文章目录
1.整体架构流转:
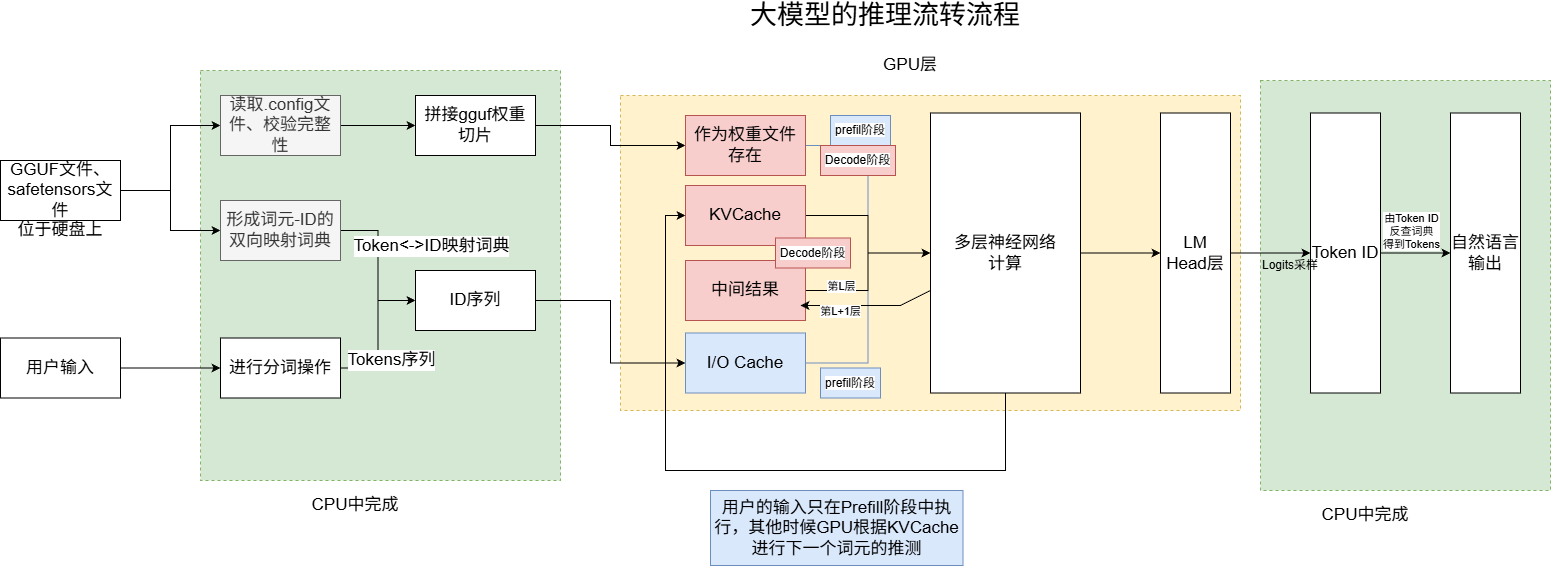
上面的图中显示了从硬盘加载到大模型输出的整体流程。在这个流程中,硬盘经历了从硬盘到CPU、从CPU到GPU、再从GPU返回CPU的过程。
那么有瘦友就会问了,为什么要这么做呢?为什么一会CPU一会GPU的呢?这其中最大的原因就是:显存太贵啦!显而易见,大家(大模型公司)都买不起这么多显卡,所以只能借用相对而言比较便宜的内存DRAM的空间来存储了。清华提出的KTransformers推理框架就是国内第一个连接CPU和GPU的推理框架哟!
那么它是怎么做的呢?
首先,我们从modelscope或者hugging face下载saftensensors或者GGUF文件后,一般情况下,会放到SSD盘,以加速读取。好了,当我们把大模型运行起来的时候,会发生什么事呢?
2.加载大模型的时候,发生了什么?
