EvoLM: In Search of Lost Language Model Training Dynamics
EvoLM EvoLM: 探寻遗失的语言模型训练动态

摘要
现代语言模型(LM)的训练已划分为多个阶段,这使得下游开发者难以评估每个阶段设计选择的影响。我们提出EvoLM,这一模型套件能够系统且透明地分析LM在预训练、持续预训练、监督微调及强化学习中的训练动态。我们从零开始训练了超过100个参数规模为1B和4B的LM,并评估了上游(语言建模)和下游(问题求解)能力,同时考虑了领域内与领域外泛化。关键见解包括:过度预训练与后训练的收益递减、领域特定持续预训练中缓解遗忘的重要性与实践、持续预训练在连接预训练与后训练阶段中的关键作用,以及在配置监督微调与强化学习时的多种复杂权衡。为促进开放研究与可复现性,我们发布了所有预训练与后训练模型、各阶段的训练数据集,以及完整的训练与评估流程。
1.引言
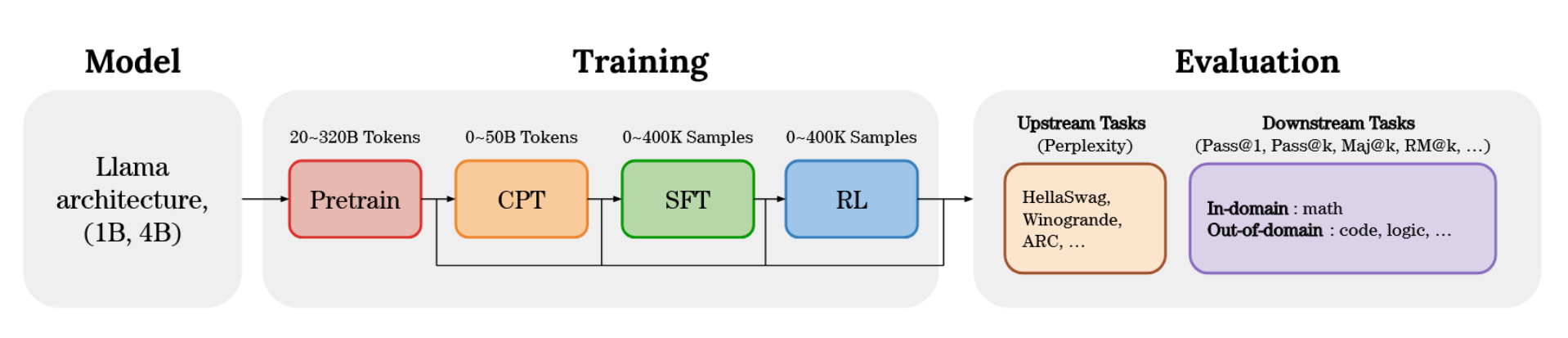
图1:EvoLM概览,一个用于研究语言模型训练动态的透明模型套件,涵盖预训练、持续预训练(CPT)、监督微调(SFT)和强化学习(RL)。该框架评估了在领域内(如数学)和领域外(如代码、逻辑)设置下的上游(语言建模)与下游(问题解决)性能,从而能够系统地分析设计权衡与扩展行为。
扩展语言模型规模已成为一种范式,能够支持多种下游应用8, 52, 32。理解规模扩展------并实现更高效的资源分配------的一种途径是通过缩放定律,该定律刻画了预训练对数损失与计算量之间的定量关系22, 27, 23, 21。部分由于开放权重模型17的设计空间广阔34以及预训练与后训练等多个训练阶段之间存在复杂交互13, 70,目前仍难以明确识别哪些决策能持续带来可靠的下游性能提升。
尽管在理解模型训练过程中的学习机制方面已取得进展59, 53, 43, 16, 66,但由于自回归生成模型中训练与推理的不匹配46以及下游性能改善的非平滑特性45,准确预测下游问题解决性能仍面临挑战。现有研究常依赖训练细节透明度有限的检查点,这可能引入潜在混淆因素,包括:(1) 依赖来自后训练研究的模糊分析,这些研究使用现成的基础模型,且通常未严格控制模型规模、预训练数据规模及数据组成等关键变量42, 10, 61;(2) 基于中间检查点的评估59, 51,由于学习率衰减不完整48, 24, 54, 67, 30,这些检查点可能具有次优的下游性能,从而使得公平比较复杂化。
在本工作中,我们利用开源工具包1, 71, 49和开源数据源38, 63, 55, 31构建了一条端到端的开发流水线,以系统且透明的方式研究语言模型在其生命周期(涵盖预训练、持续预训练、监督微调和强化学习阶段)中的推理能力。我们推出了EvoLM模型套件,包含100多个仅有解码器的自回归语言模型(参数规模为1B和4B),每个模型均从零开始训练,并在不同模型大小和数据集规模配置下完成了完整的学习率衰减。仅基于公开语料库FineWeb38进行预训练,我们的基础模型在纯英文语言建模任务上取得了与使用显著更多预训练算力的其他开源权重模型相竞争的性能(表4)。例如,我们的1B和4B模型(预训练于320B token)分别与TinyLlama-1B和Qwen1.5-4B性能相当,而后者使用了更多预训练数据(2T和3T token)。我们评估了域内数学推理与域外通用推理任务上的上游语言建模性能(以困惑度衡量)与下游实际问题解决能力(通过生成式评估表现衡量)。通过大量可控且透明的实验,我们的研究填补了理解语言模型训练动态中的若干关键空白,提供了对模型行为的洞见,并指出了近期文献中的开放研究方向。总之,我们的贡献包括:
• 对语言模型在其全生命周期(从预训练到强化学习后训练)中的能力进行系统性分析,并通过基于推理的上下游任务(上游完形填空任务与下游生成任务)评估其域内及跨域泛化能力。
• 开源100余个从头训练的1B和4B参数语言模型及其各阶段训练数据,助力研究社区基于我们的发现进一步探索。
• 开源一套全面、透明且可复现的训练流程与评估框架,推动关于规模定律、训练动态以及语言模型上下游能力评估的深入研究。
2.实验设置
2.1 训练设置
我们使用LLaMA-2 56架构初始化所有模型,参数规模分别为1B和4B。训练流程包含四个连续阶段:
• 预训练:在FineWeb-Edu 38上进行。依据Chinchilla缩放定律 23(建议每个模型参数约20个token的计算最优比例),我们在从最优20倍模型大小到320B token的预算范围内预训练模型,以研究轻度过训练(>1倍Chinchilla,≤16倍Chinchilla)和过度过训练(>16倍Chinchilla)对任务性能的影响。
• 持续预训练(CPT):在FineMath 2上进行,token预算范围为2B至42B。为缓解通用领域知识的灾难性遗忘,我们还引入了预训练数据重放策略 25, 41, 4, 62。
• 监督式微调(SFT):应用于从GSM8K 12和MATH 20扩充得到的问答对数据集,该数据集来自MetaMathQA 63、OpenMathInstruct2 55和NuminaMath 31的混合。我们使用模型正确性一致性 39过滤低质量提示,丢弃零模型间共识的样本。
• 强化学习(RL):使用近端策略优化(PPO)47进行,采用二元可验证奖励。RL阶段使用与SFT相同的数据源,但确保与SFT数据集无重叠。
我们使用紧凑的模型签名来表示每个模型在训练阶段的配置。例如,1B-160BT-8+42BT-100Kep1-100Kep16 表示具有以下设置的模型:
• 1B:拥有10亿参数的模型。
• 160BT:在来自FineWeb-Edu的1600亿个token上进行预训练。
• 8+42BT:使用80亿个回放的通用领域数据(FineWebEdu)和420亿个领域特定数据(FineMath)继续预训练。
• 100Kep1:在10万个样本上进行1个周期的监督微调。
• 100Kep16:在10万个样本上进行16个周期的强化学习微调。
对于所有配置,我们使用完整的学习率调度来训练模型,并仅将最终检查点作为研究对象。更多训练细节见附录B.2节。
2.2 评估协议
上游完形填空任务
这些任务通过下一词元预测评估模型的语言建模能力,无需对话能力。我们对预训练及持续预训练模型在以下数据集上进行评估,报告其跨数据集的平均零样本准确率:HellaSwag 65、Winogrande 44、PIQA 6、OBQA 36、ARC-Easy/Challenge 11。
下游生成任务
这些任务评估模型在生成式对话环境下的问题解决能力。我们在以下任务上测试了监督微调和强化学习微调后的模型:1)领域内任务(数学推理):GSM8K-Platinum 57(完整GSM8K 12测试集的修订版,旨在最小化标签噪声)和MATH 20。2)领域外任务:CRUXEval 19(代码推理)、BGQA 28(逻辑推理)、TabMWP 35(表格推理)和StrategyQA 18(常识推理)。我们以零样本方式评估模型,通过提示模型针对问题生成完整解决方案,并报告领域内和领域外任务的平均性能。更多评估细节(包括数据集描述、采样参数和标准误差)见B.3节。评估指标包括:
• 准确率:我们在四种提示方案下测量准确率:1)Pass@1:温度=0。生成单一确定性响应。若该响应正确,则标记问题为正确。2)Maj@16:温度=1。采样十六个响应,评估多数答案的正确性。3)RM@16:温度=1。采样十六个响应,评估其中ORM分数最高的响应的正确性。4)Pass@16:温度=1。采样十六个响应,若任一响应正确,则标记问题为已解决。对于所有设置,从模型输出中提取最终答案,并与真实解决方案比较以确定正确性。我们还额外报告正确率:在至少有一个正确解的响应组中,计算正确解数量与总解数量(16)的比值。
• ORM分数:我们使用一个结果奖励模型------Skywork-Reward-Llama-3.1-8B-v0.2 33------根据输入问题和响应,为生成的解决方案分配标量分数。该指标用作解决方案质量的代理。
3.跨三个训练阶段的规模研究
3.1 扩展预训练计算
为了量化预训练计算总量的变化如何影响语言建模性能,我们在从100亿到3200亿token的预算范围内,分别预训练了0.5B、1B和4B参数的模型。如图2所示,上游任务的性能随着预训练token的增加而稳步提升,但当token数量达到模型大小的约80倍至160倍后,收益迅速递减。例如,1B模型的平均准确率从200亿token时的约46%提升至800亿token时的52%,而从800亿token增至1600亿token时,准确率提升已不足一个百分点。更大的4B模型虽在更长时间内保持小幅提升,但到3200亿token时也趋于平稳。
