这是博主自己项目中实现的一个关于RAG检索后过滤的策略执行链的实现方式,这个思路博主一开始也没想到,是与AI交互过程中他偶然间提到的,博主觉的很有意思,于是在博主不断调试,与AI交互的过程下,该方法终于实现,不过当前还是只适用于想博主这种的小项目中。主要还是博主梳理自己的整个RAG检索后过滤的这个过程,以及分享策略执行链这个具体的思路,还是挺有意义的(▰˘◡˘▰)
一.前提讲解
因为我们一整个RAG检索后过滤流程,我们设置了多个策略,策略与策略之间构建成链条,实现是一个策略的过滤结果作为下一个策略输入参数,层层过滤,最终将合格与达标的文档交给LLM,所以这个过程就涉及到每个策略的过滤参数,过滤指标,参数设计,是否启用等等功能,比如策略1和策略2之间,我想临时关闭策略2,直接让策略1的结果送到策略3,再比如我们设置了多个知识库,如果我们想为每个知识库设计不同的过滤参数,而不是全部知识库复用同一套过滤逻辑等等。目前考虑到这个问题,博主的通用思路就是将不同参数抽取到一个配置类,然后配置全部抽取到配置文件中,这就引入了我们的RagFilterConfig过滤配置类
java
/**
* RAG 检索后过滤配置类
*
* 配置前缀: rag.filter
* 支持全局默认配置和知识库级策略覆盖
*
* @author xiaofuge bugstack.cn @小傅哥
* @since 2026/03/23
*/
@Data
@Component
@ConfigurationProperties(prefix = "rag.filter")
public class RagFilterConfig {
// ==================== 基础过滤参数 ====================
/**
* 相似度阈值,范围 0.0 ~ 1.0,默认 0.7
*/
private double similarityThreshold = 0.7;
/**
* 最小置信度阈值,默认 0.5
*/
private double minConfidenceThreshold = 0.5;
/**
* 最小文档长度(字符数),默认 50
*/
private int minDocumentLength = 50;
/**
* 最小信息密度,默认 0.3
*/
private double minInformationDensity = 0.3;
/**
* 最大返回文档数量,默认 5
*/
private int maxRetrievalResults = 5;
/**
* 最大总字符数,默认 4000
*/
private int maxTotalChars = 4000;
// ==================== 功能开关 ====================
/**
* 过滤功能全局开关,默认 true
*/
private boolean enabled = true;
/**
* 统计功能开关,默认 true
*/
private boolean statisticsEnabled = true;
// ==================== 重排配置 ====================
/**
* 重排功能开关,默认 false
*/
private boolean rerankEnabled = false;
/**
* 重排候选数量限制,默认 10
*/
private int rerankCandidateLimit = 10;
// ==================== 多样性配置 ====================
/**
* 多样性功能开关,默认 true
*/
private boolean diversityEnabled = true;
/**
* 每来源最大文档数,默认 2
*/
private int maxPerSource = 2;
// ==================== 回退配置 ====================
/**
* 回退功能开关,默认 true
*/
private boolean fallbackEnabled = true;
/**
* 回退时返回的文档数量,默认 2
*/
private int fallbackTopK = 2;
// ==================== 知识库级覆盖配置 ====================
/**
* 知识库级策略覆盖配置,Key: 知识库标签,Value: 专属配置
*/
private Map<String, RetrievalProfile> knowledgeProfiles = new HashMap<>();
/**
* 文档类型级规则,Key: 文档类型,Value: 处理规则
*/
private Map<String, TypeSpecificRules> typeSpecificRules = new HashMap<>();
/**
* 根据知识库标签解析对应的检索策略。
* <p>
* 【解析逻辑】
* 1. 创建默认策略(使用全局配置)
* 2. 如提供了知识库标签,查找对应的覆盖配置
* 3. 如找到覆盖配置,合并到默认策略中
* <p>
* 【合并规则】
* 知识库配置优先于全局配置,未配置的属性保持默认值。
* <p>
* 【示例】
* <pre>
* // 获取 grafana-guide 知识库的策略
* RetrievalPolicy policy = config.resolvePolicy("grafana-guide");
* // 如 knowledgeProfiles 中有 grafana-guide 的配置,将覆盖对应属性
* </pre>
*
* @param knowledgeTag 知识库标签,可为 null
* @return 解析后的检索策略,包含全局默认值和知识库覆盖值
*/
public RetrievalPolicy resolvePolicy(String knowledgeTag) {
// 从默认策略开始
RetrievalPolicy policy = createDefaultPolicy();
// 如提供了知识库标签,尝试应用覆盖配置
if (StringUtils.hasText(knowledgeTag)) {
RetrievalProfile profile = knowledgeProfiles.get(knowledgeTag.toLowerCase());
if (profile != null) {
// 合并知识库专属配置
mergeProfile(policy, profile);
}
}
return policy;
}
/**
* 创建默认检索策略。
* <p>
* 【使用全局配置】
* 使用当前配置对象的属性值创建策略对象,
* 作为所有策略的基础模板。
* <p>
* 【使用场景】
* - resolvePolicy 方法的基础策略
* - 临时覆盖参数时的起点(如 API 调用时临时修改阈值)
*
* @return 包含全局默认值的检索策略对象
*/
public RetrievalPolicy createDefaultPolicy() {
RetrievalPolicy policy = new RetrievalPolicy();
policy.setEnabled(enabled);
policy.setSimilarityThreshold(similarityThreshold);
policy.setMinDocumentLength(minDocumentLength);
policy.setMinInformationDensity(minInformationDensity);
policy.setMaxRetrievalResults(maxRetrievalResults);
policy.setMaxTotalChars(maxTotalChars);
policy.setRerankEnabled(rerankEnabled);
policy.setRerankCandidateLimit(rerankCandidateLimit);
policy.setDiversityEnabled(diversityEnabled);
policy.setMaxPerSource(maxPerSource);
policy.setFallbackEnabled(fallbackEnabled);
policy.setFallbackTopK(fallbackTopK);
return policy;
}这里直接展示了我们的部分源码,他的核心作用是将我们整个策略执行链的的参数统一配置在一起,便于统筹管理与配置修改
java
rag:
filter:
similarity-threshold: 0.75 # 最小相似度
max-retrieval-results: 6 # 最大返回文档数
max-total-chars: 5000 # 上下文总字符限制
rerank-enabled: true # 是否启用重排序
diversity-enabled: true # 是否启用多样性控制
max-per-source: 2 # 每来源最大文档数就拿我们项目来说,如果我们想提高向量检索的阈值,只需要调整
similarity-threshold参数,想控制向量检索返回的文档数目,只需要控制max-retrieval-result参数,想启用重排序策略,只需要设置rerank-enabled;true即可,通过配置文件配置,可以统筹管理整个策略执行链
java
全局默认配置
│
├──→ 知识库A:低相似度阈值(0.6)+ 大上下文(8000字符)
│
├──→ 知识库B:高相似度阈值(0.8)+ 小上下文(3000字符)
│
└──→ 知识库C:禁用重排序 + 启用多样性
java
// 知识库级策略覆盖配置
private Map<String, RetrievalProfile> knowledgeProfiles = new HashMap<>();
// 示例配置(application-rag-filter.yml):
knowledgeProfiles:
grafana-guide: # 知识库标签
similarityThreshold: 0.6
maxRetrievalResults: 10
maxTotalChars: 8000
product-manual:
similarityThreshold: 0.8
maxTotalChars: 3000
rerankEnabled: false对于不同的RAG知识库,我们可以采取不同知识库不同配置策略,如果没有明确指定知识库,我们的knowledgeProfiles为空,那么就走
默认策略,如果RAG知识库设置配置参数了,那么采取覆盖配置,采用我们配置的RAG这个参数,后续检索到该RAG知识库时会采取该配置参数.好处是极大提升了灵活性,不同知识库的检索可以有不同的配置参数
java
// 在 RetrievalQualityFilter 中
public List<Document> filter(String knowledgeTag, List<Document> docs) {
// 根据知识库获取对应的策略
RetrievalPolicy policy = ragFilterConfig.resolvePolicy(knowledgeTag);
// 应用策略
if (policy.getSimilarityThreshold() > 0) {
docs = filterBySimilarity(docs, policy.getSimilarityThreshold());
}
if (policy.getRerankEnabled()) {
docs = rerank(docs, policy.getRerankCandidateLimit());
}
// ...
