摘要 ------块项分解 (BTD),特别是其秩为 ( L r , L r , 1 ) (L_r, L_r, 1) (Lr,Lr,1) 的特例,在信号处理中得到了广泛应用。计算 BTD 的传统方法要么不切实际地假设块的数量和块秩是已知的,要么需要对这些参数进行穷举式的调整。虽然已经引入了促进稀疏性的正则化来更有效地估计这些参数,但它仍然需要调整正则化参数。
贝叶斯学习通过对块数和块秩采用促进稀疏性的先验来解决这些问题,但到目前为止,它仅限于完全观测的 BTD 张量。为了处理不完整的 BTD 张量,目前仅提出了少数基于优化的方法,并且它们仍然受到繁重参数调整的困扰。为了实现免调参的 BTD 补全,在贝叶斯框架内引入了一种先验,该先验在结合图结构的同时,强制实现块级稀疏性(block-wise sparsity)和块内列级稀疏性(within block column-wise sparsity)。
除了在理论上确立该先验分布的合理性之外(the legitimacy of the prior distribution),还开发了一种平均场设计(a mean-field design),从而获得了一种在不丢失图信息的情况下的闭式更新 变分推断 (variational inference,VI) 算法。
在合成数据集和真实世界数据集上进行的大量实验均表明,所提出的方法在秩学习、张量恢复和因子恢复方面,优于现有的基于优化的算法以及未包含图信息的贝叶斯模型(the Bayesian model without graph information)。
索引词------块项分解,张量补全,贝叶斯学习,图信息,免调参。
文章目录
-
- [II. PRELIMINARIES](#II. PRELIMINARIES)
-
- [A. Notation for LL1 Tensors](#A. Notation for LL1 Tensors)
- [B. Sparsity-promoting Regularization for LL1 Tensors 44](#B. Sparsity-promoting Regularization for LL1 Tensors [44])
- [III. BAYESIAN MODEL](#III. BAYESIAN MODEL)
-
- [A. Prior Distribution and Analysis](#A. Prior Distribution and Analysis)
- [B. Completion Likelihood and Joint Distribution](#B. Completion Likelihood and Joint Distribution)
- [IV. INFERENCE ALGORITHM](#IV. INFERENCE ALGORITHM)
-
- [A. General Philosophy of Variational Inference](#A. General Philosophy of Variational Inference)
- [B. Mean-Field Design](#B. Mean-Field Design)
II. PRELIMINARIES
A. Notation for LL1 Tensors
为了简化 LL1 张量的符号,因子矩阵被拼接为 A = A 1 , ... , A R ∈ R I × ∑ r = 1 R L r \mathbf{A} = \\mathbf{A}_1, \\dots, \\mathbf{A}_R \in \mathbb{R}^{I \times \sum_{r=1}^R L_r} A=A1,...,AR∈RI×∑r=1RLr , B = B 1 , ... , B R ∈ R J × ∑ r = 1 R L r \mathbf{B} = \\mathbf{B}_1, \\dots, \\mathbf{B}_R \in \mathbb{R}^{J \times \sum_{r=1}^R L_r} B=B1,...,BR∈RJ×∑r=1RLr ,以及 C = c 1 , ... , c R ∈ R K × R \mathbf{C} = \\mathbf{c}_1, \\dots, \\mathbf{c}_R \in \mathbb{R}^{K \times R} C=c1,...,cR∈RK×R 。
此外,当三维 LL1 张量 X \boldsymbol{\mathcal{X}} X 沿不同模态展开时,它们可以写为:
X ( 1 ) = vec ( X 1 , : , : ) , ... , vec ( X I , : , : ) = c 1 ⊗ B 1 ; ... ; c R ⊗ B R A ⊤ ≜ P A ⊤ ∈ R J K × I , (2) \begin{aligned} \mathbf{X}_{(1)} &= \\text{vec}(\\boldsymbol{\\mathcal{X}}_{1,:,:}), \\dots, \\text{vec}(\\boldsymbol{\\mathcal{X}}_{I,:,:}) \\ &= \\mathbf{c}_1 \\otimes \\mathbf{B}_1; \\dots; \\mathbf{c}_R \\otimes \\mathbf{B}_R \mathbf{A}^\top \triangleq \mathbf{P} \mathbf{A}^\top \in \mathbb{R}^{JK \times I}, \end{aligned} \tag{2} X(1)=vec(X1,:,:),...,vec(XI,:,:)=c1⊗B1;...;cR⊗BRA⊤≜PA⊤∈RJK×I,(2)
X ( 2 ) = vec ( X : , 1 , : ) , ... , vec ( X : , J , : ) = c 1 ⊗ A 1 ; ... ; c R ⊗ A R B ⊤ ≜ Q B ⊤ ∈ R I K × J , (3) \begin{aligned} \mathbf{X}_{(2)} &= \\text{vec}(\\boldsymbol{\\mathcal{X}}_{:,1,:}), \\dots, \\text{vec}(\\boldsymbol{\\mathcal{X}}_{:,J,:}) \\ &= \\mathbf{c}_1 \\otimes \\mathbf{A}_1; \\dots; \\mathbf{c}_R \\otimes \\mathbf{A}_R \mathbf{B}^\top \triangleq \mathbf{Q} \mathbf{B}^\top \in \mathbb{R}^{IK \times J}, \end{aligned} \tag{3} X(2)=vec(X:,1,:),...,vec(X:,J,:)=c1⊗A1;...;cR⊗ARB⊤≜QB⊤∈RIK×J,(3)
X ( 3 ) = vec ( X : , : , 1 ) , ... , vec ( X : , : , K ) = vec ( A 1 B 1 ⊤ ) , ... , vec ( A R B R ⊤ ) C ⊤ ≜ S C ⊤ ∈ R I J × K , (4) \begin{aligned} \mathbf{X}_{(3)} &= \\text{vec}(\\boldsymbol{\\mathcal{X}}_{:,:,1}), \\dots, \\text{vec}(\\boldsymbol{\\mathcal{X}}_{:,:,K}) \\ &= \\text{vec}(\\mathbf{A}_1 \\mathbf{B}_1\^\\top), \\dots, \\text{vec}(\\mathbf{A}_R \\mathbf{B}_R\^\\top) \mathbf{C}^\top \\ &\triangleq \mathbf{S} \mathbf{C}^\top \in \mathbb{R}^{IJ \times K}, \end{aligned} \tag{4} X(3)=vec(X:,:,1),...,vec(X:,:,K)=vec(A1B1⊤),...,vec(ARBR⊤)C⊤≜SC⊤∈RIJ×K,(4)
