写在前面
线上服务最让人不安的时刻,往往不是接口直接报错 ,而是平时都好好的,某个时间点整批请求一起变慢。
监控看起来又不算失控:机器没挂,线程池没满,数据库也没炸 。直到翻到 GC 日志,才发现那一小段空白时间里,JVM 正在回收内存。
问题也就跟着冒出来了:
- 程序明明还在跑,为什么回收内存会让业务停下来?
JVM到底怎么判断哪些对象该回收,哪些对象还得留下?- 为什么有时只是一次很短的年轻代回收,有时却会冒出让人头疼的
Full GC?
顺着这些问题往下走,GC 这件事其实可以拆成两步看:
- 第一步不是"删对象",而是先判断谁还活着。
- 第二步才是针对不同区域、不同寿命分布,决定用什么方式回收。
GC的主线不要从"怎么删"开始看,而要从"谁还活着"开始看。
先判断对象是不是还活着
为什么引用计数不够
很多人第一次接触垃圾回收时,直觉都会落到一个很简单的办法上:
- 谁还被引用着,谁就活
- 谁的引用数清零,谁就回收
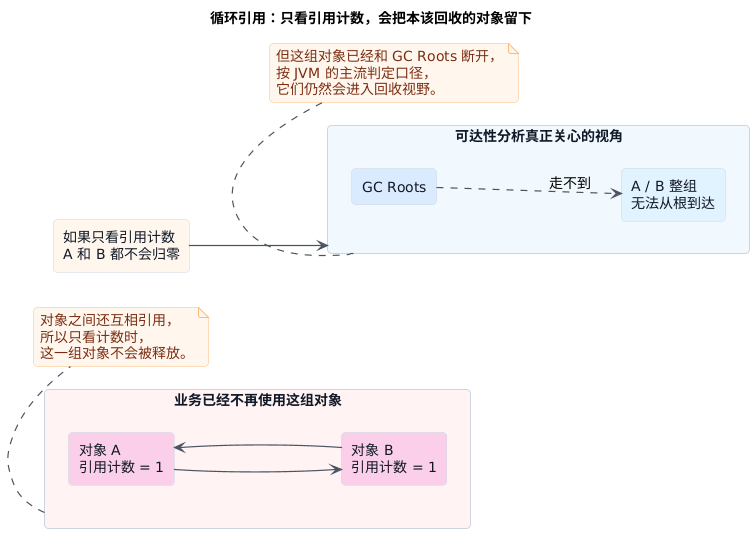
这个办法听起来顺手,真正落到 JVM 上却不够稳。最典型的问题就是循环引用 。两个对象哪怕已经和业务逻辑彻底没关系了,只要它们还互相指着,对方的引用数就不可能归零。只靠计数,JVM 很容易把本该回收的一组对象一直留在堆里。
对应到代码里,循环引用最容易长成这样:
java
class Obj {
Obj ref;
}
Obj a = new Obj();
Obj b = new Obj();
a.ref = b;
b.ref = a;
// 业务侧不再持有这两个对象
a = null;
b = null;如果只按"对象之间彼此还被引用着"来判断,原来那组对象似乎还没断开;但从程序真正还握着的入口看,这两个对象其实已经整组断根了。
如果是引用计数,a 和 b 互相持有会让这组对象的计数很难降到零;如果是可达性分析,只要它们已经和 GC Roots 断开,即使彼此还互相引用,也仍然可以被回收。
关键不在这两个对象互相引用了几次,而在于它们虽然彼此还连着,却已经不再被业务侧真正持有。如果判定规则只是"引用计数没归零就不回收",这组对象就会被错误留下。
这也是 Java 没把引用计数当作主判定口径的原因。GC 真正关心的,不是一个对象"手里还有几条线",而是这些线能不能一路追到真正还在使用它的那一端。
GC Roots 决定对象生死
JVM 的主流做法是可达性分析 。它不会从每个对象自己开始数引用,而是先拿出一组确定还在被程序直接依赖的起点,再从这些起点沿着引用关系往下走。能走到的对象,说明当前执行过程里还有意义;走不到的对象,才会进入回收视野。
这组起点就是 GC Roots。常见来源并不复杂:
- 栈帧里的局部变量
- 类的静态字段
- 运行时常量池里仍被持有的引用
JNI持有的对象引用
判断逻辑只有一句话:不是看对象还被多少个对象指着,而是看能不能从 GC Roots 出发走到它。
能从
GC Roots走到,就暂时活着;走不到,才进入回收视野。
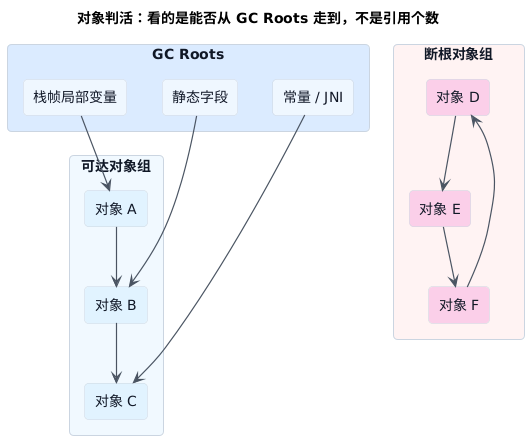
这里图里的英文其实只要先记住一个核心词就够了:GC Roots 可以直接理解成根对象 / 根引用起点。也就是程序此刻明确还在使用、可以拿来往下追引用关系的那一组起点。
图里左边那组对象虽然层层相连,但关键不在"连了几层",而在于最上面能从 GC Roots 一路走下来 ,所以它们仍然属于存活对象。右边那组对象也还互相引用,看上去并不"孤单",但整组已经和 GC Roots 断开。对 JVM 来说,这类对象就算彼此之间还在指来指去,也已经没有保留的必要了。
后面所有回收动作,都建立在先把存活对象和无效对象区分开 这个前提之上。GC 的难点从来不只是删除,而是先别删错。
为什么堆要分年轻代和老年代
多数对象其实活不久
如果堆里的对象都活得差不多长,最直接的做法就是每次都把整堆扫一遍。但真实程序不是这样跑的。
一次普通请求里,临时字符串、集合节点、中间结果对象、序列化缓冲区,往往很快就会失去意义。它们创建得快,消失得也快。真正会长期留下来的,通常只是一小部分缓存对象、会话状态、共享结构或者生命周期更长的数据。
这就给了 JVM 一个很重要的工程假设:多数对象朝生夕灭,少数对象才会长期存活。 既然寿命分布这么不均匀,就没必要每次都用同样的方式处理整片堆。更划算的办法,是把经常死得很快的对象 和活得更久的对象分开看。
一次 GC 周期里对象怎么流动
分代回收先从年轻代看起:
- 新对象通常先进入
Eden - 年轻代空间紧张时,会触发一次
Minor GC - 大多数已经没用的对象会直接在年轻代被清掉
- 只有少量还活着的对象,才会被复制到
Survivor区继续观察
如果这些对象后面几轮回收都还活着,就说明它们不再是"短命临时工"了,而是更可能长期留下来的成员。这时它们会逐步晋升到老年代。老年代里的对象存活率更高,回收代价也更重,所以后续策略自然不会和年轻代完全一样。
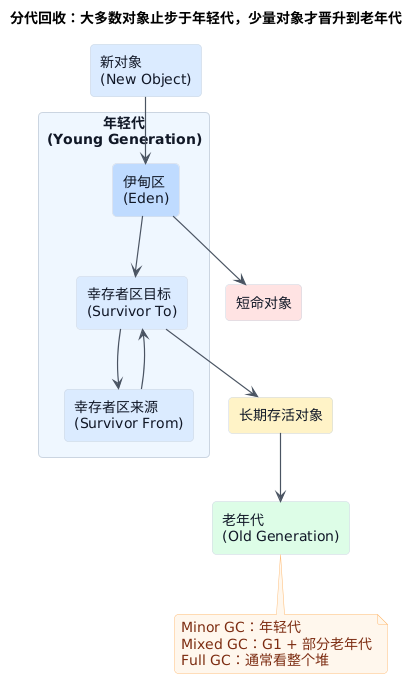
图里的英文名词先按这组中文去读:
Eden:新对象最先进入的分配区Survivor From / To:幸存者区的来源区 / 目标区,也就是"这一轮从哪来、往哪去"Minor GC:主要处理年轻代的一次回收
图里有两条关键流向。
- 第一条是左上到右侧的"短命对象流"。新对象进入
Eden后,大多数对象会在一次Minor GC后直接结束生命周期。这就是为什么年轻代适合高频回收,因为真正需要搬运和保留的对象并不多。 - 第二条是中部往下的"晋升流"。只有那些连续几轮都没死掉的对象,才会在
Survivor区之间继续流转,最后进入老年代。老年代里对象更多、活得更久,回收时更关心停顿控制和空间整理成本。
有了这个视角,几个常见术语就不容易混了:
Minor GC:主要处理年轻代Mixed GC:在G1的语境下,除了年轻代,还会顺带回收一部分老年代分区Full GC:代价最高,通常会把整个 Java 堆都纳入处理范围 ,也就是年轻代和老年代一起看;在很多HotSpot实现里,往往还会顺带处理类元数据等相关区域,所以它通常意味着堆压力已经明显上来了,或者前面的并发回收没有及时跟上
这三个词先放到一张表里:
| 术语 | 主要处理区域 | 常见触发语境 | 体感特点 |
|---|---|---|---|
