一、前言
随着AI的发展,大模型一词越来越多的出现在我们的生活工作中,一开始大家更多的是把大模型当成一个聊天机器人,但是随着AI的进一步发展,我们不再仅仅满足于和大模型聊天,所以一个更深一层的概念就出来了 ------ Agent。
二、什么是Agent
Agent直接翻译过来就是 "代理",所谓的AI Agent就是大模型和人类之间的代理,我们通过Agent和大模型进行交流,大模型通过Agent来 "感知"我们的世界。Agents 将大语言模型与工具结合,创建具备任务推理、工具使用决策、工具调用的自动化系统,系统具备持续推理、工具调用的循环迭代能力,直至问题解决。
我们日常也使用过很多Agent,例如豆包、千问、还有程序员经常使用的各种AI 工具,比如 Claude Code、Cursor、Tare等等。
这里有一个误区,这也是我一开始学习AI的时候所碰到的问题,以为大模型自己本身可以调用工具,可以联网查询等等,其实不是。大模型(LLM)全称是大语言模型(Large Language Model),说白了大模型只会输出文字,至于工具调用这一切都是通过Agent实现确切的说是通过程序员写的代码本身去执行的。
三、ReAct Agent
知道了什么是Agent之后,接下里我们学习一个概念 ReAct Agent,首先我们看下什么是ReAct Agent ,ReAct(Reasoning + Acting)是一种将推理和行动相结合的 Agent 范式。在这个范式中,Agent 会:
- 思考(Reasoning):分析当前情况,决定下一步该做什么
- 行动(Acting):执行工具调用或生成最终答案
- 观察(Observation):接收工具执行的结果
- 迭代:基于观察结果继续思考和行动,直到完成任务
这个循环使 Agent 能够:
- 将复杂问题分解为多个步骤
- 动态调整策略基于中间结果
- 处理需要多次工具调用的任务
- 在不确定的环境中做出决策
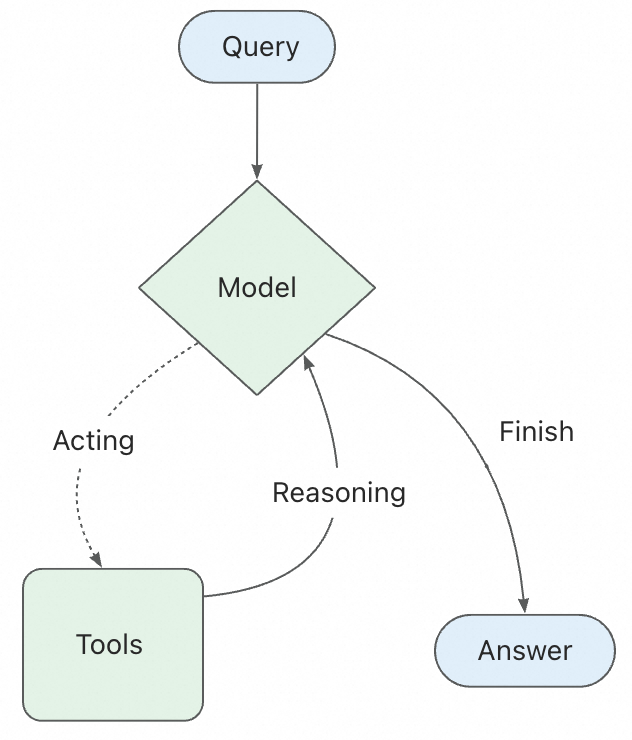
说白了ReAct Agent出现的目的就是为了解决普通Agent在解决复杂问题的时候的不足。
四、代码实现
这里展示最核心的代码,思路其实都是一样的
java
/**
* SimpleReactAgent 的核心推理方法,实现了 ReAct (Reasoning + Acting) 模式
*
* ReAct 模式的核心思想是:通过"思考 → 行动 → 观察"的反复循环来逐步解决任务。
* 每轮循环中:
* 1. Reasoning:模型根据当前上下文思考下一步该做什么
* 2. Act(ToolCall):如果需要工具则调用工具,否则输出最终答案
* 3. Observation:获取工具执行结果,进入下一轮循环
*
* 流程概述:
* - 初始化消息列表,组装系统提示词、历史记忆和当前问题
* - 进入主循环,反复调用大模型直到完成任务或达到最大轮次
* - 每次调用判断:是否有工具调用 → 执行工具 → 继续循环
* - 无工具调用时输出最终答案
*
* @param conversationId 会话ID,用于加载和保存对话历史。为null时表示不使用会话记忆
* @param question 用户当前的问题
* @return AI生成的最终回答(自然语言,非工具调用格式)
*/
public String callInternal(String conversationId, String question) {
// 使用线程安全的 List 来存储消息,确保多线程环境下数据安全
List<Message> messages = Collections.synchronizedList(new ArrayList<>());
// 判断是否使用会话记忆:只有同时提供了 conversationId 和 chatMemory 才启用
boolean useMemory = conversationId != null && chatMemory != null;
// ===== 步骤1:组装系统提示词 =====
// REACT_AGENT_SYSTEM_PROMPT 定义了 ReAct 模式的核心规则:
// - 工具调用必须通过 ToolCall 结构输出,禁止在 content 中夹杂
// - 最终答案必须是自然语言,禁止包含工具调用格式
// - 不允许重复调用同一个工具(防循环)
messages.add(new SystemMessage(REACT_AGENT_SYSTEM_PROMPT));
// 额外的系统提示词,来自用户配置的业务提示词(如角色设定等)
messages.add(new SystemMessage(systemPrompt));
// ===== 步骤2:加载历史对话记忆(可选) =====
