩ(X)−PΩ(Y)∥F2,s.t. X=RC(F1,F2,⋯,Fsup),(9)
其中 F 1 , F 2 , ⋯ , F sup 2 \mathcal{F}_1, \mathcal{F}2, \cdots, \mathcal{F}{\text{sup}}^2 F1,F2,⋯,Fsup2 是 X \mathcal{X} X 通过某种张量分解得到的因子,并且 RC ( ⋅ ) \text{RC}(\cdot) RC(⋅) 表示相应的张量重建算子。
III. PROPOSED NEURAL NETWORK
在本节中,为了进行视觉数据补全,我们开发了一种基于 CP 分解的有效编码器-解码器网络。编码器通过 Kruskal 运算在低秩域中构建张量。解码器进一步处理编码器输出并细化其细节,以提高恢复性能。
A. Algorithm Development
利用传统的优化策略,基于具有指定 CP 秩 R R R 的低秩 CP 分解的 TC 公式化为:
min A ( 1 ) , A ( 2 ) , A ( 3 ) ∥ P Ω ( X ) − P Ω ( Y ) ∥ F 2 , s.t. X = \[ A ( 1 ) , A ( 2 ) , A ( 3 ) ] , (10) \min_{\mathbf{A}^{(1)}, \mathbf{A}^{(2)}, \mathbf{A}^{(3)}} \|\mathfrak{P}{\Omega}(\mathcal{X}) - \mathfrak{P}{\Omega}(\mathcal{Y})\|_F^2, \quad \text{s.t.} \ \mathcal{X} = \\!\[\\mathbf{A}\^{(1)}, \\mathbf{A}\^{(2)}, \\mathbf{A}\^{(3)}\!], \tag{10} A(1),A(2),A(3)min∥PΩ(X)−PΩ(Y)∥F2,s.t. X=\[A(1),A(2),A(3)],(10)
其中 X , Y ∈ R I 1 × I 2 × I 3 \mathcal{X}, \mathcal{Y} \in \mathbb{R}^{I_1 \times I_2 \times I_3} X,Y∈RI1×I2×I3 是三阶张量,并且 A ( 1 ) ∈ R I 1 × R \mathbf{A}^{(1)} \in \mathbb{R}^{I_1 \times R} A(1)∈RI1×R、 A ( 2 ) ∈ R I 2 × R \mathbf{A}^{(2)} \in \mathbb{R}^{I_2 \times R} A(2)∈RI2×R 和 A ( 3 ) ∈ R I 3 × R \mathbf{A}^{(3)} \in \mathbb{R}^{I_3 \times R} A(3)∈RI3×R 是因子矩阵。
设 X ∈ R I 1 × I 2 × ⋯ × I N \mathcal{X} \in \mathbb{R}^{I_1 \times I_2 \times \cdots \times I_N} X∈RI1×I2×⋯×IN 为一个 N N N 阶张量(若为矩阵则 N = 2 N=2 N=2), Ω \Omega Ω 为已知元素的坐标索引集合。正交投影算子 P Ω ( ⋅ ) \mathfrak{P}{\Omega}(\cdot) PΩ(⋅) 作用于张量 X \mathcal{X} X 后,生成一个新的同维度张量。