Minor GC |
年轻代 | Eden 分配压力上来,新对象大量产生 |
频率高,但单次通常更轻 |
Mixed GC |
年轻代 + 一部分老年代分区 | G1 已完成并发标记,开始按回收价值分批处理老年代 Region |
不是整堆一起扫,而是分批回收 |
Full GC |
通常是整个 Java 堆,很多实现里还会连类元数据相关区域一起处理 | 堆压力明显上来,或前面的并发回收没及时跟上 | 最重、最该警惕的一类回收 |
分代回收真正解决的,不是"把堆切成两半"这么简单,而是承认对象寿命本来就不平均,然后顺着这个事实去设计更省停顿、更省成本的回收路径。
分代回收不是教条,而是顺着对象寿命分布做出来的工程优化。
三种回收算法在交换什么
把对象分出"该回收"和"不该回收"之后,下一步才轮到真正麻烦的部分:这些垃圾到底怎么清。
这里最容易产生的误解,是把回收理解成一次简单的"删除动作"。但堆内存不是表格,也不是文件夹。对象在堆里是连续分布、互相引用、还可能被移动的。只要回收开始发生,JVM 就得同时面对三件事:
- 哪些对象要保留
- 垃圾腾出来的空间还能不能顺手继续用
- 这次回收会不会带来太重的停顿和搬运成本
也正因为这三个目标经常互相打架,垃圾回收没有一种"处处都最优"的算法。后面这几类策略,本质上都是在不同代价之间做交换。
标记-清除为什么简单但会留碎片
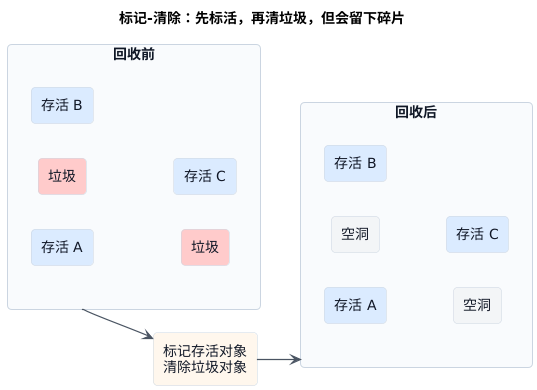
标记-清除的思路最直接。先把还活着的对象标出来,再把剩下那些没被标记的对象清掉。
它的好处也很明显:逻辑简单,不需要额外准备一整块备用内存,也不必一开始就把所有存活对象搬来搬去。 只要能分清存活对象和垃圾对象,就可以开始清理。
但问题也恰好出在"只清理,不整理"。垃圾对象虽然被删掉了,空出来的位置却可能零零散散地留在堆里。时间一长,堆里就会出现很多碎片。总空闲内存看起来不少,真正要分配一个更大的连续对象时,却可能找不到合适位置。
这就像一排书架里抽走了很多旧书,空位确实有了,但东一个、西一个。再来一本又厚又大的新书时,哪怕总空位长度加起来够,也未必能一次塞进去。
所以标记-清除的问题从来不是"能不能删垃圾",而是删完以后,堆空间是否还足够规整。 如果空间越来越碎,后面分配对象会更难,甚至可能逼出代价更高的整理动作。
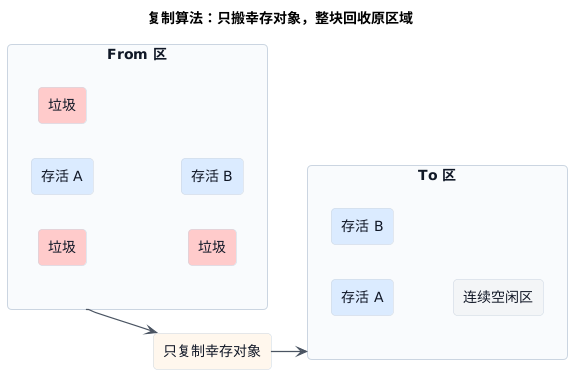
复制算法为什么适合年轻代
复制算法换了一个思路。它不急着在原地收拾残局,而是把还活着的对象直接复制到另一块干净区域,然后整块回收原来的空间。
这个办法在年轻代里尤其顺手,因为年轻代最典型的特征就是:死掉的对象很多,真正活下来的对象很少。既然多数对象都会在一次回收后直接消失,那最划算的做法往往不是在原地一点点清垃圾,而是只盯住那少量幸存对象,把它们搬走,剩下整片区域一次性清空。
它的收益有两个:
- 空间会非常规整,不容易留下碎片
- 回收成本更接近"复制少量存活对象",而不是"处理整片年轻代里的所有对象"
代价也很明确。复制算法需要预留可接收对象的新区域,而且对象每次幸存都要搬迁。如果一个区域里的对象存活率很高,复制就会变得越来越不划算。 这也是它更适合年轻代,而不适合直接拿去处理整片老年代的重要原因。
复制算法其实是在赌一件事:活下来的对象不会太多。 这个赌注放在年轻代,通常成立;放在老年代,就未必了。
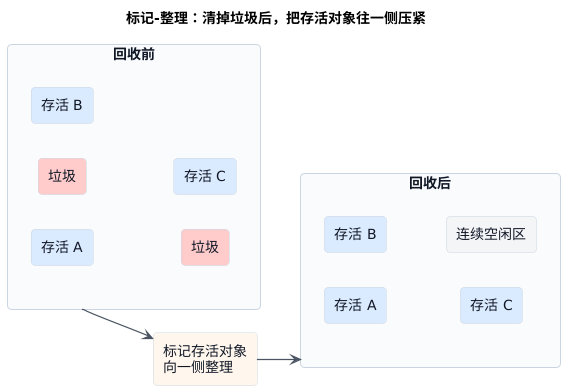
标记-整理为什么更适合老年代
老年代面临的问题和年轻代不一样。这里的对象活得更久,存活率也更高。如果还沿用年轻代那种"把少量幸存对象复制到另一块区域"的思路,搬运成本很快就会上来。
标记-整理做的事,可以理解成"先认出谁要留,再把这些对象往一边挪整齐"。它不会像标记-清除那样留下大量碎片,也不会像简单复制那样假设"幸存对象很少"。它更看重的是:既要把垃圾清掉,又要把剩下的有效空间重新整理成连续区域。
这套思路更适合老年代。老年代里对象多、活得久、后续还可能继续驻留很长时间。如果这里长期堆满碎片,后果会比年轻代更麻烦。因为一旦老年代分配和整理失控,后面更容易出现更重的停顿,甚至逼近 Full GC 这类代价更高的路径。
当然,整理也不是白来的。对象一旦移动,引用关系就要跟着调整,暂停时间和处理成本都可能上升。所以标记-整理的核心代价,不在"能不能整理",而在为了换到连续空间,要付出多少移动对象和更新引用的成本。
三种算法到底在交换什么
三类思路并排放在一起:
| 算法 | 核心动作 | 优势 | 代价 | 更适合的区域 |
|---|---|---|---|---|
| 标记-清除 | 标记存活对象,直接清掉垃圾 | 实现直接,不需要额外搬迁整批对象 | 容易留下碎片,后续分配可能越来越难 | 适合理解基础思路,但单独长期使用容易被碎片拖累 |
| 复制 | 只复制幸存对象,把原区域整块回收 | 空间容易保持连续,回收后分配更顺手 | 需要额外接收区域,而且要求幸存对象不能太多 | 年轻代,尤其适合"大量对象很快就死掉"的场景 |
| 标记-整理 | 标记存活对象,再把它们向一侧压紧 | 能同时回收垃圾并减少碎片 | 对象移动和引用更新成本更高,停顿压力也更重 | 老年代,更适合存活率更高、又更怕碎片的区域 |
这也是为什么前面讲完"对象判活"和"分代回收"之后,马上就得讲这些算法。因为后面的分代设计、收集器演进,归根到底都离不开同一个问题:在当前这片内存里,碎片、搬运、停顿,到底哪一种代价更值得承受。
三种回收算法没有绝对优劣,只有当前场景更愿意承受哪一种代价。
三色标记法:并发标记为什么必须有写屏障
前面讲了"判活""分代""三种算法"。接下来先别急着看具体收集器名字,先抽象出一种更难的执行方式:标记线程在追对象引用图,业务线程同时还在继续运行,并且还会继续改引用。
这种"标记和业务线程同时进行"的做法,就是后面经常会看到的并发标记。它不属于某一个收集器专有名词,而是一类收集器为了缩短停顿,会反复用到的核心思路。
这里顺手区分一下:并发标记 说的是"边追引用图边判活",并发清扫 说的是"边释放垃圾边让业务继续跑",并发迁移 说的是"边搬对象边让业务继续跑"。三色标记法直接解决的,是并发标记这一步里的正确性问题。
问题也正出在这里:当标记线程在追对象引用图时,业务线程也在不停改引用,业务随手改掉的一条边,会不会把"应该标到的对象"从标记视野里藏起来?