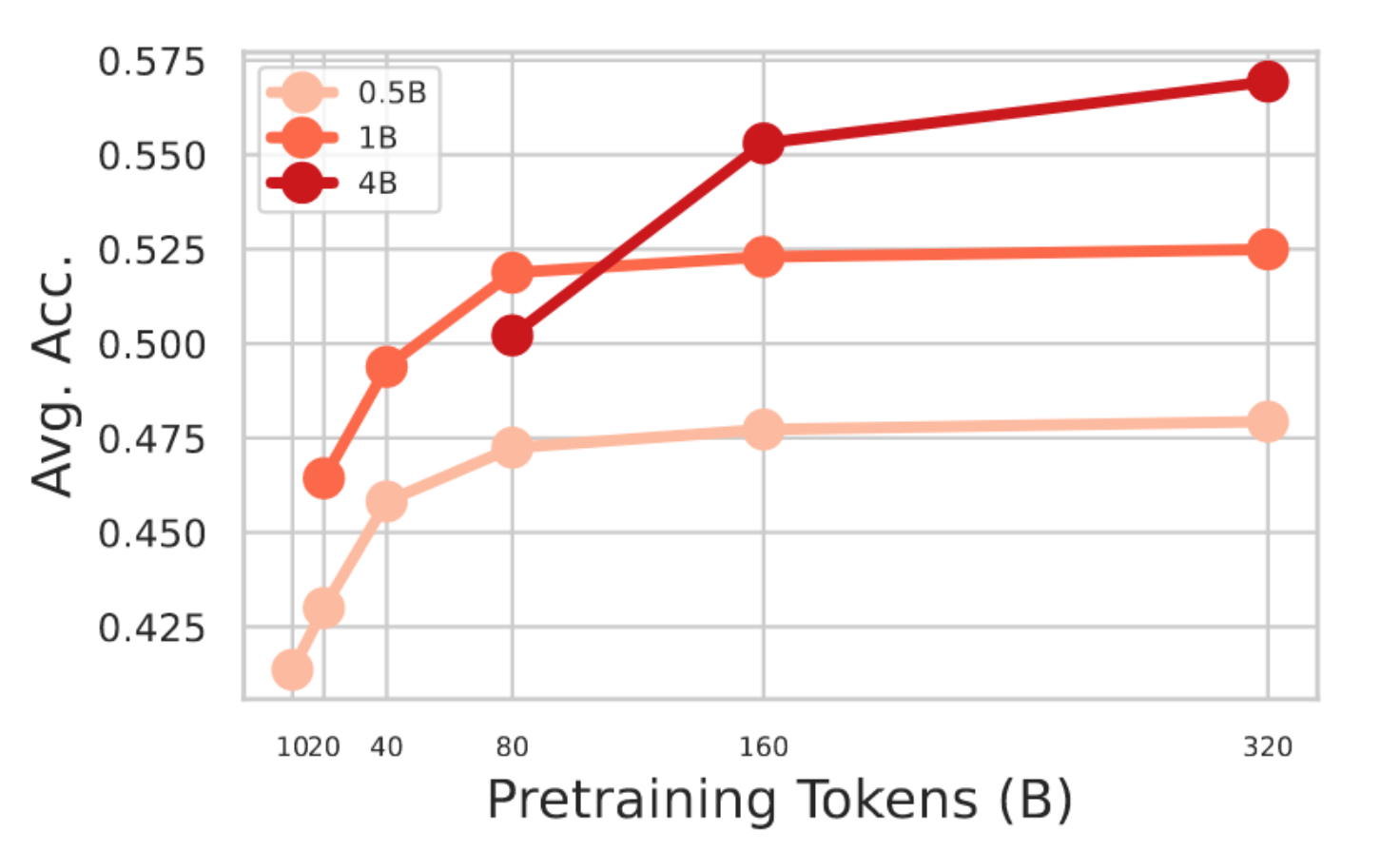
图2:上游任务性能与预训练令牌在模型{0.5B, 1B, 4B}和预训练令牌{10BT, 20BT, 40BT, 80BT, 160BT, 320BT}上的对比。
我们进一步评估了这些预训练预算如何转化为SFT和SFT+RL模型的下游能力。图3展示了1B模型在20BT到320BT预训练预算下,针对ID和OOD下游任务的所有六项指标。SFT和SFT+RL变体在80BT之前均表现出强劲的初始增益,但此后性能趋于饱和:例如,SFT模型的ID Maj@16准确率从20BT时的8%急剧上升至80BT时的15%,但在320BT时仅缓慢攀升至17%。RL相较于纯SFT带来了一致的提升,但同样在80BT之后,过度训练带来的收益微乎其微。此外,OOD任务上的Maj@16、RM@16和Pass@16准确率在160BT预算后出现下降,这种退化也因ORM分数的下降而加剧,表明整体生成质量在一定程度上降低。这些模式表明,过大的预训练预算也会导致下游性能的边际收益递减,甚至可能引发退化。这一发现与先前工作51一致,该工作指出,扩展预训练并不总能改善甚至可能损害SFT后语言模型的性能,而我们通过以下两点进一步完善了研究:1)这种性能增益停滞现象同样体现在下游生成式推理任务中;2)RL微调同样受到过度训练的限制。
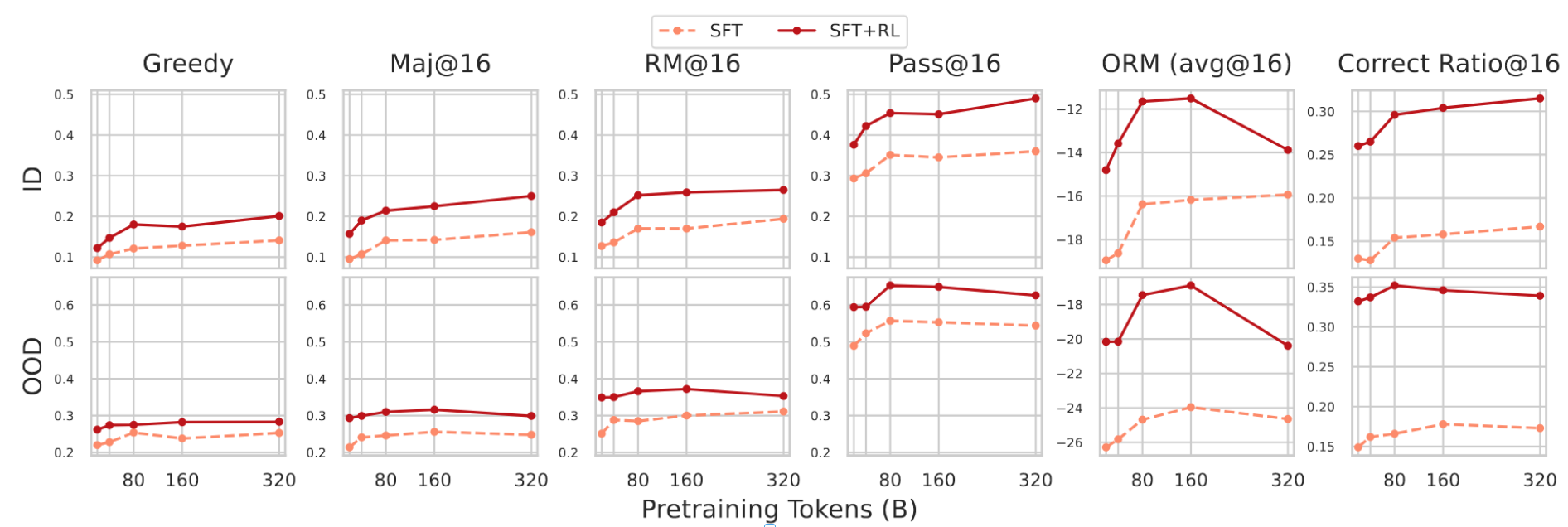
图3:下游任务性能与模型预训练令牌数量的关系:- SFT: 1B-{20BT, 40BT, 80BT, 160BT, 320BT}-8+42BT-100Kep1 - SFT+RL: 1B-{20BT, 40BT, 80BT, 160BT, 320BT}-8+42BT-100Kep1-100Kep8
要点1:过度的通用领域预训练并不总是能提升领域特定的后训练,甚至可能导致某些下游任务的性能下降(在我们的研究中,饱和发生在模型大小的80倍到160倍左右)。
我们进一步探究模型规模与预训练规模扩展之间的相互影响。如表1所示,在固定预训练计算预算(1B--320BT vs. 4B--80BT)下,较小的1B模型在SFT和SFT+RL两种设置中均优于4B模型。当匹配预训练token数量时,在较低预算下也观察到相同趋势:在80B token下,1B--80BT与4B--80BT模型表现相当,且较小模型略占优势。然而,当预算提升至160B token时,4B--160BT模型"解锁"了其规模优势:例如,4B SFT模型的ID Maj@16突增至26.4%(而1B对应模型仅为14.2%),4B SFT+RL模型则跃升至34.8%(1B对应模型为22.5%),这表明只有在达到预训练饱和阶段后,模型规模才能转化为训练后性能的显著提升。
要点2:在有限的预训练预算下,较小的后训练模型甚至能超越更大的模型。相反,一旦预训练令牌达到饱和状态,增加模型规模能够显著提升领域内性能和分布外泛化能力。
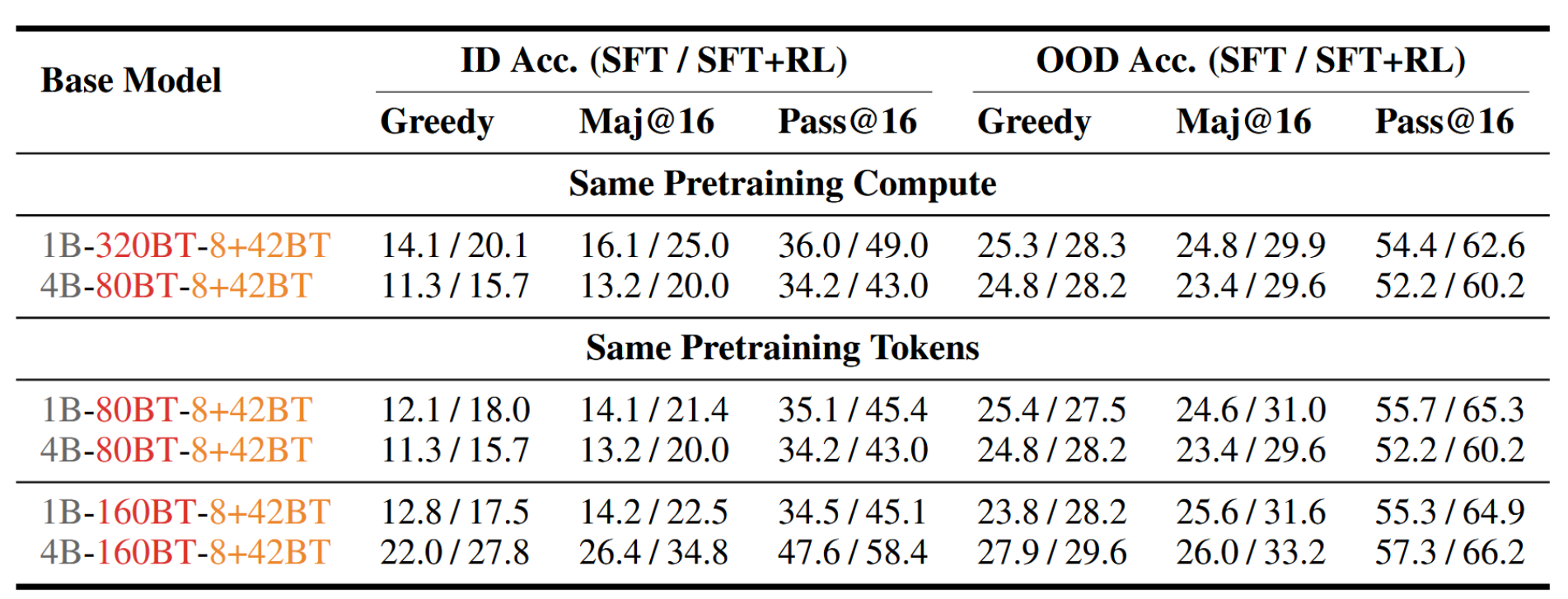
表1:固定预训练计算/令牌下1B与4B SFT/SFT+RL模型比较
3.2 扩大持续预训练计算
我们研究了持续预训练(CPT)计算量的影响,通过将总CPT token数从0(无CPT)变化到50 BT,以1B160BT预训练模型为基础。如图4所示,增加CPT计算量会逐渐降低上游任务性能,这表明存在灾难性遗忘15。为缓解这一问题,我们采用了一种简单的"回放"策略25,在CPT过程中随机穿插少量预训练数据。图4显示,在所有CPT预算下,采用8 BT回放的模型始终比无回放基线保持更高的上游准确率。随后,我们在CPT模型上对10万条样本进行一个epoch的SFT,以研究回放对下游性能的影响。表2报告了每种CPT混合配置在GSM8K-Platinum上的Pass@1准确率。纯FineMath CPT(50 BT)达到19.27%,而将8 BT FineWeb回放与42 BT FineMath token混合后,结果甚至更优,达到21.01%。回放量过少(1.6+48.4 BT)或过多(16+34 BT)的配置表现较差,这突显了适度的回放预算(约5%)能最优地平衡通用领域知识的保留与对下游生成任务的适应。
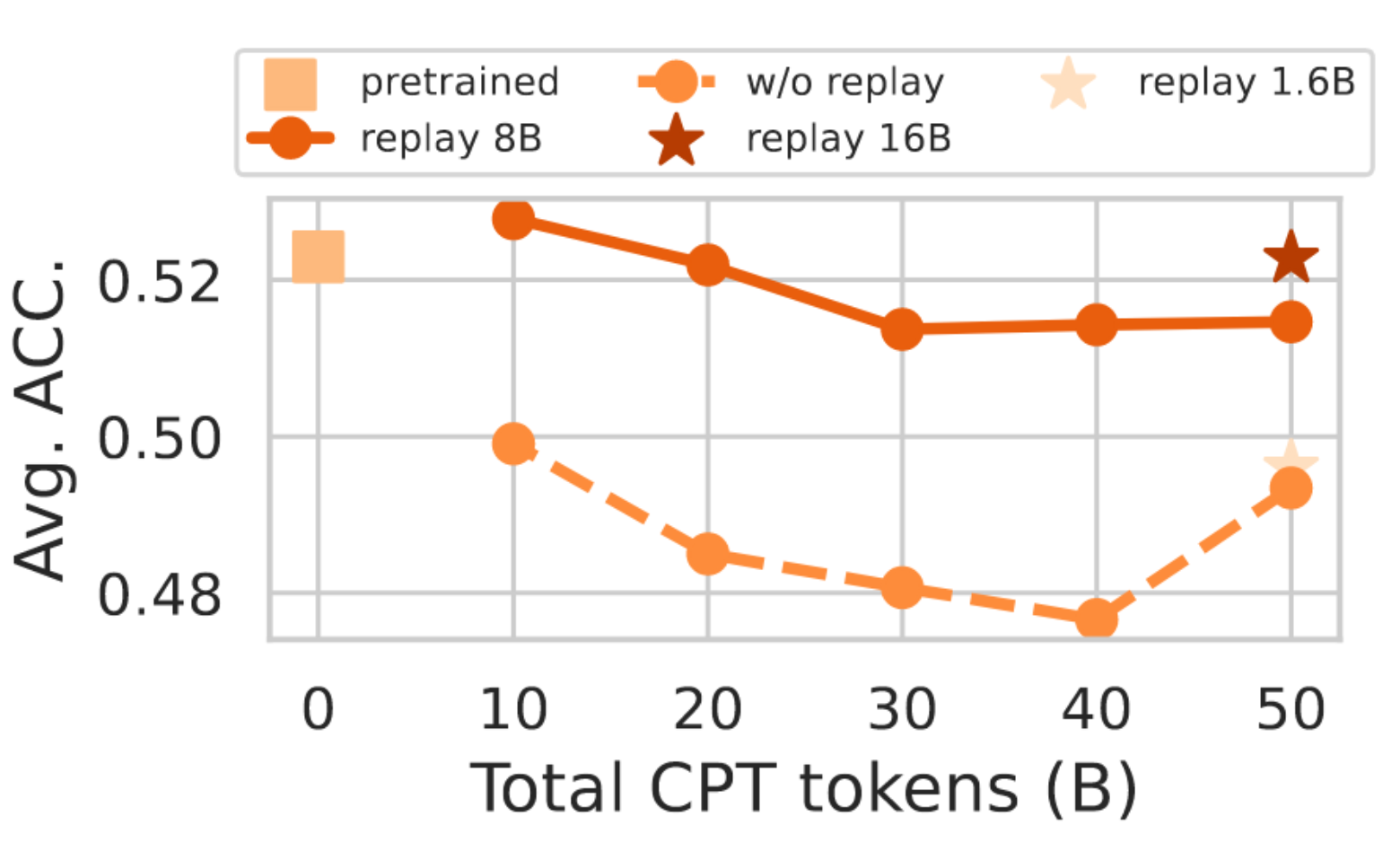
图4:上游任务性能与模型上的CPT令牌数对比:
- 预训练:1B-160BT,
- CPT:1B-160BT-8+{2BT, ..., 42BT},
- CPT:1B-160BT-0+{10BT, ..., 50BT},
- CPT:1B-160BT-{1.6+48.4BT, 16+34BT}。
要点3. 对领域特定数据进行CPT会导致预训练知识的灾难性遗忘,这可能损害上游和下游的性能,而加入少量回放预算(例如5%)可以有效缓解这种退化。
在图5中,我们绘制了SFT和SFT+RL模型的下游性能随CPT预算变化的情况(固定8 BT的重放预算)。所有变体随着领域特定token的增加而稳步提升,大约在32 BT时达到峰值,随后在42 BT时趋于平稳。例如,SFT模型的ID贪婪准确率从2 BT时的约5%上升至32 BT时的12%,之后趋于稳定。这种趋势在OOD指标中同样可见。在整个CPT范围内,RL微调始终优于纯SFT;值得注意的是,在没有CPT的情况下,RL甚至可能比SFT表现更差(如Maj@16、RM@16和Pass@16所示),但随着CPT token的增加,RL带来的增益趋于增强。
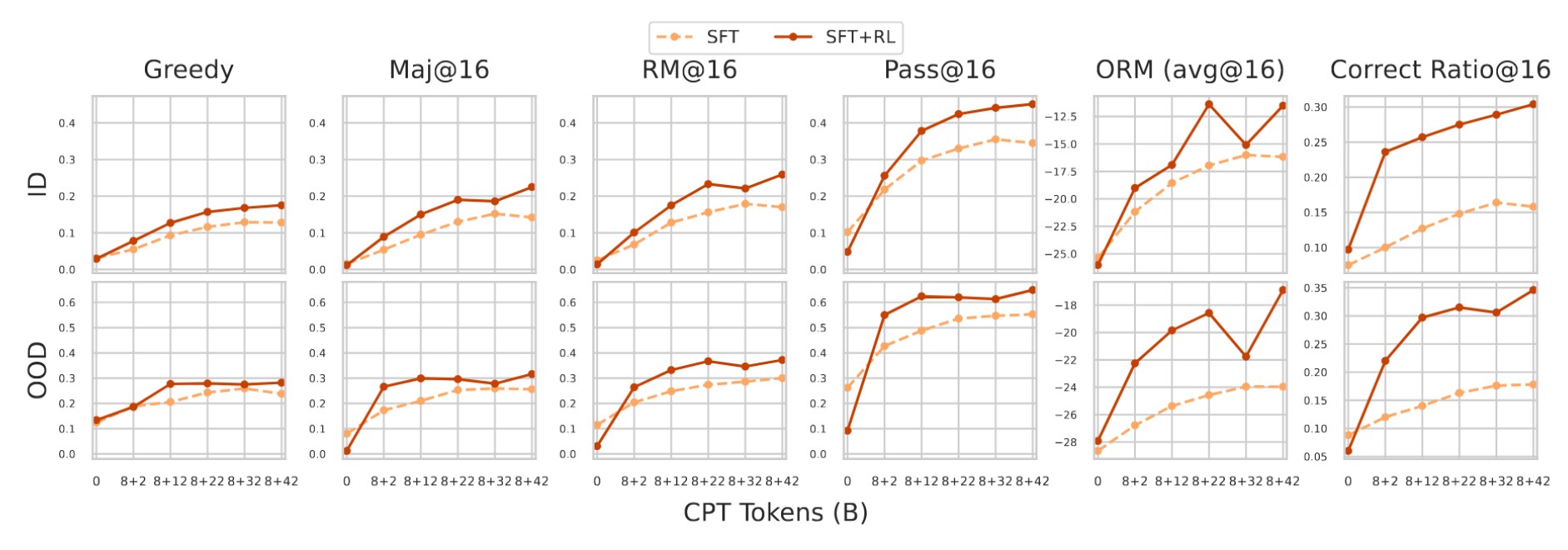
图5:在下游任务性能与持续预训练令牌数上的模型对比:
- SFT:1B-160BT-100Kep1,1B-160BT-8+{2BT, ..., 42BT}-100Kep1
- SFT+RL:1B-160BT-100Kep1-100Kep8,1B-160BT-8+{2BT, ..., 42BT}-100Kep1-100Kep8
要点4:领域特定的后训练应当由充足的领域特定CPT数据支持;否则,SFT性能仍会欠佳,而RL甚至可能进一步降低该性能。
要点5. 随着领域特定的CPT数据增加,领域内下游任务性能稳步提升,并且SFT模型能从RL微调中受益更多。
要点6. 拥有足够的领域特定CPT数据时,针对域内任务的后训练不仅提升了域内性能,还能有效泛化到域外任务。
3.3 扩展SFT计算
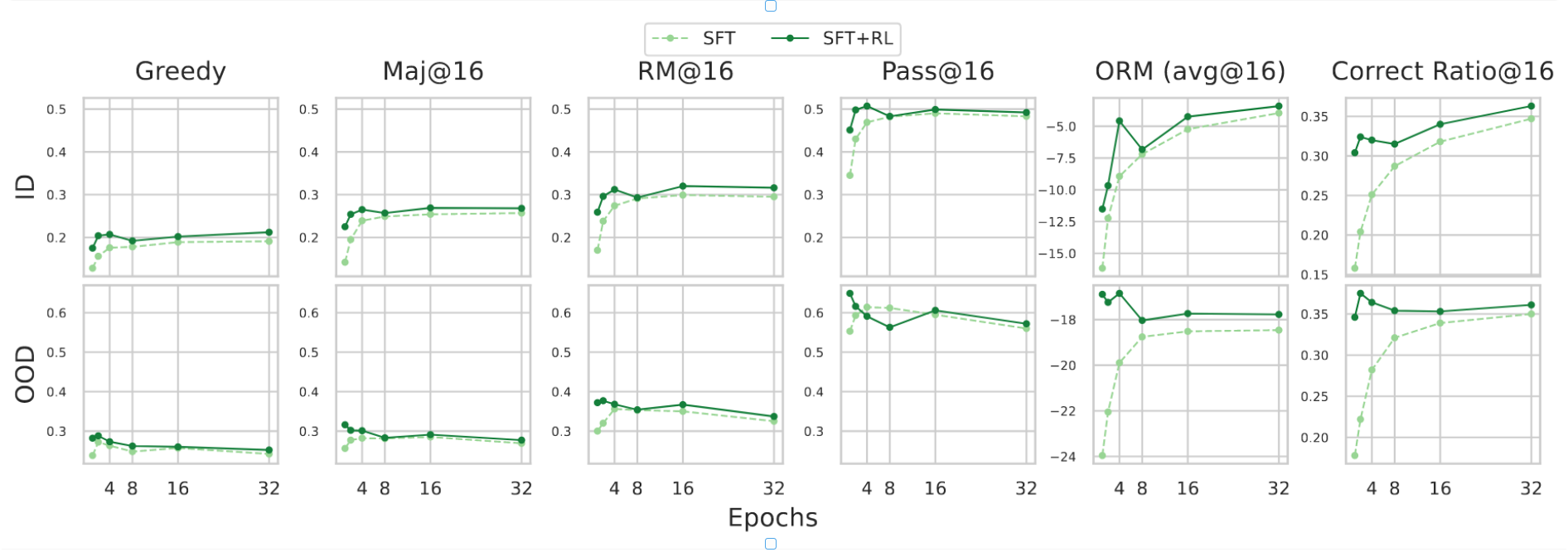
图6:下游任务性能与模型SFT轮数的关系:- SFT:1B-160BT-8+42BT-100Kep{1,2,4,8,16,32} - SFT+RL:1B-160BT-8+42BT-100Kep{1,2,4,8,16,32}-100Kep8。
为了评估下游性能如何响应增加的SFT计算量,我们以1B-160BT-8+42BT作为基础模型,进行了两项互补研究。
不同的SFT训练轮数。将SFT样例固定为10万条,我们对基础模型分别进行了{1, 2, 4, 8, 16, 32}个轮次的微调。如图6所示,域内指标随着轮数增加稳步提升,并在约8轮时趋于饱和,反映出模型对域内问题求解的 memorize 程度加深。相比之下,域外性能在2--4轮时达到峰值后开始下降,表明过度专门化会阻碍泛化。这些发现也验证了通常选择的约3轮SFT超参数。此外,下游RL微调带来的边际收益在过度训练的SFT模型上有所缩减:一旦模型过度 memorize 了监督数据,RL可改进的空间就非常有限。
不同大小的SFT数据集。正如先前研究42所提出的,下游任务的后训练性能与SFT数据集大小呈幂律关系,但该结论基于最多10K样本的实验。我们进一步扩展了这一预算,将SFT样本数量从50K变化至400K,同时将训练轮数固定为1以减少记忆效应。如图7所示,领域内性能随样本增加单调提升,证实了额外的SFT计算能持续改善域内任务表现。然而,领域外指标出现波动,甚至在更大数据集下有所下降。与增加训练轮数类似,随着模型学习更多SFT样本,RL带来的增量收益逐渐减小。
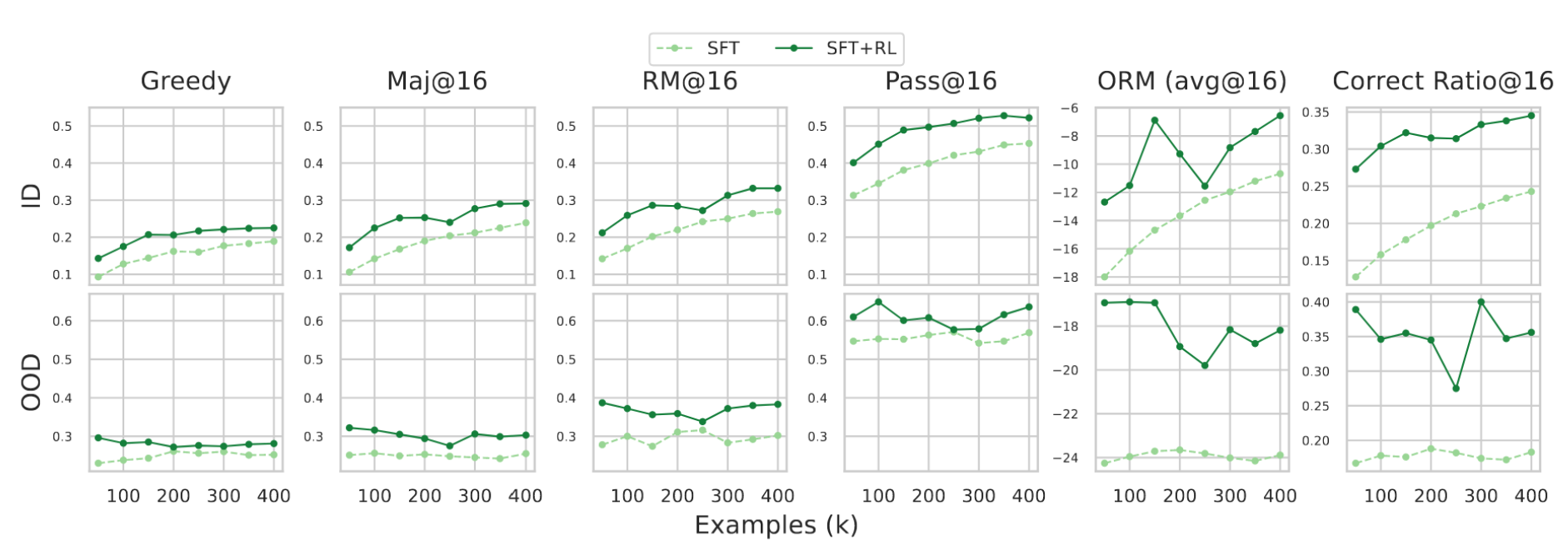
图7:下游任务性能与模型SFT样本数量的关系:- SFT: 1B-160BT-8+42BT-{50K, 100K, 150K, ..., 400K}ep1 - SFT+RL: 1B-160BT-8+42BT-{50K, 100K, 150K, ..., 400K}ep1-100Kep8。
要点7. 过度的SFT能以收益递减的方式提升ID性能,但不一定能提升OOD性能,甚至可能降低OOD性能。