新张量在任意坐标 ( i 1 , i 2 , ... , i N ) (i_1, i_2, \dots, i_N) (i1,i2,...,iN) 上的元素定义如下: P Ω ( X ) i 1 , i 2 , ... , i N = { x i 1 , i 2 , ... , i N , if ( i 1 , i 2 , ... , i N ) ∈ Ω 0 , if ( i 1 , i 2 , ... , i N ) ∉ Ω \\mathfrak{P}_{\\Omega}(\\mathcal{X}){i_1, i_2, \dots, i_N} = \begin{cases} x_{i_1, i_2, \dots, i_N}, & \text{if } (i_1, i_2, \dots, i_N) \in \Omega \\ 0, & \text{if } (i_1, i_2, \dots, i_N) \notin \Omega \end{cases} PΩ(X)i1,i2,...,iN={xi1,i2,...,iN,0,if (i1,i2,...,iN)∈Ωif (i1,i2,...,iN)∈/Ω其中, x i 1 , i 2 , ... , i N x_{i_1, i_2, \dots, i_N} xi1,i2,...,iN 表示原张量 X \mathcal{X} X 在对应坐标位置的元素值。
我们将 (10) 重写为逐元素的形式:
min A ( 1 ) , A ( 2 ) , A ( 3 ) ∑ ( i 1 , i 2 , i 3 ) ∈ Ω ( P { ( i 1 , i 2 , i 3 ) } ( X ) − P { ( i 1 , i 2 , i 3 ) } ( Y ) ) 2 , s.t. X = \[ A ( 1 ) , A ( 2 ) , A ( 3 ) ] . (11) \min_{\mathbf{A}^{(1)}, \mathbf{A}^{(2)}, \mathbf{A}^{(3)}} \sum_{(i_1, i_2, i_3) \in \Omega} (\mathfrak{P}{\{(i_1, i_2, i_3)\}}(\mathcal{X}) - \mathfrak{P}{\{(i_1, i_2, i_3)\}}(\mathcal{Y}))^2, \quad \text{s.t.} \ \mathcal{X} = \\!\[\\mathbf{A}\^{(1)}, \\mathbf{A}\^{(2)}, \\mathbf{A}\^{(3)}\!]. \tag{11} A(1),A(2),A(3)min(i1,i2,i3)∈Ω∑(P{(i1,i2,i3)}(X)−P{(i1,i2,i3)}(Y))2,s.t. X=\[A(1),A(2),A(3)].(11)
根据 (6) ,可以得出
P { ( i 1 , i 2 , i 3 ) } ( X ) = x i 1 , i 2 , i 3 = ⟨ a ˉ i 1 ( 1 ) , a ˉ i 2 ( 2 ) , a ˉ i 3 ( 3 ) ⟩ . (12) \mathfrak{P}{\{(i_1, i_2, i_3)\}}(\mathcal{X}) = x{i_1, i_2, i_3} = \langle \bar{\mathbf{a}}{i_1}^{(1)}, \bar{\mathbf{a}}{i_2}^{(2)}, \bar{\mathbf{a}}_{i_3}^{(3)} \rangle. \tag{12} P{(i1,i2,i3)}(X)=xi1,i2,i3=⟨aˉi1(1),aˉi2(2),aˉi3(3)⟩.(12)
也就是说, ( i 1 , i 2 , i 3 ) (i_1, i_2, i_3) (i1,i2,i3) 项被计算为 A ( 1 ) T {\mathbf{A}^{(1)}}^T A(1)T、 A ( 2 ) T {\mathbf{A}^{(2)}}^T A(2)T 和 A ( 3 ) T {\mathbf{A}^{(3)}}^T A(3)T 的第 i 1 i_1 i1、第 i 2 i_2 i2 和第 i 3 i_3 i3 个列向量的 N N N 重收缩,由下式给出