三色标记法就是用来解释这件事的。后面讲到 CMS / G1 / ZGC / Shenandoah 时,你再回头看 初始标记、并发标记、重新标记/最终标记、更新引用 这些阶段名,就会更容易对上它们分别在补哪一类问题。
先把三种颜色当成三种"状态"

| 颜色 | 含义 | 你可以把它理解成 |
|---|---|---|
| 黑色 | 已确认存活,且已扫描完引用 | "这个对象我已经扫过一遍了" |
| 灰色 | 已发现存活,但引用未扫描完 | "待处理队列 / 工作列表" |
| 白色 | 尚未确认可达,本轮候选回收 | "当前还没被触达" |
如果整个标记过程都在 STW 里跑,那么这套推进很直观:不断从灰色里取对象扫描,把新发现的对象放进灰色集合,把扫描完的对象变成黑色,直到灰色清空。
并发标记的关键不是"标记更快",而是标记线程在追引用图的同时,业务线程也在不停写引用:新增、删除、改指向都可能发生。
注意这里还有一个隐含规则:对象一旦变成黑色,就默认"本轮不会再回头扫描它的字段",否则并发标记就会退化成反复回扫,成本很难控。
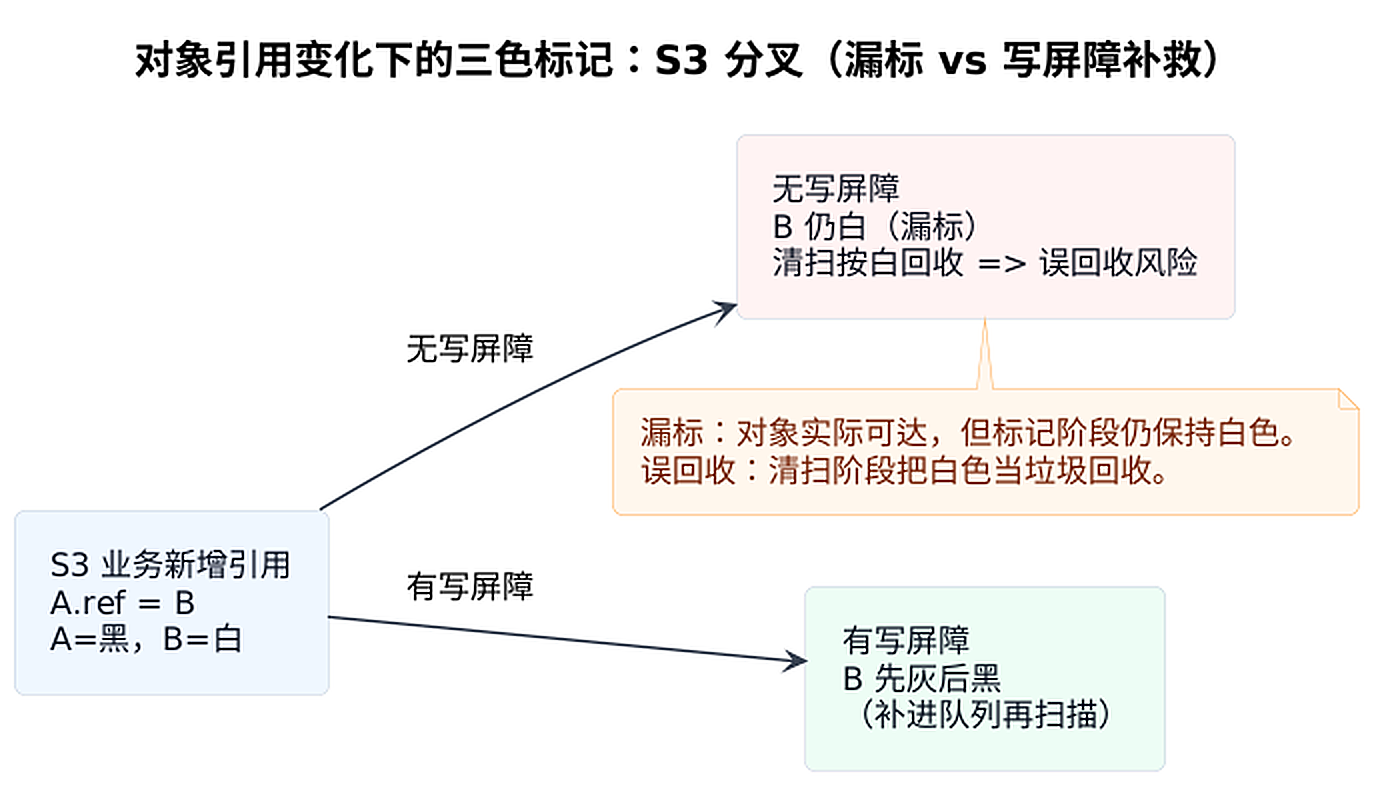
错误示例 1:对象被"误回收"(漏标)
这是并发标记里最危险的一类问题:对象其实已经可达了,但由于并发期间的引用变化,它没有被标出来,最后还留在白色集合里。 如果后续清扫阶段按"白色=垃圾"直接回收,就会出现误回收风险。
这里我不用"集合模拟器"来写代码,而是用更贴近业务写法的"对象引用变化"来讲:你只要关注 A.ref 在并发标记期间是怎么被改掉的。
java
class Obj {
Obj ref;
}
Obj root = new Obj();
Obj A = new Obj();
Obj B = new Obj();
// 初始对象图:root -> A (B 暂时不可达)
root.ref = A;
A.ref = null;
// ===== 并发标记开始(GC 线程)=====
// 初始标记后:A 被发现(灰)
// 随后 GC 扫描完 A 的字段:A 变黑
// 此时(概念上):A = 黑,B 仍可能是 白(还没被扫到)
// ===== 并发标记进行中(业务线程)=====
// 情况 1:在 A 已经变黑之后,业务新增了一条引用 A -> B
// 如果没有写屏障,GC 不会再回头扫 A 的字段,于是 B 可能一直保持白色(漏标 -> 误回收风险)
A.ref = B;
// 这就是"黑色对象直接指向白色对象"可能带来漏标的来源。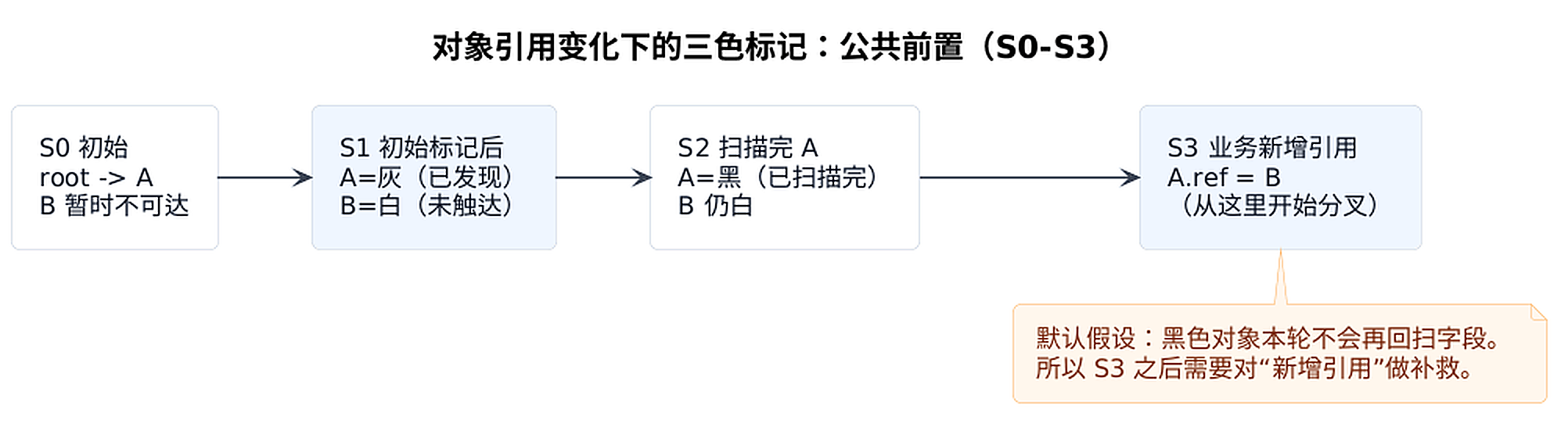
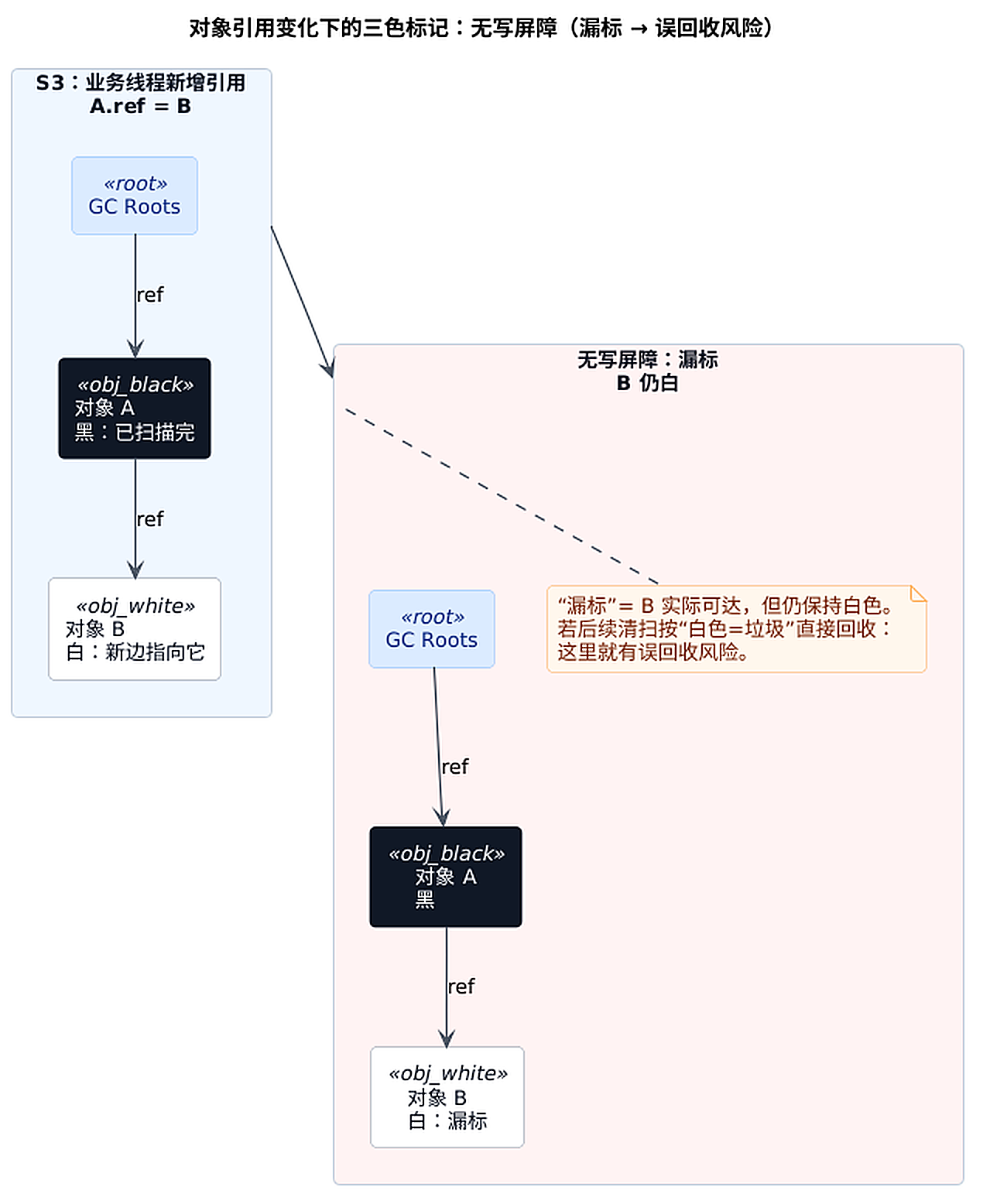
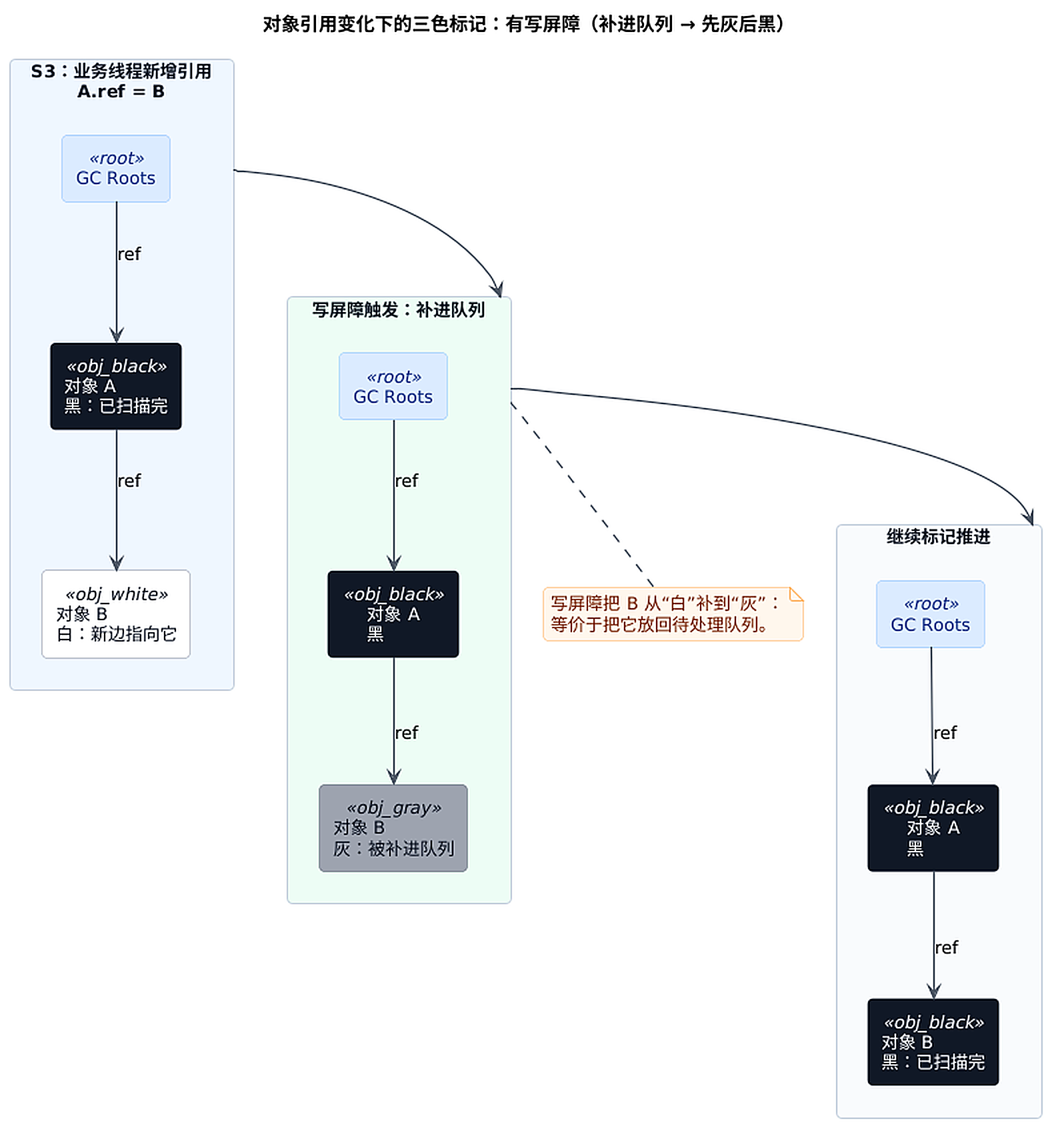
从图里的 S3 开始会分叉:
- 无写屏障:
B仍保持白色(漏标);如果后续清扫阶段按"白色=垃圾"直接回收,就会出现误回收风险 - 有写屏障:
B会被补进标记队列(先灰后黑),漏标被补上
上面这段示意代码对应的逻辑很简单:只要 "A 已经黑了" 这个事实成立,而 GC 又不会回扫黑对象字段,那么"黑对象新增指向白对象"就有机会把 B 藏起来。
这就是三色标记经常被引用的那句"不变量":不要让黑色对象直接指向白色对象长期不被发现。
解决思路:写屏障把"新引用"补回标记队列
并发标记里,问题不是"标记线程不努力",而是它不知道业务线程刚刚写入了哪条新边;所以必须在"写引用"这一下做记录,这类在写入点触发的机制就叫写屏障(write barrier)。
一个最直观的修复思路叫"增量更新":当应用线程把一个引用写进某个对象时,如果发现"黑 -> 白",就立刻把白色对象涂成灰色(也就是补进工作队列)。
在上面那段演示代码里,对应的写屏障就像这样(概念演示,isBlack/isWhite/markGray 都代表 GC 内部状态与动作):
java
// 如果 from 已经被扫描过(黑),而 to 还没被标记(白),就把 to 补进待处理队列(涂灰)
void writeBarrier(Object from, Object to) {
if (gc.isBlack(from) && gc.isWhite(to)) {