要点8. 过度的SFT,尤其是过大的轮次,可能会限制RL的进一步改进。
3.4 扩展强化学习计算
同样地,为了评估下游性能如何响应强化学习计算的增加,我们还基于1B-160BT-8+42BT-100Kep1基础模型,调整训练轮数或数据集大小。此外,我们引入0轮次/样本作为SFT基线。更多关于强化学习的实验结果与发现详见附录A.2。
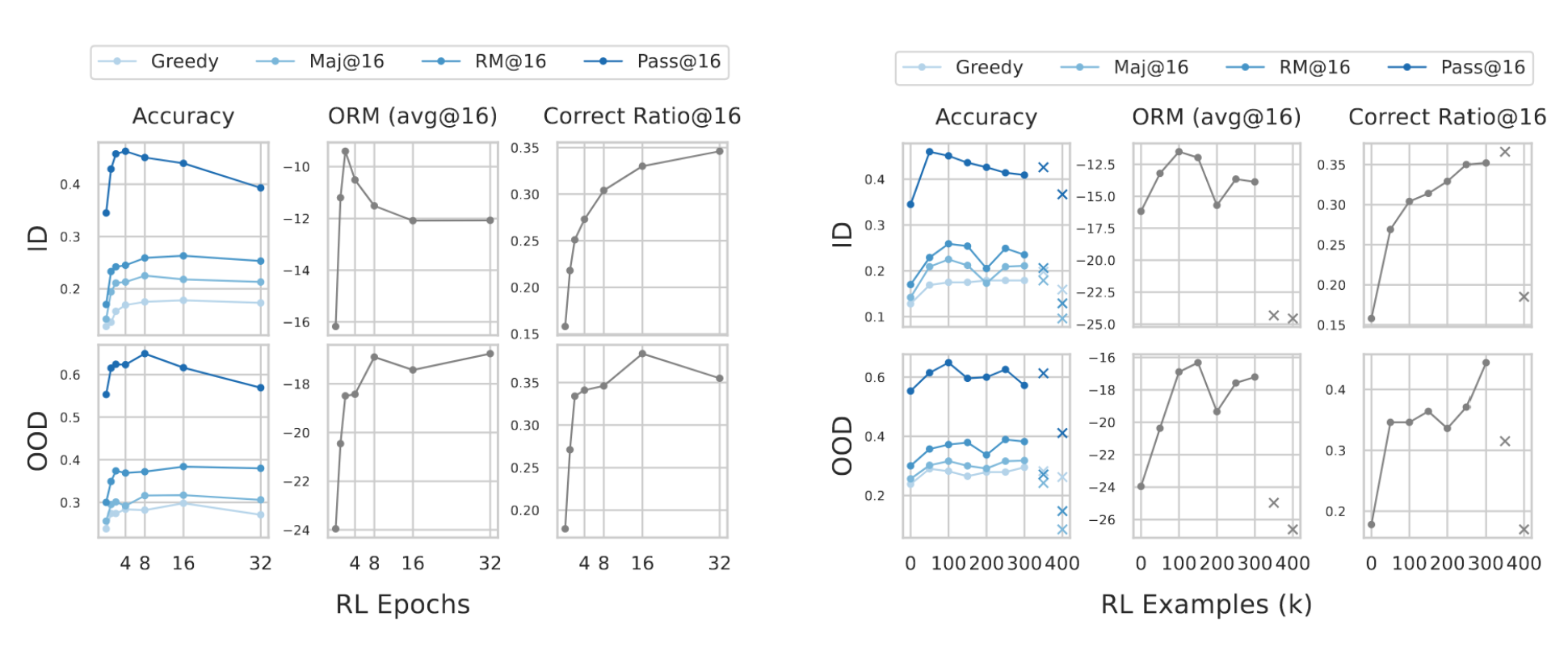
(a) 性能与强化学习轮次数量的关系,针对模型1B-160BT-8+42BT-100Kep1-100Kep{0, 1, 2, 4, 8, 16, 32}。
(b) 性能 vs. 强化学习示例数量,针对模型 1B-160BT-8+42BT-100Kep1-{0, 50K, 100K, 150K, ..., 400K}ep1。
图8:不同RL尺度下的下游任务性能。
不同RL轮次。我们在与SFT数据集无交集的另外10万条样本上,对{0,1,2,4,8,16,32}轮次应用强化学习。如图8a所示,对于ID和OOD任务,greedy、Maj@16和RM@16的准确率在约8--16轮次达到峰值,之后趋于饱和。我们还注意到,虽然正确率持续上升,但Pass@16的准确率在超过4轮次后大幅下降,这表明强化学习主要增强了已有正确输出的置信度,而非有效扩展可解样本集。这一点也反映在表1的结果中:对于1B和4B的SFT模型,Maj@16的准确率有时会低于greedy准确率,表明低质量解占据了多数。然而,在对SFT模型进行强化学习后,所有Maj@16的准确率均高于greedy准确率。
不同RL数据集规模。在固定训练轮次为8的情况下,我们将RL数据集规模从0变化到400K个样本。图8b显示,对于ID和OOD指标,贪婪解码、Maj@16和RM@16的准确率随着数据量增加而持续提升,直至约150--200K样本后增益趋于平缓并出现波动。相比之下,Pass@K的饱和点更早出现并开始下降,而正确比例持续上升,这与扩展RL训练轮次时的发现类似。这一结果与同期工作64的观察一致,该工作同样得出结论:RL主要增强了已有正确输出的置信度,而非提升语言模型的基本推理能力。我们通过进一步阐述RL训练轮次和数据集规模的精确权衡,扩展了这一见解。此外,我们注意到在350K和400K样本处性能急剧下降,训练结果显示,在最后的RL步骤中,两个模型学会大幅增加响应长度,其生成内容经常超出预定义的上下文窗口长度,从而导致性能下降。然而,过大训练轮次的RL更为稳定,并未观察到这种由响应长度扩展导致的崩溃现象。
要点9. 使用过多轮次或样本的RL会提升下游ID和OOD任务的性能,但存在收益递减(在我们的研究中,饱和发生在4-8个轮次或50-100K个样本时)。
关键要点10. 超出饱和区间后,强化学习主要提升高质量采样轨迹的概率,但未必能改进模型的基础推理能力。
为了进一步研究在数据受限场景下如何配置SFT和RL数据分配,我们从整个500K数据集中子采样了100K个样本,评估了五种SFT/RL分割比例:(10/90、30/70、50/50、70/30、90/10)K,并对每种分割分别进行4个epoch的SFT或RL训练。选择100K是因为该规模接近ID和OOD性能的饱和区域(图8b)。如图9所示,ID准确率(贪心搜索和Pass@16)随SFT数据比例增加而上升,在约70K后趋于平稳,而OOD指标则由RL分配驱动,在10K SFT(即90K RL)时达到峰值。这些趋势在1B和4B模型中均保持一致。
要点11. 在受限的下游数据预算下,将更多样本分配给SFT可以最大化域内收益,但会牺牲较弱的OOD泛化能力,而将更多样本分配给RL则能提升OOD性能。
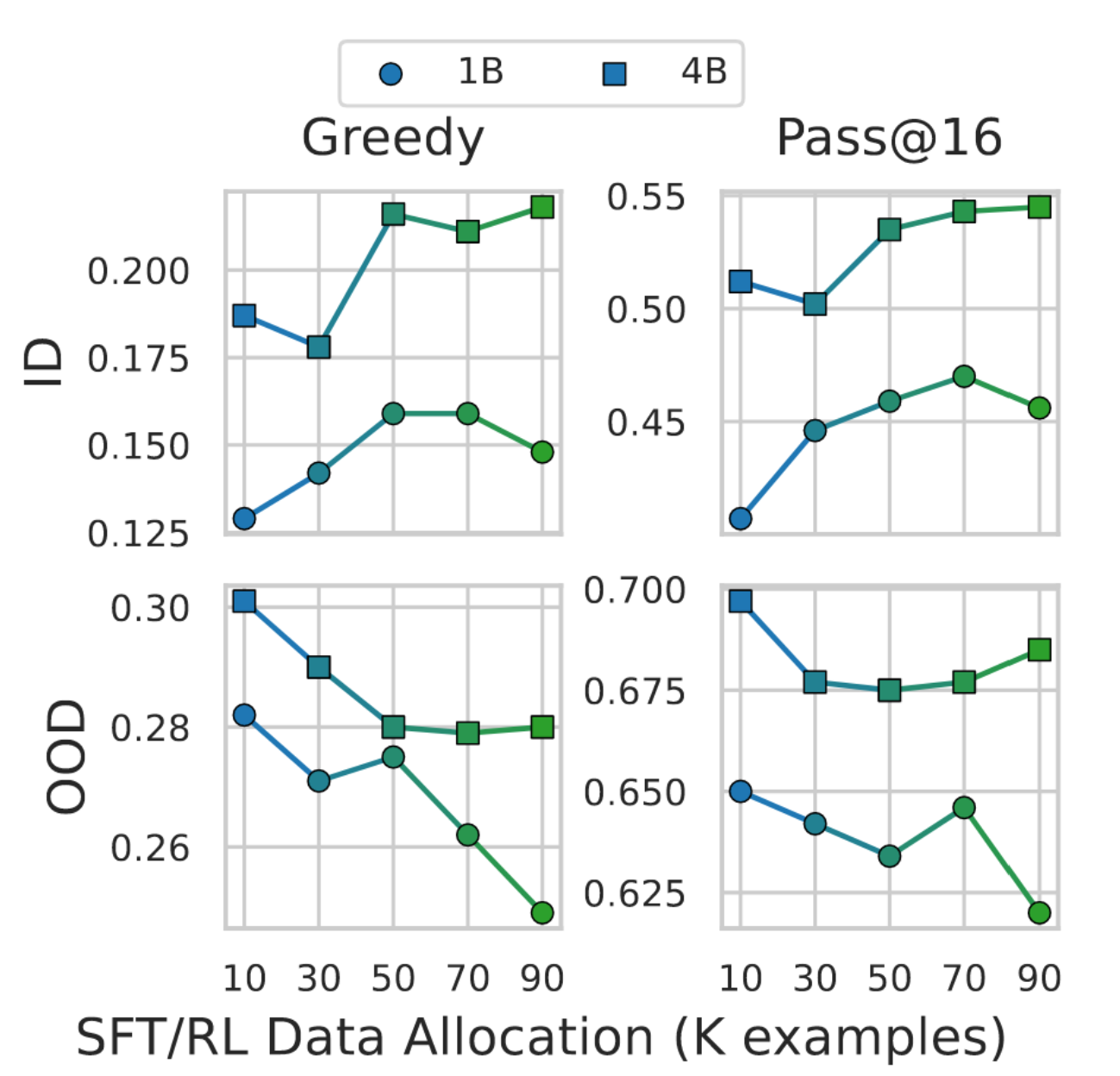
图9:{1B, 4B}-160BT-8+42BT-{10K, ..., 90K}ep4-{90K, ..., 10K}ep4的下游任务性能。深绿色/蓝色表示将更多数据分配给SFT/RL。后训练样本总数固定为100K。
要点11. 在受限的下游数据预算下,将更多样本分配给SFT可以最大化域内收益,但会牺牲较弱的OOD泛化能力,而将更多样本分配给RL则能提升OOD性能。
4.补充研究与讨论
考虑到我们发现后训练与预训练之间存在非平凡的交互作用------这需要复杂的训练方案------那么下游性能是否以平滑或可预测的方式扩展?本节提供了一个例子,说明为何我们的全面研究对于充分理解训练动态如何塑造语言模型的下游性能至关重要,并给出了另一个例子,其中某个指标可能与下游问题解决性能相关。
4.1 中间检查点可能并非可靠的替代指标
实际上,从业者通常会按照完整的学习率调度训练每个目标模型,并耗尽所有可用的预训练数据,而不是将中间检查点作为最终模型。为了模拟从零开始训练模型处理200亿或400亿token的真实工作流程,我们将这些独立运行的结果与从更长的1600亿token预训练运行中提取的、对应相同token数量(200亿和400亿)的检查点进行了比较。在每个模型处理了200亿或400亿token后,我们进一步对其应用单轮次基于10万条示例的监督微调(SFT),以赋予基本的对话基础能力,并在MATH数据集的两个最简单子集上评估模型。
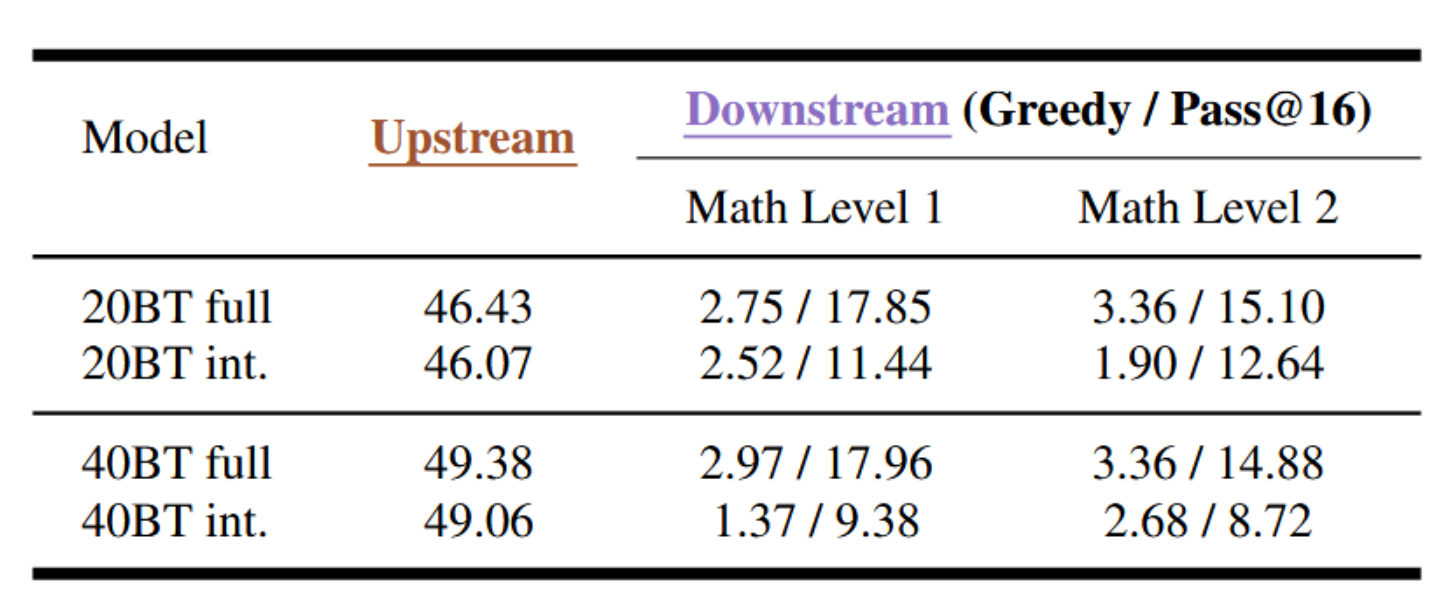
表3:不同预训练配置下上游任务和MATH(1级和2级)的性能表现。"xBT full"表示在x BT数据上进行完整的预训练运行,而"xBT int."表示在训练至1600亿个token的过程中所取的中间检查点,对应已处理x BT数据。
如表3所示,中间检查点在上游任务准确率和数学推理性能上始终落后于其专用的20B和40B对应模型。这一差距的产生,是因为在早停点(在学习率衰减和数据重复之前捕获)省略了较小规模运行所完成的完整优化轨迹。换言之,仅从较长的训练计划中截取一个40B标记的检查点,并不能重现专门训练40B标记模型所带来的益处。
这些结果提醒我们,不应将此类中间检查点用作研究和理解完全训练的小型模型的替代物。在解读训练动态时,关键在于对具有完整训练计划的同类运行进行比较,而非依赖那些低估了模型真实能力的训练中途快照。
4.2 将下游任务性能与ORM分数相关联
尽管不同领域的困惑度有时表现出强相关性,但下游任务准确率可能并非始终相关,这主要是因为后训练模型校准不充分,因此较低的验证困惑度并不一定意味着更好的生成性能。在我们的实验中,我们发现ORM分数与下游任务准确率之间存在清晰的相关关系。图10展示了从基础模型1B-160BT-8+42BT出发的所有后训练模型变体的ORM分数(avg@16)与Maj@16准确率,并发现ORM分数始终表现出强大的预测能力,这体现在ID和OOD任务中约0.62至0.84的高相关系数上。虽然我们观察到StrategyQA的相关性较低,但这可能源于:1) StrategyQA更强调常识知识而非显式推理;或2) 所使用的奖励模型不太适合该数据集的特定问题分布。

图10:不同任务中准确率与ORM分数之间的相关性。每个子图代表一个数据集,其中每个点对应一个模型变体。虚线表示线性趋势,每个标题中报告了皮尔逊相关系数。
ORM分数与下游准确性之间的非平凡相关性表明,大型ORM生成的分数可作为后训练阶段评估生成质量的可靠无监督代理指标。例如,在收集足够高质量测试样本具有挑战性的数据受限场景中,ORM分数尤为有用。当直接测试不可行时(例如,最终答案本身难以自动提取和验证的任务),ORM评分也具有优势。此外,ORM的泛化能力使从业者能够将其在现有推理任务上训练,并应用于其他数据受限的推理任务。在此类情况下,ORM分数能够在不依赖大量标注评估数据集的前提下,实现对模型的有效验证和迭代优化。
Takeaway 12. 与验证损失相比,ORM分数可能是一种更可靠的无监督验证指标,有助于在训练后预测下游任务性能。值得注意的是,来自8B奖励模型的ORM分数与1B模型在许多下游推理任务上的问题解决准确性具有良好相关性。
5.相关工作
探究语言模型在不同训练阶段的表现。近期研究探讨了不同训练阶段如何塑造语言模型的下游能力。最新研究16的观察表明,经过大量预训练的语言模型在下游任务上具有可靠的扩展性,但其结论主要基于通过top-1误差评估的预训练模型,对于经过额外后训练的模型则留下未解问题。与此相对,最新工作51提出了"灾难性过度训练":超过特定节点的长时间预训练实际上会损害下游微调效果,表现为增加对参数更新的敏感性并加剧遗忘。此外,研究人员66推导出用于微调的乘法联合缩放定律,表明性能提升更多依赖于模型规模的扩展而非预训练数据量,而最优方法则关键取决于任务与数据的具体情境。