return docs;
}
这里提一嘴,我们项目是通过knowledge参数来标注知识库来源,我们一个client配备多个知识库,他就获取这些知识库的knowledge属性,我们向量数据库检索时,如果client传递的时"产品手册",他就会读取如下过滤策略
java
knowledgeProfiles:
产品手册: # 知识库标签
similarityThreshold: 0.6
maxRetrievalResults: 10
maxTotalChars: 8000将knowledge传递给策略执行链,他就会自动根据knowledge属性,去knowledgeProfile中加载该知识库的配置属性
二:策略链的构成
现在来讲解一下我们是怎么将多个策略构成链条的,并且控制策略先后顺序
1. 策略接口定义RetrievalStrategy
java
// RetrievalStrategy.java
public interface RetrievalStrategy {
// 策略名称(用于日志)
String getName();
// 执行策略
List<Document> apply(List<Document> documents, RetrievalFilterContext context);
//获取策略所属阶段。
RetrievalStage getStage();
//读取我们RagFilterConfig文件,判断当前策略是否可以执行
boolean supports(RetrievalFilterContext context);
// 执行过滤逻辑。
List<Document> apply(RetrievalFilterContext context, List<Document> documents);
这里面提供了一系列的公共方法,所有策略都要实现,包括执行策略
apply,判断策略是否需要执行supports,读取策略的执行顺序getStage(去常量类中获取到对应的执行顺序)等等,设置策略
2.策略顺序枚举类
我们设计了一个
枚举类RetrievalStage,在这里统一配置我们项目各个策略的执行顺序(数字越小越先执行)
java
public enum RetrievalStage {
/**
* 硬过滤阶段。
* 【典型策略】
* - CandidateHardFilterStrategy
*/
HARD_FILTER(10),
/**
* 相似度过滤阶段。
* 【典型策略】
* - SimilarityCutoffStrategy
*/
SIMILARITY_FILTER(20),
/**
* 多样性控制阶段。
* 【典型策略】
* - DiversityStrategy
*/
DIVERSITY(30),
/**
* 上下文装箱阶段。
* 【典型策略】
* - ContextPackingStrategy
*/
CONTEXT_PACKING(40);
/**
* 阶段执行顺序值。
* <p>
* 值越小,执行优先级越高。
* 用于 RetrievalStrategyChain 对策略进行排序。
*/
private final int order;
/**
* 构造方法。
*
* @param order 阶段执行顺序值
*/
RetrievalStage(int order) {
this.order = order;
}
/**
* 获取阶段执行顺序值。
*
* @return 顺序值,越小优先级越高
*/
public int getOrder() {
return order;
}
}3.具体策略的实现

我们所有的策略继承关系是:具体策略->AbstractRetrievalStrategy(抽象策略接口,提供更多公用策略的方法)->RetrievalStrategy
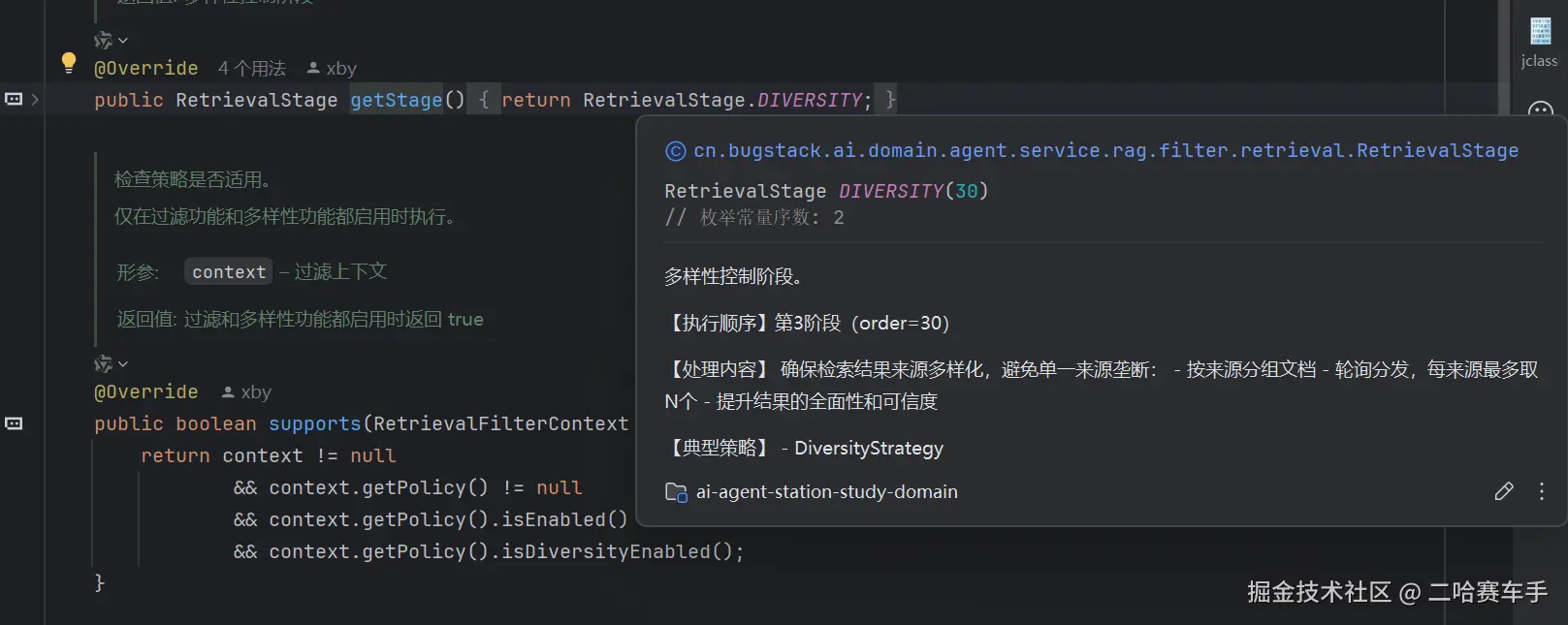
先是重写
getStage,获取到要执行的策略的顺序
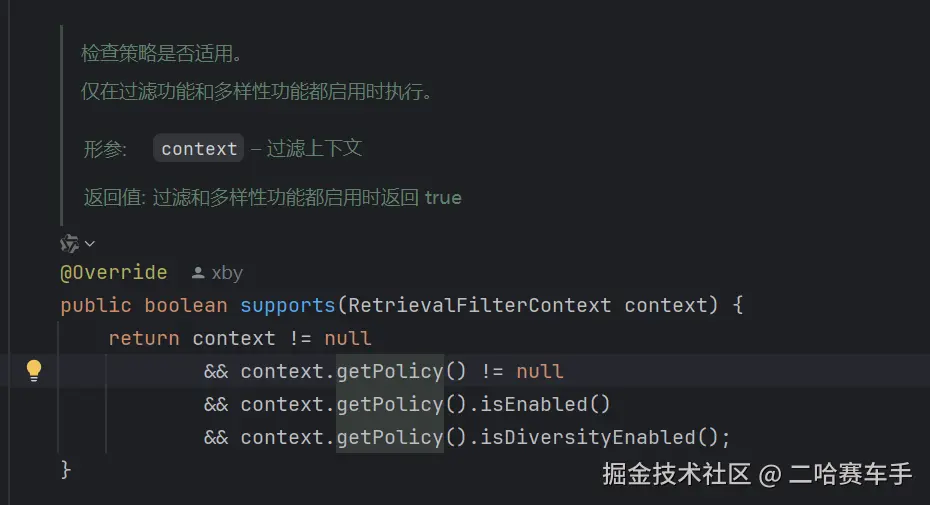
再重写
supports方法,去判断我们策略是否可以执行,这里的isEnabled和iaDiversityEnabled参数就是我们的RagFilterConfig中的参数,本质还是去读取我们配置文件中关于当前配置文件的isEnabled,iaDiversityEnabled`配置参数
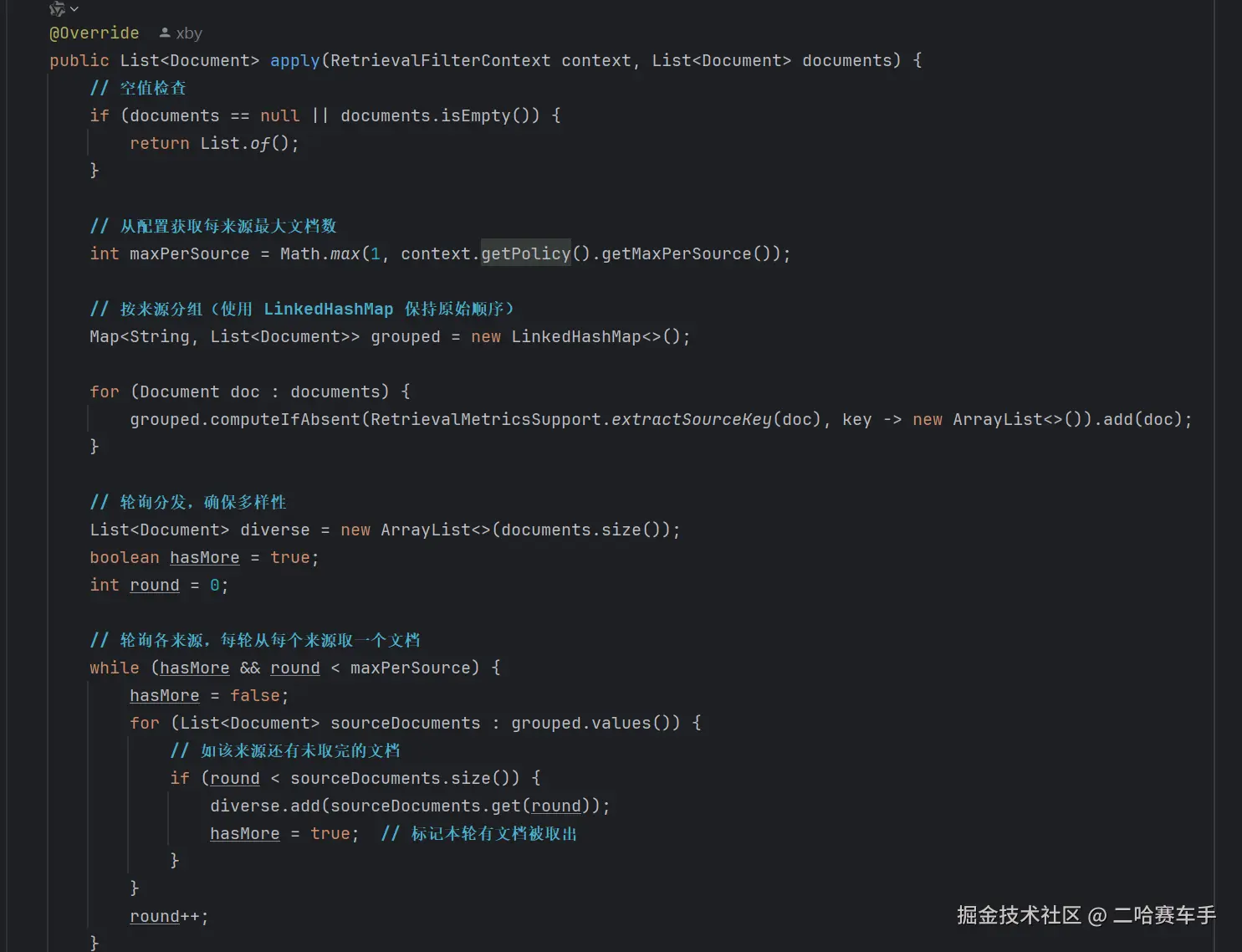
重写
apply方法,定义我们当前策略的执行逻辑,这里需要说明一下我们的我们是先调用support方法判断当前策略是否可以执行,返回true才可以正常执行apply中的逻辑
4.策略链RetrievalStrategyChain 的实现
(1)变量设置
java
/**
* pre-rerank 阶段策略列表。
* <p>
* 在重排之前执行,包括硬过滤、相似度截断等粗粒度过滤策略。
*/
private final List<RetrievalStrategy> preRerankStrategies;
/**
* post-rerank 阶段策略列表。
* <p>
* 在重排之后执行,包括多样性控制、上下文装箱等后处理策略。
*/
private final List<RetrievalStrategy> postRerankStrategies;
/**
* 重排策略提供者。
* <p>
* 使用 ObjectProvider 实现延迟获取,支持可选依赖。
* 如未配置重排策略,则跳过重排阶段。
*/
private final ObjectProvider<RerankStrategy> rerankStrategyProvider;我们将策略按照不同阶段存放,分为
pre-rerank,rerank,post-rerank三个阶段,放在不同的集合中
java
原始文档列表
│
▼
┌─────────────────────────────────────────┐
│ pre-rerank 阶段(粗过滤) │
│ │
│ 1. CandidateHardFilterStrategy │
│ - 向量相似度阈值过滤 │