其中 ⊗ \otimes ⊗ 表示克罗内克积,矩阵 P ∈ R J K × ∑ r = 1 R L r \mathbf{P} \in \mathbb{R}^{JK \times \sum_{r=1}^R L_r} P∈RJK×∑r=1RLr , Q ∈ R I K × ∑ r = 1 R L r \mathbf{Q} \in \mathbb{R}^{IK \times \sum_{r=1}^R L_r} Q∈RIK×∑r=1RLr , S ∈ R I J × R \mathbf{S} \in \mathbb{R}^{IJ \times R} S∈RIJ×R 被定义为张量展开的左因子。
B. Sparsity-promoting Regularization for LL1 Tensors 44
在优化框架中,可以通过最初高估块数 R R R 和块秩 { L r } r = 1 R \{L_r\}_{r=1}^R {Lr}r=1R ,随后使用促进稀疏性正则化(sparsity-promoting regularization)将它们减少到最优值来实现秩估计。具体而言,给定一个不完整张量 Y ∈ R I × J × K \boldsymbol{\mathcal{Y}} \in \mathbb{R}^{I \times J \times K} Y∈RI×J×K ,其观测索引在集合 O \mathcal{O} O 中,文献 44 构建了以下优化问题以联合估计因子矩阵和秩:
min A , B , C ∑ ( i , j , k ) ∈ O ( Y i , j , k − X i , j , k ) 2 + λ ∑ r = 1 R ∥ C : , r ∥ 2 2 + ( ∑ l r = 1 L r ∥ A r : , l r ∥ 2 2 + ∥ B r : , l r ∥ 2 2 + η 2 ) 2 + η 2 (5) \min_{\mathbf{A},\mathbf{B},\mathbf{C}} \sum_{(i,j,k) \in \mathcal{O}} (\boldsymbol{\mathcal{Y}}{i,j,k} - \boldsymbol{\mathcal{X}}{i,j,k})^2 + \lambda \sum_{r=1}^R \sqrt{ \|\mathbf{C}{:,r}\|2^2 + \left( \sum{l_r=1}^{L_r} \sqrt{ \|\\mathbf{A}_r{:,l_r}\|2^2 + \|\\mathbf{B}_r{:,l_r}\|_2^2 + \eta^2 } \right)^2 + \eta^2 } \tag{5} A,B,Cmin(i,j,k)∈O∑(Yi,j,k−Xi,j,k)2+λr=1∑R∥C:,r∥22+(lr=1∑Lr∥Ar:,lr∥22+∥Br:,lr∥22+η2 )2+η2 (5)
其中 X \boldsymbol{\mathcal{X}} X 在式 (1) 中定义, λ \lambda λ 是正则化参数, η 2 \eta^2 η2 是一个小的正常数以确保目标函数的平滑性。正则化项促进了两个级别的稀疏性:
- 块内列级稀疏性,它在 A r : , l r \\mathbf{A}_r{:,l_r} Ar:,lr 和 B r : , l r \\mathbf{B}_r{:,l_r} Br:,lr 中强制产生零列;
- 以及块级稀疏性,反映在列 C : , r \mathbf{C}_{:,r} C:,r 中并与 A r \mathbf{A}_r Ar 和 B r \mathbf{B}_r Br 中的所有列耦合。
这两个级别的稀疏性分别有助于估计块秩 { L r } r = 1 R \{L_r\}_{r=1}^R {Lr}r=1R 和块数 R R R 。
问题 (5) 可以通过带有 HIRLS 更新的块连续上界最小化 (a a block successive upper bound minimization,BSUM) 框架来解决,从而得出文献 44 中的 BTD-HIRLS-TC(abbreviated as HIRLS in the following,以下简称为 HIRLS)算法。
然而,由于每个不完整张量 Y \boldsymbol{\mathcal{Y}} Y 的最佳正则化参数是不同的,为了获得最佳性能而调整式 (5) 中的正则化参数 λ \lambda λ 是极其耗时的。此外,仅仅学习 BTD 结构和参数可能不足以产生令人满意的性能,特别是在观测数据有限或噪声功率较高的情况下(仿真结果将在第五节中呈现)。在这些情况下,促进稀疏性的正则化是不够的,突出了结合额外辅助信息(例如,图信息,graph information)的需求。
III. BAYESIAN MODEL
A. Prior Distribution and Analysis
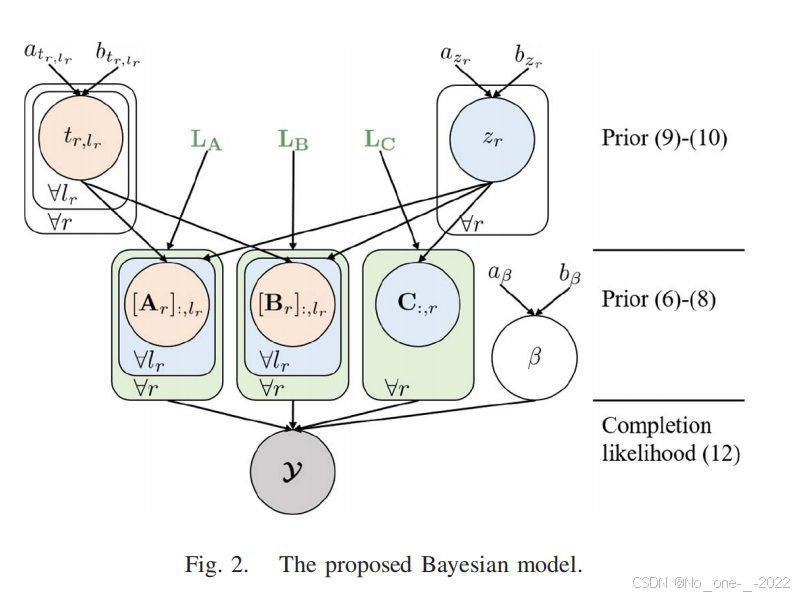
为了估计未知的块数 R R R 和块秩 { L r } r = 1 R \{L_r\}_{r=1}^R {Lr}r=1R ,并同时融入图信息,先验分布从文献 42 扩展而来,其中因子矩阵 A \mathbf{A} A 的先验被指定为
p ( A ∣ T , Z ) = M N ( A ∣ 0 I × ∑ r = 1 R L r , L A − 1 , Z b − 1 T − 1 ) , (6) p(\mathbf{A}|\mathbf{T}, \mathbf{Z}) = \mathcal{MN} \left( \mathbf{A} | \mathbf{0}{I \times \sum{r=1}^R L_r}, \mathbf{L}_{\mathbf{A}}^{-1}, \left\\mathbf{Z}\^b\\right^{-1} \mathbf{T}^{-1} \right), \tag{6} p(A∣T,Z)=MN(A∣0I×∑r=1RLr,LA−1,Zb−1T−1),(6)
其中 M N ( X ∣ M , U , V ) \mathcal{MN}(\mathbf{X}|\mathbf{M}, \mathbf{U}, \mathbf{V}) MN(X∣M,U,V) 表示随机矩阵 X \mathbf{X} X 上的矩阵正态分布(a matrix normal distribution),由均值矩阵 M \mathbf{M} M 、行协方差矩阵 U \mathbf{U} U 和列协方差矩阵 V \mathbf{V} V 参数化,其概率密度函数 (the probability density function,pdf) 为 M N ( X ∣ M , U , V ) ∝ exp ( − 1 / 2 Tr V − 1 ( X − M ) ⊤ U − 1 ( X − M ) ) \mathcal{MN}(\mathbf{X}|\mathbf{M}, \mathbf{U}, \mathbf{V}) \propto \exp(-1/2 \text{Tr}\\mathbf{V}\^{-1}(\\mathbf{X} - \\mathbf{M})\^\\top \\mathbf{U}\^{-1}(\\mathbf{X} - \\mathbf{M})) MN(X∣M,U,V)∝exp(−1/2TrV−1(X−M)⊤U−1(X−M))
在式 (6) 中,