x i 1 , i 2 , i 3 = ⟨ A ( 1 ) T e i 1 , A ( 2 ) T e i 2 , A ( 3 ) T e i 3 ⟩ , (13) x_{i_1, i_2, i_3} = \langle {\mathbf{A}^{(1)}}^T \mathbf{e}{i_1}, {\mathbf{A}^{(2)}}^T \mathbf{e}{i_2}, {\mathbf{A}^{(3)}}^T \mathbf{e}_{i_3} \rangle, \tag{13} xi1,i2,i3=⟨A(1)Tei1,A(2)Tei2,A(3)Tei3⟩,(13)
- x i 1 , i 2 , i 3 x_{i_1, i_2, i_3} xi1,i2,i3:维度为 1 × 1 1 \times 1 1×1(标量),表示张量 X \mathcal{X} X 在空间坐标 ( i 1 , i 2 , i 3 ) (i_1, i_2, i_3) (i1,i2,i3) 处的具体元素预测值或重构值。
- a ˉ i 1 ( 1 ) \bar{\mathbf{a}}_{i_1}^{(1)} aˉi1(1):维度为 R × 1 R \times 1 R×1(列向量),表示第一维度的第 i 1 i_1 i1 个特征向量(提取自因子矩阵 A ( 1 ) \mathbf{A}^{(1)} A(1) 的对应行并转置),在网络架构中作为第一个分支网络的输出特征。
- a ˉ i 2 ( 2 ) \bar{\mathbf{a}}_{i_2}^{(2)} aˉi2(2):维度为 R × 1 R \times 1 R×1(列向量),表示第二维度的第 i 2 i_2 i2 个特征向量(提取自因子矩阵 A ( 2 ) \mathbf{A}^{(2)} A(2) 的对应行并转置),在网络架构中作为第二个分支网络的输出特征。
- a ˉ i 3 ( 3 ) \bar{\mathbf{a}}_{i_3}^{(3)} aˉi3(3):维度为 R × 1 R \times 1 R×1(列向量),表示第三维度的第 i 3 i_3 i3 个特征向量(提取自因子矩阵 A ( 3 ) \mathbf{A}^{(3)} A(3) 的对应行并转置),在网络架构中作为第三个分支网络的输出特征。
- ⟨ ⋅ , ⋅ , ⋅ ⟩ \langle \cdot, \cdot, \cdot \rangle ⟨⋅,⋅,⋅⟩:无自身维度(运算结果映射为标量),表示 N N N 重收缩或广义内积运算,即对上述三个列向量进行逐元素相乘后求和,用于将多分支的高维特征融合成最终的预测标量。
其中 e i 1 ∈ R I 1 \mathbf{e}{i_1} \in \mathbb{R}^{I_1} ei1∈RI1 表示一个列向量,其项全为零,除了第 i 1 i_1 i1 项为一,而 e i 2 \mathbf{e}{i_2} ei2 和 e i 3 \mathbf{e}{i_3} ei3 的定义类似。也就是说, e i 1 \mathbf{e}{i_1} ei1、 e i 2 \mathbf{e}{i_2} ei2 和 e i 3 \mathbf{e}{i_3} ei3 指示了 x i 1 , i 2 , i 3 x_{i_1, i_2, i_3} xi1,i2,i3 在 X \mathcal{X} X 中的位置,以及在 A ( 1 ) T {\mathbf{A}^{(1)}}^T A(1)T、 A ( 2 ) T {\mathbf{A}^{(2)}}^T A(2)T 和 A ( 3 ) T {\mathbf{A}^{(3)}}^T A(3)T 中对应的列向量。因此,它们被称为索引向量。然后,我们进一步将 (11) 表示为:
min A ( 1 ) , A ( 2 ) , A ( 3 ) ∑ ( i 1 , i 2 , i 3 ) ∈ Ω ( ⟨ A ( 1 ) T e i 1 , A ( 2 ) T e i 2 , A ( 3 ) T e i 3 ⟩ − y i 1 , i 2 , i 3 ) 2 . (14) \min_{\mathbf{A}^{(1)}, \mathbf{A}^{(2)}, \mathbf{A}^{(3)}} \sum_{(i_1, i_2, i_3) \in \Omega} \left( \langle {\mathbf{A}^{(1)}}^T \mathbf{e}{i_1}, {\mathbf{A}^{(2)}}^T \mathbf{e}{i_2}, {\mathbf{A}^{(3)}}^T \mathbf{e}{i_3} \rangle - y{i_1, i_2, i_3} \right)^2. \tag{14} A(1),A(2),A(3)min(i1,i2,i3)∈Ω∑(⟨A(1)Tei1,A(2)Tei2,A(3)Tei3⟩−yi1,i2,i3)2.(14)
接下来,我们展示如何通过将 (14) 映射到神经网络中来设计编码器。具体来说, A ( 1 ) T e i 1 {\mathbf{A}^{(1)}}^T \mathbf{e}{i_1} A(1)Tei1 、 A ( 2 ) T e i 2 {\mathbf{A}^{(2)}}^T \mathbf{e}{i_2} A(2)Tei2 和 A ( 3 ) T e i 3 {\mathbf{A}^{(3)}}^T \mathbf{e}{i_3} A(3)Tei3 被认为是三个多层感知机(MLPs)的输出。这三个分支的输入是 e i 1 \mathbf{e}{i_1} ei1 、 e i 2 \mathbf{e}{i_2} ei2 和 e i 3 \mathbf{e}{i_3} ei3 ,并且输出分别是 a ˉ i 1 ( 1 ) = A ( 1 ) T e i 1 \bar{\mathbf{a}}{i_1}^{(1)} = {\mathbf{A}^{(1)}}^T \mathbf{e}{i_1} aˉi1(1)=A(1)Tei1 、 a ˉ i 2 ( 2 ) = A ( 2 ) T e i 2 \bar{\mathbf{a}}{i_2}^{(2)} = {\mathbf{A}^{(2)}}^T \mathbf{e}{i_2} aˉi2(2)=A(2)Tei2 和 a ˉ i 3 ( 3 ) = A ( 3 ) T e i 3 \bar{\mathbf{a}}{i_3}^{(3)} = {\mathbf{A}^{(3)}}^T \mathbf{e}{i_3} aˉi3(3)=A(3)Tei3 。计算 a ˉ i 1 ( 1 ) \bar{\mathbf{a}}{i_1}^{(1)} aˉi1(1) 、 a ˉ i 2 ( 2 ) \bar{\mathbf{a}}{i_2}^{(2)} aˉi2(2) 和 a ˉ i 3 ( 3 ) \bar{\mathbf{a}}{i_3}^{(3)} aˉi3(3) 的 N N N 重收缩会产生 x i 1 , i 2 , i 3 x{i_1, i_2, i_3} xi1,i2,i3 。与三分支全连接网络的前向计算相一致, A ( 1 ) T {\mathbf{A}^{(1)}}^T A(1)T 、 A ( 2 ) T {\mathbf{A}^{(2)}}^T A(2)T 和 A ( 3 ) T {\mathbf{A}^{(3)}}^T A(3)T 可以被看作是通过聚合每个 MLP 中的权重和激活操作获得的权重矩阵。因此,用最小二乘代价训练这个网络等价于寻找 (14) 的最小值。
我们使用批量输入策略(batch input strategy),因此采用单位矩阵作为输入,其中单位矩阵的列向量被视为索引向量。将单位矩阵输入到每个分支等价于将单位矩阵与权重矩阵相乘,其中结果或网络输出仍然是权重矩阵,例如, A ( 1 ) T E I 1 = A ( 1 ) T {\mathbf{A}^{(1)}}^T \mathbf{E}{I_1} = {\mathbf{A}^{(1)}}^T A(1)TEI1=A(1)T ,其中单位矩阵 E I 1 ∈ R I 1 × I 1 \mathbf{E}{I_1} \in \mathbb{R}^{I_1 \times I_1} EI1∈RI1×I1 。使用单位矩阵作为三个分支的输入会生成 A ( 1 ) \mathbf{A}^{(1)} A(1) 、 A ( 2 ) \mathbf{A}^{(2)} A(2) 和 A ( 3 ) \mathbf{A}^{(3)} A(3) 。利用这些权重矩阵,或者说 CP 分解的因子矩阵,我们可以使用 Kruskal 运算在低秩域中构建张量。然后,我们将 (14) 重写为另一种等价形式:
min A ( 1 ) , A ( 2 ) , A ( 3 ) ∥ P Ω ( \[ A ( 1 ) , A ( 2 ) , A ( 3 ) ] ) − P Ω ( Y ) ∥ F 2 . (15) \min_{\mathbf{A}^{(1)}, \mathbf{A}^{(2)}, \mathbf{A}^{(3)}} \left\| \mathfrak{P}{\Omega} \left( \\!\[ \\mathbf{A}\^{(1)}, \\mathbf{A}\^{(2)}, \\mathbf{A}\^{(3)} \!] \right) - \mathfrak{P}{\Omega}(\mathcal{Y}) \right\|_F^2 . \tag{15} A(1),A(2),A(3)min PΩ(\[A(1),A(2),A(3)])−PΩ(Y) F2.(15)
设一个三阶张量 X \mathcal{X} X 的维度是 I 1 × I 2 × I 3 I_1 \times I_2 \times I_3 I1×I2×I3。通过 CP 分解(秩为 R R R),我们得到了三个因子矩阵: A ( 1 ) \mathbf{A}^{(1)} A(1),维度为 I 1 × R I_1 \times R I1×R A ( 2 ) \mathbf{A}^{(2)} A(2),维度为 I 2 × R I_2 \times R I2×R A ( 3 ) \mathbf{A}^{(3)} A(3),维度为 I 3 × R I_3 \times R I3×R
Kruskal 运算的展开公式如下: \[ A ( 1 ) , A ( 2 ) , A ( 3 ) ] = ∑ r = 1 R a r ( 1 ) ∘ a r ( 2 ) ∘ a r ( 3 ) \\!\[\\mathbf{A}\^{(1)}, \\mathbf{A}\^{(2)}, \\mathbf{A}\^{(3)}\!] = \sum_{r=1}^{R} \mathbf{a}_r^{(1)} \circ \mathbf{a}_r^{(2)} \circ \mathbf{a}_r^{(3)} \[A(1),A(2),A(3)]=r=1∑Rar(1)∘ar(2)∘ar(3)
总而言之,编码器的输入是 E I 1 \mathbf{E}{I_1} EI1 、 E I 2 \mathbf{E}{I_2} EI2 、 E I 3 \mathbf{E}_{I_3} EI3 ,并且输出是 \[ A ( 1 ) , A ( 2 ) , A ( 3 ) ] \\!\[ \\mathbf{A}\^{(1)}, \\mathbf{A}\^{(2)}, \\mathbf{A}\^{(3)} \!] \[A(1),A(2),A(3)] 。
编码器产生一个精确的低秩张量。然而,如前所述,视觉数据并非完全是低秩的。也就是说,低秩模型可能无法保证恢复细节信息。因此,我们引入了一个解码器来细化低秩视觉数据的细节。从秩的角度来看,解码器的作用是将低秩张量变换到高秩域的函数。结合解码器,我们将 (15) 修改为:
min A ( 1 ) , A ( 2 ) , A ( 3 ) ∥ P Ω ( D ( \[ A ( 1 ) , A ( 2 ) , A ( 3 ) ] ) ) − P Ω ( Y ) ∥ F 2 , (16) \min_{\mathbf{A}^{(1)}, \mathbf{A}^{(2)}, \mathbf{A}^{(3)}} \left\| \mathfrak{P}{\Omega} \left( \mathfrak{D} \left( \\!\[ \\mathbf{A}\^{(1)}, \\mathbf{A}\^{(2)}, \\mathbf{A}\^{(3)} \!] \right) \right) - \mathfrak{P}{\Omega}(\mathcal{Y}) \right\|_F^2 , \tag{16} A(1),A(2),A(3)min PΩ(D(\[A(1),A(2),A(3)]))−PΩ(Y) F2,(16)
其中 D ( ⋅ ) \mathfrak{D}(\cdot) D(⋅) 表示解码器。
我们利用 CNN 来构建解码器,这适用于图像相关的任务。CNN 中涉及的卷积操作可以有效地捕获图像多个区域中存在的局部模式和特征,其中可学习的卷积核在整个图像中共享。在过去的几十年中,基于 CNN 的算法在图像恢复方面取得了巨大成功 37, 44,其中具有跳跃连接结构的下采样和上采样被广泛使用,例如 U-Net 45。
- 例如,在 46 中,作者采用 U-Net 进行图像超分辨率,其中输入和输出分别是低分辨率和高分辨率图像。
- 在 47 中,U-Net 被用于使用输入的噪声图像生成无噪声图像。
因此,类似地,U-Net 被采用作为我们的解码器用于细节增强。解码器的输入是低秩近似,并且输出是具有丰富细节的图像。
B. Network Structure
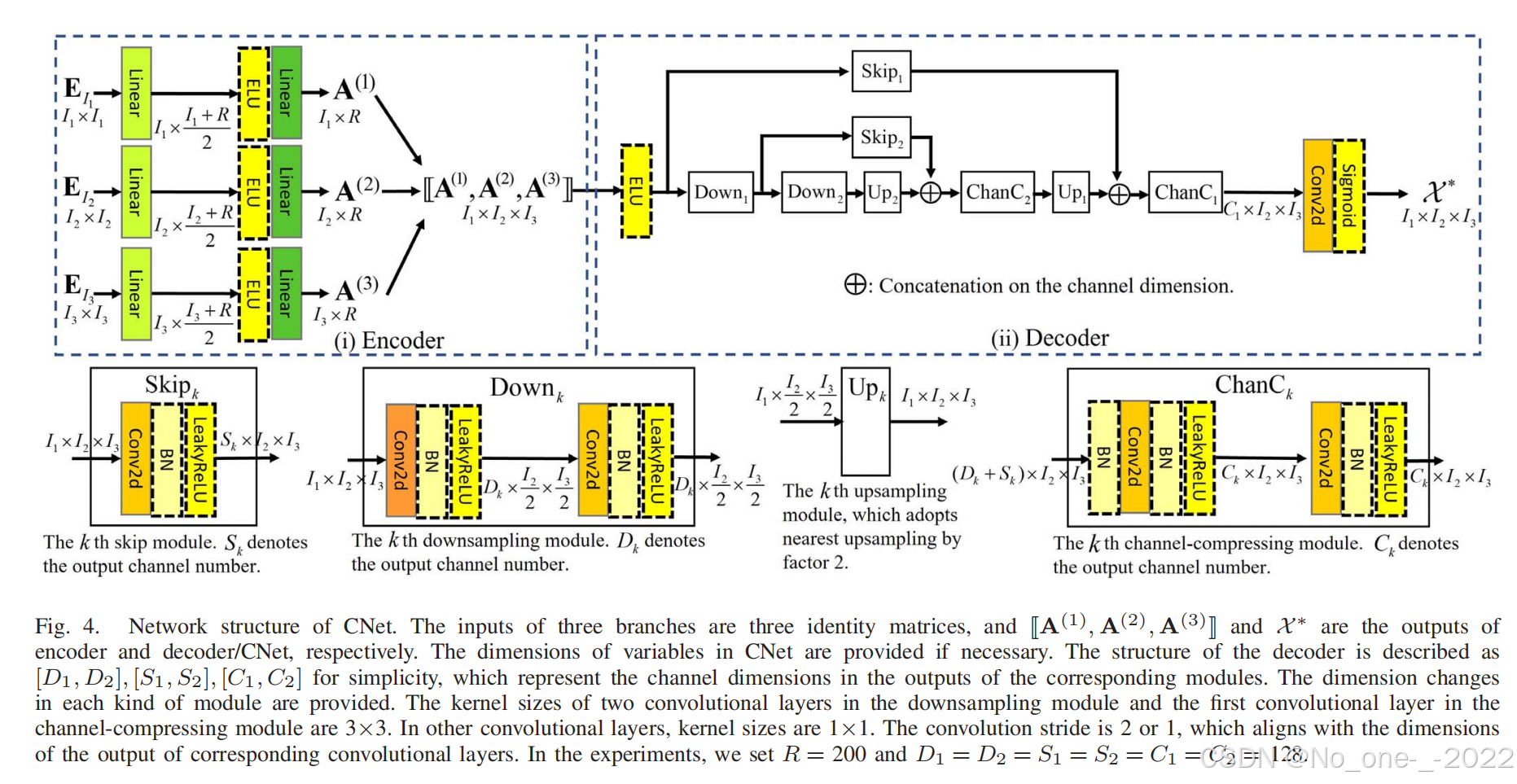
图 4. CNet 的网络结构。三个分支的输入是三个单位矩阵,并且 \[ A ( 1 ) , A ( 2 ) , A ( 3 ) ] \\!\[\\mathbf{A}\^{(1)}, \\mathbf{A}\^{(2)}, \\mathbf{A}\^{(3)}\!] \[A(1),A(2),A(3)] 和 X ∗ \mathcal{X}^* X∗ 分别是编码器和解码器/CNet 的输出。如有必要,提供了 CNet 中变量的维度。为了简单起见,解码器的结构被描述为 D 1 , D 2 , S 1 , S 2 , C 1 , C 2 D_1, D_2, S_1, S_2, C_1, C_2 D1,D2,S1,S2,C1,C2 ,它们表示相应模块输出中的通道维度。提供了每种模块中的维度变化。下采样模块中两个卷积层和通道压缩模块中第一个卷积层的核大小为 3 × 3 3 \times 3 3×3 。在其他卷积层中,核大小为 1 × 1 1 \times 1 1×1 。卷积步长为 2 或 1,这与相应卷积层输出的维度对齐。在实验中,我们设置 R = 200 R = 200 R=200 并且 D 1 = D 2 = S 1 = S 2 = C 1 = C 2 = 128 D_1 = D_2 = S_1 = S_2 = C_1 = C_2 = 128 D1=D2=S1=S2=C1=C2=128 。
CNet (16) 的网络结构如图 4 所示。对于维度为 I 1 × I 2 × I 3 I_1 \times I_2 \times I_3 I1×I2×I3 的三阶张量,编码器中三个分支的输入是三个单位矩阵 E I 1 ∈ R I 1 × I 1 \mathbf{E}{I_1} \in \mathbb{R}^{I_1 \times I_1} EI1∈RI1×I1 、 E I 2 ∈ R I 2 × I 2 \mathbf{E}{I_2} \in \mathbb{R}^{I_2 \times I_2} EI2∈RI2×I2 和 E I 3 ∈ R I 3 × I 3 \mathbf{E}_{I_3} \in \mathbb{R}^{I_3 \times I_3} EI3∈RI3×I3 ,并且输出分别是三个因子矩阵 A ( 1 ) \mathbf{A}^{(1)} A(1) 、 A ( 2 ) \mathbf{A}^{(2)} A(2) 和 A ( 3 ) \mathbf{A}^{(3)} A(3) 。