│ - 长度范围过滤 │
│ - 信息密度检查 │
│ │
│ 2. Bm25ScoringService │
│ - 计算 BM25 分数 │
│ - 回填 metadata │
│ │
│ 【目标:减少候选集,准备评分数据】 │
└─────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────┐
│ rerank 阶段(核心重排序) │
│ │
│ HeuristicRerankStrategy │
│ - 向量相似度 40% │
│ - BM25 分数 20% │
│ - 长度适宜度 10% │
│ - 信息密度 15% │
│ - 查询覆盖度 25% │
│ - 来源多样性 5% │
│ │
│ 【目标:多因子融合,精准排序】 │
└─────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────┐
│ post-rerank 阶段(后处理) │
│ │
│ 3. DiversityStrategy │
│ - 限制同一来源文档数 │
│ - 避免内容重复 │
│ │
│ 4. ContextPackingStrategy │
│ - 按字符/token 限制组装 │
│ - 确保不超出 LLM 上下文窗口 │
│ │
│ 【目标:控制输出质量和数量】 │
└─────────────────────────────────────────┘
│
▼
最终文档列表(给 LLM)这是我们项目中具体的过滤流程图,不同阶段的策略主功能不同,有些是参与打分,有些不参与,有些专门负责重排序
将过滤前后过滤后的策略抽取出来,单独管理,好处是每个策略各司其职,不会执行混乱
(2)构造方法(构建策略链条)
java
public RetrievalStrategyChain(List<RetrievalStrategy> strategies, ObjectProvider<RerankStrategy> rerankStrategyProvider) {
// 过滤并排序策略(排除 RerankStrategy)
List<RetrievalStrategy> filteredStrategies = strategies == null ? new ArrayList<>() : strategies.stream()
.filter(strategy -> strategy != null && !(strategy instanceof RerankStrategy))//重排序策略不参与比较
.collect(java.util.stream.Collectors.toCollection(ArrayList::new));
filteredStrategies.sort(Comparator.comparingInt(RetrievalStrategy::getOrder));//根据策略的getOrder的属性值进行策略按次序排放
// 以 DIVERSITY策略阶段为界,划分 pre/post-rerank
int postRerankBoundary = RetrievalStage.DIVERSITY.getOrder();
//策略顺序小于DIVERSITY策略的,统统放在preRerankStrategies
this.preRerankStrategies = filteredStrategies.stream()
.filter(strategy -> strategy.getStage().getOrder() < postRerankBoundary)
.collect(java.util.stream.Collectors.toCollection(ArrayList::new));
//策略顺序大于等于DIVERSITY策略的,统统放在postRerankStrategies
this.postRerankStrategies = filteredStrategies.stream()
.filter(strategy -> strategy.getStage().getOrder() >= postRerankBoundary)
.collect(java.util.stream.Collectors.toCollection(ArrayList::new));
//
this.rerankStrategyProvider = rerankStrategyProvider;
}这一段的核心作用还是通过我们具体策略类重写的
getState方法,获取每个策略的枚举类RetrievalStage,再调用他内部的getOrder方法获取到顺序值,就是我们下面图片内的"30"属性(值越小,策略越先执行),根据每个策略的order大小,将每个策略排序后放在filteredStategies集合中,后续又将该集合按照DICERSITY策略的order值为界限,将刚才排序好的策略放在preRerankStrategies,postRerankStrategies,rerankStrategyProvider这些集合中
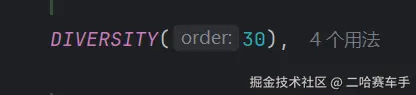
这里需要说明一下,我们的输入参数
List<RetrievalStrategy> strategies,spring会自动将接口RetrievalStrategy的实现类自动注入到这个List集合中,所以我们所有的具体策略实现类会自动注入进来
(3)策略链执行方法
java
public RetrievalFilterResult execute(RetrievalFilterContext context) {
// 获取原始文档列表
List<Document> original = context.getOriginalDocuments() == null
? List.of()
: new ArrayList<>(context.getOriginalDocuments());
List<Document> current = new ArrayList<>(original);