- 列精度矩阵(column precision matrix,协方差矩阵的逆)为 T Z b \mathbf{T}\mathbf{Z}^b TZb ,其中对角矩阵 T = diag { t 1 , 1 , ... , t 1 , L 1 , ... , t R , 1 , ... , t R , L R } ∈ R ∑ r = 1 R L r × ∑ r = 1 R L r \mathbf{T} = \text{diag}\{t_{1,1}, \dots, t_{1,L_1}, \dots, t_{R,1}, \dots, t_{R,L_R}\} \in \mathbb{R}^{\sum_{r=1}^R L_r \times \sum_{r=1}^R L_r} T=diag{t1,1,...,t1,L1,...,tR,1,...,tR,LR}∈R∑r=1RLr×∑r=1RLr 负责块内列级稀疏性,
- 而对角矩阵 Z b = diag { z 1 1 L 1 × 1 , ... , z R 1 L R × 1 } ∈ R ∑ r = 1 R L r × ∑ r = 1 R L r \mathbf{Z}^b = \text{diag}\{z_1 \mathbf{1}{L_1 \times 1}, \dots, z_R \mathbf{1}{L_R \times 1}\} \in \mathbb{R}^{\sum_{r=1}^R L_r \times \sum_{r=1}^R L_r} Zb=diag{z11L1×1,...,zR1LR×1}∈R∑r=1RLr×∑r=1RLr 是处理块级稀疏性的矩阵 Z = diag { z 1 , ... , z R } ∈ R R × R \mathbf{Z} = \text{diag}\{z_1, \dots, z_R\} \in \mathbb{R}^{R \times R} Z=diag{z1,...,zR}∈RR×R 的块扩展。
- 行精度矩阵 L A \mathbf{L}_{\mathbf{A}} LA 是一个已知的正定矩阵,用于嵌入图信息,例如图拉普拉斯矩阵。
为了对因子矩阵 B \mathbf{B} B 施加相同的稀疏模式, B \mathbf{B} B 的列精度矩阵被设置为与因子矩阵 A \mathbf{A} A 相同,而相应的图信息则通过一个已知的行精度矩阵 L B \mathbf{L}_{\mathbf{B}} LB 嵌入,
p ( B ∣ T , Z ) = M N ( B ∣ 0 J × ∑ r = 1 R L r , L B − 1 , Z b − 1 T − 1 ) . (7) p(\mathbf{B}|\mathbf{T}, \mathbf{Z}) = \mathcal{MN} \left( \mathbf{B} | \mathbf{0}{J \times \sum{r=1}^R L_r}, \mathbf{L}_{\mathbf{B}}^{-1}, \left\\mathbf{Z}\^b\\right^{-1} \mathbf{T}^{-1} \right). \tag{7} p(B∣T,Z)=MN(B∣0J×∑r=1RLr,LB−1,Zb−1T−1).(7)
对于因子矩阵 C \mathbf{C} C ,仅施加了块级稀疏性,从而得到
p ( C ∣ Z ) = M N ( C ∣ 0 K × R , L C − 1 , Z − 1 ) , (8) p(\mathbf{C}|\mathbf{Z}) = \mathcal{MN} \left( \mathbf{C} | \mathbf{0}{K \times R}, \mathbf{L}{\mathbf{C}}^{-1}, \mathbf{Z}^{-1} \right), \tag{8} p(C∣Z)=MN(C∣0K×R,LC−1,Z−1),(8)
其中行精度矩阵为已知矩阵 L C \mathbf{L}_{\mathbf{C}} LC 。
由于 T \mathbf{T} T 和 Z \mathbf{Z} Z 中的精度参数未知,因此这些参数在贝叶斯框架内联合学习,它们的先验被建模为伽马分布:
p ( T ) = ∏ r = 1 R ∏ l r = 1 L r Ga ( t r , l r ∣ a t r , l r 0 , b t r , l r 0 ) , (9) p(\mathbf{T}) = \prod_{r=1}^R \prod_{l_r=1}^{L_r} \text{Ga} \left( t_{r,l_r} | a_{t_{r,l_r}}^0, b_{t_{r,l_r}}^0 \right), \tag{9} p(T)=r=1∏Rlr=1∏LrGa(tr,lr∣atr,lr0,btr,lr0),(9)
p ( Z ) = ∏ r = 1 R Ga ( z r ∣ a z r 0 , b z r 0 ) , (10) p(\mathbf{Z}) = \prod_{r=1}^R \text{Ga} \left( z_r | a_{z_r}^0, b_{z_r}^0 \right), \tag{10} p(Z)=r=1∏RGa(zr∣azr0,bzr0),(10)
其中超参数 { a t r , l r 0 , b t r , l r 0 } l r = 1 , r = 1 L r , R \{a_{t_{r,l_r}}^0, b_{t_{r,l_r}}^0\}{l_r=1, r=1}^{L_r, R} {atr,lr0,btr,lr0}lr=1,r=1Lr,R 和 { a z r 0 , b z r 0 } r = 1 R \{a{z_r}^0, b_{z_r}^0\}_{r=1}^R {azr0,bzr0}r=1R 均被设置为 10 − 6 10^{-6} 10−6 以产生无信息先验(non-informative prior)。
对于稀疏性建模,在式 (6)-(7) 中通过 T \mathbf{T} T 和 Z \mathbf{Z} Z 中精度变量的乘积来强制实现块内列级稀疏性和块级稀疏性,而在式 (8) 中仅通过 Z \mathbf{Z} Z 来强制实现块级稀疏性。这种稀疏性建模最初是在用于完全观测张量的贝叶斯 LL1 模型 42 中引入的,其中也简要讨论了替代先验(参见文献 42 中的脚注 3)。然而,式 (6)-(8) 通过将单位行精度矩阵替换为任意正定精度矩阵(arbitrary positive-definite precision matrices),扩展了文献 42 中的先验。
虽然式 (6)-(8) 似乎是文献 42 中先验模型的直接扩展,但在下一节中将会揭示,在式 (6)-(8) 中融入图信息需要一种完全不同的推断算法。此外,虽然文献 42 通过推导相应的最大后验 (MAP) 估计量并将其与文献 13, 20, 23 中的其他促进稀疏性正则化方法进行比较,证明了先验(不包含图信息)的合理性,但没有提供对先验边缘分布的直接分析。下面,我们对先验 (6)-(8) 提出正式分析,以确立其为 BTD 引入所需稀疏性形式和图信息的合理性。该分析也首次为文献 42 中的先验提供了正式的理论依据。为了保持正文的简洁,属性 1 的证明在附录 A 中提供。
属性 1 :当超参数 { a t r , l r 0 , b t r , l r 0 } l r = 1 , r = 1 L r , R \{a_{t_{r,l_r}}^0, b_{t_{r,l_r}}^0\}{l_r=1, r=1}^{L_r, R} {atr,lr0,btr,lr0}lr=1,r=1Lr,R 和 { a z r 0 , b z r 0 } r = 1 R \{a{z_r}^0, b_{z_r}^0\}{r=1}^R {azr0,bzr0}r=1R 均趋于零时,联合边缘先验分布(the joint marginal prior distribution)变为