预训练驱动后训练。语言模型后训练近期取得的成功引发了关于后训练如何受预训练影响的研究。近期研究26通过对观测数据进行因果推断,发现通用上游能力与基础模型FLOPs高度相关,进而影响数学推理等专项能力。也有研究者通过基于强化学习的后训练证明,RL微调放大了预训练模式,驱使模型趋向于表现出具有规模相关偏差和跨任务泛化能力的优势输出分布,尤其在数学推理任务中70。为强化这些发现,部分学者审慎审视了"RL本质上能提升超越预训练基线的推理能力"这一假设,得出结论认为RL主要增强的是生成高质量解决方案的置信度与概率,而非从根本上改进推理能力64。
语言模型缩放定律。早期的缩放研究工作23, 27建立了训练损失与模型规模、数据量及计算量之间的基本关系。近期研究从多个维度拓展了这一框架。双轴缩放定律即使在远超传统最优计算点的过度训练场景中,也能可靠预测损失值16。此外,新的定量模型通过显式损失阈值或定向微调探测,预测模型准确率中的涌现行为50, 14。跨分布迁移性也被建模,使得基于最小试点数据在不同数据集之间实现损失曲线的准确外推成为可能7。进一步的改进聚焦于数据受限场景:当独特训练数据稀缺时,推导出最优轮次分配策略37;同时揭示了合成数据的类似缩放模式,并明确了其收益递减规律40。此外,缩放定律现已涵盖持续预训练动态,可指导领域特定数据与通用数据的混合,并量化领域适应过程中使用回放数据时的遗忘效应41。最后,关于计算分配的研究针对蒸馏技术建立了专用缩放关系,精确判定蒸馏方法何时能够超越直接预训练的效率9。
后训练提升推理能力。近期研究探讨了后训练策略对大型语言模型推理能力的影响。一项研究挑战了"表面对齐假说"72,表明监督微调(SFT)后训练的性能会随微调样本数量扩展,这与预训练的缩放定律类似42。此外,强化学习(RL)后训练已被证明能够放大预训练阶段习得的行为,尤其在需要高级数学推理和编码的任务中70。一项比较研究表明,SFT倾向于记忆训练数据,而RL则能促进更好的泛化能力10。针对推理机制的研究揭示了通过RL学习到的长思维链,识别出使生成扩展推理轨迹成为可能的因素61。相反,一项批判性研究质疑RL是否真正激励了超出预训练已学习范畴的推理能力,暗示RL可能并未引发本质上的新推理模式64。
6 结论
在这项工作中,我们系统研究了训练数据量、模型规模等因素如何影响语言模型的上游与下游性能。研究揭示了扩展规律、过度训练的边际收益递减现象,以及谨慎管理领域特定持续预训练以防止遗忘的重要性。此外,我们强调了ORM分数作为下游任务性能可靠指标的作用。
我们承认本研究存在若干局限性。首先,我们仅对参数规模达40亿的模型进行了定性分析。未来研究应探究所观察到的趋势是否适用于更大规模模型,并寻找更优的超参数。其次,我们聚焦于以推理为中心的后训练目标,未探讨安全对齐、指令遵循、工具调用及编码任务等目标的动态机制。最后,我们的强化学习实验仅采用基于可验证奖励的近端策略优化(PPO)。探索其他强化学习方法可为下游能力的影响提供更广泛的见解。
总体而言,我们倡导开源研究以提升透明度,通过社区协作更好地理解、控制并负责任地管理机器学习模型。
引用文献
- 1 L. AI. Litgpt. https://github.com/Lightning-AI/litgpt, 2023. 2
- 2 L. B. Allal, A. Lozhkov, E. Bakouch, G. M. Blázquez, G. Penedo, L. Tunstall, A. Marafioti, H. Kydlíˇcek, A. P. Lajarín, V. Srivastav, J. Lochner, C. Fahlgren, X.-S. Nguyen, C. Fourrier, B. Burtenshaw, H. Larcher, H. Zhao, C. Zakka, M. Morlon, C. Raffel, L. von Werra, and T. Wolf. Smollm2: When smol goes big -- data-centric training of a small language model, 2025. 2
- 3 J. Bai, S. Bai, Y. Chu, Z. Cui, K. Dang, X. Deng, Y. Fan, W. Ge, Y. Han, F. Huang, et al. Qwen technical report. arXiv preprint arXiv:2309.16609, 2023. 18
- 4 L. Bethune, D. Grangier, D. Busbridge, E. Gualdoni, M. Cuturi, and P. Ablin. Scaling laws for forgetting during finetuning with pretraining data injection. arXiv preprint arXiv:2502.06042, 2025. 2
- 5 S. Biderman, H. Schoelkopf, Q. G. Anthony, H. Bradley, K. O'Brien, E. Hallahan, M. A. Khan, S. Purohit, U. S. Prashanth, E. Raff, et al. Pythia: A suite for analyzing large language models across training and scaling. In International Conference on Machine Learning, pages 2397--2430. PMLR, 2023. 18
- 6 Y. Bisk, R. Zellers, R. L. Bras, J. Gao, and Y. Choi. Piqa: Reasoning about physical commonsense in natural language. In Thirty-Fourth AAAI Conference on Artificial Intelligence, 2020. 3
- 7 D. Brandfonbrener, N. Anand, N. Vyas, E. Malach, and S. Kakade. Loss-to-loss prediction: Scaling laws for all datasets. arXiv preprint arXiv:2411.12925, 2024. 10
- 8 T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877--1901, 2020. 1
- 9 D. Busbridge, A. Shidani, F. Weers, J. Ramapuram, E. Littwin, and R. Webb. Distillation scaling laws. arXiv preprint arXiv:2502.08606, 2025. 10
- 10 T. Chu, Y. Zhai, J. Yang, S. Tong, S. Xie, D. Schuurmans, Q. V. Le, S. Levine, and Y. Ma. Sft memorizes, rl generalizes: A comparative study of foundation model post-training. arXiv preprint arXiv:2501.17161, 2025. 2, 10
- 11 P. Clark, I. Cowhey, O. Etzioni, T. Khot, A. Sabharwal, C. Schoenick, and O. Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge. ArXiv, abs/1803.05457, 2018. 3
- 12 K. Cobbe, V. Kosaraju, M. Bavarian, M. Chen, H. Jun, L. Kaiser, M. Plappert, J. Tworek, J. Hilton, R. Nakano, et al. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021. 2, 3, 21
- 13 R. Dominguez-Olmedo, F. E. Dorner, and M. Hardt. Training on the test task confounds evaluation and emergence. arXiv preprint arXiv:2407.07890, 2024. 1
