引擎分类
官网把CH的引擎分成4大类
MergeTree
MergeTree引擎:一个带有自动整理、压缩、打标签功能的智能保险柜,适合存放最重要、最庞大的核心数据。
这类引擎数据实际存储在 ClickHouse 本地磁盘,用于持久化分析。
王者引擎。支持分区、主键索引、数据副本(Replicated)、TTL(数据生命周期)。生产环境 99% 的核心表都用它。
Log
Log 引擎:一个普通的纸箱,东西可以快速扔进去,但找起来很麻烦,也没有整理功能。适合存放临时、不重要的小批量数据。
轻量级日志引擎。数据追加写入,不支持索引、删除和更新。适合临时存储或小表(< 100万行)。
Memory
内存表。数据只存在内存中,服务重启即丢失。适合做高速临时计算。
integration
这类引擎本身通常不存数据,而是作为代理(Proxy),将查询转发给外部系统。
Kafka :
消息队列连接器。直接消费 Kafka Topic 数据。必须配合物化视图(Materialized View) 将数据写入 MergeTree 表才能持久化。
Redis:
缓存映射。将 Redis 的 Key-Value 结构映射为表,适合做高速维度表查询。
如果有主键,主键一定要在排序中
- 核心原因:主键的本质是"稀疏索引"
在 ClickHouse 的 MergeTree引擎中:
ORDER BY 决定了数据在磁盘上的物理存储顺序(就像字典按拼音排序)。
PRIMARY KEY 是为了建立跳数索引(Sparse Index)。它不会为每一行数据都建索引,而是每隔一段(默认 8192 行)取一行的值作为索引键。
如果你想通过主键快速找到数据,那么主键值必须是有序的。如果主键不在排序字段里,数据在磁盘上是乱序的,索引也就失去了快速定位的意义。
-
去重机制的要求
ClickHouse 的 ReplacingMergeTree引擎有一个特性:同一个排序键(ORDER BY 字段)的数据会被合并,保留最后插入的版本。
排序键是数据合并的最小单位。
如果你希望根据某个字段(比如 id)去重,那么 id必须是排序键的一部分。否则 ClickHouse 不知道该把哪几行归为一组进行去重。
-
语法规则(硬性限制)
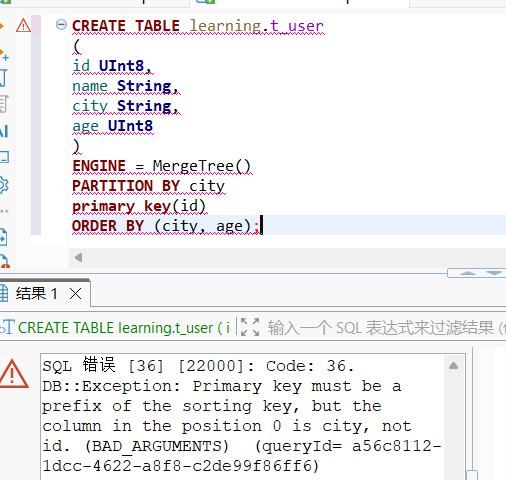
这是最直观的一点:在 ClickHouse 中,主键(PRIMARY KEY)必须是排序键(ORDER BY)的前缀。
反列子
正确的sql
sql
CREATE TABLE learning.t_user
(
id UInt8,
name String,
city String,
age UInt8
)
ENGINE = MergeTree()
PARTITION BY city
primary key(id)
ORDER BY (id, age);不去重
建表完成后我们执行2次下面的语句
sql
insert into learning.t_user
values (1,'lufu','east',18),
(2,'zuolong','east',19),
(3,'wusuopu','west',17);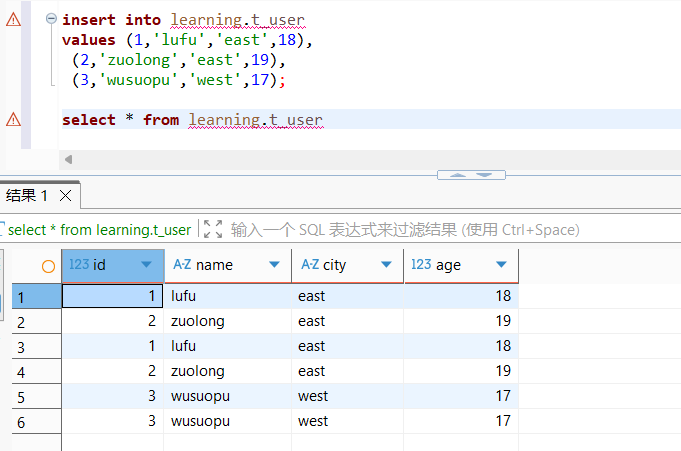
可以看到虽然有主键,但是不会根据主键去重
原因也很好理解,CH 是以文件块的方式append的,无法感知其他块的数据