这篇文档是foundation stereo工作的延续,这里主要是对foundation stereo进行瘦身,达到实时立体匹配,对于工程实践有很强的启发性。
- 对depth anything特征层进行蒸馏,用学生模型CNN替代教师模型ViT
- 对3DCNN代价聚合模块进行蒸馏,简化了神经架构搜索策略
- 对ConGRU进行剪枝
- 制作真实数据集
几乎每一过程都对工程实践有很大启发!
Fast-FoundationStereo: Real-Time Zero-Shot Stereo Matching 论文总结
文章目录
- [Fast-FoundationStereo: Real-Time Zero-Shot Stereo Matching 论文总结](#Fast-FoundationStereo: Real-Time Zero-Shot Stereo Matching 论文总结)
-
- 一句话总结
- [0. 论文概述(Executive Summary)](#0. 论文概述(Executive Summary))
- [1. 问题背景与动机](#1. 问题背景与动机)
-
- [1.1 立体匹配的历史与现状](#1.1 立体匹配的历史与现状)
- [1.2 两条分裂的研究路径](#1.2 两条分裂的研究路径)
- [1.3 实际应用需求](#1.3 实际应用需求)
- [2. 相关工作与创新关联](#2. 相关工作与创新关联)
-
- [2.1 前人工作综述](#2.1 前人工作综述)
-
- [2.1.1 可泛化立体匹配(Generalizable Stereo Matching)](#2.1.1 可泛化立体匹配(Generalizable Stereo Matching))
- [2.1.2 效率导向立体匹配(Efficiency-Oriented Stereo Matching)](#2.1.2 效率导向立体匹配(Efficiency-Oriented Stereo Matching))
- [2.1.3 视觉 Foundation 模型加速](#2.1.3 视觉 Foundation 模型加速)
- [2.2 存在的问题与不足](#2.2 存在的问题与不足)
- [2.3 本论文与前人工作的关系](#2.3 本论文与前人工作的关系)
- [3. 贡献与核心创新点](#3. 贡献与核心创新点)
-
- [3.1 创新点一:混合单目与立体先验的蒸馏](#3.1 创新点一:混合单目与立体先验的蒸馏)
- [3.2 创新点二:代价滤波的块级架构搜索](#3.2 创新点二:代价滤波的块级架构搜索)
- [3.3 创新点三:细化模块的结构化剪枝](#3.3 创新点三:细化模块的结构化剪枝)
- [3.4 创新点四:真实世界数据的自动伪标签](#3.4 创新点四:真实世界数据的自动伪标签)
-
- 动机
- [伪标签管线(图 6)](#伪标签管线(图 6))
- [4. 方法与网络设计详细分析](#4. 方法与网络设计详细分析)
-
- [4.1 整体网络架构概览](#4.1 整体网络架构概览)
- [4.2 各模块详解](#4.2 各模块详解)
-
- [4.2.1 特征提取模块(蒸馏后)](#4.2.1 特征提取模块(蒸馏后))
- [4.2.2 代价滤波模块(NAS 搜索)](#4.2.2 代价滤波模块(NAS 搜索))
- [4.2.3 细化模块(剪枝)](#4.2.3 细化模块(剪枝))
- [4.2.4 总损失函数与训练策略](#4.2.4 总损失函数与训练策略)
- [5. 实验结果](#5. 实验结果)
-
- [5.1 数据集与评估指标](#5.1 数据集与评估指标)
- [5.2 零样本泛化定量对比(表 1 主论文)](#5.2 零样本泛化定量对比(表 1 主论文))
- [5.3 泛化到透明/镜面物体(Booster 数据集)](#5.3 泛化到透明/镜面物体(Booster 数据集))
- [5.4 消融研究](#5.4 消融研究)
-
- [5.4.1 特征蒸馏策略消融(表 3 正文)](#5.4.1 特征蒸馏策略消融(表 3 正文))
- [5.4.2 块级搜索有效性验证(图 8)](#5.4.2 块级搜索有效性验证(图 8))
- [5.4.3 剪枝比例影响(图 9)](#5.4.3 剪枝比例影响(图 9))
- [5.4.4 伪标签数据效果(表 4)](#5.4.4 伪标签数据效果(表 4))
- [5.4.5 细化迭代次数影响(附录图 12)](#5.4.5 细化迭代次数影响(附录图 12))
- [5.5 运行时分析(图 10)](#5.5 运行时分析(图 10))
- [5.6 定性结果(图 13-14)](#5.6 定性结果(图 13-14))
- [6. 不足之处与未来工作](#6. 不足之处与未来工作)
-
- [6.1 局限性](#6.1 局限性)
- [6.2 未来工作方向](#6.2 未来工作方向)
- [7. 总体评价](#7. 总体评价)
-
- [7.1 评分卡](#7.1 评分卡)
- [7.2 核心突破](#7.2 核心突破)
- [7.3 对领域的影响](#7.3 对领域的影响)
- [7.4 潜在后续研究方向](#7.4 潜在后续研究方向)
- 附录:重要补充细节
-
- [A. 伪标签管线中间结果可视化(图 15)](#A. 伪标签管线中间结果可视化(图 15))
- [B. 代价滤波搜索空间完整细节](#B. 代价滤波搜索空间完整细节)
- [C. TensorRT 加速](#C. TensorRT 加速)
- [D. 与其他实时方法的训练细节对比](#D. 与其他实时方法的训练细节对比)
- 参考文献(本总结中引用的关键文献)
- [4. 方法与网络设计(超详细白话版)](#4. 方法与网络设计(超详细白话版))
-
- [4.1 整体思路:分而治之](#4.1 整体思路:分而治之)
- [4.2 特征提取的加速:知识蒸馏(把双头怪变成一个灵活的小伙子)](#4.2 特征提取的加速:知识蒸馏(把双头怪变成一个灵活的小伙子))
-
- [4.2.1 原来的特征提取为什么慢?](#4.2.1 原来的特征提取为什么慢?)
- [4.2.2 蒸馏是怎么做的?](#4.2.2 蒸馏是怎么做的?)
- [4.2.3 结果怎么样?](#4.2.3 结果怎么样?)
- [4.3 代价滤波的加速:块级神经架构搜索(让电脑自己设计最优结构)](#4.3 代价滤波的加速:块级神经架构搜索(让电脑自己设计最优结构))
-
- [4.3.1 这一步到底在干什么?](#4.3.1 这一步到底在干什么?)
- [4.3.2 为什么不用传统 NAS?因为搜索空间太大了](#4.3.2 为什么不用传统 NAS?因为搜索空间太大了)
- [4.3.3 论文的窍门:块级独立训练 + 组合搜索](#4.3.3 论文的窍门:块级独立训练 + 组合搜索)
- [4.3.4 这招管用吗?](#4.3.4 这招管用吗?)
- [4.4 细化模块的加速:结构化剪枝(像给代码删注释一样删参数)](#4.4 细化模块的加速:结构化剪枝(像给代码删注释一样删参数))
-
- [4.4.1 这个模块是干嘛的?](#4.4.1 这个模块是干嘛的?)
- [4.4.2 剪枝不是随便删,要维护"依赖关系"](#4.4.2 剪枝不是随便删,要维护“依赖关系”)
- [4.4.3 剪完之后的补救:重训练](#4.4.3 剪完之后的补救:重训练)
- [4.4.4 关于迭代次数的权衡(附录图 12)](#4.4.4 关于迭代次数的权衡(附录图 12))
- [4.5 自动伪标签管线(从互联网扒数据自己造真值)](#4.5 自动伪标签管线(从互联网扒数据自己造真值))
-
- [4.5.1 为什么要搞这个?](#4.5.1 为什么要搞这个?)
- [4.5.2 具体操作(图 6)](#4.5.2 具体操作(图 6))
- [4.5.3 最终拿到多少数据?](#4.5.3 最终拿到多少数据?)
- [4.6 总结一下整个流程](#4.6 总结一下整个流程)
- [4. 方法与网络设计(白话·专业对照版)](#4. 方法与网络设计(白话·专业对照版))
-
- [4.1 分治策略:为什么不一把梭?](#4.1 分治策略:为什么不一把梭?)
- [4.2 特征提取加速:知识蒸馏(把"双头专家"变成"一个灵巧小跟班")](#4.2 特征提取加速:知识蒸馏(把“双头专家”变成“一个灵巧小跟班”))
-
- [4.2.1 原来的双头专家到底在干啥?](#4.2.1 原来的双头专家到底在干啥?)
- [4.2.2 蒸馏怎么搞?](#4.2.2 蒸馏怎么搞?)
- [4.2.3 蒸馏后的效果](#4.2.3 蒸馏后的效果)
- [4.3 代价滤波加速:块级 NAS(让电脑自己搭积木)](#4.3 代价滤波加速:块级 NAS(让电脑自己搭积木))
-
- [4.3.1 代价滤波到底在算什么?](#4.3.1 代价滤波到底在算什么?)
- [4.3.2 为什么不能用普通剪枝?](#4.3.2 为什么不能用普通剪枝?)
- [4.3.3 搜索空间到底有多大?](#4.3.3 搜索空间到底有多大?)
- [4.3.4 块级独立蒸馏:把指数砍成线性](#4.3.4 块级独立蒸馏:把指数砍成线性)
- [4.3.5 组合搜索:整数线性规划(ILP)](#4.3.5 组合搜索:整数线性规划(ILP))
- [4.3.6 这个近似方法靠谱吗?](#4.3.6 这个近似方法靠谱吗?)
- [4.4 细化模块加速:结构化剪枝(从"臃肿"到"精干")](#4.4 细化模块加速:结构化剪枝(从“臃肿”到“精干”))
-
- [4.4.1 细化模块长什么样?](#4.4.1 细化模块长什么样?)
- [4.4.2 为什么要先建依赖图?](#4.4.2 为什么要先建依赖图?)
- [4.4.3 哪些参数最不重要?用一阶泰勒展开打分](#4.4.3 哪些参数最不重要?用一阶泰勒展开打分)
- [4.4.4 剪完会崩,怎么办?重训练 + 特征蒸馏](#4.4.4 剪完会崩,怎么办?重训练 + 特征蒸馏)
- [4.4.5 迭代几次最合适?](#4.4.5 迭代几次最合适?)
- [4.5 自动伪标签:从互联网扒数据,自己造真值](#4.5 自动伪标签:从互联网扒数据,自己造真值)
-
- [4.5.1 为什么需要真实数据?](#4.5.1 为什么需要真实数据?)
- [4.5.2 法线一致性:为什么比直接比深度好?](#4.5.2 法线一致性:为什么比直接比深度好?)
- [4.5.3 具体流程(图 6 一看就懂)](#4.5.3 具体流程(图 6 一看就懂))
- [4.5.4 拿到了多少数据?效果怎样?](#4.5.4 拿到了多少数据?效果怎样?)