p ( A , B , C ) ∝ exp ( − ∑ r = 1 R ( K ln ∥ L C 1 / 2 C : , r ∥ 2 2 + ∑ l r = 1 L r ( I + J ) ln ∥ L A 1 / 2 A r : , l r ∥ 2 2 + ∥ L B 1 / 2 B r : , l r ∥ 2 2 ) ) . (11) \begin{aligned} p(\mathbf{A}, \mathbf{B}, \mathbf{C}) \propto \exp \Bigg( &-\sum{r=1}^R \Bigg( K \ln \sqrt{\|\mathbf{L}{\mathbf{C}}^{1/2} \mathbf{C}{:,r}\|2^2} \\ &+ \sum{l_r=1}^{L_r} (I+J) \ln \sqrt{\|\mathbf{L}{\mathbf{A}}^{1/2} \\mathbf{A}_r{:,l_r}\|2^2 + \|\mathbf{L}{\mathbf{B}}^{1/2} \\mathbf{B}_r_{:,l_r}\|_2^2} \Bigg) \Bigg). \end{aligned} \tag{11} p(A,B,C)∝exp(−r=1∑R(Kln∥LC1/2C:,r∥22 +lr=1∑Lr(I+J)ln∥LA1/2Ar:,lr∥22+∥LB1/2Br:,lr∥22 )).(11)
从属性 1 可以看出,当超参数 { a t r , l r 0 , b t r , l r 0 } l r = 1 , r = 1 L r , R \{a_{t_{r,l_r}}^0, b_{t_{r,l_r}}^0\}{l_r=1, r=1}^{L_r, R} {atr,lr0,btr,lr0}lr=1,r=1Lr,R 和 { a z r 0 , b z r 0 } r = 1 R \{a{z_r}^0, b_{z_r}^0\}_{r=1}^R {azr0,bzr0}r=1R 极小时,式 (11) 中的边缘先验分布促进了两个级别的稀疏性。具体而言,
- 它通过鼓励 A r : , l r \\mathbf{A}_r{:,l_r} Ar:,lr 和 B r : , l r \\mathbf{B}_r{:,l_r} Br:,lr 同时向零收缩来强制实现块内列级稀疏性,从而能够估计块秩 { L r } r = 1 R \{L_r\}_{r=1}^R {Lr}r=1R 。
- 此外,它诱导了块级稀疏性,因为列 C : , r \mathbf{C}_{:,r} C:,r 以及 A r \mathbf{A}_r Ar 和 B r \mathbf{B}_r Br 中的所有列一起趋于零,从而有助于估计块数 R R R 。
在最大后验概率估计 (MAP) 中,最大化后验等价于最小化负对数后验。对式 (11) 取负对数,得到目标函数中的正则化项 R ( A , B , C ) \mathcal{R}(\mathbf{A}, \mathbf{B}, \mathbf{C}) R(A,B,C) :
R ( A , B , C ) ∝ exp ( ∑ r = 1 R ( K 2 ln ( ∥ L C 1 / 2 C : , r ∥ 2 2 ) + I + J 2 ∑ l r = 1 L r ln ( ∥ L A 1 / 2 A r : , l r ∥ 2 2 + ∥ L B 1 / 2 B r : , l r ∥ 2 2 ) ) ) \mathcal{R}(\mathbf{A}, \mathbf{B}, \mathbf{C}) \propto \text{exp} \left( \sum_{r=1}^R \left( \frac{K}{2} \ln \left( \|\mathbf{L}{\mathbf{C}}^{1/2} \mathbf{C}{:,r}\|2^2 \right) + \frac{I+J}{2} \sum{l_r=1}^{L_r} \ln \left( \|\mathbf{L}{\mathbf{A}}^{1/2} \\mathbf{A}_r{:,l_r}\|2^2 + \|\mathbf{L}{\mathbf{B}}^{1/2} \\mathbf{B}_r_{:,l_r}\|_2^2 \right) \right) \right) R(A,B,C)∝exp(r=1∑R(2Kln(∥LC1/2C:,r∥22)+2I+Jlr=1∑Lrln(∥LA1/2Ar:,lr∥22+∥LB1/2Br:,lr∥22)))
该惩罚项从以下三个层面在数学上强制实现了稀疏性:
对数惩罚项的稀疏诱导机制
该项构成了一种对数和正则化。函数 f ( x ) = ln ( x ) f(x) = \ln(x) f(x)=ln(x) 的导数为 1 / x 1/x 1/x ,当变量 x → 0 + x \to 0^+ x→0+ 时,惩罚梯度趋于无穷大。在数学极限上,对数惩罚是 ℓ p \ell_p ℓp 拟范数在 p → 0 + p \to 0^+ p→0+ 时的极限,比 ℓ 1 \ell_1 ℓ1 或 ℓ 1 / 2 \ell_{1/2} ℓ1/2 范数具有更强的稀疏诱导能力。
块内列级稀疏性(组稀疏性)
观察与 A \mathbf{A} A 和 B \mathbf{B} B 相关的惩罚项:
∑ l r = 1 L r ln ( ∥ L A 1 / 2 A r : , l r ∥ 2 2 + ∥ L B 1 / 2 B r : , l r ∥ 2 2 ) \sum_{l_r=1}^{L_r} \ln \left( \|\mathbf{L}{\mathbf{A}}^{1/2} \\mathbf{A}_r{:,l_r}\|2^2 + \|\mathbf{L}{\mathbf{B}}^{1/2} \\mathbf{B}_r_{:,l_r}\|_2^2 \right) lr=1∑Lrln(∥LA1/2Ar:,lr∥22+∥LB1/2Br:,lr∥22)这在数学上等价于组正则化。为了最小化该非负和,优化算法会强制 A r : , l r \\mathbf{A}_r{:,l_r} Ar:,lr 和 B r : , l r \\mathbf{B}_r{:,l_r} Br:,lr 协同且同时收缩为零向量。通过统计非零列组的数量,可自动估计块秩 L r L_r Lr 。
块级稀疏性(全局结构稀疏性)
观察与 C \mathbf{C} C 相关的惩罚项:
∑ r = 1 R K 2 ln ( ∥ L C 1 / 2 C : , r ∥ 2 2 ) \sum_{r=1}^R \frac{K}{2} \ln \left( \|\mathbf{L}{\mathbf{C}}^{1/2} \mathbf{C}{:,r}\|_2^2 \right) r=1∑R2Kln(∥LC1/2C:,r∥22)对数惩罚会使某些列 C : , r \mathbf{C}{:,r} C:,r 直接优化为零向量。在 BTD 模型中,若 C : , r = 0 \mathbf{C}{:,r} = \mathbf{0} C:,r=0 ,第 r r r 个块对数据拟合项(似然函数)的贡献严格为零。此时,似然函数不再对 A r \mathbf{A}_r Ar 和 B r \mathbf{B}_r Br 提供梯度阻碍,正则化项会直接将 A r \mathbf{A}_r Ar 和 B r \mathbf{B}_r Br 中的对应列全部推向零,从而剔除整个第 r r r 块并实现对全局块数 R R R 的估计。
然而,与式 (5) 不同(在式 (5) 中,与 A \mathbf{A} A 和 B \mathbf{B} B 相关的项与 C \mathbf{C} C 的项是分层组合的),边缘先验 (11) 将它们分开处理。此外,它引入了应用于范数的额外对数函数,从而产生了对数和正则化。由于较小的 p p p 值会在 ℓ p \ell_p ℓp 范数中引起更强的稀疏性,并且对数和正则化可以被视为当 p → 0 + p \rightarrow 0^+ p→0+ 时的极限 49, 50, 51,因此预计式 (11) 中的边缘先验在促进稀疏性方面比式 (5) 中使用的 ℓ 1 / 2 \ell_{1/2} ℓ1/2 范数更有效。这在图 1 中得到了证实,该图表明,与更平滑的 ℓ 1 / 2 \ell_{1/2} ℓ1/2 正则化相比,对数和正则化在原点附近引起了更尖锐的轮廓曲线,从而促进了更强的稀疏性。