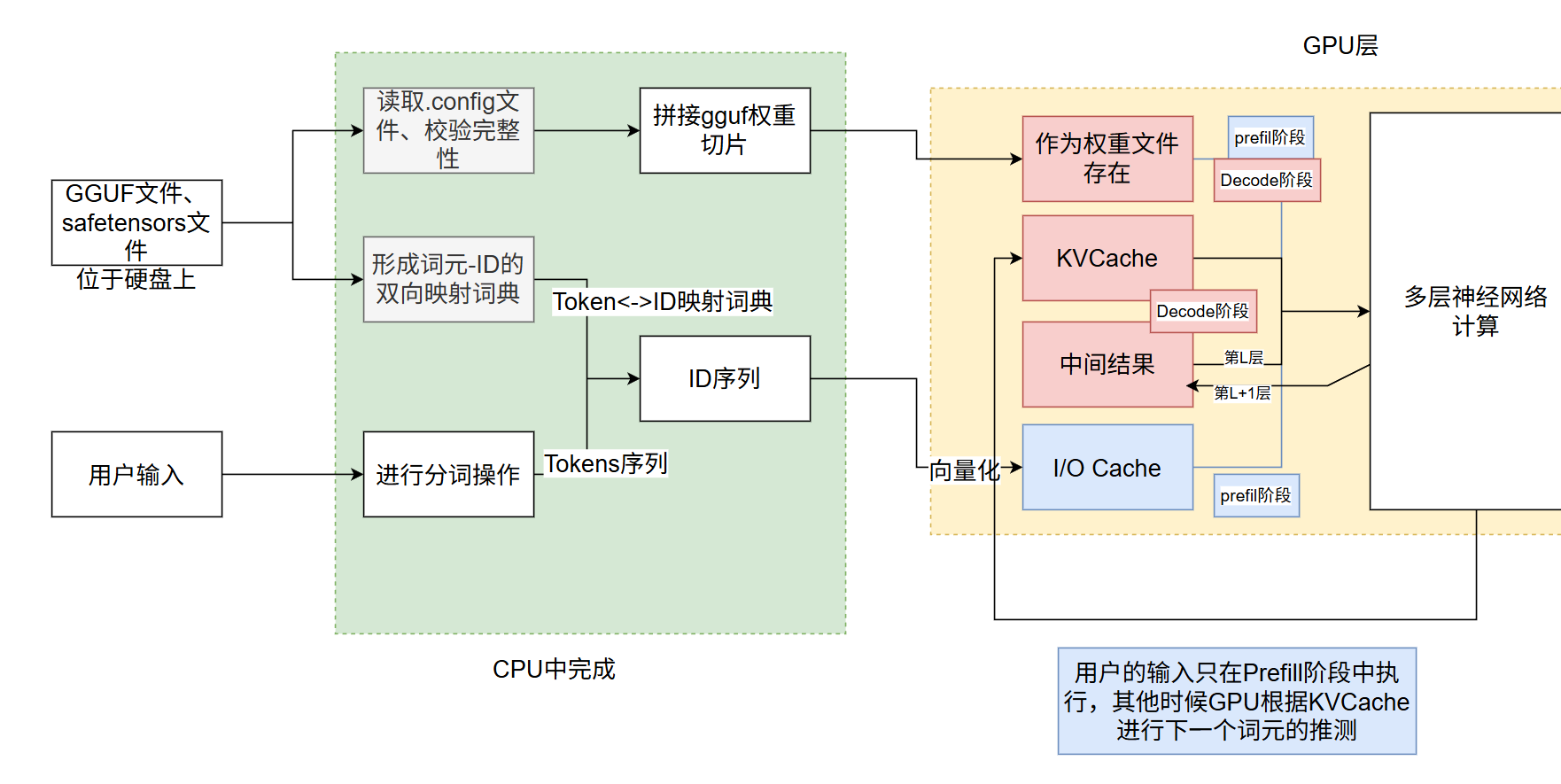
假设这个时候,用户还来不及提问,只是默默等待大模型运转的时候。(为什么要等这么久呢?,且听我说------
因为加载真的太久了!
首先,它要预加载一下,一方面,加载TOKEN-ID的映射关系。比如he - 01, she - 02。。这样的从词到ID的对应关系,组成TOKEN - ID的双向映射词典。
接着,它要加载权重文件 了,加载的第一步是先做校验,看下模型是不是完整的。假设全加载进来才发现模型有错,天啊,天都塌了。所以,为了预防这种天都塌了的情况,它会先去校验.config文件。(下载过safetensors文件/gguf文件的瘦友一定都见过这份文件的吧!)然后它就对这份模型文件有了解了,之后,再通过.config文件对整个模型进行拼接、量化。
准备完成后,将模型文件加载到GPU!好了,那么至此,漫长的等待模型权重文件加载的过程就完成了。
请注意,在此时,KVCache是空的哟!IO Cache也是空的哟!中间处理结果Cache更是空的!此时显存中就是权重文件在孤单地等待.
3.用户输入第一次提问的时候,发生了什么?
一直等...等...
终于等到用户输入了!