gc.markGray(to);
}
}有了这类写屏障,"黑对象写入新引用"这类并发写入就不会漏标:白色对象会被补进灰色集合,最终被标成黑色。
错误示例 2:对象"没有被回收"(浮动垃圾)
到这里你已经看到了一类写屏障的目标:修补"新增引用导致的漏标"。但并发期间还有另一类变化:引用被删除/覆盖。很多收集器会用另一套思路,也就是 SATB(Snapshot At The Beginning,起始快照 / 标记开始时快照),去保证"不误回收",代价就是本轮可能多留下一些浮动垃圾。
并发标记的另一种常见现象不是"误回收",而是"该死的对象本轮没死"。例如标记开始时对象是可达的,但并发标记过程中引用被断开了。为了保证不漏标,收集器可能选择把它先保守地标活,让它变成"浮动垃圾",留到下一轮再回收。
java
// 仍然是同一张对象图:root -> A -> B
root.ref = A;
A.ref = B;
// ===== 并发标记开始(GC 线程)=====
// A、B 先后被发现/扫描(可能变灰、再变黑)
// ===== 并发标记进行中(业务线程)=====
// 情况 2:业务把 A -> B 这条边断开
// 从"此刻起"的业务视角:B 已经不可达了
A.ref = null;
// 但 GC 为了"绝不误回收",很多实现会更像在维护"开始那一刻的快照":
// 它可能仍把 B 当作本轮存活对象,结果就是 B 本轮没回收(浮动垃圾),下一轮再处理。这就是你在 SATB 语境下经常听到的那句直觉:本轮宁可多留(浮动垃圾),也不要误回收。
这类策略通常和"快照式 SATB"思路有关:标记时更像在维护"开始那一刻的可达快照",所以本轮可能会多保留一些对象,换来"不会误回收"的安全性。
你在很多收集器里看到的 重新标记/最终标记,也可以理解成一个"收束点":并发阶段里攒下来的变更记录需要在这里被集中处理完,确保本轮标记闭合。
并发标记阶段的难点不是"算力不够",而是"正确性保障更难";三色标记和写屏障就是为了解决这件事。
收集器为什么会一路演进
前面讲了三种回收算法,也讲了三色标记法在并发标记里怎么保证正确性。接下来才轮到收集器这一层:在线上系统里,回收不只是"能不能做",还要在吞吐、停顿、碎片和并发开销之间做取舍。 收集器演进,本质上就是把这些代价放进不同场景里重新分配。
如果回收算法的差别只是书本上的三种基本思路,Java 也不至于一路长出这么多收集器。真正推动演进的,不是"想把算法名词变多",而是应用场景一直在变。
早期程序堆不大、机器核数不多,能先把垃圾回收这件事稳定做对就已经很重要。后来服务端程序越跑越久、堆越给越大、延迟要求也越来越严格,新的矛盾就冒出来了:吞吐、停顿、碎片、并发开销,不可能永远靠同一套收集器平衡。
所以看收集器演进,最好别把它当成一条版本时间线,而是把它看成一串连续的问题修复。每一代都不是凭空出现,而是在试图解决前一代最难受的那个短板。
如果把这条演进线整体摊开,主脉络大致就是这样:
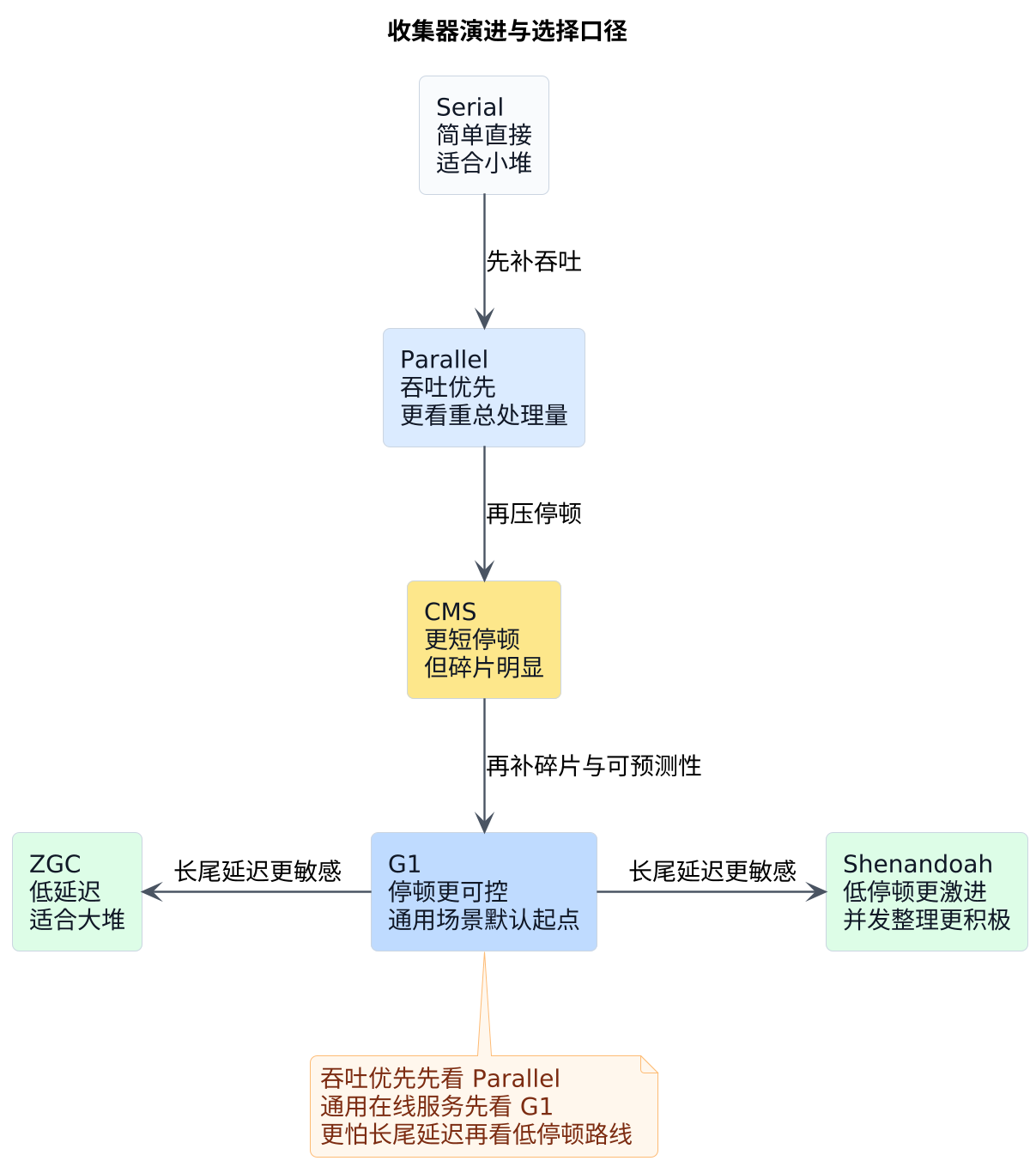
一条主线:把重活从 STW 挪到并发(以及代价怎么转移)
把收集器当成一串名字,最后很容易只剩"背结论"。更稳的读法,是把它们当成在不同约束下做的工程交换:
- 想要更短的停顿,就得把更多工作搬到并发阶段
- 但并发不是白来的:需要更多协调、更复杂的正确性保障,也通常会吃掉更多 CPU
- 老年代越大、对象存活率越高,"碎片"和"搬迁成本"就越绕不过去
所以这条演进线看起来在变"收集器",实际上在变的是:我们愿意把代价从哪里挪到哪里。
| 你想压的痛点 | 常见做法 | 换来的代价 |
|---|---|---|
| 吞吐不够 | 停顿内并行(更多 GC 线程) | 停顿仍在,未必更短 |
| 停顿太长 | 把标记/清扫并发化 | 并发协调成本 + 退化风险 |
| 碎片太难受 | 需要整理 / 需要搬迁 | 搬迁与引用更新成本 |
| 停顿要更稳 | 把回收单元切细并调度 | 实现复杂度更高 |
先解决"能回收"和"吞吐不够"
先抓住 Serial 的定位:先把回收稳定做完,代价是停顿最直接。 它实现简单,回收逻辑清楚,单线程把事情做完。对于小堆、单核或者不太在意停顿的场景,这种办法不一定差。对象不多、堆也不大时,简单往往就是优势,因为系统不需要额外为复杂并发回收付出太多协调成本。