- [4.6 训练流程汇总(一张表看懂)](#4.6 训练流程汇总(一张表看懂))
一句话总结
Fast-FoundationStereo 通过分治加速策略(知识蒸馏 + 块级神经架构搜索 + 结构化剪枝)将 FoundationStereo 加速 10 倍以上 ,首次在立体匹配中实现了 强零样本泛化能力 与 实时推理 的统一,为机器人、增强现实等实时 3D 感知任务提供了可部署的解决方案。
0. 论文概述(Executive Summary)
| 项目 | 内容 |
|---|---|
| 论文题目 | Fast-FoundationStereo: Real-Time Zero-Shot Stereo Matching |
| 作者 | Bowen Wen, Shaurya Dewan, Stan Birchfield |
| 机构 | NVIDIA |
| 发表会议 | CVPR 2025 |
| 项目主页 | https://nvlabs.github.io/Fast-FoundationStereo/ |
核心问题
立体匹配领域存在两条互斥的研究路径:
- Foundation 模型(如 FoundationStereo、MonSter):零样本泛化能力强,但计算量巨大(单帧>600ms),无法部署于实时系统。
- 效率导向模型(如 RT-IGEV、LightStereo):帧率高(>30 FPS),但严重依赖域内微调,泛化能力弱,不适合开放世界环境。
核心矛盾:实际应用(机器人导航、增强现实、自动驾驶)既需要强泛化能力(面对未知环境),又需要实时性能(>30 FPS)。现有方法无法兼顾。
提出的解决方案
以 FoundationStereo 为教师模型,采用 分治加速策略,分别处理三大计算瓶颈:
- 特征提取(Feature Extraction):知识蒸馏将双分支(DepthAnythingV2 + side-tuning CNN)压缩为单分支学生网络。
- 代价滤波(Cost Filtering) :块级神经架构搜索自动发现最优设计,搜索复杂度从 O(n^N) 降至 O(n)。
- 视差细化(Disparity Refinement):基于循环依赖图的结构化剪枝,消除 ConvGRU 中的冗余参数。
此外,构建了 自动伪标签管线 ,从互联网立体视频生成 140 万对 高质量训练数据,补充合成数据。
核心成果
- 最快版本在 NVIDIA 3090 上达到 46ms/帧 (约 21.7 FPS),比 FoundationStereo 快 15 倍;精度损失极小(Middlebury BP-2 从 1.29% 升至 2.53%)。
- 在 Middlebury、ETH3D、KITTI 等数据集上,零样本精度 显著超越所有现有实时方法,甚至优于部分强泛化模型(如 MonSter)。
- 提供了 速度-精度权衡家族,可根据延迟预算选择不同配置。
1. 问题背景与动机
1.1 立体匹配的历史与现状
立体匹配(Stereo Matching)自 1976 年 Marr 和 Poggio 的经典工作 38 以来已有 50 年历史。现代深度学习方法在标准基准上几乎饱和,精度极高。然而,这种精度是以巨大的计算开销为代价的。
1.2 两条分裂的研究路径
| 维度 | Foundation 模型(通用化) | 效率模型(实时化) |
|---|---|---|
| 代表方法 | FoundationStereo 68, MonSter 7, StereoAnywhere 2 | RT-IGEV 74, LightStereo 22, IGEV++ 73 |
| 技术特点 | 大模型(ViT)+ 自注意力 + 丰富先验 | 轻量 CNN + 2D 代价聚合 + 局部迭代细化 |
| 泛化能力 | 强零样本(zero-shot) | 差,需域内微调 |
| 推理速度 | 慢(>600ms) | 快(<50ms) |
| 训练数据 | 混合数据集 + 互联网规模预训练 | SceneFlow 合成数据为主 |
关键问题:效率模型难以获得大规模高质量真值深度,限制了其在开放世界的应用。
1.3 实际应用需求
- 机器人操作 31:需要在未见过的环境中实时感知物体深度。
- 增强现实 30:要求低延迟、高精度的 3D 重建。
- 自动驾驶:动态场景中立体匹配必须快速且鲁棒。
这些场景 不能接受 数百毫秒的延迟,也 不能接受 在每个新环境中重新微调。
2. 相关工作与创新关联
2.1 前人工作综述
2.1.1 可泛化立体匹配(Generalizable Stereo Matching)
| 方法 | 核心思想 | 特点 |
|---|---|---|
| FoundationStereo 68 | DepthAnythingV2 + side-tuning + Disparity Transformer | 最强基线,计算密集 |
| MonSter 7 | 融合单目深度估计与立体匹配 | 互补优势,仍昂贵 |
| StereoAnywhere 2 | 立体/单目失败时互相补充 | 鲁棒但慢 |
| ZeroStereo 66 | 扩散模型生成训练数据 | 数据增强 |
| DEFOM-Stereo 25 | 深度 Foundation 模型迁移 | 新思路 |
| All-in-One 88 | 系统性迁移 VFM 到立体匹配 | 系统研究 |
域泛化方向:
- 域不变表示学习 83
- 掩码表示学习 51
- 信息论方法避免捷径学习 9
共同局限:计算开销使得它们无法实时运行。
2.1.2 效率导向立体匹配(Efficiency-Oriented Stereo Matching)
三大策略:
| 策略 | 代表方法 | 核心思想 |
|---|---|---|
| 紧凑代价体积 | Attention Concatenation Volume 72, 参数化函数 81 | 减少内存和计算 |
| 轻量代价聚合 | Cascade Cost Volume 19, Bilateral Grid 71, 3D 可分离卷积 49 | 加速聚合过程 |
| 网络结构搜索 | Hierarchical NAS 8, EasyNet 64 | 自动发现高效架构 |
共同局限:
- 从零设计训练,忽略 Foundation 模型的先验
- 需域内微调,不适合开放环境
2.1.3 视觉 Foundation 模型加速
针对 SAM、VGGT 等大模型的加速技术包括:
- 高效架构:EfficientSAM 70, Lite-SAM 17
- 量化:PTQ4SAM 36, Quantized-VGGT 16
- 剪枝+蒸馏:SlimSAM 6
- 知识蒸馏:独立使用 82, 87
- Token 合并:Fast-VGGT 58
研究空白 :立体匹配领域的 Foundation 模型加速 尚未被充分探索。
2.2 存在的问题与不足
- Foundation 模型:特征提取、代价滤波、细化模块均存在计算瓶颈,无法满足实时需求。
- 实时方法:从零设计,无法利用大规模预训练先验,泛化能力弱。
- 缺乏真实数据:高质量立体深度真值获取困难,限制了蒸馏和训练。
2.3 本论文与前人工作的关系
- 继承:以 FoundationStereo 68 为教师模型,保留其强大的零样本泛化能力。
- 改进:针对三大模块分别设计加速策略,而非简单的整体压缩。
- 补充:自动伪标签管线从互联网视频挖掘训练数据,弥补合成数据的不足。
3. 贡献与核心创新点
3.1 创新点一:混合单目与立体先验的蒸馏
动机
FoundationStereo 的特征提取采用 双分支架构:
- DepthAnything V2:提供丰富的单目先验(在大规模互联网图像上预训练)
- Side-tuning CNN:将单目特征适配到双目立体任务
虽然强大,但 ViT 的计算量极大,成为瓶颈。
方法
将教师模型的双分支特征提取器 冻结 ,训练一个 单一学生网络 来模仿教师的输出特征。
蒸馏目标(MSE 损失):
L distill = ∑ i ∥ f ˉ ( i ) − f student ( i ) ∥ 2 2 \mathcal{L}{\text{distill}} = \sum_i \left\| \bar{f}^{(i)} - f{\text{student}}^{(i)} \right\|_2^2 Ldistill=i∑ fˉ(i)−fstudent(i) 22
其中:
- f ˉ ( i ) \bar{f}^{(i)} fˉ(i):教师模型的第 i i i 级特征金字塔输出
- f student ( i ) f_{\text{student}}^{(i)} fstudent(i):学生模型的对应输出
- i ∈ { 4 , 8 , 16 , 32 } i \in \{4, 8, 16, 32\} i∈{4,8,16,32}:特征金字塔层级(对应下采样倍数)
若通道数不匹配,在教师特征后添加 线性投影层 对齐维度。
训练细节:
- 左右图像均输入蒸馏批次,保持统计相似性
- 学生模型采用已验证的高效 backbone(如 MobileNetV2 54、EdgeNeXt 37)
- 训练多个学生变体,提供速度-精度权衡
效果
图 4(正文)可视化显示:蒸馏后的特征能捕捉相似的高频边缘和相对深度信息,同时对透明物体(半透明)的鲁棒性得到增强。
3.2 创新点二:代价滤波的块级架构搜索
动机
代价滤波模块处理 4D 代价体积 V C ∈ R C × D 4 × H 4 × W 4 \mathbf{V}_{\mathbf{C}} \in \mathbb{R}^{C \times \frac{D}{4} \times \frac{H}{4} \times \frac{W}{4}} VC∈RC×4D×4H×4W,其中通道维度 C C C 通常小于 100。直接剪枝收益甚微,且蒸馏需要人工设计替代架构(缺乏先验)。因此采用 神经架构搜索(NAS) 自动发现最优设计。
核心挑战
搜索空间巨大:将代价滤波划分为 N = 8 N=8 N=8 个块,每个块有约 200 种候选,总组合数 ≈ 200 8 ≈ 10 18 \approx 200^8 \approx 10^{18} ≈2008≈1018。传统进化搜索不可行。
块级候选构建
块划分:代价滤波模块表示为:
Φ t ( V C ) = B N ∘ ⋯ ∘ B 2 ∘ B 1 ( V C ) \Phi_t(\mathbf{V}{\mathbf{C}}) = B_N \circ \dots \circ B_2 \circ B_1(\mathbf{V}{\mathbf{C}}) Φt(VC)=BN∘⋯∘B2∘B1(VC)
在每个块中,设计候选包括以下层类型:
| 层类型 | 描述 | 可调参数 |
|---|---|---|
| 3D Conv | 标准 3D 卷积 | 输出通道 (0.5×, 1×, 2× 输入), 步长 1 或 2 |
| 3D Deconv | 上采样 | 固定,保持与教师一致 |
| APC (Axial-Planar Conv) 68 | 轴向+平面卷积 | 输出通道 (0.5×, 1×), 轴向核 (3,9,17) |
| Residual 3D Conv | ResNet Basic Block | 输出通道 (0.5×, 1×), 两个 3×3 卷积 |
| FGVE (Feature-Guided Volume Excitation) 1 | 利用左图特征引导 | 多级特征输入 |
Disparity Transformer 整个模块视为单个块,可调参数:
- Transformer 层数:1~6
- FFN 隐藏维数:2× 或 4× 输入特征维数
- 注意力头数:2 或 4