if (useMemory) {
// 从 ChatMemory 中获取该 conversationId 的历史消息
List<Message> history = chatMemory.get(conversationId);
if (!history.isEmpty()) {
// 将历史消息追加到当前消息列表末尾,保持上下文连贯性
messages.addAll(history);
}
}
// ===== 步骤3:添加当前问题 =====
// 使用 XML 标签包裹问题,便于模型识别问题边界
messages.add(new UserMessage("<question>" + question + "</question>"));
// 同时将用户问题存入记忆(用于后续对话的上下文延续)
if (useMemory) {
chatMemory.add(conversationId, new UserMessage(question));
}
// ===== 步骤4:进入 ReAct 主循环 =====
int round = 0; // 当前推理轮次计数器
int reflectionRound = 0; // 反思轮次计数器(用于 reflection 机制)
while (true) {
round++;
// ----- 轮次限制检查 -----
if (maxRounds > 0 && round > maxRounds) {
// 达到最大推理轮次,强制终止并生成最终答案
log.warn("=== 达到 maxRounds({}),强制生成最终答案 ===", maxRounds);
// 向模型注入一条系统消息,要求它基于已有信息直接输出答案
messages.add(new UserMessage("""
你已达到最大推理轮次限制。
请基于当前已有的上下文信息,
直接给出最终答案。
禁止再调用任何工具。
如果信息不完整,请合理总结和说明。
"""));
// 调用大模型生成最终答案
String finalText = chatClient.prompt().messages(messages).call().content();
// 保存最终答案到会话记忆
if (useMemory) {
chatMemory.add(conversationId, new AssistantMessage(finalText));
}
return finalText;
}
// ----- 调用大模型 -----
// 将当前所有消息(系统提示 + 历史 + 当前问题 + 工具响应)发送给模型
ChatClientResponse chatResponse = chatClient
.prompt()
.messages(messages)
.call()
.chatClientResponse();
// 提取模型的输出文本
String aiText = chatResponse.chatResponse().getResult().getOutput().getText();
// 构建 AssistantMessage 的 Builder,用于后续添加工具调用信息
AssistantMessage.Builder builder = AssistantMessage.builder().content(aiText);
// ----- 判断模型输出类型 -----
// ===== 分支A:没有工具调用,视为最终答案 =====
if (!chatResponse.chatResponse().hasToolCalls()) {
// ----- Reflection 反思机制(可选)-----
// 如果开启了反思功能,并且模型在 context 中标记了 reflection.required,
// 说明模型认为当前答案不够完善,需要进行自我反思和修正
if (maxReflectionRounds > 0 && Boolean.TRUE.equals(chatResponse.context().get("reflection.required"))) {
// 防止无限反思:达到最大反思轮次后强制输出当前答案
if (reflectionRound >= maxReflectionRounds) {
log.warn("======= Reflection 最大轮次已达,直接输出结论 =======");
if (useMemory) {
chatMemory.add(conversationId, new AssistantMessage(aiText));
}
return aiText;
}
reflectionRound++;
log.info("===== 当前反思机制,第 {} 轮次 =====", reflectionRound);