除了稀疏性建模之外,式 (11) 还通过行精度矩阵结合了图正则化,从而根据潜在的图结构促进平滑度。例如,如果行精度矩阵 L A \mathbf{L}{\mathbf{A}} LA 被设置为图拉普拉斯矩阵(graph Laplacian matrix),定义为 L A = D A − G A \mathbf{L}{\mathbf{A}} = \mathbf{D}{\mathbf{A}} - \mathbf{G}{\mathbf{A}} LA=DA−GA ,其中
- G A ∈ R I × I \mathbf{G}_{\mathbf{A}} \in \mathbb{R}^{I \times I} GA∈RI×I 是图权重矩阵(the graph weight matrix),其第 ( i , i ′ ) (i, i') (i,i′) 个元素是顶点 i i i 和 i ′ i' i′ 之间的权重,
- 且 D A = diag { ∑ i ′ = 1 I G 1 , i ′ , ... , ∑ i ′ = 1 I G I , i ′ } ∈ R I × I \mathbf{D}{\mathbf{A}} = \text{diag}\{\sum{i'=1}^I \mathbf{G}{1,i'}, \dots, \sum{i'=1}^I \mathbf{G}_{I,i'}\} \in \mathbb{R}^{I \times I} DA=diag{∑i′=1IG1,i′,...,∑i′=1IGI,i′}∈RI×I ,
则项 ∥ L A 1 / 2 A r : , l r ∥ 2 2 \|\mathbf{L}{\mathbf{A}}^{1/2} \\mathbf{A}_r{:,l_r}\|2^2 ∥LA1/2Ar:,lr∥22 可以等价地表示为 1 2 ∑ i = 1 I ∑ i ′ = 1 I G A i , i ′ ( A r i , l r − A r i ′ , l r ) 2 \frac{1}{2} \sum{i=1}^I \sum_{i'=1}^I \\mathbf{G}_{\\mathbf{A}}{i,i'} (\\mathbf{A}_r{i,l_r} - \\mathbf{A}_r{i',l_r})^2 21∑i=1I∑i′=1IGAi,i′(Ari,lr−Ari′,lr)2 48,这表明元素 A r i , l r \\mathbf{A}_r{i,l_r} Ari,lr 和 A r i ′ , l r \\mathbf{A}_r{i',l_r} Ari′,lr 根据图权重 G A i , i ′ \\mathbf{G}_{\\mathbf{A}}{i,i'} GAi,i′ 是平滑的。同样的原理也适用于 B \mathbf{B} B 和 C \mathbf{C} C 中的列。
总而言之,先验 (6)-(10) 同时嵌入了图信息(embed graph information)和所需的稀疏性,以实现对块数 R R R 和块秩 { L r } r = 1 R \{L_r\}_{r=1}^R {Lr}r=1R 的学习,从而为提高块项张量补全的性能铺平了道路。
B. Completion Likelihood and Joint Distribution
在加性高斯白噪声 (AWGN) 的假设下,LL1 张量补全的似然函数被构建为观测条目上高斯分布的乘积,
p ( Y ∣ A , B , C , β ) = ∏ ( i , j , k ) ∈ O N ( Y i , j , k ∣ X i , j , k , β − 1 ) ∝ exp ( ∣ O ∣ 2 ln β − β 2 ∥ W ∗ ( Y − X ) ∥ F 2 ) , (12) \begin{aligned} p(\boldsymbol{\mathcal{Y}}|\mathbf{A}, \mathbf{B}, \mathbf{C}, \beta) &= \prod_{(i,j,k) \in \mathcal{O}} \mathcal{N}(\boldsymbol{\mathcal{Y}}{i,j,k} | \boldsymbol{\mathcal{X}}{i,j,k}, \beta^{-1}) \\ &\propto \exp \left( \frac{|\mathcal{O}|}{2} \ln \beta - \frac{\beta}{2} \|\boldsymbol{\mathcal{W}} * (\boldsymbol{\mathcal{Y}} - \boldsymbol{\mathcal{X}})\|_F^2 \right), \end{aligned} \tag{12} p(Y∣A,B,C,β)=(i,j,k)∈O∏N(Yi,j,k∣Xi,j,k,β−1)∝exp(2∣O∣lnβ−2β∥W∗(Y−X)∥F2),(12)
其中 β \beta β 表示噪声精度, ∣ O ∣ |\mathcal{O}| ∣O∣ 表示观测条目的数量,而运算符 ∗ * ∗ 表示哈达玛积。张量 W \boldsymbol{\mathcal{W}} W 是一个二元观测指示张量,如果索引 ( i , j , k ) ∈ O (i,j,k) \in \mathcal{O} (i,j,k)∈O ,则 W i , j , k = 1 \boldsymbol{\mathcal{W}}{i,j,k} = 1 Wi,j,k=1 ,否则 W i , j , k = 0 \boldsymbol{\mathcal{W}}{i,j,k} = 0 Wi,j,k=0 。与参数 T \mathbf{T} T 和 Z \mathbf{Z} Z 类似,噪声精度 β \beta β 也是未知的,并在贝叶斯框架内进行联合学习。其先验被赋予伽马分布 p ( β ) = Ga ( β ∣ a β 0 , b β 0 ) p(\beta) = \text{Ga}(\beta|a_\beta^0, b_\beta^0) p(β)=Ga(β∣aβ0,bβ0) ,其中超参数 a β 0 , b β 0 a_\beta^0, b_\beta^0 aβ0,bβ0 被设置为 10 − 6 10^{-6} 10−6 以产生无信息先验。
结合先验分布(the prior distribution)和张量补全似然函数,完整的贝叶斯模型总结在图 2 中。不完整张量数据 Y \boldsymbol{\mathcal{Y}} Y 和模型参数 Θ = { A , B , C , T , Z , β } \boldsymbol{\Theta} = \{\mathbf{A}, \mathbf{B}, \mathbf{C}, \mathbf{T}, \mathbf{Z}, \beta\} Θ={A,B,C,T,Z,β} 的联合分布由下式给出
p ( Y , Θ ) = p ( Y ∣ A , B , C , β ) p ( A ∣ T , Z ) p ( B ∣ T , Z ) × p ( C ∣ Z ) p ( T ) p ( Z ) p ( β ) . (13) \begin{aligned} p(\boldsymbol{\mathcal{Y}}, \boldsymbol{\Theta}) &= p(\boldsymbol{\mathcal{Y}}|\mathbf{A}, \mathbf{B}, \mathbf{C}, \beta) p(\mathbf{A}|\mathbf{T}, \mathbf{Z}) p(\mathbf{B}|\mathbf{T}, \mathbf{Z}) \\ &\quad \times p(\mathbf{C}|\mathbf{Z}) p(\mathbf{T}) p(\mathbf{Z}) p(\beta). \end{aligned} \tag{13} p(Y,Θ)=p(Y∣A,B,C,β)p(A∣T,Z)p(B∣T,Z)×p(C∣Z)p(T)p(Z)p(β).(13)
公式 (13) 的推导基于概率论的乘法法则 与贝叶斯网络中的条件独立性假设。具体推导步骤如下:
1. 联合分布的基础分解