long startTime = System.currentTimeMillis();
log.info("[RetrievalStrategyChain] 开始执行检索后处理 - 原始文档数: {}", original.size());
// 阶段1:pre-rerank(硬过滤、相似度截断)
int preRerankSize = current.size();
current = applyStrategies(preRerankStrategies, context, current);
log.info("[RetrievalStrategyChain] pre-rerank完成 - 向量检索返回文档数: {} -> pre-rerank 过滤后剩下的文档数: {}", preRerankSize, current.size());
context.setCurrentDocuments(current);
// 阶段2:rerank(BM25打分、启发式重排)
RerankStrategy rerankStrategy = rerankStrategyProvider.getIfAvailable();
if (rerankStrategy != null && context.getPolicy() != null
&& context.getPolicy().isRerankEnabled()
&& rerankStrategy.supports(context)) {
try {
long rerankStart = System.currentTimeMillis();
// 执行重排,获取带分数的文档列表
List<DocumentScore> scores = rerankStrategy.rerank(context, current);
context.setRerankScores(scores);
// 提取重排后的文档顺序
current = scores.stream().map(DocumentScore::getDocument).toList();
context.setCurrentDocuments(current);
log.info("[RetrievalStrategyChain] rerank完成 - 重排序的文档数: {}, 耗时: {}ms", current.size(), System.currentTimeMillis() - rerankStart);
} catch (Exception e) {
// 重排失败,保留当前顺序,记录警告
log.warn("RAG rerank failed, keep original order - error={}", e.getMessage());
}
}
// 阶段3:post-rerank(多样性、上下文装箱)
int postRerankSize = current.size();
current = applyStrategies(postRerankStrategies, context, current);
log.info("[RetrievalStrategyChain] post-rerank完成 - 重排序前文档数: {} -> post-rerank 过滤后剩下的文档数: {}", postRerankSize, current.size());
// 回退机制:如结果为空且启用回退,返回原始文档的前K个
if (context.getPolicy() != null
&& context.getPolicy().isFallbackEnabled()
&& current.isEmpty()
&& !original.isEmpty()) {
int fallbackTopK = Math.max(1, context.getPolicy().getFallbackTopK());
current = new ArrayList<>(original.subList(0, Math.min(original.size(), fallbackTopK)));
context.setFallbackUsed(true);
log.info("[RetrievalStrategyChain] 触发回退机制 - 返回原始结果前{}个", fallbackTopK);
}
long totalTime = System.currentTimeMillis() - startTime;
log.info("[RetrievalStrategyChain] 检索后处理完成 - 原始: {}, 最终: {}, 总耗时: {}ms", original.size(), current.size(), totalTime);
context.setCurrentDocuments(current);
return buildResult(context);
}
java
private List<Document> applyStrategies(List<RetrievalStrategy> strategies, RetrievalFilterContext context, List<Document> current) {
List<Document> result = current == null ? List.of() : new ArrayList<>(current);
for (RetrievalStrategy strategy : strategies) {
// 检查策略是否支持当前上下文
if (!shouldApply(strategy, context)) {
continue;
}
int before = result.size();
try {
// 执行策略
result = safeApply(strategy, context, result);
} catch (Exception e) {
// 策略执行失败,记录日志,继续执行后续策略
log.warn("RAG retrieval strategy failed - strategy={}, error={}", strategy.getName(), e.getMessage());