每个分支由两个线性层和位于它们之间作为激活函数的一个指数线性单元(exponential linear unit,ELU)组成,其中矩阵的维度变化为:对于 n = 1 , 2 , 3 n = 1, 2, 3 n=1,2,3 , I n × I n → I n × ( I n + R ) / 2 → I n × R I_n \times I_n \rightarrow I_n \times (I_n + R)/2 \rightarrow I_n \times R In×In→In×(In+R)/2→In×R 。然后,利用这些因子矩阵,通过 Kruskal 运算构建一个低秩张量,作为编码器的输出。
解码器主要由两个下采样模块、两个上采样模块、两个通道压缩模块(two channel-compression modules)和两个跳跃模块(two skip modules)组成。
- 下采样操作提取低秩视觉数据的特征,
- 而上采样操作结合通道压缩操作旨在从提取的特征中生成具有高恢复精度的视觉数据。
低秩视觉数据首先通过一个 ELU,作为后续模块的输入。
记为 Down k \text{Down}_k Downk (对于 k = 1 , 2 k = 1, 2 k=1,2 )的下采样模块具有两个卷积层,每个卷积层之后跟有一个批量归一化(BN)层和一个 LeakyReLU 激活函数。 Down k \text{Down}_k Downk 中两个卷积层的核大小和卷积步长分别为 3 × 3 3 \times 3 3×3 、 2 2 2 和 3 × 3 3 \times 3 3×3 、 1 1 1 。
跳跃模块 Skip k \text{Skip}_k Skipk 由一个卷积层、一个 BN 层和一个 LeakyReLU 函数组成,其中核大小和卷积步长分别为 1 × 1 1 \times 1 1×1 和 1 1 1 。上采样模块 Up k \text{Up}_k Upk 将下采样模块 Down k \text{Down}_k Downk 或前一个通道压缩模块的输出按因子 2 2 2 进行上采样,然后上采样后的张量与 Skip k \text{Skip}_k Skipk 的输出在通道维度上的拼接作为通道压缩模块 ChanC k \text{ChanC}_k ChanCk 的输入。
ChanC k \text{ChanC}_k ChanCk 的组成与 Down k \text{Down}_k Downk 类似,只是在开头多了一个 BN 层。 ChanC k \text{ChanC}_k ChanCk 中的两个卷积层的核大小分别为 3 × 3 3 \times 3 3×3 和 1 × 1 1 \times 1 1×1 ,其中卷积步长均为 1 1 1 。最终通道压缩模块的输出经历一个额外的步骤以将其转换为 I 1 × I 2 × I 3 I_1 \times I_2 \times I_3 I1×I2×I3 张量,这是通过将输出通过一个卷积层并应用 sigmoid 激活函数来实现的,从而产生 CNet 的最终输出。
请注意, Down k \text{Down}_k Downk 、 Skip k \text{Skip}_k Skipk 和 ChanC k \text{ChanC}_k ChanCk 输出中的通道数分别为 D k D_k Dk 、 S k S_k Sk 和 C k C_k Ck 。为了表示方便,图 4 中解码器的结构记为 D 1 , D 2 , S 1 , S 2 , C 1 , C 2 D_1, D_2, S_1, S_2, C_1, C_2 D1,D2,S1,S2,C1,C2 。关于编码器和解码器结构的消融研究将在第四节中详细说明。