从这里往后,图里会反复出现一些阶段名,先统一一下中文口径。
但先说清楚一点:这些阶段名不是每个收集器都有。 比如 Serial / Parallel 基本没有"并发阶段",也不会出现"初始标记/重新标记/最终标记"这种拆分;它们更多是"停顿内把活一口气做完"。
STW:Stop-The-World,也就是暂停应用线程初始标记:先把直接从GC Roots能摸到的对象快速标出来并发阶段:默认指 GC 线程和应用线程同时进行,不是只表示"有多个 GC 线程一起做事"重新标记:把并发阶段里发生变化的引用再收一遍尾最终标记:把本轮标记阶段正式收束迁移 / 搬迁:把对象挪到新的位置更新引用:把旧地址关系修正到新地址上最终根更新:把根对象握着的旧地址关系也收束到新地址上,作为最后一个短暂停顿收尾
下面这张表列的是"哪些收集器会出现哪些阶段"。
这里把 CMS 也放进来,主要是为了把收集器演进这条线讲完整。它更适合放在"理解历史演进"的语境里看,而不是当成今天的主流默认选型入口。
| 收集器 | 你在图里会看到的典型阶段 | 备注 |
|---|---|---|
Serial / Parallel |
主要就是 STW(停顿内完成标记/清理/整理或复制) |
基本不出现"并发阶段"这类词 |
CMS |
初始标记(STW)-> 并发阶段 -> 重新标记(STW) |
目标是把追踪/清扫搬到并发,但碎片仍是代价 |
G1 |
初始标记(常和年轻代回收合并)-> 并发阶段 -> 重新标记 -> 混合回收 多轮停顿 |
通过 Region 粒度把停顿拆细并纳入调度 |
ZGC |
初始标记(STW)-> 并发阶段 -> 最终标记(STW)-> 迁移(含短暂停顿 + 并发迁移) |
只保留少数切换点,重活尽量并发推进 |
Shenandoah |
初始标记(STW)-> 并发阶段 -> 最终标记(STW)-> 更新引用 / 最终根更新(STW) |
并发搬迁与并发更新引用更激进 |
同样地,"这个收集器主要作用在年轻代还是老年代"也不是一刀切的。下面这张表按常见组合/常见定位给你一个直觉坐标:
| 收集器 | 主要作用区域(常见口径) | 一句话说明 |
|---|---|---|
Serial |
年轻代 + 老年代 | 小堆/简单场景常见,整体偏"停顿内做完" |
Parallel |
年轻代 + 老年代 | 典型吞吐路线,停顿仍在但停顿内并行 |
CMS |
老年代为主 | 通常搭配一个年轻代收集器,核心是老年代并发清扫 |
G1 |
年轻代 + 老年代(全堆 Region) | 通过 Region 粒度分批回收,Mixed GC 会带一部分老年代 |
ZGC |
覆盖整堆(现代 JDK 里也可按分代实现) | 更强调低停顿,这里先突出它的低停顿节奏,不展开分代细节 |
Shenandoah |
覆盖整堆(逻辑上全堆) | 同样偏低停顿,并发搬迁/更新引用更激进 |
从这里开始,图里除了 GC 自己的阶段线,我还额外加了一条应用线程状态线 :绿色表示业务线程还在继续跑,红色表示这一步已经被 STW 暂停。
所以后面图里只要看到绿色并发阶段,默认都在表达同一件事:GC 线程还在做事,应用线程也没有停。
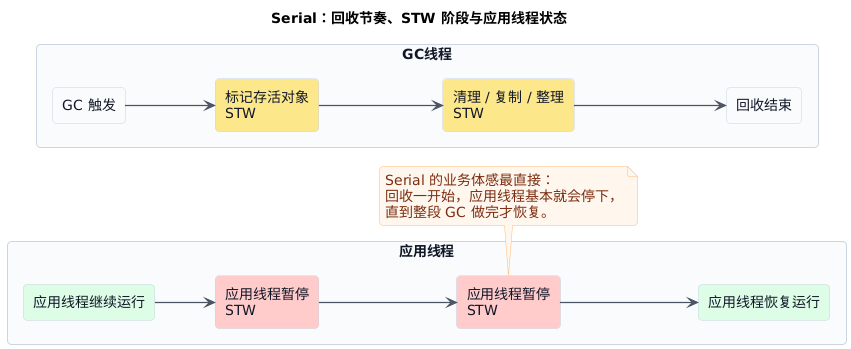
- 触发回收以后,标记、清理、整理这些主要动作几乎都直接落在一次停顿里
- 这也是它实现简单的原因:不用为复杂的并发阶段付出额外协调成本
- 代价同样很直接:一旦堆变大或对象变多,停顿就会更集中地落到业务线程头上
记 Serial 就抓一句:逻辑最直、实现最简单,但停顿也最不遮掩。
再看 Parallel,先抓它的定位:停顿还在,但停顿里的 GC 工作改成多线程并行,目标是把总吞吐顶上去。 机器核数上来、吞吐要求上来之后,瓶颈就从"能不能回收"变成了"回收线程跟不跟得上应用本身的分配速度"。Parallel 收集器做的事情也很朴素:既然回收本身是重活,那就让更多线程一起干,优先把总处理能力顶上去。