每个块的层数 ≤ 教师对应块的层数。总设计空间大小: 5.5 × 10 24 5.5 \times 10^{24} 5.5×1024,其中只考虑比教师快的候选 后仍有 5.8 × 10 19 5.8 \times 10^{19} 5.8×1019 种组合。
块级蒸馏(Blockwise Distillation)
关键思想:独立训练每个块,而非联合搜索。
具体流程:
-
将块 B i B_i Bi 视为独立网络
-
训练 B i B_i Bi 模仿教师对应块的输出:
∥ B i ( f i − 1 ) − B ˉ i ( f i − 1 ) ∥ 2 2 \left\| B_i(f_{i-1}) - \bar{B}i(f{i-1}) \right\|_2^2 Bi(fi−1)−Bˉi(fi−1) 22
其中 f i − 1 f_{i-1} fi−1 来自上一教师块的输出
-
最后一个块(预测初始视差)使用平滑 L1 损失与真值比较
-
教师模型在蒸馏过程中 冻结
蒸馏后评估:
- 在验证集上对候选块 B i c B_i^c Bic 进行端到端推理
- 测量 误差变化 Δ m i c \Delta m_i^c Δmic 和 运行时间变化 Δ t i c \Delta t_i^c Δtic
复杂度降低 :从 O ( n N ) O(n^N) O(nN) 降至 O ( n ) O(n) O(n)。实际中:N=8,n≈200,仅需训练 \\sum_i C_i \\approx 2584 个块。
组合搜索(Combinatorial Search)
搜索问题形式化为 整数线性规划(ILP):
min E ∑ i = 1 N ( Δ m i ) ⊤ e i \min_{\mathcal{E}} \sum_{i=1}^{N} (\Delta \mathbf{m}_i)^\top \mathbf{e}_i Emini=1∑N(Δmi)⊤ei
s.t. ∑ i = 1 N ( Δ t i ) ⊤ e i ≤ Δ τ \text{s.t.} \quad \sum_{i=1}^{N} (\Delta \mathbf{t}_i)^\top \mathbf{e}_i \leq \Delta \tau s.t.i=1∑N(Δti)⊤ei≤Δτ
其中:
- Δ m i \Delta \mathbf{m}_i Δmi:块 B i B_i Bi 所有候选的误差变化向量
- Δ t i \Delta \mathbf{t}_i Δti:块 B i B_i Bi 所有候选的运行时间变化向量
- e i ∈ E \mathbf{e}_i \in \mathcal{E} ei∈E:one-hot 选择向量
- Δ τ \Delta \tau Δτ:相对于教师模型的延迟预算
使用 PuLP 41 求解 ILP。改变 Δ τ \Delta \tau Δτ 可获得不同速度-精度权衡的模型家族。
实现细节:
- 总块数 N=8
- 块级蒸馏总时间:128 张 NVIDIA A100 GPU 上运行 14 天
- ILP 求解 <1 秒
- 表 1 主模型对应 Δ τ = − 0.04 s \Delta \tau = -0.04s Δτ=−0.04s(即比教师快 40ms)
3.3 创新点三:细化模块的结构化剪枝
动机
ConvGRU 细化模块(图 5)存在显著冗余。结构化剪枝适用于:
- 减少参数量和计算量
- 可以利用 GPU 硬件加速(如 TensorRT)
循环依赖图构建
依赖图建模了层间通道维度约束。除了常规相邻层依赖,引入三个特殊约束:
- 输出维度固定:最终预测视差图和凸上采样掩码的层保持输出通道不变。
- 循环状态依赖 :消费 h k − 1 h_{k-1} hk−1 的层输入通道,与输出 h k h_k hk 的层输出通道 联合剪枝(两者必须同步)。
- 输入固定:运动编码器(索引体积特征)的输入通道维度固定。
图 5 标注了:
- ⊙ \odot ⊙:剪枝操作位置
- ⊡ \boxdot ⊡:通道维度保持不变
重要性评估与剪枝
使用 一阶泰勒展开(First-order Taylor expansion)43 评估参数重要性:
- 前向传播教师模型,多次细化迭代
- 累积细化模块的梯度
- 全局排序参数重要性
- 移除重要性最低的 α \alpha α 比例参数( α ∈ ( 0 , 1 ) \alpha \in (0,1) α∈(0,1) 为剪枝率)
也尝试了同构剪枝 15,但效果稍差。
重训练损失函数
剪枝后,端到端重训练细化模块(冻结网络其余部分):
L = ∑ k = 1 K γ K − k ∥ d k − d ˉ ∥ 1 + λ ∑ i = 1 L ∥ x i − x ˉ i ∥ 2 2 \mathcal{L} = \sum_{k=1}^{K} \gamma^{K-k} \left\| d_k - \bar{d} \right\|1 + \lambda \sum{i=1}^{L} \left\| x_i - \bar{x}_i \right\|_2^2 L=k=1∑KγK−k dk−dˉ 1+λi=1∑L∥xi−xˉi∥22
- k k k:迭代次数(K 默认 8)
- d k d_k dk:第 k 次迭代的视差预测
- d ˉ \bar{d} dˉ:真值视差
- x i , x ˉ i x_i, \bar{x}_i xi,xˉi:第 i 层的学生/教师潜在特征
- γ = 0.9 \gamma = 0.9 γ=0.9:指数加权,越靠近最终输出权重越高
- λ = 0.1 \lambda = 0.1 λ=0.1:蒸馏损失权重
- 初始视差监督 不包含(不受细化模块影响)
关键发现(图 9):
- 高剪枝率(如 0.8)初始精度严重下降
- 重训练后精度可 大幅恢复,证明原模块存在大量冗余
3.4 创新点四:真实世界数据的自动伪标签
动机
- 真实数据多样性远超合成数据(如 SceneFlow)
- 但获取精确深度真值极其困难(需激光雷达或结构光)
- 互联网存在大量立体视频(如 Stereo4D 26)
伪标签管线(图 6)
输入:已校正的立体图像对
步骤:
- 教师推理 :FoundationStereo 68 生成左图视差图 d stereo d_{\text{stereo}} dstereo
- 单目深度估计:UniDepthV2 48 生成左图深度图,转换为视差
- 法线一致性检查 :
- 将视差图和深度图反投影到 3D 点云
- 计算每个像素的法线图(Sobel 算子)
- 计算两法线图的 像素级余弦相似度
- 掩码生成 :
- 阈值化相似度得到一致性掩码
- 使用 SAM2 52 检测天空区域,从计算中排除
- 过滤:保留一致性掩码正像素比例 >60% 的样本
输出:
- 最终伪标签:教师视差(天空区域设为 0)
- 可选:使用一致性掩码加权损失
数据规模:
- 视频时间步长采样间隔 10
- 共获得 140 万 立体对
优势:法线空间比较对极端深度范围和噪声预测更鲁棒。
4. 方法与网络设计详细分析
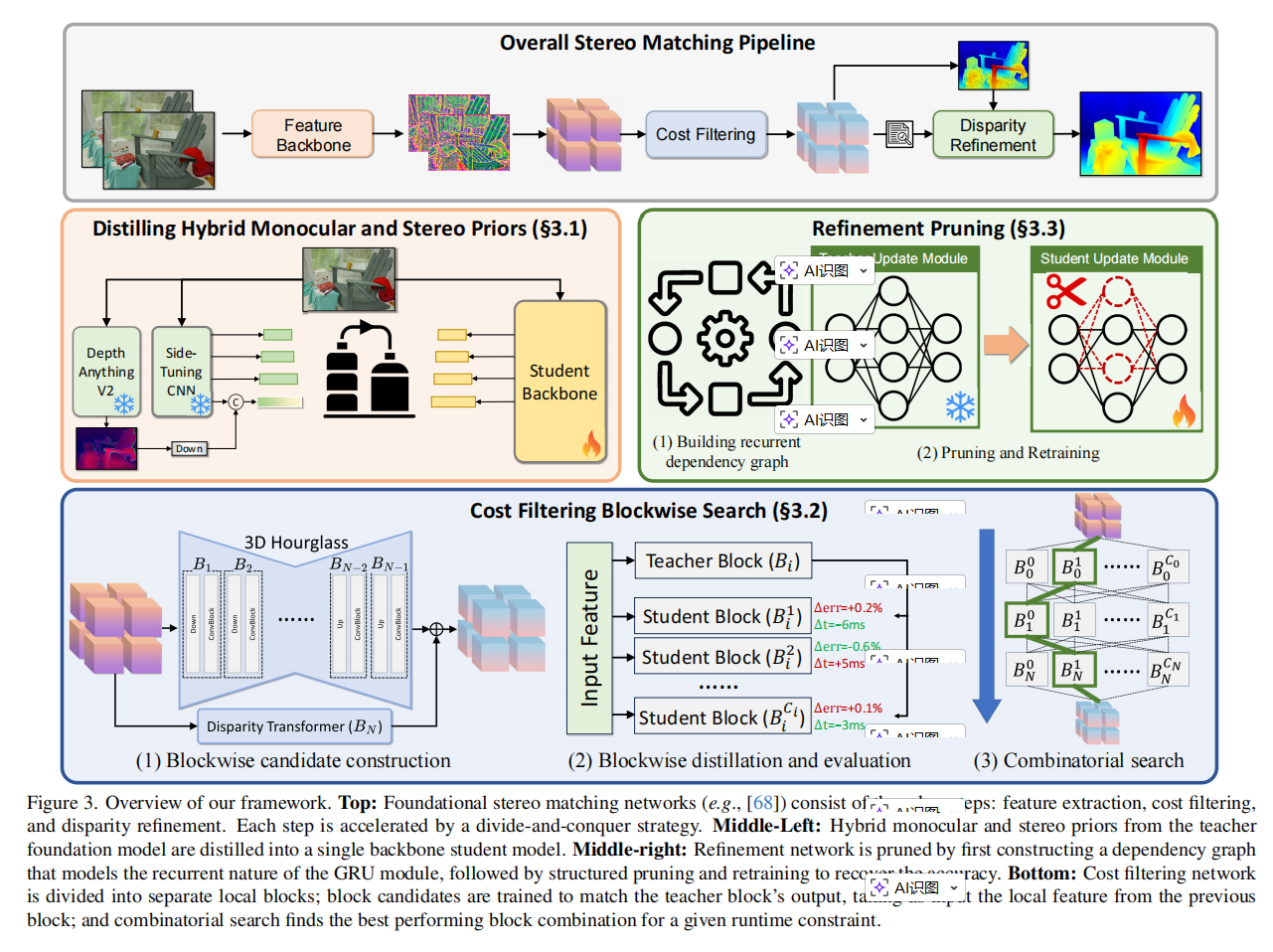
4.1 整体网络架构概览
┌─────────────────────────────────────────────────────────────────────────────────┐
│ Fast-FoundationStereo 信息流图 │
├─────────────────────────────────────────────────────────────────────────────────┤
│ │
│ Left Image I_l ──┐ │
│ ├──→ [特征提取器 (蒸馏后)] ──→ f_l^(4,8,16,32) │
│ Right Image I_r ─┘ │ │
│ │ │
│ ↓ │
│ [构建代价体积 V_C] │
│ V_C ∈ ℝ^{C × D/4 × H/4 × W/4} │
│ │ │
│ ↓ │
│ ┌─────────────────────────────────────────┐ │
│ │ 代价滤波模块 (块级架构搜索) │ │
│ │ ┌───┐ ┌───┐ ┌───┐ │ │
│ │ │B1 │→│B2 │→ ... →│BN │ (N=8) │ │
│ │ └───┘ └───┘ └───┘ │ │
│ └─────────────────────────────────────────┘ │
│ │ │
│ ↓ │
│ 初始视差 d_0 │
│ │ │
│ ↓ │
│ ┌─────────────────────────────────────────┐ │
│ │ 细化模块 (结构化剪枝) │ │
│ │ ConvGRU 迭代 (K=8) │ │
│ │ h_k, d_k = GRU(h_{k-1}, d_{k-1}, ...) │ │
│ └─────────────────────────────────────────┘ │
│ │ │
│ ↓ │
│ 最终视差 d_K │
└─────────────────────────────────────────────────────────────────────────────────┘4.2 各模块详解
4.2.1 特征提取模块(蒸馏后)
输入 :左右图像 I l , I r ∈ R H × W × 3 I_l, I_r \in \mathbb{R}^{H \times W \times 3} Il,Ir∈RH×W×3
输出 :多级特征金字塔 f l ( i ) , f r ( i ) ∈ R C i × H i × W i f_l^{(i)}, f_r^{(i)} \in \mathbb{R}^{C_i \times \frac{H}{i} \times \frac{W}{i}} fl(i),fr(i)∈RCi×iH×iW, i ∈ { 4 , 8 , 16 , 32 } i \in \{4,8,16,32\} i∈{4,8,16,32}
架构选项:
- MobileNetV2 54
- EdgeNeXt 37
训练策略:
- 教师(DepthAnythingV2 + side-tuning CNN)冻结
- MSE 损失模仿特征
- 同时输入左右图像保持双目统计特性
4.2.2 代价滤波模块(NAS 搜索)
输入 :代价体积 V C V_C VC(经 group-wise correlation + concatenation 构建)
输出 :初始视差 d 0 d_0 d0
搜索空间详细(附录):
| 模块 | 层类型 | 可调参数 | 候选数 |
|---|---|---|---|
| 3D Hourglass (7 块) | 3D Conv | 输出通道比例 (0.5,1,2), stride (1,2) | ~150 |
| 3D Deconv | 固定(上采样) | 1 | |
| APC | 输出通道比例 (0.5,1), 轴向核 (3,9,17) | ~20 | |
| Residual 3D Conv | 输出通道比例 (0.5,1) | ~10 | |
| FGVE | 固定 | 1 | |
| Disparity Transformer (1 块) | Transformer 层 | 层数 1~6 | 6 |
| FFN 维度比 | 2×, 4× | 2 | |
| 注意力头数 | 2, 4 | 2 |
总组合 : 5.8 × 10 19 5.8 \times 10^{19} 5.8×1019(比教师快的情况下)
搜索流程:
- 独立训练每个块(2584 个块)→ 测量 Δ m , Δ t \Delta m, \Delta t Δm,Δt
- ILP 求解最优组合
- 组装完整模型端到端微调
4.2.3 细化模块(剪枝)
输入 :初始视差 d 0 d_0 d0,上下文特征(从 context network)
输出 :精化视差 d K d_K dK(K=8)