continue;
}
// 记录该策略过滤掉的文档数量
context.addRemoved(strategy.getName(), Math.max(0, before - result.size()));
}
return result;
}
/**
* 判断策略是否应该应用。
*
* @param strategy 检索策略
* @param context 检索过滤上下文
* @return 是否应用该策略
*/
private boolean shouldApply(RetrievalStrategy strategy, RetrievalFilterContext context) {
return strategy != null && strategy.supports(context);
}
/**
* 安全地应用策略。
* <p>
* 如策略返回 null,返回空列表而非 null,避免 NPE。
*
* @param strategy 检索策略
* @param context 检索过滤上下文
* @param documents 当前文档列表
* @return 过滤后的文档列表(不会为 null)
*/
private List<Document> safeApply(RetrievalStrategy strategy, RetrievalFilterContext context, List<Document> documents) {
List<Document> result = strategy.apply(context, documents);
return result == null ? List.of() : result;
}
java
开始
│
▼
获取原始文档 (original)
│
▼
┌─────────────────────────────────────────┐
│ 阶段1: pre-rerank │
│ 执行: preRerankStrategies 列表 │
│ 策略: 硬过滤、BM25评分 │
│ 结果: current 更新 │
└─────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────┐
│ 阶段2: rerank(可选) │
│ 条件: 策略存在 && 启用 && 支持 │
│ 执行: rerankStrategy.rerank() │
│ 结果: 按分数重排序 │
└─────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────┐
│ 阶段3: post-rerank │
│ 执行: postRerankStrategies 列表 │
│ 策略: 多样性、上下文装箱 │
│ 结果: current 更新 │
└─────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────┐
│ 回退机制(可选) │
│ 条件: 结果为空 && 启用回退 │
│ 执行: 返回原始文档前K个 │
└─────────────────────────────────────────┘
│
▼
构建并返回 RetrievalFilterResult这是我们主要的策略链启动方法,当外界调用
execute方法时,他会启动整个执行链条,将我们传递的文档根据不同策略进行过滤操作,他的核心操作还是路由与分发,当我们遍历到策略1时,他会通过提前调用shouldApply,底层调用我们具体遍历到的策略的support方法判断当前策略是否允许执行(前面提到了),然后通过调用safeApply方法,底层调用我们具体的每个策略的apply方法执行具体的策略过滤逻辑,其流程图如下
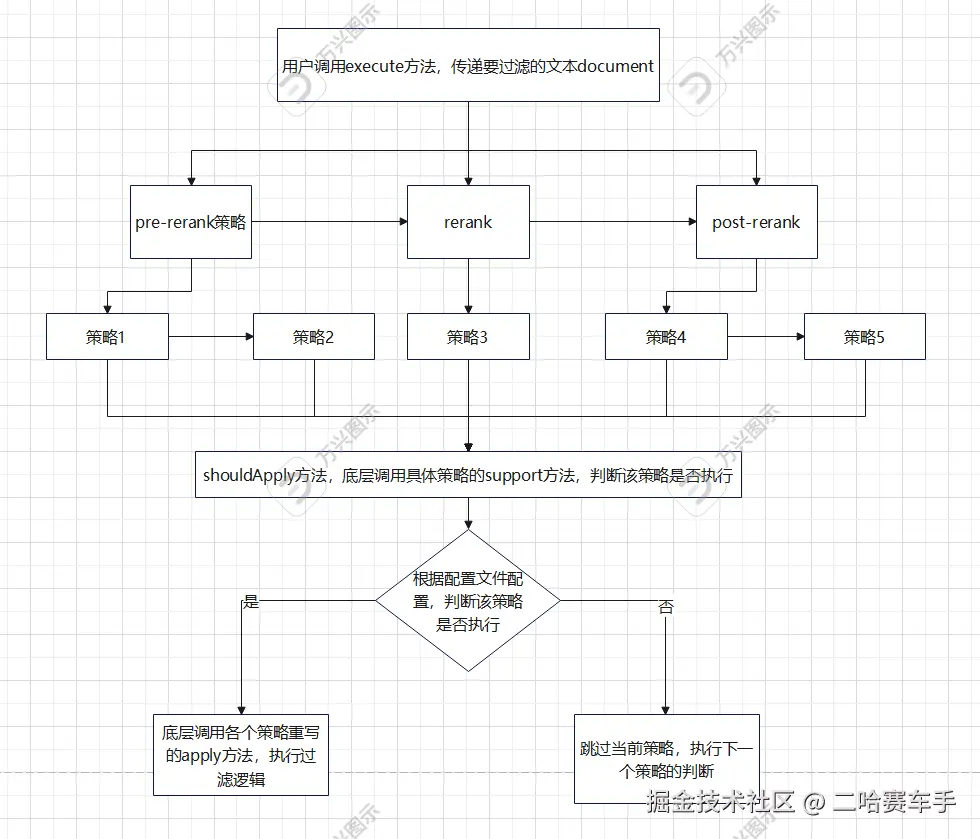
5.检索过滤上下文RetrievalFilterContext
java
@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
public class RetrievalFilterContext {
/**
* 用户查询文本。
* <p>
* 用于策略判断(如重排时需要查询文本计算相关性)。
*/
private String query;
/**
* 知识库标签。
* <p>
* 标识当前查询所属的知识库,用于获取对应的策略配置。
*/
private String knowledgeTag;
/**
* 检索策略配置。
* <p>
* 包含相似度阈值、最大返回数量、各功能开关等配置。
*/
private RagFilterConfig.RetrievalPolicy policy;
/**
* 原始文档列表。
* <p>
* 从向量数据库检索到的原始结果,策略执行过程中不应修改。
* 用于统计和回退机制。
*/
@Builder.Default
private List<Document> originalDocuments = new ArrayList<>();
/**
* 当前文档列表。
* <p>
* 策略执行过程中的当前状态,各策略会更新此列表。
* 初始值为原始文档的副本,策略执行后变为过滤后的结果。
*/
@Builder.Default
private List<Document> currentDocuments = new ArrayList<>();
/**
* 重排分数列表。
* <p>
* 如启用了重排策略,存储重排后的文档及其分数。
* 用于结果分析和调试。
*/
@Builder.Default
private List<DocumentScore> rerankScores = new ArrayList<>();
/**
* 各策略过滤数量统计。
* <p>
* Key:策略名称(如 "hard-filter", "similarity-cutoff")
* Value:该策略过滤掉的文档数量
* <p>
* 使用 LinkedHashMap 保持插入顺序,便于按执行顺序查看统计。