这类思路特别适合吞吐优先 的场景。停顿依然存在,但目标不是把停顿压到极低,而是让应用整体完成更多工作。换句话说,Parallel 解决的是"GC 太慢、总效率不够"的问题,不是"停顿必须足够短"的问题。
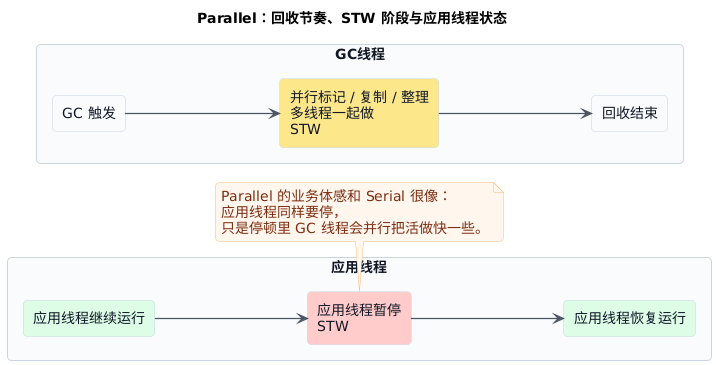
Parallel并没有拿掉停顿,它只是把停顿里的回收工作改成多线程一起做- 所以它优化的主要是总处理能力,而不是把一次停顿压得特别短
- 这也解释了为什么它更适合吞吐优先,而不是延迟特别敏感的系统
记 Parallel 就抓一句:它解决的是"GC 太慢",不是"停顿太长"。
CMS 为什么不再是终点
当应用从批处理、单机任务慢慢转到更典型的在线服务后,另一个问题开始变得刺眼:有时候系统总吞吐并不差,但一次偏长的停顿就足以把延迟打花。
先抓 CMS 的定位:开始明确转向低停顿,把一部分老年代工作挪到并发阶段。 它的核心诉求不是把回收做得最省 CPU,而是尽量缩短停顿,让更多工作和应用线程并发进行。对服务端系统来说,这种方向非常有吸引力,因为它直接回应了"接口别一下卡住太久"这个现实问题。
但 CMS 也有自己的代价:
- 没有很好地解决碎片整理
- 并发回收本身也不是免费的
- 系统要为更复杂的协调和额外 CPU 成本买单
所以 CMS 的意义很大,但它并没有把问题彻底做完。它证明了"低停顿值得追",也把后面的路线进一步逼了出来:如果既想控制停顿,又不想长期背着碎片问题走,那还得继续往前。
如果只从 STW 分布看,CMS 的思路就会非常清楚:把最重的追踪和清扫尽量搬到并发阶段,只把两个关键收束点留在停顿里。
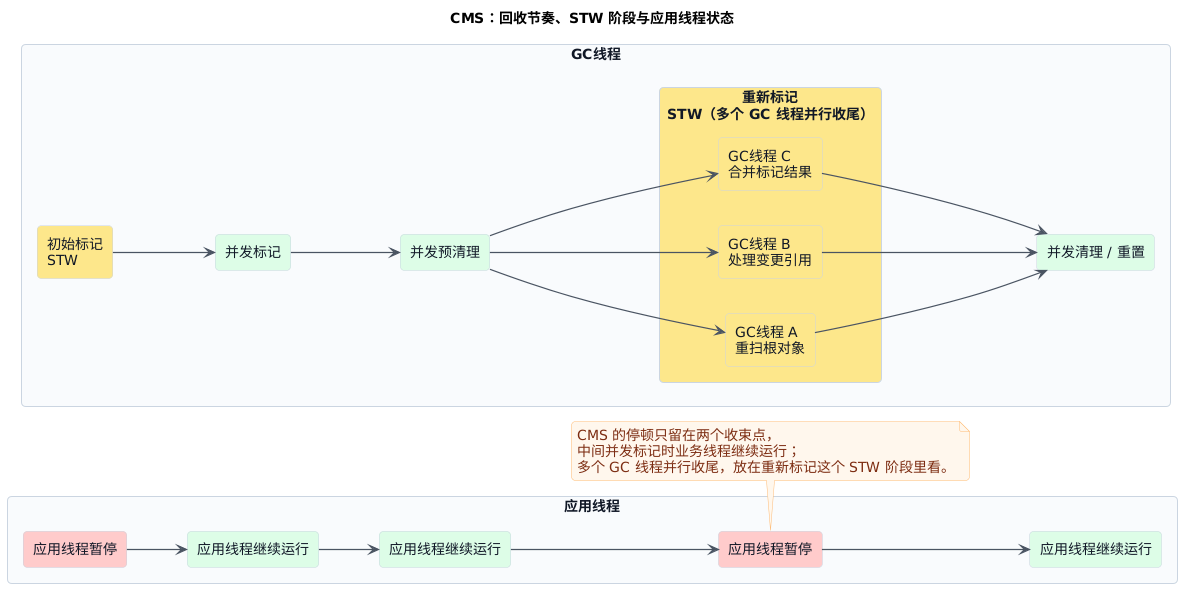
- 核心目标:先把老年代回收从"整段长停顿"改成"只有少数收束点停顿"
- 主要做法:
初始标记和重新标记保留在STW,中间的标记和清扫尽量并发 - 主要代价:碎片问题没有解决,并发回收跟不上时还可能退化
记 CMS 就抓一句:它先把停顿压下来了,但还背着碎片和退化风险。
一旦回收从停顿内转向并发,核心难点就不再只是速度,而是并发期间如何保证标记正确性。前面单独展开的三色标记法,解决的就是这里的问题。
前面那章三色标记法,正好可以对回这里:在 CMS / G1 里常写作 重新标记,在 ZGC / Shenandoah 里常写作 最终标记,它们都是并发标记后的收束点。
G1 为什么成了主流默认
先抓 G1 的定位:不是单纯继续压停顿,而是开始追求"停顿更可控、更可预测"。 它的关键,不是先谈"默认",而是先把堆管理粒度从"按代大块处理"改成"按 Region 分批调度"。有了这个基础,后面你看到的 Mixed GC 和"停顿更可预测"才真正成立。
G1 之所以重要,不是因为它第一次提出了某个全新的回收动作,而是因为它在工程上给出了一套更均衡的答案。
它的核心思路有两点。
- 第一,不再把堆看成几块特别粗的区域,而是拆成很多更细的分区来管理。
- 第二,不再只盯"把垃圾清掉",而是开始显式地把停顿目标也纳入调度考虑。
这意味着 G1 处理的,已经不是单个算法问题,而是一个更现实的综合问题:在有限停顿预算里,优先回收哪些分区,怎样一边回收一边尽量维持总体吞吐和空间可用性。
到了 G1,收集器演进的主线已经从"能不能回收"变成了"能不能更可预测地回收"。对大量线上业务来说,这比追求某个单点指标的极致更实际。
它不追求像吞吐型收集器那样把总效率压到极致,也不一味地为了低停顿把所有代价都推高。正因为这种平衡感,G1 很适合大多数通用服务场景 。官方文档也明确把它作为现代 HotSpot JVM 中大多数硬件和操作系统配置下的默认选择。
如果把 G1 拆成 STW 节奏来看,它并不是"只有很少几次停顿",而是把停顿切成更可控、更分散的几段。
G1 的堆为什么切成 Region(以及 Mixed GC 为什么成立)
前几代收集器常见的堆直觉是"年轻代一块、老年代一块"。这种划分简单直接,但它也意味着:老年代一旦变大,很多决策容易变成"要么不收、要么收一大块"。
G1 做的关键一步,是把整堆切成很多大小相同的 Region。分代仍然存在,但它不再依赖两块连续大区,而是让不同 Region 在当前阶段扮演 Eden / Survivor / Old 等角色。

| 维度 | 传统分代连续区(Serial / Parallel / CMS 常见形态) | G1 Region |