与 DIP (deep image prior)的区别:在网络结构方面,解码器类似于 DIP。然而,它们服务于不同的目的:一个细化粗略的估计,另一个填补缺失的项。具体而言,
- 前者旨在细化由编码器生成的粗略视觉数据,
- 而后者旨在完成缺失的项。
对于 CNet,补全任务是使用基于 CP 分解设计的编码器来实现的。与包括 DIP 在内的被称为"黑盒"的主流神经网络相比,CNet 是基于低秩 TC 模型设计的,解释了为什么缺失的元素可以被恢复。
对于索引集 Ω \Omega Ω 下部分观测的张量 Y \mathcal{Y} Y ,给定其观测元素,我们构造索引向量 e i 1 \mathbf{e}{i_1} ei1 、 e i 2 \mathbf{e}{i_2} ei2 和 e i 3 \mathbf{e}{i_3} ei3 。这些索引向量与观测元素相结合被视为训练数据。CNet 的输入是 E I 1 \mathbf{E}{I_1} EI1 、 E I 2 \mathbf{E}{I_2} EI2 和 E I 3 \mathbf{E}{I_3} EI3 ,它们的列向量是索引向量。CNet 的输出与 Y \mathcal{Y} Y 在索引集 Ω \Omega Ω 上的差异用于计算损失。
我们没有使用常用的均方误差(MSE)损失,而是为 CNet 选择了 Charbonnier 损失(the Charbonnier loss) 48。由于我们使用观测到的不完整张量来训练网络,其中编码器和解码器都没有经过预训练,因此先验信息非常有限。如果没有经过适当的训练,CNet 可能会产生伪影(被视为异常值)。因此,我们更倾向于使用一种稳健的度量,即 Charbonnier 损失:
Char loss ( y , y ^ ) = ( y ^ − y ) 2 + ε 2 . \text{Char}_{\text{loss}} (y, \hat{y}) = \sqrt{(\hat{y} - y)^2 + \varepsilon^2}. Charloss(y,y^)=(y^−y)2+ε2 .
这里, y y y 是标签, y ^ \hat{y} y^ 是网络输出,并且 ε \varepsilon ε 是一个常数,在实验中设置为 ( 10 − 3 ) (10^{-3}) (10−3) 。引入一个小的常数 ε \varepsilon ε 使得 Charbonnier 损失在零点处可导。然后,训练过程解决以下最小化问题:
Θ ∗ = arg min Θ ∥ P Ω ( F ( E I 1 , E I 2 , E I 3 ∣ Θ ) ) − P Ω ( Y ) ∥ F 2 + ε 2 , (17) \Theta^* = \arg\min_{\Theta} \sqrt{\|\mathfrak{P}{\Omega}(\mathfrak{F}(\mathbf{E}{I_1}, \mathbf{E}{I_2}, \mathbf{E}{I_3}|\Theta)) - \mathfrak{P}_{\Omega}(\mathcal{Y})\|_F^2 + \varepsilon^2}, \tag{17} Θ∗=argΘmin∥PΩ(F(EI1,EI2,EI3∣Θ))−PΩ(Y)∥F2+ε2 ,(17)
其中 F ( ⋅ ∣ Θ ) \mathfrak{F}(\cdot|\Theta) F(⋅∣Θ) 表示具有可学习参数集 Θ \Theta Θ 的网络函数。使用训练好的 CNet,恢复的张量计算如下:
X ∗ = F ( E I 1 , E I 2 , E I 3 ∣ Θ ∗ ) . (18) \mathcal{X}^* = \mathfrak{F}(\mathbf{E}{I_1}, \mathbf{E}{I_2}, \mathbf{E}_{I_3}|\Theta^*). \tag{18} X∗=F(EI1,EI2,EI3∣Θ∗).(18)
我们在算法 1 中总结了我们的方法。
