****论文题目:****Attention-based map encoding for learning generalized legged locomotion(基于注意的映射编码学习广义腿部运动)
****期刊:****Science Robotics
****摘要:****腿式机器人的动态运动是扩展移动机器人操作范围的一个关键而又具有挑战性的课题。当可能的立足点稀疏时,它需要精确的规划,对不确定性和干扰的鲁棒性,以及跨越不同地形的通用性。尽管传统的基于模型的控制器擅长在复杂地形上进行规划,但它们难以应对现实世界的不确定性。基于学习的控制器对这种不确定性具有鲁棒性,但在具有稀疏可步进区域的地形上往往缺乏精度。混合方法通过结合两种方法来增强稀疏地形上的鲁棒性,但计算量大,并且受到基于模型的规划器固有局限性的约束。为了在保持基于学习的控制器的鲁棒性的同时实现在不同地形上的广义腿部运动,本文提出了一种基于机器人本体感觉的基于注意力的地图编码,并使用强化学习将其作为控制器的一部分进行训练。我们表明,当机器人动态导航各种具有挑战性的地形时,网络学会关注可行走的区域,为未来的立足点做好准备。我们合成了对不确定性表现出鲁棒性的行为,同时实现了对稀疏地形的精确和敏捷穿越。此外,我们的方法提供了一种解释神经网络的地形感知的方法。我们已经为一个12自由度的四足机器人和一个23自由度的人形机器人训练了两个控制器,并在现实世界中测试了各种具有挑战性的室内和室外场景,包括训练中看不到的场景。
让机器人像人一样走路:注意力机制如何让腿足机器人征服复杂地形
引言:腿足机器人的终极挑战
人类和动物几乎能穿越地球上任何地形------从山地碎石到独木桥,从建筑废墟到狭窄台阶。让腿足机器人拥有同样的能力,是机器人学领域几十年来的核心追求。然而,要做到这一点,控制器必须同时满足三个苛刻的要求:
- 精确性:当可落脚区域稀疏时(如踏脚石、横梁),必须精准规划每一步的落脚点;
- 鲁棒性:面对传感器噪声、执行器误差、地形变形等现实不确定性,依然能稳定运动;
- 泛化性:能够应对训练阶段从未见过的地形。
这三者,现有方法几乎从未同时做到。来自 ETH Zurich 机器人系统实验室与 Disney Research Zurich 的研究团队,在 Science Robotics 上发表了这项工作,提出了一种基于注意力机制的地图编码方法,首次以纯学习框架在四足和人形机器人上同时实现了上述三个目标。
一、现有方法的困境
1.1 三类方法,各有软肋
在腿足机器人运动控制领域,研究者们长期探索三条路线:
深度强化学习(DRL) 方法通过大量仿真训练,让机器人在不确定性面前表现出色------它能从跌倒中恢复、应对地面突变。但当地形变得稀疏(如随机摆放的踏脚石)时,DRL 算法很难在训练中找到有效的落脚点并从中学习。即使采用课程学习(curriculum learning)来引入人类直觉引导训练(如 baseline-rl 文献14),也往往只能过拟合少数几种地形,换一种布局就失败,泛化能力严重不足。