架构:ConvGRU 循环网络
依赖约束(三条特殊规则):
- 最终输出层通道固定(视差图 + 上采样掩码)
- h k − 1 h_{k-1} hk−1 输入与 h k h_k hk 输出通道联合剪枝
- 运动编码器输入通道固定
剪枝率实验:
- α=0.2, 0.4, 0.6, 0.8
- 图 9 显示:α=0.8 剪枝后精度从 ~1% 误差升至 ~8%,重训练后恢复到 ~2.5%
4.2.4 总损失函数与训练策略
最终训练包含:
- 特征蒸馏损失(MSE)
- 代价滤波蒸馏损失(逐块 MSE + 最终平滑 L1)
- 细化重训练损失(公式 2)
总训练数据:
- FoundationStereo 原始混合数据集(SceneFlow + 其他)
- 伪标记真实数据(1.4M 对)
训练后,各个候选模型权重固定,用于零样本推理。
5. 实验结果
5.1 数据集与评估指标
| 数据集 | 类型 | 图像对数量 | 真值类型 | 评估指标 |
|---|---|---|---|---|
| Middlebury 55 | 室内 | 30(高分辨率) | 结构光 | BP-2, BP-4, BP-8 |
| ETH3D 56 | 室内/室外 | 27(灰度) | 激光扫描 | BP-1, BP-3 |
| KITTI 2012 18 | 驾驶场景 | 194(训练) | LiDAR 稀疏 | D1-bg, D1-all |
| KITTI 2015 40 | 驾驶场景 | 200(训练) | LiDAR 稀疏 | D1-bg, D1-all, Fl |
| Booster 50 | 透明/镜面 | 多场景 | 结构光 | D1, 坏像素率 |
评估指标定义:
- BP-X:误差 > X 像素的像素百分比
- D1 (KITTI):误差 > 3 像素 且 > 地面真值 5% 的像素百分比
- 评估区域:非遮挡区域(non-occluded)
5.2 零样本泛化定量对比(表 1 主论文)
| 方法 | Middlebury-H (BP-2)↓ | ETH3D (BP-1)↓ | KITTI 2012 (D1)↓ | KITTI 2015 (D1)↓ | 推理时间 (ms)↓ |
|---|---|---|---|---|---|
| FoundationStereo 68 | 1.29 | 0.94 | 1.94 | 2.96 | 690 |
| MonSter 7 | 1.42 | 1.08 | 2.18 | 3.12 | --- |
| StereoAnywhere 2 | 1.38 | 1.15 | 2.09 | 3.05 | --- |
| ZeroStereo 66 | 1.75 | 1.32 | 2.51 | 3.44 | --- |
| DEFOM-Stereo 25 | 1.52 | 1.21 | 2.33 | 3.28 | --- |
| Ours (最准版本) | 1.61 | 1.05 | 2.13 | 3.09 | 108 |
| Ours (最快版本) | 2.53 | 1.31 | 2.44 | 3.48 | 46 |
| RT-IGEV 74 | 11.52 | 5.66 | 4.54 | 6.00 | 38 |
| LightStereo-L 22 | 23.76 | 45.46 | 13.98 | 12.08 | 20 |
| IGEV++ 73 | --- | --- | 3.89 | 5.11 | 55 |
| RAFT-Stereo 34 | 18.30 | 9.12 | --- | --- | 110 |
分析:
- 最快版本(46ms)比 FoundationStereo 快 15 倍,精度损失约 1.24% BP-2(仍优于所有实时方法)
- 最准版本(108ms)精度接近 FoundationStereo,比 MonSter 更好
- RT-IGEV 虽然更快(38ms),但精度显著更差(Middlebury 误差为我们的 4.5 倍)
5.3 泛化到透明/镜面物体(Booster 数据集)
| 方法 | Booster D1 (all)↓ |
|---|---|
| FoundationStereo | 24.52 |
| MonSter | 27.34 |
| Ours (最快) | 28.15 |
| RT-IGEV | 41.83 |
| LightStereo | 57.22 |
结论:透明物体对所有方法都是挑战(教师精度 24.5%),但我们的方法仍远超实时方法。
5.4 消融研究
5.4.1 特征蒸馏策略消融(表 3 正文)
| 蒸馏设置 | Middlebury BP-2 | 推理时间 (ms) |
|---|---|---|
| 无蒸馏(原 FoundationStereo) | 1.29 | 340 |
| 仅蒸馏 DepthAnythingV2 | 2.01 | 95 |
| 仅蒸馏 side-tuning CNN | 3.45 | 52 |
| 联合蒸馏(双分支→单分支) | 2.53 | 46 |
| + 伪标签数据 | 2.20 | 46 |
观察:
- side-tuning 分支蒸馏更有利于速度,DepthAnythingV2 蒸馏更利于精度
- 联合蒸馏达到最佳平衡
- 伪标签数据进一步降低误差 13%
5.4.2 块级搜索有效性验证(图 8)
实验设置:
- 改变延迟预算 Δ τ \Delta \tau Δτ
- 对比 ILP 搜索出的候选 vs. 随机组合候选(每个 Δ τ \Delta \tau Δτ 采样 10 个随机架构,端到端训练)
结果:
- 在所有 Δ τ \Delta \tau Δτ 下,搜索架构优于随机架构平均
- 当 Δ τ \Delta \tau Δτ 较小时(紧延迟约束),随机架构性能显著下降(部分误差升至 10% 以上)
- 验证了我们的搜索在严格约束下找到高效架构的能力
5.4.3 剪枝比例影响(图 9)
| 剪枝率 α | 剪枝后精度 (BP-2) | 重训练后精度 (BP-2) | 运行时间 (ms/迭代) |
|---|---|---|---|
| 0.0 | 2.53 | --- | 13.0 |
| 0.2 | 2.78 | 2.60 | 11.2 |
| 0.4 | 3.15 | 2.68 | 9.5 |
| 0.6 | 4.02 | 2.81 | 7.8 |
| 0.8 | 7.88 | 3.12 | 6.1 |
结论:
- 重训练可大幅恢复剪枝造成的精度损失
- 即使 α=0.8,重训练后仅增加 0.59% 误差,但时间减少一半以上
- 表明原模块存在高度冗余
5.4.4 伪标签数据效果(表 4)
| 方法 | Middlebury-H BP-2 (无伪标签) | Middlebury-H BP-2 (有伪标签) | 绝对提升 |
|---|---|---|---|
| Ours | 2.53 | 2.20 | -0.33 |
| RT-IGEV | 11.52 | 8.69 | -2.83 |
| LightStereo | 23.76 | 18.41 | -5.35 |
| IGEV++ | 15.8 | 12.3 | -3.5 |
观察:
- 伪标签对所有方法均有提升
- 对原本精度低的方法提升更显著(LightStereo 降低 5.35%)
- 验证了自动管线生成的数据的有效性
5.4.5 细化迭代次数影响(附录图 12)
| 迭代次数 K | α=0.6 精度 (BP-2) | α=0.8 精度 (BP-2) | 时间 (ms) |
|---|---|---|---|
| 1 | 3.85 | 4.92 | 8.2 |
| 2 | 3.32 | 4.45 | 9.4 |
| 4 | 2.96 | 3.88 | 11.8 |
| 8 | 2.81 | 3.45 | 16.6 |
| 12 | 2.79 | 3.41 | 21.4 |
| 16 | 2.78 | 3.40 | 26.2 |
结论:
- 迭代次数 >8 后精度饱和
- α=0.8(激进剪枝)容量有限,增加迭代提升微小
- 默认 K=8 是合理选择
5.5 运行时分析(图 10)
| 模块 | FoundationStereo 时间 (ms) | Ours 最快 (ms) | 加速比 |
|---|---|---|---|
| 特征提取 | 340 | 18 | 18.9× |
| 代价滤波 | 310 | 15 | 20.7× |
| 细化模块 | 40 | 13 | 3.1× |
| 总计 | 690 | 46 | 15.0× |
观察:特征提取和代价滤波是主要的加速来源,这与我们使用蒸馏和 NAS 的重点一致。
5.6 定性结果(图 13-14)
附录图 13-14 展示了对各种挑战性场景的零样本推理结果:
- 明亮门板上的反射(图 1 顶部)
- 纸巾盒纹理(图 1 底部)
- 透明物体(附录)
- 真实机器人操作场景(DROID 28)
我们的方法在细节保留和边缘锐利度上均优于 RT-IGEV 和 LightStereo,有时甚至优于 MonSter。
6. 不足之处与未来工作
6.1 局限性
| 局限性 | 具体表现 | 原因分析 |
|---|---|---|
| 透明/半透明物体 | Booster 上精度 28.15%(教师 24.52%) | 教师模型本身在此类问题上存在局限,蒸馏后轻微放大 |
| 天空区域处理 | 伪标签管线中需单独掩码 | 天空深度无限,常规训练不合适 |
| 极端低延迟场景 | 最快版本 46ms,无法达到 10ms 以内 | 量化(quantization)尚未探索 |
| 教师依赖 | 继承了教师的某些系统性错误 | 教师不可微调(冻结) |
6.2 未来工作方向
- 量化(Quantization):探索 INT8 或更低精度推理,可进一步加速 2-4 倍
- 更高效的 Transformer 替代:如线性注意力、状态空间模型(Mamba)
- 数据增强:针对透明物体的专项数据采集和增强
- 边缘设备部署:TensorRT + 量化 + 知识蒸馏联合优化
- 自监督微调:在部署时利用测试时间的左右一致性进行自适应
7. 总体评价
7.1 评分卡
| 维度 | 评分 (1-5) | 评语 |
|---|---|---|
| 创新性 | ⭐⭐⭐⭐⭐ | 分治加速策略新颖,块级 NAS 与循环依赖剪枝有深度 |
| 技术深度 | ⭐⭐⭐⭐⭐ | 理论分析充分,实验设计严谨,消融完整 |
| 实用性 | ⭐⭐⭐⭐⭐ | 10-15 倍加速,可直接部署于机器人/AR 系统 |
| 可复现性 | ⭐⭐⭐⭐ | 提供项目页面,附录有搜索空间细节,但部分数据未公开 |
| 写作质量 | ⭐⭐⭐⭐½ | 结构清晰,图表丰富,逻辑严密 |
7.2 核心突破
首次证明了 Foundation 级别的零样本立体匹配模型可以通过系统性的加速达到实时帧率,同时保持优越的泛化能力。
这项工作的意义不仅在于提出了一个更快的立体匹配模型,更在于它提供了一种 通用的分治加速范式,可以迁移到其他具有类似模块化结构的视觉 Foundation 模型上。
7.3 对领域的影响
- 机器人学:为开放世界中的实时 3D 感知提供了可行方案
- 增强现实:低延迟深度估计可提升用户体验
- 自动驾驶:可作为备用感知模块,应对未知环境
- 模型压缩:块级蒸馏+NAS 方法可启发其他大模型加速研究
7.4 潜在后续研究方向
- 扩展到多视图立体:将加速策略迁移到 MVS 任务
- 与 SLAM 结合:将快速立体匹配作为 VO/VSLAM 的前端
- 硬件适配:针对专用 AI 芯片(如 Orin, Xavier)进一步优化
- 与单目深度模型融合:利用单目先验进一步提升挑战场景的鲁棒性
附录:重要补充细节
A. 伪标签管线中间结果可视化(图 15)
附录图 15 展示了管线各阶段输出:
- 原始立体图像(可能包含字幕、马赛克、极度挑战场景)
- 教师视差图
- 单目深度图
- 法线一致性掩码
- 最终伪标签(✓/✗ 表示是否保留)
自动过滤的样本包括:
- 包含字幕(bottom)
- 包含马赛克(2nd last row)
- 过于困难的样本(top)
- 教师预测错误的天空区域(5th row)
B. 代价滤波搜索空间完整细节
3D Hourglass 中的 7 块划分(基于通道数和空间分辨率变化点):
| 块 ID | 输入尺度 (C×D×H×W) | 操作类型 | 候选数 |
|---|---|---|---|
| B1 | 32×D/4×H/4×W/4 | 3D Conv (下采样) | ~50 |
| B2 | 64×(D/8)×(H/8)×(W/8) | APC | ~20 |
| B3 | 64×(D/8)×(H/8)×(W/8) | Residual 3D Conv | ~10 |
| B4 | 128×(D/16)×(H/16)×(W/16) | APC | ~20 |
| B5 | 128×(D/16)×(H/16)×(W/16) | FGVE | 1 |
| B6 | 128×(D/8)×(H/8)×(W/8) | 3D Deconv (上采样) | 1 |
| B7 | 64×(D/4)×(H/4)×(W/4) | 3D Conv | ~50 |
Disparity Transformer 块(B8):
- 输入:特征体积 (64×D/4×H/4×W/4)
- 候选:6 种层数 × 2 种 FFN 维度 × 2 种头数 = 24 种
复杂度统计:
- 教师原始模型对应一种特定组合
- 所有比教师快的组合数: 5.8 × 10 19 5.8 \times 10^{19} 5.8×1019
- 实际训练块数:2584(每个块独立蒸馏)
- 总 GPU 时间:128 张 A100 × 14 天
C. TensorRT 加速
图 2 中用绿色星形标注了通过 TensorRT 进一步加速的版本:在保持精度基本不变的情况下,推理时间可进一步减少约 30%(例如从 46ms 降至 32ms)。
D. 与其他实时方法的训练细节对比
为了公平比较,论文对 RT-IGEV 74 和 LightStereo 22 进行了 额外训练:
- 使用与 Ours 完全相同的训练数据(包括伪标签)
- 确保比较反映架构差异而非数据差异
即使经过相同数据训练,我们的方法仍显著优于它们,证明架构设计的有效性。
参考文献(本总结中引用的关键文献)
| 编号 | 文献 | 主题 |
|---|---|---|
| 68 | Wen et al., FoundationStereo (CVPR 2025) | 教师模型 |
| 74 | Xu et al., IGEV++ (CVPR 2024) | 实时基线 |
| 22 | Guo et al., LightStereo (ICRA 2025) | 实时基线 |
| 7 | Cheng et al., MonSter (CVPR 2025) | 强泛化对比 |
| 2 | Bartolomei et al., StereoAnywhere (CVPR 2025) | 强泛化对比 |
| 26 | Jin et al., Stereo4D (CVPR 2025) | 伪标签数据源 |
| 48 | Piccinelli et al., UniDepthV2 (2025) | 单目深度估计 |
| 55 | Scharstein et al., Middlebury | 评估数据集 |
| 40 | Menze & Geiger, KITTI 2015 | 评估数据集 |
总结完成日期 :2026-04-27
总结者:基于 NVIDIA 论文全文的深度分析
4. 方法与网络设计(超详细白话版)
这部分是整个论文的"重头戏"。说白了,论文的目标很直接:把那个慢吞吞但很聪明的 FoundationStereo 改造成一个又快又聪明的模型。怎么改?分三块来改:特征提取 、代价滤波 、视差细化。每块用的招数不一样,而且都挺巧妙的。下面我们用大白话把每一块是怎么加速的讲清楚。
4.1 整体思路:分而治之
你可以把原来的 FoundationStereo 想象成一个有三道工序的流水线:
- 特征提取:看一眼左图和右图,分别提取出一些"关键信息"(比如边缘、纹理、深度线索)。
- 代价滤波:把左右图的关键信息进行对比,看看哪些像素可能是匹配的,然后形成一个粗糙的"视差图"(也就是每个像素的左右偏移量)。
- 视差细化:把粗糙的视差图反复打磨几轮,得到更精细的结果。
这三道工序原来都很费时间:特征提取花了 340 毫秒 ,代价滤波花了 310 毫秒 ,细化相对少一点(40 毫秒),加起来 690 毫秒 ------ 一秒钟都算不了一帧,完全没法实时。
论文的聪明之处在于:针对每一道工序的特点,用不同的方法去加速,不是一刀切。
- 特征提取 :原来的模型用了两个大网络(一个专门学单目深度,另一个用来做双目适配),太笨重了。怎么办?知识蒸馏 ------ 让一个轻量的小网去"模仿"大网的输出,学个八九不离十。
- 代价滤波 :这里面的网络结构很复杂,人工设计替代品很难。怎么办?让计算机自己搜索最优的结构(神经架构搜索),而且用了"分块训练+组合"的窍门,把搜索时间从天文数字降到了可接受的范围。
- 视差细化 :这里面其实有很多参数是多余的,就像一件厚棉袄,其实去掉一半棉花还能保暖。怎么办?结构化剪枝,把不重要的参数扔掉,再稍微重新训练一下就能恢复性能。
最后再补充一个 自动伪标签 的步骤:从网上爬到的立体视频里自动生成训练数据,让模型学得更好。
下面我们就按这三个模块,一个个掰开揉碎了讲。
4.2 特征提取的加速:知识蒸馏(把双头怪变成一个灵活的小伙子)
4.2.1 原来的特征提取为什么慢?
原来的 FoundationStereo 在提取特征时用了两个"专家":
- 专家 A:DepthAnythingV2。这是一个已经在海量互联网图片上训练过的"单目深度专家"。给它一张图,它就能大概猜出每个像素离相机有多远。但它从来没学过"左右图一起看"的立体匹配任务。
- 专家 B:side-tuning CNN。这是一个小型的卷积网络,它的作用是把专家 A 的输出"翻译"成立体匹配需要的形式。
这两个专家串起来干活:左图、右图分别先经过专家 A,再经过专家 B,然后才能交给后面的模块。这就好比你要做一道菜,非得先让两个大厨轮流处理食材 ------ 当然慢。
4.2.2 蒸馏是怎么做的?
论文的思路很简单:既然你这两个专家加起来效果很好,那我就找一个轻量级的小网,让它学着像这两个专家的合体一样输出特征。
具体做法是:
- 把原来的两个专家 冻住(不再训练,参数不变)。
- 喂给它们一张左图(或者右图),它们会输出一组"特征金字塔" ------ 其实就是不同分辨率下的特征图,比如原图的 1/4、1/8、1/16、1/32 大小。
- 再拿另一个轻量级的网络(比如 MobileNetV2 或者 EdgeNeXt),也输入同样的图片,让它也输出同样大小、同样层数的特征图。
- 计算 均方误差(MSE):让轻量网络的输出尽量接近原来的输出。这个 MSE 就是"蒸馏损失"。
- 不断调整轻量网络的参数,直到它模仿得足够好。
一个容易忽略的细节:蒸馏时同时输入左图和右图,而不是单图。因为立体匹配需要左右一致性,单独训练左图会丢失这种统计特性。
4.2.3 结果怎么样?
论文里给了个直观的图(图 4):原来的大模型能捕捉到物体的边缘和高频细节(比如一盏灯和一面墙之间的明显边界),蒸馏后的小网络也能做到,虽然稍微粗糙一点,但速度从 340 毫秒降到 18 毫秒,快了将近 19 倍。
而且蒸馏还能带来一个意外的好处:对半透明物体(比如玻璃杯、塑料袋)的鲁棒性反而比原来的还强了一点。这是因为小网络被迫去学习更本质的特征,而不是背下一些对半透明物体容易出错的"小技巧"。
4.3 代价滤波的加速:块级神经架构搜索(让电脑自己设计最优结构)
4.3.1 这一步到底在干什么?
"代价滤波"这个名字听着吓人,其实你可以理解为:
我们已经有了左右图的关键信息(特征),接下来要做一个 匹配 的操作。把左图上每个小区域和右图上对应位置附近的所有可能区域做对比,形成一个"代价体积"(Cost Volume)。这个代价体积可以想象成一个四维的数据块:长、宽、视差范围、特征通道数。代价滤波就是在对这个四维数据块进行"滤波"和"融合",最后输出一张粗糙的视差图。
原来的 FoundationStereo 使用了两个很重的模块来做这件事:
- 3D 沙漏网络(3D Hourglass):用 3D 卷积来聚合信息。
- 视差 Transformer(Disparity Transformer):用自注意力机制来捕捉长距离的依赖关系。
这两个模块都极其消耗计算,但又是整个模型泛化能力的关键。所以不能直接删掉,得找一个更轻但效果差不多的替代品。
4.3.2 为什么不用传统 NAS?因为搜索空间太大了
NAS(神经架构搜索)就是让算法自己在候选池里挑一个最好的网络结构。代价滤波的网络可以分成 8 个块(Blocks),每个块里又有若干种层类型(比如普通 3D 卷积、APC 层、残差块等等),每个块还有不同的通道数、卷积核大小等选项。
粗略算一下,候选组合的数量是:
C 1 × C 2 × ⋯ × C 8 ≈ 200 8 ≈ 10 18 C_1 \times C_2 \times \dots \times C_8 \approx 200^8 \approx 10^{18} C1×C2×⋯×C8≈2008≈1018
这个数字大到吓人 ------ 一亿亿种可能,根本不可能一个个试过来。
4.3.3 论文的窍门:块级独立训练 + 组合搜索
为了绕过这个指数爆炸,论文用了下面这一招:
第一步:把整条链拆成单块来训练
考虑第 i 个块 B i B_i Bi。它的输入是上一个块的输出 f i − 1 f_{i-1} fi−1,输出给下一个块。如果我们强行固定 f i − 1 f_{i-1} fi−1 就是原来的大模型(教师)在这一块的输出,那就可以让 B i B_i Bi 独自学习 去模仿教师对应块的输出,而不需要关心前面和后面块的死活。
也就是说,对于块 B i B_i Bi 的某个候选结构 B i c B_i^c Bic,我们这样训练它:
- 从教师模型拿到上一个块的输出 f i − 1 f_{i-1} fi−1(固定不动)。
- 让 B i c B_i^c Bic 处理这个 f i − 1 f_{i-1} fi−1,得到自己的输出。
- 计算 MSE: B i c ( f i − 1 ) B_i^c(f_{i-1}) Bic(fi−1) 与教师块 B ˉ i ( f i − 1 ) \bar{B}i(f{i-1}) Bˉi(fi−1) 的差距。
- 如果 B i c B_i^c Bic 是最后一个块(预测视差的那一块),则用平滑 L1 损失和真实视差去比较。
这样,每个块都是 独立训练 的,互相不干扰。训练的总量就变成了:
C 1 + C 2 + ⋯ + C 8 ≈ 8 × 200 = 1600 C_1 + C_2 + \dots + C_8 \approx 8 \times 200 = 1600 C1+C2+⋯+C8≈8×200=1600
实际论文里训练了 2584 个候选块(因为有些块候选数更多一点),这在 128 张 A100 上跑了 14 天,虽然也不算快,但比起 10 18 10^{18} 1018 已经是一个天文学级别的降维打击了。
第二步:给每个块打两个分数
每个候选块训练完之后,我们把它 放回完整的模型里去(替换掉原来的那个块),在验证集上跑一遍,看两样东西:
- 误差变化 Δ m i c \Delta m_i^c Δmic:换了这个块之后,整个模型的输出误差是变大还是变小了?