// 从 context 中提取反思意见(由 reflection advisor 生成)
String feedback = (String) chatResponse.context().get("reflection.feedback");
// 将反思意见作为新的用户消息注入,引导模型重新思考和规划
// 这形成了一个新的推理循环:模型会根据反馈重新决定是否需要调用工具
messages.add(new AssistantMessage("""
【Reflection Feedback】
%s
请你根据以上反思意见重新规划任务,
必要时可以重新调用工具,
然后再给出最终答案。
""".formatted(feedback)));
continue; // 继续下一轮推理
}
// ----- 保存最终答案到记忆并返回 -----
if (useMemory) {
chatMemory.add(conversationId, new AssistantMessage(aiText));
}
return aiText; // 任务完成,返回最终答案
}
// ===== 分支B:有工具调用,执行工具 =====
// 将模型的 ToolCall 信息添加到消息列表
messages.add(builder.toolCalls(chatResponse.chatResponse().getResult().getOutput().getToolCalls()).build());
// 遍历所有需要调用的工具
chatResponse.chatResponse()
.getResult()
.getOutput()
.getToolCalls()
.forEach(toolCall -> {
String toolName = toolCall.name(); // 工具名称
String argsJson = toolCall.arguments(); // 工具参数(JSON格式)
// 在注册的工具列表中查找对应的 ToolCallback
ToolCallback callback = findTool(toolName);
if (callback == null) {
// 工具未找到:注入错误响应信息,继续处理其他工具调用
addErrorToolResponse(messages, toolCall, "工具未找到:" + toolName);
return;
}
Object result;
try {
// 执行工具调用,传入 JSON 参数
result = callback.call(argsJson);
// 构建工具响应消息,包含工具调用的ID、名称和执行结果
// 系统会自动将此响应注入到上下文中供模型下一轮使用
ToolResponseMessage.ToolResponse tr = new ToolResponseMessage.ToolResponse(toolCall.id(), toolName, result.toString());
messages.add(ToolResponseMessage.builder().responses(List.of(tr)).build());
} catch (Exception ex) {
// 工具执行异常:注入错误信息,但不中断其他工具的执行
addErrorToolResponse(messages, toolCall, "工具执行失败:" + ex.getMessage());
}
});
// 循环回到 while(true) 继续下一轮推理
// 下一轮中,模型将看到"问题 → 历史推理 → 工具调用 → 工具响应",
// 从而基于观察到的结果继续思考和行动
}
}五、结束语
现阶段的 AI,从底层逻辑来看本质就是超大参数量的概率生成模型,它并不具备真正的自主意识、逻辑悟性与真实认知,所有输出都只是基于海量训练数据,按照概率分布推演拼接出最合理的文本与内容。
而我们人与 AI 之间的所有交互,核心载体其实全部都是提示词。提示词既是我们向 AI 下达指令、传递需求的唯一入口,也是引导 AI 理解意图、划定输出边界的核心桥梁。可以说,会不会写提示词、能不能精准把控提示逻辑,直接决定了 AI 输出内容的质量、准确度和实用性。
也正因 AI 是概率模型、交互依赖提示词的底层特性,如何精准约束、规范、控制 AI 的输出结果,就成了当下使用 AI、落地 AI 应用必须解决的核心问题。想要摆脱 AI 输出随意化、逻辑断层、偏离需求、幻觉编造等问题,就需要一套成熟可落地的框架思路,而ReAct 框架正是这一思路下非常优质的实践方案。它通过推理思考 + 行动反馈的循环模式,让 AI 不再单纯做概率式文本生成,而是学会分步拆解问题、实时校验信息、依据行动结果修正推理逻辑,从根本上提升了 AI 输出的逻辑性、真实性和可控性