模型预测控制(MPC) 方法擅长在已知动力学模型下做精确规划,能在楼梯、台阶、斜坡等地形上稳定行走,并预测精确的落脚点。但它本质上是在求解确定性最优控制问题,一旦遇到感知噪声、执行器误差或模型失配,性能就会显著下降。
混合方法(Hybrid) 试图结合两者优势。其中最具代表性的是 Deep Tracking Control(DTC)文献1:训练一个 DRL 控制器来跟踪模型优化器(TAMOLS)给出的参考轨迹,有效克服了模型失配问题。然而,混合方法代价高昂------DTC 训练时需要同时在 CPU 上运行模型规划器、在 GPU 上运行训练流水线,总训练时间长达14天。更关键的是,部署时仍需实时运行 MPC,若感知退化,规划器可能产生不可行的落脚点引导,导致整个系统失效。
1.2 核心空白
目前尚不存在一个整体式(holistic)学习方法,能在稀疏地形上同时实现精确、鲁棒、泛化的腿足运动。此外,还没有任何方法成功将感知控制器 sim-to-real 迁移到四足和双足机器人上,用于稀疏地形的动态运动。
这正是本文要填补的空白。
二、核心创新:注意力机制学会"看哪里落脚"
2.1 整体控制框架
论文提出的框架可以用一句话概括:将机器人本体感知(proprioception)作为查询(Query),让神经网络学会从地形高度图中"注意"未来的落脚点,并将这一表征直接映射到关节动作。
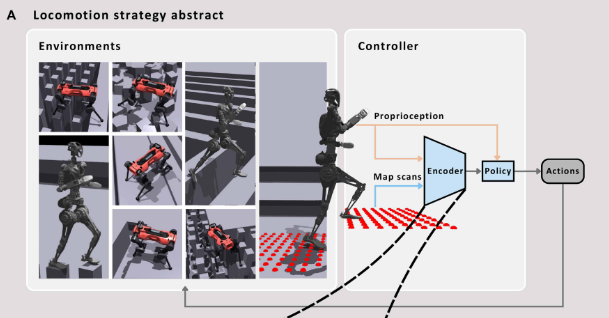
📌 配图:Fig. 8(A) --- 运动策略抽象示意图 展示环境、编码器、策略、动作的整体流程,以及与模型方法、学习方法、混合方法的类比关系。
整个编码器由两个层级构成:
第一层:CNN 局部特征提取
输入是以机器人为中心的高度图,尺寸为 L×W×3(L行、W列,每个点有三维坐标)。z 值(高度信息)首先送入一个两层卷积神经网络(CNN):
- 使用 zero padding 保持原始空间维度不变;
- 卷积核大小为 5,用于提取每个点周围的局部地形特征;
- 第一层 16 个隐藏单元,第二层 d-3 个隐藏单元(d=64);
- 输出与三维坐标拼接,得到形状为 LW×d 的点级局部特征。
第二层:多头注意力(MHA)地图编码
与此同时,机器人本体感知信息(关节位置、速度、角速度、重力向量等)通过一个线性层映射为维度为 d 的本体感知嵌入,作为注意力机制的 Query(Q)。
CNN 输出的点级特征同时作为 Key(K)和 Value(V)。MHA 模块(d=64,h=16个头,n=1)计算每个地图点对当前机器人状态的相关程度,输出加权融合后的地图编码。
最终,地图编码与本体感知拼接,送入后续 MLP 策略网络,输出目标关节位置(由低级 PD 控制器跟踪)。
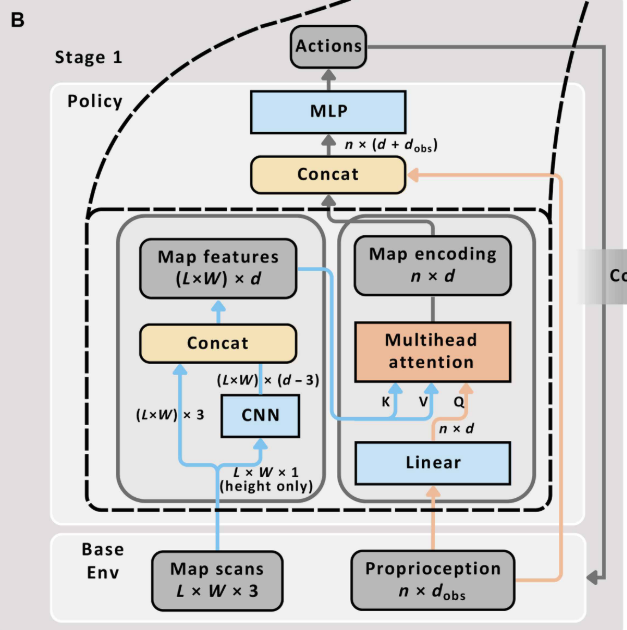
📌 配图:Fig. 8(B) --- Stage 1 网络结构图 展示 CNN → 点级特征 → MHA(Q来自本体感知)→ 地图编码 → Concat → MLP → 动作的完整架构。
2.2 为什么 MHA 比 MLP 更合适?