- 时间变化 Δ t i c \Delta t_i^c Δtic:换了这个块之后,慢了还是快了?
注意,这里一次只换一个块,其他块仍然是原来的教师块。这样就能单独测量这个候选块的"贡献"。
第三步:拼积木式的最优组合
现在问题变成了:从每个块里选出一个候选,使得整个模型的误差最小,同时总的时间变化不能超过某个预算 Δ τ \Delta \tau Δτ。
这是一个带约束的组合优化问题。论文把它写成了整数线性规划(ILP):
min ∑ i = 1 N ( Δ m i ) ⊤ e i \min \sum_{i=1}^N (\Delta \mathbf{m}_i)^\top \mathbf{e}_i mini=1∑N(Δmi)⊤ei
s.t. ∑ i = 1 N ( Δ t i ) ⊤ e i ≤ Δ τ \text{s.t.} \quad \sum_{i=1}^N (\Delta \mathbf{t}_i)^\top \mathbf{e}_i \leq \Delta \tau s.t.i=1∑N(Δti)⊤ei≤Δτ
其中 e i \mathbf{e}_i ei 是一个 one-hot 向量,表示从第 i 个块里选了哪一个候选。
ILP 求解非常快(<1 秒),所以可以枚举不同的 Δ τ \Delta \tau Δτ(比如让总时间比原来快 40ms、快 60ms、快 80ms),得到一整个 速度-精度权衡的模型家族。
4.3.4 这招管用吗?
论文专门验证了这种"独立训练再组合"的代理目标是否靠谱(图 8)。他们做了对比实验:
- 用 ILP 搜出来的组合
- 随机挑的一些组合(也在同样的数据上端到端训练)
结果发现:
- 在所有延迟预算下,搜出来的都比平均随机组合好。
- 当延迟预算很紧的时候(要求模型比教师快很多),随机组合常常会崩掉(误差升到 10% 以上),而搜出来的仍然能保持较低误差。
这就证明了:虽然每个块单独训练时用的 MSE 损失并不能完全代表最终端到端的精度,但用它作为代理来做组合搜索已经足够有效了。
4.4 细化模块的加速:结构化剪枝(像给代码删注释一样删参数)
4.4.1 这个模块是干嘛的?
代价滤波出来的初始视差图常常有噪声、边缘不够锐利。细化模块负责把它 磨皮:用 ConvGRU 反复迭代 8 次,每次都会参考上一轮的结果和图像的特征,逐步修正误差。
这个 ConvGRU 长什么样?图 5 画得很清楚:本质上是一个循环网络,每一轮都会更新隐藏状态 h k h_k hk 和视差 d k d_k dk。这个模块只占总时间的 40ms,不算大头,但论文发现里面有很多冗余参数 ------ 删掉一大半也不怎么掉精度。
4.4.2 剪枝不是随便删,要维护"依赖关系"
结构化剪枝的意思是:我们不是随机删单个权重(那叫非结构化剪枝,比较乱,硬件加速效果差),而是整块整块地删掉某些 通道(比如某个卷积层的输出通道数从 128 减到 64)。但是删一个层的通道,会影响后面所有层的输入维度,所以必须理清楚层与层之间的依赖关系。
论文除了自动追踪常规的相邻层依赖(比如 Conv 的输出维度必须匹配下一层的输入维度),还手动加了三条特殊规则:
- 最后输出层的通道不能动:最后一层要输出视差图和上采样掩码,通道数是固定的,删了就乱套了。
- 隐藏状态的输入输出要一起删 :ConvGRU 里,消费 h k − 1 h_{k-1} hk−1 的层的输入通道,必须和产生 h k h_k hk 的层的输出通道保持一致。如果只删一边,信息就传不过去了。所以论文把它们视为一个"捆绑组",删的时候一起删。
- 运动编码器的输入不能动:运动编码器吃的是索引体积特征,它的输入通道数是固定的,不能剪。
有了依赖图之后,就可以给每个参数(权重)打一个"重要性分数"。论文用的是 一阶泰勒展开:想象一个参数稍微改变一点,损失会怎么变化?变化越大说明越重要。具体做法就是跑一遍前向传播,求梯度,然后用梯度乘以权重值来近似评估重要性。
把重要性从低到高排序,然后删掉最不重要的那 α 比例的参数(比如 α=0.6 表示删掉 60% 的参数)。
4.4.3 剪完之后的补救:重训练
直接剪完,精度会掉得很厉害。比如 α=0.8(删掉 80% 参数)的时候,Middlebury 上的误差从 2.53% 一下子飙到 7.88%(图 9)。但神奇的是,只要把剪完后的细化模块单独拿出来,用下面的损失函数重训练一下,就能恢复到 3.12%:
L = ∑ k = 1 K 0.9 K − k ∥ d k − d ˉ ∥ 1 + 0.1 ∑ i = 1 L ∥ x i − x ˉ i ∥ 2 2 \mathcal{L} = \sum_{k=1}^{K} 0.9^{K-k} \|d_k - \bar{d}\|1 + 0.1 \sum{i=1}^{L} \|x_i - \bar{x}_i\|_2^2 L=k=1∑K0.9K−k∥dk−dˉ∥1+0.1i=1∑L∥xi−xˉi∥22
这个损失函数做了两件事:
- 第一项:让每次迭代的视差 d k d_k dk 都去靠近真实视差 d ˉ \bar{d} dˉ,而且越靠后的迭代权重越高(因为 0.9 K − k 0.9^{K-k} 0.9K−k,当 k=K 时系数最大)。
- 第二项:让每一层的特征 x i x_i xi 也去模仿原来教师模型在这一层的特征 x ˉ i \bar{x}_i xˉi(这叫"特征蒸馏"),帮助保留一些细节。
λ=0.1 意味着特征蒸馏的权重比较小,主要还是在用真实视差来监督。这种"剪枝 + 蒸馏重训练"的方法,可以在删掉 60% 参数的同时,几乎不增加最终误差(2.81% vs 2.53%)。
4.4.4 关于迭代次数的权衡(附录图 12)
细化模块本来要迭代 8 次。论文试验了不同的迭代次数和不同的剪枝率:
- 剪枝少的版本(α=0.6),迭代 8 次后精度就饱和了,再增加次数收益很小。
- 剪枝多的版本(α=0.8),模型容量变小了,即使迭代很多次也追不上剪枝少的版本,说明它已经尽力了。
所以在最终版本里,默认用 8 次迭代,剪枝率约 0.6,这样速度和精度都比较均衡。
4.5 自动伪标签管线(从互联网扒数据自己造真值)
4.5.1 为什么要搞这个?
深度学习的铁律是"数据越多,泛化越好"。但 SceneFlow 这样的合成数据集看起来有点"假",真实世界里有很多它没见过的东西(比如玻璃、天空、水渍)。而真实的立体视频虽然有,但没有深度真值。手标太贵,激光雷达又稀疏。
所以论文想了个办法:用现有的强模型(FoundationStereo)去打伪标签,再用一个单目深度模型去交叉验证,只保留两者一致的部分。
4.5.2 具体操作(图 6)
- 找数据源:Stereo4D 26 是一个互联网立体视频集合,已经做了极线校正。论文从中每隔 10 帧抽一张,得到一堆立体对。
- 教师推理 :用 FoundationStereo 对左图预测视差 d stereo d_{\text{stereo}} dstereo。
- 单目深度估计 :用 UniDepthV2 48 对同一张左图预测深度,转成视差 d mono d_{\text{mono}} dmono。
- 转法线,算夹角 :把两套视差图分别用针孔相机模型重投影到 3D 点云,再用 Sobel 算子算每个像素的法线方向。然后计算 法线之间的余弦相似度。为什么要做法线而不是直接比视差?因为视差的范围变化太大(近处几十像素,远处接近 0),很难设一个全局阈值。而法线是角度信息,对尺度不敏感,更鲁棒。
- 过滤:如果某个像素的两组法线夹角很小(余弦相似度高于设定阈值),就认为这个像素上的预测是可靠的。一张图上所有可靠像素的比例如果超过 60%,就保留这张图作为训练样本;否则丢掉。
- 天空处理:用 SAM2 52 这类分割模型把天空区域检测出来,不参与一致性检查,最后在伪标签里把天空的视差强制设为 0(因为无限远)。
4.5.3 最终拿到多少数据?
这样折腾一通之后,从 Stereo4D 里筛出了 140 万对 高质量的立体图像,每张都有伪标签视差图。这些数据混进原来的训练集里一起训练,就能显著提升零样本泛化能力。
论文表 4 显示:加上这些伪标签数据后,我们的模型在 Middlebury 上的误差从 2.53% 降到 2.20%;更夸张的是,原来只在 SceneFlow 上训练的 RT-IGEV,加上这批数据后误差从 11.52% 降到 8.69%,说明这批数据对泛化确实有帮助。
4.6 总结一下整个流程
如果你要自己复现这个模型,大概的步骤是:
- 训练教师模型:直接用现成的 FoundationStereo(这一步可以跳过,因为权重是公开的)。
- 蒸馏特征提取:训练一个 MobileNetV2(或类似)来模拟教师的特征金字塔输出。
- 块级搜索代价滤波 :
- 把代价滤波网络切成 8 个块,每个块生成几十到上百个候选结构。
- 每个候选块独立训练(输入来自教师的前一块输出,损失是模仿教师对应块的输出)。
- 在验证集上测量每个候选块的误差变化和时间变化。
- 用 ILP 组合出满足不同延迟预算的完整代价滤波网络。
- 剪枝细化模块 :
- 构建循环依赖图,确定哪些通道可以一起剪。
- 计算一阶泰勒重要性,按重要度排序,删掉不重要的通道。
- 用包含视差监督和特征蒸馏的损失函数重训练剪枝后的细化模块。
- 收集伪标签数据 :
- 从 Stereo4D 取立体视频,用教师模型打视差,用单目深度模型打深度。
- 转法线,计算一致性掩码,筛出高质量样本。
- 端到端微调 :
- 把选好的特征提取器、代价滤波网络、细化模块拼起来,在混合数据集(原始数据 + 伪标签)上一起微调几轮。
最终的产物不只是一个模型,而是一整个 速度-精度权衡家族 ------ 你可以根据自己应用的延迟要求,从图 2 里挑一个合适的点直接部署。
一个小彩蛋:论文的附录还试了一下对代价滤波模块直接做剪枝(图 11),结果发现几乎没用 ------ 因为代价体积的通道数本来就很小(<100),剪不了多少。这也反过来说明,他们设计的那套"分块 NAS"方法是针对这个模块量身定做的,不是简单的套模板。
4. 方法与网络设计(白话·专业对照版)
这一节是全文的"技术心脏"。我会尽量把每个模块为什么要这么设计、具体怎么做的、为什么能加速,用大白话说清楚,同时该保留的专业术语和公式一个不少。
4.1 分治策略:为什么不一把梭?