|---|---|---|
| 基本管理单元 | 连续大区 | 大量等大小 Region |
| 分代的落点 | 通过大区边界体现 | 通过 Region 的"角色"体现 |
| 回收决策粒度 | 更像"按代/按大区" | 更像"按 Region 价值分批" |
Mixed GC 体感 |
不太突出"顺带回收一部分老年代" | 回收一批年轻代 + 选中的老年代 Region |
| 大对象(Humongous) | 常见实现需要单独处理策略 | G1 里会有专门的 Humongous Region 口径 |
所以 G1 的优势不是"完全没有停顿",而是:把回收单元切细到 Region 粒度后,更容易围绕停顿目标做调度。
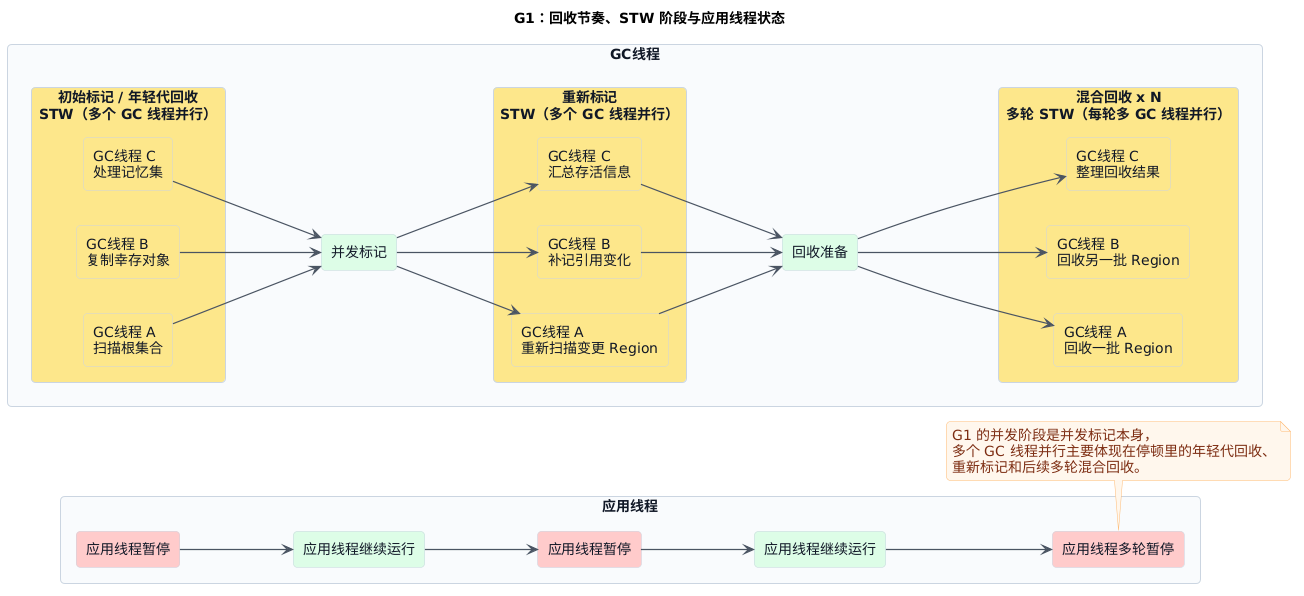
- 核心目标:不是单纯继续压停顿,而是让停顿更可控、更可预测
- 主要做法:用
Region切细回收单元,保留初始标记 / 重新标记,再把后续回收拆成多轮Mixed GC - 主要代价:实现更复杂,停顿并没有消失,只是被拆细并纳入调度
记 G1 就抓一句:它不追求绝对最短,而是让停顿更容易控。
ZGC 和 Shenandoah 还在继续压什么
即便如此,G1 也没有让所有场景都满意。只要堆继续变大、延迟目标继续收紧,就还是会有人觉得停顿不够短,或者不够稳定。
如果把 G1 看作"停顿更可预测",那 ZGC 和 Shenandoah 继续追的,就是"把停顿进一步压短,而且尽量别随着堆变大一起拖长"。它们的共同方向都很明确:把更多本来容易造成停顿的工作继续并发化,尽量让应用线程少停、短停;差别则主要体现在并发搬迁、引用更新这些动作组织得有多激进。
这类收集器解决的问题,比 CMS 当年还更激进。它们不是简单追求"比以前短一点",而是在低停顿目标上进一步往前压。官方资料里,ZGC 的定位就是低延迟、大堆、停顿时间尽量与堆大小解耦;Shenandoah 也明确把"更稳定的短停顿"作为核心目标。
代价也很明确。更激进的并发回收,通常意味着:
- 实现更复杂
- 额外开销更高
- 吞吐和资源占用未必像更传统的收集器那样好看
所以它们不是默认适合所有系统,而是更适合那些把响应时间放在非常靠前位置的场景。
先抓 ZGC 的定位:继续压低停顿,把大部分重活留在并发阶段,只保留少数很短的切换点。 它不是彻底消灭停顿,而是努力把 STW 压缩成几个很短的切换点。这里为了突出它的停顿组织方式,先按低停顿阶段来讲,不把分代细节展开到这张图里。
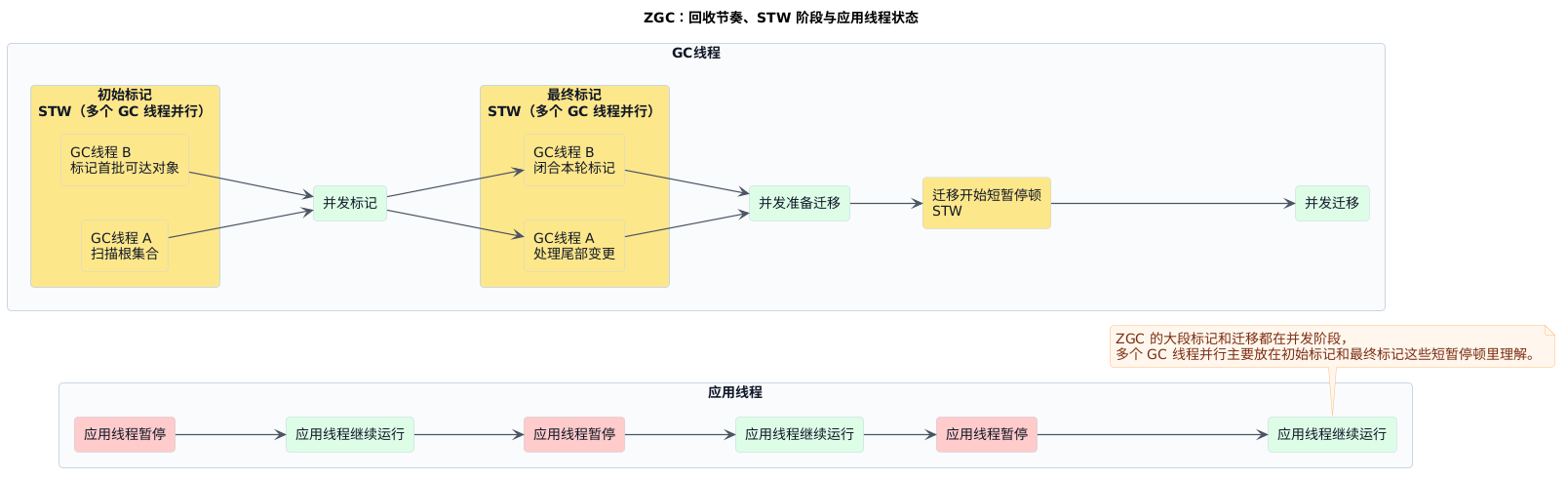
- 核心目标:把停顿进一步压短,并尽量别随着堆变大一起拖长
- 主要做法:只保留
初始标记 / 最终标记 / 迁移开始这些短切换点,把标记和迁移重活尽量放进并发阶段 - 主要代价:实现复杂,并发开销更高,对资源条件也更挑剔
记 ZGC 就抓一句:它追求的不是没有停顿,而是让停顿短到不再随着堆一起明显变长。
再看 Shenandoah,先抓它的定位:低停顿方向更激进,连搬迁和更新引用都尽量往并发阶段挪。 从 STW 图上也能看出来:它不只并发标记,还尽量把 对象搬迁 / 更新引用 这些重活一起搬到并发阶段。
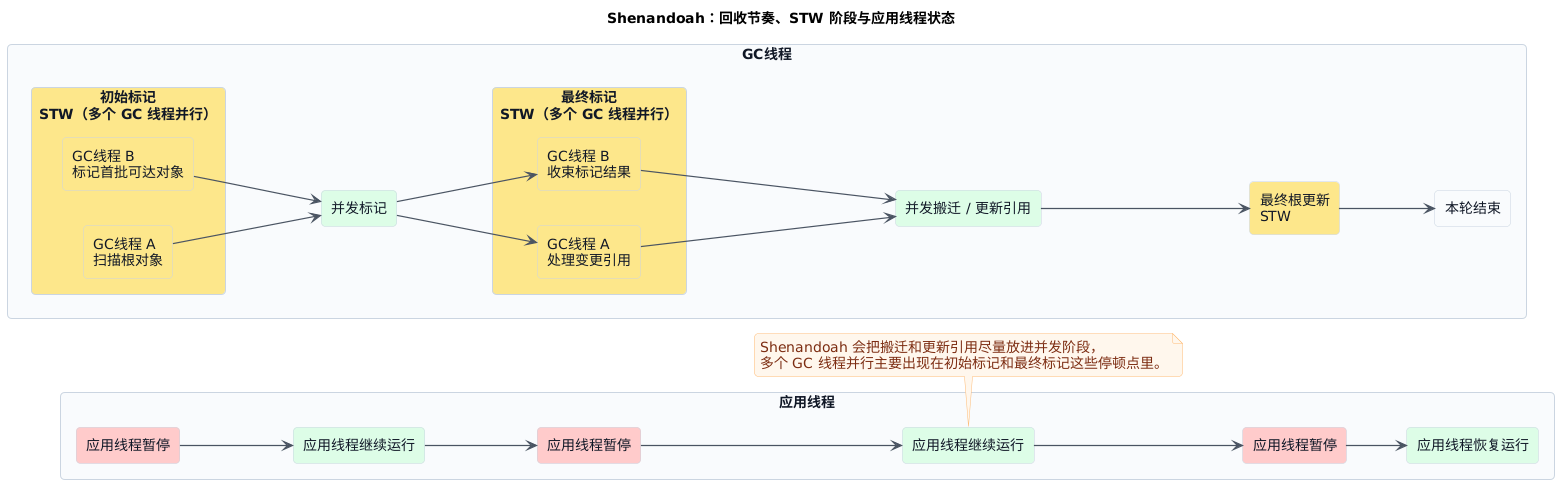
- 核心目标:继续追低停顿,并把整理这件事也尽量并发化
- 主要做法:除了并发标记,还把并发搬迁和并发更新引用一起往前推
- 主要代价:并发 CPU 和空间开销更高,实现复杂度也更重
记 Shenandoah 就抓一句:它和 ZGC 一样追低停顿,但在并发整理这件事上走得更深。

Serial / Parallel:核心目标是先把回收做稳、把吞吐顶上去;主要做法是把回收主体留在STW里,其中Parallel再把停顿内的工作并行化CMS:核心目标是先压低老年代停顿;主要做法是把标记和清扫尽量放进并发阶段,只把初始标记 / 重新标记留作收束点G1:核心目标是让停顿更可控;主要做法是把堆切成Region,再把初始标记 / 重新标记 / 混合回收拆成更可预测的多段节奏ZGC / Shenandoah:核心目标是继续追低停顿;主要做法是把更重的标记、迁移和整理动作继续往并发阶段搬,只保留少数短切换点