注意力权重对地图点的关注程度依赖于机器人当前状态(即权重是 state-dependent 的),这使得编码器能够根据机器人的位置、速度、姿态动态调整对地形的"关注焦点"。相比之下,MLP 对所有地图点的处理方式相对固定,难以建模这种复杂的动态关系。
更令人惊喜的是:在没有任何显式落脚点监督信号的情况下,MHA 模块自发学会将注意力集中在未来的落脚区域------这是一种涌现行为(emergent behavior),而非人为设计的结果。

📌 配图:Fig. 7 --- 注意力权重可视化 展示在 mixed terrain(A)、基础地形不同方向命令(B)、未见细调地形(C)上,红色热力图标记注意力高权重区域(即预测落脚点)的直观效果。
三、两阶段训练流程
为了让地图编码在复杂真实环境中也能正常工作,论文设计了两阶段渐进式训练流程:
Stage 1:基础技能习得
在基础地形(grid stones、pallets、beams、gaps 等)上,使用完美感知(无噪声、无漂移,仅在仿真中可得)进行训练。这一阶段的目的是:
- 初始化地图编码学习,让网络"看懂"地形;
- 建立基本的运动技能,如稳定步态、避障等。
对于 ANYmal-D:18,000 epochs;对于 GR-1:15,000 epochs。
Stage 2:鲁棒性强化与泛化提升
在 Stage 1 的基础上,引入:
- 更多更难的地形(pentagon stones、single-column stones、narrow pallets、consecutive gaps、rough hills 等);
- 感知噪声和漂移(模拟真实传感器误差);
- 外部扰动(随机推力);
- Domain randomization(质量、摩擦系数随机化)。
Stage 2 微调后的控制器在真实世界中表现出色,完成 zero-shot sim-to-real 迁移。
对于 ANYmal-D:3,600 epochs,Stage 2 每 epoch 24 秒,加上 Stage 1 总计约6天 (Nvidia Tesla A100-40GB GPU)。对于 GR-1:Stage 2 共 3,200 epochs,每 epoch 14 秒,总计约3.5天 (Nvidia RTX 4090 GPU)。这比 DTC 的14天训练时间减少约60%。
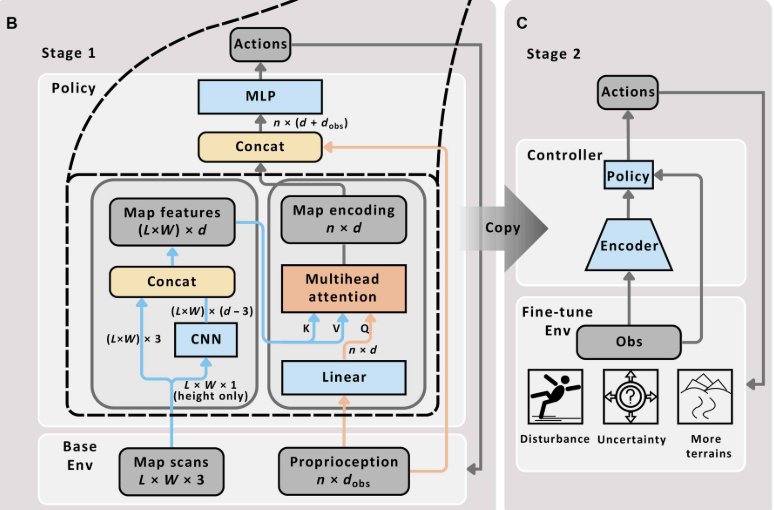
📌 配图建议:Fig. 8(B)(C) --- 两阶段训练流程对比图 展示 Stage 1(完美感知 + 基础地形)和 Stage 2(引入噪声/扰动/更难地形)的训练配置差异。
四、实验结果
4.1 仿真对比:大幅超越现有方法
论文在仿真环境中(Isaac Gym,4096个并行机器人)与两个基线方法进行了系统比较。
速度跟踪误差(vs. DTC)
在多种稀疏地形上,以不同前向速度命令(0.4~1.0 m/s)部署机器人,记录存活机器人的平均跟踪误差:
- 本方法在几乎所有速度和地形组合下跟踪误差均更低;
- DTC 在高速命令(~1.0 m/s)时误差尤其大,原因是其固定步态频率导致落脚点规划更难;
- 本方法可以自适应调整步态频率,在不同速度命令下保持精准跟踪。
整体成功率
在所有训练地形的组合上,对三个控制器进行部署测试(成功 = 在一个 episode 内走出地形边界;失败 = 非预期接触;卡住 = 其余情况):
| 方法 | 整体成功率提升(相对) |
|---|---|
| 本方法 vs. DTC | +26.5% |
| 本方法 vs. baseline-rl | +77.3% |
单地形成功率
DTC 在 grid stones(20cm×20cm 随机方石)、small grid stones(12cm×12cm)、narrow beams(15cm宽)上的成功率低于20%,原因是其模型规划器无法接受小于阈值的支撑面,产生不可行引导。baseline-rl 过拟合于训练地形,在轻微变化的未见布局(如随机横梁穿插的grid stones、pentagon stones)上即告失败。
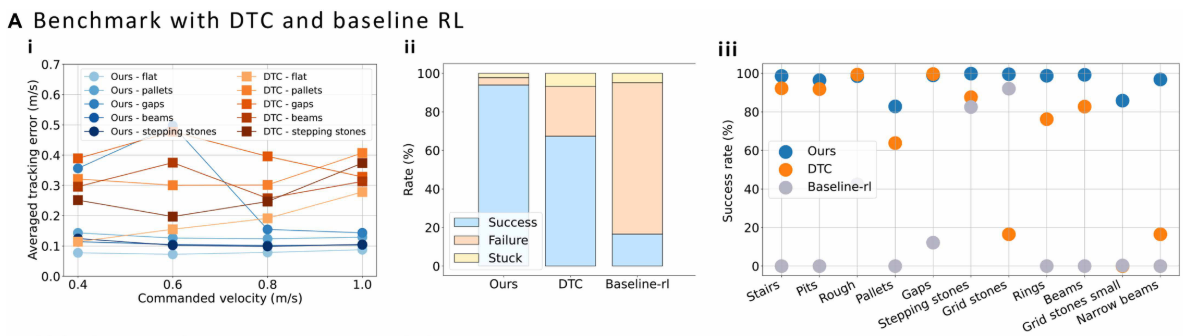
📌 配图:Fig. 6(A) --- 与 DTC 和 baseline-rl 的三维对比图 包含(i)速度跟踪误差曲线、(ii)整体成功/失败/卡住率柱状图、(iii)各地形单独成功率散点图。
4.2 消融研究一:两阶段训练的必要性
论文对比了三种训练策略(以 ANYmal-D 为例):
- Ours:Stage 1 基础地形+完美感知 → Stage 2 全部地形+噪声;
- C2:从头开始,全部地形+完美感知;
- C3:从头开始,基础地形+噪声。
训练过程中的地形难度等级(0-9分)曲线显示:
- Ours 收敛至最高难度,曲线先超过6再稳定收敛,表明大多数机器人能解决最难地形;
- C2 无法达到相同等级,说明直接在所有地形上训练反而导致学习失败;
- C3 无法稳定收敛回6,说明从一开始引入噪声会干扰基础技能的建立。
部署成功率同样显示 Ours 在几乎所有地形上均优于 C2 和 C3,尤其在稀疏地形(grid stones、beams等)上差距最大。
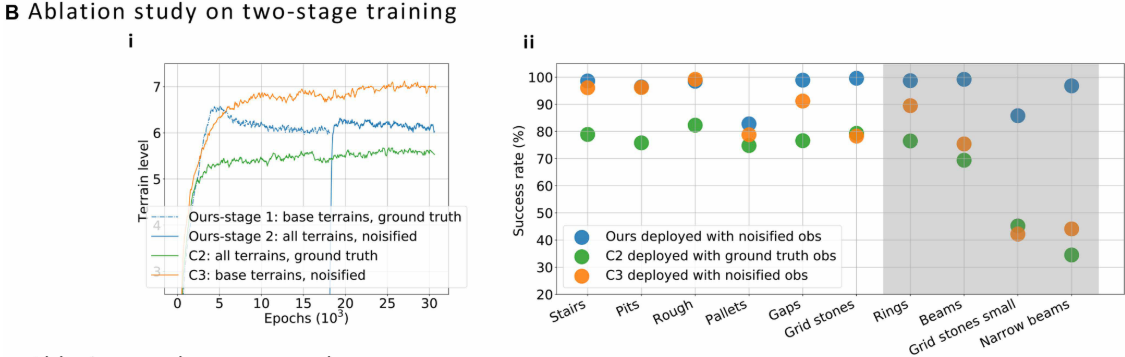
📌 配图:Fig. 6(B) --- 两阶段训练消融结果 (i) 三种训练策略的地形难度等级训练曲线;(ii) 各地形部署成功率对比散点图(白底=基础地形,灰底=细调地形)。
4.3 消融研究二:网络结构的优越性
论文将提出的网络结构与以下三种替代方案对比:
- Transformer encoder(类似文献36的完整 Transformer);
- CNN down-sampling(用另一个 CNN 代替 MHA,对地图进行下采样而非点级关注);