根据概率乘法法则,观测数据 Y \boldsymbol{\mathcal{Y}} Y 与参数集合 Θ = { A , B , C , T , Z , β } \boldsymbol{\Theta} = \{\mathbf{A}, \mathbf{B}, \mathbf{C}, \mathbf{T}, \mathbf{Z}, \beta\} Θ={A,B,C,T,Z,β} 的联合分布可分解为似然与先验的乘积:
p ( Y , Θ ) = p ( Y ∣ Θ ) p ( Θ ) p(\boldsymbol{\mathcal{Y}}, \boldsymbol{\Theta}) = p(\boldsymbol{\mathcal{Y}} | \boldsymbol{\Theta}) p(\boldsymbol{\Theta}) p(Y,Θ)=p(Y∣Θ)p(Θ)2. 似然函数的条件独立性化简
在给定核心因子矩阵 A , B , C \mathbf{A}, \mathbf{B}, \mathbf{C} A,B,C 和噪声精度 β \beta β 的条件下,数据 Y \boldsymbol{\mathcal{Y}} Y 的生成与高层超参数 T , Z \mathbf{T}, \mathbf{Z} T,Z 条件独立。因此似然函数化简为:
p ( Y ∣ Θ ) = p ( Y ∣ A , B , C , β ) p(\boldsymbol{\mathcal{Y}} | \boldsymbol{\Theta}) = p(\boldsymbol{\mathcal{Y}} | \mathbf{A}, \mathbf{B}, \mathbf{C}, \beta) p(Y∣Θ)=p(Y∣A,B,C,β)3. 联合先验分布的层次分解
根据分层贝叶斯图模型的单向依赖结构,联合先验 p ( Θ ) p(\boldsymbol{\Theta}) p(Θ) 可按层级拆解:
- 分解因子与超参数层 :
p ( Θ ) = p ( A , B , C ∣ T , Z , β ) p ( T , Z , β ) p(\boldsymbol{\Theta}) = p(\mathbf{A}, \mathbf{B}, \mathbf{C} | \mathbf{T}, \mathbf{Z}, \beta) p(\mathbf{T}, \mathbf{Z}, \beta) p(Θ)=p(A,B,C∣T,Z,β)p(T,Z,β)- 因子层条件独立 (给定 T , Z \mathbf{T}, \mathbf{Z} T,Z ,因子矩阵间相互独立,且与 β \beta β 无关):
p ( A , B , C ∣ T , Z , β ) = p ( A ∣ T , Z ) p ( B ∣ T , Z ) p ( C ∣ Z ) p(\mathbf{A}, \mathbf{B}, \mathbf{C} | \mathbf{T}, \mathbf{Z}, \beta) = p(\mathbf{A}|\mathbf{T}, \mathbf{Z}) p(\mathbf{B}|\mathbf{T}, \mathbf{Z}) p(\mathbf{C}|\mathbf{Z}) p(A,B,C∣T,Z,β)=p(A∣T,Z)p(B∣T,Z)p(C∣Z)- 超参数层先验独立 (顶层参数 T , Z , β \mathbf{T}, \mathbf{Z}, \beta T,Z,β 被设定为相互独立):
p ( T , Z , β ) = p ( T ) p ( Z ) p ( β ) p(\mathbf{T}, \mathbf{Z}, \beta) = p(\mathbf{T}) p(\mathbf{Z}) p(\beta) p(T,Z,β)=p(T)p(Z)p(β)
将上述结果相乘,得到化简后的联合先验:
p ( Θ ) = p ( A ∣ T , Z ) p ( B ∣ T , Z ) p ( C ∣ Z ) p ( T ) p ( Z ) p ( β ) p(\boldsymbol{\Theta}) = p(\mathbf{A}|\mathbf{T}, \mathbf{Z}) p(\mathbf{B}|\mathbf{T}, \mathbf{Z}) p(\mathbf{C}|\mathbf{Z}) p(\mathbf{T}) p(\mathbf{Z}) p(\beta) p(Θ)=p(A∣T,Z)p(B∣T,Z)p(C∣Z)p(T)p(Z)p(β)4. 最终合并
将化简后的似然函数(步骤 2)与联合先验分布(步骤 3)相乘,即可得到完整的联合概率分布:
p ( Y , Θ ) = p ( Y ∣ A , B , C , β ) p ( A ∣ T , Z ) p ( B ∣ T , Z ) × p ( C ∣ Z ) p ( T ) p ( Z ) p ( β ) . (13) \begin{aligned} p(\boldsymbol{\mathcal{Y}}, \boldsymbol{\Theta}) &= p(\boldsymbol{\mathcal{Y}}|\mathbf{A}, \mathbf{B}, \mathbf{C}, \beta) p(\mathbf{A}|\mathbf{T}, \mathbf{Z}) p(\mathbf{B}|\mathbf{T}, \mathbf{Z}) \\ &\quad \times p(\mathbf{C}|\mathbf{Z}) p(\mathbf{T}) p(\mathbf{Z}) p(\beta). \end{aligned} \tag{13} p(Y,Θ)=p(Y∣A,B,C,β)p(A∣T,Z)p(B∣T,Z)×p(C∣Z)p(T)p(Z)p(β).(13)构建公式 (13) 这个联合分布的最终数学目的是为了计算后验分布(Posterior Distribution) p ( Θ ∣ Y ) p(\boldsymbol{\Theta}|\boldsymbol{\mathcal{Y}}) p(Θ∣Y)。根据贝叶斯定理: p ( Θ ∣ Y ) = p ( Y , Θ ) p ( Y ) ∝ p ( Y , Θ ) p(\boldsymbol{\Theta}|\boldsymbol{\mathcal{Y}}) = \frac{p(\boldsymbol{\mathcal{Y}}, \boldsymbol{\Theta})}{p(\boldsymbol{\mathcal{Y}})} \propto p(\boldsymbol{\mathcal{Y}}, \boldsymbol{\Theta}) p(Θ∣Y)=p(Y)p(Y,Θ)∝p(Y,Θ)由于证据项 p ( Y ) p(\boldsymbol{\mathcal{Y}}) p(Y) 是一个难以精确计算的常数积分,整个贝叶斯推断(例如本文后续采用的变分推断 VI 算法)的核心优化目标,就是通过最大化上述联合分布 p ( Y , Θ ) p(\boldsymbol{\mathcal{Y}}, \boldsymbol{\Theta}) p(Y,Θ)(或其变分下界),来寻找在给定观测数据下,模型参数 Θ \boldsymbol{\Theta} Θ 的最优概率分布。
IV. INFERENCE ALGORITHM
A. General Philosophy of Variational Inference
与获得点估计的最大似然 (ML) 或 MAP 不同,完全贝叶斯推断计算后验分布 p ( Θ ∣ Y ) = p ( Y ∣ Θ ) p ( Θ ) / ∫ p ( Y ∣ Θ ) p ( Θ ) d Θ p(\boldsymbol{\Theta}|\boldsymbol{\mathcal{Y}}) = p(\boldsymbol{\mathcal{Y}}|\boldsymbol{\Theta})p(\boldsymbol{\Theta}) / \int p(\boldsymbol{\mathcal{Y}}|\boldsymbol{\Theta})p(\boldsymbol{\Theta})d\boldsymbol{\Theta} p(Θ∣Y)=p(Y∣Θ)p(Θ)/∫p(Y∣Θ)p(Θ)dΘ 。然而,对于所提出的贝叶斯模型,由于参数之间的复杂关系,这种精确计算是难以处理的。变分推断 (VI) 通过使用来自易处理分布族的代理变分概率密度函数 (a surrogate variational probability density function) 来近似精确的后验分布,从而应对这一挑战。