- 14 Z. Du, A. Zeng, Y. Dong, and J. Tang. Understanding emergent abilities of language models from the loss perspective. arXiv preprint arXiv:2403.15796, 2024. 10
- 15 R. M. French. Catastrophic forgetting in connectionist networks. Trends in cognitive sciences, 3(4):128--135, 1999. 5
- 16 S. Y. Gadre, G. Smyrnis, V. Shankar, S. Gururangan, M. Wortsman, R. Shao, J. Mercat, A. Fang, J. Li, S. Keh, et al. Language models scale reliably with over-training and on downstream tasks. arXiv preprint arXiv:2403.08540, 2024. 2, 10
- 17 K. Gandhi, A. Chakravarthy, A. Singh, N. Lile, and N. D. Goodman. Cognitive behaviors that enable self-improving reasoners, or, four habits of highly effective stars, 2025. 1
- 18 M. Geva, D. Khashabi, E. Segal, T. Khot, D. Roth, and J. Berant. Did aristotle use a laptop? a question answering benchmark with implicit reasoning strategies. Transactions of the Association for Computational Linguistics, 9:346--361, 2021. 3, 21 19 A. Gu, B. Rozière, H. Leather, A. Solar-Lezama, G. Synnaeve, and S. I. Wang. Cruxeval: A benchmark for code reasoning, understanding and execution. arXiv preprint arXiv:2401.03065, 2024. 3, 21
- 20 D. Hendrycks, C. Burns, S. Kadavath, A. Arora, S. Basart, E. Tang, D. Song, and J. Steinhardt. Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874, 2021. 2, 3, 21
- 21 D. Hernandez, T. Brown, T. Conerly, N. DasSarma, D. Drain, S. El-Showk, N. Elhage, Z. Hatfield-Dodds, T. Henighan, T. Hume, et al. Scaling laws and interpretability of learning from repeated data. arXiv preprint arXiv:2205.10487, 2022. 1
- 22 J. Hestness, S. Narang, N. Ardalani, G. Diamos, H. Jun, H. Kianinejad, M. M. A. Patwary, Y. Yang, and Y. Zhou. Deep learning scaling is predictable, empirically. arXiv preprint arXiv:1712.00409, 2017. 1
- 23 J. Hoffmann, S. Borgeaud, A. Mensch, E. Buchatskaya, T. Cai, E. Rutherford, D. d. L. Casas, L. A. Hendricks, J. Welbl, A. Clark, et al. Training compute-optimal large language models. arXiv preprint arXiv:2203.15556, 2022. 1, 2, 10
- 24 S. Hu, Y. Tu, X. Han, C. He, G. Cui, X. Long, Z. Zheng, Y. Fang, Y. Huang, W. Zhao, et al. Minicpm: Unveiling the potential of small language models with scalable training strategies. arXiv preprint arXiv:2404.06395, 2024. 2
- 25 A. Ibrahim, B. Thérien, K. Gupta, M. L. Richter, Q. Anthony, T. Lesort, E. Belilovsky, and I. Rish. Simple and scalable strategies to continually pre-train large language models. arXiv preprint arXiv:2403.08763, 2024. 2, 5
- 26 J. Jin, V. Syrgkanis, S. Kakade, and H. Zhang. Discovering hierarchical latent capabilities of language models via causal representation learning, 2025. 10
- 27 J. Kaplan, S. McCandlish, T. Henighan, T. B. Brown, B. Chess, R. Child, S. Gray, A. Radford, J. Wu, and D. Amodei. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361, 2020. 1, 10
- 28 M. Kazemi, Q. Yuan, D. Bhatia, N. Kim, X. Xu, V. Imbrasaite, and D. Ramachandran. Boardgameqa: A dataset for natural language reasoning with contradictory information. Advances in Neural Information Processing Systems, 36:39052--39074, 2023. 3, 21
- 29 W. Kwon, Z. Li, S. Zhuang, Y. Sheng, L. Zheng, C. H. Yu, J. E. Gonzalez, H. Zhang, and I. Stoica. Efficient memory management for large language model serving with pagedattention. In Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023. 21
- 30 H. Li, W. Zheng, J. Hu, Q. Wang, H. Zhang, Z. Wang, S. Xuyang, Y. Fan, S. Zhou, X. Zhang, et al. Predictable scale: Part i--optimal hyperparameter scaling law in large language model pretraining. arXiv preprint arXiv:2503.04715, 2025. 2
- 31 J. LI, E. Beeching, L. Tunstall, B. Lipkin, R. Soletskyi, S. C. Huang, K. Rasul, L. Yu, A. Jiang, Z. Shen, Z. Qin, B. Dong, L. Zhou, Y. Fleureau, G. Lample, and S. Polu. Numinamath. https://huggingface.co/AI-MO/NuminaMath-CoT(https://github.com/ project-numina/aimo-progress-prize/blob/main/report/numina_dataset.pdf), 2024. 2, 21