六种收集器的对比表如下:
| 收集器 | 核心目标 | 主要做法 | 主要代价 | 记一句 |
|---|---|---|---|---|
Serial |
先把回收稳定做完 | 基本把标记、清理、整理都放在一次 STW 里,由单线程完成 |
堆一大,停顿就容易很集中 | 逻辑最直、实现最简单,但停顿也最不遮掩 |
Parallel |
把总吞吐顶上去 | 停顿仍在,但把停顿里的 GC 工作改成多线程并行 | 停顿未必短,不适合强延迟诉求 | 它解决的是"GC 太慢",不是"停顿太长" |
CMS |
先把老年代回收从整段长停顿改成少数收束点停顿 | 初始标记 / 重新标记 留在 STW,中间的标记和清扫尽量并发 |
碎片问题没有解决,并发回收跟不上时还可能退化 | 它先把停顿压下来了,但还背着碎片和退化风险 |
G1 |
让停顿更可控、更可预测 | 用 Region 切细回收单元,保留 初始标记 / 重新标记,再把后续回收拆成多轮 Mixed GC |
实现更复杂,停顿没有消失,只是被拆细并纳入调度 | 它不追求绝对最短,而是让停顿更容易控 |
ZGC |
把停顿进一步压短,并尽量别随着堆变大一起拖长 | 只保留 初始标记 / 最终标记 / 迁移开始 这些短切换点,把标记和迁移重活尽量放进并发阶段 |
实现复杂,并发开销更高,对资源条件也更挑剔 | 它追求的不是没有停顿,而是让停顿短到不再随着堆一起明显变长 |
Shenandoah |
继续追低停顿,并把整理这件事也尽量并发化 | 除了并发标记,还把并发搬迁和并发更新引用一起往前推 | 并发 CPU 和空间开销更高,实现复杂度也更重 | 它和 ZGC 一样追低停顿,但在并发整理这件事上走得更深 |
从
CMS到G1,再到ZGC / Shenandoah,真正变化的不是"会不会回收",而是"把多少重活留在停顿里,又把多少重活搬到并发阶段"。
收集器演进主线
收集器演进的主线如下:
Serial:先把回收稳定做完,适合简单和小规模场景Parallel:优先把吞吐顶上去CMS:开始明显转向低停顿诉求G1:在停顿、吞吐和空间整理之间做更均衡的工程权衡ZGC / Shenandoah:继续把低停顿目标往前推进
所以收集器演进真正想说明的,不是"新的一定全面替代旧的",而是应用关心的指标变了,收集器的最优解也会跟着变。
回到怎么选
到这里,判活、分代、算法和收集器演进已经能连成一条线。最后一步不是再记一遍名词,而是把这条主线压成几条能落地的选型判断。
吞吐优先和停顿优先怎么选
- 如果系统最看重的是总吞吐,而且可以接受更长一些的停顿,思路通常会偏向
Parallel这类更强调整体效率的方案 - 如果系统是更典型的在线服务,希望在大多数情况下把停顿控制得更稳,
G1往往是更自然的起点 - 如果系统对长尾延迟特别敏感,堆又比较大,关注点才会继续往
ZGC、Shenandoah这类更强调低停顿的路线走
这几条判断背后其实都是同一个问题:当前系统最怕失去什么。
- 有的系统怕总处理能力不够
- 有的系统怕一次停顿太长
- 有的系统怕堆越来越大以后停顿形态失控
收集器的选择,不是先背结论,而是先把这个"最怕什么"想清楚。
先想清系统最怕失去什么,再选收集器。
最后只留三件事
GC的第一步永远是判活,不是上来就删对象- 分代回收成立,不是因为堆天生该分年轻代和老年代,而是因为对象寿命本来就不平均
- 收集器一路演进,核心始终没变:围绕吞吐、停顿、碎片和并发开销这几种代价,换一个更适合当前场景的平衡点
如果再回到这篇文章的理解主线,顺序还是这三步:先看对象怎么判活,再看分代和回收节奏怎么设计,最后再看当前业务到底更怕吞吐掉下来,还是更怕停顿拉长。
如果真到线上排查 GC 卡顿,第一反应通常还是先看 GC 日志、停顿类型、回收频率和堆占用,而不是先做对象可达性分析。
Java GC不是在追求一个永远最强的收集器,而是在不同代价之间不断找平衡。
再回头看开头那个"服务突然卡一下"的现象,排查路径可以直接落成三步:
- 先看对象还能不能从
GC Roots走到 - 再看它会落在哪一代、适合哪种回收策略
- 最后再看当前系统更在意吞吐还是停顿
先判活,再回收;先分代,再选择收集器。把这条线抓住,
Java GC就不会再像一堆零散名词。