- Vision Transformer(ViT)(文献42,将地图图块化后用 Transformer 处理)。
结果表明:
- 本方法的训练收敛地形难度等级最高,且部署成功率在所有单地形上均最优;
- 在未见地形上,本方法的泛化能力尤为突出,说明点级注意力机制对于处理未知地形组合具有结构性优势。
此外,论文还发现:本方法的网络结构能够自主促进强化学习探索,在与 MLP 策略相同奖励函数下,本方法策略能有效学习可行步态,而 MLP 策略在稀疏地形上的训练极为困难。
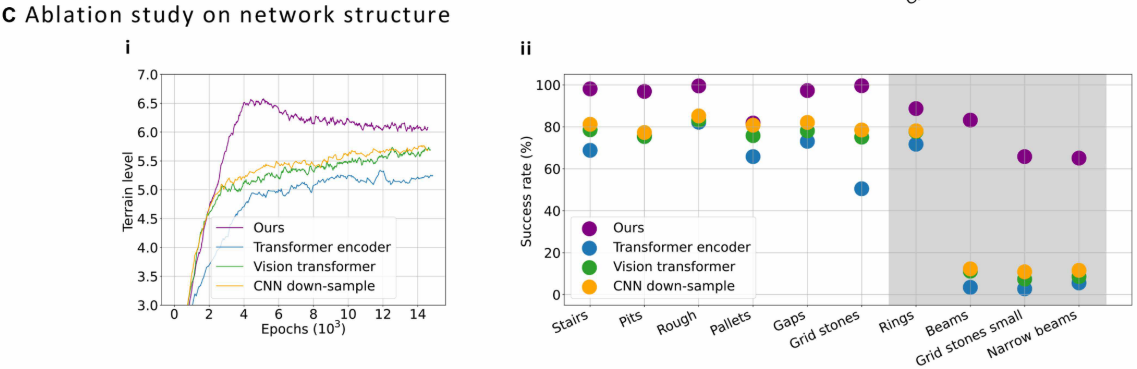
📌 配图:Fig. 6(C) --- 网络结构消融结果 (i) 四种网络结构的地形难度等级训练曲线;(ii) 各地形成功率对比散点图。
4.4 真实机器人实验:zero-shot 部署
论文在两台真实机器人上以 50 Hz 控制频率进行 zero-shot(仿真到真实无微调)部署:
ANYmal-D(12自由度四足机器人,ETH Zurich):
- 感知方案:机载 Nvidia Jetson 运行 elevation mapping,Intel Core i7 8850H CPU 进行策略推理;
- 成功穿越:踏脚石、有高度差踏脚石、随机布置踏脚石(前向/侧向)、箱子和间隙、19cm宽横梁等。
Fourier GR-1(23自由度人形机器人,Fourier Intelligence):
- 感知方案:Qualysis 动作捕捉系统获取位姿,基于预设地形网格进行光线投射采样地图,Intel Core i7 13700H CPU 进行策略推理;
- 成功穿越:横梁+间隙混合地形、有高度差的单列石块等。
两台机器人在 Grandia et al. 文献24 设计的 obstacle parkour 测试集上(训练中从未见过)均达到 100% 成功率(测试包含干扰和不确定性)。


📌 配图:Fig. 1 --- 真实硬件实验全景图 展示 ANYmal-D(A-I)和 GR-1(J-O)在各种室内外挑战地形上的照片,以及 K、M、O 中叠加的注意力权重可视化(红色高注意力点=下一落脚区域)。

📌 配图 :Fig. 3 --- 真实机器人稀疏地形详细展示 GR-1(A)和 ANYmal-D(B)在各种稀疏地形上的动作序列照片。
4.5 涌现的敏捷行为与恢复反射
一个令人印象深刻的结果是,控制器在没有被显式训练的情况下,涌现出多种精妙的运动行为:
- ANYmal-D 在攀爬大石块时主动用膝盖协助发力,同时旋转躯干;在碎石地面发生脚部陷入时,通过膝盖支撑自救;
- GR-1 在不平踏脚石上行走时,臂部摆动频率和幅度随地形和步态动态变化;在摇晃横梁上自主维持平衡;在滑倒时快速迈步恢复;甚至在当前落脚点不合适时,在空中完成单腿换脚跳跃,成功踏上下一块石头;
这些行为来自整体学习,而非人工设计------模型方法通常依赖接触状态机和手工启发式规则,很难产生此类行为。