- 32 A. Liu, B. Feng, B. Xue, B. Wang, B. Wu, C. Lu, C. Zhao, C. Deng, C. Zhang, C. Ruan, et al. Deepseek-v3 technical report. arXiv preprint arXiv:2412.19437, 2024. 1
- 33 C. Y. Liu, L. Zeng, J. Liu, R. Yan, J. He, C. Wang, S. Yan, Y. Liu, and Y. Zhou. Skywork-reward: Bag of tricks for reward modeling in llms. arXiv preprint arXiv:2410.18451, 2024. 3
- 34 E. Liu, A. Bertsch, L. Sutawika, L. Tjuatja, P. Fernandes, L. Marinov, M. Chen, S. Singhal, C. Lawrence, A. Raghunathan, et al. Not-just-scaling laws: Towards a better understanding of the downstream impact of language model design decisions. arXiv preprint arXiv:2503.03862, 2025. 1
- 35 P. Lu, L. Qiu, K.-W. Chang, Y. N. Wu, S.-C. Zhu, T. Rajpurohit, P. Clark, and A. Kalyan. Dynamic prompt learning via policy gradient for semi-structured mathematical reasoning. arXiv preprint arXiv:2209.14610, 2022. 3, 22
- 36 T. Mihaylov, P. Clark, T. Khot, and A. Sabharwal. Can a suit of armor conduct electricity? a new dataset for open book question answering. In EMNLP, 2018. 3
- 37 N. Muennighoff, A. Rush, B. Barak, T. Le Scao, N. Tazi, A. Piktus, S. Pyysalo, T. Wolf, and C. A. Raffel. Scaling data-constrained language models. Advances in Neural Information Processing Systems, 36:50358--50376, 2023. 10
- 38 G. Penedo, H. Kydlíˇcek, A. Lozhkov, M. Mitchell, C. A. Raffel, L. Von Werra, T. Wolf, et al. The fineweb datasets: Decanting the web for the finest text data at scale. Advances in Neural Information Processing Systems, 37:30811--30849, 2024. 2, 21
- 39 Z. Qi, M. Ma, J. Xu, L. L. Zhang, F. Yang, and M. Yang. Mutual reasoning makes smaller llms stronger problem-solvers. arXiv preprint arXiv:2408.06195, 2024. 2
- 40 Z. Qin, Q. Dong, X. Zhang, L. Dong, X. Huang, Z. Yang, M. Khademi, D. Zhang, H. H. Awadalla, Y. R. Fung, et al. Scaling laws of synthetic data for language models. arXiv preprint arXiv:2503.19551, 2025. 10
- 41 H. Que, J. Liu, G. Zhang, C. Zhang, X. Qu, Y. Ma, F. Duan, Z. Bai, J. Wang, Y. Zhang, et al. D-cpt law: Domain-specific continual pre-training scaling law for large language models. Advances in Neural Information Processing Systems, 37:90318--90354, 2024. 2, 10
- 42 M. Raghavendra, V. Nath, and S. Hendryx. Revisiting the superficial alignment hypothesis. arXiv preprint arXiv:2410.03717, 2024. 2, 7, 10
- 43 Y. Ren and D. J. Sutherland. Learning dynamics of llm finetuning. arXiv preprint arXiv:2407.10490, 2024. 2
- 44 K. Sakaguchi, R. L. Bras, C. Bhagavatula, and Y. Choi. Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM, 64(9):99--106, 2021. 3
- 45 R. Schaeffer, B. Miranda, and S. Koyejo. Are emergent abilities of large language models a mirage? Advances in Neural Information Processing Systems, 36:55565--55581, 2023. 2
- 46 F. Schmidt. Generalization in generation: A closer look at exposure bias. arXiv preprint arXiv:1910.00292, 2019. 2
- 47 J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017. 3
- 48 Y. Shen, M. Stallone, M. Mishra, G. Zhang, S. Tan, A. Prasad, A. M. Soria, D. D. Cox, and R. Panda. Power scheduler: A batch size and token number agnostic learning rate scheduler. arXiv preprint arXiv:2408.13359, 2024. 2
- 49 G. Sheng, C. Zhang, Z. Ye, X. Wu, W. Zhang, R. Zhang, Y. Peng, H. Lin, and C. Wu. Hybridflow: A flexible and efficient rlhf framework. arXiv preprint arXiv: 2409.19256, 2024. 2
- 50 C. Snell, E. Wallace, D. Klein, and S. Levine. Predicting emergent capabilities by finetuning. arXiv preprint arXiv:2411.16035, 2024. 10
- 51 J. M. Springer, S. Goyal, K. Wen, T. Kumar, X. Yue, S. Malladi, G. Neubig, and A. Raghunathan. Overtrained language models are harder to fine-tune. arXiv preprint arXiv:2503.19206, 2025. 2, 4, 10