具体而言,VI 通过最小化到精确后验分布 p ( Θ ∣ Y ) p(\boldsymbol{\Theta}|\boldsymbol{\mathcal{Y}}) p(Θ∣Y) 的 Kullback-Leibler (KL) 散度来寻找变分 pdf q ( Θ ) q(\boldsymbol{\Theta}) q(Θ) :
min q ( Θ ) ∈ F KL ( q ( Θ ) ∥ p ( Θ ∣ Y ) ) = − E q ( Θ ) ln p ( Θ ∣ Y ) q ( Θ ) , (14) \min_{q(\boldsymbol{\Theta}) \in \mathcal{F}} \text{KL}(q(\boldsymbol{\Theta}) \| p(\boldsymbol{\Theta}|\boldsymbol{\mathcal{Y}})) = -\mathbb{E}_{q(\boldsymbol{\Theta})} \left \\ln \\frac{p(\\boldsymbol{\\Theta}\|\\boldsymbol{\\mathcal{Y}})}{q(\\boldsymbol{\\Theta})} \\right, \tag{14} q(Θ)∈FminKL(q(Θ)∥p(Θ∣Y))=−Eq(Θ)lnq(Θ)p(Θ∣Y),(14)
其中 F \mathcal{F} F 表示预先选择的易处理分布族(the pre-selected family of tractable distributions),而 KL ( ⋅ ∥ ⋅ ) \text{KL}(\cdot\|\cdot) KL(⋅∥⋅) 表示 KL 散度。
在本文中, F \mathcal{F} F 被选择为平均场分布族(the mean-field family),定义为 F = { q ( Θ ) = ∏ k = 1 K q ( Θ k ) } \mathcal{F} = \{ q(\boldsymbol{\Theta}) = \prod_{k=1}^K q(\boldsymbol{\Theta}_k) \} F={q(Θ)=∏k=1Kq(Θk)} ,其中 { Θ k } k = 1 K \{\boldsymbol{\Theta}k\}{k=1}^K {Θk}k=1K 是 Θ \boldsymbol{\Theta} Θ 的一个划分。在此假设下,优化问题 (14) 变为多凸问题(multi-convex),这意味着固定 q ( Θ j ) , j ≠ k q(\boldsymbol{\Theta}_j), j \neq k q(Θj),j=k 会使得该问题关于 q ( Θ k ) q(\boldsymbol{\Theta}_k) q(Θk) 是凸的。这一属性表明可以使用交替优化算法,其中每个 q ( Θ k ) q(\boldsymbol{\Theta}_k) q(Θk) 都被迭代更新,同时保持其他分布固定。根据文献 52,平均场假设下的更新规则为
ln q ∗ ( Θ k ) = E ∏ j ≠ k q ( Θ j ) ln p ( Y , Θ ) + const . (15) \ln q^*(\boldsymbol{\Theta}k) = \mathbb{E}{\prod_{j \neq k} q(\boldsymbol{\Theta}_j)} \\ln p(\\boldsymbol{\\mathcal{Y}}, \\boldsymbol{\\Theta}) + \text{const}. \tag{15} lnq∗(Θk)=E∏j=kq(Θj)lnp(Y,Θ)+const.(15)
通过对每个 q ( Θ k ) q(\boldsymbol{\Theta}_k) q(Θk) 迭代应用此更新规则,该算法保证收敛到对数证据 log p ( Y ) \log p(\boldsymbol{\mathcal{Y}}) logp(Y) 的下界的驻点,这也称为证据下界 (ELBO) 52。
B. Mean-Field Design
平均场假设涵盖了划分 Θ \boldsymbol{\Theta} Θ 的多种可能方式。然而,并非所有的划分都能在式 (15) 中得到闭式表达式。选择合适的划分至关重要,因为它在 VI 算法的易处理性和其引入到变分分布 q ( Θ ) q(\boldsymbol{\Theta}) q(Θ) 中的近似程度之间取得了平衡。在本小节中,开发了一种平均场设计,该设计不仅能产生闭式更新,还能保留图信息的嵌入。
首先,考虑施加最小独立性假设(minimal independence assumptions)的情况。在对因子矩阵内部没有任何限制的情况下,变分分布表示为: q ( Θ ) = q ( A ) q ( B ) q ( C ) q ( T ) q ( Z ) q ( β ) q(\boldsymbol{\Theta}) = q(\mathbf{A})q(\mathbf{B})q(\mathbf{C})q(\mathbf{T})q(\mathbf{Z})q(\beta) q(Θ)=q(A)q(B)q(C)q(T)q(Z)q(β) 。在这种平均场设计下,将式 (13) 代入式 (15) 中,由此产生的 VI 算法不会得到闭式更新。例如,考虑参数 A \mathbf{A} A ,更新方程 (15) 变为
E − β 2 ∥ W ( 1 ) ∗ ( Y ( 1 ) − P A ⊤ ) ∥ F 2 − 1 2 Tr ( T Z b A ⊤ L A A ) + const , (16) \mathbb{E} \left -\\frac{\\beta}{2} \\\|\\mathbf{W}_{(1)} \* (\\mathbf{Y}_{(1)} - \\mathbf{P} \\mathbf{A}\^\\top)\\\|_F\^2 - \\frac{1}{2} \\text{Tr}(\\mathbf{T}\\mathbf{Z}\^b\\mathbf{A}\^\\top \\mathbf{L}_{\\mathbf{A}} \\mathbf{A}) \\right + \text{const}, \tag{16} E−2β∥W(1)∗(Y(1)−PA⊤)∥F2−21Tr(TZbA⊤LAA)+const,(16)
其中 ⋅ ( 1 ) \\cdot{(1)} ⋅(1) 表示对应张量的模-1 展开, P \mathbf{P} P 在式 (2) 中定义。由于 W ( 1 ) \boldsymbol{\mathcal{W}}{(1)} W(1) 和非对角行精度矩阵 L A \mathbf{L}_{\mathbf{A}} LA 的存在,方程 (16) 不能表示为矩阵正态分布。
p p p 与 q q q 是两个不同的分布
- p ( Θ ) p(\boldsymbol{\Theta}) p(Θ) 是"真实世界"的先验分布:如你所列出的公式,在模型真实的生成机制中,参数之间确实存在严格的条件依赖关系(例如 p ( A ∣ T , Z ) p(\mathbf{A}|\mathbf{T}, \mathbf{Z}) p(A∣T,Z) )。这是我们想要逼近但无法直接计算的目标。
