1. 背景
前面我有文章介绍子Flash Attention 针对长序列的正向优化,而其反向算子(Backward Pass)的优化由于涉及到复杂的梯度重计算和显存权衡,往往比正向过程更具挑战性。
在反向算子中,核心目标是计算梯度 dQ,dK, dV。首先看公式, 为了描述简单,其计算流程也简单,系数、mask等先省略。
|--------------------------------------------|------------------------------------------------------------------------------|
| 正向计算公式 | 反向计算公式 |
| |
,
|
| |
, |
| |
|
2. Flash Attention分块
类似Flash Attention前向的tiling分块优化,可以优化显存访问量,但反向过程会增加一次S和P的重计算,详解流程图可以看我前面的一篇正向文章。先看看伪代码:
python
def flash_attention_backward(Q, K, V, dO, m, l, Bc, Br):
N, d = Q.shape
dQ = dK = dV = zeros(N, d)
# 外层循环:遍历K、V的块(列块)
for j in range(0, N, Bc):
Kj = K[j:j+Bc, :] # [Bc, d]
Vj = V[j:j+Bc, :] # [Bc, d]
# 内层循环:遍历Q、dO的块(行块)
for i in range(0, N, Br):
Qi = Q[i:i+Br, :] # [Br, d]
dOi = dO[i:i+Br, :] # [Br, d]
m_i = m[i:i+Br] # [Br]
l_i = l[i:i+Br] # [Br]
# ===== 1. 重计算前向 =====
Sij = Qi @ Kj.T # [Br, Bc]
# 稳定Softmax
Pij = exp(Sij - m_i.unsqueeze(1)) / l_i.unsqueeze(1) # [Br, Bc]
# ===== 2. 计算 dP = dO · V^T =====
dPij = dOi @ Vj.T # [Br, Bc] (mm1)
# ===== 3. Softmax反向,计算 dS = P ⊙ (dP - rowsum(P⊙dP)) =====
rowsum = (Pij * dPij).sum(dim=1, keepdim=True) # [Br, 1]
dSij = Pij * (dPij - rowsum) # [Br, Bc]
# ===== 4. 计算梯度贡献并累加 =====
dQ[i:i+Br, :] += dSij @ Kj # [Br, d] (mm2的一部分)
dK[j:j+Bc, :] += Qi.T @ dSij # [Bc, d] (mm3的一部分)
dV[j:j+Bc, :] += Pij.T @ dOi # [Bc, d] (mm4的一部分)
return dQ, dK, dV和正向FlashAttention类似,尽量利用好片上SRAM,这样MAC(显存访问量)从传统的优化到
,显存占用从
优化到
, N是序列长度,d是tokens向量的维度。
3. 数学恒等式的简化
其中计算dS时有个技巧,按行先存下Di,这样可以避免重复冗余计算。
,
利用链式法则,损失对注意力得分S的梯度可以化简为:
,
为了方便工程实现,我们通常记 , 于是公式变为:
4.负载均衡
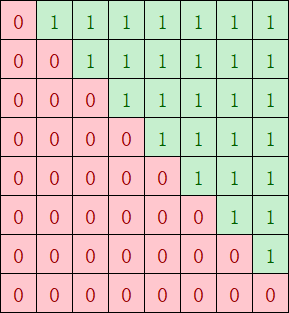
在反向传播中,由于 Casual Mask(因果掩码)的存在,矩阵是一个下三角矩阵。
问题:如果简单划分 Workload,处理上三角部分的线程块会无事可做,导致 GPU 利用率低下。
优化:动态调整分块任务的分发,确保每个 Streaming Multiprocessor (SM) 处理的有效计算量大致相等。
5. Flash Attention-2 与 v3 的进阶优化
-
FA2 改进:在 FA2 中,反向过程进一步减少了非矩阵乘法(non-matmul)的计算。通过改变循环顺序,使得对 dQ, dK, dV 的更新更加高效,减少了原子加(Atomic Add)的冲突。
-
FA3 (Hopper GPU 优化):
-
Warp-specialization:将 Warp 划分为"生产者"和"消费者",分别负责数据搬运和计算。
-
FP8 精度:针对 H100 等硬件,利用新的 Tensor Core 支持 FP8 训练,大幅提升吞吐量。
-
6. 总结对比
| 特性 | 传统 Attention 反向 | Flash Attention 反向 |
|---|---|---|
| 显存占用 | ||
| 显存IO访问量 | ||
| IO 瓶颈 | 高 (频繁读写 HBM) | 低 (在 SRAM 中完成计算) |
| 计算量 | 较低 | 较高 (通过重计算换取空间) |
| 主要性能限制 | 内存带宽 | 算力 (Compute Bound) |