- 52 G. Team, R. Anil, S. Borgeaud, J.-B. Alayrac, J. Yu, R. Soricut, J. Schalkwyk, A. M. Dai, A. Hauth, K. Millican, et al. Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805, 2023. 1
- 53 K. Tirumala, A. Markosyan, L. Zettlemoyer, and A. Aghajanyan. Memorization without overfitting: Analyzing the training dynamics of large language models. Advances in Neural Information Processing Systems, 35:38274--38290, 2022. 2
- 54 H. Tissue, V. Wang, and L. Wang. Scaling law with learning rate annealing. arXiv preprint arXiv:2408.11029, 2024. 2
- 55 S. Toshniwal, W. Du, I. Moshkov, B. Kisacanin, A. Ayrapetyan, and I. Gitman. Openmathinstruct-2: Accelerating ai for math with massive open-source instruction data. arXiv preprint arXiv:2410.01560, 2024. 2, 21
- 56 H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozière, N. Goyal, E. Hambro, F. Azhar, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023. 2, 18
- 57 J. Vendrow, E. Vendrow, S. Beery, and A. Madry. Do large language model benchmarks test reliability? arXiv preprint arXiv:2502.03461, 2025. 3, 21
- 58 Y. Wang, Q. Yang, Z. Zeng, L. Ren, L. Liu, B. Peng, H. Cheng, X. He, K. Wang, J. Gao, et al. Reinforcement learning for reasoning in large language models with one training example. arXiv preprint arXiv:2504.20571, 2025. 18
- 59 M. Xia, M. Artetxe, C. Zhou, X. V. Lin, R. Pasunuru, D. Chen, L. Zettlemoyer, and V. Stoyanov. Training trajectories of language models across scales. arXiv preprint arXiv:2212.09803, 2022. 2
- 60 A. Yang, B. Zhang, B. Hui, B. Gao, B. Yu, C. Li, D. Liu, J. Tu, J. Zhou, J. Lin, et al. Qwen2. 5-math technical report: Toward mathematical expert model via self-improvement. arXiv preprint arXiv:2409.12122, 2024. 21
- 61 E. Yeo, Y. Tong, M. Niu, G. Neubig, and X. Yue. Demystifying long chain-of-thought reasoning in llms. arXiv preprint arXiv:2502.03373, 2025. 2, 10
- 62 Ç. Yıldız, N. K. Ravichandran, N. Sharma, M. Bethge, and B. Ermis. Investigating continual pretraining in large language models: Insights and implications. arXiv preprint arXiv:2402.17400, 2024. 2
- 63 L. Yu, W. Jiang, H. Shi, J. Yu, Z. Liu, Y. Zhang, J. T. Kwok, Z. Li, A. Weller, and W. Liu. Metamath: Bootstrap your own mathematical questions for large language models. arXiv preprint arXiv:2309.12284, 2023. 2, 21
- 64 Y. Yue, Z. Chen, R. Lu, A. Zhao, Z. Wang, S. Song, and G. Huang. Does reinforcement learning really incentivize reasoning capacity in llms beyond the base model? arXiv preprint arXiv:2504.13837, 2025. 8, 10
- 65 R. Zellers, A. Holtzman, Y. Bisk, A. Farhadi, and Y. Choi. Hellaswag: Can a machine really finish your sentence? arXiv preprint arXiv:1905.07830, 2019. 3
- 66 B. Zhang, Z. Liu, C. Cherry, and O. Firat. When scaling meets llm finetuning: The effect of data, model and finetuning method. arXiv preprint arXiv:2402.17193, 2024. 2, 10
- 67 H. Zhang, D. Morwani, N. Vyas, J. Wu, D. Zou, U. Ghai, D. Foster, and S. M. Kakade. How does critical batch size scale in pre-training? In The Thirteenth International Conference on Learning Representations, 2025. 2
- 68 P. Zhang, G. Zeng, T. Wang, and W. Lu. Tinyllama: An open-source small language model. arXiv preprint arXiv:2401.02385, 2024. 18
- 69 S. Zhang, S. Roller, N. Goyal, M. Artetxe, M. Chen, S. Chen, C. Dewan, M. Diab, X. Li, X. V. Lin, et al. Opt: Open pre-trained transformer language models. arXiv preprint arXiv:2205.01068, 2022. 18
- 70 R. Zhao, A. Meterez, S. Kakade, C. Pehlevan, S. Jelassi, and E. Malach. Echo chamber: Rl post-training amplifies behaviors learned in pretraining. arXiv preprint arXiv:2504.07912, 2025. 1, 10