*/
@Builder.Default
private Map<String, Integer> removedCounts = new LinkedHashMap<>();
/**
* 扩展属性容器。
* <p>
* 用于策略间传递额外数据,如中间计算结果、缓存等。
* Key:属性名,Value:属性值(任意类型)
*/
@Builder.Default
private Map<String, Object> attributes = new HashMap<>();
/**
* 是否使用了回退机制。
* <p>
* 当过滤后结果为空且启用了回退时,标记为 true。
*/
private boolean fallbackUsed;
/**
* 记录某策略过滤的文档数量。
* <p>
* 【使用方式】
* 策略执行后调用,统计该策略过滤掉的文档数。
* 如该策略已有过滤记录,则累加。
* <p>
* 【示例】
* <pre>
* int before = documents.size();
* List<Document> filtered = applyFilter(documents);
* context.addRemoved("similarity-cutoff", before - filtered.size());
* </pre>
*
* @param stage 策略名称/阶段标识
* @param count 过滤的文档数量(如小于等于0则忽略)
*/
public void addRemoved(String stage, int count) {
if (count <= 0) {
return;
}
// 使用 merge 方法累加,如不存在则初始化为 count
removedCounts.merge(stage, count, Integer::sum);
}
java
┌─────────────────────────────────────────┐
│ RetrievalFilterContext │
│ (数据传递载体) │
│ │
│ ├── 输入数据 │
│ │ ├── originalDocuments 原始文档 │
│ │ ├── query 查询文本 │
│ │ └── policy 策略配置 │
│ │ │
│ ├── 中间状态 │
│ │ ├── currentDocuments 当前文档 │
│ │ ├── rerankScores 重排分数 │
│ │ └── fallbackUsed 是否回退 │
│ │ │
│ └── 输出结果 │
└── 最终文档列表 │
└─────────────────────────────────────────┘
│
▼
在各策略间传递他的作用是将每个策略所需要都参数封装在一起,便于统一传递和管理,比如每个策略都需要读取RagFilterConfig中的配置,所以都需要policy属性,bm25检索策略需要query与原始文档,所以这些也需要传递。还有每个策略需要统计过滤后剩余的文档数,所以需要currentDocuments字段。如果每个方法都传一堆参数,会很乱。所以用 RetrievalFilterContext 统一承载。
三.具体策略讲解
这一部分我们就快速讲解了,具体策略可以多种多样,只要通过我们上面的策略执行器链,我们就可以自己搭配策略了
(1)向量检索策略

这部分本质是没有设定策略的,我们执行向量数据库检索后就会返回向量检索的文本,我们后续的过滤策略的原始文本都来自这里
(2)CandidateHardFilterStrategy(候选硬过滤)
作用 :快速剔除明显低质量的文档
策略链的第一个过滤器,用"硬门槛"快速剔除明显不合格的文档。
三个过滤条件详解
1. 必须有文本内容
java
// 检查文档是否有有效文本
if (!RetrievalMetricsSupport.hasText(doc)) {
continue; // 跳过这个文档
}
// hasText 实现:
public static boolean hasText(Document doc) {
if (doc == null) return false;
String text = doc.getText();
return StringUtils.hasText(text); // 非空且不只包含空白字符
}过滤场景 :
- 空文档
- 只有空格、换行符
- 只有标点符号
2. 长度 >= 50字符(可配置,在我们的RagFilterConfig中)
java
// 从策略配置获取最小长度(默认50)
int minLength = context.getPolicy().getMinDocumentLength();
String text = doc.getText().trim();
if (text.length() < minLength) {
continue; // 太短,跳过
}为什么过滤短文档 :
java
"好的" → 2字符,删掉(无意义)
"Grafana是一款开源工具" → 13字符,删掉(信息太少)
"Grafana是一款开源的数据可视化工具,支持多种数据源..." → 50+字符,保留配置方式 :
java
rag:
filter:
min-document-length: 50 # 可调整为30、100等3. 信息密度 >= 0.3(可配置)
java
// 从策略配置获取最小密度(默认0.3)
double minDensity = context.getPolicy().getMinInformationDensity();
// 计算信息密度
double density = RetrievalMetricsSupport.calculateInformationDensity
(text);
if (density < minDensity) {
continue; // 密度太低,跳过
}什么是信息密度 :
java
// 有效字符 = 字母、数字、中文
// 总字符 = 所有字符
信息密度 = 有效字符数 / 总字符数示例 :
java
文本:"啊啊啊啊啊啊啊啊啊!!!!!!"