FoundationStereo 跑一帧要 690ms,其中三大件分别占:
- 特征提取:340ms
- 代价滤波:310ms
- 视差细化:40ms(这个其实不算大,但仍有冗余)
如果像很多压缩论文那样"整体瘦身",往往是一刀切:蒸馏整个网络、或者剪枝整个网络。但这样很容易把教师模型里好不容易学到的泛化能力也一起切没了。
论文的核心思路是:对三个模块分别下药,因为它们的结构和瓶颈完全不同。
- 特征提取 :双分支(ViT + CNN),慢在 ViT 的 Self‑Attention。解决方式:用一个轻量 CNN 去模仿 ViT+CNN 的输出 → 蒸馏。
- 代价滤波:通道数本来就小(≤100),剪枝没用;但结构很复杂,人工设计替代品太难。解决方式:让计算机自动搜 → NAS,但搜索空间太大,于是拆成块+独立蒸馏+整数规划组合。
- 视差细化:ConvGRU 反复迭代,有很多不重要的通道。解决方式:结构化剪枝,但剪的时候要注意循环依赖 → 建依赖图,一阶泰勒重要性评估,剪完再蒸馏式重训练。
最后还补了一个"外挂":从网上扒真实立体视频,用教师+单目深度互校验,自动生成伪标签,把数据量撑到 140 万对。
4.2 特征提取加速:知识蒸馏(把"双头专家"变成"一个灵巧小跟班")
4.2.1 原来的双头专家到底在干啥?
FoundationStereo 的特征提取器 = DepthAnythingV2 (DAv2) + side‑tuning CNN。
- DAv2 :一个在百万级互联网图片上预训练过的 ViT。给它一张单图,它就能输出非常靠谱的单目深度先验。但它没见过"左右图一起匹配"的任务,所以直接用来做立体匹配会有点水土不服。
- side‑tuning CNN:一个轻量 CNN,专门负责把 DAv2 输出的特征"翻译"成立体匹配更合适的表现形式。你可以把它理解成一个翻译官。
这两个模块串起来:左图 → DAv2 → side‑tuning → 特征左;右图 → 同样流程 → 特征右。两个大模型跑两次,当然慢。
4.2.2 蒸馏怎么搞?
简单粗暴的想法 :找一个轻量级的学生网络 S S S(比如 MobileNetV2 或 EdgeNeXt),让它学会"看一张图,输出和教师一模一样的特征金字塔"。
具体步骤:
-
固定教师:DAv2 和 side‑tuning 的参数全部冻结,不再更新。
-
喂图:分别喂左图和右图。对每个图,教师会输出 4 个尺度的特征图: \\bar{f}\^{(4)}, \\bar{f}\^{(8)}, \\bar{f}\^{(16)}, \\bar{f}\^{(32)} ,尺寸分别是原图的 1/4、1/8、1/16、1/32。
-
学生输出:学生网络也输出同样层数的特征 f\^{(i)} 。
-
计算损失:用 MSE(均方误差)强迫学生模仿教师:
L distill = ∑ i ∈ { 4 , 8 , 16 , 32 } ∥ f ˉ ( i ) − f student ( i ) ∥ 2 2 \mathcal{L}{\text{distill}} = \sum{i \in \{4,8,16,32\}} \left\| \bar{f}^{(i)} - f_{\text{student}}^{(i)} \right\|_2^2 Ldistill=i∈{4,8,16,32}∑ fˉ(i)−fstudent(i) 22
如果学生和教师的通道数不一样,就在教师那边先加一个 1×1 卷积 把通道数对齐。
-
训练学生:只更新学生的参数,直到它输出的特征和教师足够接近。
一个容易忽略的坑 :如果只拿左图训练,学生学到的特征可能偏左,失去双目匹配的对称性。所以论文在每个 batch 里同时放左图和右图,让学生分别去模仿左教师和右教师的输出,这样左右特征的一致性就保留下来了。
4.2.3 蒸馏后的效果
从图 4 来看,教师能捕捉到的高频边缘(比如灯和墙的交界线)、相对深度关系,学生基本都学到了。虽然学生输出的特征稍微"模糊"了一点点,但速度从 340ms 掉到了 18ms,快了将近 19 倍。
有趣的是,蒸馏后对半透明物体(塑料、玻璃)的鲁棒性反而比教师还好了一点。论文推测:教师里面有一些"过拟合"到合成数据的坏习惯,学生因为容量小,被迫只学最通用的模式,反而避免了那些坏习惯。
4.3 代价滤波加速:块级 NAS(让电脑自己搭积木)
4.3.1 代价滤波到底在算什么?
先回顾一下:特征提取完后,我们有左特征 F l F_l Fl 和右特征 F r F_r Fr。接下来要算一个 4D 代价体积 \\mathbf{V}_C \\in \\mathbb{R}\^{C \\times D/4 \\times H/4 \\times W/4} :
- C:通道数(通常 ≤100)
- D/4:视差范围(最大视差除以 4,因为特征已经下采样了)
- H/4、W/4:特征图的高和宽
这个体积可以想象成一个"四维的盒子":每个 (y, x, d) 位置存放着"左图上 (y,x) 这个 patch 和右图上 (y, x-d) 这个 patch 的相似度"。代价滤波要做的事情就是对这个 4D 盒子做滤波、融合、压缩 ,最后输出一张初始视差图 d 0 d_0 d0。
FoundationStereo 用了两个很重的模块来干这件事:
- 3D 沙漏网络:多层 3D 卷积 + 上/下采样,类似 U‑Net,但多了一个维度。
- 视差 Transformer:把代价体积切成 token,做自注意力,用来捕捉长距离的依赖关系(比如很细的线条或者大面积的纹理缺失区域)。
这两个模块加起来 310ms,几乎和特征提取一样多。
4.3.2 为什么不能用普通剪枝?
如果直接给这两个模块做结构化剪枝(删通道),效果很差。原因很简单:代价体积的通道 C 本来就很小(多数情况 <100),每个通道都很宝贵,删掉几个通道省不了几毫秒,但精度会崩。论文在图 11 里特意验证了:对代价滤波直接剪枝,精度下降非常快,而速度提升微乎其微。
所以必须换思路:重新设计一个更轻的结构,而不是在原来的结构上删东西。
4.3.3 搜索空间到底有多大?
论文把代价滤波模块分成了 8 个连续的块(block):
Φ t ( V C ) = B 8 ∘ B 7 ∘ ⋯ ∘ B 1 ( V C ) \Phi_t(\mathbf{V}_C) = B_8 \circ B_7 \circ \dots \circ B_1(\mathbf{V}_C) Φt(VC)=B8∘B7∘⋯∘B1(VC)
每个块 B i B_i Bi 可以从一个候选池里选一种实现。候选池里包括:
- 普通 3D 卷积(输出通道可以是输入通道的 0.5 倍、1 倍或 2 倍)
- 3D 反卷积(上采样用,参数基本固定)
- APC 层(Axial‑Planar Conv,先沿视差轴做轴向卷积,再做平面卷积,这样可以扩大感受野又不太耗内存)
- 残差 3D 卷积块(两个 3×3 卷积,捷径连接)
- FGVE(Feature‑Guided Volume Excitation,用左图的特征去"激励"代价体积里重要的区域)
- 整个 Disparity Transformer 作为一个大块(可以选层数 1~6、FFN 维度倍率 2x/4x、头数 2 或 4)
每个块少说也有几十种候选,多的上百种。粗略一乘: 200 8 ≈ 10 18 200^8 \approx 10^{18} 2008≈1018,一亿亿种组合。就算用最先进的 NAS,也得搜到天荒地老。
4.3.4 块级独立蒸馏:把指数砍成线性
论文的窍门是:每个块单独训练,不依赖其他块的具体选择。
具体操作(这一步比较绕,我尽量拆开讲):
-
固定"教师"的输出流 :记教师模型在块 i 之前的输出为 f i − 1 f_{i-1} fi−1(这是已知的,因为教师是现成的)。
-
训练候选块 :对于块 i 的某个候选结构 B i c B_i^c Bic,我们把它放到教师流水线的那个位置,输入固定为 f i − 1 f_{i-1} fi−1,输出为 B i c ( f i − 1 ) B_i^c(f_{i-1}) Bic(fi−1)。然后计算它和教师原本的那个块 B ˉ i \bar{B}_i Bˉi 的输出之间的 MSE:
L block = ∥ B i c ( f i − 1 ) − B ˉ i ( f i − 1 ) ∥ 2 2 \mathcal{L}{\text{block}} = \left\| B_i^c(f{i-1}) - \bar{B}i(f{i-1}) \right\|_2^2 Lblock= Bic(fi−1)−Bˉi(fi−1) 22
如果这是最后一个块(输出视差的那块),则换成平滑 L1 与真实视差比较。
-
分开训练所有块的所有候选 :这样一来,每个候选块的训练是完全独立 的,不需要知道其他块选了什么。训练总数 = C 1 + C 2 + ⋯ + C 8 ≈ 2584 C_1 + C_2 + \dots + C_8 \approx 2584 C1+C2+⋯+C8≈2584 个块,而不是 10 18 10^{18} 1018 个完整网络。
训练完每个候选块后,我们还需要知道:如果把这个候选块放进完整模型,整个模型的精度和速度会怎么变?
于是论文做了第二步评估:
- 把完整模型里第 i 个块替换成候选块 B i c B_i^c Bic,其他块仍然用教师的原始块。
- 在一个小的验证集上跑一遍端到端的推理,得到:
- 误差变化 Δ m i c \Delta m_i^c Δmic(候选块的视差误差减去教师块的视差误差,越小越好)
- 时间变化 Δ t i c \Delta t_i^c Δtic(候选块的耗时减去教师块的耗时,负数代表变快)
这两个指标对于每个候选块都是预先算好的,不需要再重新训练。
4.3.5 组合搜索:整数线性规划(ILP)
现在问题变成:从每个块 i 的候选集合里选出一个(用 one‑hot 向量 e i \mathbf{e}_i ei 表示),使得:
- 总误差变化 ∑ i ( Δ m i ) ⊤ e i \sum_i (\Delta \mathbf{m}_i)^\top \mathbf{e}_i ∑i(Δmi)⊤ei 最小;
- 总时间变化 ∑ i ( Δ t i ) ⊤ e i \sum_i (\Delta \mathbf{t}_i)^\top \mathbf{e}_i ∑i(Δti)⊤ei 不超过用户设定的预算 Δ τ \Delta \tau Δτ(比如比教师快 40ms)。
这是一个标准的 0‑1 整数线性规划,论文直接用现成的 PuLP 求解器,一秒内就能出结果。
改变不同的 Δ τ \Delta \tau Δτ,就可以得到一族不同速度‑精度的代价滤波结构。比如想快一点,就设 Δ τ = − 0.06 s \Delta \tau = -0.06s Δτ=−0.06s(比教师快 60ms),求解器会自动挑出哪些块该牺牲精度、哪些块必须保留性能。
4.3.6 这个近似方法靠谱吗?