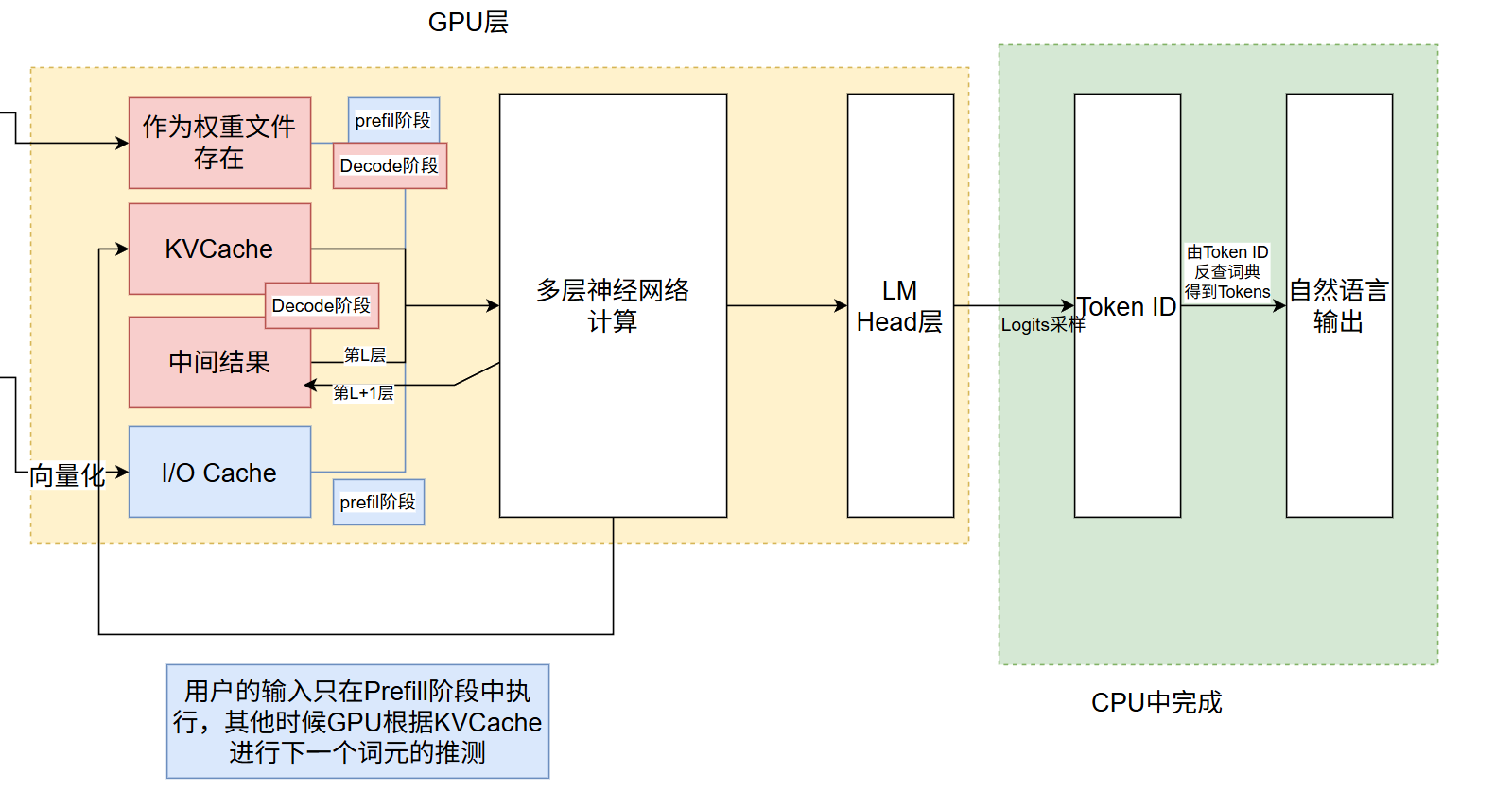
CPU开始干活了。还记得前面我们已经在CPU中完成了TOKEN-ID的映射词典了吗?这个时候就要发挥作用了,根据用户输入的自然语言(简单理解就是看得懂的人话),CPU将自然语言翻译成对应的ID序列。ID序列传入到GPU后再进一步地做向量化,就被放到IO Cache了。
等待已久的大模型终于开始工作了。
此时进入了我们常说的prefill阶段,这个阶段也是最考察大模型的阶段。它要将着急忙慌地做一大段的推理,根据IO Cache的序列,以及权重文件,经历N层的神经网络、前向传播过程(在此期间每层网络更新的时候,不断更新中间过程Cache,以及每层KVCache),至此KVCache和中间过程Cache都有了数据,而此后也不需要IO Cache的数据了。
),至此KVCache和中间过程Cache都有了数据,而此后也不需要IO Cache的数据了。
大模型开始了自己的运转,也就是我们说的Decode阶段。根据N个KVcahe + 权重文件,大模型输出了第N+1个K/V,第N+1个K/V被放到KVCache的末尾,并在用户界面输出这个ID对应的词元;大模型循环往复,直到结束第一轮对话的问答。