有效字符:0(无意义重复)
总字符:20
密度:0/20 = 0.0 → 删掉
文本:"Grafana支持Prometheus、InfluxDB等数据源"
有效字符:30(字母、中文)
总字符:30
密度:30/30 = 1.0 → 保留配置方式 :
java
rag:
filter:
min-information-density: 0.3 # 可调整为0.2、0.5等完整执行流程
java
public List<Document> apply(RetrievalFilterContext context,
List<Document> documents) {
// 获取配置
int minLength = context.getPolicy().getMinDocumentLength
(); // 50
double minDensity = context.getPolicy().getMinInformationDensity
(); // 0.3
List<Document> filtered = new ArrayList<>();
for (Document doc : documents) {
// 检查1:有文本?
if (!hasText(doc)) continue;
String text = doc.getText().trim();
// 检查2:长度够?
if (text.length() < minLength) continue;
// 检查3:密度够?
double density = calculateInformationDensity(text);
if (density < minDensity) continue;
// 三个检查都通过,保留
filtered.add(doc);
}
return filtered;
}实际效果
java
向量检索返回:100个文档
│
├── 空文档/纯符号 → 删掉5个
├── 长度<50字符 → 删掉10个
└── 信息密度<0.3 → 删掉5个
│
最终保留:80个文档(3)BM25检索打分策略
这一块在我们BM25笔记那篇讲过了,这里跳过
(4). HeuristicRerankStrategy(启发式重排序)
RAG检索的核心策略,用6个因子综合打分,让最相关的文档排在最前面
6个评分因子详解
1. 向量相似度(40%)
java
// 从metadata提取pgvector的相似度分数
double similarity = RetrievalMetricsSupport.extractSimilarityScore
(doc);
score += similarity * 0.40;作用 :语义相关性,理解同义词、上下文
示例 :
java
查询:"如何配置Grafana"
文档:"Grafana配置教程..." → similarity=0.85 → 贡献34分2. BM25分数(20%)
java
// 从metadata提取(Bm25ScoringService回填)
double bm25 = RetrievalMetricsSupport.extractDoubleMetadata(doc,
"bm25_score");
score += bm25 * 0.20;作用 :关键词精确匹配,弥补向量的不足
示例 :
java
查询:"Grafana配置"
文档1:"Grafana配置步骤..." → bm25=0.90 → 贡献18分
文档2:"配置监控工具..." → bm25=0.30 → 贡献6分为什么需要BM25 :
java
向量问题:"八千代"可能匹配成"八千年"(语义相近)
BM25解决:精确匹配"八千代"这个词3. 查询覆盖度(25%)
java
// 查询词在文档中的覆盖程度
double coverage = RetrievalMetricsSupport.calculateQueryCoverage
(text, query);
score += coverage * 0.25;计算方式 :
java
// 1. 查询分词:[如何, 配置, Grafana]
// 2. 统计每个词在文档中出现情况
// 3. 覆盖度 = 匹配词数 / 总词数
查询:"如何配置Grafana"
文档:"Grafana配置教程,介绍如何安装"
→ 匹配:Grafana✓ 配置✓ 如何✓ → coverage=1.0 → 贡献25分4. 信息密度(15%)
java
// 有效字符占总字符的比例
double density = RetrievalMetricsSupport.calculateInformationDensity
(text);
score += density * 0.15;计算 :
java
有效字符 = 字母、数字、中文
总字符 = 所有字符(包括标点、空格)
密度 = 有效字符 / 总字符示例 :
java
"Grafana支持多种数据源,如Prometheus、InfluxDB..."
有效字符:35,总字符:40 → 密度=0.875 → 贡献13.1分
"啊啊啊!!!???"
有效字符:0,总字符:10 → 密度=0 → 贡献0分5. 长度适宜度(10%)
java
String text = doc.getText();
int length = text.length();
if (length < 100) {
// 太短:线性加分
score += (length / 100.0) * 0.10;
} else if (length <= 1000) {
// 理想长度:满分
score += 0.10;
} else {
// 太长:递减加分
score += (1000.0 / length) * 0.10;
}评分曲线 :
java
长度 得分
50 0.05 (50/100 * 0.10)
100 0.10 ✓满分
500 0.10 ✓满分
1000 0.10 ✓满分
2000 0.05 (1000/2000 * 0.10)为什么这样设计 :
- 太短:信息不足
- 100-1000:理想长度
- 太长:可能包含噪音
6. 来源多样性(5%)
java
// 多来源引用的文档小幅加分
Object sourceCount = RetrievalMetricsSupport.firstMetadata(doc,
"source_count");
if (sourceCount > 1) {
score += Math.min(0.05, sourceCount * 0.01);
}作用 :鼓励信息多样性
示例 :
java
单来源文档(source_count=1)→ 加0分
多来源文档(source_count=3)→ 加0.03分完整评分示例
java
文档A:"Grafana配置教程:如何配置数据源"
├─ 向量相似度:0.90 × 0.40 = 0.360
├─ BM25分数:0.85 × 0.20 = 0.170
├─ 查询覆盖度:1.0 × 0.25 = 0.250
├─ 信息密度:0.80 × 0.15 = 0.120
├─ 长度适宜度:500字符 = 0.100
└─ 来源多样性:1 = 0.000
─────────────────────────
总分:1.000(满分!)