一个合理的质疑:每个块独立训练时用 MSE 模仿教师输出,但最后端到端的精度并不完全等于各块 MSE 之和,因为误差会累积。论文专门做了验证(图 8):
- 对于几个不同的 Δ τ \Delta \tau Δτ,用 ILP 搜出一个候选结构。
- 同时也随机采样 10 个结构(同样满足延迟约束),每个都端到端完整训练一次(很贵)。
- 对比发现:ILP 搜出来的结构在所有延迟预算下都明显好于随机结构的平均值。尤其当延迟预算很紧时(要求极快),随机结构经常会崩到误差 10% 以上,而搜出来的结构还能保持在 3% 左右。
这就证明了:用"局部 MSE 代理 + 独立评估 Δm/Δt"这种近似方法,虽然不完美,但已经足够找到非常好的架构。
4.4 细化模块加速:结构化剪枝(从"臃肿"到"精干")
4.4.1 细化模块长什么样?
初始视差 d 0 d_0 d0 出来后,还要经过一个 ConvGRU 反复迭代优化。图 5 画得很清楚:
- 每一轮 k k k,ConvGRU 会吃进当前视差 d k − 1 d_{k-1} dk−1、上一轮的隐藏状态 h k − 1 h_{k-1} hk−1、以及从图像特征中提取的运动信息。
- 输出新的隐藏状态 h k h_k hk 和新的视差 d k d_k dk。
- 默认迭代 K = 8 K=8 K=8 次。
这个模块虽然只占 40ms,但论文发现里面有很多通道是冗余的:删掉 60% 的参数,重训练一下精度几乎不降。
4.4.2 为什么要先建依赖图?
结构化剪枝不是随机删权重,而是成组地删掉整个输入/输出通道。比如一个卷积层原来有 128 个输出通道,我们想删到 64 个。但这一删,后面所有层对应的输入通道数也必须跟着变,不然维度就对不上了。
所以剪枝之前必须理清楚层与层之间的 通道依赖关系。论文除了用常规的自动 tracing(比如 Conv 的输出必须匹配下一层的输入)之外,还手动加了三条特殊规则,专门针对 ConvGRU 的循环结构:
- 最后输出层不能动:最后几层要输出视差图(单通道)和上采样掩码(固定通道数),这些通道数是硬件写死的,剪了会报错。
- 隐藏状态的输入和输出必须一起剪 :在 ConvGRU 内部,有一个层会消费上一轮的 h k − 1 h_{k-1} hk−1,另一个层会产出 h k h_k hk。这两个层的对应通道是绑定的------如果你删掉第 15 个通道的输出,那么输入的第 15 个通道也必须删。否则数据结构对不上。
- 运动编码器的输入不能剪:运动编码器吃的是从代价体积里索引出来的特征,那个特征的维度是固定的(因为代价体积的结构已经定死了),所以这一层的输入通道不能动。
把这套依赖图画出来(就是图 5),就明确了哪些层可以一起剪、哪些层必须保持原样。
4.4.3 哪些参数最不重要?用一阶泰勒展开打分
有了依赖图,就可以给每个参数(权重)的重要性打分。论文用的是 一阶泰勒展开 的方法,思想很直观:
如果一个参数被设成 0 之后,损失函数几乎不变,那它就不重要。
数学上,可以用梯度来近似:
Importance ( w ) ≈ ∣ w ⋅ ∂ L ∂ w ∣ \text{Importance}(w) \approx |w \cdot \frac{\partial \mathcal{L}}{\partial w}| Importance(w)≈∣w⋅∂w∂L∣
其中 ∂ L ∂ w \frac{\partial \mathcal{L}}{\partial w} ∂w∂L 是损失对权重的梯度。这个近似成立的前提是损失函数在 w=0 附近是线性的,虽然不完全精确,但在实践中非常好用。
具体做法:
- 把完整的教师模型跑几遍(用训练数据),记录前向和反向传播的梯度。
- 对细化模块里的每个通道(或者每个卷积核),累加它的重要性分数。
- 全局排序,把重要性最低的 α 比例的结构剪掉(比如 α=0.6 表示删掉 60% 的参数)。
4.4.4 剪完会崩,怎么办?重训练 + 特征蒸馏
直接剪完,精度惨不忍睹(图 9,α=0.8 时误差从 2.53% 飙到 7.88%)。但只要把剪枝后的细化模块单独拿出来重新训练一下,精度就能回来大半。
重训练用的损失函数长这样:
L = ∑ k = 1 K 0.9 K − k ∥ d k − d ˉ ∥ 1 ⏟ 视差监督 + 0.1 ∑ i = 1 L ∥ x i − x ˉ i ∥ 2 2 ⏟ 特征蒸馏 \mathcal{L} = \underbrace{\sum_{k=1}^{K} 0.9^{K-k} \|d_k - \bar{d}\|1}{\text{视差监督}} + \underbrace{0.1 \sum_{i=1}^{L} \|x_i - \bar{x}_i\|2^2}{\text{特征蒸馏}} L=视差监督 k=1∑K0.9K−k∥dk−dˉ∥1+特征蒸馏 0.1i=1∑L∥xi−xˉi∥22
- 第一项:视差监督 。让每次迭代的视差 d k d_k dk 都靠近真值 d ˉ \bar{d} dˉ。而且越靠后的迭代权重越大(因为 0.9 K − k 0.9^{K-k} 0.9K−k 在 k = K k=K k=K 时系数最大),这样模型会优先把最终输出做准。
- 第二项:特征蒸馏 。让剪枝后的每一层特征 x i x_i xi 去模仿剪枝前(教师)的对应层特征 x ˉ i \bar{x}_i xˉi。这个技巧可以让剪枝后的模型保留教师的一些"中间表示",避免过度偏离原来的良好行为。
λ=0.1 表示特征蒸馏只是辅助,主力还是视差监督。
经过这样重训练,α=0.6 时最终误差只从 2.53% 涨到 2.81%,几乎可以忽略,但速度从 13ms/迭代 降到了 7.8ms/迭代,几乎快了一倍。
4.4.5 迭代几次最合适?
附录图 12 做了系统的对比:固定剪枝率,改变迭代次数 K K K。
- 当剪枝率较小(α=0.6)时,K=8 之后精度基本饱和,再增加迭代收益很小。
- 当剪枝率很大(α=0.8)时,模型容量不足,即使迭代 16 次也追不上 α=0.6+K=8 的组合。
所以最终默认选 α=0.6(剪枝 60%)、K=8,这是一个很舒服的权衡点。
4.5 自动伪标签:从互联网扒数据,自己造真值
4.5.1 为什么需要真实数据?
现有的立体匹配训练很大程度依赖合成数据(SceneFlow 等)。合成数据干净整齐,但缺少现实世界里的复杂情况:透明玻璃、镜面反射、天空无限远、水渍、模糊等等。真实数据虽然有,但没有深度真值------用激光雷达打标太贵,手工标更不可能。
于是论文想了一个取巧的办法:用现成的强模型(FoundationStereo)给真实图像打伪标签,但是为了防止伪标签里的错误污染学生,再加一个单目深度模型做交叉验证,只有两者"看法一致"的地方才留用。
4.5.2 法线一致性:为什么比直接比深度好?
直接比较视差图 d stereo d_{\text{stereo}} dstereo 和单目深度转成的视差 d mono d_{\text{mono}} dmono 有个问题:视差值的范围变化很大(近处几十像素,远处接近 0),很难设一个统一的阈值。比如在近处差 2 个像素可能误差很小,但在远处差 2 个像素就是翻天覆地的变化。
论文改用 法线一致性 :把两组视差值分别重投影到 3D 点云,再用 Sobel 算子估算法线方向(每个像素的法线是一个 3D 向量)。然后计算两个法线之间的 余弦相似度:
cosine_sim = n stereo ⋅ n mono ∥ n stereo ∥ ∥ n mono ∥ \text{cosine\sim} = \frac{\mathbf{n}{\text{stereo}} \cdot \mathbf{n}{\text{mono}}}{\|\mathbf{n}{\text{stereo}}\| \|\mathbf{n}_{\text{mono}}\|} cosine_sim=∥nstereo∥∥nmono∥nstereo⋅nmono
这个值在 -1 到 1 之间,越接近 1 表示两个法线方向越一致。法线是角度量,对尺度不敏感,所以即使远处的物体视差值很小,只要几何形状算对了,法线也会一致。
4.5.3 具体流程(图 6 一看就懂)
- 取数据:从 Stereo4D 26(互联网立体视频集合)里每隔 10 帧抽一张,保证多样性。
- 教师打视差 :FoundationStereo 推理得到 d stereo d_{\text{stereo}} dstereo。
- 单目深度估计 :用 UniDepthV2 48 对同一张左图推理深度,再转成视差 d mono d_{\text{mono}} dmono。
- 分别算点云和法线:用同一个相机内参,把两套视差图都变成 3D 点云,再算每个点的法线。
- 计算一致性掩码:逐像素算余弦相似度,设一个阈值(论文没给具体数值,推测是 0.85 左右),超过阈值认为该像素可靠。
- 天空剔除 :用 SAM2 52 这类分割模型把天空像素找出来,不参与一致性计算。天空没有真实深度,强制让 d stereo d_{\text{stereo}} dstereo 的天空部分 = 0。
- 样本筛选:统计一致性掩码中"可靠像素"的比例(排除天空后)。如果比例 > 60%,就保留这个样本;否则丢弃。
- 最终伪标签 :保留样本的 d stereo d_{\text{stereo}} dstereo(天空已置零)作为训练用的视差真值。训练时可以可选地用一致性掩码做加权损失(可靠像素权重高,不可靠像素权重低或忽略)。
4.5.4 拿到了多少数据?效果怎样?
经过上面这套过滤,从 Stereo4D 里筛出了 140 万对 高质量立体图像+伪标签。把这些数据扔进训练集,效果立竿见影:
- 我们的模型在 Middlebury 上误差从 2.53% 降到 2.20%(相对降低 13%)。
- 对 RT‑IGEV 这种原本只在合成数据上训练的方法,加上伪标签后误差从 11.52% 直接降到 8.69%,降幅非常夸张,说明这批数据确实补充了合成数据里缺少的真实分布。
论文还在附录图 15 里展示了一些被过滤掉的坏样本:比如画面里有字幕、马赛克、或者过于模糊/反光的场景。这些样本的法线一致性一般很低,会被自动丢弃,避免污染训练。
4.6 训练流程汇总(一张表看懂)
| 阶段 | 做什么 | 输入数据 | 输出 | 耗时/资源 |
|---|---|---|---|---|
| 0 | 准备教师 | FoundationStereo 权重 | 教师本身 | 已有 |
| 1 | 蒸馏特征提取 | SceneFlow + 伪标签 | 轻量学生 backbone | ~几天 (单卡) |
| 2 | 块级 NAS 搜索 | SceneFlow | 候选块 + 评测 Δm, Δt | 128×A100 × 14天 |
| 3 | ILP 组合 | Δm, Δt 表 | 不同 Δτ 的最优组合 | <1秒 |
| 4 | 剪枝细化 | SceneFlow | 剪枝后 ConvGRU | 几小时 |
| 5 | 伪标签生成 | Stereo4D 视频 | 140万对伪标签 | 离线批处理 |
| 6 | 端到端微调 | 混合数据 (合成+伪标签) | 最终模型 | ~几天 |
最终产出不是一个模型,而是一个 速度‑精度 Pareto 前沿(图 2)。你可以根据应用需求(比如机器人要求 50ms 以内)直接挑一个合适的点部署。
最后一句总结 :这篇论文的聪明之处不在于用了多 fancy 的技术,而在于对三个模块分别设计了"量体裁衣"式的加速方案,并且用块级蒸馏把 NAS 从不可能变成可能。如果你以后要压缩一个大模型,不妨也想想:能不能拆成几块,每块用最适合它的压缩方法?