📌 配图:Fig. 4 --- 敏捷行为与恢复反射序列图 展示 ANYmal-D 膝盖攀岩(A)、滑动恢复(B)、GR-1 臂部摆动(C)、摇晃平衡(D)、滑倒恢复(E)、单腿换脚跳(F)等六组动作序列。
4.6 全向速度跟踪与多样步态
论文还展示了控制器的速度跟踪多功能性:
- ANYmal-D 在碎石堆(带可移动支撑物)上完成全向运动(前进、侧移、转向);
- GR-1 在摇晃横梁上,当速度命令从 0.7 m/s 提升至 1.5 m/s 时,步幅自动加大;
- GR-1 在单列踏脚石上:1.5 m/s 时每石一步,0.7 m/s 时每石两步------步态模式随速度自适应变化。

📌 配图:Fig. 5 --- 速度跟踪多样性展示 展示 ANYmal-D 全向机动(A)、GR-1 加速(B)、GR-1 高速单步(C)、GR-1 低速双步(D)的照片序列。
五、可解释性:神经网络的"视角"
这项工作另一个重要贡献是让神经网络的决策过程变得可解释。
通过可视化 MHA 模块对各地图点分配的注意力权重(颜色深浅,红色越深代表权重越高),可以清晰看到:
- 混合地形(Stage 2 控制器):注意力集中于下一个可踏区域;
- 不同方向命令(Stage 1 控制器):前向行走时注意力在正前方,侧移时注意力偏向侧方;
- 不可行命令 :当机器人在横梁上被命令转向,但转向会导致踩空时,注意力拒绝跟随命令,仍然集中在横梁上;
- 未见地形:即使是 pentagon stones、single-column stones 等训练中从未出现的地形,注意力仍能正确定位到可踏区域。
这种可解释性不仅有助于调试和分析,也为未来研究提供了理解神经网络地形感知的新视角。

📌 配图:Fig. 7 --- 注意力权重完整可视化(A/B/C三组)
六、局限性与未来方向
作者坦诚地指出了当前方法的三个局限:
- 训练耗时仍较长:即使比 DTC 快60%,6天的训练周期仍使超参数调优代价高昂;
- 使用 2.5D 高度图表示:对于狭小空间等场景不适用,需要 3D 表示;
- 未涉及手臂操作:GR-1 的手臂主要用于辅助运动平衡,如何兼顾运动和操作(locomanipulation)尚未研究。
未来工作将探索:提高训练效率、开发适用于更广泛场景的 3D 地形表示,以及将注意力机制扩展到开门、移动障碍物、手脚并用攀爬等全身操作任务。
结语
这项工作代表了腿足机器人运动控制的一次重要突破:无需模型规划器、无需特权信息、无需人工设计落脚点监督,仅凭注意力机制和强化学习,就让机器人学会了"看哪里落脚"。
它不仅在数值指标上大幅超越此前最优方法(整体成功率比 DTC 高26.5%、比 baseline-rl 高77.3%,训练时间减少约60%),更在真实世界的四足和人形机器人上成功验证------包括大量训练中从未见过的地形场景。
注意力机制赋予了控制器可解释性,而整体学习框架赋予了它真正的涌现能力。这或许正在预示着:未来通用腿足机器人的控制,将不再依赖手工设计的规则,而是从数据中自主涌现出来。