- 71 Y. Zheng, R. Zhang, J. Zhang, Y. Ye, Z. Luo, Z. Feng, and Y. Ma. Llamafactory: Unified efficient fine-tuning of 100+ language models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations), Bangkok, Thailand, 2024. Association for Computational Linguistics. 2
- 72 C. Zhou, P. Liu, P. Xu, S. Iyer, J. Sun, Y. Mao, X. Ma, A. Efrat, P. Yu, L. Yu, et al. Lima: Less is more for alignment. Advances in Neural Information Processing Systems, 36:55006--55021, 2023. 10
附录
附加实验结果
A.1 预训练模型的观察性比较
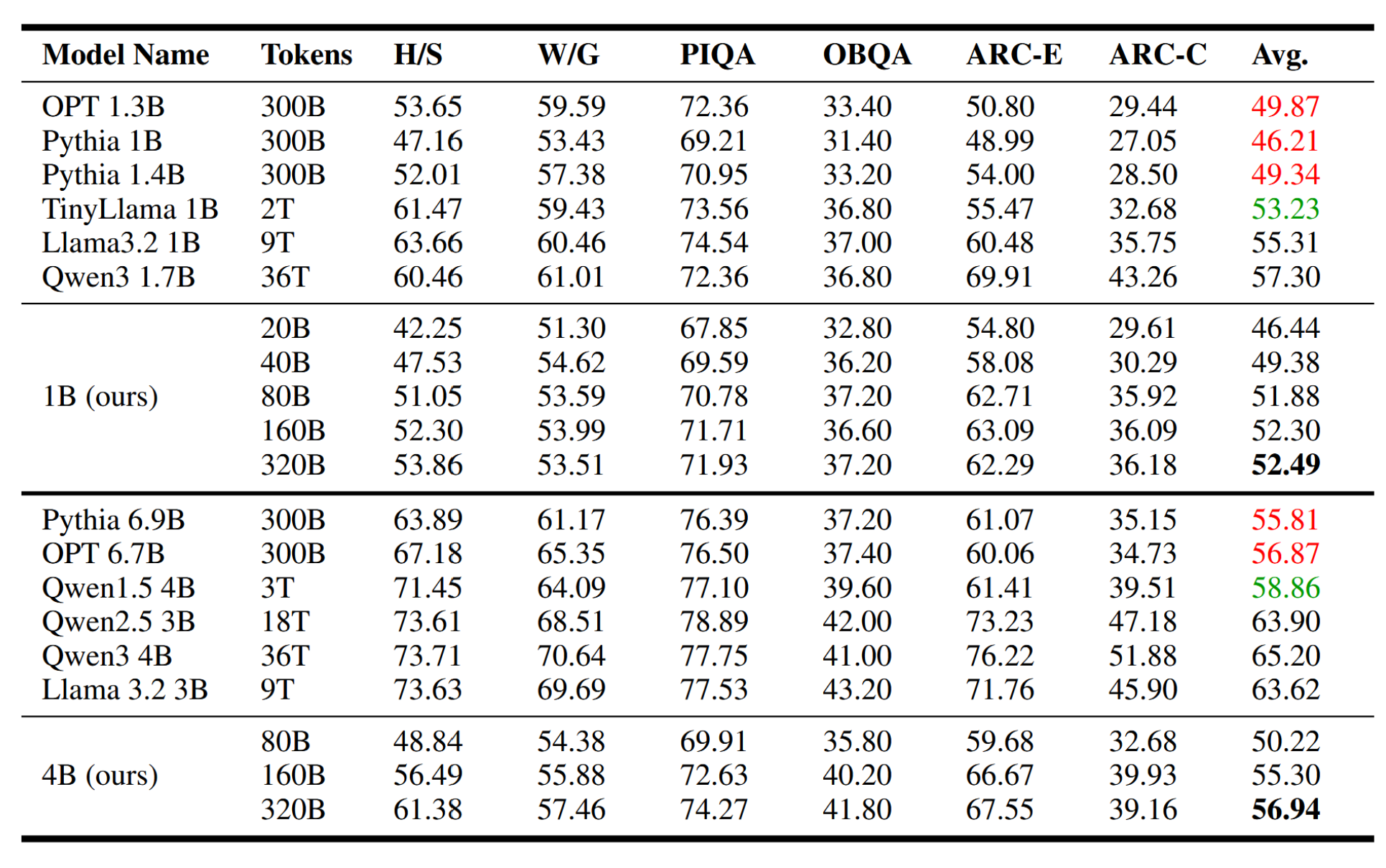
表4:各小型语言模型的上游基准比较。所有分数均为百分比。我们以粗体突出显示基础模型性能,以红色表示性能相当规模的模型,以绿色表示过度训练但性能相似的模型。
表1将我们的预训练模型与多个开放权重模型进行了比较,包括OPT 69、Pythia 5、TinyLlama 68、Llama 56和Qwen 3。我们的模型在显著更少的token(我们的1B和4B模型使用320B token)上完成预训练,却展现出与其他先进小模型(如基于2T token训练的TinyLlama-1B和基于3T token训练的Qwen1.5-4B)相竞争的性能。
具体而言,尽管TinyLlama-1B和Qwen1.5-4B模型分别使用了6.25倍和9.38倍的更多令牌进行训练,但我们的1B和4B模型在HellaSwag (H/S)、Winogrande (W/G)、PIQA、OBQA、ARC-Easy (ARC-E)和ARC-Challenge (ARC-C)等标准基准测试中取得了相似或略优的结果。这一实证观察与我们第3.1节的实验结果一致,强调了过度预训练的收益递减:超出某个最优计算阈值后,额外的预训练对通用领域上游任务性能的提升微乎其微。
A.2 扩展强化学习计算规模
为进一步探究扩展强化学习计算量的有效实践,我们在图11中以"示例-周期"为单位(示例数×周期数,以10^5计)绘制了结果。我们使用了与第3.4节相同的配置。在固定计算预算下,将更多周期分配到一个中等规模数据集(例如100K×8 = 800K示例-周期)通常比将计算量分散到更大但周期更少的数据集上能获得更高的分布内和分布外性能,而使用过多训练示例进行强化学习有时会因响应过长且未完成而导致性能崩溃(如图11中的叉号及图12中的响应长度所示),但在使用过多训练周期进行强化学习时,我们并未观察到此类问题(如图13所示)。这表明,对于强化学习扩展,每个样本上的更深度策略优化比更广泛的数据覆盖更具成本效益,这与文献58提出的发现一致,即即使仅使用一个训练示例进行强化学习,也能有效激发大型语言模型的数学推理能力。
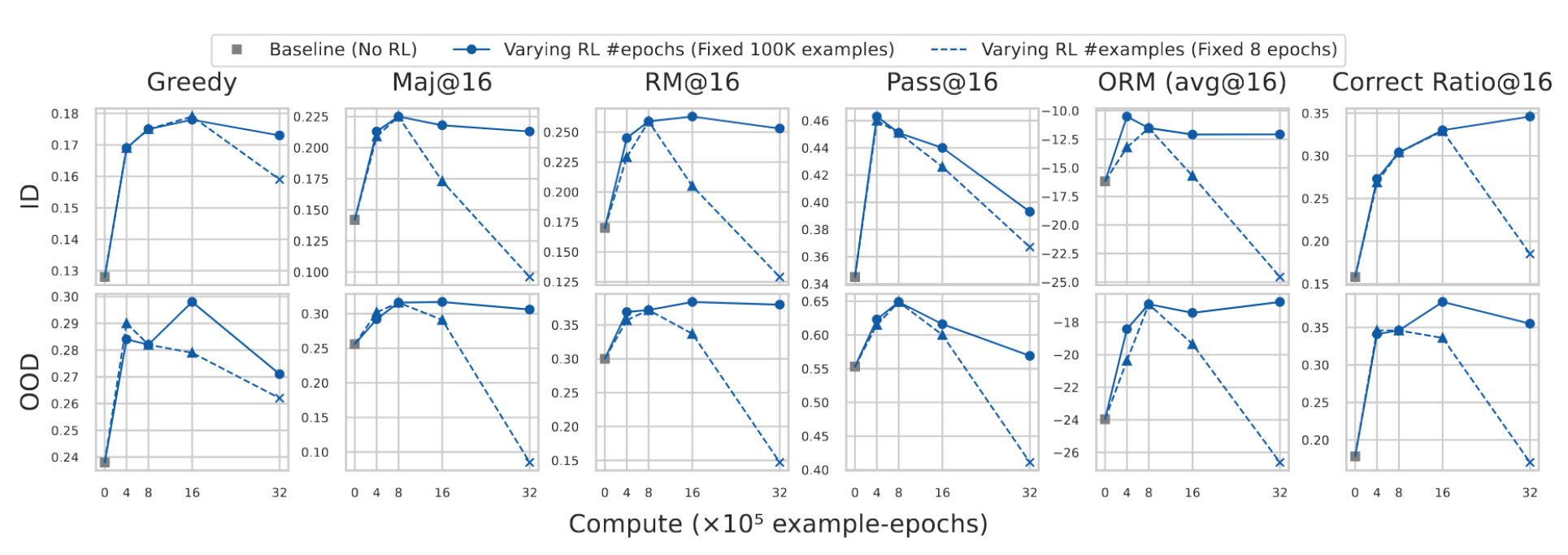
图11:下游任务性能与RL计算量对比。叉号表示倾向于生成超过其上下文窗口限制长度的响应的模型。
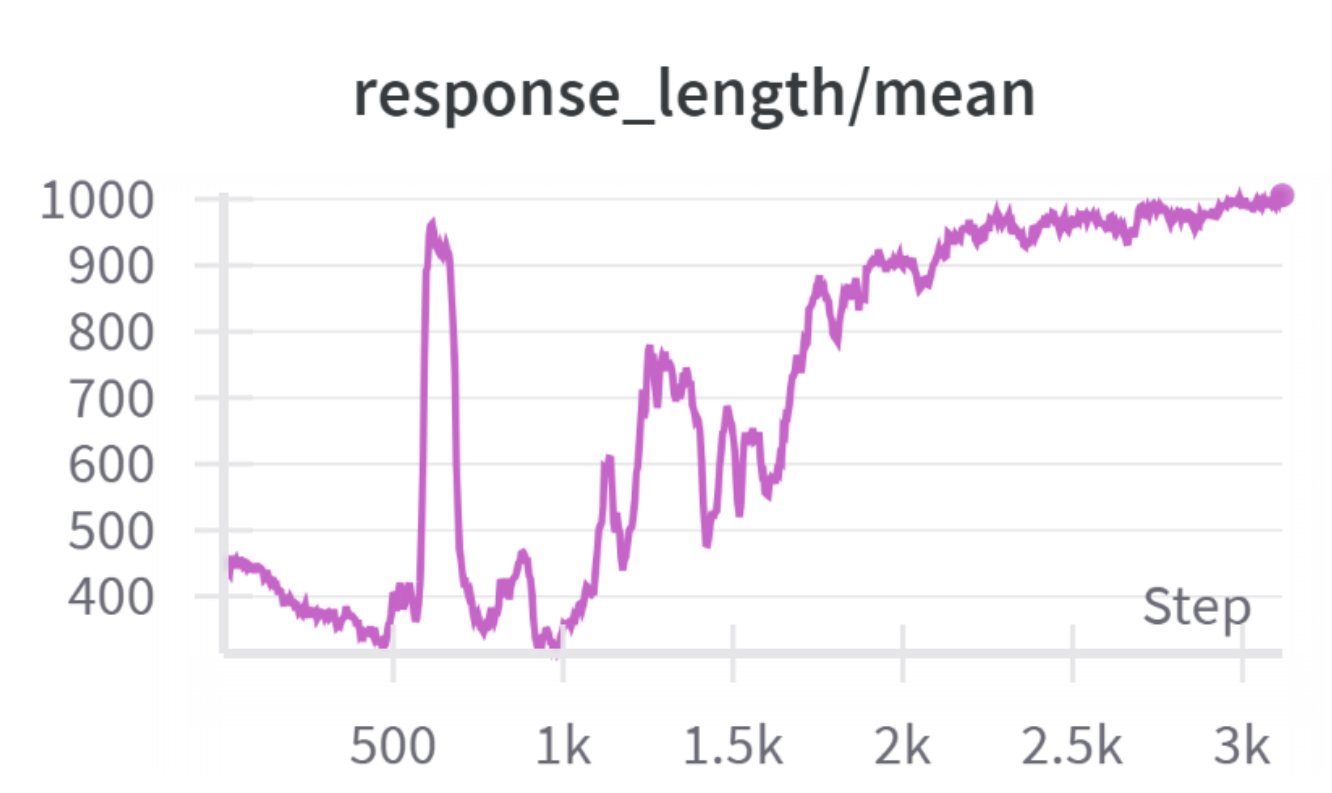
图12:在调整1B-160BT-8+42BT-100Kep1400Kep8时响应长度与训练步骤的关系图。
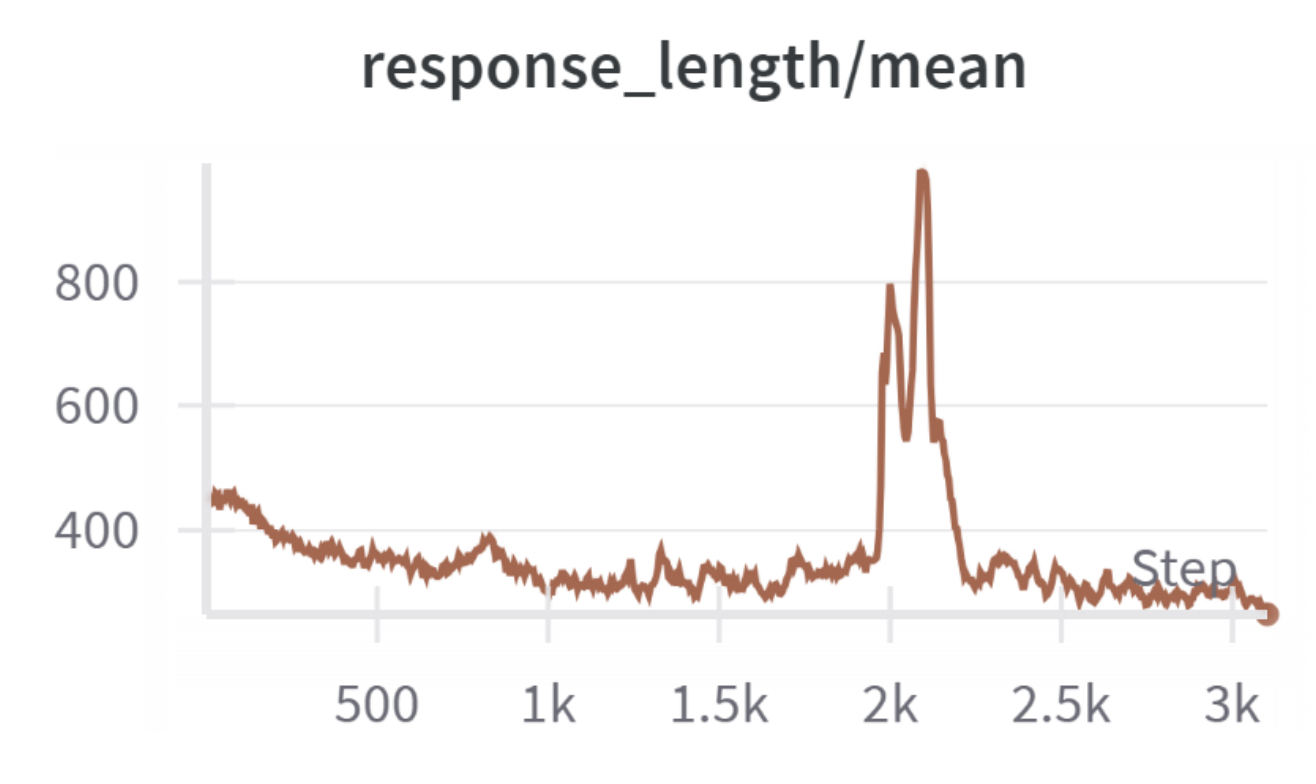
图13:在调优1B-160BT-8+42BT-100Kep1100Kep32时响应长度与训练步数的关系。
A.3 后训练模型在语言建模任务上校准不良
我们的上游评估表明,后训练的语言模型在通过验证集困惑度(PPL)评估时表现出显著的校准误差。我们针对每个后训练模型,在验证集(与训练集不相交)上评估PPL。如图14所示,我们观察到,各数据集的验证集困惑度与下游任务准确性之间的相关性可忽略不计。具体而言,皮尔逊相关系数接近于零,这进一步证实了低困惑度并不能可靠地预测生成推理性能的提升。这与第4.2节讨论的ORM评分所展现的强大预测能力形成了鲜明对比。尽管验证集困惑度通常用于监控模型质量,但在后训练阶段(尤其是评估生成推理任务时)却不足以胜任。在实际应用中,仅依赖困惑度作为验证指标可能会误导训练过程中的资源分配决策。

图14:不同任务下准确率与验证困惑度之间的相关性。每个子图代表一个数据集,其中每个点对应一个训练后的模型变体。虚线表示线性趋势,每个子图标题中报告了皮尔逊相关系数。
B 可重复性
B.1 模型架构
我们在表5中展示了0.5B、1B和4B模型的架构细节。

表5:模型架构细节。
B.2 训练细节
B.2.1 超参数
预训练/持续预训练、SFT和RL的超参数分别见表6、表7和表8。我们在所有训练阶段均使用AdamW优化器,最多配备32块NVIDIA H100 80GB HBM3 GPU。对于预训练、持续预训练和SFT,我们采用标准的热身-余弦衰减学习率调度策略。对于RL,我们应用热身-恒定学习率调度策略。
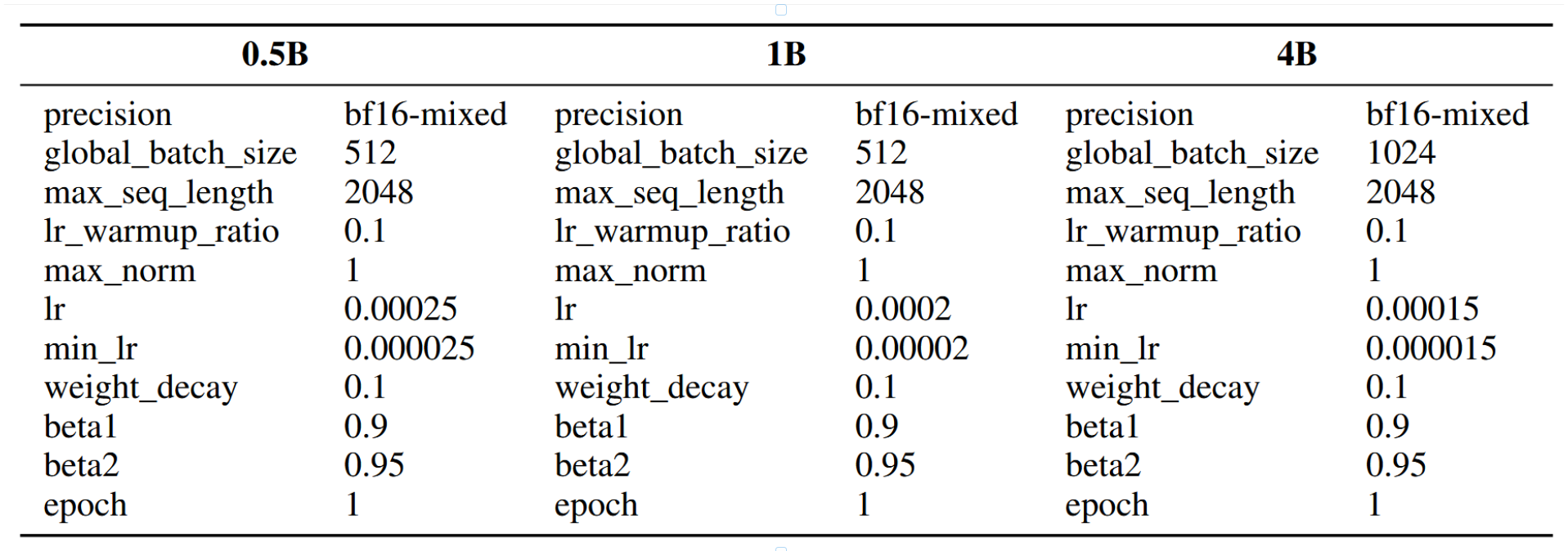
表6:预训练/持续预训练的超参数。
表7:监督微调的超参数。
B.2.2 SFT/RL 模板
我们使用以下模板进行SFT和RL调优:
人类:{query} 助手:{response}
表8:强化学习(PPO)的超参数。
B.2.3 训练数据
FineWeb-Edu 38:一个从网络内容中提取的广泛教育数据集,专门设计用于在高质量学术和教育文本上预训练语言模型,总计约1.3万亿个令牌。
FineMath 38:一个包含数学文本、问题和解答的精选数据集,旨在增强语言模型的数学知识,总计约500亿个令牌。
OpenMathInstruct2 55、MetaMathQA 63、NuminaMath 31:指令调优数据集,包含数学问题及其逐步解答和解释,旨在提升大语言模型的数学推理能力。这些数据集中与提示对应的回答通过调用Qwen2.5-7B-Math-Instruct模型 60 收集得到。
B.3 评估细节
B.3.1 基准与采样参数
对于所有测试数据集和所有模型,我们直接使用与SFT/RL相同的提示模板向模型提出相应问题。我们将贪婪解码的温度设置为0,随机解码(生成次数为16)的温度设置为1,并将重复惩罚设置为1.1。我们使用vLLM框架29进行推理。每个测试数据集的详细信息如下。
MATH 20是一个旨在评估数学推理能力的大规模基准测试。它包含来自数学竞赛的12,500个具有挑战性的问题,涵盖代数、几何、微积分和数论等七个主题,并分为五个难度等级。每个问题需要生成详细的逐步解答,而非简单的数值答案,强调全面的推理能力和逻辑演绎。
GSM8K-Platinum 57是GSM8K 12的手动清洗与去噪版本。GSM8K是一个数学基准测试,包含8,500个高质量、语言多样的小学数学应用题,专为多步推理(2至8步)设计。解答涉及基础算术运算,且无需早期代数以外的概念。其测试集包含1,319个独特问题。
BoardgameQA 28是一个逻辑推理基准测试,旨在评估语言模型使用可废止推理处理矛盾信息的能力,其中冲突基于来源偏好(如可信度或时效性)解决。其测试集包含15,000个独特问题。
CRUXEval 19是一个用于评估代码推理、理解与执行的基准测试,包含800个Python函数(3-13行),附带输入输出对,用于输入和输出预测任务。给定函数片段和输入示例,LLM需生成相应输出。其测试集包含800个独特问题。
StrategyQA 18是一个常识问答基准测试,专为多跳推理设计,其中必要的推理步骤是隐含的,必须通过策略推断。其2,780个示例均包含一个策略问题、逐步分解过程以及支持性的维基百科证据。
TabMWP 35 是一个引入用于评估表格数据上数学推理的基准测试。它包含约38,000个数学文字问题,每个问题都附有相关表格,涵盖算术运算、比较和聚合任务等多种数学推理类型。
B.3.2 统计显著性
在B.3.2节中,我们展示了第3节所有主要结果中模型在ID和OOD任务上的性能标准误差,包括Maj@16、Pass@16、RM@16、ORM评分和正确率。这些结果来自四次不同随机种子的实验。
表9:预训练扩展(第3.1节)、CPT(第3.2节)、SFT(第3.3节)和RL(第3.4节)主要结果的标准误差。Maj@16、Pass@16、RM@16和Correct Ratio@16的统计值以百分比表示。