文档B:"监控工具介绍"
├─ 向量相似度:0.70 × 0.40 = 0.280
├─ BM25分数:0.30 × 0.20 = 0.060
├─ 查询覆盖度:0.3 × 0.25 = 0.075
├─ 信息密度:0.75 × 0.15 = 0.112
├─ 长度适宜度:200字符 = 0.100
└─ 来源多样性:1 = 0.000
─────────────────────────
总分:0.627
结果:文档A排在文档B前面(5).DiversityStrategy(多样性控制)
避免所有结果都来自同一个文档,确保知识来源的多样性。
为什么要做多样性控制
问题场景
java
用户问:"Grafana如何配置"
不重排序的结果(按相似度):
1. Grafana官方文档-第1章
2. Grafana官方文档-第2章
3. Grafana官方文档-第3章
4. Grafana官方文档-第4章
5. Grafana官方文档-第5章
问题:所有结果都来自同一文档,信息单一!多样性控制后
java
1. Grafana官方文档-第1章 (source-A)
2. 社区博客-Grafana实战 (source-B)
3. 视频教程-快速入门 (source-C)
4. Grafana官方文档-第2章 (source-A)
5. 技术论坛-常见问题 (source-D)
优势:覆盖多种来源,信息更全面!轮询分发算法详解
核心思想
java
像发牌一样,轮流从每个来源取一个文档执行过程
java
// 输入:按来源分组(保持原有排序)
source-A: [A1, A2, A3] // Grafana官方文档
source-B: [B1, B2] // 社区博客
source-C: [C1] // 视频教程
// maxPerSource = 2(每个来源最多2个)
// 第1轮:从每个来源取第1个
→ [A1, B1, C1]
// 第2轮:从每个来源取第2个
→ [A1, B1, C1, A2, B2]
// 第3轮:C来源已空,停止
// A3被截断(已达到maxPerSource=2)
最终结果:[A1, B1, C1, A2, B2]代码实现
java
public List<Document> apply(RetrievalFilterContext context,
List<Document> documents) {
// 1. 获取配置:每个来源最多保留几个(默认2)
int maxPerSource = context.getPolicy().getMaxPerSource();
// 2. 按来源分组(LinkedHashMap保持顺序)
Map<String, List<Document>> grouped = new LinkedHashMap<>();
for (Document doc : documents) {
String source = extractSourceKey(doc); // 提取来源标识
grouped.computeIfAbsent(source, k -> new ArrayList<>()).add
(doc);
}
// 3. 轮询分发
List<Document> diverse = new ArrayList<>();
boolean hasMore = true;
int round = 0;
while (hasMore && round < maxPerSource) {
hasMore = false;
// 遍历每个来源,取第round个文档
for (List<Document> sourceDocs : grouped.values()) {
if (round < sourceDocs.size()) {
diverse.add(sourceDocs.get(round));
hasMore = true; // 本轮有文档被取出
}
}
round++;
}
return diverse;
}可视化流程
java
原始排序(按相似度):
┌─────────────────────────────────────────┐
│ 1. A1 (source-A, sim=0.95) │
│ 2. A2 (source-A, sim=0.93) │
│ 3. A3 (source-A, sim=0.90) │
│ 4. B1 (source-B, sim=0.88) │
│ 5. A4 (source-A, sim=0.87) │
│ 6. B2 (source-B, sim=0.85) │
│ 7. C1 (source-C, sim=0.82) │
│ 8. A5 (source-A, sim=0.80) │
└─────────────────────────────────────────┘
↓ 按来源分组
分组结果:
source-A: [A1, A2, A3, A4, A5]
source-B: [B1, B2]
source-C: [C1]
↓ 轮询分发 (maxPerSource=2)
多样性排序:
┌─────────────────────────────────────────┐
│ 1. A1 (source-A, 第1轮) │
│ 2. B1 (source-B, 第1轮) │
│ 3. C1 (source-C, 第1轮) │
│ 4. A2 (source-A, 第2轮) │
│ 5. B2 (source-B, 第2轮) │
│ │
│ A3, A4, A5 被截断(A已达上限2个) │
└─────────────────────────────────────────┘配置参数
java
rag:
filter:
diversity-enabled: true # 是否启用
max-per-source: 2 # 每个来源最多保留几个他的核心作用还是为了避免RAG检索高度集中在同一篇文档中,比如我5篇文档都与用户问题有关,最后返回的全是第一篇文档的内容,通过每个文档取出相似度最高的知识片段返回给AI,AI才能更加全面的回答我们的问题
四.测试示例
我们发出"八千代为什么这么孤独"问题


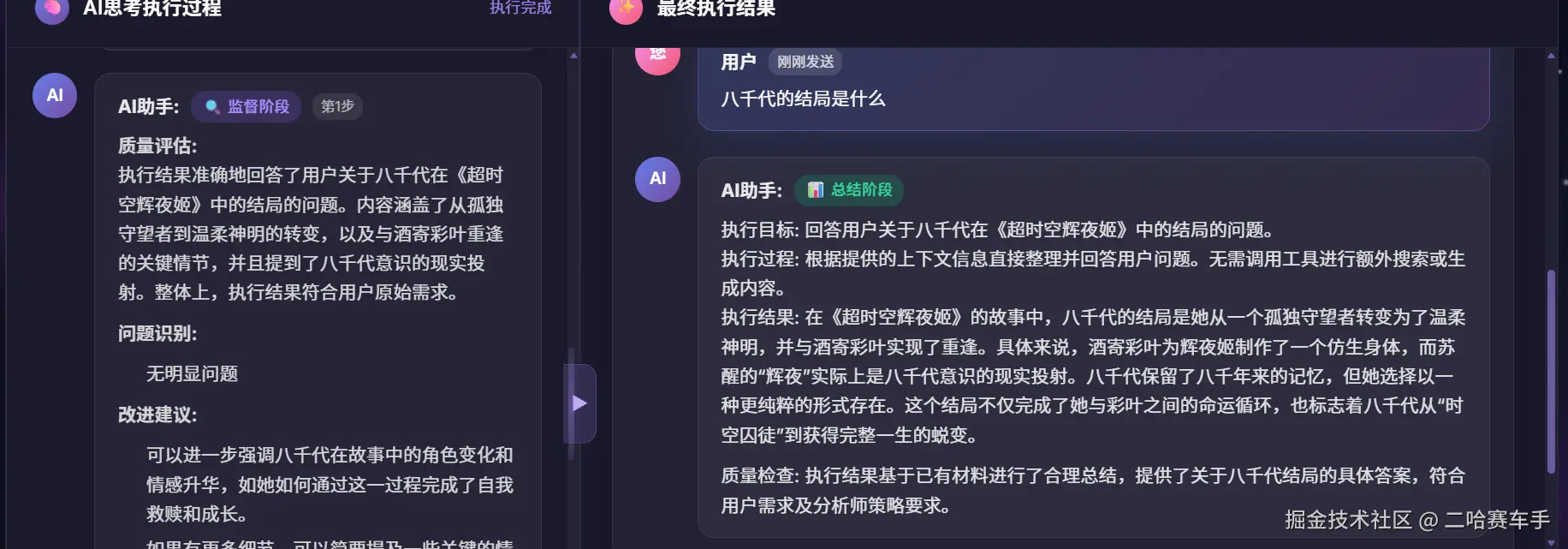
验证成功,通过日志可以看见整个RAG策略执行链是可以正常工作的,AI也成功返回我们RAG知识库中比较准确的结果