- q ( Θ ) q(\boldsymbol{\Theta}) q(Θ) 是"近似世界"的代理分布:由于真实后验 p ( Θ ∣ Y ) p(\boldsymbol{\Theta}|\boldsymbol{\mathcal{Y}}) p(Θ∣Y) 的分母(证据项 ∫ p ( Y ∣ Θ ) p ( Θ ) d Θ \int p(\boldsymbol{\mathcal{Y}}|\boldsymbol{\Theta})p(\boldsymbol{\Theta})d\boldsymbol{\Theta} ∫p(Y∣Θ)p(Θ)dΘ )包含极端复杂的高维多重积分,直接求解在数学上是无解的(Intractable)。因此,我们需要引入一个容易计算的"替代品",这就是变分分布 q ( Θ ) q(\boldsymbol{\Theta}) q(Θ)。
其中协方差和均值参数为
Σ A i , : = ( E β E P ⊤ diag \[ \[ W ( 1 ) : , i ] P ] + L A i , i E T E Z b ) − 1 , (18) \boldsymbol{\Sigma}{\mathbf{A}{i,:}} = \left( \mathbb{E}\\beta \mathbb{E} \left \\mathbf{P}\^\\top \\text{diag}\[\[\\mathbf{W}_{(1)}{:,i}] \mathbf{P} \right] + \\mathbf{L}_{\\mathbf{A}}{i,i} \mathbb{E}\\mathbf{T} \mathbb{E}\left\\mathbf{Z}\^b\\right \right)^{-1}, \tag{18} ΣAi,:=(EβEP⊤diag\[\[W(1):,i]P]+LAi,iETEZb)−1,(18)
μ A i , : = Σ A i , : E β E P ⊤ diag \[ W ( 1 ) : , i ] Y ( 1 ) : , i . (19) \boldsymbol{\mu}{\mathbf{A}{i,:}} = \boldsymbol{\Sigma}{\mathbf{A}{i,:}} \mathbb{E}\\beta \mathbb{E}\\mathbf{P}^\top \text{diag}\[\\mathbf{W}_{(1)}{:,i}] \\mathbf{Y}_{(1)}{:,i}. \tag{19} μAi,:=ΣAi,:EβEP⊤diag\[W(1):,i]Y(1):,i.(19)
这种平均场假设选择的问题在于 Σ A i , : \boldsymbol{\Sigma}{\mathbf{A}{i,:}} ΣAi,: 仅包含行精度矩阵 L A i , i \\mathbf{L}_{\\mathbf{A}}{i,i} LAi,i 的对角元素,而忽略了编码图中与其他顶点相互作用的非对角元素。因此,图结构没有完全融入到变分分布 q ∗ ( A i , : ) q^*(\mathbf{A}{i,:}) q∗(Ai,:) 中。同样的问题也出现在变分分布 q ∗ ( B j , : ) q^*(\mathbf{B}{j,:}) q∗(Bj,:) 和 q ∗ ( C k , : ) q^*(\mathbf{C}{k,:}) q∗(Ck,:) 中。
为了同时保留图信息嵌入并在 VI 算法中提供闭式更新,我们提出了一种平均场假设,该假设强制因子矩阵的各列之间相互独立:
q ( Θ ) = ∏ r = 1 R ∏ l r = 1 L r q ( A r : , l r ) ∏ r = 1 R ∏ l r = 1 L r q ( B r : , l r ) × ∏ r = 1 R q ( C : , r ) q ( T ) q ( Z ) q ( β ) . (20) \begin{aligned} q(\boldsymbol{\Theta}) &= \prod_{r=1}^R \prod_{l_r=1}^{L_r} q(\\mathbf{A}_r{:,l_r}) \prod{r=1}^R \prod_{l_r=1}^{L_r} q(\\mathbf{B}_r{:,l_r}) \\ &\quad \times \prod{r=1}^R q(\mathbf{C}_{:,r}) q(\mathbf{T}) q(\mathbf{Z}) q(\beta). \end{aligned} \tag{20} q(Θ)=r=1∏Rlr=1∏Lrq(Ar:,lr)r=1∏Rlr=1∏Lrq(Br:,lr)×r=1∏Rq(C:,r)q(T)q(Z)q(β).(20)
在这种设计下,每一列的最优变分分布 q ∗ ( A r : , l r ) q^*(\\mathbf{A}_r_{:,l_r}) q∗(Ar:,lr) 由下式给出
q ∗ ( A r : , l r ) = N ( A r : , l r ∣ μ A r : , l r , Σ A r : , l r ) , (21) q^*(\\mathbf{A}_r{:,l_r}) = \mathcal{N} \left( \\mathbf{A}_r{:,l_r} | \boldsymbol{\mu}{\\mathbf{A}_r{:,l_r}}, \boldsymbol{\Sigma}{\\mathbf{A}_r{:,l_r}} \right), \tag{21} q∗(Ar:,lr)=N(Ar:,lr∣μAr:,lr,ΣAr:,lr),(21)
其中协方差和均值参数为
Σ A r : , l r = ( E β diag ( W ( 1 ) ⊤ E \[ P r : , l r ∗ P r : , l r ] ) + E z r E t r , l r L A ) − 1 , (22) \begin{aligned} \boldsymbol{\Sigma}{\\mathbf{A}_r{:,l_r}} &= \Bigg( \mathbb{E}\\beta \text{diag} \left( \mathbf{W}{(1)}^\top \mathbb{E}\[\\mathbf{P}_r{:,l_r} * \\mathbf{P}_r{:,l_r}] \right) \\ &\quad + \mathbb{E}z_r \mathbb{E}t_{r,l_r} \mathbf{L}{\mathbf{A}} \Bigg)^{-1}, \end{aligned} \tag{22} ΣAr:,lr=(Eβdiag(W(1)⊤E\[Pr:,lr∗Pr:,lr])+EzrEtr,lrLA)−1,(22)
μ A r : , l r = E β Σ A r : , l r ( W ( 1 ) ⊤ ∗ Y ( 1 ) ⊤ ) E \[ P r : , l r ] − E β Σ A r : , l r ∑ ( i , j ) ≠ ( r , l r ) E ( W ( 1 ) ⊤ ∗ ( \[ A i : , j P i : , j ⊤ ) ) P r : , l r ] , (23) \begin{aligned} \boldsymbol{\mu}{\\mathbf{A}_r{:,l_r}} &= \mathbb{E}\\beta \boldsymbol{\Sigma}{\\mathbf{A}_r{:,l_r}} \left( \mathbf{W}{(1)}^\top * \mathbf{Y}{(1)}^\top \right) \mathbb{E}\[\\mathbf{P}_r{:,l_r}] \\ &\quad - \mathbb{E}\\beta \boldsymbol{\Sigma}{\\mathbf{A}_r{:,l_r}} \sum{(i,j) \neq (r,l_r)} \mathbb{E} \left \\left( \\mathbf{W}_{(1)}\^\\top \* (\[\\mathbf{A}_i{:,j} \\mathbf{P}_i{:,j}^\top) \right) \\mathbf{P}_r_{:,l_r} \right], \end{aligned} \tag{23} μAr:,lr=EβΣAr:,lr(W(1)⊤∗Y(1)⊤)E\[Pr:,lr]−EβΣAr:,lr(i,j)=(r,lr)∑E(W(1)⊤∗(\[Ai:,jPi:,j⊤))Pr:,lr],(23)